







一、java基础
字符串常量Java内部加载-上
代码:
public class StringPoolDemo {
public static void main(String[] args) {
String str1 = new StringBuffer("mei").append("tuan").toString();
System.out.println(str1);
System.out.println(str1.intern());
System.out.println(str1 == str1.intern());
System.out.println("-------------");
String str2 = new StringBuffer("ja").append("va").toString();
System.out.println(str2);
System.out.println(str2.intern());
System.out.println(str2 == str2.intern());
}
}
运行:
meituan
meituan
true
-------------
java
java
false
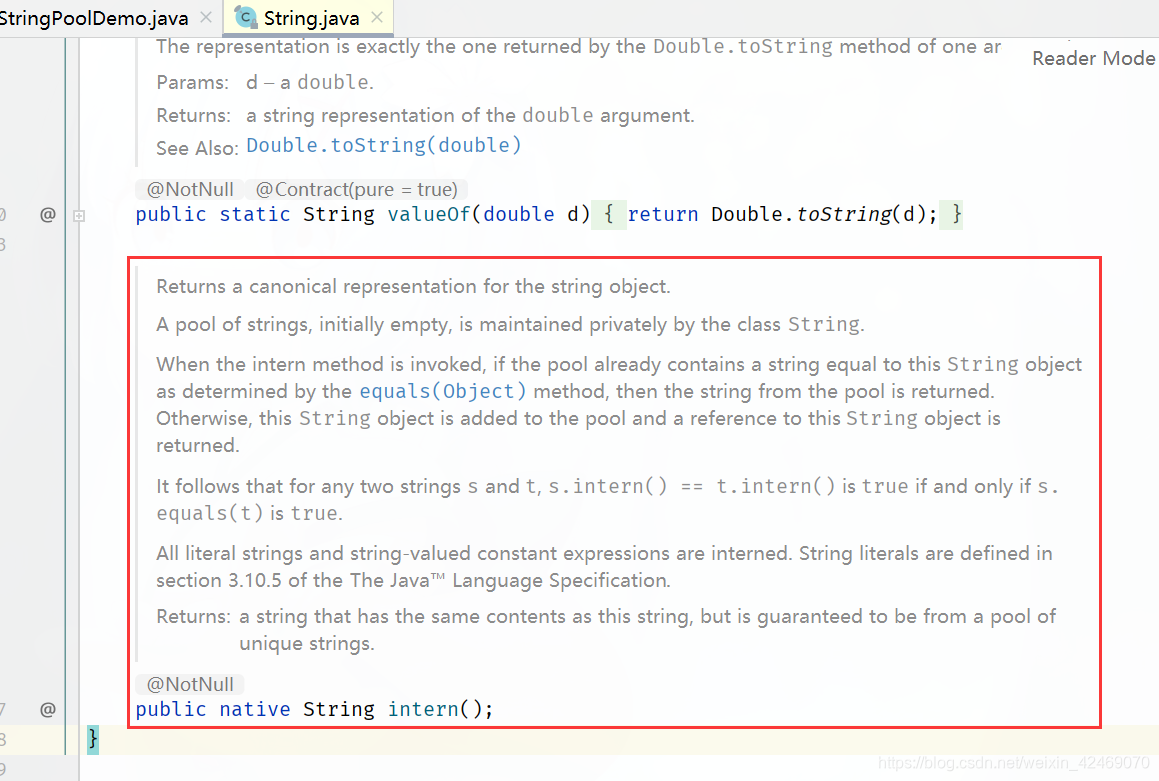
Stirng类intern()方法:
Returns a canonical representation for the string object.
A pool of strings, initially empty, is maintained privately by the class String.
When the intern method is invoked, if the pool already contains a string equal to this String object as determined by the equals(Object) method, then the string from the pool is returned. Otherwise, this String object is added to the pool and a reference to this String object is returned.
It follows that for any two strings s and t, s.intern() == t.intern() is true if and only if s.equals(t) is true.
All literal strings and string-valued constant expressions are interned. String literals are defined in section 3.10.5 of the The Java™ Language Specification.
Returns:
a string that has the same contents as this string, but is guaranteed to be from a pool of unique strings.
直接翻译:

方法区和运行时常量池溢出
由于运行时常量池是方法区的一部分,所以这两个区域的溢出测试可以放到一起进行。HotSpot从JDK 7开始逐步“去永久代”的计划,并在JDK8中完全使用元空间来代替永久代的背景故事,在此我们就以测试代码来观察一下,使用 “永久代” 还是 “元空间" 来实现方法区,对程序有什么实际的影响。
String:intern()是一个本地方法,它的作用是如果字符串常量池中已经包含一个等于此String对象的字符串,则返回代表池中这个字符串的String对象的引用;否则,会将此String对象包含的字符串添加到常量池中,并且返回此String对象的引用。在JDK 6或更早之前的HotSpot虚拟机中,常量池都是分配在永久代中,我们可以通过 -XX:PermSize 和 -XX:MaxPermSize 限制永久代的大小,即可间接限制其中常量池的容量。
字符串常量Java内部加载-下
按照代码结果,Java字符串答案为false
必然是两个不同的java,那另外一个java字符串如何加载进来的?
为什么?
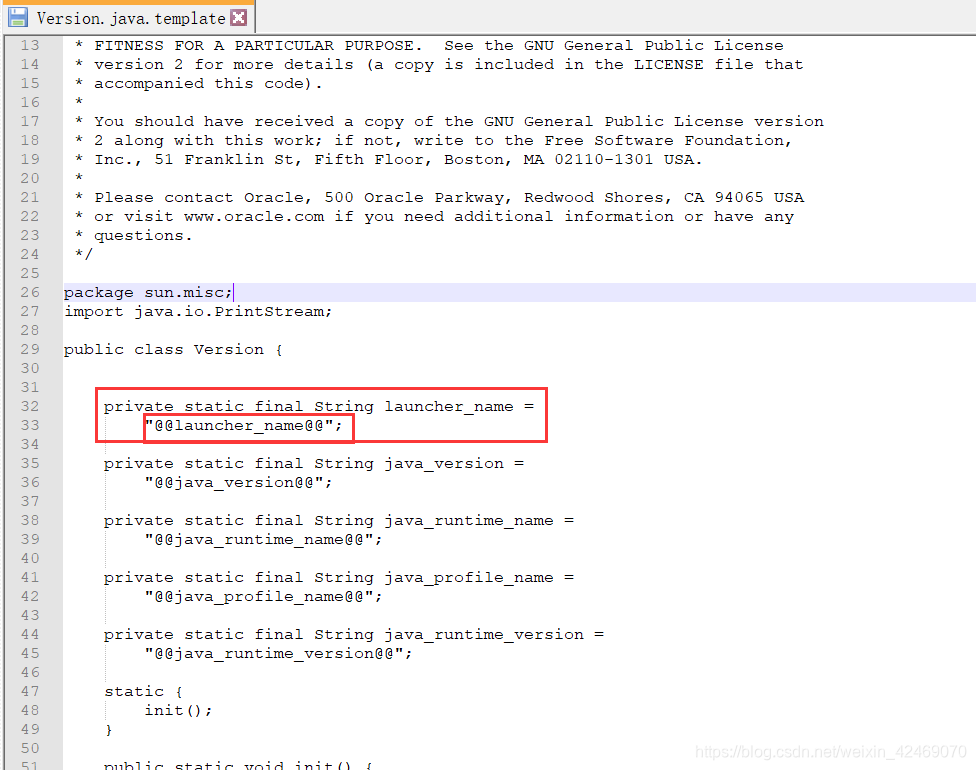
有一个初始化的Java字符串(JDK出娘胎自带的),在加载sun.misc.Version这个类的时候进入常量池
OpenJDK8底层源码说明
递推步骤:
System代码解析
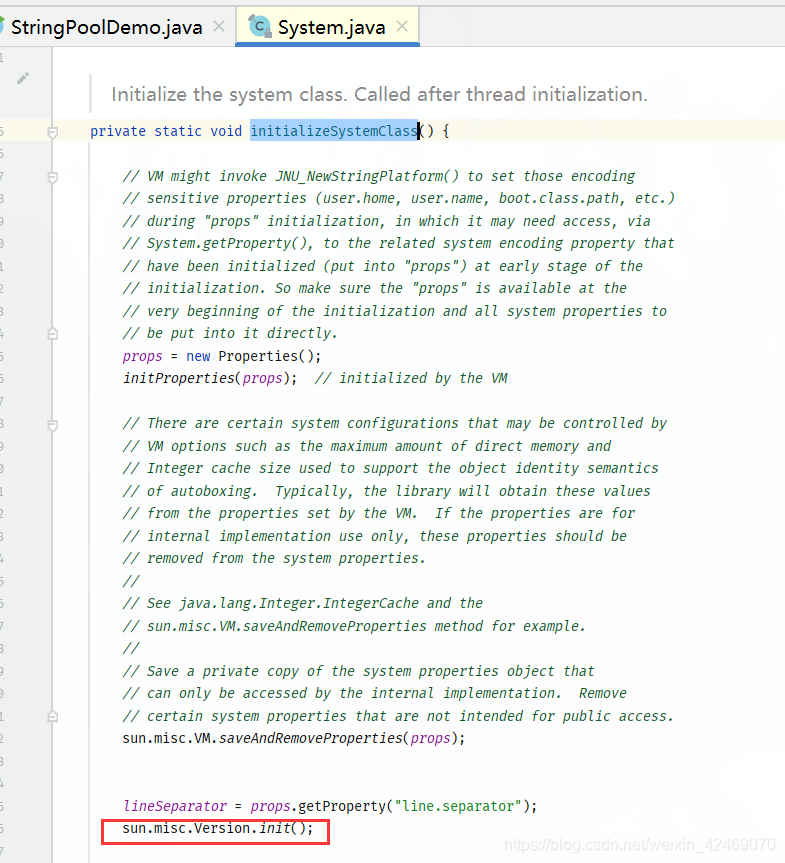
System-->initializeSystemClass-->Version
System类
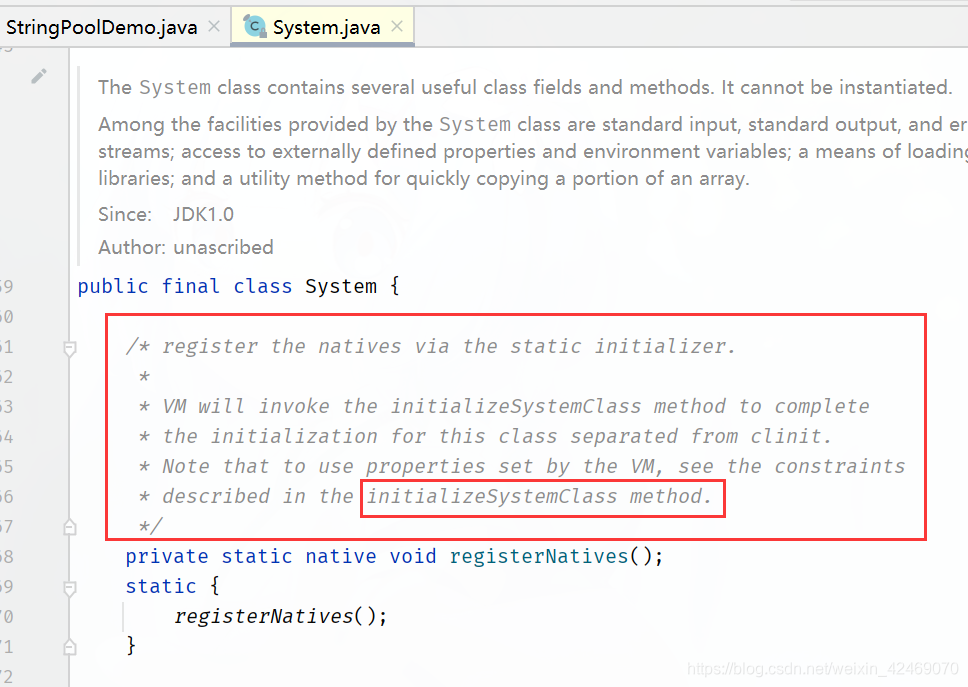

initializeSystemClass方法
Version类
-
类加载器和
rt.jar
根加载器提前部署加载rt.jar
-
OpenJDK8源码:
http://openjdk.java.net/
openjdk8\jdk\src\share\classes\sun\misc
-
考查点 -
intern()方法,判断true/false?- 《深入理解java虚拟机》书原题是否读过经典JVM书籍
《深入理解java虚拟机》 第3版 2.4.3章
解释
这段代码在JDK 6中运行,会得到两个false,而在JDK 7中运行,会得到一个true和一个false。产生差异的原因是,在JDK 6中,intern()方法会把首次遇到的字符串实例复制到永久代的字符串常量池中存储,返回的也是永久代里面这个字符串实例的引用,而由StringBuilder创建的字符串对象实例在Java堆上,所以必然不可能是同一个引用,结果将返回false。
而JDK 7(以及部分其他虚拟机,例如JRockit)的intern()方法实现就不需要再拷贝字符串的实例到永久代了,既然字符串常量池已经移到Java堆中,那只需要在常量池里记录一下首次出现的实例引用即可,因此intern()返回的引用和由StringBuilder创建的那个字符串实例就是同一个。而对str2比较返回false,这是因为“java”这个字符串在执行String-Builder.toString()之前就已经出现过了,字符串常量池中已经有它的引用,不符合intern()方法要求“首次遇到"”的原则,“计算机软件"这个字符串则是首次出现的,因此结果返回true。
