







1. Redis 安装
1.1 Redhat7 redis 安装
1.1.1 安装 redis
wget http://download.redis.io/releases/redis-6.0.8.tar.gz
tar xzf redis-6.0.8.tar.gz
cd redis-6.0.8
make
1.1.2 命令
# 解压之后的安装目录
cd src
# 可以指定配置文件启动 也可以不指定默认启动
./redis-server [redis.conf]
# 启动 redis 客户端
./redis-cli
redis-cli -h 127.0.0.1 -p 6379 -a myPassword
# 创建软连接
ln -s /usr/local/software/redis-5.0.2/src/redis-server /usr/bin/redis-server
ln -s /usr/local/software/redis-5.0.2/src/redis-cli /usr/bin/redis-cli
# 设置后端启动
先将 redis.conf 中 daemonize 设置为yes,确保守护进程开启。
./redis-cli 配置文件
# 修改密码
redis.conf 中 # requirepass foobared 去掉注释
# 去掉后可以客户端访问
redis.conf 中 将bind 127.0.0.1改为#bind 127.0.0.1(即注释掉)
# 查看redis 进行
ps -ef|grep redis
# 停止
# 强制停止
kill -9 pid
# 正确停止
redis-cli shutdown
/etc/init.d/redis-server stop
关闭RDB
默认rdb是自动开启的,aof是关闭的。
# 关闭rdb的命令
config set save ""
# 或者进入配置文件将
Save 900 1
Save 300 10
Save 60 10000
# 注释掉,并打开save "" 的注释,使得 save "" 生效,即可关闭rdb;
1.2 docker redis 安装
docker run --name redis -p 6379:6379 redis-test --requirepass 123456
1.3 Window 安装
redis-cli -h[ip] -p [账号] -a [密码]
1.4 客户端
2. Redis 介绍

2.1 Redis 简介
Redis [ Remote Dictionnary Serivce ],远程字典服务。Redis是一个开源的使用 ANSI C语言编写,支持网络,可基于内存也可持久化的日志型,Key-Value NoSql 数据库,并提供了多种语言的 API , 相比 Memcached 它支持存储的类型相对更多 (字符,哈希,集合,有序集合,列表等),同时Redis是线程安全的。
优点:
-
Redis 是一种基于键值对(key-value)的 NoSQL 数据库。
-
支持存储多种类型,支持string(字符串)、hash(哈希)、 list(列表)、set(集合)、zset(有序集合)、Bitmaps(位图)、 HyperLogLog、GEO(地理信息定位)等多种数据结构,因此 Redis可以满足很多的应用场景。特定的数据结构使得CRUD更快。
-
纯内存操作,Redis会将所有数据都存放在内存中,所以它的读写性能非常出色。
-
持久化,Redis可以将内存的数据利用快照和日志的形式保存到硬盘上,这样在发生类似断电或者机器故障的时候,内存中的数据不会 “丢失”。
-
单线程操作(网络接口), 避免了线程频繁的上下文切换,避免加锁解锁。(瓶颈在内存和带宽上)
-
采用了非阻塞 I/O 多路复用机制.
-
Redis还提供了键过期、发布订阅、事务、流水线、Lua 脚本等附加功能。
缺点:
- 缓存和数据库双写一致性问题
- 缓存雪崩问题
- 缓存击穿问题
- 缓存的并发竞争问题
2.2 Spring Boot Redis 使用
2.2.1 客户端介绍
连接池
客户端连接 Redis 使用的是 TCP协议,直连的方式每次需要建立 TCP连接,而连接池的方式是可以预先初始化好客户端连接,所以每次只需要从 连接池借用即可,而借用和归还操作是在本地进行的,只有少量的并发同步开销,远远小于新建TCP连接的开销。另外,直连的方式无法限制 redis客户端对象的个数,在极端情况下可能会造成连接泄漏,而连接池的形式可以有效的保护和控制资源的使用。
| 名称 | 优点 | 缺点 |
|---|---|---|
| 直连 | 简单方便,适用于少量长期连接的场景 | 1. 存在每次新建/关闭TCP连接开销 2. 资源无法控制,极端情况下出现连接泄漏 3. Jedis对象线程不安全(Lettuce对象是线程安全的) |
| 连接池 | 1. 无需每次连接生成Jedis对象,降低开销 2. 使用连接池的形式保护和控制资源的使用 | 相对于直连,使用更加麻烦,尤其在资源的管理上需要很多参数来保证,一旦规划不合理也会出现问题 |
java 连接客户端
| 名称 | 原理 | 其它 |
|---|---|---|
| Jedis | 直连 | 1. 线程不安全(多个线程之间共用一个jedis实例) 2. 和redis指令一一对应, redis操作比较全面。 3. 同步阻塞, 不支持异步 |
| Lettuce | 基于Netty事件驱动通讯 | 1. 线程安全 2. 异步和响应使用,支持集群,Sentinel,管道和编码器 |
| Redisson | 基于Netty事件驱动通讯 | 1. 线程安全,分布式锁 2. 异步 3. 实现了分布式和可扩展的Java数据结构, 多用于分布式微服务 4. 不支持字符串操作,不支持排序、事务、管道、分区等Redis特性 |
-
jedis时springboot 1.5使用的, 若要线程安全需要为每个jedis实例增加物理连接, 不然多线程下不安全。在Springboot2以后,底层访问redis已经不再是jedis了,而是lettuce。
-
总体来说jedis淘汰了, lettuce还行, redisson 支持很多高级特性(高大上)
2.2.2 配置信息
2.2.2.1 Lettuce 客户端的配置使用
依赖
<!-- spring-boot-data-redis 对 redis 客户端又进行了一系列的封装,抽象出了一层接口。在使用的时候可以灵活的切换 redis 客户端的实现。 -->
<!-- redis依赖 springboot 2.0 中已经默认使用的是 lettuce-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- redis 连接池 若配置连接池需要使用该依赖 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
配置
spring:
# redis 配置
redis:
host: 127.0.0.1
port: 6379
database: 0
# 没有就不要出现这个属性 否则报错
password: xxxx
lettuce:
pool:
# 连接池最大连接数(使用负值表示没有限制) 默认为8
max-active: 8
# 连接池最大阻塞等待时间(使用负值表示没有限制) 默认为-1
max-wait: -1ms
# 连接池中的最大空闲连接 默认为8
max-idle: 8
# 连接池中的最小空闲连接 默认为 0
min-idle: 0
2.2.2.2 Redisson 客户端的配置使用
依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- redisson 依赖 -->
<!-- redisson-spring-boot-starter 实现了 spring-boot-data-redis。所以跟平时没有区别。直接使用 springboot提供的,RedisTemplate 即可。 -->
<!-- 也可以从IOC中获取到 RedissonClient,直接使用Redisson 提供的各种强大功能。 -->
<!-- https://mvnrepository.com/artifact/org.redisson/redisson-spring-boot-starter -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.14.0</version>
</dependency>
配置
spring:
# redis 配置
redis:
host: 127.0.0.1
port: 6379
database: 0
# 没有就不要出现这个属性 否则报错
password: xxxx
lettuce:
pool:
# 连接池最大连接数(使用负值表示没有限制) 默认为8
max-active: 8
# 连接池最大阻塞等待时间(使用负值表示没有限制) 默认为-1
max-wait: -1ms
# 连接池中的最大空闲连接 默认为8
max-idle: 8
# 连接池中的最小空闲连接 默认为 0
min-idle: 0
redisson.yml
# 单节点配置
singleServerConfig:
# 连接空闲超时,单位:毫秒
idleConnectionTimeout: 10000
# 连接超时,单位:毫秒
connectTimeout: 10000
# 命令等待超时,单位:毫秒
timeout: 3000
# 命令失败重试次数,如果尝试达到 retryAttempts(命令失败重试次数) 仍然不能将命令发送至某个指定的节点时,将抛出错误。
# 如果尝试在此限制之内发送成功,则开始启用 timeout(命令等待超时) 计时。
retryAttempts: 3
# 命令重试发送时间间隔,单位:毫秒
retryInterval: 1500
# # 重新连接时间间隔,单位:毫秒
# reconnectionTimeout: 3000
# # 执行失败最大次数
# failedAttempts: 3
# 密码
password:
# 单个连接最大订阅数量
subscriptionsPerConnection: 5
# 客户端名称
clientName: null
# # 节点地址
address: redis://ip
# 发布和订阅连接的最小空闲连接数
subscriptionConnectionMinimumIdleSize: 1
# 发布和订阅连接池大小
subscriptionConnectionPoolSize: 50
# 最小空闲连接数
connectionMinimumIdleSize: 32
# 连接池大小
connectionPoolSize: 64
# 数据库编号
database: 0
# DNS监测时间间隔,单位:毫秒
dnsMonitoringInterval: 5000
# 线程池数量,默认值: 当前处理核数量 * 2
threads: 0
# Netty线程池数量,默认值: 当前处理核数量 * 2
nettyThreads: 0
# 编码
codec: !<org.redisson.codec.JsonJacksonCodec> {}
# 传输模式
transportMode : "NIO"
clusterServersConfig:
# 连接空闲超时,单位:毫秒 默认10000
idleConnectionTimeout: 10000
pingTimeout: 1000
# 同任何节点建立连接时的等待超时。时间单位是毫秒 默认10000
connectTimeout: 10000
# 等待节点回复命令的时间。该时间从命令发送成功时开始计时。默认3000
timeout: 3000
# 命令失败重试次数
retryAttempts: 3
# 命令重试发送时间间隔,单位:毫秒
retryInterval: 1500
# 重新连接时间间隔,单位:毫秒
reconnectionTimeout: 3000
# 执行失败最大次数
failedAttempts: 3
# 密码
password: test1234
# 单个连接最大订阅数量
subscriptionsPerConnection: 5
clientName: null
# loadBalancer 负载均衡算法类的选择
loadBalancer: !<org.redisson.connection.balancer.RoundRobinLoadBalancer> {}
#从节点发布和订阅连接的最小空闲连接数
slaveSubscriptionConnectionMinimumIdleSize: 1
#从节点发布和订阅连接池大小 默认值50
slaveSubscriptionConnectionPoolSize: 50
# 从节点最小空闲连接数 默认值32
slaveConnectionMinimumIdleSize: 32
# 从节点连接池大小 默认64
slaveConnectionPoolSize: 64
# 主节点最小空闲连接数 默认32
masterConnectionMinimumIdleSize: 32
# 主节点连接池大小 默认64
masterConnectionPoolSize: 64
# 订阅操作的负载均衡模式
subscriptionMode: SLAVE
# 只在从服务器读取
readMode: SLAVE
# 集群地址
nodeAddresses:
- "redis://192.168.184.128:30001"
- "redis://192.168.184.128:30002"
- "redis://192.168.184.128:30003"
- "redis://192.168.184.128:30004"
- "redis://192.168.184.128:30005"
- "redis://192.168.184.128:30006"
# 对Redis集群节点状态扫描的时间间隔。单位是毫秒。默认1000
scanInterval: 1000
#这个线程池数量被所有RTopic对象监听器,RRemoteService调用者和RExecutorService任务共同共享。默认2
threads: 0
#这个线程池数量是在一个Redisson实例内,被其创建的所有分布式数据类型和服务,以及底层客户端所一同共享的线程池里保存的线程数量。默认2
nettyThreads: 0
# 编码方式 默认org.redisson.codec.JsonJacksonCodec
codec: !<org.redisson.codec.JsonJacksonCodec> {}
#传输模式
transportMode: NIO
# 分布式锁自动过期时间,防止死锁,默认30000
lockWatchdogTimeout: 30000
# 通过该参数来修改是否按订阅发布消息的接收顺序出来消息,如果选否将对消息实行并行处理,该参数只适用于订阅发布消息的情况, 默认true
keepPubSubOrder: true
# 用来指定高性能引擎的行为。由于该变量值的选用与使用场景息息相关(NORMAL除外)我们建议对每个参数值都进行尝试。
#
#该参数仅限于Redisson PRO版本。
#performanceMode: HIGHER_THROUGHPUT
Bean的配置
@Configuration
public class RedissonConfig {
@Bean
public RedissonClient redisson(Environment env) throws IOException {
// 配置文件的方式配置
// Config config = Config.fromYAML(new ClassPathResource("redisson.yml").getInputStream());
