







1.常用方法
1.1selenium api查看方式
可以通过命令行启动静态服务来查看
输入命令“python -m pydoc -p6666”,然后按“Enter”键
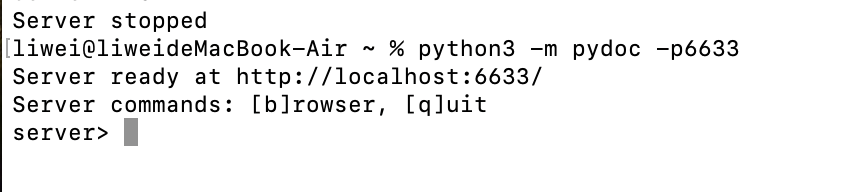
本地访问

注意▶ 命令“python -m pydoc -p6666”中的“-p”后面的数字是指定服务启动的端口号,你可以换成PC端任意未占用的端口。
1.2selenium 常用方法
打开关闭浏览器
-
关键字
- 打开Chrome浏览器:webdriver.Chrome()。
- 打开Firefox浏览器:webdriver.Firefox()。
- 关闭当前浏览器窗口:driver.close()。
- 退出浏览器进程:driver.quit()。
# 要使用WebDriver提供的API,首先要导入包
from selenium import webdriver
from time import sleep
# 定义一个变量,用来存储实例化后的浏览器,这里打开Chrome浏览器
driver1 = webdriver.Chrome()
sleep(2) # 这里等待2秒,看效果
driver1.close() # 关闭当前浏览器窗口
# 定义一个变量driver2,用来打开Firefox浏览器
driver2 = webdriver.Firefox()
sleep(2)
driver2.quit() # 退出浏览器进程
访问某个网址
- 关键字
- 打开Chrome浏览器:webdriver.Chrome()。●打开Firefox浏览器:webdriver.Firefox()。●关闭当前浏览器窗口:driver.close()。●退出浏览器进程:driver.quit()。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