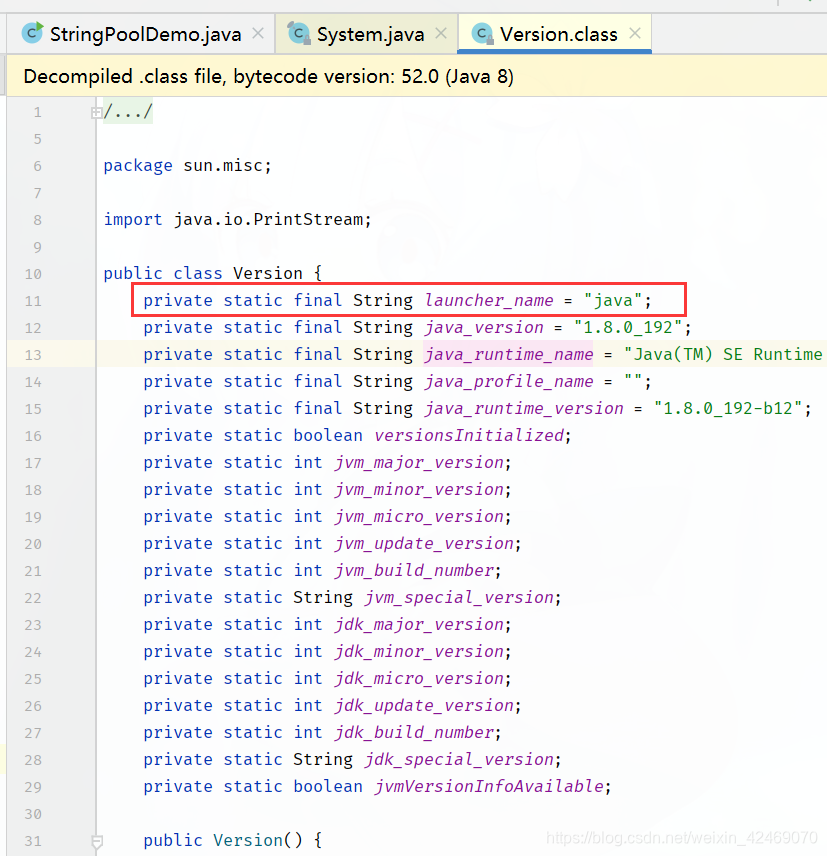
sun.misc.Version类会在JDK类库的初始化过程中被加载并初始化,而在初始化时它需要对静态常量字段根据指定的常量值(ConstantValue)做默认初始化,此时被 sun.misc.Version.launcher 静态常量字段所引用的"java"字符串字面量就被intern到HotSpot VM的字符串常量池——StringTable里了。
闲聊力扣算法第一题
字节跳动两数求和
1、 两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
来源:力扣(LeetCode)
TwoSum暴力解法
代码示例:
/**
* 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出和为目标值 的那两个整数,并返回它们的数组下标。
*
* 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
*
* 给定:nums = [2,7,11,15], target = 9
* 因为:nums[0] + nums[1] == 9
*
* 返回: [0,1]
*
*/
public class TwoSumDemo {
// 遍历 ---》暴力破解
public static int[] twoSum1(int[] nums, int target){
for (int i = 0; i < nums.length; i++) {
for (int j = i + 1; j < nums.length; j++) {
if(target - nums[i] == nums[j]){
return new int[]{i,j};
}
}
}
return null;
}
public static void main(String[] args) {
int[] nums = new int[]{2,7,11,15};
int target = 9;
int[] myIndex = twoSum1(nums,target);
for(int element : myIndex){
System.out.println(element);
}
}
}
运行:
0
1
通过双重循环遍历数组中所有元素的两两组合。当出现符合的值返回两个元素下标
TwoSum优化解法
代码示例:
/**
* 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出和为目标值 的那两个整数,并返回它们的数组下标。
*
* 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
*
* 给定:nums = [2,7,11,15], target = 9
* 因为:nums[0] + nums[1] == 9
*
* 返回: [0,1]
*
*/
public class TwoSumDemo {
// 哈希
public static int[] twoSum2(int[] nums, int target){
Map<Integer,Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
int partnerNumber = target - nums[i];
if(map.containsKey(partnerNumber)){
return new int[]{map.get(partnerNumber),i};
}
map.put(nums[i],i);
}
return null;
}
public static void main(String[] args) {
int[] nums = new int[]{2,7,11,15};
int target = 17;
int[] myIndex = twoSum2(nums,target);
for(int element : myIndex){
System.out.println(element);
}
}
}
运行:
0
3
使用HashMap的K、V键 , 性能更优
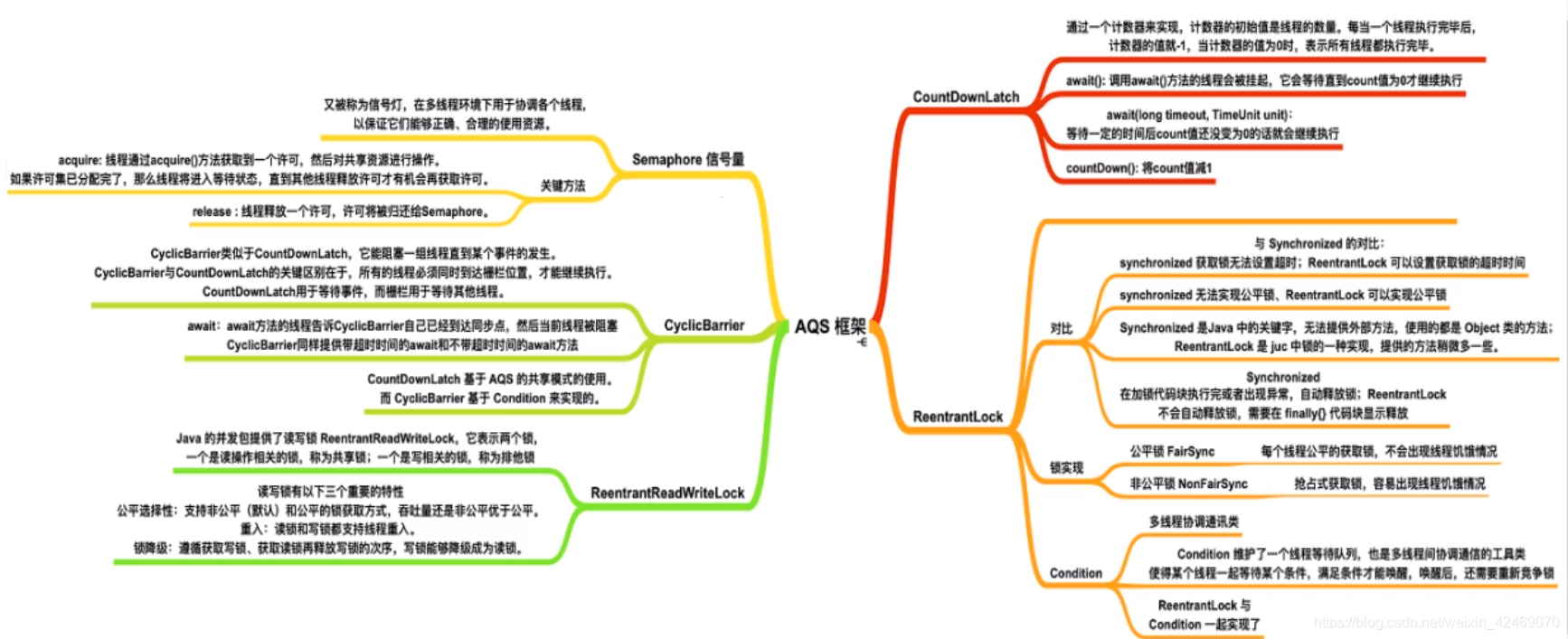
二、JUC
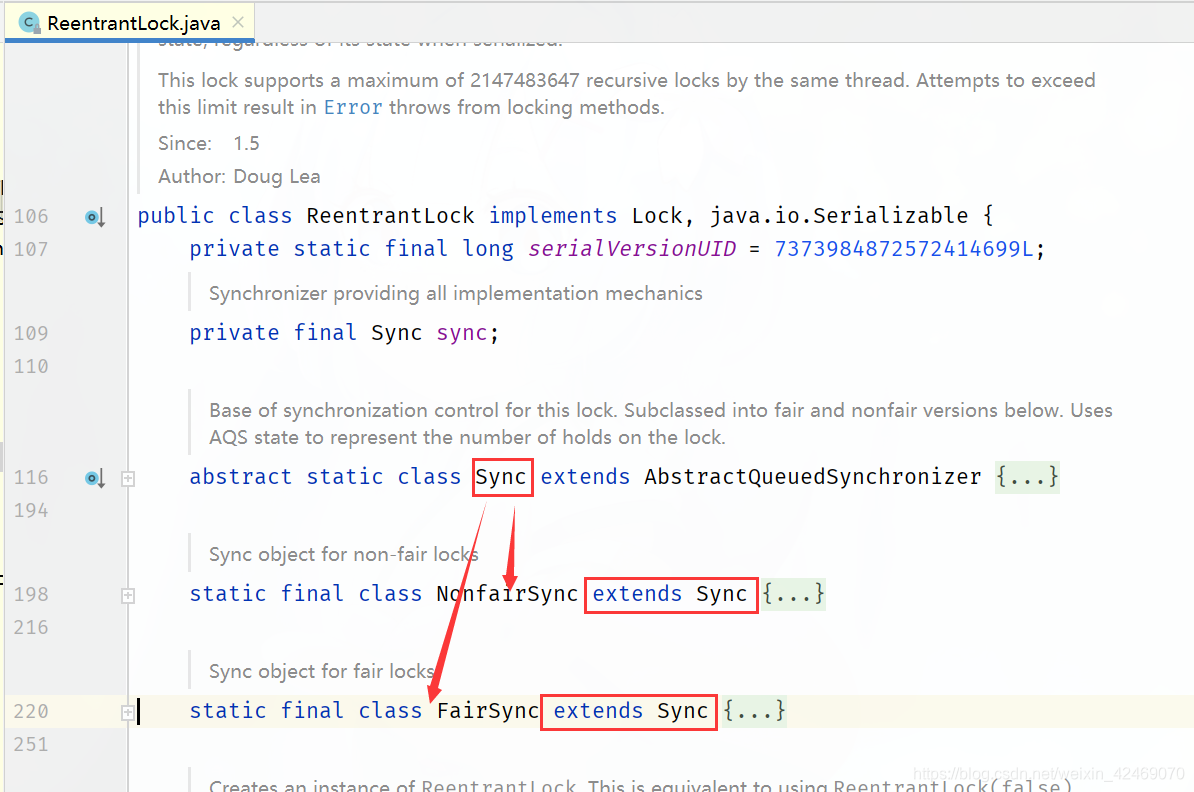
可重入锁理论
可重入锁(又名递归锁):
是指在同一个线程在外层方法获取锁的时候,再进入该线程的的内层方法会自动获取锁(前提,锁对象得是同一个对象),
不会因为之前已经获取过还没释放而阻塞。
Java中ReentrantLock和synchronized都是可重入锁,可重入锁的一个优点是可一定程度避免死锁
“可重入锁”这四个字分开来解释:
- 可:可以
- 重:再次
- 入:进入
- 锁:同步锁
进入什么?-- 进入同步域(即同步代码块 / 方法或显示锁锁定的代码)
一个线程中的多个流程可以获取同一把锁,持有这把同步锁可以再次进入。
自己可以获取自己的内部锁。
可重入锁的代码验证-上
可重入锁的种类:
-
隐式锁(即
synchronized关键字使用的锁)默认是可重入锁。(JVM层控制)
同步块
同步方法 -
Synchronized的重入的实现机理。
-
显式锁(即
Lock)也有ReentrantLock这样的可重入锁。(手动加锁/解锁)
隐式锁(synchronized)同步块代码演示:
/**
* 可重入锁:可重复可递归调用的锁,在外层使用锁之后,在内层仍然可以使用,并且不会发生死锁,这样的锁就叫做可重入锁
*
* 在一个synchronized修饰的方法或者代码块的内部
* 调用本类的其他synchronized修饰的方法或者代码块时,是永远可以得到锁的
*/
public class ReEnterLockDemo {
static Object objectLockA = new Object();
public static void m1(){
new Thread(()->{
synchronized (objectLockA){
System.out.println(Thread.currentThread().getName() + "\t" + "--------外层调用");
synchronized (objectLockA){