Config config = new Config();
String redisAddress = "redis://" + env.getProperty("spring.redis.host") + ":" + env.getProperty("spring.redis.port");
config.useSingleServer()
.setAddress(redisAddress)
.setPassword(env.getProperty("spring.redis.password"))
.setDatabase(0)
.setTimeout(3000)
.setIdleConnectionTimeout(10000)
.setConnectTimeout(10000)
.setRetryAttempts(3)
.setRetryInterval(1500)
.setSubscriptionsPerConnection(5);
return Redisson.create(config);
}
@Bean
public RedissonConnectionFactory redissonConnectionFactory(RedissonClient redisson) {
return new RedissonConnectionFactory(redisson);
}
}
2.3 和关系型数据库的比较
关系型数据库遵循ACID规则(原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)),而Nosql数据库遵循BASE原则(基本可用(Basically Availble)、软/柔性事务(Soft-state )、最终一致性(Eventual Consistency))。
| 区别 | NoSql | 关系型数据库 |
|---|---|---|
| 存储方式 | key, value 存储,动态结构,容易适应数据类型和结构的变化 | 遵循范式,基本数据类型,预先定义结构(数据建模),稳定,可靠,不易变化 |
| 存储 | 内存存储,查询速度快 | 存储在磁盘上,天然持久化 |
2.4 Redis 的快
Redis的速度⾮常的快,单机的Redis就可以⽀撑每秒十几万的并发,相对于MySQL来说,性能是MySQL的⼏⼗倍。速度快的原因主要有⼏点:
- 完全基于内存操作
- 使⽤单线程,避免了线程切换和竞态产生的消耗。确切的说redis单线程指的是redis的网络IO和键值对读写是由一个线程完成的。但是其它功能如持久化,异步删除,集群数据同步等都是额外的线程来完成的(耗时命令如 keys 要谨慎操作)。
- 基于⾮阻塞的IO多路复⽤机制。
- C语⾔实现,优化过的数据结构,基于⼏种基础的数据结构,redis做了⼤量的优化,性能极⾼
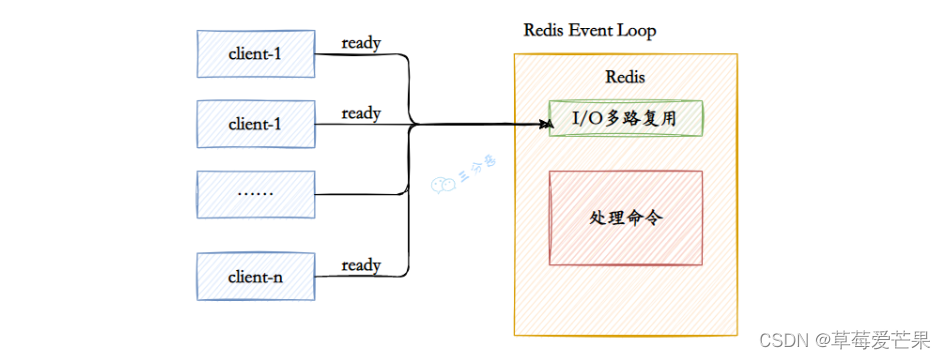
2.5 redis 压测
redis-benchmark # 压测命令
redis-benchmark -h
3. Redis 数据结构
redis 9种数据结构由5种最基本的数据结构(String、List、Hash、Set、Sorted Set(zset)) 加 bitmap、geohash、hyperloglog、streams 组成。
Redis 所有的数据结构都是以唯一的 key 字符串作为名称,然后通过这个唯一 key 值来获取相应的 value 数据。不同类型的数据结构的差异就在于 value 的结构不一样。
3.0 通用命令
| 命令 | 描述 |
|---|---|
| help @string,help @sorted_set | |
| keys [pattern] | 全量扫描 |
| scan | 渐进式扫描,返回的值 就是下一次遍历的游标,直到返回0,遍历过程中增加,删除会有影响 |
| exists [key] | 查询该key是否存在,存在则返回1 |
| del [key] | 删除key |
| flushall | redis 缓存全清 |
| select index | 选择新的数据库 |
3.1 String (字符串)
3.1.1 简介
简单动态字符串(Simple Dynamic Strings, SDS)是最基础的数据结构。字符串类型的值实际可以是字符串(简单的字符串、复杂的字符串(例如JSON、XML))、数字 (整数、浮点数),甚至是二进制(图片、音频、视频),但是值最大不能超过512MB。
3.1.2 使用命令
| 命令 | 描述 | 案例 |
|---|---|---|
| SET key value [EX seconds|PX milliseconds] [NX|XX] [KEEPTTL] | 将key指定为设置的字符串,如果key有值将会被覆盖,并且忽略原来的类型,并且当命令成功后设置的过期时间都将失效。 EX seconds – 设置键key的过期时间,单位时秒 PX milliseconds – 设置键key的过期时间,单位时毫秒 NX – 只有键key不存在的时候才会设置key的值 XX – 只有键key存在的时候才会设置key的值 | 可用于分布式锁 |
| get | ||
| mset | 批量设置 | |
| mget | ||
| setnx | 分布式锁 | |
| incr | 累加操作,自增是有范围的,它的范围是signed long 的最大最小值,超过了这个值会报错 | |
| incrby | 批量生成序列号 |
3.1.3 使用场景
- 缓存功能,(key value缓存,对象缓存序列化)
- 计数
- 共享Session
- 限速
- 分布式锁,setnx
3.1.4 底层结构
3.1.4.1 底层结构
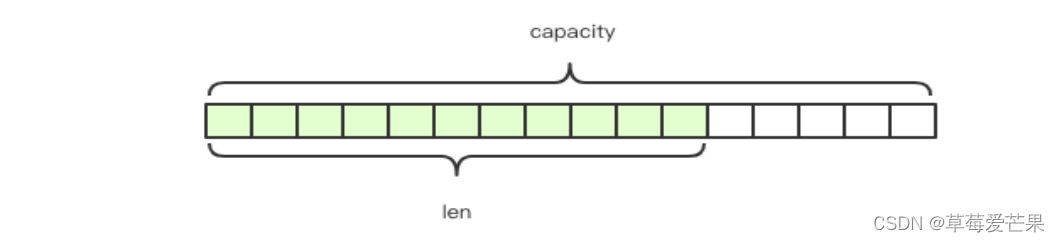
String 类型的 value 值是一个动态字符串,它的内部结构类似于ArrayList,当字符串长度达到阈值时会自动扩容。如下它的实际容量为capacity,当前存储value的长度是len。默认value值最大是512M,当值字符串大小小于1M时,扩容是加倍现有的空间,若大于1M则每次扩容都是增加1M。
3.1.4.2 编码
String 3种内部编码:int、embstr、raw
- **int 编码:**当一个key的value是整型时,Redis就将其编码为int类型(另外还有一个条件:把这个value当作字符串来看,它的长度不能超过20,保存的是可以用 long 类型表示的整数值)。这种编码类型为了节省内存。Redis默认会缓存10000个整型值(#define OBJ_SHARED_INTEGERS 10000),这就意味着,如果有10个不同的KEY,其value都是10000以内的值,事实上全部都是共享同一个对象。
- **embstr 编码:**保存长度小于44字节的字符串(redis3.2版本之前是39字节,之后是44字节)。
- **raw 编码:**保存长度大于44字节的字符串(redis3.2版本之前是39字节,之后是44字节)。
int 编码是用来保存整数值,raw 编码是用来保存长字符串,而embstr是用来保存短字符串。其实 embstr 编码是专门用来保存短字符串的一种优化编码。
raw 和 embstr 的区别如下图:
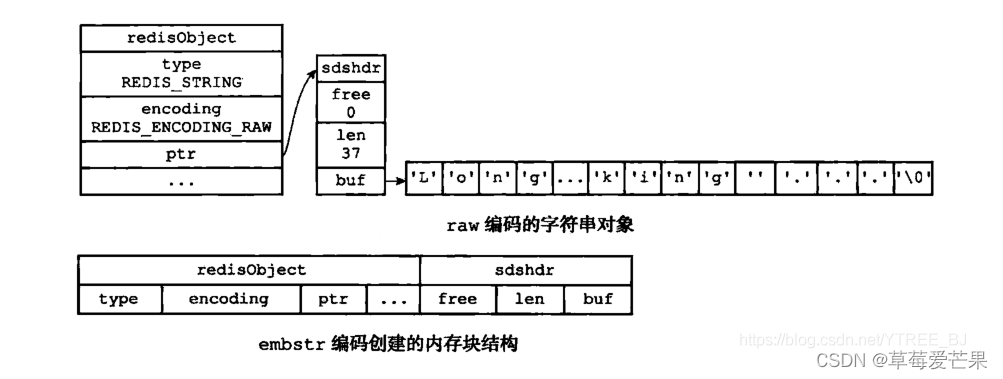
embstr 与raw 都使用 redisObject 和 sds 保存数据,区别在于,embstr 的使用只分配一次内存空间(因此redisObject和sds是连续的),而 raw 需要分配两次内存空间(分别为 redisObject 和 sds 分配空间)。因此与 raw 相比,embstr 的好处在于创建时少分配一次空间,删除时少释放一次空间,以及对象的所有数据连在一起,寻找方便。而 embstr 的坏处也很明显,如果字符串的长度增加需要重新分配内存时,整个 redisObject 和 sds 都需要重新分配空间,因此 redis 中的embstr 实现为只读。
**PS:**Redis 中对于浮点数类型也是作为字符串保存的,在需要的时候再将其转换成浮点数类型。
编码的转换:
当 int 编码保存的值不再是整数,或大小超过了long的范围时,自动转化为raw。
对于 embstr 编码,由于 Redis 没有对其编写任何的修改程序(embstr 是只读的),在对embstr对象进行修改时,都会先转化为raw再进行修改,因此,只要是修改embstr对象,修改后的对象一定是raw的,无论是否达到了44个字节。
3.2 C 语言底层
3.2.1 底层数据结构
// 内容紧凑 根据偏移量即可得到 len free buf
// 内存存放在柔性buf中(只能放在结构体末尾,通过malloc函数动态分配内存),对上层暴露的也是buf的指针,而不是sds的指针,所以兼容C字符串处理函数
// 由于len的存在,不依赖 \0 终止符 保证了二进制安全
// sdshdr8、sdshdr16、sdshdr32和sdshdr64
struct sds {
int len; // buf 中已占用字节数
int free; // buf 中剩余可用字节数
char buf[]; // 数据空间
};
struct __attribute__ ((__packed__))sdshdr5 {
unsigned char flags; /* 低3位存储类型, 高5位存储长度 */
char buf[]; /* 柔性数组,存放实际内容 */
};
struct __attribute__((__packed__))sdshdr8 {
uint8_t len; /* 已使用长度,用1字节存储 */
uint8_t alloc; /* 总长度,用1字节存储*/
unsigned char flags; /* 低3位存储类型, 高5位预留 */
char buf[]; /* 柔性数组,存放实际内容*/
};
struct __attribute__((__packed__))sdshdr16 {
uint16_t len; /* 已使用长度,用2字节存储*/
uint16_t alloc; /* 总长度,用2字节存储*/
unsigned char flags; /* 低3位存储类型, 高5位预留 */
char buf[]; /* 柔性数组,存放实际内容*/
};
struct __attribute__((__packed__))sdshdr32 {
uint32_t len; /* 已使用长度,用4字节存储*/
uint32_t alloc; /* 总长度,用4字节存储*/
unsigned char flags; /* 低3位存储类型, 高5位预留 */
char buf[]; /* 柔性数组,存放实际内容*/
};
struct __attribute__((__packed__))sdshdr64 {
uint64_t len; /* 已使用长度,用8字节存储*/
uint64_t alloc; /* 总长度,用8字节存储*/
unsigned char flags; /* 低3位存储类型, 高5位预留 */
char buf[]; /* 柔性数组,存放实际内容*/
};
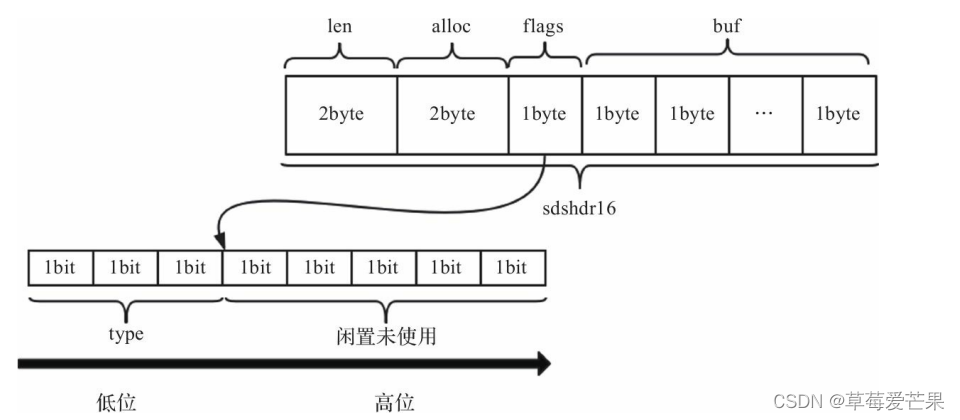
sdshdr16 的结构,即len,free 的字节数根据字符串长度来决定,8就是1byte, 16就是2byte, 32 就是4byte等
3.2.2 创建字符串
创建空字符串时会强制转换为sdshdr8。原因可能是创建空字符串后,其内容可能会频繁更新而引发扩容,故创建时直接创建为 sdshdr8。
- 创建空字符串时,SDS_TYPE_5被强制转换为 SDS_TYPE_8。
- 长度计算时有“+1”操作,是为了算上结束符“\0”。
- 返回值是指向sds结构buf字段的指针。
sds sdsnewlen(const void *init, size_t initlen) {
void *sh;
sds s;
char type = sdsReqType(initlen); // 根据字符串长度选择不同的类型
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8; // SDS_TYPE_5强制转化为SDS_TYPE_8
int hdrlen = sdsHdrSize(type); // 计算不同头部所需的长度
unsigned char *fp; / * 指向flags的指针 */
sh = s_malloc(hdrlen+initlen+1); // "+1"是为了结束符'\0'
...
s = (char*)sh+hdrlen; // s是指向buf的指针
fp = ((unsigned char*)s)-1; // s是柔性数组buf的指针,-1即指向flags
...
s[initlen] = '\0'; // 添加末尾的结束符
return s;
}
3.2.3 释放字符串
// 通过对s的偏移,可定位到SDS结构体的首部,然后调用s_free释放内存:
void sdsfree(sds s) {
if (s == NULL) return;
s_free((char*)s-sdsHdrSize(s[-1])); // 此处直接释放内存
}
// 通过重置统计值达到清空目的的方法——sdsclear。该方法仅将SDS的len归零,此处已存在的buf并没有真正被清除,新的数据可以覆盖写,而不用重新申请内存。
void sdsclear(sds s) {
sdssetlen(s, 0); // 统计值len归零
s[0] = '\0'; // 清空buf
}
3.2.4 字符串扩容
/* 将指针t的内容和指针s的内容拼接在一起,该操作是二进制安全的*/
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s);
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL;
memcpy(s+curlen, t, len); //直接拼接,保证了二进制安全
sdssetlen(s, curlen+len);
s[curlen+len] = '\0'; //加上结束符
return s;
}
1)若sds中剩余空闲长度avail大于新增内容的长度addlen,直接在柔性数组buf末尾追加即可,无须扩容。
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK; // s[-1]即flags
int hdrlen;
if (avail >= addlen) return s; // 无须扩容,直接返回
...
}
- 若sds中剩余空闲长度avail小于或等于新增内容的长度addlen,则分情况讨论:新增后总长度len+addlen<1MB的,按新长度的2倍扩容;新增后总长度len+addlen>1MB的,按新长度加上1MB扩容。
sds sdsMakeRoomFor(sds s, size_t addlen) {
...
newlen = (len+addlen);
if (newlen < SDS_MAX_PREALLOC)// SDS_MAX_PREALLOC这个宏的值是1MB
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
...
}
- 根据新长度重新选取存储类型,并分配空间。此处若无须更改类型,通过realloc扩大柔性数组即可;否则需要重新开辟内存,并将原字符串的buf内容移动到新位置。
sds sdsMakeRoomFor(sds s, size_t addlen) {
...
