







 该博客内容讲述了作者对古典文化感兴趣,特别是甲骨文,因此进行了相关网站的爬虫编写,目的是爬取并保存甲骨文的图片以及其对应的中文含义。爬虫代码实现了从指定网页抓取图片,并将其存储到本地文件夹中。提供的链接提供了所有爬取结果的打包下载地址。
该博客内容讲述了作者对古典文化感兴趣,特别是甲骨文,因此进行了相关网站的爬虫编写,目的是爬取并保存甲骨文的图片以及其对应的中文含义。爬虫代码实现了从指定网页抓取图片,并将其存储到本地文件夹中。提供的链接提供了所有爬取结果的打包下载地址。
由于对古典文化较感兴趣,因此爬取甲骨文图片,及其对应的中文含义,因为网页是分目录的,因此分目录爬取。
数据来源网址:
http://www.9610.com/jiagu/bian/index.htm,
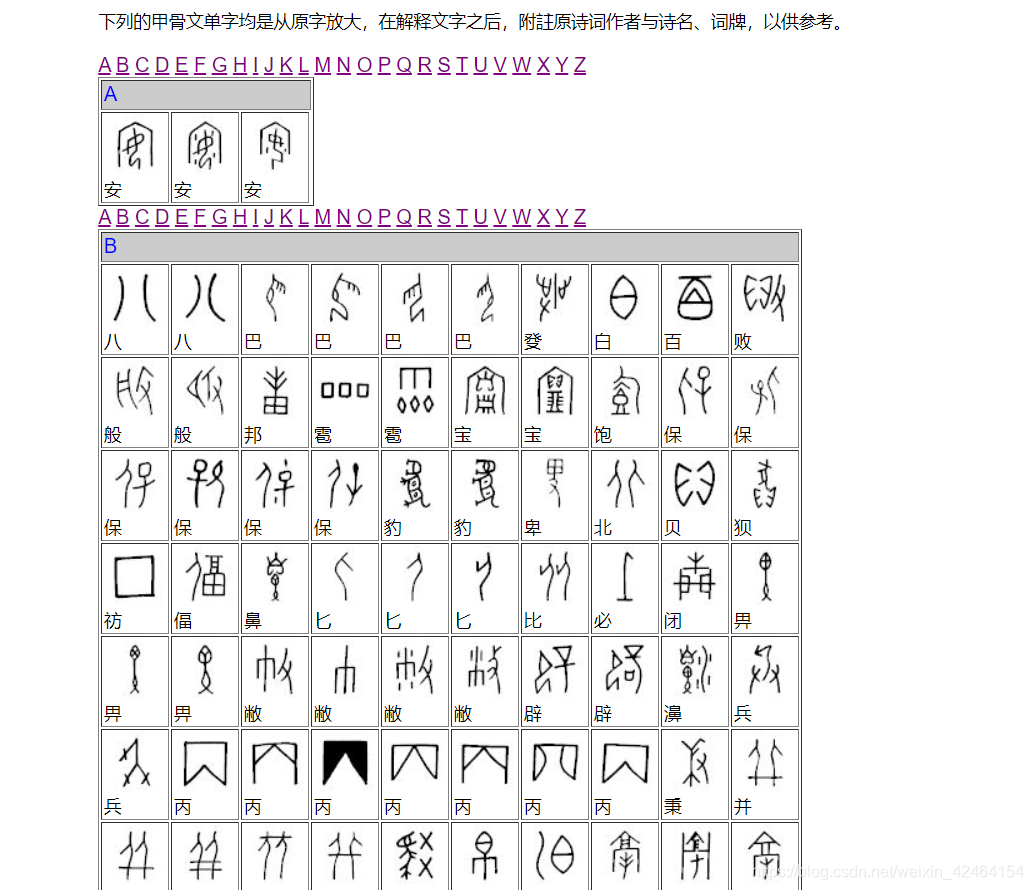
爬取所用代码:
import urllib.request
import re
import os
import urllib
def get_html(url):
page = urllib.request.urlopen(url)
html_a = page.read()
print(html_a.decode('gbk'))
return html_a.decode('gbk')
def get_img(html):
reg = r'\b\d+\b.jpg'
reg1=r'<IMG[^>]*>(.*)</TD>'
imgre = re.compile(reg) # 转换成一个正则对象
imglist = imgre.findall(html) # 表示在整个网页过滤出所有图片的地址,放在imgList中
imgre1 = re.compile(reg1) # 转换成一个正则对象