System.out.println(Thread.currentThread().getName() + "\t" + "--------中层调用");
synchronized (objectLockA){
System.out.println(Thread.currentThread().getName() + "\t" + "--------内层调用");
}
}
}
},"t1").start();
}
public static void main(String[] args) {
m1();
}
}
运行:
t1 --------外层调用
t1 --------中层调用
t1 --------内层调用
可重入锁的代码验证-下
- 隐式锁(即
synchronized关键字使用的锁)默认是可重入锁。
同步块
同步方法
隐式锁(synchronized)同步方法代码演示:
/**
* 可重入锁:可重复可递归调用的锁,在外层使用锁之后,在内层仍然可以使用,并且不会发生死锁,这样的锁就叫做可重入锁
*
* 在一个synchronized修饰的方法或者代码块的内部
* 调用本类的其他synchronized修饰的方法或者代码块时,是永远可以得到锁的
*/
public class ReEnterLockDemo {
public synchronized void m1(){
System.out.println("======外层 m1()");
m2();
}
public synchronized void m2(){
System.out.println("======中层 m2()");
m3();
}
public synchronized void m3(){
System.out.println("======内层 m3()");
}
public static void main(String[] args) {
new ReEnterLockDemo().m1();
}
}
运行:
======外层 m1()
======中层 m2()
======内层 m3()
-
Synchronized的重入的实现机理
每个锁对象拥有一个锁计数器和一个指向持有该锁的线程的指针。当执行
monitorenter时,如果目标锁对象的计数器为零,那么说明它没有被其他线程所持有,Java虚拟机会将该锁对象的持有线程设置为当前线程,并且将其计数器加1。在目标锁对象的计数器不为零的情况下,如果锁对象的持有线程是当前线程,那么Java虚拟机可以将其计数器加1,否则需要等待,直至持有线程释放该锁。
当执行
monitorexit时,Java虚拟机则需将锁对象的计数器减1。计数器为零代表锁已被释放。
- 显式锁(即
Lock)也有ReentrantLock这样的可重入锁。
显式锁(Lock)锁代码演示:
/**
* 可重入锁:可重复可递归调用的锁,在外层使用锁之后,在内层仍然可以使用,并且不会发生死锁,这样的锁就叫做可重入锁
*
* 在一个synchronized修饰的方法或者代码块的内部
* 调用本类的其他synchronized修饰的方法或者代码块时,是永远可以得到锁的
*/
public class ReEnterLockDemo {
static Lock lock = new ReentrantLock();
public static void main(String[] args) {
new Thread(()->{
lock.lock();
try
{
System.out.println("=====外层");
lock.lock();
try
{
System.out.println("=====内层");
}finally
{
// 这里故意注释,实现加锁次数和释放次数不一样
// 由于加锁次数和释放次数不一样,第二个线程始终无法获取到锁,导致一直等待
lock.unlock(); //正常情况,加锁几次就要释放几次
}
}finally
{
lock.unlock();
}
},"t1").start();
new Thread(()->{
lock.lock();
try
{
System.out.println(Thread.currentThread().getName() + "\t ---第二个线程调用");
}finally
{
lock.unlock();
}
},"t2").start();
}
}
运行:
=====外层
=====内层
t2 ---第二个线程调用
这里故意注释,实现加锁次数和释放次数不一样
由于加锁次数和释放次数不一样,第二个线程始终无法获取到锁,导致一直等待
结果:

LockSupport是什么
以java11API实例

LockSupport:用于创建锁和其他同步类的基本线程阻塞原语。

LockSupport是用来创建锁和其他同步类的基本线程阻塞原语。
LockSupport中的park()和 unpark()的作用分别是阻塞线程和解除阻塞线程。
LockSupport是线程等待唤醒机制(wait/notify)加强、改良版本,比synchronized(wait/notify)、Lock(await/signal)功能更强
waitNotify限制
线程等待唤醒机制(wait/notify)
3种让线程等待和唤醒的方法:
- 方式1:使用
Object中的wait()方法让线程等待,使用object中的notify()方法唤醒线程 - 方式2:使用JUC包中
Condition的await()方法让线程等待,使用signal()方法唤醒线程 - 方式3:
LockSupport类可以阻塞当前线程以及唤醒指定被阻塞的线程
Object类中的wait和notify方法实现线程等待和唤醒
代码演示:
public class LockSuppertDemo {
static Object objectLock = new Object();
public static void main(String[] args) {
new Thread(()->{
synchronized (objectLock){
System.out.println(Thread.currentThread().getName() + "\t ---come in");
try
{
objectLock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "\t ---被唤醒");
}
},"A").start();
new Thread(()->{
