






二叉排序树(BST)
二叉排序树也称二叉查找树,可以是一棵空树,也可能是具有下列特性的二叉树。
(1)若左子树非空,则左子树上所有结点的值均小于根结点的值
(2)若右子树非空,则右子树上所有结点的值均大于根结点的值
(3)左右子树也分别是一棵二叉排序树。
左子树结点值 < 根结点值 < 右子树结点值
所以对二叉排序树进行中序遍历,可以得到一个递增的有序序列。
typedef struct BSTNode{ ElemType data; struct BSTNode *lchild,*rchild; }BSTNode, *BSTree;二叉排序树的查找
若树非空,目标值与根结点的值比较:
若相等,则查找成功;
若小于根结点,则在左子树上查找,否则在右子树上查找。
查找成功返回结点指针;查找失败返回NULL。
二叉排序树的插入
若原二叉排序树为空,则直接插入结点;否则,若关键字k小于根结点值,则插入到左子树,若关键字k大于根结点值,则插入到右子树。
注:新插入的结点一定是叶子结点!
二叉排序树的构造
注:不同的关键字序列可能得到同样的二叉排序树,也可能得到不同的二叉排序树!!
二叉排序树的删除(考点)
先搜索找到目标结点:
①若被删除的结点是叶子结点,则直接删除,不会破坏二叉排序树的性质。
②若被删除的结点只有一棵子树,则让结点的子树称为结点父结点的子树(即替代被删除结点的位置)即可,也不会破坏二叉排序树的性质。
③若被删除的结点有左右两颗子树,则可令该结点的直接后继或直接前驱替代该结点。然后从二叉排序树中删去这个直接后继或直接前驱,这样就可以转换成①或②
直接后继:右子树中值最小的结点,其实就是找到右子树中序遍历的第一个结点。(最左下结点)
直接前驱:左子树中值最大的结点,其实就是找到左子树中序遍历的最后一个结点。(最右下结点)
注:
二叉排序树BST在删除叶子结点后再插入该结点,前后树相同。
删除非叶子结点后再插入该结点,前后树不同。
二叉排序树的查找效率分析(考点)
查找长度——在查找运算中,需要对比关键字的次数。反映列查找操作时间复杂度。
注:结点的查找长度 = 结点的深度(从1开始)。
平均查找长度ASL(Average Search Length)
注意:平均查找长度ASL分为查找成功和失败,查找成功需要计算所有结点的SL,失败则只需要计算失败位置的结点SL,不用计算已知结点的SL。
查找成功时:
ASL = (∑SL)/n
查找失败时:
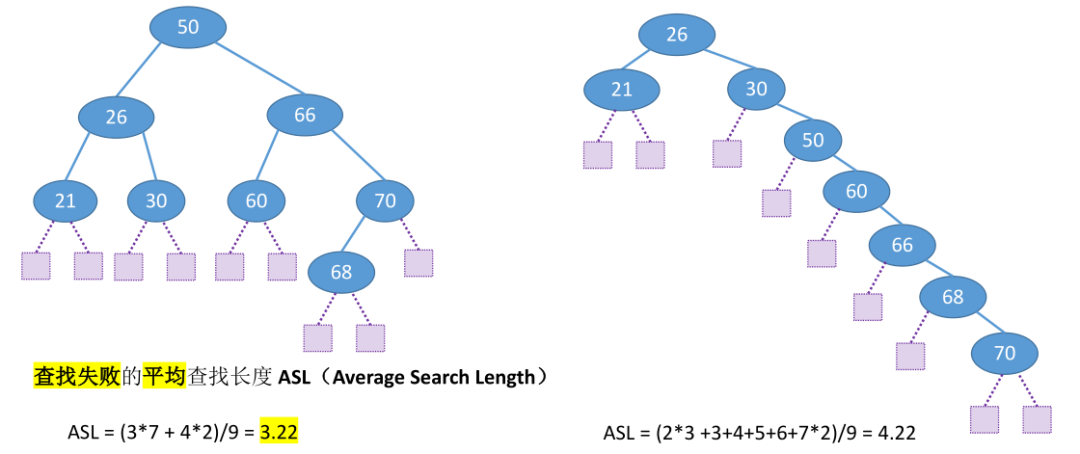
由上可知:二叉查找树的效率很大程度上取决于树的高度。因此构造一棵高度尽可能低的排序二叉树会使得查找效率尽可能高。查找效率最好和最坏情况如下