# 通过get方法访问网址,这里访问人民邮电出版社官网
driver.get('https://www.ptpress.com.cn/')
sleep(2)
driver.quit()
网页的前进后退
- 关键字
- 网页后退:back方法。
- 网页前进:forward方法。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/') # 打开百度首页
sleep(2)
driver.get('https://www.ptpress.com.cn/') # 打开人民邮电出版社官网首页
sleep(2)
driver.back() # 通过back方法后退到百度首页
sleep(2)
driver.forward() # 通过forward方法前进到人民邮电出版社官网首页
sleep(2)
driver.quit()
刷新浏览器页面
- 关键字
- 刷新页面:refresh方法。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.ptpress.com.cn/') # 打开人民邮电出版社官网首页
sleep(2)
driver.refresh() # 通过refresh方法刷新页面
sleep(2)
driver.quit()
浏览器窗口最大化、最小化和全屏
- 关键字
- 浏览器窗口最大化:driver.maximize_window方法。
- 浏览器窗口最小化:driver.minimize_window方法。
- 浏览器窗口全屏:driver.fullscreen_window方法。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
sleep(2)
driver.maximize_window() #最大化
sleep(2)
driver.minimize_window() #最小化
sleep(2)
driver.fullscreen_window()
sleep(2)
driver.quit()
获取、设置浏览器大小
- 关键字
- 获取当前浏览器窗口的大小:driver.get_window_size方法。
- 设置浏览器窗口的大小:set_window_size(500,800)。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
winsize = driver.get_window_size() # 获取当前窗口的大小
print(winsize)
print(type(winsize)) # 输出winsize变量的类型
sleep(2)
driver.set_window_size(500,800) # 设置窗口的大小
sleep(2)
driver.quit()
{‘width’: 1050, ‘height’: 660}
<class ‘dict’>
获取、设置浏览器窗口的位置
- 关键字
- 获取窗口的位置:driver.get_window_position方法。
- 设置窗口的位置:set_window_position(500,300)。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
pos = driver.get_window_position() # 获取窗口的位置
print(pos)
sleep(2)
driver.set_window_position(500,300) # 设置窗口的位置
sleep(2)
print(driver.get_window_position()) # 再次输出窗口的位置
driver.quit()
{‘x’: 10, ‘y’: 10}
{‘x’: 500, ‘y’: 300}
获取页面title
- 关键字
- 获取页面的title:driver.title。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