synchronized (objectLock){
objectLock.notify();
System.out.println(Thread.currentThread().getName() + "\t ---通知");
}
},"B").start();
}
}
运行:
A ---come in
B ---通知
A ---被唤醒
注释synchronized时候演示:
public class LockSuppertDemo {
static Object objectLock = new Object();
public static void main(String[] args) {
new Thread(()->{
// synchronized (objectLock){
System.out.println(Thread.currentThread().getName() + "\t ---come in");
try
{
objectLock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "\t ---被唤醒");
// }
},"A").start();
new Thread(()->{
// synchronized (objectLock){
objectLock.notify();
System.out.println(Thread.currentThread().getName() + "\t ---通知");
// }
},"B").start();
}
}
运行:
A ---come in
Exception in thread "B" Exception in thread "A" java.lang.IllegalMonitorStateException
at java.lang.Object.wait(Native Method)
at java.lang.Object.wait(Object.java:502)
at com.zzp.test.LockSuppertDemo.lambda$main$0(LockSuppertDemo.java:14)
at java.lang.Thread.run(Thread.java:748)
java.lang.IllegalMonitorStateException
at java.lang.Object.notify(Native Method)
at com.zzp.test.LockSuppertDemo.lambda$main$1(LockSuppertDemo.java:24)
at java.lang.Thread.run(Thread.java:748)
java.lang.IllegalMonitorStateException意思就是说用wait和notify的时候没有拥有这个监视器对象,使用Object类中的wait()和notify()方法实现线程等待和唤醒的时候,如果不在一个代码块里wait()和notify()是不可以使用的,必须要在同步代码块或者方法里面并且成对出现使用;如果notify()比wait()先执行,会导致程序在wait()阻塞,使程序无法执行下去,因为无法唤醒程序
awaitSignal限制
代码演示:
public class AwaitSignalDemo {
static Lock lock = new ReentrantLock();
static Condition condition = lock.newCondition();
public static void main(String[] args) {
new Thread(()->{
lock.lock();
try
{
System.out.println(Thread.currentThread().getName() + "\t ---come in");
try
{
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "\t ---被唤醒");
}finally
{
lock.unlock();
}
},"A").start();
new Thread(()->{
lock.lock();
try
{
condition.signal();
System.out.println(Thread.currentThread().getName() + "\t ---通知");
}finally
{
lock.unlock();
}
},"B").start();
}
}
运行:
A ---come in
B ---通知
A ---被唤醒
异常情况:故意注释 lock.lock(); 和 lock.unlock(); 必须成双成对注释掉
运行:
A ---come in
Exception in thread "A" Exception in thread "B" java.lang.IllegalMonitorStateException
at java.util.concurrent.locks.ReentrantLock$Sync.tryRelease(ReentrantLock.java:151)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.release(AbstractQueuedSynchronizer.java:1261)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.fullyRelease(AbstractQueuedSynchronizer.java:1723)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2036)
at com.zzp.test.AwaitSignalDemo.lambda$main$0(AwaitSignalDemo.java:21)
at java.lang.Thread.run(Thread.java:748)
java.lang.IllegalMonitorStateException
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.signal(AbstractQueuedSynchronizer.java:1939)
at com.zzp.test.AwaitSignalDemo.lambda$main$1(AwaitSignalDemo.java:36)
