







 本文探讨了无向图模型的学习问题,重点介绍了极大似然估计的挑战与解决方法,包括随机最大似然法和对比散度法,并详细解析了受限玻尔兹曼机的学习过程。
本文探讨了无向图模型的学习问题,重点介绍了极大似然估计的挑战与解决方法,包括随机最大似然法和对比散度法,并详细解析了受限玻尔兹曼机的学习过程。
一、概述
对于有向概率图模型来说,由于图中存在天然的拓扑排序关系,所以有向概率图的因式分解的形式很容易写出来。而对于无向图来说就需要根据它图中的最大团来写成一个因式分解的形式,无向图模型在局部并没有表现出是一个概率模型,在整体上才表现地是一个概率模型,由此我们也就遇到了配分函数。在无向图模型的学习和评估问题中,我们会面对概率公式中的配分函数(Partition Function),往往这个配分函数是很难处理的。
对于连续或离散的高维随机变量 x ∈ R p o r { 0 , 1 , ⋯ , k } p x\in \mathbb{R}^{p}\; or\; \left \{0,1,\cdots ,k\right \}^{p} x∈Rpor{0,1,⋯,k}p,它可以表示成一个无向概率图,模型参数为 θ \theta θ,它的概率公式也就可以写成以下形式:
P ( x ; θ ) = 1 Z ( θ ) P ^ ( x ; θ ) P(x;\theta )=\frac{1}{Z(\theta )}\hat{P}(x;\theta ) P(x;θ)=Z(θ)1P^(x;θ)
其中 Z ( θ ) Z(\theta ) Z(θ)也就是配分函数,可以表示为:
Z ( θ ) = P ^ ( x ; θ ) d x Z(\theta )=\hat{P}(x;\theta )\mathrm{d}x Z(θ)=P^(x;θ)dx
对于这个概率模型的参数估计,可以采用极大似然估计的方法,首先,我们有一些样本,表示为 X = { x i } i = 1 N X=\left \{x_{i}\right \}_{i=1}^{N} X={xi}i=1N,然后使用这些样本来做极大似然估计:
θ ^ = a r g m a x θ P ( X ; θ ) = a r g m a x θ ∏ i = 1 N P ( x i ; θ ) = a r g m a x θ l o g ∏ i = 1 N P ( x i ; θ ) = a r g m a x θ ∑ i = 1 N l o g P ( x i ; θ ) = a r g m a x θ ∑ i = 1 N ( l o g P ^ ( x i ; θ ) − l o g Z ( θ ) ) = a r g m a x θ ∑ i = 1 N l o g P ^ ( x i ; θ ) − N l o g Z ( θ ) = a r g m a x θ 1 N ∑ i = 1 N l o g P ^ ( x i ; θ ) − l o g Z ( θ ) ⏟ 记 作 l ( θ ) \hat{\theta }=\underset{\theta }{argmax}\; P(X;\theta )\\ =\underset{\theta }{argmax}\prod_{i=1}^{N}P(x_{i};\theta )\\ =\underset{\theta }{argmax}\; log\prod_{i=1}^{N}P(x_{i};\theta )\\ =\underset{\theta }{argmax}\sum_{i=1}^{N} logP(x_{i};\theta )\\ =\underset{\theta }{argmax}\sum_{i=1}^{N}\left (log\hat{P}(x_{i};\theta )-logZ(\theta )\right ) \\ =\underset{\theta }{argmax}\sum_{i=1}^{N}log\hat{P}(x_{i};\theta )-NlogZ(\theta )\\ =\underset{\theta }{argmax}\underset{记作l(\theta )}{\underbrace{\frac{1}{N}\sum_{i=1}^{N}log\hat{P}(x_{i};\theta )-logZ(\theta )}} θ^=θargmaxP(X;θ)=θargmaxi=1∏NP(xi;θ)=θargmaxlogi=1∏NP(xi;θ)=θargmaxi=1∑NlogP(xi;θ)=θargmaxi=1∑N(logP^(xi;θ)−logZ(θ))=θargmaxi=1∑NlogP^(xi;θ)−NlogZ(θ)=θargmax记作l(θ) N1i=1∑NlogP^(xi;θ)−logZ(θ)
这里我们也就得到了目标函数 l ( θ ) l(\theta ) l(θ):
l ( θ ) = 1 N ∑ i = 1 N l o g P ^ ( x i ; θ ) − l o g Z ( θ ) l(\theta )=\frac{1}{N}\sum_{i=1}^{N}log\hat{P}(x_{i};\theta )-logZ(\theta ) l(θ)=N1i=1∑NlogP^(xi;θ)−logZ(θ)
接下来使用梯度上升的方法来求解参数 θ \theta θ,因此也就需要对 l ( θ ) l(\theta ) l(θ)求导:
∇ θ l ( θ ) = 1 N ∑ i = 1 N ∇ θ l o g P ^ ( x i ; θ ) ⏟ ① − ∇ θ l o g Z ( θ ) ⏟ ② \nabla _{\theta }l(\theta )=\underset{①}{\underbrace{\frac{1}{N}\sum_{i=1}^{N}\nabla _{\theta }log\hat{P}(x_{i};\theta )}}-\underset{②}{\underbrace{\nabla _{\theta }logZ(\theta )}} ∇θl(θ)=① N1i=1∑N∇θlogP^(xi;θ)−② ∇θlogZ(θ)
这里我们首先看一下②这一项的求导:
② = ∇ θ l o g Z ( θ ) = 1 Z ( θ ) ∇ θ Z ( θ ) = P ( x ; θ ) P ^ ( x ; θ ) ∇ θ ∫ P ^ ( x ; θ ) d x = P ( x ; θ ) P ^ ( x ; θ ) ∫ ∇ θ P ^ ( x ; θ ) d x = ∫ P ( x ; θ ) P ^ ( x ; θ ) ∇ θ P ^ ( x ; θ ) d x = ∫ P ( x ; θ ) ∇ θ l o g P ^ ( x ; θ ) d x = E P ( x ; θ ) [ ∇ θ l o g P ^ ( x ; θ ) ] ②=\nabla _{\theta }logZ(\theta )\\ ={\color{Red}{\frac{1}{Z(\theta )}}}{\color{Blue}{\nabla _{\theta }Z(\theta )}}\\ ={\color{Red}{\frac{P(x;\theta )}{\hat{P}(x;\theta )}}}{\color{Blue}{\nabla _{\theta }\int \hat{P}(x;\theta )\mathrm{d}x}}\\ =\frac{P(x;\theta )}{\hat{P}(x;\theta )}\int \nabla _{\theta }\hat{P}(x;\theta )\mathrm{d}x\\ =\int \frac{P(x;\theta )}{\hat{P}(x;\theta )}\nabla _{\theta }\hat{P}(x;\theta )\mathrm{d}x\\ =\int P(x;\theta )\nabla _{\theta }log\hat{P}(x;\theta )\mathrm{d}x\\ =E_{P(x;\theta )}\left [\nabla _{\theta }log\hat{P}(x;\theta )\right ] ②=∇θlogZ(θ)=Z(θ)1∇θZ(θ)=P^(x;θ)P(x;θ)∇θ∫P^(x;θ)dx=P^(x;θ)P(x;θ)∫∇θP^(x;θ)dx=∫P^(x;θ)P(x;θ)∇θP^(x;θ)dx=∫P(x;θ)∇θlogP^(x;θ)dx=EP(x;θ)[∇θlogP^(x;θ)]
注意这里的 P ( x ; θ ) P ^ ( x ; θ ) \frac{P(x;\theta )}{\hat{P}(x;\theta )} P^(x;θ)P(x;θ)之所以能够放到积分号里面,是因为对于任意 x x x来说 P ( x ; θ ) P ^ ( x ; θ ) \frac{P(x;\theta )}{\hat{P}(x;\theta )} P^(x;θ)P(x;θ)都是个常数。
上面式子之所以这么变换的目的也就是要将这个导数写成关于 P ( x ; θ ) P(x;\theta ) P(x;θ)的期望的形式,然而 P ( x ; θ ) P(x;\theta ) P(x;θ)正是我们要求解的分布,是一个未知的分布,因此没办法精确求解,也就没办法计算这个梯度 ∇ θ l ( θ ) \nabla _{\theta }l(\theta ) ∇θl(θ),只能近似采样。如果没有②这一项, l ( θ ) l(\theta) l(θ)就可以采用梯度上升,但是由于存在配分函数就无法直接采用梯度上升了。以上就是问题所在。
二、随机最大似然(Stochastic Maximum Likelihood)
现在我们可以把 ∇ θ l ( θ ) \nabla _{\theta }l(\theta ) ∇θl(θ)下面的形式:
∇ θ l ( θ ) = 1 N ∑ i = 1 N ∇ θ l o g P ^ ( x i ; θ ) − E P ( x ; θ ) [ ∇ θ l o g P ^ ( x ; θ ) ] \nabla _{\theta }l(\theta )=\frac{1}{N}\sum_{i=1}^{N}\nabla _{\theta }log\hat{P}(x_{i};\theta )-E_{P(x;\theta )}\left [\nabla _{\theta }log\hat{P}(x;\theta )\right ] ∇θl(θ)=N1i=1∑N∇θlogP^(xi;θ)−EP(x;θ)[∇θlogP^(x;θ)]
对于我们的训练数据,我们可以把它们看做服从一个分布 P d a t a P_{data} Pdata,这个分布也就是训练数据的真实分布,是我们要去拟合的分布,然而也是一个我们永远不可能真正精确得到的分布,因为我们能够拿到的只有这个分布的若干样本(也就是训练数据)。有了 P d a t a P_{data} Pdata这个定义以后,我们也可以把上面梯度中减号左边的一项写成期望的形式:
∇ θ l ( θ ) = E P d a t a [ ∇ θ l o g P ^ ( x ; θ ) ] − E P ( x ; θ ) [ ∇ θ l o g P ^ ( x ; θ ) ] \nabla _{\theta }l(\theta )={\color{Red}{E_{P_{data}}}}\left [\nabla _{\theta }log\hat{P}(x;\theta )\right ]-E_{P(x;\theta )}\left [\nabla _{\theta }log\hat{P}(x;\theta )\right ] ∇θl(θ)=EPdata[∇θlogP^(x;θ)]−EP(x;θ)[∇θlogP^(x;θ)]
我们的目的也就是要让 P ( x ; θ ) P(x;\theta ) P(x;θ)尽可能地逼近 P d a t a P_{data} Pdata,这个 P ( x ; θ ) P(x;\theta ) P(x;θ)也就是我们的模型,所以我们把 P ( x ; θ ) P(x;\theta ) P(x;θ)这个分布记作 P m o d e l P_{model} Pmodel,现在我们就有了两个定义的分布,即数据的真实分布 P d a t a P_{data} Pdata和用来拟合 P d a t a P_{data} Pdata的 P m o d e l P_{model} Pmodel:
{ d a t a d i s t r i b u t i o n : P d a t a m o d e l d i s t r i b u t i o n : P m o d e l ≜ P ( x ; θ ) \left\{\begin{matrix} data\; distribution:P_{data}\\ model\; distribution:P_{model}\triangleq P(x;\theta ) \end{matrix}\right. {datadistribution:Pdatamodeldistribution:Pmodel≜P(x;θ)
现在 ∇ θ l ( θ ) \nabla _{\theta }l(\theta ) ∇θl(θ)就可以写成 ∇ θ l o g P ^ ( x ; θ ) \nabla _{\theta }log\hat{P}(x;\theta ) ∇θlogP^(x;θ)关于 P d a t a P_{data} Pdata和 P m o d e l P_{model} Pmodel的期望的形式:
∇ θ l ( θ ) = E P d a t a [ ∇ θ l o g P ^ ( x ; θ ) ] ⏟ p o s i t i v e p h a s e − E P m o d e l [ ∇ θ l o g P ^ ( x ; θ ) ] ⏟ n e g a t i v e p h a s e \nabla _{\theta }l(\theta )=\underset{positive\; phase}{\underbrace{{\color{Red}{E_{P_{data}}}}\left [\nabla _{\theta }log\hat{P}(x;\theta )\right ]}}-\underset{negative\; phase}{\underbrace{{\color{Red}{E_{P_{model}}}}\left [\nabla _{\theta }log\hat{P}(x;\theta )\right ]}} ∇θl(θ)=positivephase EPdata[∇θlogP^(x;θ)]−negativephase EPmodel[∇θlogP^(x;θ)]
这里分别定义等号左边和右边的部分为正相(positive phase)和负相(negative phase)。
我们期待使用梯度上升法来迭代地求解最优的 θ \theta θ:
θ ( t + 1 ) = θ ( t ) + η ∇ θ l ( θ ( t ) ) \theta ^{(t+1)}=\theta ^{(t)}+\eta \nabla _{\theta }l(\theta ^{(t)}) θ(t+1)=θ(t)+η∇θl(θ(t))
对于负相来说,我们无法对这个期望值积分,因此只能采用近似的方法,也就是在每次迭代时利用MCMC的方法(比如吉布斯采样)从 P m o d e l = P ( x ; θ ( t ) ) P_{model}=P(x;\theta ^{(t)}) Pmodel=P(x;θ(t))里采样得到样本,然后利用这些样本来近似计算负相这个积分值。这里采样得到的 M M M个样本记作 { x ^ i } i = 1 m \left \{\hat{x}_{i}\right \}_{i=1}^{m} {x^i}i=1m,这些样本叫做幻想粒子(fantacy particles):
x ^ 1 ∼ P ( x ; θ ( t ) ) ⋮ x ^ m ∼ P ( x ; θ ( t ) ) } f a n t a c y p a r t i c l e s \left.\begin{matrix} \hat{x}_{1}\sim P(x;\theta ^{(t)})\\ \vdots \\ \hat{x}_{m}\sim P(x;\theta ^{(t)}) \end{matrix}\right\}fantacy\; particles x^1∼P(x;θ(t))⋮x^m∼P(x;θ(t))⎭⎪⎬⎪⎫fantacyparticles
有了这些样本就可以计算负相,也就是说现在就可以用梯度上升的方法来迭代求解参数 θ \theta θ了,以下就是迭代求解的公式(这里也会从训练集中抽 m m m个样本):
θ ( t + 1 ) = θ ( t ) + η ( ∑ i = 1 m ∇ θ l o g P ^ ( x i ; θ ( t ) ) − ∑ i = 1 m ∇ θ l o g P ^ ( x ^ i ; θ ( t ) ) ) \theta ^{(t+1)}=\theta ^{(t)}+\eta \left (\sum_{i=1}^{m}\nabla _{\theta }log\hat{P}(x_{i};\theta ^{(t)})-\sum_{i=1}^{m}\nabla _{\theta }log\hat{P}(\hat{x}_{i};\theta ^{(t)})\right ) θ(t+1)=θ(t)+η(i=1∑m∇θlogP^(xi;θ(t))−i=1∑m∇θlogP^(x^i;θ(t)))
这个方法就叫做Gradient Ascent based on MCMC。
上面介绍的内容中引入了几个不容易理解的名词:正相、负相和幻想粒子,现在可以直观地解释一下这几个名词的含义。 ∇ θ l ( θ ( t ) ) \nabla _{\theta }l(\theta ^{(t)}) ∇θl(θ(t))中存在正相和负相,对比目标函数 l ( θ ) l(\theta ) l(θ)的表达式可以直观地理解这样命名的用意。
正相的作用是让模型分布在训练样本处概率增大,也就是从 P d a t a P_{data} Pdata中采样,然后让这些样本在 P m o d e l P_{model} Pmodel中的概率增大。负相的作用是让 Z ( θ ) Z(\theta) Z(θ)的值变小,也就是说要让从 P m o d e l P_{model} Pmodel中采样出来的幻想粒子在 P m o d e l P_{model} Pmodel中的概率减小,这些样本可以认为我们是不信任它的,称它们是fantasy的,因此要让它们的概率减小。正相和负相共同作用,最终结果就会让 P m o d e l P_{model} Pmodel逼近 P d a t a P_{data} Pdata,这个过程可以由下图表示:
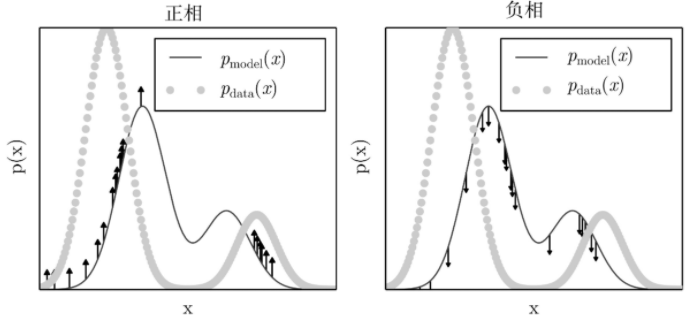
可以想象如果 P m o d e l P_{model} Pmodel已经非常逼近 P d a t a P_{data} Pdata,那么采样得到的幻想粒子和从数据集中采样的样本就会非常一致,这时对这些样本既要增大它们的概率也要压低它们的概率,此时正相和负相的作用就会抵消,也就不会再产生梯度,训练也就必须停止。
三、对比散度
对于MCMC的方法,可以参考这两个链接:
①MCMC-1|机器学习推导系列(十五)
②MCMC-2|机器学习推导系列(十六)
上面的目标函数需要从 P d a t a P_{data} Pdata和 P m o d e l P_{model} Pmodel里面都采样 m m m个样本,从 P d a t a P_{data} Pdata里面采样是很容易的,只需要从训练数据中抽取 m m m个训练数据,而从 P m o d e l P_{model} Pmodel中采样就要采用MCMC的方法,具体的操作就是使用一个初始分布初始化马尔可夫链,然后等马尔可夫链随机游走到达平稳分布时进行采样,这里可以构建一条马尔可夫链然后从中采集 m m m个样本,也可以构建 m m m条马尔可夫链然后从每条马尔可夫链中采集一个样本(只不过这样比较消耗资源)。上述MCMC方法的问题是对于高维数据分布,很可能马尔可夫链的混合时间(或者叫燃烧期)会非常地长。
下图展示了采样多条马尔可夫链的吉布斯采样方法的过程,假设燃烧期是 k k k,由于数据维度过高,很可能 k k k就会非常大,我们可以认为是无穷大$\infty $。这里也要注意,吉布斯采样的过程是对高维随机变量的每一维依次采样,因此这里的图中的每个step其实都表示高维随机变量每一维采样的过程:
◯ 0 − s t e p → ◯ 1 − s t e p → ⋯ ◯ k − s t e p ⏞ m i x i n g t i m e → ⋯ ◯ → x ^ 1 ⋮ ◯ 0 − s t e p → ◯ 1 − s t e p → ⋯ ◯ k − s t e p → ⋯ ◯ → x ^ m } G i b b s S a m p l i n g \left.\begin{matrix} \overset{mixing\; time}{\overbrace{\underset{0-step}{\bigcirc} \rightarrow \underset{1-step}{\bigcirc}\rightarrow \cdots \underset{k-step}{\bigcirc}}}\rightarrow \cdots \bigcirc\rightarrow \hat{x}_{1}\\ \vdots \\ \underset{0-step}{\bigcirc} \rightarrow \underset{1-step}{\bigcirc}\rightarrow \cdots \underset{k-step}{\bigcirc}\rightarrow \cdots \bigcirc\rightarrow \hat{x}_{m} \end{matrix}\right\}Gibbs\; Sampling 0−step◯→1−step◯→⋯k−step◯ mixingtime→⋯◯→x^1⋮0−step◯→1−step◯→⋯k−step◯→⋯◯→x^m⎭⎪⎪⎪⎪⎪⎬⎪⎪⎪⎪⎪⎫GibbsSampling
对比散度(Contrastive Divergence)的方法可以避免燃烧期过长的问题,在上面的抽样过程中需要为0-step的 x ^ i \hat{x}_{i} x^i按照一个初始化分布进行初始化,而对比散度的方法就是使用 P d a t a P_{data} Pdata这个分布来作为初始化分布,具体的做法也就是从训练数据中抽取 m m m个样本来初始化这 m m m条马尔可夫链,也就是:
x ^ 1 = x 1 , x ^ 2 = x 2 , ⋯ , x ^ m = x m \hat{x}_{1}=x_{1},\hat{x}_{2}=x_{2},\cdots ,\hat{x}_{m}=x_{m} x^1=x1,x^2=x2,⋯,x^m=xm
使用 P d a t a P_{data} Pdata初始化马尔可夫链以后只需要经过很短的几步就可以采集样本了,比如经过 k k k步就开始采样,即使 k = 1 k=1 k=1也是可以的。总之,对比散度的方法与普通的直接MCMC采样的方法的区别就在于使用了 P d a t a P_{data} Pdata初始化马尔可夫链,然后不用等漫长的混合时间,只需要 k k k步就可以采样了,无论 k k k步时有没有达到平稳分布,而 k = 1 , 2 , 3 k=1,2,3 k=1,2,3等很小的数字也是可以的。这种对比散度的方法就叫做CD Learning,之前的方法叫做ML Learning。
接下来来看看对比散度这个名字的由来。首先,先看这个式子:
θ ^ = a r g m a x θ 1 N ∑ i = 1 N l o g P ( x ; θ ) = a r g m a x θ E P d a t a [ l o g P m o d e l ] = a r g m a x θ ∫ P d a t a l o g P m o d e l d x = a r g m a x θ ∫ P d a t a l o g P m o d e l d x − a r g m a x θ ∫ P d a t a l o g P d a t a d x ⏟ 与 θ 无 关 = a r g m a x θ ∫ P d a t a l o g P m o d e l P d a t a d x = a r g m a x θ − K L ( P d a t a ∣ ∣ P m o d e l ) = a r g m i n θ K L ( P d a t a ∣ ∣ P m o d e l ) \hat{\theta }=\underset{\theta }{argmax}\frac{1}{N}\sum_{i=1}^{N}logP(x;\theta )\\ =\underset{\theta }{argmax}E_{P_{data}}\left [logP_{model}\right ]\\ =\underset{\theta }{argmax}\int P_{data}logP_{model}\mathrm{d}x\\ =\underset{\theta }{argmax}\int P_{data}logP_{model}\mathrm{d}x-\underset{与\theta 无关}{\underbrace{\underset{\theta }{argmax}\int P_{data}logP_{data}\mathrm{d}x}}\\ =\underset{\theta }{argmax}\int P_{data}log\frac{P_{model}}{P_{data}}\mathrm{d}x \\ =\underset{\theta }{argmax}-KL(P_{data}||P_{model})\\ =\underset{\theta }{argmin}KL(P_{data}||P_{model}) θ^=θargmaxN1i=1∑NlogP(x;θ)=θargmaxEPdata[logPmodel]=θargmax∫PdatalogPmodeldx=θargmax∫PdatalogPmodeldx−与θ无关 θargmax∫PdatalogPdatadx=θargmax∫PdatalogPdataPmodeldx=θargmax−KL(Pdata∣∣Pmodel)=θargminKL(Pdata∣∣Pmodel)
可以看到,原来的极大似然估计的方法其实是在最小化 P d a t a P_{data} Pdata和 P m o d e l P_{model} Pmodel的KL散度。而现在在对比散度的方法中,我们用 P d a t a P_{data} Pdata作为第 0 0 0步的初始化分布,而在经过很长的步数后才能达到平稳分布,我们现在把第 0 0 0步的分布记作 P ( 0 ) P^{(0)} P(0),最终的平稳分布记作 P ( ∞ ) P^{(\infty )} P(∞),而中间的第 k k k步的马尔可夫链的分布记作 P ( k ) P^{(k)} P(k)。由于现在 P m o d e l P_{model} Pmodel采样的样本来自 P ( k ) P^{(k)} P(k)而非 P ( ∞ ) P^{(\infty )} P(∞),所以通过这些样本进行的参数估计就不是在最小化 K L ( P ( 0 ) ∣ ∣ P ( ∞ ) ) KL(P^{(0)}||P^{(\infty )}) KL(P(0)∣∣P(∞))(也就是 K L ( P d a t a ∣ ∣ P m o d e l ) KL(P_{data}||P_{model}) KL(Pdata∣∣Pmodel))了,而是在按照下面式子中的目标函数进行参数估计:
θ ^ = a r g m i n [ K L ( P ( 0 ) ∣ ∣ P ( ∞ ) ) − K L ( P ( k ) ∣ ∣ P ( ∞ ) ) ] ⏟ C o n t r a s t i v e D i v e r g e n c e \hat{\theta }=argmin\underset{Contrastive\; Divergence}{\underbrace{\left [KL(P^{(0)}||P^{(\infty )})-KL(P^{(k)}||P^{(\infty )})\right ]}} θ^=argminContrastiveDivergence [KL(P(0)∣∣P(∞))−KL(P(k)∣∣P(∞))]
这个目标函数就是对比散度。使用CD-Learning的方法的算法如下:
t + 1 t+1 t+1时刻:
①为正相从 P d a t a P_{data} Pdata中采样, x 1 , x 2 , ⋯ , x m x_{1},x_{2},\cdots ,x_{m} x1,x2,⋯,xm是采样的数据,也就是训练数据;
②为负相从 P m o d e l = P ( x ; θ ( t ) ) P_{model}=P(x;\theta ^{(t)}) Pmodel=P(x;θ(t))中采样,使用为正相采样的数据初始化马尔可夫链:
x ^ 1 = x 1 , x ^ 2 = x 2 , ⋯ , x ^ m = x m \hat{x}_{1}=x_{1},\hat{x}_{2}=x_{2},\cdots ,\hat{x}_{m}=x_{m} x^1=x1,x^2=x2,⋯,x^m=xm
然后使用吉布斯采样从马尔可夫链中第 k k k步的分布抽取 m m m个样本, k k k可以是很小的数字,甚至是 1 1 1:
◯ 0 − s t e p → ◯ 1 − s t e p → ⋯ ◯ k − s t e p → x ^ 1 ⋮ ◯ 0 − s t e p → ◯ 1 − s t e p → ⋯ ◯ k − s t e p → x ^ m } G i b b s S a m p l i n g \left.\begin{matrix} \underset{0-step}{\bigcirc} \rightarrow \underset{1-step}{\bigcirc}\rightarrow \cdots \underset{k-step}{\bigcirc}\rightarrow \hat{x}_{1}\\ \vdots \\ \underset{0-step}{\bigcirc} \rightarrow \underset{1-step}{\bigcirc}\rightarrow \cdots \underset{k-step}{\bigcirc}\rightarrow \hat{x}_{m} \end{matrix}\right\}Gibbs\; Sampling 0−step◯→1−step◯→⋯k−step◯→x^1⋮0−step◯→1−step◯→⋯k−step◯→x^m⎭⎪⎪⎪⎬⎪⎪⎪⎫GibbsSampling
四、受限玻尔兹曼机的学习
- 表示
受限玻尔兹曼机在前一篇介绍了它的表示和推断问题,参考链接如下:受限玻尔兹曼机|机器学习推导系列(二十五)。
它的概率模型如下:
{ P ( h , v ) = 1 Z e x p { − E ( h , v ) } E ( h , v ) = − ( h T W v + α T v + β T h ) \left\{\begin{matrix} P(h,v)=\frac{1}{Z}exp\left \{-E(h,v)\right \}\\ E(h,v)=-\left (h^{T}Wv+\alpha ^{T}v+\beta ^{T}h\right ) \end{matrix}\right. {P(h,v)=Z1exp{−E(h,v)}E(h,v)=−(hTWv+αTv+βTh)
其中:
h = ( h 1 h 2 ⋯ h m ) T v = ( v 1 v 2 ⋯ v n ) T W = [ w i j ] m × n α = ( α 1 α 2 ⋯ α n ) T β = ( β 1 β 2 ⋯ β m ) T h=\begin{pmatrix} h_{1} & h_{2} & \cdots & h_{m} \end{pmatrix}^{T}\\ v=\begin{pmatrix} v_{1} & v_{2} & \cdots & v_{n} \end{pmatrix}^{T}\\ W=\left [w_{ij}\right ]_{m\times n}\\ \alpha =\begin{pmatrix} \alpha _{1} & \alpha _{2} & \cdots & \alpha _{n} \end{pmatrix}^{T}\\ \beta =\begin{pmatrix} \beta _{1} & \beta _{2} & \cdots & \beta _{m} \end{pmatrix}^{T} h=(h1h2⋯hm)Tv=(v1v2⋯vn)TW=[wij]m×nα=(α1α2⋯αn)Tβ=(β1β2⋯βm)T
- 具有隐变量的能量模型
对于具有隐变量的能量模型来说,我们有的数据是观测变量 v v v的数据,假设数据集是 S S S, S S S的规模是 N N N,即 ∣ S ∣ = N \left |S\right |=N ∣S∣=N,另外用 θ \theta θ表示参数 ( W , α , β ) (W,\alpha ,\beta ) (W,α,β),那么数据的 l o g log log似然就是:
l ( θ ) = 1 N ∑ v ∈ S l o g P ( v ) l(\theta )=\frac{1}{N}\sum _{v\in S}logP(v) l(θ)=N1v∈S∑logP(v)
对于概率 l o g P ( v ) logP(v) logP(v),来求它对 θ \theta θ的梯度,首先对这个概率做一些变换:
l o g P ( v ) = l o g ∑ h P ( h , v ) = l o g ∑ h 1 Z e x p { − E ( h , v ) } = l o g ∑ h e x p { − E ( h , v ) } − l o g Z = l o g ∑ h e x p { − E ( h , v ) } ⏟ 记 作 ① − l o g ∑ h , v e x p { − E ( h , v ) } ⏟ 记 作 ② logP(v)=log\sum _{h}P(h,v)\\ =log\sum _{h}\frac{1}{Z}exp\left \{-E(h,v)\right \}\\ =log\sum _{h}exp\left \{-E(h,v)\right \}-logZ\\ =\underset{记作①}{\underbrace{log\sum _{h}exp\left \{-E(h,v)\right \}}}-\underset{记作②}{\underbrace{log\sum _{h,v}exp\left \{-E(h,v)\right \}}} logP(v)=logh∑P(h,v)=logh∑Z1exp{−E(h,v)}=logh∑exp{−E(h,v)}−logZ=记作① logh∑exp{−E(h,v)}−记作② logh,v∑exp{−E(h,v)}