注:log2n向下取整+1 = log2(n+1)向上取整。
二叉排序树查找序列
根据二叉排序树左子树结点值 < 根结点值 < 右子树结点值的性质。可以总结出二叉排序树的查找序列应满足的规律。
小增,右走,且后面的不能更小。
如果当前的关键字比下一个关键字小,即序列关键字值增大,则对应二叉树的遍历往右子树走,右子树应该满足所有的关键字值都大于当前关键字。因此序列后面的不能比当前关键字更小。
大减,左走,且后面的不能更大。
如果当前的关键字比下一个关键字大,即序列关键字值减小,则对应二叉树的遍历往左子树走,左子树应该满足所有的关键字值都小于当前关键字。因此序列后面的不能比当前关键字更大。
只用看序列是否满足上面两个规律就可以判断出序列是否能充当二叉排序树的查找序列。
平衡二叉树AVL
为避免树的高度增长过快,降低二叉排序树的性能,规定在插入和删除二叉树结点时,要保证任意结点的左右子树的高度之差不超过1。这样的二叉树称为平衡二叉树,也叫AVL树。
结点的平衡因子 = 左子树高度 - 右子树高度。(-1,0,1)
注:
AVL树在插入和删除结点后都有可能导致树的形态改变。
在删除某个结点(无论是叶子结点还是非叶子结点)后再重新插入该结点得到的新树与原树不一定相同。
平衡二叉树的插入
主要问题是,在二叉排序树中插入新结点,如何使树依旧保持平衡。
在插入操作中,只要将最小不平衡子树调整平衡,则其他祖先结点都会恢复平衡。
那么如何调整最小不平衡子树呢?
LL平衡旋转(右单旋转)
问题:在A的左孩子的左子树中插入新结点,A的平衡因子由1增至2。导致以A为根的子树失去平衡。
目标:恢复平衡并且保持二叉排序树的特性。
BL < B < BR
解决办法:需要一次向右的旋转操作。将A的左孩子B向右上旋转代替A成为根结点,将A结点向右下旋转成为B的右子树的根结点,而B的原右子树则作为A结点的左子树。
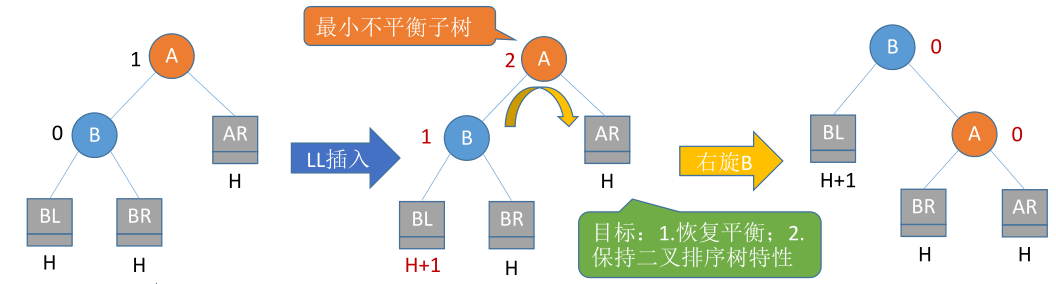
总结:LL
儿子变爸爸(S->F)
儿子的左儿子不变,右儿子变为爸爸的左儿子(SR->FL)
爸爸的右儿子不变
RR平衡旋转(左单旋转)
问题:在A的右孩子的右子树上插入了新结点,A的平衡因子由-1减至-2,导致以A为根的子树失去平衡。
目标:恢复平衡并且保持二叉排序树的特性。
AL < A < BL < B < BR
解决方法:需要一次向左的旋转操作。将A的右孩子B向左上旋转代替A成为根结点,将A结点左右下旋转成为B的左子树的根结点,而B的原左子树则作为A结点的右子树。
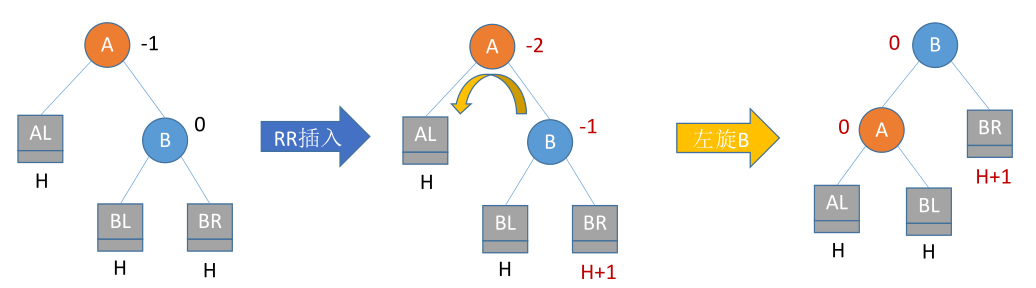
总结:RR
儿子变爸爸
儿子的右儿子不动,左儿子变为爸爸的右儿子(SL->FR)
爸爸的左儿子不动
LR平衡旋转(先左后右双旋转)
由于在A的左孩子的右子树上插入新结点,A的平衡因子由1增至2,导致以A为根的子树失去平衡。
解决方法:进行两次旋转操作,先将A结点的左孩子B的右子树的根结点C向左上旋转提升到B结点的位置,然后再把该C结点向右上旋转提升到A结点的位置。