at java.lang.Thread.run(Thread.java:748)
使用Condition的await()比signal()必须配对 lock.lock()和 lock.unlock(),并且先有await()才有signal()顺序不能搞反。不然程序不会执行下去
LockSupport方法介绍
是什么?通过 park() 和 unpark(thread) 方法来实现阻塞和唤醒线程的操作
LockSupport用于创建锁和其他同步类的基本线程阻塞原语。
LockSupport类使用了一种名为 Permit(许可) 的概念来做到阻塞和唤醒线程的功能,每个线程都有一个许可(Permit)
permit只有两个值1和零,零认是零。
可以把许可看成是一种(0,1)信号量(Semaphore),但与 Semaphore 不同的是,许可的累加上限是1。
主要方法:
-
API
park()– 除非许可证可用,否则禁用当前线程以进行线程调度。
unpark(Thread thread)– 如果给定线程尚不可用,则为其提供许可。 -
阻塞
park()/park(Object blocker)
阻塞当前线程 / 阻塞传入的具体线程
permit默认是0,所以一开始调用park()方法,当前线程就会阻塞,直到别的线程将当前线程的peimit设置为1时,park方法会被唤醒,然后会将permit再次设置为0并返回。 -
唤醒
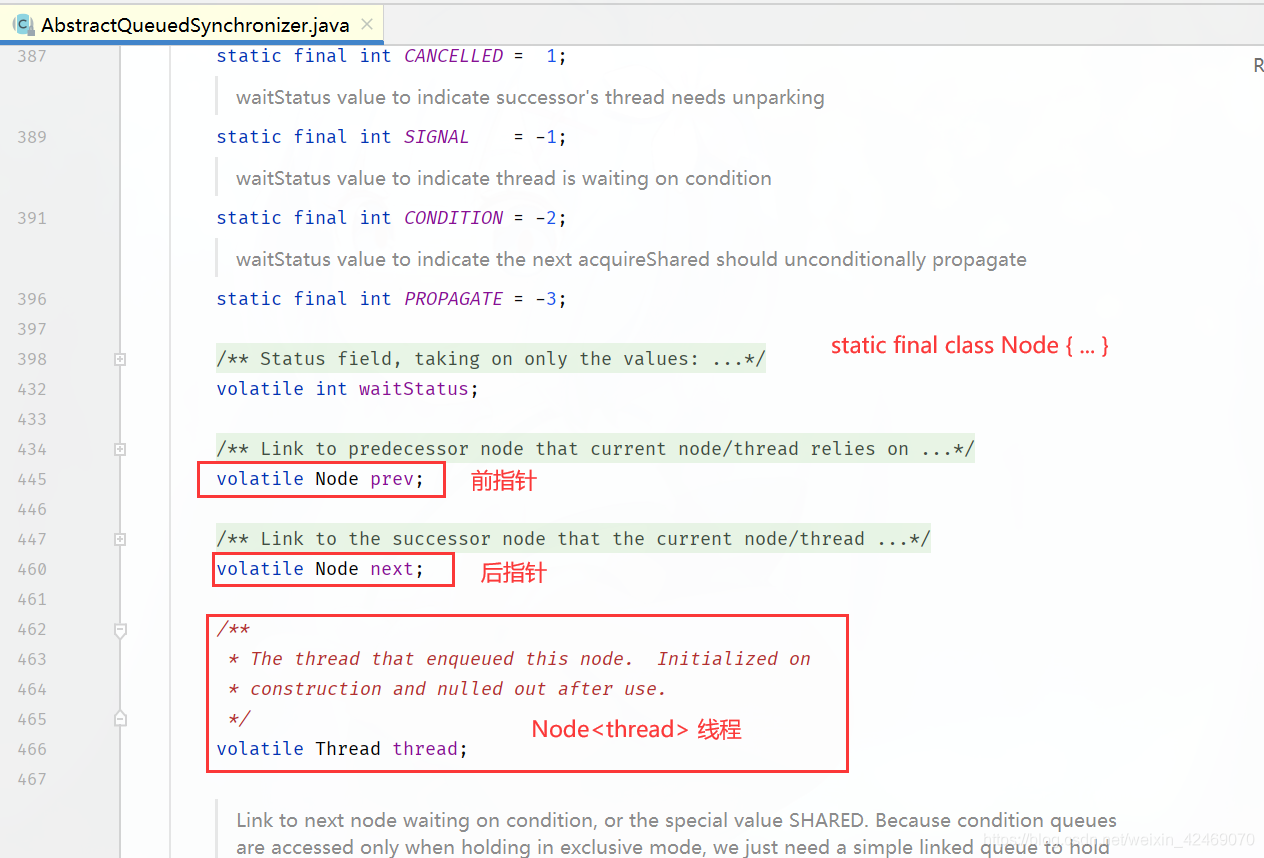
unpark(Thread thread)
唤醒处于阻塞状态的指定的线程

调用unpark(thread)方法后,就会将thread线程的许可permit设置为1(注意多次调用unpark方法,不会累加,permit值还是1)会自动唤醒thread线程,即之前阻塞中的LockSuppert.park()方法会立即返回。
LockSupport案例解析
代码演示:
public class LockSuppertDemo {
public static void main(String[] args) throws InterruptedException {
Thread a = new Thread(()->{
System.out.println(Thread.currentThread().getName() + "\t ---come in");
LockSupport.park();//被阻塞...等待通知等待放行,它要通过需要许可证
System.out.println(Thread.currentThread().getName() + "\t ---被唤醒");
},"a");
a.start();
TimeUnit.SECONDS.sleep(3L);
Thread b = new Thread(()->{
LockSupport.unpark(a);//给a发放许可证
System.out.println(Thread.currentThread().getName() + "\t ---发放许可证");
},"b");
b.start();
}
}
运行:
a ---come in
b ---发放许可证
a ---被唤醒
LockSupport.park(); 和LockSupport.unpark(a)顺序调换一下:
代码:
public class LockSuppertDemo {
public static void main(String[] args) throws InterruptedException {
Thread a = new Thread(()->{
try { TimeUnit.SECONDS.sleep(3L); } catch (InterruptedException e) { e.printStackTrace(); }
System.out.println(Thread.currentThread().getName() + "\t ---come in:"+System.currentTimeMillis());
LockSupport.park();//被阻塞...等待通知等待放行,它要通过需要许可证
System.out.println(Thread.currentThread().getName() + "\t ---被唤醒:"+System.currentTimeMillis());
},"a");
a.start();
Thread b = new Thread(()->{
LockSupport.unpark(a);//给a发放许可证
System.out.println(Thread.currentThread().getName() + "\t ---发放许可证");
},"b");
b.start();
}
}
运行:
b ---发放许可证
a ---come in:1618714913370
a ---被唤醒:1618714913370
重点说明
LockSupport是用来创建锁和共他同步类的基本线程阻塞原语。
LockSuport是一个线程阻塞工具类,所有的方法都是静态方法,可以让线程在任意位置阻塞,阻寨之后也有对应的唤醒方法。归根结底,LockSupport调用的Unsafe中的native代码。
LockSupport提供park()和unpark()方法实现阻塞线程和解除线程阻塞的过程
LockSupport和每个使用它的线程都有一个许可(permit)关联。permit相当于1,0的开关,默认是0,
调用一次unpark就加1变成1,
调用一次park会消费permit,也就是将1变成0,同时park立即返回。
如再次调用park会变成阻塞(因为permit为零了会阻塞在这里,一直到permit变为1),这时调用unpark会把permit置为1。
每个线程都有一个相关的permit, permit最多只有一个,重复调用unpark也不会积累凭证。
形象的理解
线程阻塞需要消耗凭证(permit),这个凭证最多只有1个
当调用park方法时
- 如果有凭证,则会直接消耗掉这个凭证然后正常退出。
- 如果无凭证,就必须阻塞等待凭证可用。
而unpark则相反,它会增加一个凭证,但凭证最多只能有1个,累加无放
面试题
为什么可以先唤醒线程后阻塞线程?
因为unpark获得了一个凭证,之后再调用park方法,就可以名正言顺的凭证消费,故不会阻塞。
为什么唤醒两次后阻塞两次,但最终结果还会阻塞线程?