接下来看①和②这两项对参数 θ \theta θ的导数:
∂ ① ∂ θ = ∂ ∂ θ l o g ∑ h e x p { − E ( h , v ) } = − 1 ∑ h e x p { − E ( h , v ) } ∑ h e x p { − E ( h , v ) } ∂ E ( h , v ) ∂ θ = − ∑ h e x p { − E ( h , v ) } ∑ h e x p { − E ( h , v ) } ∂ E ( h , v ) ∂ θ = − ∑ h 1 Z e x p { − E ( h , v ) } 1 Z ∑ h e x p { − E ( h , v ) } ∂ E ( h , v ) ∂ θ = − ∑ h P ( h , v ) ∑ h P ( h , v ) ∂ E ( h , v ) ∂ θ = − ∑ h P ( h ∣ v ) ∂ E ( h , v ) ∂ θ ∂ ② ∂ θ = ∂ ∂ θ l o g ∑ h , v e x p { − E ( h , v ) } = − 1 ∑ h , v e x p { − E ( h , v ) } ∑ h , v e x p { − E ( h , v ) } ∂ E ( h , v ) ∂ θ = − ∑ h , v e x p { − E ( h , v ) } ∑ h , v e x p { − E ( h , v ) } ∂ E ( h , v ) ∂ θ = − ∑ h , v e x p { − E ( h , v ) } Z ∂ E ( h , v ) ∂ θ = − ∑ h , v P ( h , v ) ∂ E ( h , v ) ∂ θ \frac{\partial ①}{\partial \theta }=\frac{\partial}{\partial \theta }log\sum _{h}exp\left \{-E(h,v)\right \}\\ =-\frac{1}{\sum _{h}exp\left \{-E(h,v)\right \}}\sum _{h}exp\left \{-E(h,v)\right \}\frac{\partial E(h,v)}{\partial \theta }\\ =-\sum _{h}\frac{exp\left \{-E(h,v)\right \}}{\sum _{h}exp\left \{-E(h,v)\right \}}\frac{\partial E(h,v)}{\partial \theta }\\ =-\sum _{h}\frac{{\color{Red}{\frac{1}{Z}}}exp\left \{-E(h,v)\right \}}{{\color{Red}{\frac{1}{Z}}}\sum _{h}exp\left \{-E(h,v)\right \}}\frac{\partial E(h,v)}{\partial \theta }\\ =-\sum _{h}\frac{P(h,v)}{\sum _{h}P(h,v)}\frac{\partial E(h,v)}{\partial \theta }\\ =-\sum _{h}P(h|v)\frac{\partial E(h,v)}{\partial \theta }\\ \frac{\partial ②}{\partial \theta }=\frac{\partial}{\partial \theta }log\sum _{h,v}exp\left \{-E(h,v)\right \}\\ =-\frac{1}{\sum _{h,v}exp\left \{-E(h,v)\right \}}\sum _{h,v}exp\left \{-E(h,v)\right \}\frac{\partial E(h,v)}{\partial \theta }\\ =-\sum _{h,v}\frac{exp\left \{-E(h,v)\right \}}{\sum _{h,v}exp\left \{-E(h,v)\right \}}\frac{\partial E(h,v)}{\partial \theta }\\ =-\sum _{h,v}\frac{exp\left \{-E(h,v)\right \}}{Z}\frac{\partial E(h,v)}{\partial \theta }\\ =-\sum _{h,v}P(h,v)\frac{\partial E(h,v)}{\partial \theta } ∂θ∂①=∂θ∂logh∑exp{−E(h,v)}=−∑hexp{−E(h,v)}1h∑exp{−E(h,v)}∂θ∂E(h,v)=−h∑∑hexp{−E(h,v)}exp{−E(h,v)}∂θ∂E(h,v)=−h∑Z1∑hexp{−E(h,v)}Z1exp{−E(h,v)}∂θ∂E(h,v)=−h∑∑hP(h,v)P(h,v)∂θ∂E(h,v)=−h∑P(h∣v)∂θ∂E(h,v)∂θ∂②=∂θ∂logh,v∑exp{−E(h,v)}=−∑h,vexp{−E(h,v)}1h,v∑exp{−E(h,v)}∂θ∂E(h,v)=−h,v∑∑h,vexp{−E(h,v)}exp{−E(h,v)}∂θ∂E(h,v)=−h,v∑Zexp{−E(h,v)}∂θ∂E(h,v)=−h,v∑P(h,v)∂θ∂E(h,v)
那么最终 l o g P ( v ) logP(v) logP(v)对参数 θ \theta θ的梯度为:
∂ ∂ θ l o g P ( v ) = ∂ ① ∂ θ − ∂ ② ∂ θ = ∑ h , v P ( h , v ) ∂ E ( h , v ) ∂ θ − ∑ h P ( h ∣ v ) ∂ E ( h , v ) ∂ θ \frac{\partial}{\partial \theta }logP(v)=\frac{\partial ①}{\partial \theta }-\frac{\partial ②}{\partial \theta }\\ =\sum _{h,v}P(h,v)\frac{\partial E(h,v)}{\partial \theta }-\sum _{h}P(h|v)\frac{\partial E(h,v)}{\partial \theta } ∂θ∂logP(v)=∂θ∂①−∂θ∂②=h,v∑P(h,v)∂θ∂E(h,v)−h∑P(h∣v)∂θ∂E(h,v)