type = sdsReqType(newlen);
/* type5的结构不支持扩容,所以这里需要强制转成type8 */
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
if (oldtype==type) {
/* 无须更改类型,通过realloc扩大柔性数组即可,注意这里指向buf的指针s被更新了 */
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
/* 扩容后数据类型和头部长度发生了变化,此时不再进行realloc操作,而是直接重新开辟内存,拼接完内容后,释放旧指针 */
newsh = s_malloc(hdrlen+newlen+1); // 按新长度重新开辟内存
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1); // 将原buf内容移动到新位置
s_free(sh); // 释放旧指针
s = (char*)newsh+hdrlen; // 偏移sds结构的起始地址,得到字符串起始地址
s[-1] = type; // 为falgs赋值
sdssetlen(s, len); // 为len属性赋值
}
sdssetalloc(s, newlen); // 为alloc属性赋值
return s;
}
3.2 list
3.2.1 简介
列表(list)类型是用来存储多个有序的字符串。列表是一种比较灵活的数据结构,它可以充当栈和队列的角色
3.2.2 使用命令
| 命令 | 描述 | 举例 |
|---|---|---|
| lpush | 左边进 | |
| rpush | 右边进 | |
| lpop | 左边出 | |
| rpop | 右边出 | |
| lrange | ||
| lindex | 根据下标获取,O(n),index 可以为负数,-1表示倒数第一个元素 | |
| ltrim key start_index end_index | 区间内的值保留,区间外的删除 | ltrim key 1 0 删除了整个列表 |
| blpop/brpop | 阻塞获取,若数据为空则阻塞,当有数据时自动唤醒。 | |
3.2.3 使用场景
- 消息队列(微博消息,微信公众号消息),不能保证可靠性
- 文章列表
3.2.4 底层结构
3.2.4.1 底层结构
Redis 列表相当于 Java 语言中的 LinkedList ,所以它的增删非常快,但是遍历是 O(n),当列表弹出最后一个元素之后,数据结构会被自动删除,内存被回收。
Redis 使用双向列表, List 中可以包含的最大元素数量是 4294967295(42亿)
3.3 hash
3.3.1 简介
哈希类型是指键值本身又是一个键值对结构。
3.3.2 使用命令
| 命令 | 描述 | 举例 |
|---|---|---|
| hmset | 批量添加 hash 数据 | |
| hmget | 批量获取 hash 数据 | |
| hset | 添加一个 hash 数据 | |
| hget | 获取一个 hash 数据 | |
| hincrby | hash 计数 类似于 字符串类型的 incr 命令 | hincrby user-laoqian age 1 |
| hlen | hash 存储的数据的长度 | |
| hdel | 删除一个 hash key 数据 | |
| hgetall | 获取全部的 hash 指定 key 里面的数据 | |
3.3.3 使用场景
- 缓存用户信息
- 缓存对象
- 电商购物车
- 记录帖子的点赞数,评论数,点击数
3.3.4 底层结构
3.3.4.1 底层结构
Redis 字典类似于 Java 中的 HashMap,它是无序的字典,它的内部结构也是类似的,不同的是 Redis 字典值只能是字符串,另外它的rehash也不一样,HashMap 是一次性全部 rehash,redis 采用的是渐进式的 rehash 策略。渐进式的 rehash 会保留新旧两个 hash 结构,查询时会同时查询两个,在后续的定时任务中渐进的将旧的 hash 内容迁移到新的 hash 中。当 hash 的最后一个元素移除时,该结构会被删除,且内存会被回收。
3.3.4.2 C 底层
Daniel J.Bernstein在comp.lang.c上发布的 “times 33” 散列函数,其使用的核心算法是:“hash(i)=hash(i-1)*33+str[i]”,这是针对字符串已知的最好的散列函数之一,因为其计算速度快,而且输出值分布得很好。
字典结构
typedef struct dictht {
dictEntry **table; /* 指针数组,用于存储键值对 该数组中的元素指向的是 dictEntry 的结构体 每个dictEntry 里面存有键值对 */
unsigned long size; /* table 数组的大小 */
unsigned long sizemask; /* 掩码 = size - 1 */
unsigned long used; /* table 数组已存元素个数,包含next单链表的数据 */
} dictht;
sizemask:人为设定Hash表的数组容量初始值为4,随着键值对存储量的增加,就需对Hash表扩容,新扩容的容量大小设定为当前容量大小的一倍,也就是说,Hash表的容量大小只能为4,8,16,32…。而sizemask掩码的值就只能为3,7,15,31…,对应的二进制为11,111,1111,11111…,因此掩码值的二进制肯定是每一位都为1。
typedef struct dictEntry {
void *key; /* 存储键 */
union {
void *val; /* db.dict 中的 val */
uint64_t u64;
int64_t s64; /* db.expires 中存储过期时间 */
double d;
} v; /* 值,是个联合体 */
struct dictEntry *next; /* 当Hash冲突时,指向冲突的元素,形成单链表 */
} dictEntry;
v字段是个联合体,存储的是键值对中的值,在不同场景下使用不同字段。例如,用字典存储整个Redis数据库所有的键值对时,用的是*val字段,可以指向不同类型的值;再比如,字典被用作记录键的过期时间时,用的是s64字段存储;当出现了Hash冲突时,next字段用来指向冲突的元素,通过头插法,形成单链表.
-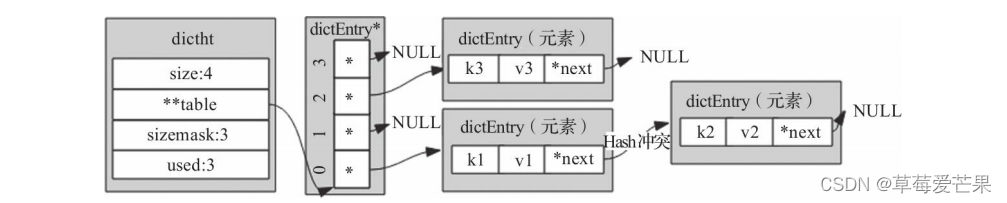
完整的字典结构示意图
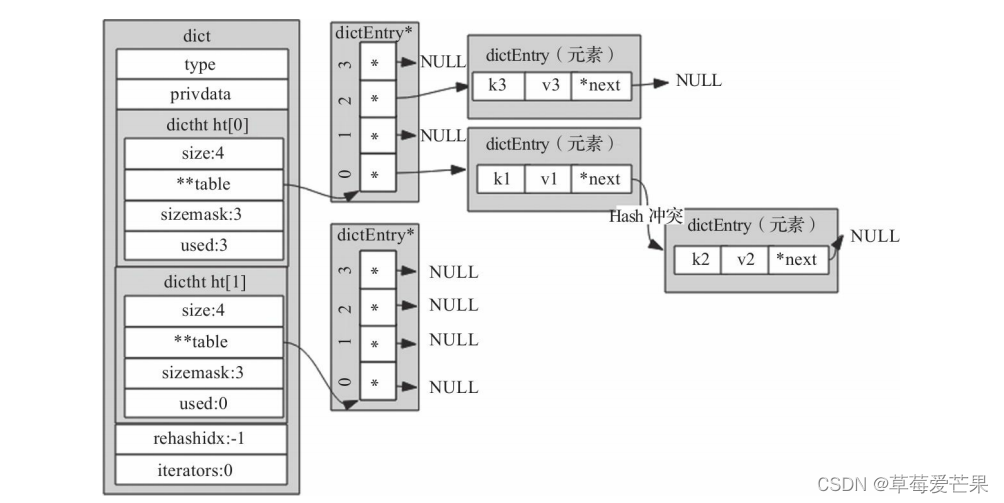
3.4 set
3.4.1 简介
集合(set)类型也是用来保存多个的字符串元素,但和列表类型不一 样的是,集合中不允许有重复元素,并且集合中的元素是无序的。
3.5.2 使用命令
| 命令 | 描述 | 举例 |
|---|---|---|
| sadd key value… | 添加元素,可以添加多个 | |
| smembers key | 获取集合中的元素,无序的 | |
| sismember key value | 查询某个元素是否存在 | |
| scard key | 获取集合的长度 | |
| spop key | 弹出一个 |
3.4.3 使用场景
- 标签(tag)
- 共同关注
- 抽奖(参与抽奖)
- 点赞,收藏
- 关注模型(集合操作)
3.4.4 底层结构
3.4.4.1 底层结构
Redis set 类型相当于 Java 的 HashSet ,它内部的键值是无序唯一的。它的内部实现相当于一个特殊的字典,字典中所有的 value 值都一个 Null。当集合中最后一个元素移除,数据结构自动被删除,内存被回收。
3.5 zset
3.5.1 简介
有序集合中的元素可以排序。但是它和列表使用索引下标作为排序依据不同的是,它给每个元素设置一个权重(score)作为排序的依据。
3.5.2 使用命令
| 命令 | 说明 | 举例 |
|---|---|---|
| Zadd(key, score, member) | 添加元素, 已存在会更新score即重新排序 | |
| Zrem(key, member…) | 删除元素 | |
| Zremrangebylex | 根据指定集合区间进行删除 | |
| Zremrangebyrank(key, min, max) | 删除min<=index<=max的zset元素 | |
| Zremrangebyscore(key, min, max) | 删除min<=score<=max的zset元素 | |
| Zcard(key) | 查询集合成员数量 | |
| zcount mySet 1 3 | 获取zset集合指定分数之间存在的成员个数 | |
| zlexcount | 成员区间成员数量 | |
| Zscore(key, element) | 指定key和值,获取分数 | |
| Zrange(key, start, end) [withscores] | 返回start->end范围的成员, start 0 开始位置 end -1 最后一个,score由小到大 | |
| Zrank(key, member) | 获取zset成员的下标位置,如果值不存在返回null | |
| zrangebylex | 指定key和值,获取下标 | |
| Zrangebyscore(key, min, max) | 返回min<=score<=max的zset元素 | |
| Zrevrank(key, member) | 返回key的zset从大到小, 没有返回nil | |
| Zrevrange(key, start, end) [withscores] | 返回start->end范围的成员,score由大到小 | |
| Zincrby(key, ncrement, member) | key存在score加ncrement, 否子添加score=ncrement |
3.5.3 使用场景
- 用户点赞统计
- 用户排序,排行榜
- 7 日榜单计算
- 使用 zset 作为延时队列,用时间作为 score, 当获取是取得 score 范围为 0 - now 的时间的范围数据
3.5.4 底层结构
3.5.4.1 底层结构
Redis 中的有序集合, 元素是string类型且不能重复, 集合的最大成员数是2^32 - 1即42多亿, 每个元素关联一个double类型的分数, double可以重复且用来进行排序。当移除最后一个元素,数据结构被删除,内存被回收。
Zset 当采用ziplist结构式crud的时间复杂度是O(1), 当采用skiplist时时间复杂度为O(log(n))。
Redis的配置文件中关于有序集合底层实现的两个配置。
-
zset-max-ziplist-entries 128:zset采用压缩列表时,元素个数最大值。默认值为128。
-
zset-max-ziplist-value 64:zset采用压缩列表时,每个元素的字符串长度最大值。默认值为64。
zset添加元素的主要逻辑位于t_zset.c的zaddGenericCommand函数中。zset插入第一个元素时,会判断下面两种条件:
-
zset-max-ziplist-entries的值是否等于0;
-
zset-max-ziplist-value小于要插入元素的字符串长度。
满足任一条件Redis就会采用跳跃表作为底层实现,否则采用压缩列表作为底层实现方式。
插入第一个元素时
if (server.zset_max_ziplist_entries == 0 || server.zset_max_ziplist_value < sdslen(c->argv[scoreidx+1]->ptr)) {
zobj = createZsetObject(); // 创建跳跃表结构
} else {
zobj = createZsetZiplistObject();// 创建压缩列表结构
}
插入元素时
if (zzlLength(zobj->ptr) > server.zset_max_ziplist_entries)
zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);
if (sdslen(ele) > server.zset_max_ziplist_value)
zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);
zset在转为跳跃表之后,即使元素被逐渐删除,也不会重新转为压缩列表
3.5.4.2 跳跃表(skiplist)
-
跳跃表由很多层构成。
-
跳跃表有一个头(header)节点,头节点中有一个64层的结构,每层的结构包含指向本层的下个节点的指针,指向本层下个节点中间所跨越的节点个数为本层的跨度(span)。
-
除头节点外,层数最多的节点的层高为跳跃表的高度(level),图中跳跃表的高度为3。
-
每层都是一个有序链表,数据递增。
-
除header节点外,一个元素在上层有序链表中出现,则它一定会在下层有序链表中出现。
-
跳跃表每层最后一个节点指向NULL,表示本层有序链表的结束。
-
跳跃表拥有一个tail指针,指向跳跃表最后一个节点。
-
最底层的有序链表包含所有节点,最底层的节点个数为跳跃表的长度(length)(不包括头节点),图中跳跃表的长度为7。
-
每个节点包含一个后退指针,头节点和第一个节点指向NULL;其他节点指向最底层的前一个节点。
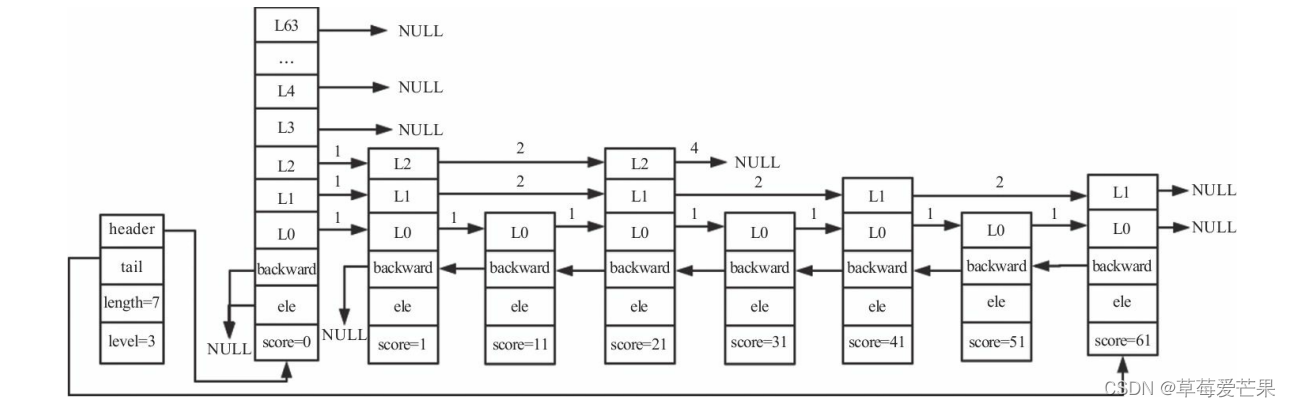
跳跃表是以牺牲空间的形式来达到快速查找的目的。跳跃表与平衡树相比,实现方式更简单,只要熟悉有序链表,就可以轻松地掌握跳跃表。
3.5.4.2.1 跳跃表节点信息
typedef struct zskiplistNode {
// 用于存储字符串类型的数据
sds ele;
// 用于存储排序的分值,从小到大进行排列,当score相同会根据member的字典序进行排序
double score;
// 后退指针,只能指向当前节点最底层的前一个节点,头节点和第一个节点——backward指向NULL,从后向前遍历跳跃表时使用。
struct zskiplistNode *backward;
// 为柔性数组。每个节点的数组长度不一样,在生成跳跃表节点时,随机生成一个1~64的值,值越大出现的概率越低。
struct zskiplistLevel {
// 指向本层下一个节点,尾节点的forward指向NULL。
