






一、实验目的
了解什么是OpenMP,如何应用OpenMP。
运用OpenMP程序结构编写程序,了解蒙特卡罗算法。
二、实验内容
利用蒙特卡罗算法计算半径为 1 单元的球体体积。要求:
- 分别用串行程序和OpenMP并行程序实现;
- 比较并行和串行程序的执行时间;
- 计算并行程序相对于串行程序的加速比;
三、 实验环境
(1)并行命令:OpenMP
(2)支持命令配置:Visual Studio 2020
(3)CPU: Intel(R) i7-12700H 2.70 GHz
四、实验过程
(1)实验环境搭建
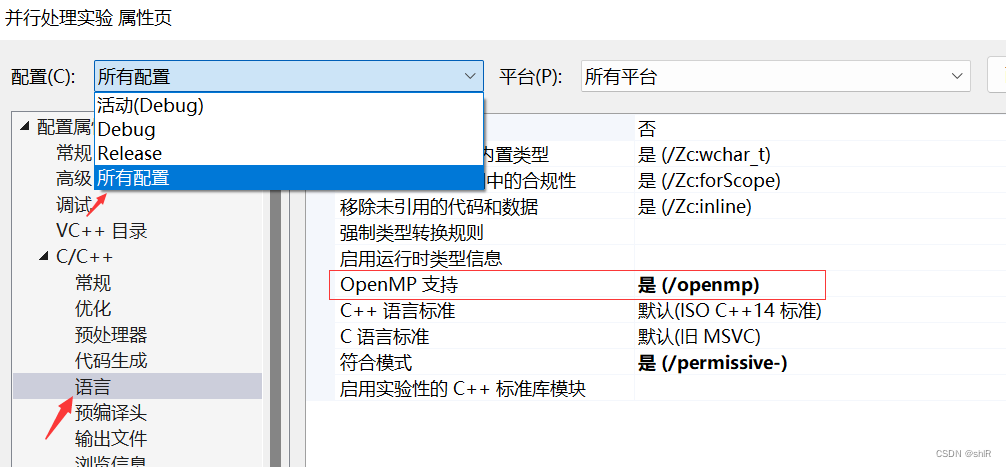
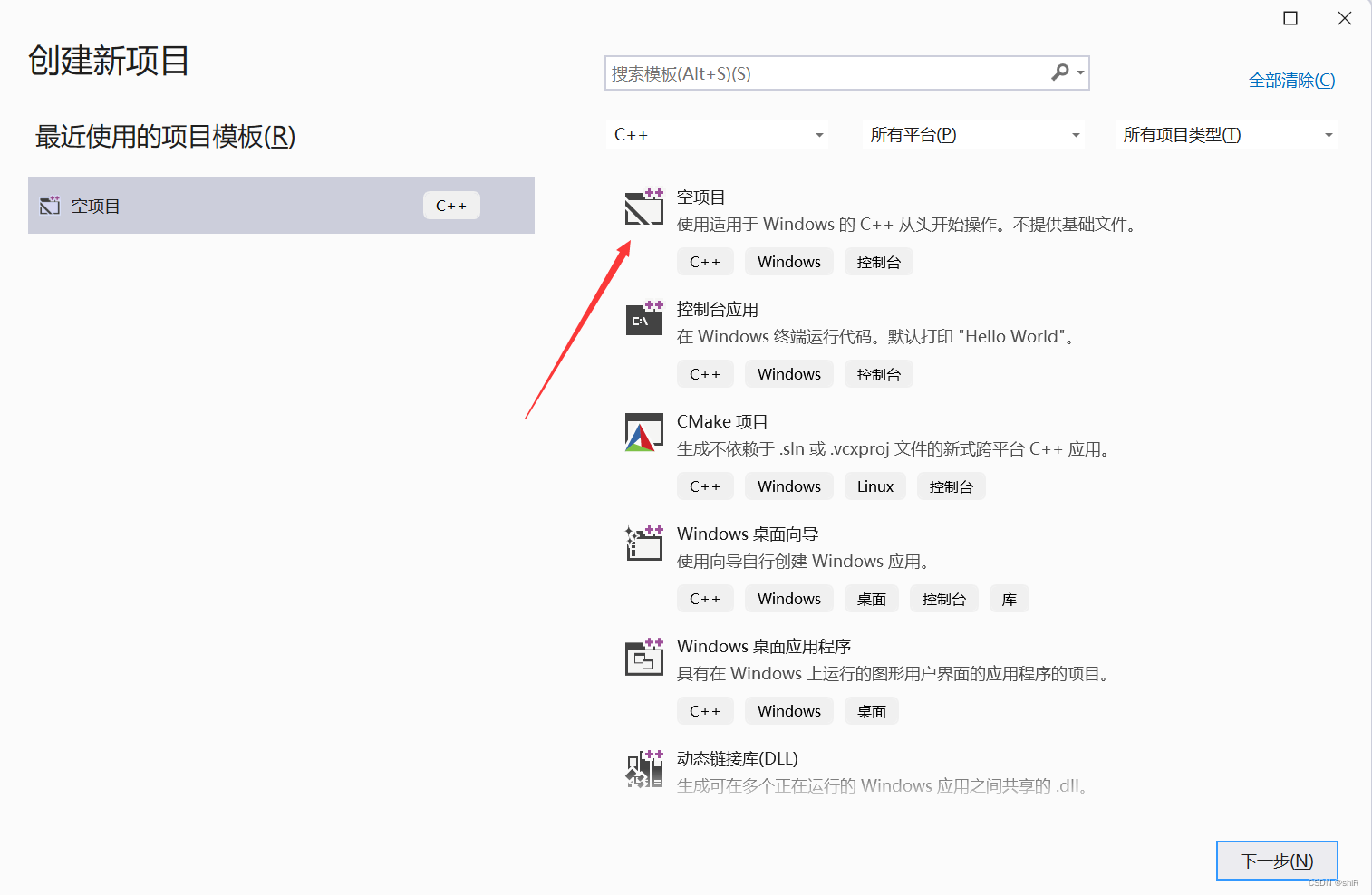
在VS中启用OpenMP,解决方案资源管理器->项目->属性->配置框选择所有配置->openmp支持选择(是),创建项目时,一定是新项目不是控制台应用。
(2)程序设计说明
1、蒙特卡罗算法原理
蒙特·卡罗方法(Monte Carlo method),也称统计模拟方法,它是一种思想或者方法的统称,而不是严格意义上的算法。蒙特卡罗方法的起源是1777年由法国数学家布丰(Comte de Buffon)提出的用投针实验方法求圆周率,在20世纪40年代中期,由于计算机的发明结合概率统计理论的指导,从而正式总结为一种数值计算方法,其主要是用随机数来估算计算问题。