总结:LR
孙子变爷爷(S->G)
爸爸变为左儿子(F->SL),爷爷变为右儿子(G->SR)
孙子的左儿子变为爸爸的右儿子(SL->FR)
孙子的右儿子变为爷爷的左儿子(SR->GL)
RL平衡旋转(先右后左双旋转)
由于在A的右孩子的左子树上插入新结点,A的平衡因子由-1减至-2,导致以A为根的子树失去平衡。
解决方法:进行两次旋转操作,先将A结点的右孩子B的左子树的根结点C向右上旋转提升到B结点的位置,然后再把该C结点向左上旋转提升到A结点的位置。
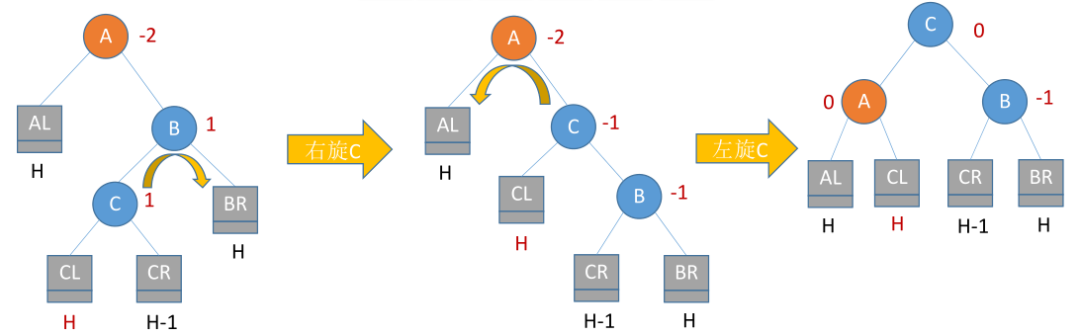
总结:RL
孙子变爷爷(S->G)
爸爸变为右儿子(F->SR),爷爷变为左儿子(G->SL)
孙子的右儿子变为爸爸的左儿子(SR->FL)
孙子的左儿子变为爷爷的右儿子(SL->GR)
平衡二叉树的查找效率

哈夫曼树和哈夫曼编码
结点的权:有某种显示含义的数值
结点的带权路径长度:从树的根到该结点的路径长度(经过的边数)与该结点上权值的乘积。
树的带权路径长度:树中所有叶子结点的带权路径长度之和(WPL,Weight Path Length)。
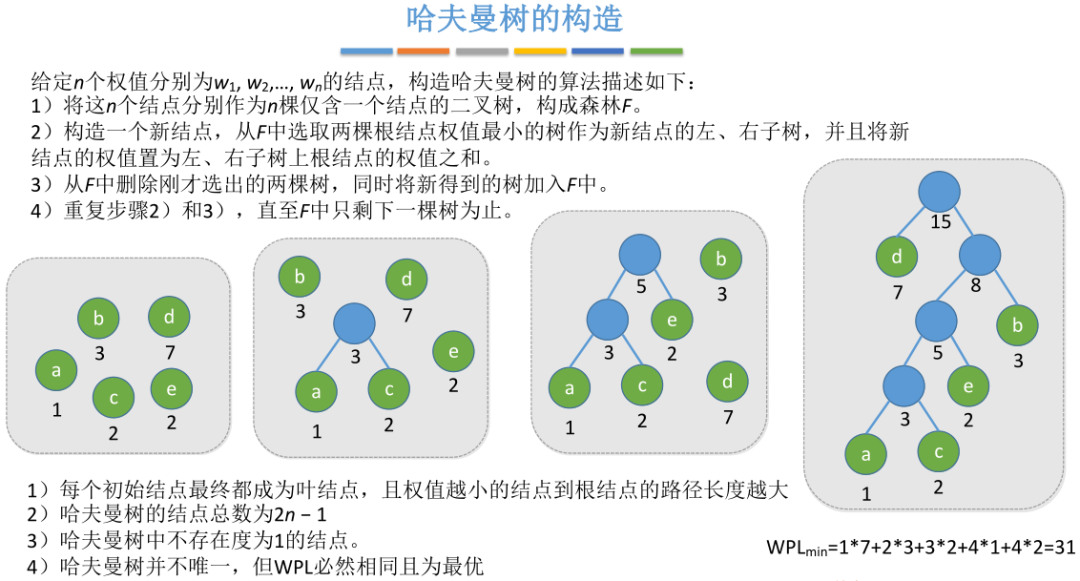
哈夫曼树

构造哈夫曼树
n个结点,两两结合,每次结合都会出现一个新的非叶子结点,所以会多出n-1个结点,进而哈夫曼树共有2n-1个结点,其中n个叶子结点,n-1个非叶子结点。
哈夫曼编码
由哈夫曼树得到哈夫曼编码——字符集中的每个字符作为一个叶子结点,各个字符出现的频数作为结点的权值。
哈夫曼编码可用于数据的压缩。
前缀编码:没有一个编码是另一个编码的前缀。
注:固定长度编码也有可能是前缀编码。如{00,01,10,11}这就满足没有一个编码是另一个编码的前缀。
固定长度编码:每个字符用相等长度的二进制位表示,如ASCII编码。
可变长度编码:允许对不同字符用不等长的二进制位表示。
哈夫曼树的应用
利用哈夫曼树的带权路径长度最小的特性
分析:带权路径长度的本质,














 359
359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