struct zskiplistNode *forward;
// forward指向的节点与本节点之间的元素个数。span值越大,跳过的节点个数越多。
unsigned int span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
// 指向跳跃表头节点。头节点是跳跃表的一个特殊节点,它的level数组元素个数为64。头节点在有序集合中不存储任何member和score值,ele值为NULL,score值为0;也不计入跳跃表的总长度。头节点在初始化时,64个元素的forward都指向NULL,span值都为0。
// 指向跳跃表尾节点。
struct zskiplistNode *header, *tail;
// 跳跃表长度,表示除头节点之外的节点总数。
unsigned long length;
// 跳跃表的高度。
int level;
} zskiplist;
3.5.4.2.2 创建跳跃表
节点层高
# define ZSKIPLIST_MAXLEVEL 64
# define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */
// Redis通过zslRandomLevel函数随机生成一个1~64的值,作为新建节点的高度,值越大出现的概率越低。节点层高确定之后便不会再修改
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
创建跳跃表节点
// 申请空间
zskiplistNode *zn =zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
// 赋值数据
zn->score = score;
zn->ele = ele;
return zn;
头结点
// 头节点是一个特殊的节点,不存储有序集合的member信息。头节点是跳跃表中第一个插入的节点,其level数组的每项forward都为NULL,span值都为0。
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
创建跳跃表
// 创建跳跃表结构体对象zsl。
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
// 将zsl的头节点指针指向新创建的头节点。
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
zsl->header->backward = NULL;
// 跳跃表层高初始化为1,长度初始化为0,尾节点指向NULL。
zsl->level = 1;
zsl->length = 0;
zsl->tail = NULL;
3.5.4.3.3 插入节点
查找插入位置
-
update[]:插入节点时,需要更新被插入节点每层的前一个节点。由于每层更新的节点不一样,所以将每层需要更新的节点记录在update[i]中。
-
rank[]:记录当前层从header节点到update[i]节点所经历的步长,在更新update[i]的span和设置新插入节点的span时用到。
x = zsl->header;
// 1. 第一次for循环,i=1。x为跳跃表的头节点。
// 2. 经过第二次for循环,i=0。x为跳跃表的第一个节点(score=1)。
for (i = zsl->level-1; i >= 0; i--) {
// 1. 此时i的值与zsl->level-1相等,所以rank[1]的值为0。
// 2. 此时i的值与zsl->level-1不相等,所以rank[0]等于rank[1]的值,值为1。
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
// 1. header->level[1].forward存在,并且header->level[1].forward->score==1小于要插入的score
// 1.2 第一个节点的第1层的forward指向NULL,所以不会再进入while循环。经过第一次for循环,rank[1]=1。x和update[1]都为第一个节点(score=1)。
// 2. x->level[0]->forward存在,并且x->level[0].foreard->score==21小于要插入的score,所以可以进入while循环,rank[0]=2。x为第二个节点(score=21)。
// 2.2 x->level[0]->forward存在,并且x->level[0].foreard->score==41大于要插入的score,所以不会再进入while,经过第二次for循环,rank[0]=2。x和update[0]都为第二个节点(score=21)
while (x->level[i].forward &&(x->level[i].forward->score < score ||(x->level[i].forward->score == score &&sdscmp(x->level[i].forward->ele,ele) < 0))) {
// 1. 进入while循环,rank[1]=1,x为第一个节点。
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
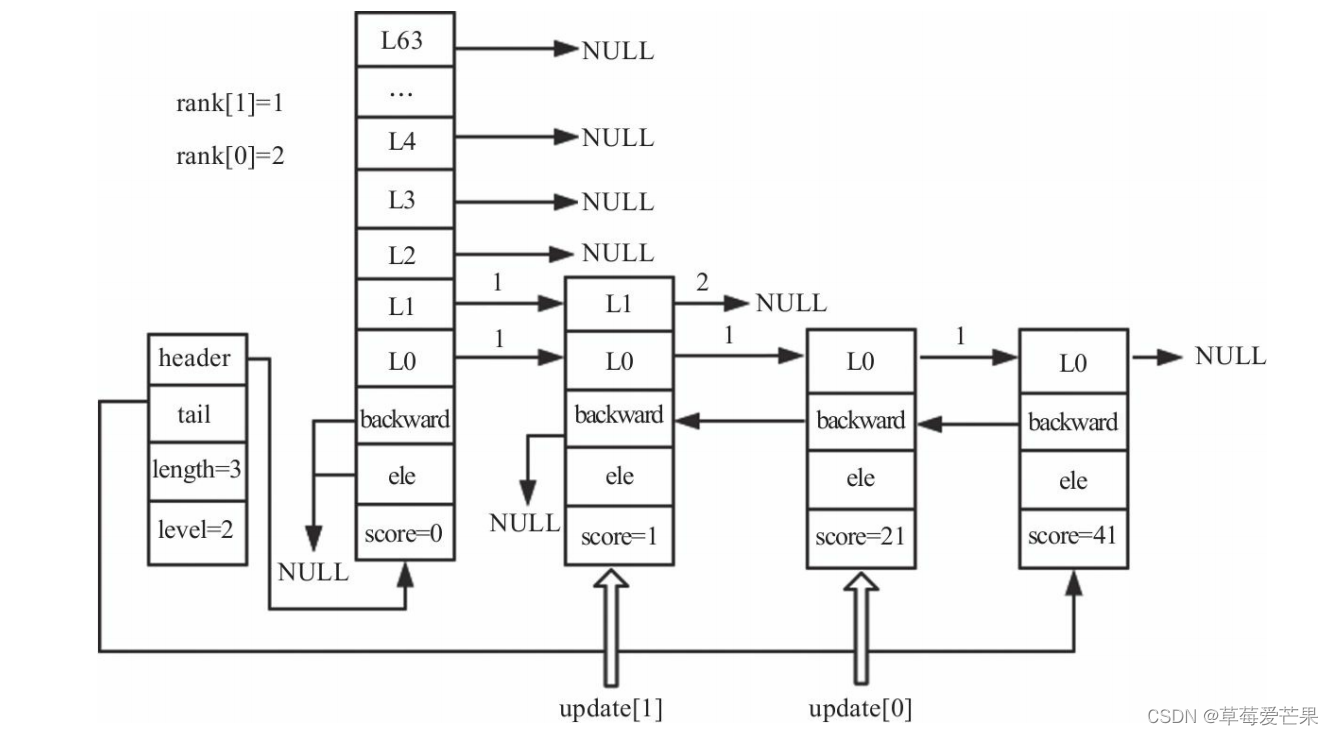
调整跳跃表高度
level = zslRandomLevel();
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
插入节点
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
调整backward
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
3.5.4.3.4 删除节点
查找节点位置 和 插入节点查找相同
设置span和forward
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
for (i = 0; i < zsl->level; i++) {
if (update[i]->level[i].forward == x) {
update[i]->level[i].span += x->level[i].span - 1;
update[i]->level[i].forward = x->level[i].forward;
} else {
update[i]->level[i].span -= 1;
}
}
}
更新跳跃表高度长度信息
if (x->level[0].forward) {
x->level[0].forward->backward = x->backward;
else {
zsl->tail = x->backward;
}
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
zsl->length--;
删除跳跃表
void zslFree(zskiplist *zsl) {
zskiplistNode *node = zsl->header->level[0].forward, *next;
zfree(zsl->header);
while(node) {
next = node->level[0].forward;
zslFreeNode(node);
node = next;
}
zfree(zsl);
}
3.5.4.3 压缩列表(ziplist)
压缩列表ziplist本质上就是一个字节数组,是Redis为了节约内存而设计的一种线性数据结构,可以包含多个元素,每个元素可以是一个字节数组或一个整数。
Redis的有序集合、散列和列表都直接或者间接使用了压缩列表。当有序集合或散列表的元素个数比较少,且元素都是短字符串时,Redis便使用压缩列表作为其底层数据存储结构。列表使用快速链表(quicklist)数据结构存储,而快速链表就是双向链表与压缩列表的组合。
3.5.4.3.1 存储结构
压缩列表结构

-
zlbytes: 压缩列表的字节长度,占4个字节,因此压缩列表最多有
2^32 -1个字节。 -
zltail: 压缩列表尾元素相对于压缩列表起始地址的偏移量,占4个字节。
-
zllen: 压缩列表的元素个数,占2个字节。zllen无法存储元素个数超过65535(2^16 -1)的压缩列表,必须遍历整个压缩列表才能获取到元素个数。
-
entryX: 压缩列表存储的元素,可以是字节数组或者整数,长度不限。
-
zlend: 压缩列表的结尾,占1个字节,恒为0xFF。
元素entry结构

previous_entry_length字段表示前一个元素的字节长度,占1个或者5个字节,当前一个元素的长度小于254字节时,用1个字节表示;当前一个元素的长度大于或等于254字节时,用5个字节来表示。而此时previous_entry_length字段的第1个字节是固定的0xFE,后面4个字节才真正表示前一个元素的长度。假设已知当前元素的首地址为p,那么p-previous_entry_length就是前一个元素的首地址,从而实现压缩列表从尾到头的遍历。
encoding字段表示当前元素的编码,用字节表示各个编码。长度可变。可解析出当前存储的是那个数据类型或者数组和数组的长度。
3.6 bitmap
3.7 geohash
3.8 hyperloglog
3.9 streams
3.9.1 简单介绍
Redis5.0 发布,一种新型的数据结构;它的目的是一个新的强大的支持多播的可持久化消息队列。
3.9.2 底层结构
Redis Stream 的结构如下所示,它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容,每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消息时自动创建。
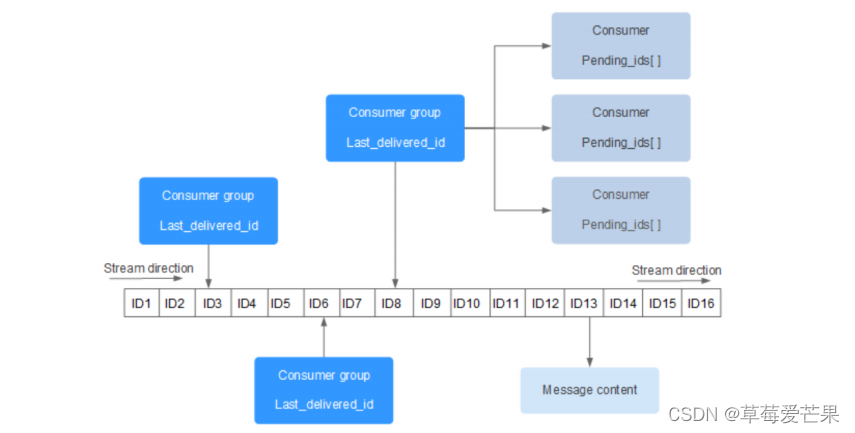
- Consumer Group: 消费组,使用 XGROUP CREATE 命令创建,一个消费组有多个消费者 (Consumer)。
- last_delivered_id: 游标,每个消费组会有个游标 last_delivered_id,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。
- pending_ids: 消费者 (Consumer) 的状态变量,作用是维护消费者的未确认的 id。pending_ids 记录了当前已经被客户端读取的消息,但是还没有 ack (Acknowledge character:确认字符)。
3.9.3 命令使用
3.9.1 Stream 添加元素
添加到stream中
ID组成: <millisecondsTime>-<sequenceNumber>
XADD mystream * sensor-id 1234 temperature 19.8
1518951480106-0
# XADD 往 stream 中添加一个数据
# mystream stream 的名称
# * 条目ID, * 表示Redis服务器为我们自动生成一个新的ID
# 添加了一个条目 sensor-id: 123, temperature: 19.8
> XADD somestream 0-2 foo bar
0-2
# 显示指定ID
# 最小ID为0-1,并且命令不接受等于或小于前一个ID的ID
3.9.2 查看元素
获取stream条目数量
XLEN mystream
(integer) 1
要根据范围查询Stream
# 根据两个ID,start 和 end,返回包含改id的区间的数据信息
# - 和 + 分表代表最小和最大id
> XRANGE mystream - +
1) 1) 1518951480106-0
2) 1) "sensor-id"
2) "1234"
3) "temperature"
4) "19.8"
2) 1) 1518951482479-0
2) 1) "sensor-id"
2) "9999"
3) "temperature"
4) "18.2"
根据时间返回进行获取
XRANGE mystream 1518951480106 1518951480107
1) 1) 1518951480106-0
2) 1) "sensor-id"
2) "1234"
3) "temperature"
4) "19.8"
根据count返回进行获取的区间信息的指定数量的条目
XRANGE mystream - + COUNT 2
1) 1) 1519073278252-0
2) 1) "foo"
2) "value_1"
2) 1) 1519073279157-0
2) 1) "foo"
2) "value_2"
# count 类似于分页,一页大小多少,下一页可以使用
# 该页数最后一个时间或者条目+1
# > XRANGE mystream 1519073279158 + COUNT 2
XREVRANGE命令与XRANGE相同,但是以相反的顺序返回元素
XREVRANGE mystream + - COUNT 1
1) 1) 1519073287312-0
2) 1) "foo"
2) "value_10"
3.9.3 消费组
创建消费组
# $ 表示 group 的offset 是队列中的最后一个元素,即从尾部开始消费,以前的消息忽略
# MKSTREAM这个参数会判断stream是否存在,如果不存在会创建一个我们指定名称的stream,不加这个参数,stream不存在会报错。
XGROUP CREATE mystream mygroup $ MKSTREAM
# 表示从头开始消费
xgroup create mystream cg1 0-0
删除消费者组
XGROUP DESTROY mystream consumer-group-name
添加消费者
XGROUP createconsumer mystream customer1 c1
删除消费者
XGROUP delconsumer mystream customer1 c1
3.9.4 消费消息
消费消息
# XREAD 和 XREADGROUP
# 从mystream和writers这2个stream中读取消息,offset都是0,COUNT参数指定了每个队列中读取的消息数量不多于2个
XREAD COUNT 2 STREAMS mystream writers 0-0 0-0