2、蒙特卡罗算法的基本步骤
蒙特卡罗算法一般分为三个步骤,包括构造随机的概率的过程,从构造随机概率分布中抽样,求解估计量。
<1> 构造随机的概率过程
对于本身就具有随机性质的问题,要正确描述和模拟这个概率过程。对于本来不是随机性质的确定性问题,比如计算定积分,就必须事先构造一个人为的概率过程了。它的某些参数正好是所要求问题的解,将不具有随机性质的问题转化为随机性质的问题。
<2> 从已知概率分布抽样
由于各种概率模型都可以看作是由各种各样的概率分布构成的,因此产生已知概率分布的随机变量,就成为实现蒙特卡罗方法模拟实验的基本手段。随机数是我们实现蒙特卡罗模拟的基本工具。
<3> 求解估计量
实现模拟实验后,确定一个随机变量,作为所要求问题的解,即无偏估计。建立估计量,相当于对实验结果进行考察,从而得到问题的解。
(3)实验步骤
1、并行串行
parallel:用在一个结构块之前,表示这段代码将被多个线程并行执行;
parallel for: parallel和for指令的结合,也是用在for循环语句之前,表示for循环体的代码将被多个线程并行执行,它同时具有并行域的产生和任务分担两个功能
private:指定一个或多个变量在每个线程中都有它自己的私有副本
2、程序执行时间计算