title = driver.title # 输出当前网页的title,即“百度一下,你就知道”
print(title)
driver.quit()
获取当前浏览器页面的url
- 关键字
- 获取浏览器页面url:driver.current_url
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
url = driver.current_url # 获取当前页面的URL地址
print(url)
driver.quit()
获取页面源码
- 关键字
- 获取当前页面源码:driver.page_source
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
pagesource = driver.page_source # 获取页面的源码
print(pagesource)
driver.quit()
多窗口操作 - selenium3
当我们单击Web页面上的超链接时,有可能会打开一个新窗口或新标签,并且这个新窗口或标签会处于当前页面(可操作)。不过这对Selenium
WebDriver来说是个难题,因为它并不知道哪个窗口处于当前状态(active,可操作)。因此,要想在新打开的窗口或标签中进行操作,首先要切换到新窗口或标签。每个窗口都有一个唯一标识,我们称之为“句柄”,该标识在单个会话中保持不变(浏览器不关闭就不会发生改变)。Selenium允许使用句柄来操作窗口或标签。
- 关键字
- 获取当前窗口句柄:driver.current_window_handle。
- 获取所有窗口句柄:driver.window_handles。
- 切换当前窗口:driver.switch_to.window(all_handles[1])。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('http://sahitest.com/demo/index.htm')