- RBM的 l o g log log似然梯度
接下来以求解 W W W为例来看RBM的参数学习方法。上面有了 l o g P ( v ) logP(v) logP(v)对参数 θ \theta θ的梯度,类似地 l o g P ( v ) logP(v) logP(v)对参数 w i j w_{ij} wij的梯度为:
∂ ∂ w i j l o g P ( v ) = ∑ h , v P ( h , v ) ∂ E ( h , v ) ∂ w i j − ∑ h P ( h ∣ v ) ∂ E ( h , v ) ∂ w i j \frac{\partial}{\partial w_{ij}}logP(v)=\sum _{h,v}P(h,v)\frac{\partial E(h,v)}{\partial w_{ij}}-\sum _{h}P(h|v)\frac{\partial E(h,v)}{\partial w_{ij}} ∂wij∂logP(v)=h,v∑P(h,v)∂wij∂E(h,v)−h∑P(h∣v)∂wij∂E(h,v)
然后观察一下能量函数 E ( h , v ) E(h,v) E(h,v):
E ( h , v ) = − ( h T W v + α T v + β T h ⏟ 与 W 无 关 , 记 作 Δ ) = − ( h T W v + Δ ) = − ( ∑ i = 1 m ∑ i = 1 n h i w i j v j + Δ ) E(h,v)=-(h^{T}Wv+\underset{与W无关,记作\Delta }{\underbrace{\alpha ^{T}v+\beta ^{T}h}})\\ =-(h^{T}Wv+\Delta )\\ =-(\sum_{i=1}^{m}\sum_{i=1}^{n}h_{i}w_{ij}v_{j}+\Delta ) E(h,v)=−(hTWv+与W无关,记作Δ αTv+βTh)=−(hTWv+Δ)=−(i=1∑mi=1∑nhiwijvj+Δ)
那么 ∂ E ( h , v ) ∂ w i j \frac{\partial E(h,v)}{\partial w_{ij}} ∂wij∂E(h,v)也就很容易写出来:
∂ E ( h , v ) ∂ w i j = − h i v j \frac{\partial E(h,v)}{\partial w_{ij}}=-h_{i}v_{j} ∂wij∂E(h,v)=−hivj
代入 ∂ ∂ w i j l o g P ( v ) \frac{\partial}{\partial w_{ij}}logP(v) ∂wij∂logP(v)就有:
∂ ∂ w i j l o g P ( v ) = ∑ h , v P ( h , v ) ( − h i v j ) − ∑ h P ( h ∣ v ) ( − h i v j ) = ∑ h P ( h ∣ v ) h i v j ⏟ 记 作 ① − ∑ h , v P ( h , v ) h i v j ⏟ 记 作 ② \frac{\partial}{\partial w_{ij}}logP(v)=\sum _{h,v}P(h,v)(-h_{i}v_{j})-\sum _{h}P(h|v)(-h_{i}v_{j})\\ =\underset{记作①}{\underbrace{\sum _{h}P(h|v)h_{i}v_{j}}}-\underset{记作②}{\underbrace{\sum _{h,v}P(h,v)h_{i}v_{j}}} ∂wij∂logP(v)=h,v∑P(h,v)(−hivj)−h∑P(h∣v)(−hivj)=记作① h∑P(h∣v)hivj−记作② h,v∑P(h,v)hivj
有一点要回忆一下,就是RBM无论隐变量还是观测变量都是二值的,取值只能是 0 0 0或 1 1 1。接下来对①和②继续进行变换,需要利用这一点:
① = ∑ h 1 ∑ h 2 ⋯ ∑ h i ⋯ ∑ h m P ( h 1 , h 2 , ⋯ , h i , ⋯ , h m ∣ v ) h i v j = ∑ h i P ( h i ∣ v ) h i v j = P ( h i = 1 ∣ v ) 1 ⋅ v j + P ( h i = 0 ∣ v ) 0 ⋅ v j = P ( h i = 1 ∣ v ) v j ② = ∑ h ∑ v P ( h , v ) h i v j = ∑ h ∑ v P ( v ) P ( h ∣ v ) h i v j = ∑ v P ( v ) ∑ h P ( h ∣ v ) h i v j ⏟ 同 ① = ∑ v P ( v ) P ( h i = 1 ∣ v ) v j ①=\sum _{h_{1}}\sum _{h_{2}}\cdots \sum _{h_{i}}\cdots \sum _{h_{m}}P(h_{1},h_{2},\cdots ,h_{i},\cdots ,h_{m}|v)h_{i}v_{j}\\ =\sum _{h_{i}}P(h_{i}|v)h_{i}v_{j}\\ =P(h_{i}=1|v)1\cdot v_{j}+P(h_{i}=0|v)0\cdot v_{j}\\ =P(h_{i}=1|v)v_{j}\\ ②=\sum_{h}\sum_{v}P(h,v)h_{i}v_{j}\\ =\sum_{h}\sum_{v}P(v)P(h|v)h_{i}v_{j}\\ =\sum_{v}P(v)\underset{同①}{\underbrace{\sum_{h}P(h|v)h_{i}v_{j}}}\\ =\sum_{v}P(v)P(h_{i}=1|v)v_{j} ①=h1∑h2∑⋯hi∑⋯hm∑P(h1,h2,⋯,hi,⋯,hm∣v)hivj=hi∑P(hi∣v)hivj=P(hi=1∣v)1⋅vj+P(hi=0∣v)0⋅vj=P(hi=1∣v)vj②=h∑v∑P(h,v)hivj=h∑v∑P(v)P(h∣v)hivj=v∑P(v)同① h∑P(h∣v)hivj=v∑P(v)P(hi=1∣v)vj
因此也就有:
∂ ∂ w i j l o g P ( v ) = P ( h i = 1 ∣ v ) v j − ∑ v P ( v ) P ( h i = 1 ∣ v ) v j \frac{\partial}{\partial w_{ij}}logP(v)=P(h_{i}=1|v)v_{j}-\sum_{v}P(v)P(h_{i}=1|v)v_{j} ∂wij∂logP(v)=P(hi=1∣v)vj−v∑P(v)P(hi=1∣v)vj
对于上面式子中的 P ( h i = 1 ∣ v ) P(h_{i}=1|v) P(hi=1∣v)这个条件概率,我们是可以直接写出来的,这个概率在上一篇的推断问题中已经推导过了,可以参照本节开头的链接。
- RBM的CD-k方法