# 从stream 头部读取两条信息, 顺序消费需要记住上一个消息的id, 以此id开始
xread count 2 streams mystream 0-0
# 从stream 读取一条信息
xread count 1 streams mystream $
# 从尾部阻塞等待新消息到来,0 表示永远阻塞 1000 表示阻塞1秒,若1s还没有消息到来返回 nil
xread block 0 count 1 streams mystream $
# 这个命令是使用消费组mygroup的Alice这个消费者从mystream这个stream中读取1条消息
# 使用了BLOCK,表示是阻塞读取,如果读不到数据,会阻塞等待2s,不加这个条件默认是不阻塞的
# ">"表示只接受其他消费者没有消费过的消息
# 如果没有">",消费者会消费比指定id偏移量大并且没有被自己确认过的消息,这样就不用关系是否ACK过或者是否BLOCK了。
XREADGROUP GROUP customer1 c1 BLOCK 2000 COUNT 1 STREAMS mystream >
确认消息
XACK mystream mygroup 1526569495631-0
3.9.5 信息查看
查看信息
XINFO STREAM mystream
XINFO GROUPS mystream
XINFO CONSUMERS customer1
XINFO HELP
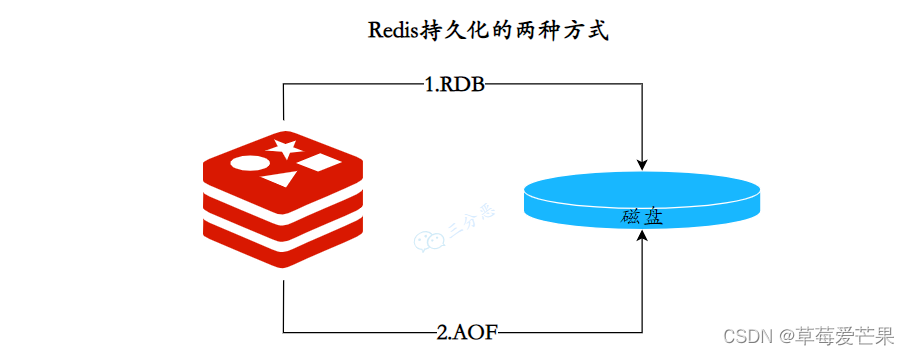
4. Redis 持久化
4.1 RDB
RDB(Redis DataBase), 在不同的时间点,将redis存储的数据生成快照并存储到磁盘等介质上 。默认不开启。
Redis会将数据集的快照 dump 到 dump.rdb 文件中。
手动dump
手动触发分别对应save和bgsave命令:
- save命令:阻塞当前Redis服务器,直到RDB过程完成为止,对于内存比较大的实例会造成长时间阻塞,线上环境不建议使用。
- bgsave命令:Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。
自动触发
- 使用save相关配置,如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。
- 如果从节点执行全量复制操作,主节点自动执行bgsave生成RDB文件并发送给从节点
- 执行debug reload命令重新加载Redis时,也会自动触发save操作
- 默认情况下执行shutdown命令时,如果没有开启AOF持久化功能则自动执行bgsave。
通过配置文件来修改Redis服务器dump快照的频率,在打开 6379.conf 文件之后,搜索 save,可以看到下面的配置信息:
#
save 900 1
#
save 300 10
#
save 60 10000
| 优点 | 缺点 |
|---|---|
只有一个紧凑的二进制文件 dump.rdb,非常适合备份、全量复制的场景。 | 实时性低,RDB 是间隔一段时间进行持久化,没法做到实时持久化/秒级持久化。如果在这一间隔事件发生故障,数据会丢失。 |
| 容灾性好,可以把RDB文件拷贝道远程机器或者文件系统张,用于容灾恢复。 | 存在兼容问题,Redis演进过程存在多个格式的RDB版本,存在老版本Redis无法兼容新版本RDB的问题。 |
| 复速度快,RDB恢复数据的速度远远快于AOF的方式 |
4.2 AOF
AOF(Append Only File)Redis持久化的主流方式, 换了一个角度来实现持久化,将redis执行过的所有写指令记录下来,在下次redis重新启动时,只要把这些写指令从前到后再重复执行一遍,就可以实现数据恢复了。 主要作用是解决了数据持久化的实时性。默认不开启。
AOF的工作流程操作:命令写入 (append)、文件同步(sync)、文件重写(rewrite)、重启加载 (load)
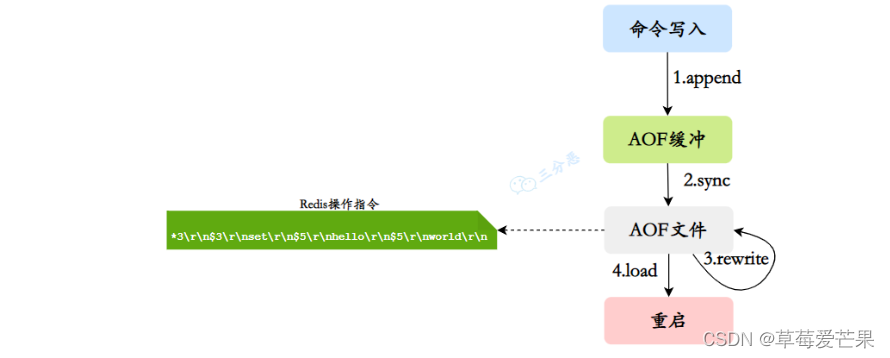
1)所有的写入命令会追加到aof_buf(缓冲区)中。
2)AOF缓冲区根据对应的策略向硬盘做同步操作。
3)随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩 的目的。
4)当Redis服务器重启时,可以加载AOF文件进行数据恢复。
在Redis的配置文件中存在三种同步方式,它们分别是:
appendfsync always # 每次有数据修改发生时都会写入AOF文件。
appendfsync everysec # 每秒钟同步一次,该策略为AOF的缺省策略。
appendfsync no # 从不同步。高效但是数据不会被持久化。
| 优点 | 缺点 |
|---|---|
实时性好,aof 持久化可以配置 appendfsync 属性,有 always,每进行一次命令操作就记录到 aof 文件中一次。 | AOF 文件比 RDB 文件大,且 恢复速度慢。 |
| 通过 append 模式写文件,即使中途服务器宕机,可以通过 redis-check-aof 工具解决数据一致性问题。 | 数据集大 的时候,比 RDB 启动效率低。 |
重启后恢复数据采用 AOF
5. Redis 其它功能
5.1 事务
5.1.1 Redis 事务
Redis 提供了一个 multi 命令开启事物,exec 命令提交事物,在它们之间的命令是在一个事物内的,能保证原子性。
Redis 事物的特点是 Redis 在没有执行到 exec 命令之前是不会执行命令的,只是将命令缓存起来,直到执行到 exec 命令再一次性原子的去执行。
Redis执行命令的错误主要分为两种:
-
命令错误:执行命令语法错误,比如说将 set 命令写成 sett
-
运行时错误:命令语法正确,但是执行错误,比如说对 List 集合执行 sadd 命令
Redis事物中如果发生上面两种错误,处理机制也是不同的:
-
命令错误:开启事物之后,往事物中添加的命令如果有命令错误(语法错误),那么整个事物中的命令都不会执行。
-
运行时错误:如果语法没有错误,而执行过程中发生了运行时错误,Redis不仅不会回滚事物,还会跳过这个运行时错误,继续向下执行命令
Watch 命令
事物能保证事物内的操作是原子性的,但是无法保证在事物开启到事物提交之间事物中的 key 没有被其他客户端修改。
Redis 提供了 watch 命令来解决这个问题,在 multi 命令之前我们可以使用 watch 命令来 “观察” 一个或多个key,在事物提交之前 Redis 会确保被 “观察” 的 key有没有被修改过,没有被修改过才会执行事物中的命令,如果存在 key 被修改过,那么整个事物中的命令都不会执行,有点类似于乐观锁的机制。
5.2 lua 脚本执行
在2.6版本推出了 lua 脚本功能。
redis 虽然提供了丰富的指令,且每一个指令的操作都是原子性的。但是在某些特定的场景下需要保证多个指令的执行是具有原子性的,就需要使用到lua脚本来扩展完成。Redis 服务器会单线程原子性执行 lua 脚本,保证 lua 脚本在处理的过程中不会被任意其它请求打断。
使用lua脚本的优点:
- 减少网络开销。可以将多个请求通过脚本的形式一次发送,减少网络时延。
- 原子操作。Redis会将整个脚本作为一个整体执行,中间不会被其他请求插入。因此在脚本运行过程中无需担心会出现竞态条件,无需使用事务。
- 复用。客户端发送的脚本会永久存在redis中,这样其他客户端可以复用这一脚本,而不需要使用代码完成相同的逻辑。
lua : Lua 是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。
5.2.1 lua 常用命令
5.2.1.1 EVAL
EVAL script numkeys key [key …] arg [arg …]
* script: 是一段 Lua5.1 脚本程序。 脚本不必定义为一个 Lua 函数
* numkeys: 指定后续参数有几个key,即:key [key …]中key的个数。如没有key,则为0
* key [key …]: 从 EVAL 的第三个参数开始算起,表示在脚本中所用到的那些 Redis 键(key)。在Lua脚本中通过KEYS[1], KEYS[2]获取。
* arg [arg …]: 附加参数。在Lua脚本中通过ARGV[1],ARGV[2]获取。
-- lua Eval 命令的使用示例:
-- 1. numkeys=1,keys数组只有1个元素key1,arg数组无元素
EVAL "return KEYS[1]" 1 key1
-- 2. numkeys=0,keys数组无元素,arg数组元素中有1个元素value1
EVAL "return ARGV[1]" 0 value1
eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second
-- lua 在执行redsi 命令示例:
EVAL "redis.call('SET', KEYS[1], ARGV[1]); redis.call('EXPIRE', KEYS[1], ARGV[2]); return 1;" 1 userAge 10 60
脚本中使用 redis.call() 去调用redis的命令,在 Lua 脚本中,可以使用两个不同函数来执行 Redis 命令,它们分别是: redis.call() 和 redis.pcall()
错误处理
redis.call() 在执行命令的过程中发生错误时,脚本会停止执行,并返回一个脚本错误,错误的输出信息会说明错误造成的原因。
127.0.0.1:6379> eval "return redis.call('get', 'foo')" 0
(error) ERR Error running script (call to f_282297a0228f48cd3fc6a55de6316f31422f5d17): ERR Operation against a key holding the wrong kind of value
redis.pcall() 出错时并不引发(raise)错误,而是返回一个带 err 域的 Lua 表(table),用于表示错误。
127.0.0.1:6379> EVAL "return redis.pcall('get', 'foo')" 0
(error) ERR Operation against a key holding the wrong kind of value
5.2.1.2 SCRIPT LOAD, EVALSHA
SCRIPT LOAD
SCRIPT LOAD script
-- 命令的执行结果为 SHA1
SCRIPT LOAD 将脚本 script 添加到Redis服务器的脚本缓存中,并不立即执行这个脚本,而是会立即对输入的脚本进行求值。并返回给定脚本的 SHA1 校验和。如果给定的脚本已经在缓存里面了,那么不执行任何操作。
EVALSHA
-- 使用 SCRIPT LOAD script 命令的执行结果 xxx
EVALSHA SHA1 numkeys key [key …] arg [arg …]
在脚本被加入到缓存之后,在任何客户端通过EVALSHA命令,可以使用脚本的 SHA1 校验和来调用这个脚本。脚本可以在缓存中保留无限长的时间,直到执行SCRIPT FLUSH为止。
# 案例
## SCRIPT LOAD加载脚本,并得到sha1值
SCRIPT LOAD "redis.call('SET', KEYS[1], ARGV[1]);redis.call('EXPIRE', KEYS[1], ARGV[2]); return 1;"
返回: "6aeea4b3e96171ef835a78178fceadf1a5dbe345"
# 使用返回的值执行脚本
EVALSHA 6aeea4b3e96171ef835a78178fceadf1a5dbe345 1 userAge 10 60
5.2.1.3 SCRIPT EXISTS
SCRIPT EXISTS sha1 [sha1 …]
给定一个或多个脚本的 SHA1 校验和,返回一个包含 0 和 1 的列表,表示校验和所指定的脚本是否已经被保存在缓存当中
127.0.0.1:6379> SCRIPT EXISTS 6aeea4b3e96171ef835a78178fceadf1a5dbe345 6aeea4b3e96171ef835a78178fceadf1a5dbe366
1) (integer) 1
2) (integer) 0
5.2.1.4 SCRIPT FLUSH
SCRIPT FLUSH
127.0.0.1:6379> SCRIPT FLUSH
OK
清除Redis服务端所有 Lua 脚本缓存
5.2.1.5 SCRIPT KILL
SCRIPT FLUSH
杀死当前正在运行的 Lua 脚本,当且仅当这个脚本没有执行过任何写操作时,这个命令才生效。 这个命令主要用于终止运行时间过长的脚本,比如一个因为 BUG 而发生无限 loop 的脚本,诸如此类。
假如当前正在运行的脚本已经执行过写操作,那么即使执行SCRIPT KILL,也无法将它杀死,因为这是违反 Lua 脚本的原子性执行原则的。在这种情况下,唯一可行的办法是使用SHUTDOWN NOSAVE命令,通过停止整个 Redis 进程来停止脚本的运行,并防止不完整(half-written)的信息被写入数据库中。
5.2.2 编写lua脚本
5.2.2.1 简单的脚本案例
- 编写脚本
local key = KEYS[1]
local val = redis.call("GET", key);
if val == ARGV[1]
then
redis.call('SET', KEYS[1], ARGV[2])
return 1
else
return 0
end
- 执行
执行命令: redis-cli -a 密码 --eval Lua脚本路径 key [key …] , arg [arg …]
如:redis-cli -a 123456 --eval ./Redis_CompareAndSet.lua userName , zhangsan lisi
注意:“–eval"而不是命令模式中的"eval”,一定要有前端的两个-,脚本路径后紧跟key [key …],相比命令行模式,少了numkeys这个key数量值key [key …] 和 arg [arg …] 之间的“ , ”,英文逗号前后必须有空格,否则报错。