imglist1 = imgre1.findall(html) # 表示在整个网页过滤出所有图片的地址,放在imgList中
print(imglist)
print(imglist1)
x = 0 # 声明一个变量赋值
path = 'E:\\lianxi\\mypic\\y_z' # 设置图片的保存地址
if not os.path.isdir(path):
os.makedirs(path) # 判断没有此路径则创建
paths = path + '\\' # 保存在test路径下
for imgurl in imglist:
urllib.request.urlretrieve("http://www.9610.com/jiagu/bian/"+imgurl, '{0}{1}.jpg'.format(paths, str(x)+imglist1[x])) # 打开imgList,下载图片到本地
x = x + 1
print('图片开始下载,注意查看文件夹')
return imglist
html_b = get_html("http://www.9610.com/jiagu/bian/yz.htm#y") # 获取该网页的详细信息
print(get_img(html_b)) # 从网页源代码中分析下载保存图片
爬取结果如下:
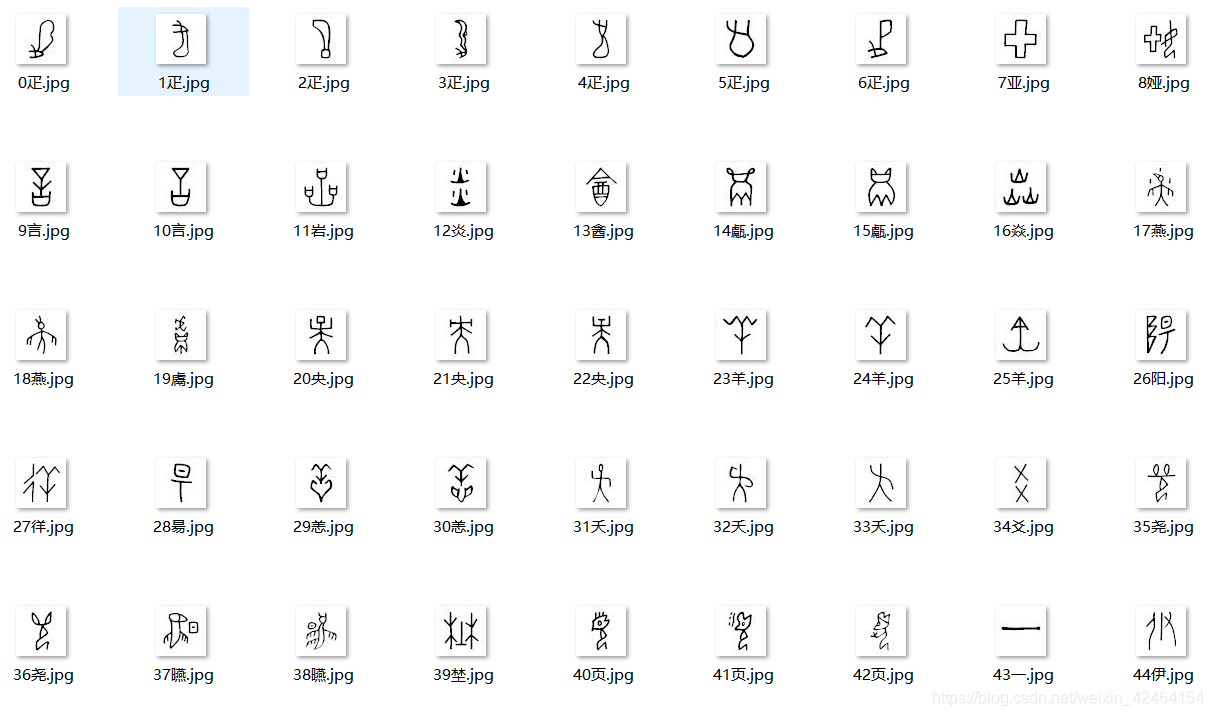
所有结果打包下载地址:
链接:https://pan.baidu.com/s/1IZR9tKkESY6vNbEzrbHRRQ
提取码:1tj9
欢迎下载使用,可在自建网站中作为素材使用…


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