所有样本的 l o g log log似然 l ( θ ) l(\theta) l(θ)对 w i j w_{ij} wij的梯度现在就可以表示为:
∂ l ( θ ) ∂ w i j = 1 N ∑ v ∈ S ∂ ∂ w i j l o g P ( v ) = 1 N ∑ v ∈ S ( P ( h i = 1 ∣ v ) v j − ∑ v P ( v ) P ( h i = 1 ∣ v ) v j ⏟ E P ( v ) [ P ( h i = 1 ∣ v ) v j ] ) \frac{\partial l(\theta)}{\partial w_{ij}}=\frac{1}{N}\sum _{v\in S}\frac{\partial}{\partial w_{ij}}logP(v)\\ =\frac{1}{N}\sum _{v\in S}(P(h_{i}=1|v)v_{j}-\underset{E_{P(v)}\left [P(h_{i}=1|v)v_{j}\right ]}{\underbrace{{\color{Red}{\sum_{v}P(v)P(h_{i}=1|v)v_{j}}}}}) ∂wij∂l(θ)=N1v∈S∑∂wij∂logP(v)=N1v∈S∑(P(hi=1∣v)vj−EP(v)[P(hi=1∣v)vj] v∑P(v)P(hi=1∣v)vj)
这里红色的项需要对 v v v进行积分,是untrackable的,这一项其实也就是关于 P ( v ) P(v) P(v)的期望,因此需要借助MCMC(这里指CD-k的方法,因为RBM里的随机变量也是高维的,只用MCMC也会面临燃烧期过长的问题)的方法。
使用的采样方法还是吉布斯采样,这里具体的采样过程如下图所示,首先使用训练数据来初始化 v ( 0 ) v^{(0)} v(0),然后固定 v ( 0 ) v^{(0)} v(0)来依次采样 h ( 0 ) h^{(0)} h(0)的每一维,然后固定 h ( 0 ) h^{(0)} h(0)再来依次采样 v ( 1 ) v^{(1)} v(1)的每一维,按照如此流程进行 k k k步,最终采样得到 v ( k ) v^{(k)} v(k)这一个样本,这种固定一部分来采另一部分的方法叫做块吉布斯采样(block Gibbs Sampling):
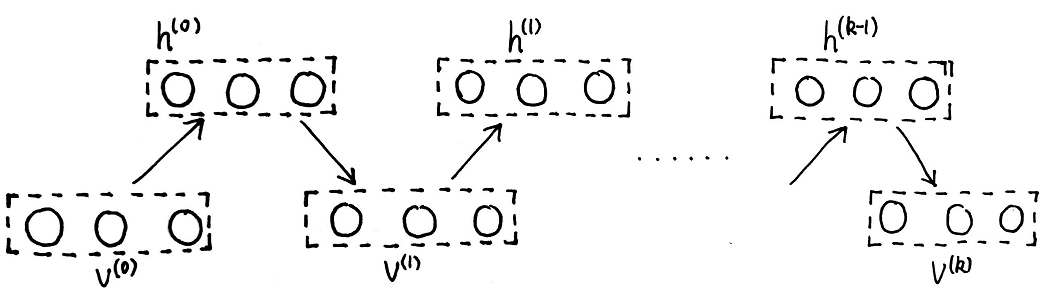
需要注意的是虽然按照吉布斯采样的方法需要依次采集每一个维度,但在RBM中由于模型的特殊性,在固定 v v v或者 h h h时,其余的随机变量都是相互独立的,因此实际操作中并行采每一维也是可以的。
另外我们一共有 N N N个训练数据,因此使用每个训练数据初始化一次都可以采集到一个 v ( k ) v^{(k)} v(k),因此最终采集到的 v ( k ) v^{(k)} v(k)一共有 N N N个。
具体的CD-k for RBM算法为:
for each v v v:
v ( 0 ) ← v v^{(0)}\leftarrow v v(0)←v
for l = 0 , 1 , 2 , ⋯ , k − 1 l=0,1,2,\cdots ,k-1 l=0,1,2,⋯,k−1:
for i = 1 , 2 , ⋯ , m i=1,2,\cdots ,m i=1,2,⋯,m:sample h i ( l ) ∼ P ( h i ∣ v ( l ) ) h_{i}^{(l)}\sim P(h_{i}|v^{(l)}) hi(l)∼P(hi∣v(l))
for j = 1 , 2 , ⋯ , n j=1,2,\cdots ,n j=1,2,⋯,n:sample v j ( l + 1 ) ∼ P ( v j ∣ h ( l ) ) v_{j}^{(l+1)}\sim P(v_{j}|h^{(l)}) vj(l+1)∼P(vj∣h(l))
for i = 1 , 2 , ⋯ , m i=1,2,\cdots ,m i=1,2,⋯,m, j = 1 , 2 , ⋯ , n j=1,2,\cdots ,n j=1,2,⋯,n:
Δ w i j ← Δ w i j + ∂ ∂ w i j l o g P ( v ) \Delta w_{ij}\leftarrow \Delta w_{ij}+\frac{\partial}{\partial w_{ij}}logP(v) Δwij←Δwij+∂wij∂logP(v)
这里的 Δ w i j \Delta w_{ij} Δwij初始化为 0 0 0,这里的 ∂ ∂ w i j l o g P ( v ) \frac{\partial}{\partial w_{ij}}logP(v) ∂wij∂logP(v)也就是:
∂ ∂ w i j l o g P ( v ) ≈ P ( h i = 1 ∣ v ( 0 ) ) v j ( 0 ) − P ( h i = 1 ∣ v ( k ) ) v j ( k ) \frac{\partial}{\partial w_{ij}}logP(v)\approx P(h_{i}=1|v^{(0)})v_{j}^{(0)}-P(h_{i}=1|v^{(k)})v_{j}^{(k)} ∂wij∂logP(v)≈P(hi=1∣v(0))vj(0)−P(hi=1∣v(k))vj(k)
也就是说用每个训练数据采样得到的样本对应的 P ( h i = 1 ∣ v ( k ) ) v j ( k ) P(h_{i}=1|v^{(k)})v_{j}^{(k)} P(hi=1∣v(k))vj(k)来代替期望 E P ( v ) [ P ( h i = 1 ∣ v ) v j ] E_{P(v)}\left [P(h_{i}=1|v)v_{j}\right ] EP(v)[P(hi=1∣v)vj],并且将所有训练数据计算得到的 ∂ ∂ w i j l o g P ( v ) \frac{\partial}{\partial w_{ij}}logP(v) ∂wij∂logP(v)累计起来得到的 Δ w i j \Delta w_{ij} Δwij作为 ∂ l ( θ ) ∂ w i j \frac{\partial l(\theta)}{\partial w_{ij}} ∂wij∂l(θ)的近似值,即:
∂ l ( θ ) ∂ w i j = 1 N ∑ v ∈ S ∂ ∂ w i j l o g P ( v ) ≈ 1 N Δ w i j \frac{\partial l(\theta)}{\partial w_{ij}}=\frac{1}{N}\sum _{v\in S}\frac{\partial}{\partial w_{ij}}logP(v)\approx \frac{1}{N}\Delta w_{ij} ∂wij∂l(θ)=N1v∈S∑∂wij∂logP(v)≈N1Δwij
最后进行梯度上升迭代求解就可以了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