因为凭证的数量最多为1(不能累加),连续调用两次 unpark和调用一次 unpark效果一样,只会增加一个凭证;而调用两次park却需要消费两个凭证,证不够,不能放行。
AQS理论初步
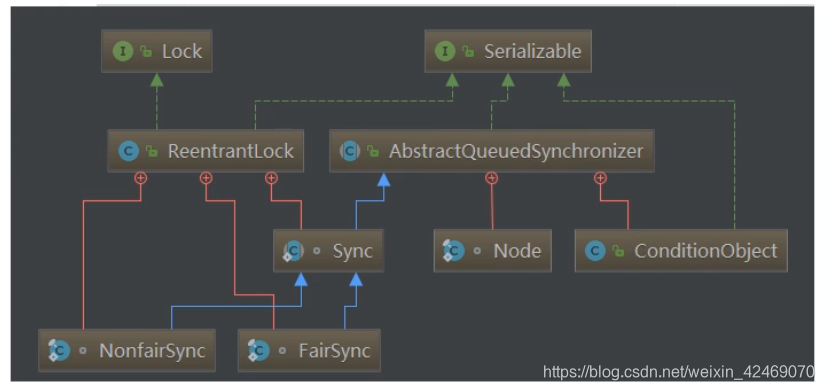
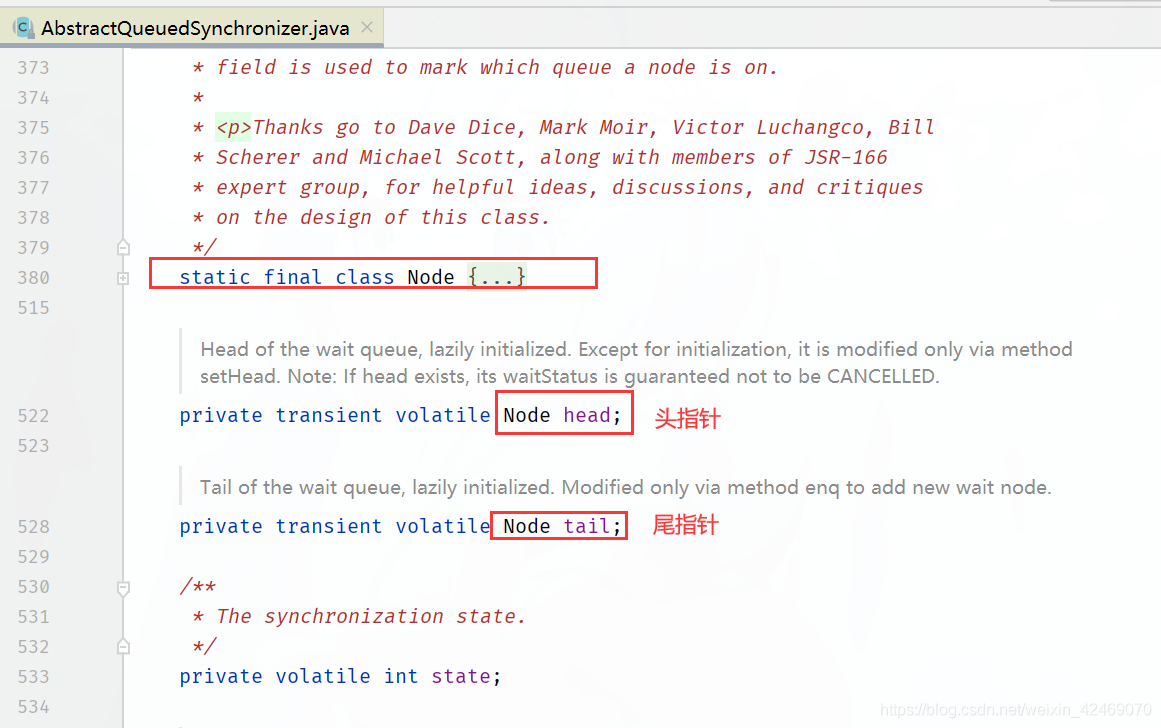
字面上的意思: 抽象的队列同步器
源码包位置:
AbstractOwnableSynchronizerAbstractQueuedLongSynchronizerAbstractQueuedSynchronizer
通常地:AbstractQueuedSynchronizer简称为AQS
技术解释:
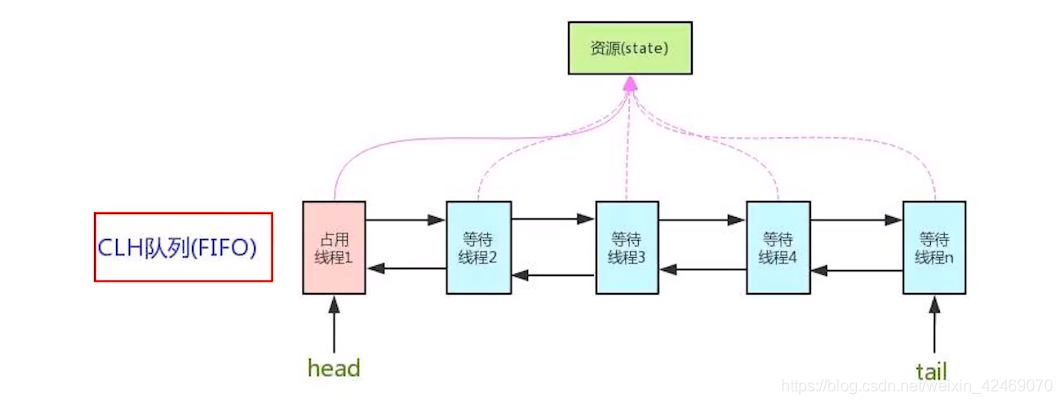
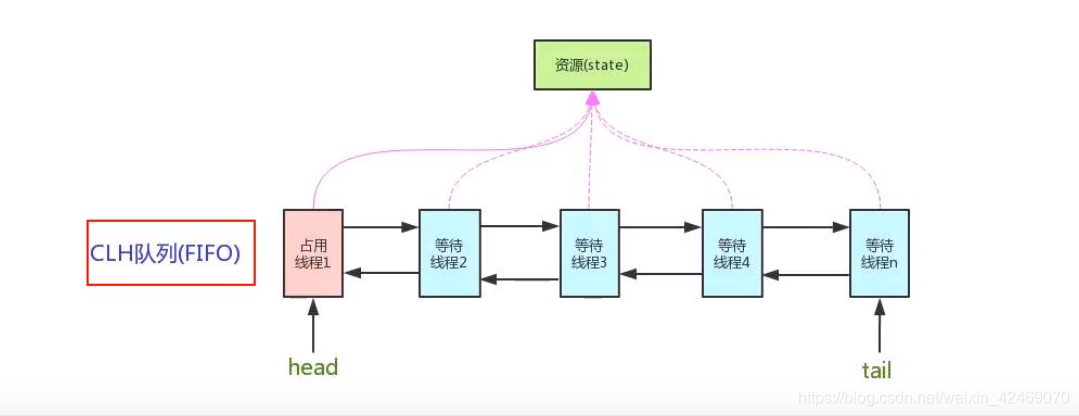
是用来构建锁或者其它同步器组件的重量级基础框架及整个JUC体系的基石,通过内置的FIFO队列来完成资源获取线程的排队工作,并通过一个int类型变量表示持有锁的状态。
CLH(Craig、Landin and Hagersten)队列,是一个单向链表,AQS中的队列是CLH变体的虚拟双向队列FIFO。
AQS能干嘛
AQS为什么是JUC内容中最重要的基石?
和AQS有关的:
-
ReentrantLock
-
CountDownLatch
-
ReentrantReadWriteLock
-
Semaphore
-
…
进一步理解锁和同步器的关系:
-
锁,面向锁的使用者
定义了程序员和锁交互的使用层APl,隐藏了实现细节,你调用即可。 -
同步器,面向锁的实现者
比如Java并发大神DougLee,提出统一规范并简化了锁的实现,屏蔽了同步状态管理、阻塞线程排队和通知、唤醒机制等。
能干嘛?
加锁会导致阻塞 :有阻塞就需要排队,实现排队必然需要有某种形式的队列来进行管理
解释说明:
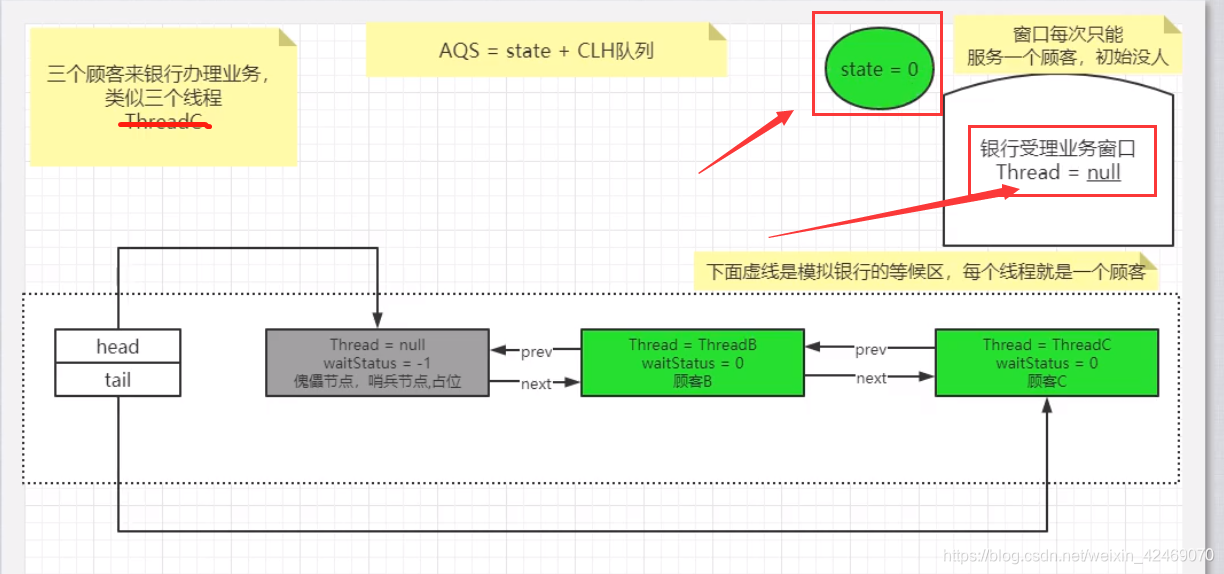
抢到资源的线程直接使用处理业务逻辑,抢不到资源的必然涉及一种排队等候机制。抢占资源失败的线程去等待(类似银行业务办理窗口都满了,暂时没有受理窗口的顾客只能去侯客去排队等候),但等候线程仍然保留获取锁的可能且获取锁流程仍在继续(侯客区的顾客也在等着叫号,轮到了再去受理窗口办理业务)。
既然说到了排队等候机制,那么就一定会有某种队列形成,这样的队列是什么数据结构呢?