print(driver.current_window_handle) # 查看当前窗口句柄
driver.find_element_by_link_text('Window Open Test').click() # 打开新window1
print(driver.window_handles) # 查看所有窗口句柄
sleep(2)
driver.close()
print(driver.window_handles)# 查看现在的所有窗口句柄,可以看到第一个窗口关闭,第二个窗口还在
sleep(2)
driver.quit() # 可以看到所有窗口都被关闭
多窗口操作 - selenium4
Selenium 4提供了一个新方法用于在打开一个新窗口或标签时,将其自动切换为当前状态。
# 打开一个新标签,并切换到新标签
driver.switch_to.new_window('tab')
# 打开一个新窗口,并切换到新窗口
driver.switch_to.new_window('window')
新方法虽然简单,但是如果你已经打开了多个窗口,然后又打开新窗口,此种情况下还是需要使用循环的方式去切换窗口,然后才能进行相应的操作。
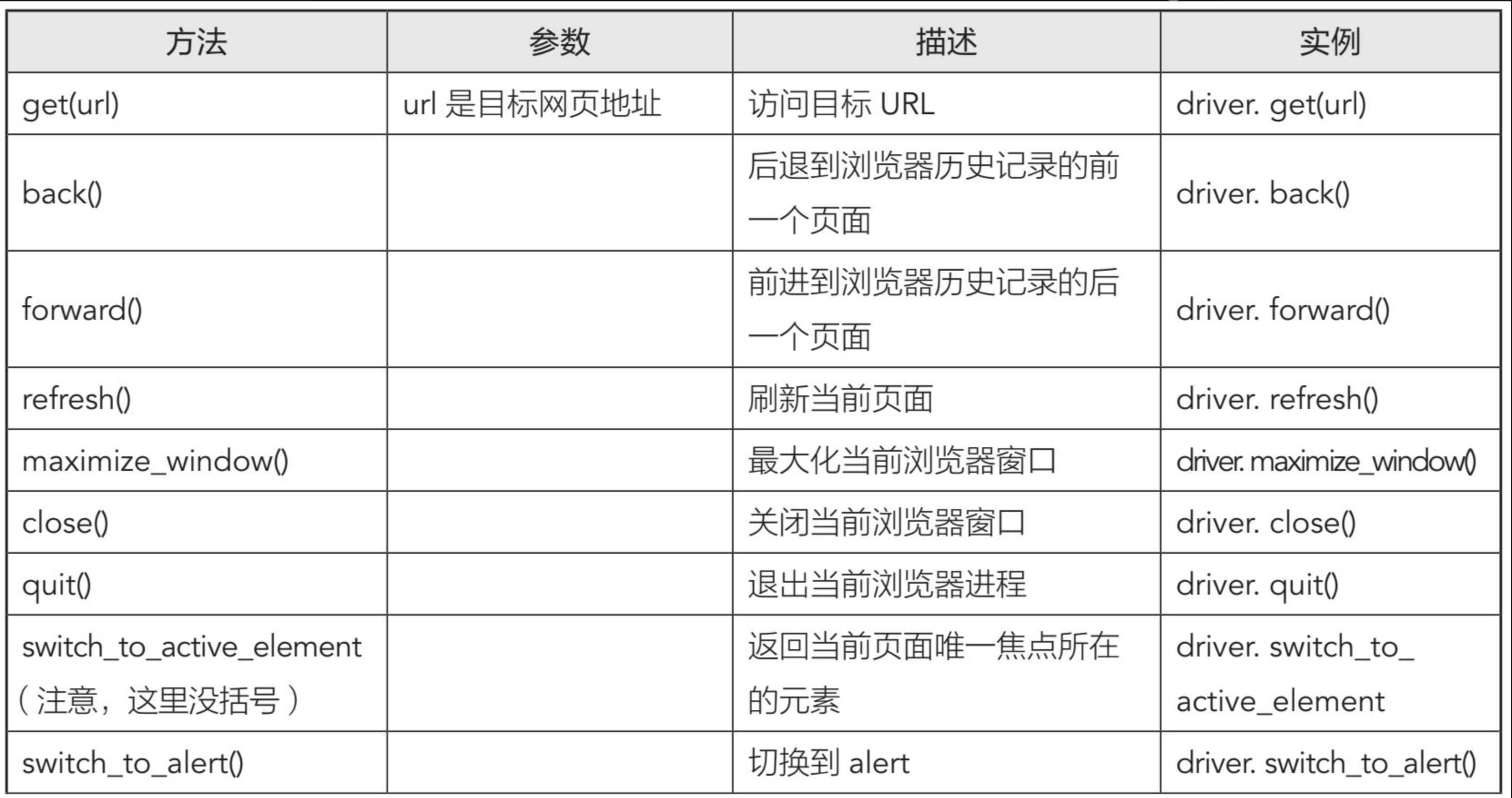
浏览器方法属性汇总
- 方法:
| 方法 | 参数 | 描述 | 实例 |
|---|---|---|---|
| get(url) | |||
| back() | |||
| forward() |
不想手画图表了 直接贴图吧
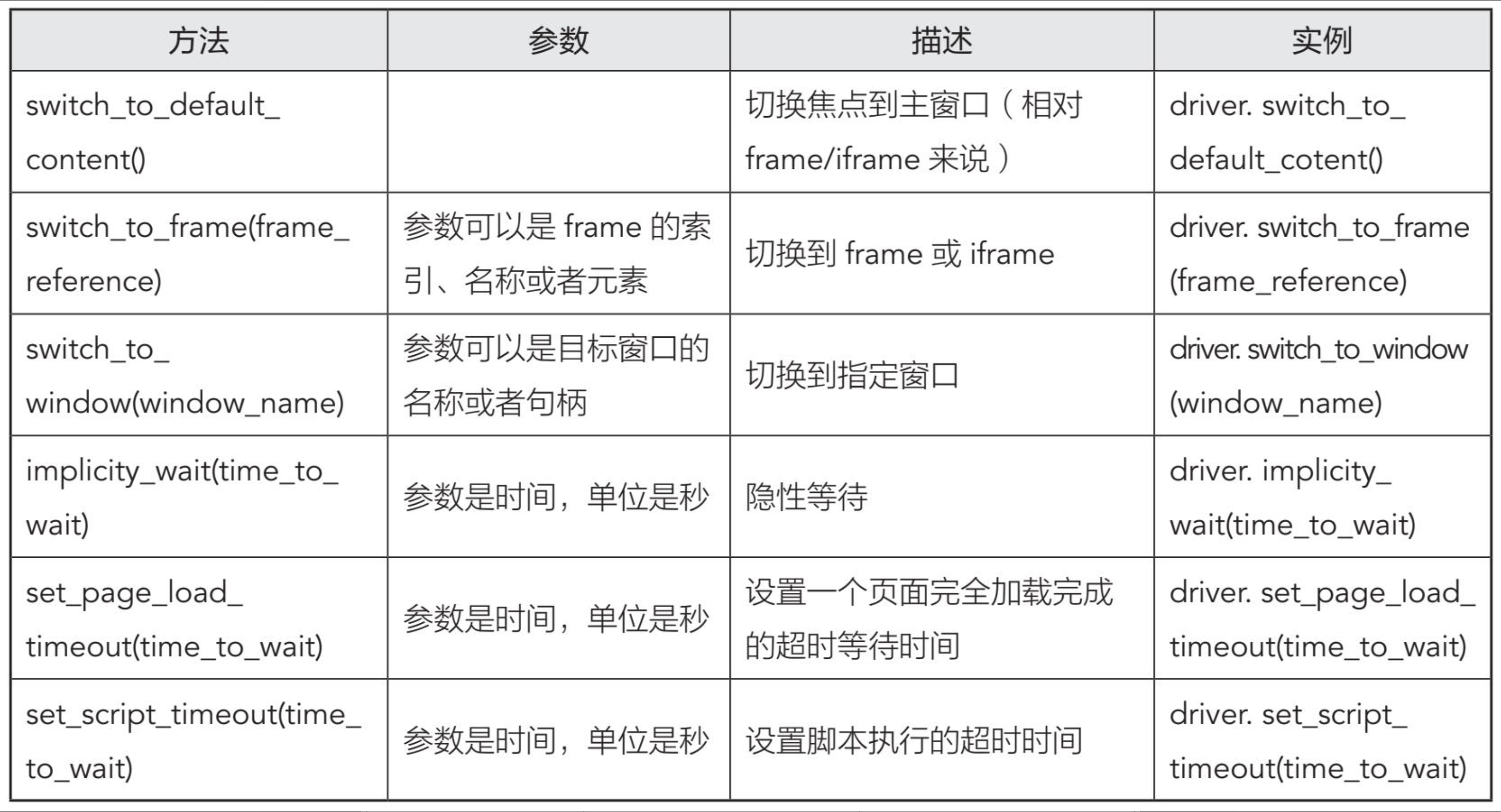
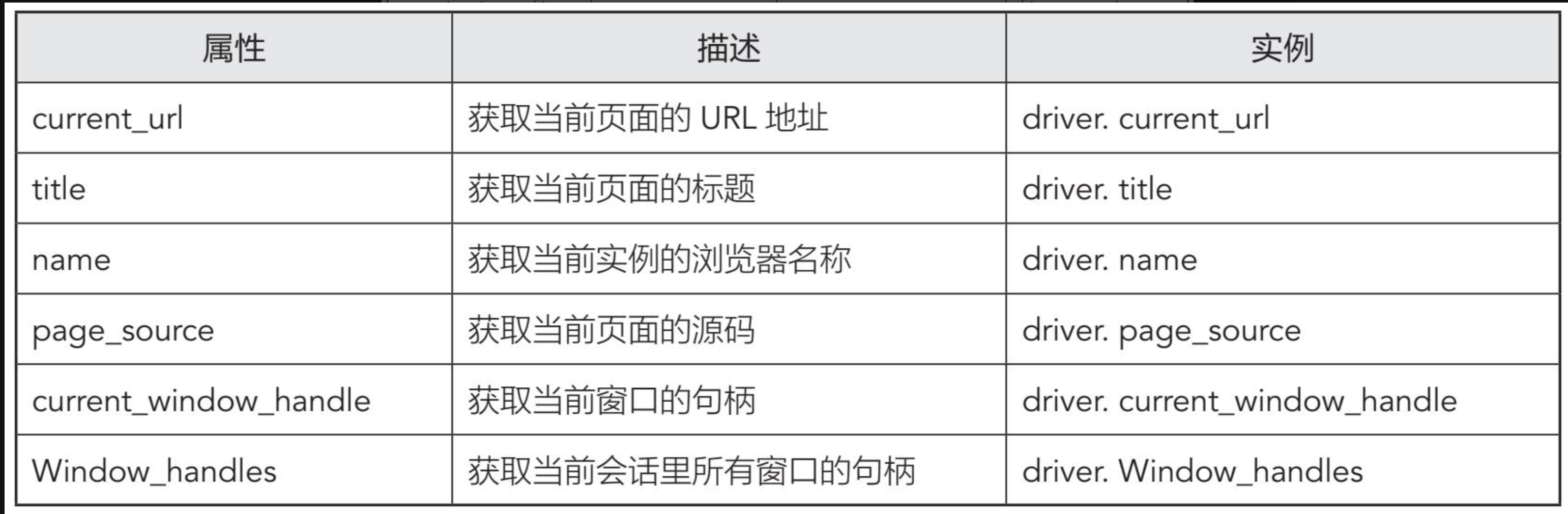
- 属性
2.元素定位