5.2.2.2 lua 脚本
Demo1:
redis.call ('set', KEYS[1], ARGV[1])
redis.call ('set', KEYS[2], ARGV[1])
redis.call('expire', KEYS[1], 28800)
redis.call('expire', KEYS[2], 28800)
local str1 = redis.call ('get', KEYS [1])
local str2 = redis.call ('get', KEYS [2])
if str1 == str2 then
return true
end
return false
Demo2:
local times = redis.call('incr',KEYS[1])
if times == 1 then
redis.call('expire',KEYS[1], ARGV[1])
end
if times > tonumber(ARGV[2]) then
return 0
end
return 1
Demo3:
-- 表示注释
-- KEYS[1] 表示接收传入的第一个key参数
-- 先清空原有的数据集合
redis.call('del', KEYS[1])
-- for循环插入数据
-- i=1表示从1开始,20表示截止,1表示递增值
for i=1, 20, 1 do
-- 使用lpush向redis写入
redis.call('lpush', KEYS[1], i)
end
return "success" -- 返回成功
local keys = KEYS
for i, k in ipairs(keys) do
redis.call("ZADD", k, 1, ARGV[1])
end
Demo4:
local wrapIdObj = redis.call ('get', KEYS [1])
if wrapIdObj ~= nil then
redis.call ('set', KEYS[1], ARGV[1])
redis.call('expire', KEYS[1], 28800)
return true
else
return false
end
Demo5:
-- redis 释放锁
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
5.2.3 Java 执行lua脚本
5.2.3.1 文件执行
/**
* redis 执行 lua 脚本
* @param scriptFileName lua 脚本文件名 lua 脚本文件需要放到 classpath:redis/lua/
* @param keys 参数
* @param r Long, Boolean, List, or deserialized value type
* @param args 参数
* @param <R> Long, Boolean, List, or deserialized value type
* @return 返回结果
*/
public <R> R executeLua(@NotNull String scriptFileName, @NotNull String[] keys, @NotNull Class<R> r, Object... args) {
try {
// 执行 lua 脚本
DefaultRedisScript<R> redisScript = new DefaultRedisScript<>();
// 指定 lua 脚本
redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource("redis/lua/" + scriptFileName + ".lua")));
// 指定返回类型
redisScript.setResultType(r);
// 参数一:redisScript,参数二:key列表, 参数三:arg(可多个)
return redisTemplate.execute(redisScript, Arrays.asList(keys), args);
} catch (Exception e) {
return null;
}
}
5.2.3.2 字符串形式执行
// 只需要变化 DefaultRedisScript 即可
DefaultRedisScript<R> redisScript = new DefaultRedisScript<>();
redisScript.setScriptText([脚本字符串]);
redisScript.setResultType([返回类型]);
5.3 分布式锁
5.3.1 第一阶段
# 加锁
# Redis Setnx(SET if Not eXists) 命令在指定的 key 不存在时,为 key 设置指定的值。
# 设置成功,返回 1 。 设置失败,返回 0 。
setnx key value
# 释放锁
del key
存在的问题
当程序宕机,或者关机时容易造成死锁,即锁永远得不到释放
5.3.2 第二阶段
方式一 使用lua脚本
# 如果key不存在,则创建并赋值,成功加入缓存并且返回1;如果已存在,则返回0。
SETNX key value
# 设置key的生存时间,当key过期(生存时间为0),会自动删除
EXPIRE key seconds
方式二 redis 在2.6.12版本过后增加新的解决方案
# EX seconds: 将键的过期时间设置为 seconds 秒。
# SET key value EX seconds 等同于 SETEX key seconds value
# PX millisecounds:将键的过期时间设置为 milliseconds 毫秒。
# SET key value PX milliseconds 等同于 PSETEX key milliseconds value
# NX:只在键不存在的时候,才对键进行设置操作。
# SET key value NX 等同于 SETNX key value
# XX:只在键已经存在的时候,才对键进行设置操作
# SET操作成功后,返回的是OK,失败返回NIL
set key value [expiration EX seconds|PX milliseconds] [NX|XX]
存在的问题
1> 程序换没有执行完,锁过期了
2> 锁被其它程序误删
5.3.2 第三阶段
程序换没有执行完,锁过期了
-
测试并预估加锁业务逻辑的执行时长,设置合理的过期时间
-
可以使用看门狗,存储时key-value-10,同时异步运行一个看门狗,当5的时候检查key的值是不是value,若是则续期10,然后继续检查
锁被其它程序误删
在锁删除时先获取值value是否是自己,是的话再删除。因为判断是否是自己这段逻辑不是原子的,所以需要使用lua脚本来保证。
-- redis 释放锁
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
分段锁
为了提高redis锁的性能问题,可以采用分段锁,即一个资源被分为多个部分,每个部分有一把锁,让锁的粒度更细,从而提升性能。
高可用
一台redis肯定会存在风险,所以引入高可用,redis主从,但是高可用也存在数据同步不实时的问题。
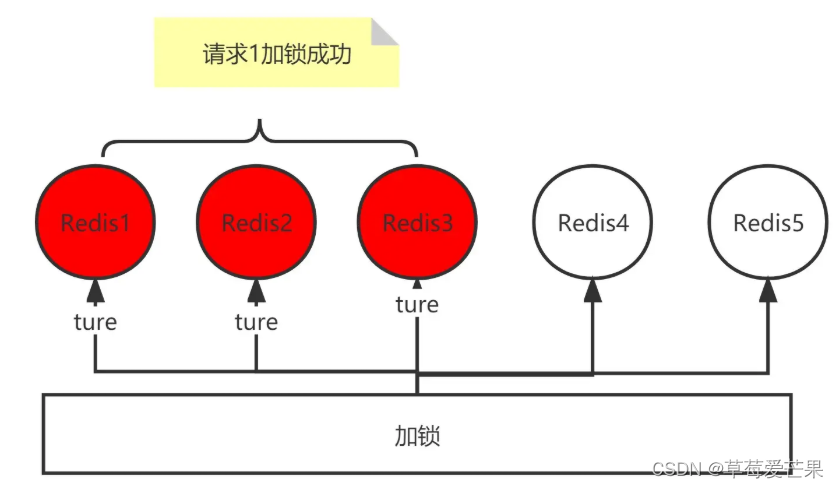
红锁
由于redis主从具有数据同步不实时的问题,所以使用红锁来实现高可用。
加锁时,多个redis都进行加锁,若成功一半,则认为加锁成功。
5.3.4 加锁失败处理
5.3 Redisson 分布式
5.3.1 分布式锁
5.3.2 分布式锁的使用
5.3.2.1 可重入锁
@Autowired
private RedissonClient redissonClient;
public String testRedisson(){
// 获取分布式锁,只要锁的名字一样,就是同一把锁
RLock lock = redissonClient.getLock("lock");
// 加锁(阻塞等待),默认过期时间是30秒
lock.lock();
try{
// 如果业务执行过长,Redisson会自动给锁续期
Thread.sleep(1000);
System.out.println("加锁成功,执行业务逻辑");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 解锁,如果业务执行完成,就不会继续续期,即使没有手动释放锁,在30秒过后,也会释放锁
// 如果false 说明已经释放了 不需要在释放了
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
return "Hello Redisson!";
}
5.3.2.2 读写锁
分布式可重入读写锁允许同时有多个读锁和一个写锁处于加锁状态。在读写锁中,读读共享、读写互斥、写写互斥。
RReadWriteLock rwlock = redisson.getReadWriteLock("anyRWLock");
// 最常见的使用方法
rwlock.readLock().lock();
// 或
rwlock.writeLock().lock();
举例
读写锁测试类,当访问write接口时,read接口会被阻塞住。
@RestController
public class TestController {
@Autowired
RedissonClient redissonClient;
@Autowired
StringRedisTemplate redisTemplate;
@RequestMapping("/write")
public String write(){
RReadWriteLock readWriteLock = redissonClient.getReadWriteLock("wr-lock");
RLock writeLock = readWriteLock.writeLock();
String s = UUID.randomUUID().toString();
writeLock.lock();
try {
redisTemplate.opsForValue().set("wr-lock-key", s);
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
writeLock.unlock();
}
return s;
}
@RequestMapping("/read")
public String read(){
RReadWriteLock readWriteLock = redissonClient.getReadWriteLock("wr-lock");
RLock readLock = readWriteLock.readLock();
String s = "";
readLock.lock();
try {
s = redisTemplate.opsForValue().get("wr-lock-key");
} finally {
readLock.unlock();
}
return s;
}
}
5.3.2.3 闭锁(CountDownLatch)
CountDownLatch作用:某一线程,等待其他线程执行完毕之后,自己再继续执行。
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.trySetCount(1);
latch.await();
// 在其他线程或其他JVM里
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.countDown();
在TestController中添加测试方法,访问close接口时,调用await()方法进入阻塞状态,直到有三次访问release接口时,close接口才会返回。
@RequestMapping("/close")
public String close() throws InterruptedException {
RCountDownLatch close = redissonClient.getCountDownLatch("close");
close.trySetCount(3);
close.await();
return "close";
}
@RequestMapping("/release")
public String release(){
RCountDownLatch close = redissonClient.getCountDownLatch("close");
close.countDown();
return "release";
}
5.3.3 信号量
Redisson的分布式信号量与的用法与java.util.concurrent.Semaphore相似
RSemaphore semaphore = redisson.getSemaphore("semaphore");
semaphore.acquire();
//或
semaphore.acquireAsync();
semaphore.acquire(23);
semaphore.tryAcquire();
//或
semaphore.tryAcquireAsync();
semaphore.tryAcquire(23, TimeUnit.SECONDS);
//或
semaphore.tryAcquireAsync(23, TimeUnit.SECONDS);
semaphore.release(10);
semaphore.release();
//或
semaphore.releaseAsync();
// 当访问acquireSemaphore接口时,redis中的semaphore会减1;访问releaseSemaphore接口时,redis中的semaphore会加1。当redis中的semaphore为0时,继续访问acquireSemaphore接口,会被阻塞,直到访问releaseSemaphore接口,使得semaphore>0,acquireSemaphore才会继续执行。
@RequestMapping("/releaseSemaphore")
public String releaseSemaphore(){
RSemaphore semaphore = redissonClient.getSemaphore("semaphore");
semaphore.release();