如果共享资源被占用,就需要一定的阻塞等待唤醒机制来保证锁分配。这个机制主要用的是CLH队列的变体实现的,将暂时获取不到锁的线程加入到队列中,这个队列就是AQS的抽象表现。它将请求共享资源的线程封装成队列的结点(Node),通过CAS、自旋以及LockSupport.park()的方式,维护state变量的状态,使并发达到同步的控制效果。
AQS源码体系-上
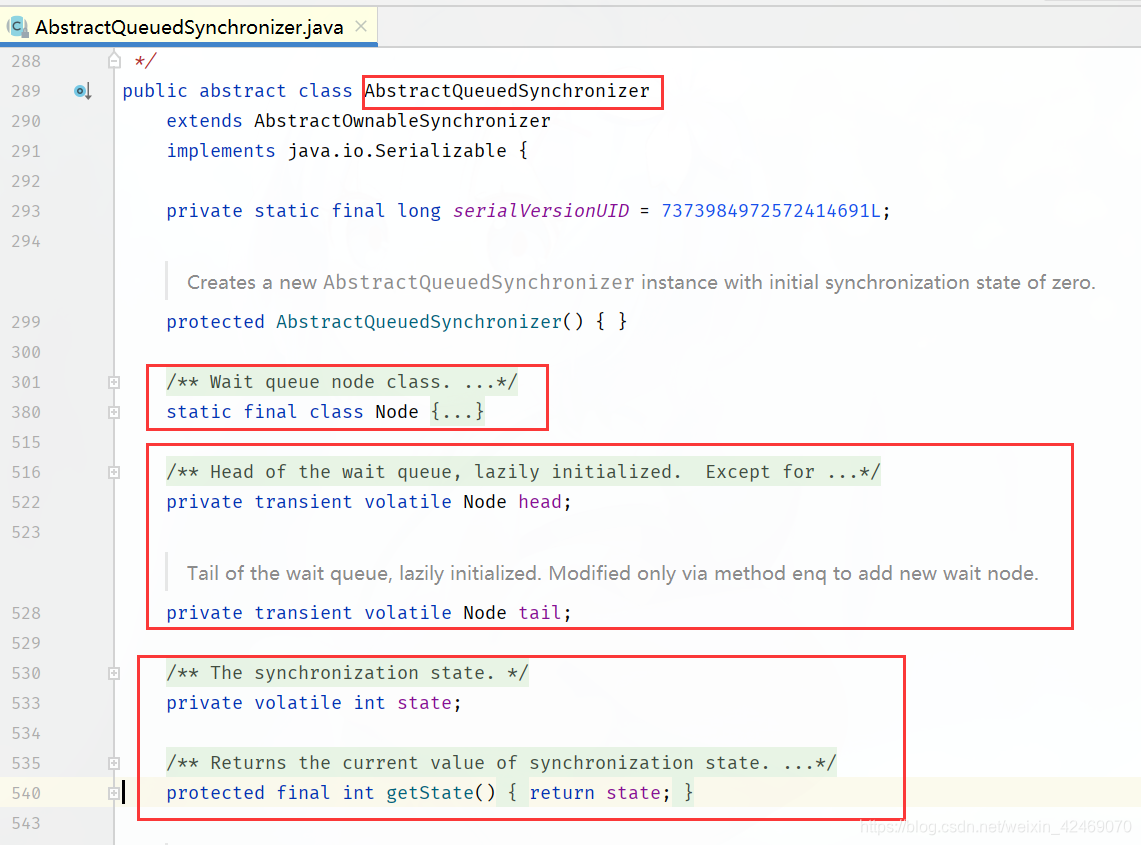
AQS代码解释:java.util.concurrent.locks.AbstractQueuedSynchronizer
/**
* Provides a framework for implementing blocking locks and related
* synchronizers (semaphores, events, etc) that rely on
* first-in-first-out (FIFO) wait queues. This class is designed to
* be a useful basis for most kinds of synchronizers that rely on a
* single atomic {@code int} value to represent state. Subclasses
* must define the protected methods that change this state, and which
* define what that state means in terms of this object being acquired
* or released. Given these, the other methods in this class carry
* out all queuing and blocking mechanics. Subclasses can maintain
* other state fields, but only the atomically updated {@code int}
* value manipulated using methods {@link #getState}, {@link
* #setState} and {@link #compareAndSetState} is tracked with respect
* to synchronization.
*
.......
翻译
提供一个框架来实现阻塞锁和相关的
依赖于的同步器(信号量、事件等)
先进先出(FIFO)等待队列。本课程旨在
对于大多数依赖于
表示状态的单个原子{@code int}值。子类
必须定义更改此状态的受保护方法,以及
定义该状态对于获取的对象意味着什么
或者被释放。给定这些,这个类中的其他方法
排除所有排队和阻塞机制。子类可以维护
其他状态字段,但只有原子更新的{@code int}
使用{@link#getState}、{@link方法操作的值
#setState}和{@link#compareAndSetState}是根据
到同步。
有阻塞就需要排队,实现排队必然需要队列
AQS使用一个volatile的int类型的成员变量来表示同步状态,通过内置的FIFO队列类完成资源获取的排队工作将每条要抢占资源的线程封装成一个Node节点来实现锁的分配,通过CAS完成对State值的修改
AQS源码体系-下
AQS内部体系架构:
AQS自身
AQS的int变量:AQS的同步状态state成员变量
/**
* The synchronization state.
*/
private volatile int state;
state成员变量类似:银行办理业务的受理窗口状态
- 零就是没人,自由状态可以办理
- 大于等于1,有人占用窗口,去侯客区
AQS的CLH队列:
- CLH队列(三个大神的名字组成),为一个双向队列
- 银行候客区的等待顾客
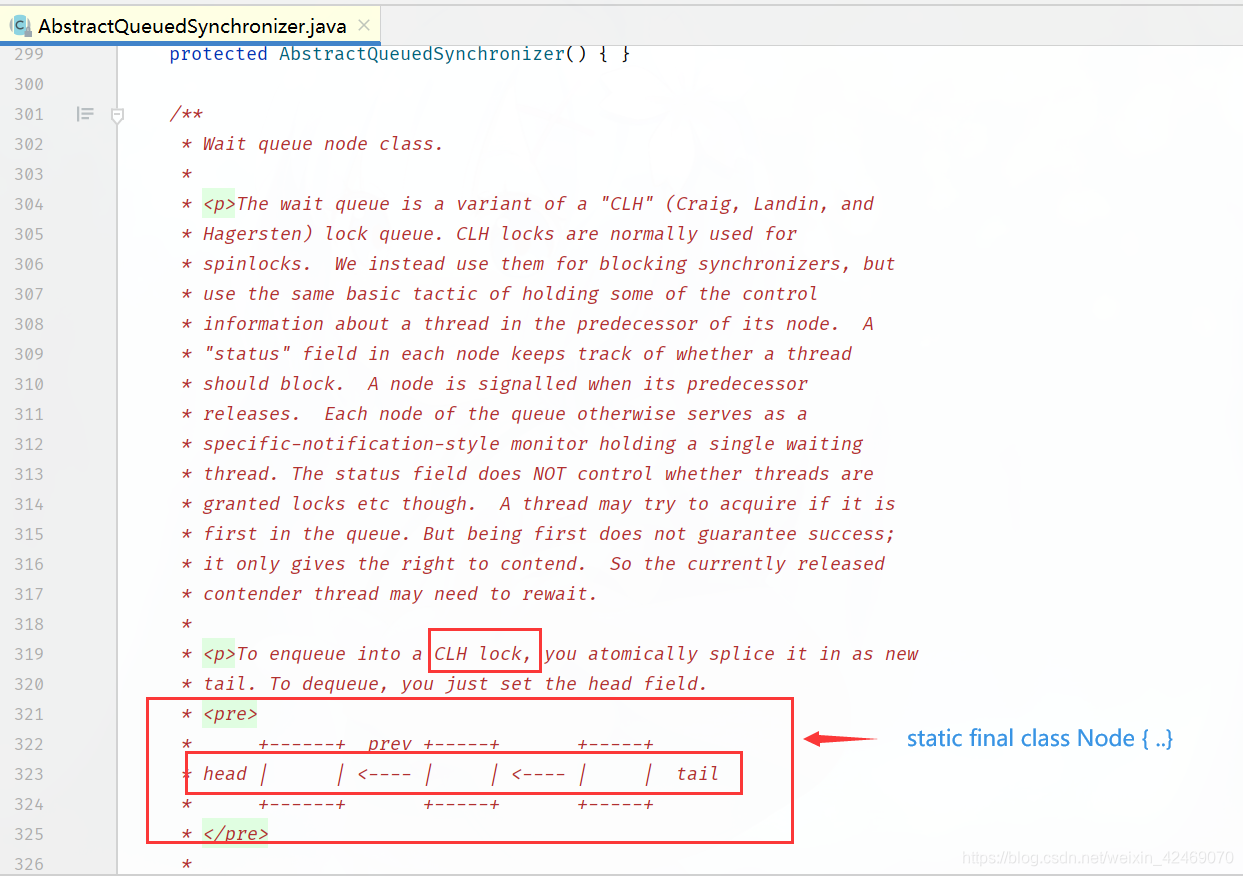
/**
* Wait queue node class.