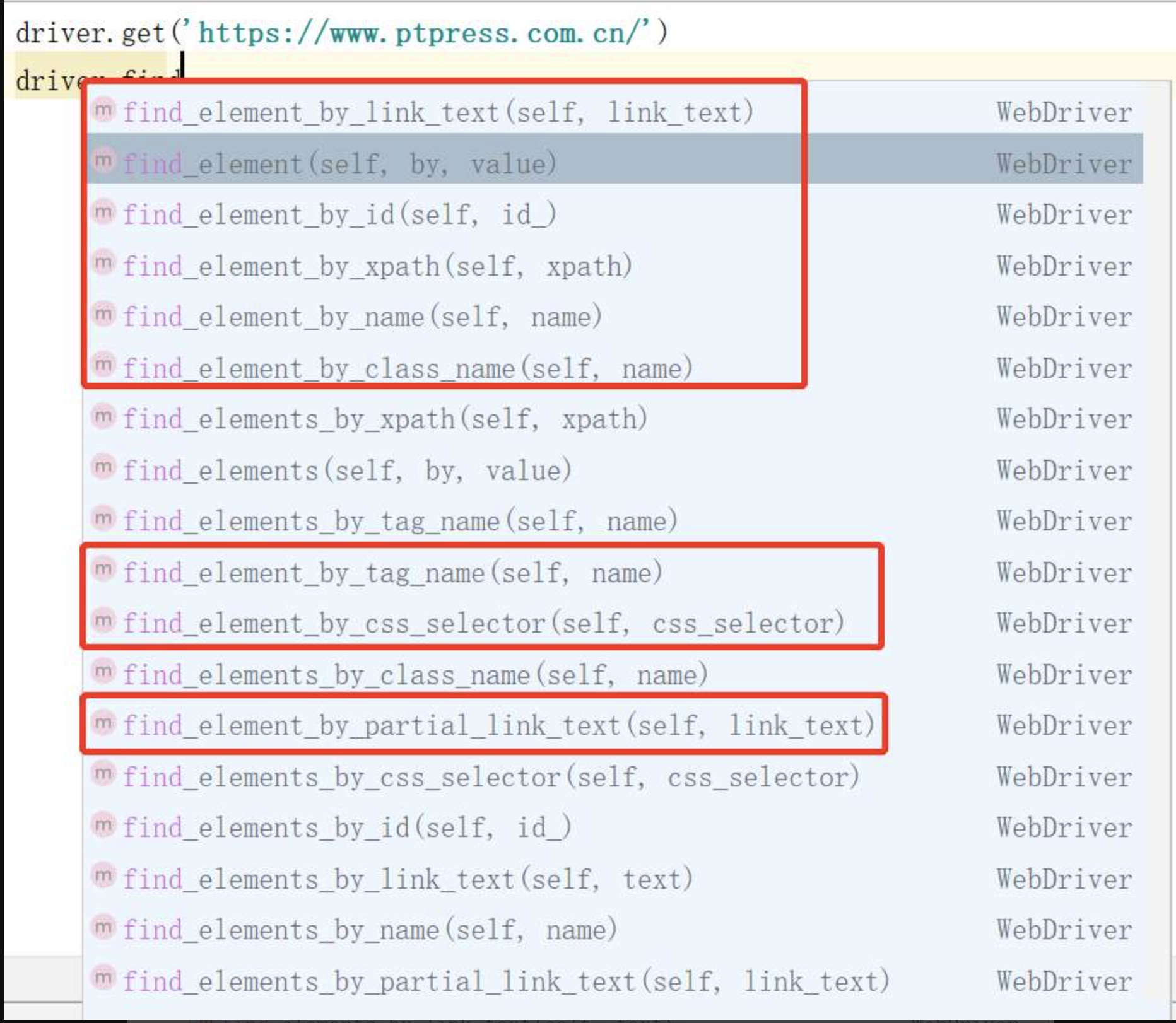
方法概览
WebDriver一共提供了18种元素定位的方法。element是单数形式,elements复数形式。前者用来定位到单个元素,返回值的类型是WebElement;后者用来定位一组元素,返回值的类型是列表。
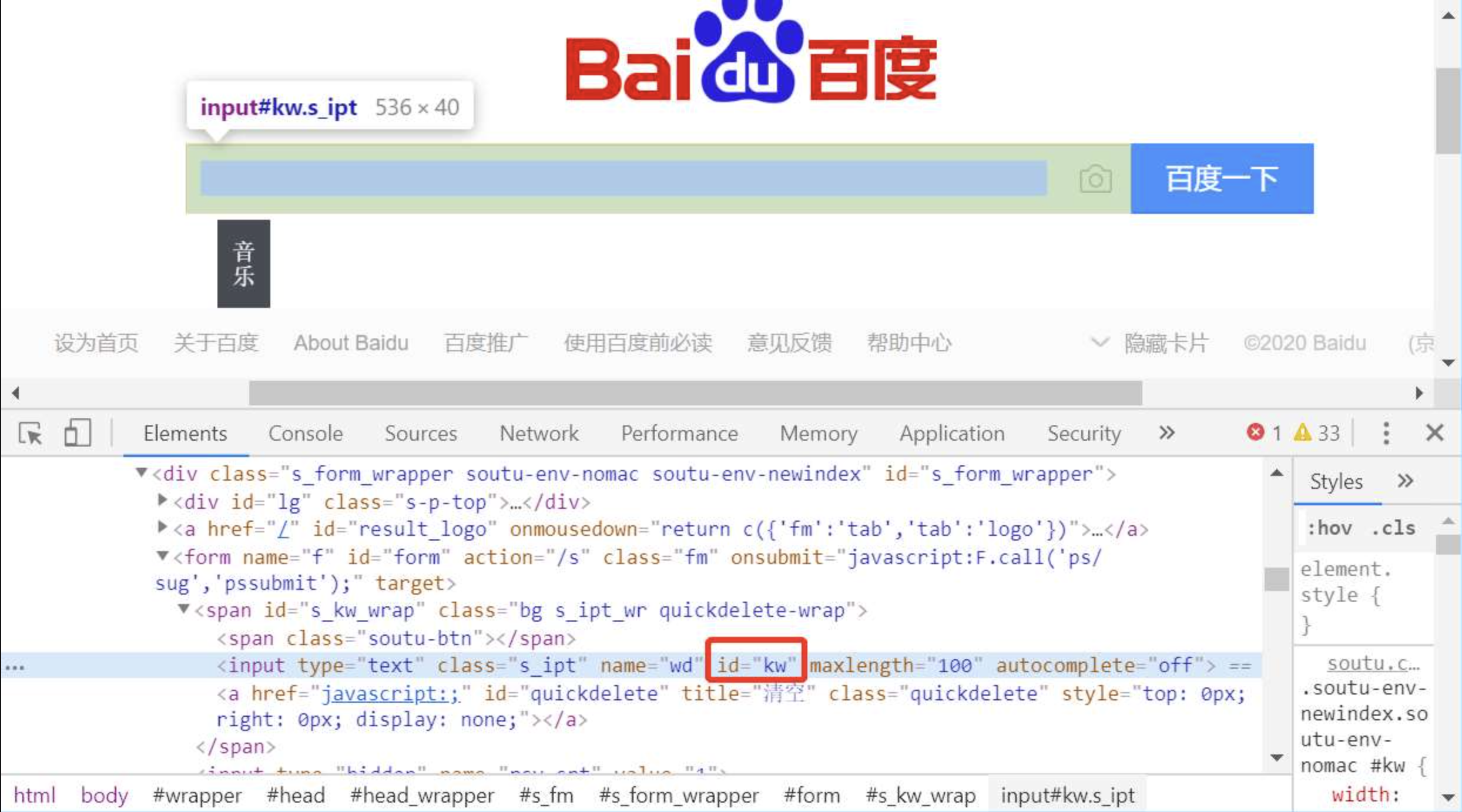
id 定位
简述:使用id定位百度的搜索框,输入“storm”。使用开发者工具查看元素id属性,如图所示。
# 导入WebDriver包
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
# 定位百度搜索框
myinput = driver.find_element_by_name('wd')
# 对其进行操作,输入"storm"
myinput.send_keys("storm")
# 等待2秒,可以发现搜索框中出现输入内容
sleep(2)
# 退出浏览器进程
driver.quit()
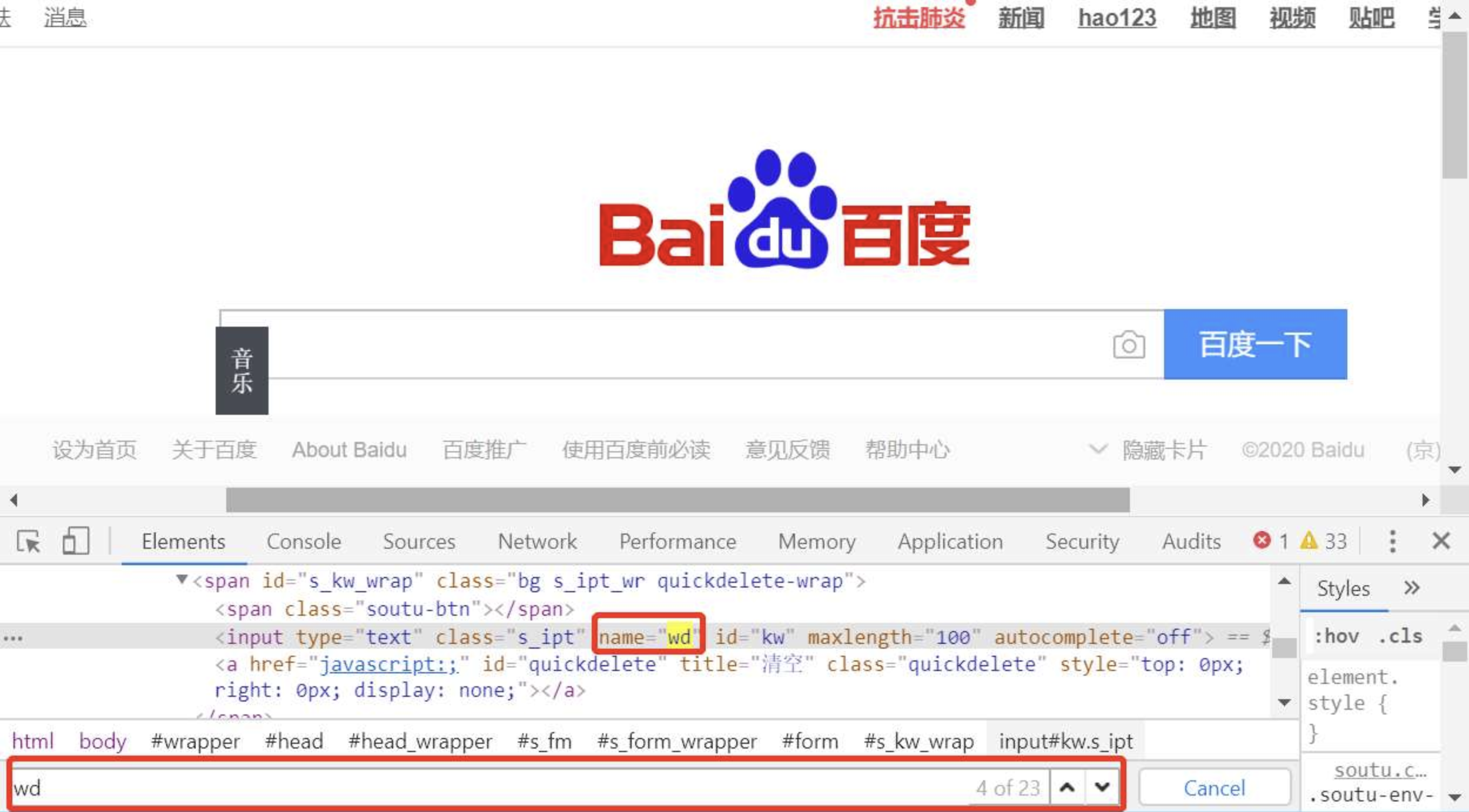
使用name定位元素
简述:使用name定位百度搜索框,输入“storm”。使用开发者工具查看元素name属性,如图所示
# 导入WebDriver包
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
# 定位百度搜索框
myinput = driver.find_element_by_name('wd')
# 对其进行操作,输入"storm"
myinput.send_keys("storm")
# 等待2秒,可以发现搜索框中出现输入内容
sleep(2)
# 退出浏览器进程
driver.quit()
使用class name定位元素
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>使用class or tag name定位元素</title>