return "release success";
}
@RequestMapping("/acquireSemaphore")
public String acquireSemaphore() throws InterruptedException {
RSemaphore semaphore = redissonClient.getSemaphore("semaphore");
semaphore.acquire();
return "acquire success";
}
5.3.4 其它分布式功能
5.3.5 API
| 方法 | 描述 | 其它 |
|---|---|---|
| trylock() | tryLock()方法是有返回值的,它表示用来尝试获取锁 | 如果获取成功,则返回true 如果获取失败(即锁已被其他线程获取),则返回false 这个方法无论如何都会立即返回。 在拿不到锁时不会一直在那等待 |
| tryLock((long)waitTimeout, (long)leaseTime, TimeUnit.SECONDS); | waitTimeout 尝试获取锁的最大等待时间,超过这个值,则认为获取锁失败 锁的持有时间,超过这个时间锁会自动失效(值应设置为大于业务处理的时间,确保在锁有效期内业务能处理完) | |
5.4 发布订阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
# 订阅一个或多个符合给定模式的频道。
PSUBSCRIBE pattern [pattern ...]
# 查看订阅与发布系统状态。
PUBSUB subcommand [argument [argument ...]]
# 将信息发送到指定的频道。
PUBLISH channel message
# 退订所有给定模式的频道。
PUNSUBSCRIBE [pattern [pattern ...]]
# 订阅给定的一个或多个频道的信息。
SUBSCRIBE channel [channel ...]
# 指退订给定的频道。
UNSUBSCRIBE [channel [channel ...]]
# 基于模式(pattern)的发布/订阅
# ? 表示1个占位符,* 表示1个以上占位符
$ psubscribe p-test*
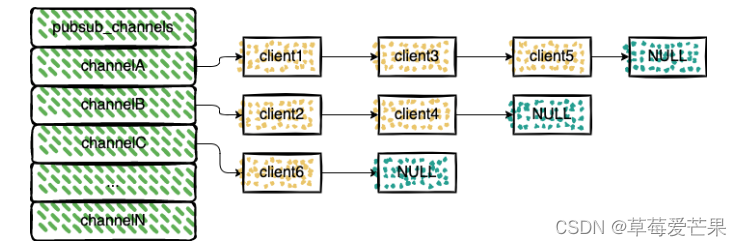
5.5 Rdies 缓存击穿,穿透,雪崩
当请求进来的时候,先从缓存中取数据,如果有则直接返回缓存中的数据。如果缓存中没数据,就去数据库中读取数据并写到缓存中,再返回结果。但这样也会带来缓存击穿,穿透,雪崩的问题。
5.5.1 缓存击穿
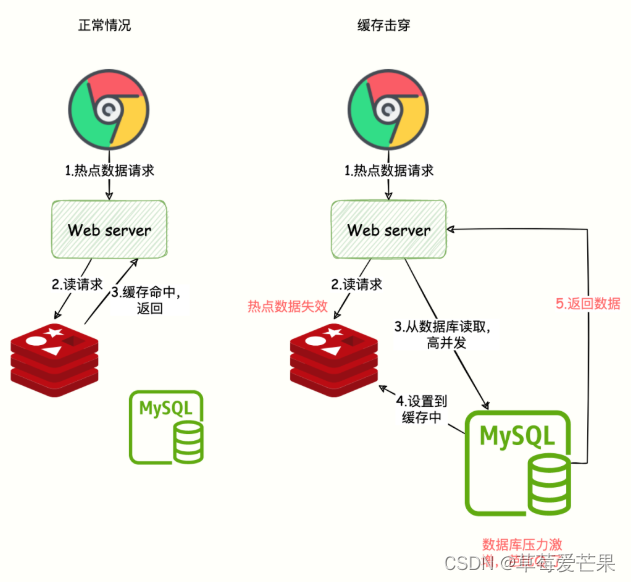
高并发流量,访问的这个数据是热点数据,请求的数据在 DB 中存在,但是 Redis 存的那一份已经过期,后端需要从 DB 从加载数据并写到 Redis。
但是由于高并发,可能会把 DB 压垮,导致服务不可用。
解决方案1:
可以永久的保存管理这些热点数据,不设置过期时间,或者手动删除而不是自动删除,又或者当单位时间平均qps大的话过期时间自动续期。
解决方案2:
热点数据过期,当重新重mysql读回redis时可以使用分布式锁。
5.5.2 缓存穿透
缓存穿透通常是指redis不存在这样的key,mysql也不存在, 导致每次请求都会穿透到数据库,缓存成了摆设,对数据库产生很大压力从而影响正常服务。
解决方案1:
在进行缓存查找时进行逻辑校验,拦截哪些根本不可能存在或者逻辑上不会有的key的访问,若key是合法的而数据库没有,那么缓存其value值为null并添加过期时间。
解决方案2:
使用布隆过滤器,虽然可能存在误判。
5.5.3 缓存雪崩
缓存雪崩指的是大量的请求无法在 Redis 缓存系统中处理,请求全部打到数据库,导致数据库压力激增,甚至宕机。 也就是缓存同时失效,或者重启时redis为空的情况容易发生。
解决方案1:
对于大量的key同时过期的情况,可以给数据设置不同的过期时间,采用随机值得方式。
解决方案2:
接口限流
解决方案3:
对于重启造成的雪崩,可以使用预加载的方式。
5.5.4 布隆过滤器
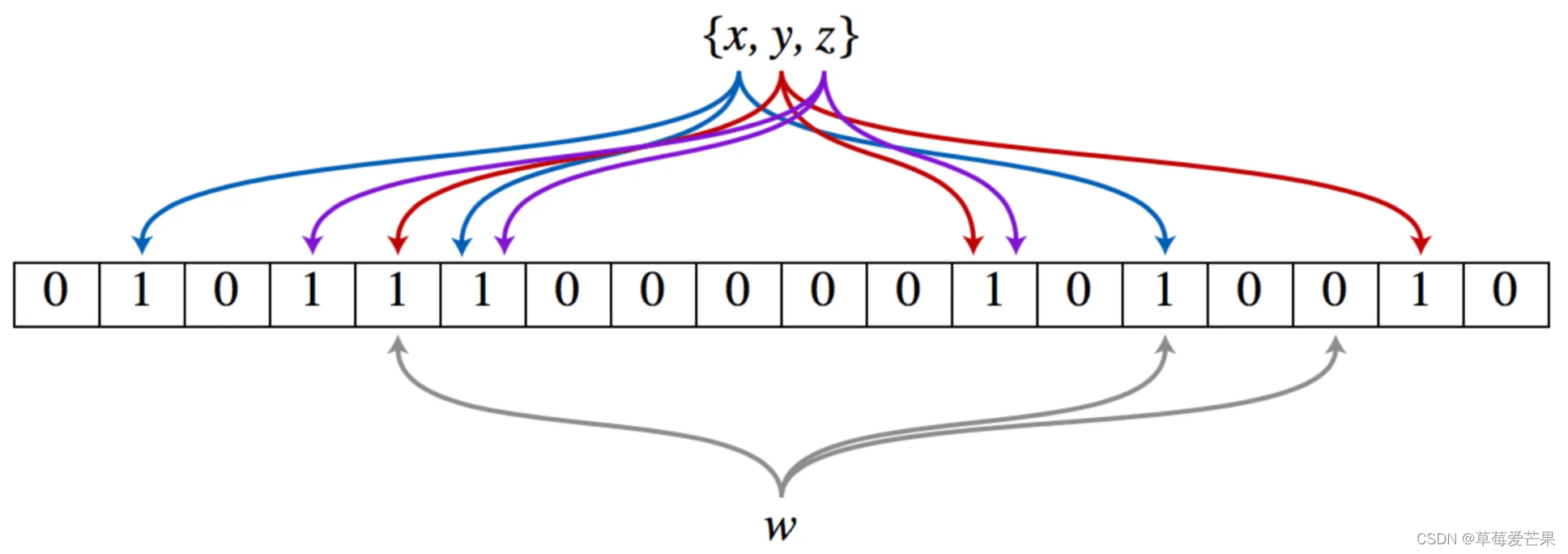
布隆过滤器(Bloom Filter), 可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。 相关文献
布隆过滤器的原理介绍
当一个元素加入布隆过滤器中的时候,会进行如下操作:
- 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1。
当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:
- 对给定元素再次进行相同的哈希计算;
- 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
6. Redis 高可用
6.1 主从
6.1.1 主从介绍
主从复制,是指将一台 Redis 服务器的数据,复制到其他的 Redis 服务器。前者称为 主节点(master),后者称为 从节点(slave)。且数据的复制是 单向 的,只能由主节点到从节点。Redis 主从复制支持 主从同步 和 从从同步 两种,后者是 Redis 后续版本新增的功能,以减轻主节点的同步负担。
主要作用:
- 数据冗余: 主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复: 当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复 (实际上是一种服务的冗余)。
- 负载均衡: 在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务 (即写 Redis 数据时应用连接主节点,读 Redis 数据时应用连接从节点),分担服务器负载。尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高 Redis 服务器的并发量。
- 高可用基石: 除了上述作用以外,主从复制还是哨兵和集群能够实施的 基础,因此说主从复制是 Redis 高可用的基础。
Redis主从有几种常见的拓扑结构
一主一从,一主多从,树状主从
6.1.2 主从复制流程

- 保存主节点(master)信息 这一步只是保存主节点信息,保存主节点的ip和port。
- 主从建立连接 从节点(slave)发现新的主节点后,会尝试和主节点建立网络连接。
- 发送ping命令 连接建立成功后从节点发送ping请求进行首次通信,主要是检测主从之间网络套接字是否可用、主节点当前是否可接受处理命令。
- 权限验证 如果主节点要求密码验证,从节点必须正确的密码才能通过验证。
- 同步数据集 主从复制连接正常通信后,主节点会把持有的数据全部发送给从节点。
- 命令持续复制 接下来主节点会持续地把写命令发送给从节点,保证主从数据一致性。
6.1.3 主从复制方式
6.1.3.1 全量复制
一般用于初次复制场景,Redis早期支持的复制功能只有全量复制,它会把主节点全部数据一次性发送给从节点,当数据量较大时,会对主从节点和网络造成很大的开销。
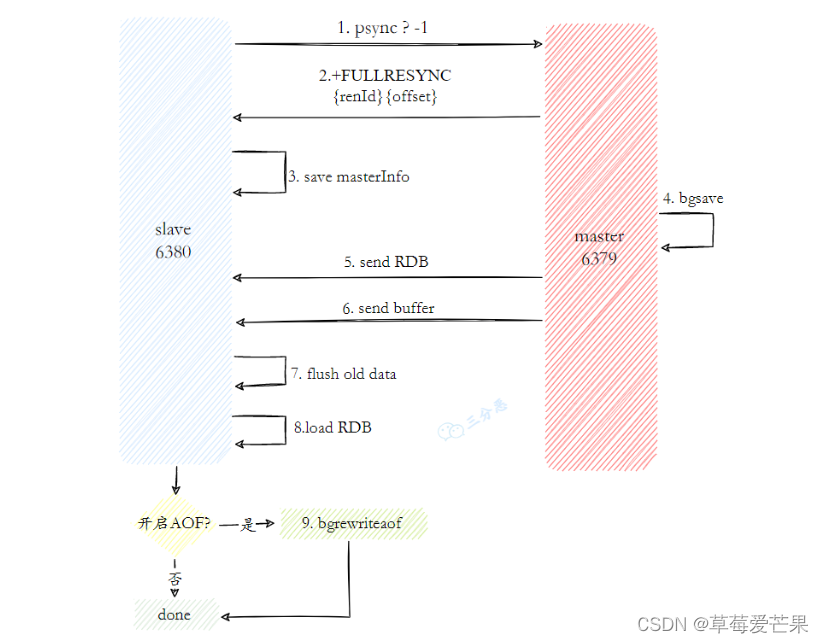
- 发送psync命令进行数据同步,由于是第一次进行复制,从节点没有复制偏移量和主节点的运行ID,所以发送psync-1。
- 主节点根据psync-1解析出当前为全量复制,回复+FULLRESYNC响应。
- 从节点接收主节点的响应数据保存运行ID和偏移量offset
- 主节点执行bgsave保存RDB文件到本地
- 主节点发送RDB文件给从节点,从节点把接收的RDB文件保存在本地并直接作为从节点的数据文件
- 对于从节点开始接收RDB快照到接收完成期间,主节点仍然响应读写命令,因此主节点会把这期间写命令数据保存在复制客户端缓冲区内,当从节点加载完RDB文件后,主节点再把缓冲区内的数据发送给从节点,保证主从之间数据一致性。
- 从节点接收完主节点传送来的全部数据后会清空自身旧数据
- 从节点清空数据后开始加载RDB文件
- 从节点成功加载完RDB后,如果当前节点开启了AOF持久化功能, 它会立刻做bgrewriteaof操作,为了保证全量复制后AOF持久化文件立刻可用。
6.1.3.2 增量复制
部分复制部分复制主要是Redis针对全量复制的过高开销做出的一种优化措施, 使用psync{runId}{offset}命令实现。当从节点(slave)正在复制主节点 (master)时,如果出现网络闪断或者命令丢失等异常情况时,从节点会向 主节点要求补发丢失的命令数据,如果主节点的复制积压缓冲区内存在这部分数据则直接发送给从节点,这样就可以保持主从节点复制的一致性。
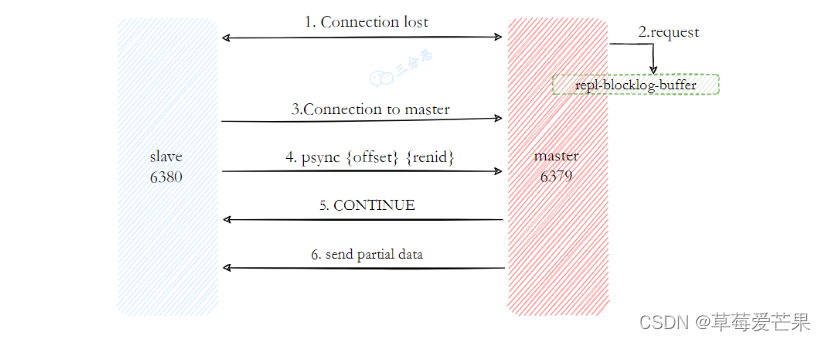
- 当主从节点之间网络出现中断时,如果超过repl-timeout时间,主节点会认为从节点故障并中断复制连接
- 主从连接中断期间主节点依然响应命令,但因复制连接中断命令无法发送给从节点,不过主节点内部存在的复制积压缓冲区,依然可以保存最近一段时间的写命令数据,默认最大缓存1MB。
- 当主从节点网络恢复后,从节点会再次连上主节点
- 当主从连接恢复后,由于从节点之前保存了自身已复制的偏移量和主节点的运行ID。因此会把它们当作psync参数发送给主节点,要求进行部分复制操作。
- 主节点接到psync命令后首先核对参数runId是否与自身一致,如果一 致,说明之前复制的是当前主节点;之后根据参数offset在自身复制积压缓冲区查找,如果偏移量之后的数据存在缓冲区中,则对从节点发送+CONTINUE响应,表示可以进行部分复制。
- 主节点根据偏移量把复制积压缓冲区里的数据发送给从节点,保证主从复制进入正常状态。
6.1.4 主从复制存在的问题
- 一旦主节点出现故障,需要手动将一个从节点晋升为主节点,同时需要修改应用方的主节点地址,还需要命令其他从节点去复制新的主节点,整个过程都需要人工干预。
- 主节点的写能力受到单机的限制。
- 主节点的存储能力受到单机的限制。
第一个问题是Redis的高可用问题,第二、三个问题属于Redis的分布式问题。
6.2 哨兵
6.2.1 介绍
哨兵 Redis Sentinel,其实就是用于解决主从复制存在的问题。
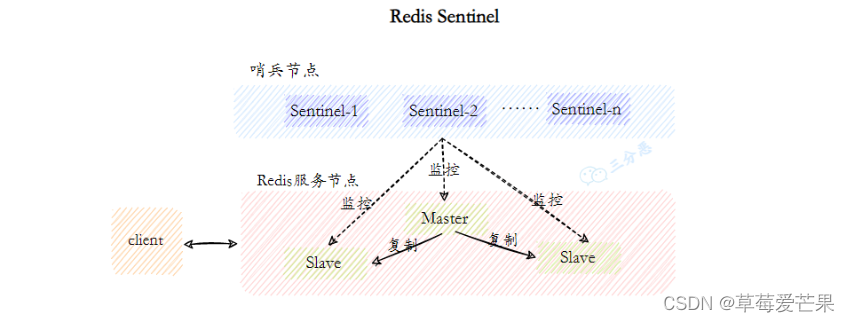
Redis Sentinel ,它由两部分组成,哨兵节点和数据节点:
- 哨兵节点: 哨兵系统由一个或多个哨兵节点组成,哨兵节点是特殊的 Redis 节点,不存储数据,对数据节点进行监控。
- 数据节点: 主节点和从节点都是数据节点;
在复制的基础上,哨兵实现了 自动化的故障恢复 功能,下面是官方对于哨兵功能的描述:
- 监控(Monitoring): 哨兵会不断地检查主节点和从节点是否运作正常。
- 自动故障转移(Automatic failover): 当 主节点 不能正常工作时,哨兵会开始 自动故障转移操作,它会将失效主节点的其中一个 从节点升级为新的主节点,并让其他从节点改为复制新的主节点。
- 配置提供者(Configuration provider): 客户端在初始化时,通过连接哨兵来获得当前 Redis 服务的主节点地址。
- 通知(Notification): 哨兵可以将故障转移的结果发送给客户端。
其中,监控和自动故障转移功能,使得哨兵可以及时发现主节点故障并完成转移。而配置提供者和通知功能,则需要在与客户端的交互中才能体现。
6.2.2 原理
哨兵模式是通过哨兵节点完成对数据节点的监控、下线、故障转移。
Redis Sentinel通过三个定时监控任务完成对各个节点发现和监控:
-
每隔10秒,每个Sentinel节点会向主节点和从节点发送info命令获取最新的拓扑结构
-
每隔2秒,每个Sentinel节点会向Redis数据节点的__sentinel__:hello 频道上发送该Sentinel节点对于主节点的判断以及当前Sentinel节点的信息
-
每隔1秒,每个Sentinel节点会向主节点、从节点、其余Sentinel节点发送一条ping命令做一次心跳检测,来确认这些节点当前是否可达
6.2.1 主观下线和客观下线
主观下线就是哨兵节点认为某个节点有问题,客观下线就是超过一定数量的哨兵节点认为主节点有问题。
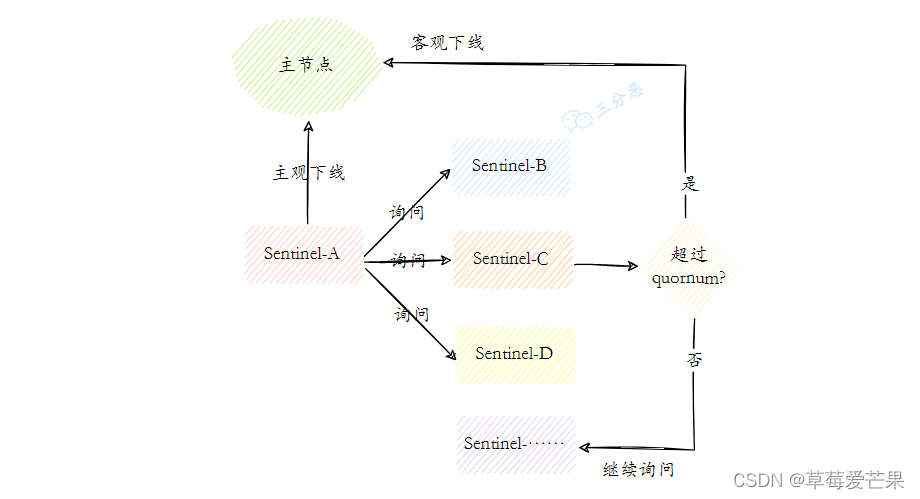
-
主观下线 每个Sentinel节点会每隔1秒对主节点、从节点、其他Sentinel节点发送ping命令做心跳检测,当这些节点超过 down-after-milliseconds没有进行有效回复,Sentinel节点就会对该节点做失败判定,这个行为叫做主观下线。
-
客观下线 当Sentinel主观下线的节点是主节点时,该Sentinel节点会通过sentinel is- master-down-by-addr命令向其他Sentinel节点询问对主节点的判断,当超过 个数,Sentinel节点认为主节点确实有问题,这时该Sentinel节点会做出客观下线的决定
6.2.2 领导者Sentinel节点选举
Sentinel节点之间会做一个领导者选举的工作,选出一个Sentinel节点作为领导者进行故障转移的工作。Redis使用了Raft算法实现领导者选举。
6.2.2.1 Raft 算法
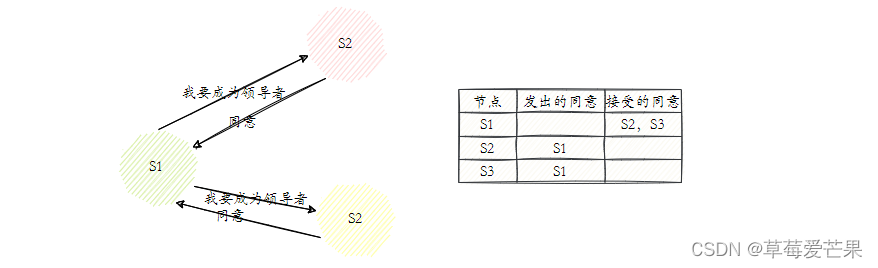
- 每个在线的Sentinel节点都有资格成为领导者,当它确认主节点主观 下线时候,会向其他Sentinel节点发送sentinel is-master-down-by-addr命令, 要求将自己设置为领导者。
- 收到命令的Sentinel节点,如果没有同意过其他Sentinel节点的sentinel is-master-down-by-addr命令,将同意该请求,否则拒绝。
- 如果该Sentinel节点发现自己的票数已经大于等于max(quorum, num(sentinels)/2+1),那么它将成为领导者。
- 如果此过程没有选举出领导者,将进入下一次选举。
6.2.3 故障转移
领导者Sentinel进行故障转移,
- 在从节点列表中选出一个节点作为新的主节点,这一步是相对复杂一些的一步
- Sentinel领导者节点会对第一步选出来的从节点执行slaveof no one命令让其成为主节点
- Sentinel领导者节点会向剩余的从节点发送命令,让它们成为新主节点的从节点