对比两个程序执行时间,用clock()函数
<1>clock()函数在头文件#include<time.h>中。
<2>clock()函数的返回值类型为clock_t。clock_t其实是long,即长整形。
<3>clock()函数的功能:从程序被调用,创建程序进程到clock()函数调用之间的cpu时间计时单位
3、加速比
加速比(speedup),是同一个任务在单处理器系统和并行处理器系统中运行消耗的时间的比率,用来衡量并行系统或程序并行化的性能和效果。
计算公式:Sp=T1/Tp。Sp是加速比,T1是单处理器下的运行时间,Tp是在有P个处理器并行系统中的运行时间。
(4)源程序
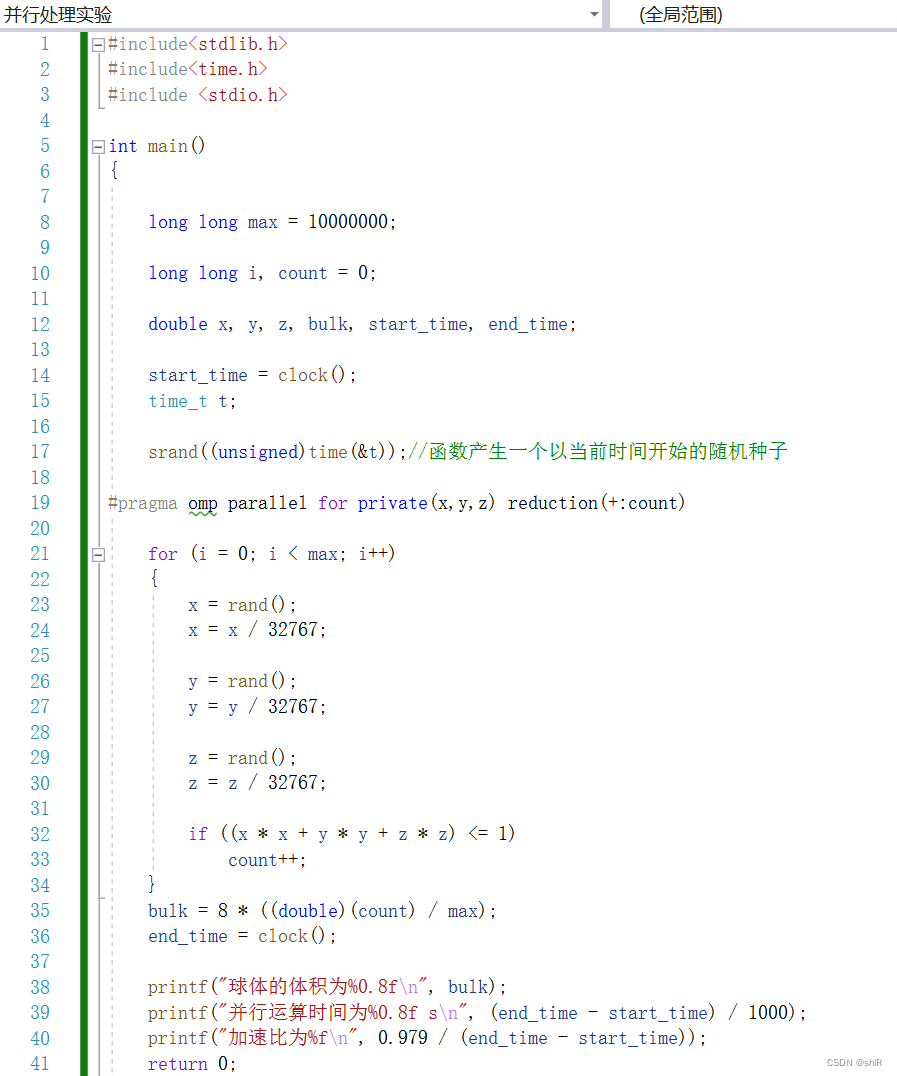
(1)并行程序
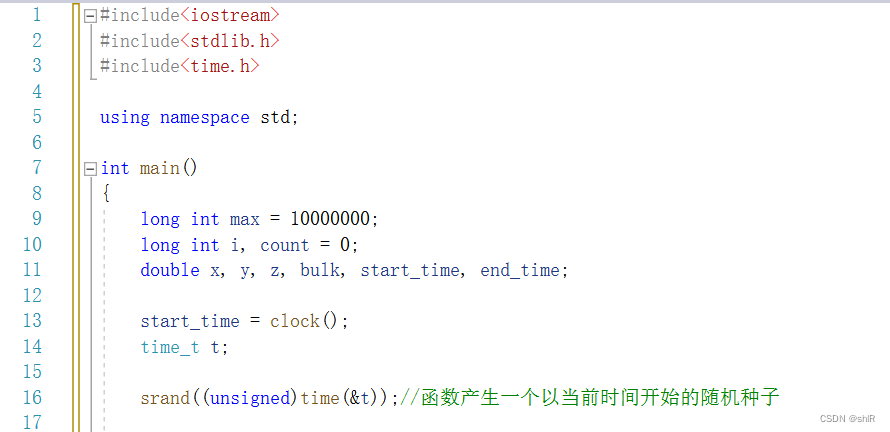
(2)串行程序
(5)程序运行结果
串行处理计算结果:
球体体积约为4.19,串行执行时间为0.979s

并行处理计算结果:
球体体积约为4.19,并行执行时间为0.115s

加速比计算:串行执行时间/并行执行时间≈8.434
(6)结果分析
通过实验1,2结果可以看到,并行执行程序时间明显比串行执行程序时间要短,而且线程数量约多,每个线程分工工作数量约少,同时工作的时间越少效率越高,从而执行时间越少。 