</head>
Please input your name:
<input class="myclass"></input>
</body>
</html>
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('d:\\Love\\Chapter-4\\4-2\\test4_2-4.html') # 绝对路径加HTML文件
ele = driver.find_element_by_class_name('myclass') # 通过class name定位元素
ele.send_keys('storm')
sleep(2)
driver.quit()
使用tag name定位元素
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>使用class or tag name定位元素</title>
</head>
Please input your name:
<input class="myclass" name="myname" id="myid"></input>
</body>
</html>
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('d:\\Love\\Chapter-5\\test5_1.html') # 绝对路径加HTML文件
ele = driver.find_element_by_tag_name('input') # 通过tag name定位元素
ele.send_keys('storm')
sleep(2)
driver.quit()
使用链接的全部文字定位元素
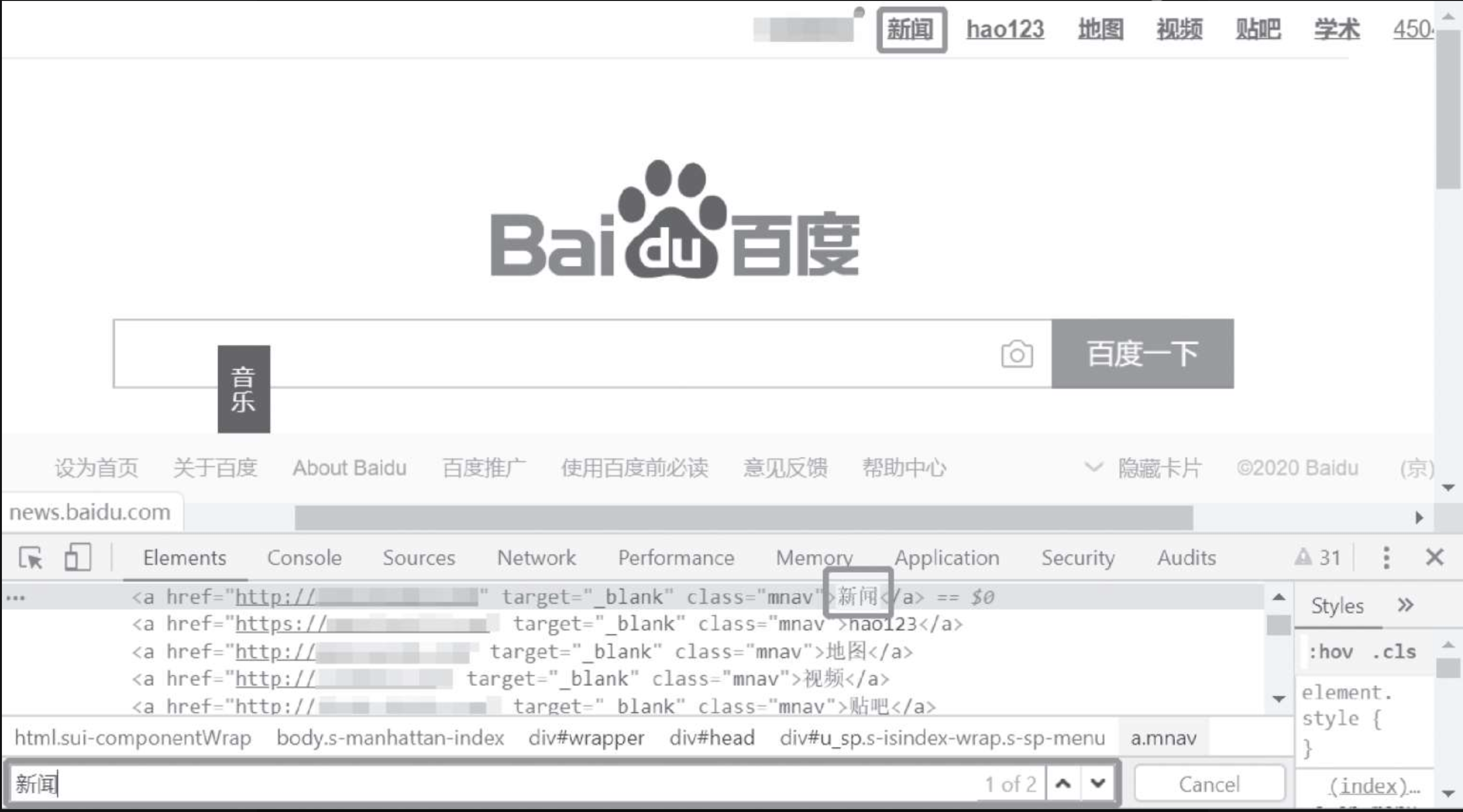
使用部分链接文字定位元素