- Sentinel节点集合会将原来的主节点更新为从节点,并保持着对其关注,当其恢复后命令它去复制新的主节点
主节点选择
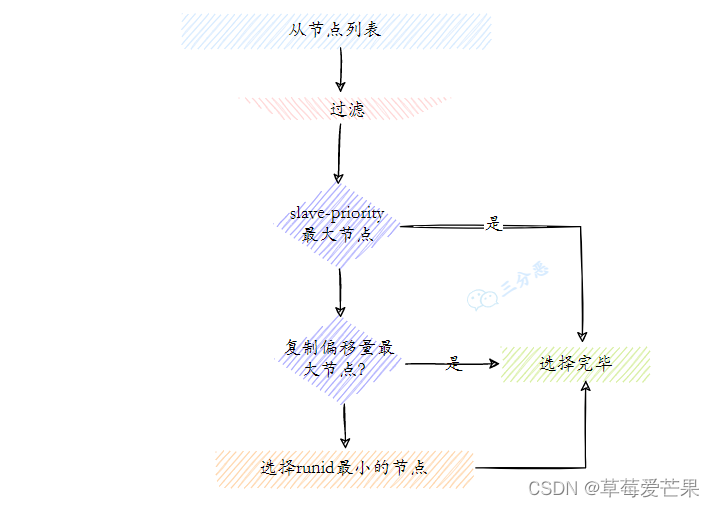
- 过滤:“不健康”(主观下线、断线)、5秒内没有回复过Sentinel节 点ping响应、与主节点失联超过down-after-milliseconds*10秒。
- 选择slave-priority(从节点优先级)最高的从节点列表,如果存在则返回,不存在则继续。
- 选择复制偏移量最大的从节点(复制的最完整),如果存在则返 回,不存在则继续。
- 选择runid最小的从节点。
6.3 集群
6.3.1 介绍
解决高可用和分布式问题
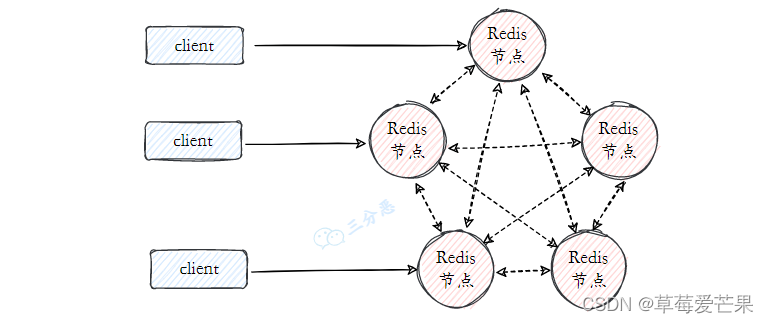
-
数据分区: 数据分区 (或称数据分片) 是集群最核心的功能。集群将数据分散到多个节点,一方面 突破了 Redis 单机内存大小的限制,存储容量大大增加;另一方面 每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力。
-
高可用: 集群支持主从复制和主节点的 自动故障转移 (与哨兵类似),当任一节点发生故障时,集群仍然可以对外提供服务。
6.3.2 数据分区
6.3.2.1 节点取余分区
对响应的hash值取余:hash(key)%N,来确定数据映射到哪一个节点上。当节点数量变化时,如扩容或收缩节点,数据节点映射关 系需要重新计算,会导致数据的重新迁移。
6.3.2.2 一致性哈希分区
将整个 Hash 值空间组织成一个虚拟的圆环,然后将缓存节点的 IP 地址或者主机名做 Hash 取值后,放置在这个圆环上。当我们需要确定某一个 Key 需 要存取到哪个节点上的时候,先对这个 Key 做同样的 Hash 取值,确定在环上的位置,然后按照顺时针方向在环上“行走”,遇到的第一个缓存节点就是要访问的节点。
比如说下面 这张图里面,Key 1 和 Key 2 会落入到 Node 1 中,Key 3、Key 4 会落入到 Node 2 中,Key 5 落入到 Node 3 中,Key 6 落入到 Node 4 中。
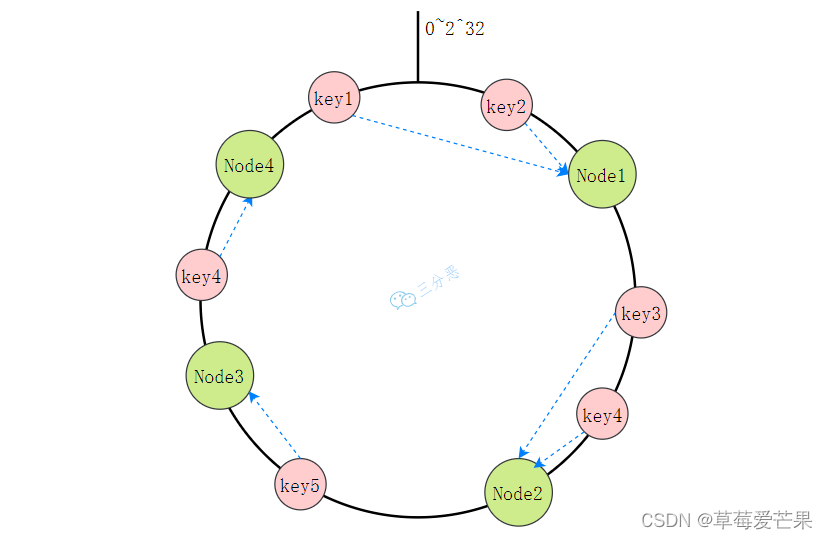
这种方式相比节点取余最大的好处在于加入和删除节点只影响哈希环中 相邻的节点,对其他节点无影响。
但它还是存在问题:
- 缓存节点在圆环上分布不平均,会造成部分缓存节点的压力较大
- 当某个节点故障时,这个节点所要承担的所有访问都会被顺移到另一个节点上,会对后面这个节点造成力。
6.3.2.3 虚拟槽分区
这个方案 一致性哈希分区的基础上,引入了 虚拟节点 的概念。Redis 集群使用的便是该方案,其中的虚拟节点称为 槽(slot)。槽是介于数据和实际节点之间的虚拟概念,每个实际节点包含一定数量的槽,每个槽包含哈希值在一定范围内的数据。
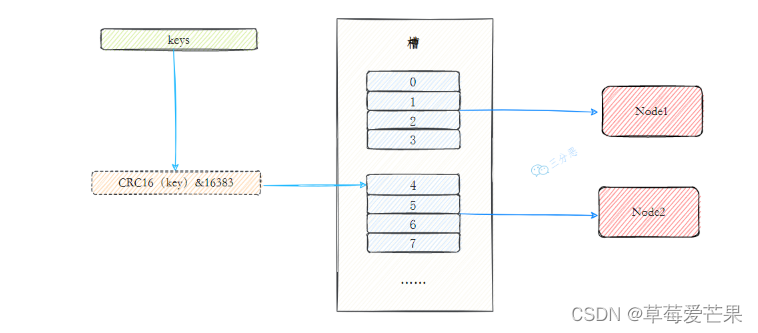
在使用了槽的一致性哈希分区中,槽是数据管理和迁移的基本单位。槽解耦了数据和实际节点之间的关系,增加或删除节点对系统的影响很小。仍以上图为例,系统中有 4 个实际节点,假设为其分配 16 个槽(0-15);
槽 0-3 位于 node1;4-7 位于 node2;以此类推…
如果此时删除 node2,只需要将槽 4-7 重新分配即可,例如槽 4-5 分配给 node1,槽 6 分配给 node3,槽 7 分配给 node4,数据在其他节点的分布仍然较为均衡。
7. Redis 集成
7.1 spring boot redis 配置
spring:
redis:
# Redis数据库索引(默认为0)
database: ''
# Redis服务器地址
host: 127.0.0.1
# Redis服务器连接端口
port: 6379
lettuce:
pool:
# 连接池最大连接数(使用负值表示没有限制)
max-active: 20
# 连接池最大阻塞等待时间(使用负值表示没有限制)
max-wait: -1
# 连接池中的最大空闲连接
max-idle: 10
# 连接池中的最小空闲连接
min-idle: ''
# 连接超时时间(毫秒)
timeout: 1000
7.2 gateway redis 配置
spring:
redis:
host: localhost
port: 6379
database: 0
8. 常见问题
8.1 RedisCommandExecutionException: WRONGTYPE Operation against a key holding the wrong kind of value
- 告诉你操作key错误了,那么你可能设置的key是String类型,你用hget获取hash的方式获取,就会出错
- 你的redis中已经存在一个key名为test,然后你又设置,名为test的key,且它两类型不一致。
8.2 ERR Client sent AUTH, but no password is set
-
配置文件中设置一个有效的密码
-
配置文件中,若没有密码就不要写,不允许下面这样,为空的书写
spring.redis.password:
# 9. Redis常见漏洞
## 9.1 未授权漏洞
### 9.1.1 漏洞描述
+ 攻击者无需认证访问到内部数据,可能导致敏感信息泄露,黑客也可以恶意执行flushall来清空所有数据
+ 攻击者可通过eval执行lua代码,或通过数据备份功能往磁盘写入后门文件
+ 如果redis以root身份运行,黑客可以给root账户写入SSH公钥文件,直接通过SSH登录目标服务器
### 9.1.2 漏洞修复方法
#### 9.1.2.1 云平台
可在安全组通过策略限制非必要IP访问端口
#### 9.1.2.2 虚拟机
+ 修改 redis.conf 文件在SECURITY这一项中,添加如下配置来禁用一些高危命令
```conf
# Redis危险命令重命名
rename-command FLUSHDB ""
rename-command FLUSHALL ""
rename-command CONFIG ""
rename-command EVAL ""
# Redis危险命令重命名 保留命令 通过重命名使得不会被轻易使用
rename-command FLUSHDB joYAPNXRPmcarcR4ZDgC81TbdkSmLAzRPmcarcR
rename-command FLUSHALL qf69aZbLAX3cf3ednHM3SOlbpH71yEXLAX3cf3e
...
-
redis.conf 中添加密码
requirepass xxxxxx -
绑定需要访问数据库的ip
bind 127.0.0.1 10.252.254.41 bind 127.0.0.1 # 绑定本机循环地址 即只能本机连接访问 bind 0.0.0.0 # 任意计算机可以访问 bind 10.252.254.41 # 10.252.254.41 为本机网卡,所以通过10.252.254.41来的redis请求都被允许 # bind 用于指定本机网卡对应的ip地址 不能绑定非本机网卡地址 protected-mode 改配置开启之后,只有本机才可以访问redis。 如果以下三个条件任何一个不满足,就不会开启保护机制 (1)protected-mode yes(处于开启) (2)没有bind指令 (3)没有设置密码 -
修改redis服务运行账号,以较低权限运行redis,且禁用该账号的登录权限
useradd -s /sbin/nologin redis cd /home/redis 略 -
保证 authorized_keys 文件的安全
为了保证安全,您应该阻止其他用户添加新的公钥。 将 authorized_keys 的权限设置为对拥有者只读,其他用户没有任何权限: $ chmod 400 ~/.ssh/authorized_key 为保证 authorized_keys 的权限不会被改掉,您还需要设置该文件的 immutable 位权限: # chattr +i ~/.ssh/authorized_keys 然而,用户还可以重命名 ~/.ssh,然后新建新的 ~/.ssh 目录和 authorized_keys 文件。要避免这种情况,需要设置 ~./ssh 的 immutable 位权限: # chattr +i ~/.ssh
10. 重点解答
10.1 Redis6.0使用多线程是怎么回事 ?
Redis6.0的多线程是用多线程来处理数据的读写和协议解析,但是Redis执行命令还是单线程的。
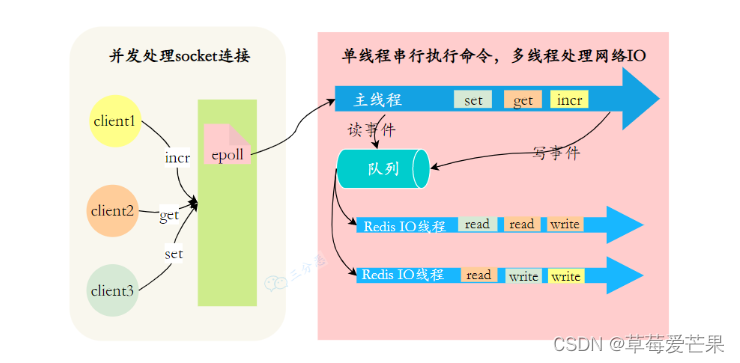
这样做的⽬的是因为Redis的性能瓶颈在于⽹络IO⽽⾮CPU,使⽤多线程能提升IO读写的效率,从⽽整体提⾼Redis的性能。
10.2 RDB和AOF如何选择?
根据业务场景进行选择
- 数据只在服务运行时存在,不需要进行持久化
- 实时性要求不高,允许丢失几分钟数据的,rdb即可
- 实时性高的使用aof,rdb结合,rdb恢复数据快,便于存储,有效避免aof的bug,aof数据比较完善,实时性高,重启时默认使用aof来进行恢复。
10.3 Redis 4.0 的混合持久化
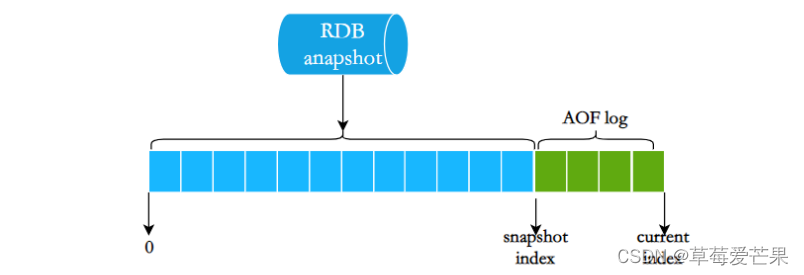
Redis 4.0 为了解决AOF恢复慢的问题,带来了一个新的持久化选项——混合持久化。即将 rdb 文件的内容和增量的 AOF 日志文件存在一起。这里的 AOF 日志不再是全量的日志,而是 自持久化开始到持久化结束 的这段时间发生的增量 AOF 日志,通常这部分 AOF 日志很小:
11. 大佬文章资料
12. Redis 开发规范
1 、 Redis key命名风格
**【推荐】**Redis key命名需具有可读性以及可管理性,不该使用含义不清的key以及特别长的key名;
【强制】以英文字母开头,命名中只能出现小写字母、数字、英文点号(.)和英文半角冒号(😃;
【强制】不要包含特殊字符,如下划线、空格、换行、单双引号以及其他转义字符;
2 、命名规范
【强制】命名规范:业务模块名:业务逻辑含义:其他:value类型
1 )业务模块名:具体的功能模块
2)逻辑含义段:
【强制】不同业务逻辑含义使用英文半角冒号(:)分割,
**【强制】**同一业务逻辑含义段的单词之间使用英文半角点号 (.)分割,用来表示一个完整的语义
3)value类型:
**【强制】**Redis key命名以key所代表的value类型结尾,以提高可读性;
示例:user:basic.info:{userid}:string
3 、 value 设计
【强制】:拒绝bigkey(防止网卡流量、慢查询)。
String类型控制在10KB以内,Hash、List、Set、ZSet元素个数不要超过5000。
三、业务规范
1、【强制】使用Redis进行缓存时,必须进行申请。申请之前,需要拿出使用的合理方案,然后进行评估,避免随意使用。
2、【强制】Redis应用场景应该是**纯缓存服务,**功能主要是缓存数据,缓存数据可丢失,除特殊需求外,需提供可行性、可实施的方案。
3、【强制】 关于过期时间
Redis key一定要设置过期时间。要跟自己的业务场景,需要对key设置合理的过期时间。可以在写入key时,就要追加过期时间;也可以在需要写入另一个key时,删除上一个key。
说明:
(1)若不设置的话,这些key会一直占用内存不释放,随着时间的推移会越来越大,直到达到服务器的内存上限,导致服务器宕机等重大事故;
(2)对于key的超时时长设置,可根据业务场景进行评估,设置合理有效期;
(3)某些业务的确需要长期有效,可以判断即将到期时,重新设置有效期,避免引起热点key问题。
4、【推荐】Redis的使用,应该考虑冷热数据分离,不该将所有数据全部放到Redis中,对于使用不频繁,且无关紧要的信息存入MySQL,或日志文件中,Redis的数据存储全部都是在内存中的,成本昂贵。
5、【推荐】Redis有数据丢失风险,程序处理数据时,应该考虑丢失后的重新加载过程。
6、【强制】禁止大key
大key数据存⼊Redis,除了带来极大的内存占用外,在并发高时,很容易就会将网卡流量占满,进而造成整个服务器上的所有服务不可用。虽然Redis支持512MB大小的string,但是假设1mb的string大key,每秒重复写入10次,就会导致写入网络IO达10MB;
(1)读写大key会导致超时严重,网卡流量占满,甚至阻塞服务,更甚者导致宕机风险。
(2)如果删除大key,DEL命令可能阻塞Redis进程数十秒,使得其他请求阻塞,对应用程序和Redis集群可用性造成严重的影响。
(3)每个key不要超过10Kb。
7、【强制】Redis一定不可使用Keys正则匹配操作。
8、【推荐】选择合适的数据类型。
目前Redis支持的数据库结构类型较多:字符串(String),哈希(Hash),列表(List),集合(Set),有序集合(Sorted Set), Bitmap, HyperLogLog和地理空间索引(geospatial)等,需要根据业务场景选择合适的类型。
在不能确定其它复杂数据结构⼀定优于String类型时,避免使用Redis的复杂数据结构。 每种数据结构都有相应的使⽤场景,String类型是Redis中最简单的数据类型,建议使用String类型。 但是考虑到具体的业务场景,综合评估性能、存储网络等方面之后使用适当的数据结构。 需要根据业务场景选择合适的类型,常见的如:String可以用作普通的K-V、简单数据类类型等;Hash可以用作对象如居民、医生等,包含较多属性的信息;List可以用作息队列、医生同行/关注列表等;Set可以用于推荐;Sorted Set可以用于排行等。
9、【推荐】关于集合类操作
出现问题最多的就是超时问题,因为使用了O(N)的操作,导致服务超时,甚至服务不可用。
使用Set,Zset,List,Hash等集合类的O(N)操作时要评估当前元素个数的规模以及将来的增长规模,对于短期就可能变为大集合的key,要预估O(N)操作的元素数量,避免全量操作,可以使用HSCAN,SSCAN,ZSCAN进行渐进操作。集合元素数量过大在使用过程中会影响Redis的实际性能,Hash类元素个数建议尽量不要超过100,集合类、链表类数据尽量不要超过10k。元素数量过大可考虑拆分成多个key进行处理















 892
892











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