计算出的加速比约等于8.434,加速比每台机器的加速比不一样,加速比更能反映出程序并行化的性能和效果,通常情况下,并行线程处理时间约小,加速比越大,处理时间和线程数挂钩,也就是说线程数越多,执行效率越高,加速比也越大。
从而总结出多线程的优势:可并行处理任务,减少单个任务的等待时间;线程较进程开销更小;线程间可共享资源;多核情况下可充分利用CPU资源。发挥多处理器的强大性能,提升资源利用率以及系统的吞吐率。提供更好的GUI交互体验(如腾讯视频可边下边播)充分利用服务器硬件资源;提高服务吞吐量、降低响应时间。
五、出现的问题及解决方法
1、在VS中配置OpenMP时,一般情况下,建的是空项目文件,可以自己写头文件等代码,而控制台应用项目文件会初始化基本的配置。选择控制台应用时,按照网上的配置程序找不到配置openmp的那个选项,也就是项目属性下面的C/C++下面的语言下面的开启openmp选项找不到。选择空项目。才会出现OpenMP选项
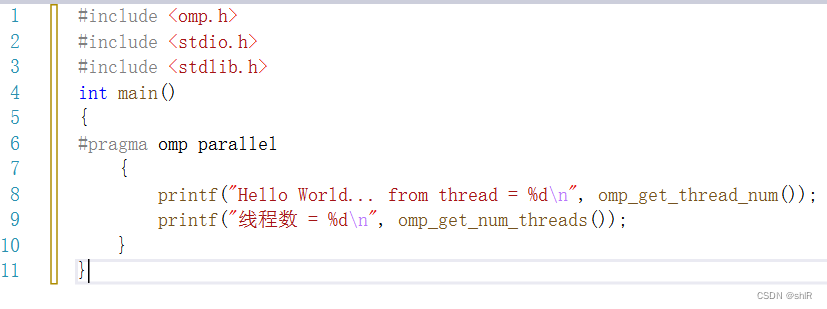
2、验证OpenMP是否配置成功
通过代码测试本机的核数
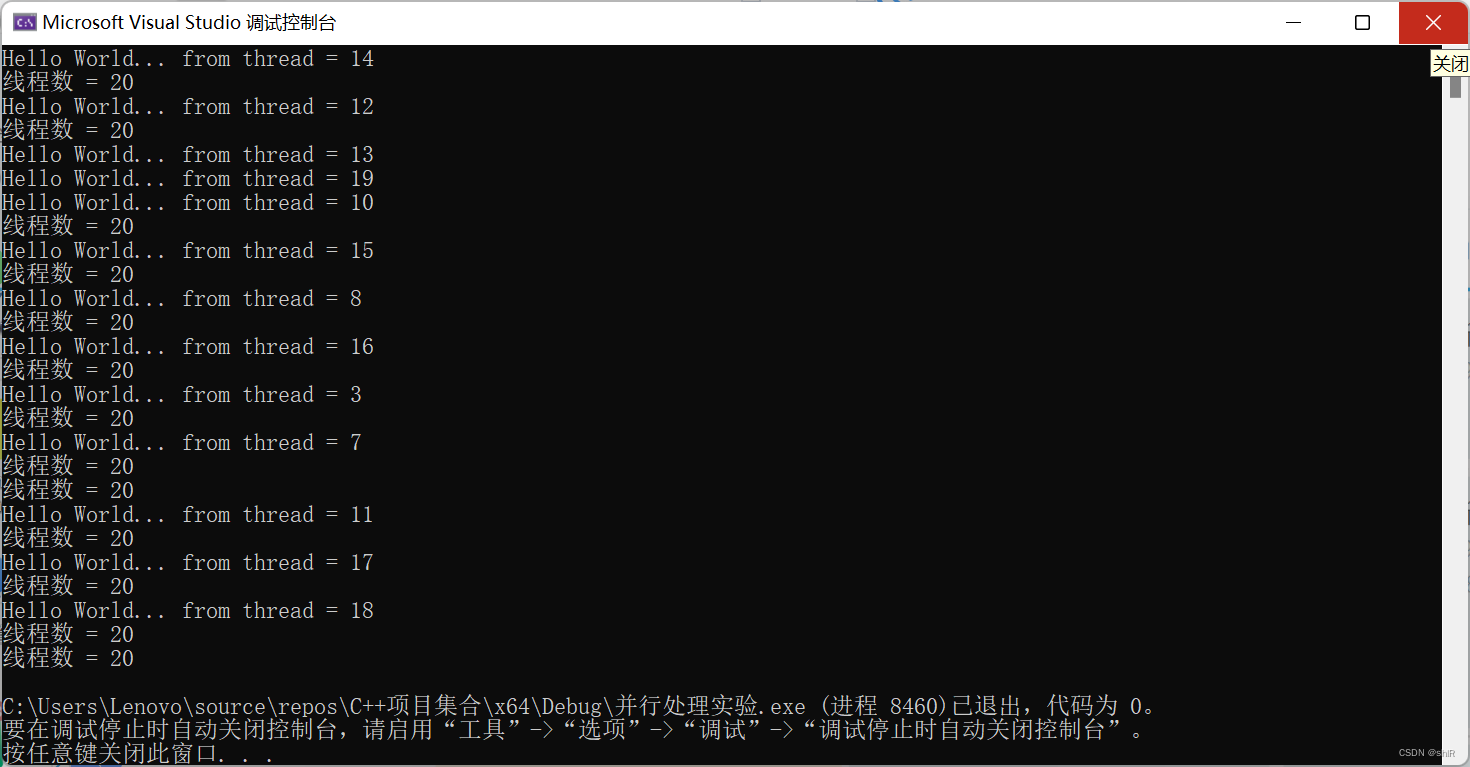
六、实验总结
OpenMP采用fork-join的执行模式。开始的时候只存在一个主线程,当需要进行并行计算的时候,派生出若干个分支线程来执行并行任务。当并行代码执行完成之后,分支线程会合,并把控制流程交给单独的主线程。
OpenMP是一种用于共享内存并行系统的多线程程序设计方案,支持的编程语言包括C、C++和Fortran。OpenMP提供了对并行算法的高层抽象描述,特别适合在多核CPU机器上的并行程序设计。编译器根据程序中添加的pragma指令,自动将程序并行处理,使用OpenMP降低了并行编程的难度和复杂度。当编译器不支持OpenMP时,程序会退化成普通(串行)程序。程序中已有的OpenMP指令不会影响程序的正常编译运行。
并行处理多线程可并行处理任务,减少单个任务的等待时间;线程较进程开销更小;线程间可共享资源;多核情况下可充分利用CPU资源。发挥多处理器的强大性能,提升资源利用率以及系统的吞吐率。提供更好的GUI交互体验(如腾讯视频可边下边播)充分利用服务器硬件资源;提高服务吞吐量、降低响应时间;
单进程多线程模型不方便通过操作系统管理。一旦出现死锁或者线程阻塞很容易导致整个VM进程挂起失去响应,隔离性很差。设计更复杂:资源共享、数据一致性及可见性、调试困难;线程安全问题。锁竞争、上下文切换开销、内存开销
















 1042
1042











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