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get(“http://www.baidu.com”)
# 单击百度首页右上角的“新闻”链接
ele = driver.find_element_by_partial_link_text(“闻”)
ele.click() # 单击该链接
sleep(2)
# 退出浏览器进程
driver.quit()
使用xpath定位
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
ele = driver.find_element_by_xpath('//*[@id="kw"]') # 使用XPath定位搜索框
ele.send_keys('storm')
sleep(2)
# 退出浏览器进程
driver.quit()
详见:
xpath定位文章链接
使用CSS定位元素
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
ele = driver.find_element_by_css_selector('#kw') # 使用CSS来定位元素
ele.send_keys('storm')
sleep(2)
driver.quit()
详见:
css定位元素文章
元素定位的方法汇总
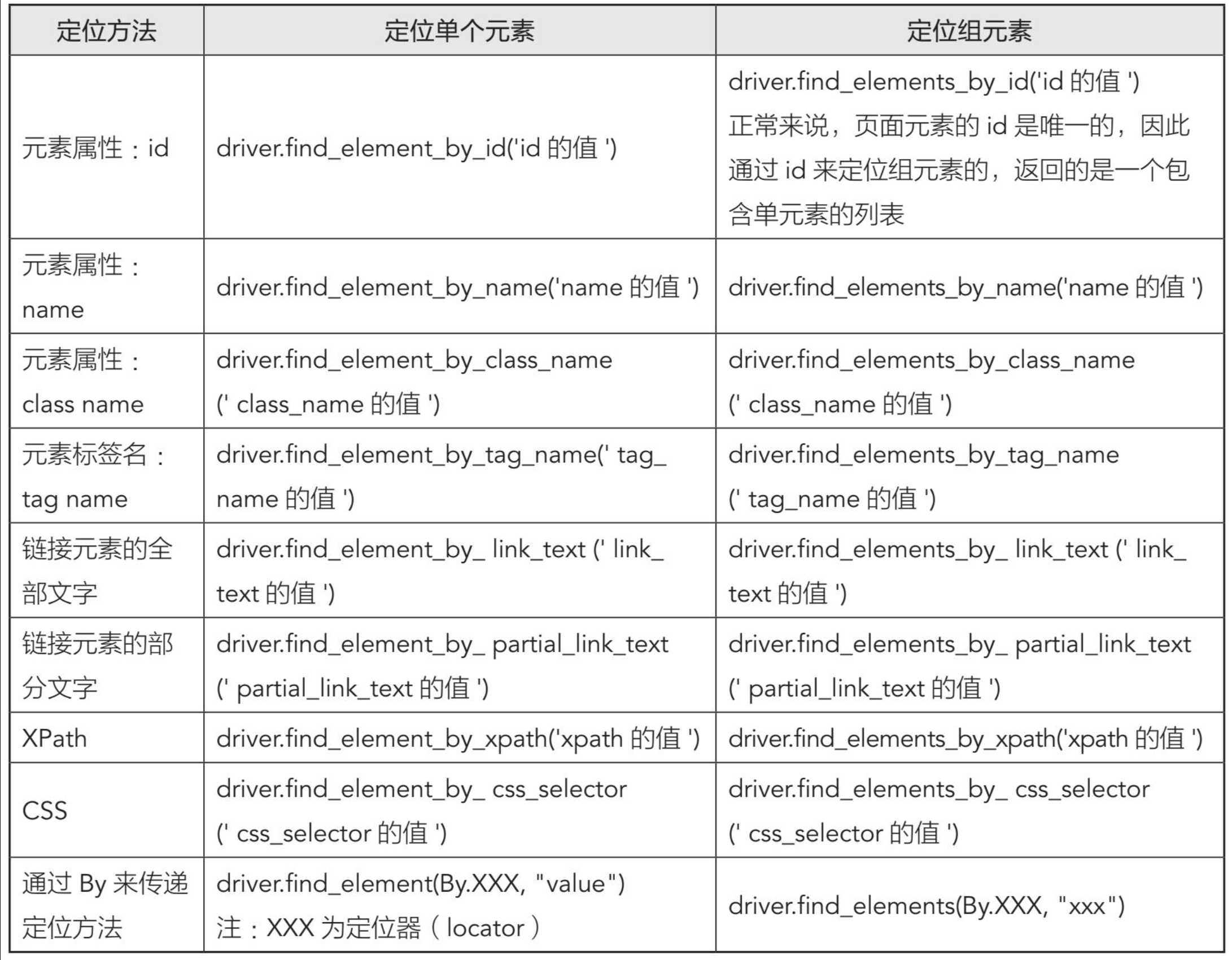
selenium4的相对定位方式
3.获取元素信息
详见:
获取元素信息文章
4.鼠标操作
详见:
鼠标操作文章
5.键盘操作
详见:
键盘操作文章
6.常见控件实际应用
7.selenium高级应用
8.selenium等待机制
详见:
selenium等待机制
今天先写到这 ,后边再补充
















 957
957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