*
* <p>The wait queue is a variant of a "CLH" (Craig, Landin, and
* Hagersten) lock queue. CLH locks are normally used for
* spinlocks. We instead use them for blocking synchronizers, but
* use the same basic tactic of holding some of the control
* information about a thread in the predecessor of its node. A
* "status" field in each node keeps track of whether a thread
* should block. A node is signalled when its predecessor
* releases. Each node of the queue otherwise serves as a
* specific-notification-style monitor holding a single waiting
* thread. The status field does NOT control whether threads are
* granted locks etc though. A thread may try to acquire if it is
* first in the queue. But being first does not guarantee success;
* it only gives the right to contend. So the currently released
* contender thread may need to rewait.
*
* <p>To enqueue into a CLH lock, you atomically splice it in as new
* tail. To dequeue, you just set the head field.
* <pre>
* +------+ prev +-----+ +-----+
* head | | <---- | | <---- | | tail
* +------+ +-----+ +-----+
* </pre>
* ...
* /
static final class Node { ... }
翻译:
等待队列是“CLH”(Craig、Landin和Hagersten)锁队列的变体。CLH锁通常用于自旋锁等待。
用它们来阻止同步器,
但是使用相同的基本策略,在其节点的前一个线程中保存一些关于该线程的控制信息。
每个节点中的“status”字段跟踪线程是否应该阻塞。
节点在其前一个节点释放时发出信号。
队列的每个节点都充当一个特定的通知样式监视器,其中包含一个等待线程。
状态字段并不控制线程是否被授予锁等。
如果线程是队列中的第一个线程,它可能会尝试获取。但做第一并不能保证成功;
它只给了我们抗争的权利。
因此,当前发布的竞争者线程可能需要重新等待。
要排队进入CLH锁,您可以将其作为新的尾部进行原子拼接。要出列,只需设置head字段(从头部出列)。
<pre>
+------+ prev +-----+ +-----+
head | | <---- | | <---- | | tail
+------+ +-----+ +-----+
</pre>
小总结:
- 有阻塞就需要排队,实现排队必然需要队列
- state变量 + CLH变种的双端队列
内部类Node(Node类在AQS类的内部)
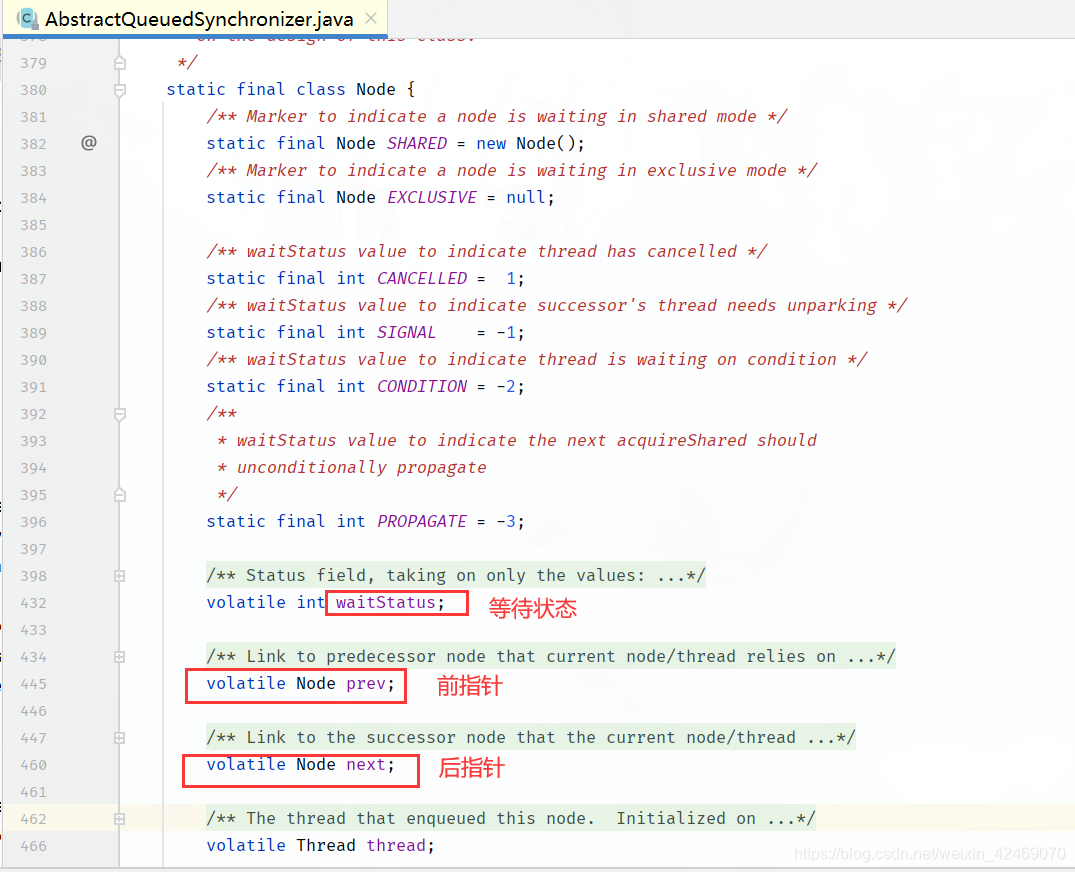
内部结构:
static final class Node {
//共享
static final Node SHARED = new Node();
// 独占
static final Node EXCLUSIVE = null;
// 线程取消了
static final int CANCELLED = 1;
// 后续线程需要唤醒
static final int SIGNAL = -1;
// 等待 condition 唤醒
static final int CONDITION = -2;
// 共享式同步状态获取将会无条件地传播下去
static final int PROPAGATE = -3;
// 初始为0,状态是上面几种
volatile int waitStatus;
// 前置节点
volatile Node prev;
// 后续节点
volatile Node next;
volatile Thread thread;
Node nextWaiter;
final boolean isShared() {
return nextWaiter == SHARED;
}
final Node predecessor() throws NullPointerException {
Node p = prev;
if (p == null)
throw new NullPointerException();
else
return p;
}
Node() { // Used to establish initial head or SHARED marker
}
Node(Thread thread, Node mode) { // Used by addWaiter
this.nextWaiter = mode;
this.thread = thread;
}
Node(Thread thread, int waitStatus) { // Used by Condition
this.waitStatus = waitStatus;
this.thread = thread;
}
}
属性说明:
-
SHARED:表示线程以共享的模式等待锁 -
EXCLUSIVE:表示线程正在以独占的方式等待锁 -
waitStatus: 当前节点在队列中的状态
0:当一个Node被初始化的时候的默认值
CANCELLED:为1,表示线程获取锁的请求已被取消了
CONDITION: 为2,表示节点在等待队列中,节点线程等待唤醒
PROPAGATE: 为3,当前线程处于在SHARED情况下,改字段才会使用
SIGNAL:为-1,表示线程已经准备好了,就等待资源释放了 -
thread:表示处于该节点的线程 -
prev:前驱指针 -
predecessor:返回前驱节点,没有的话抛出npe -
nextWaiter:指向下一个CONDITION状态的节点(SHARED) -
next:后续指针
AQS同步队列的基本结构:
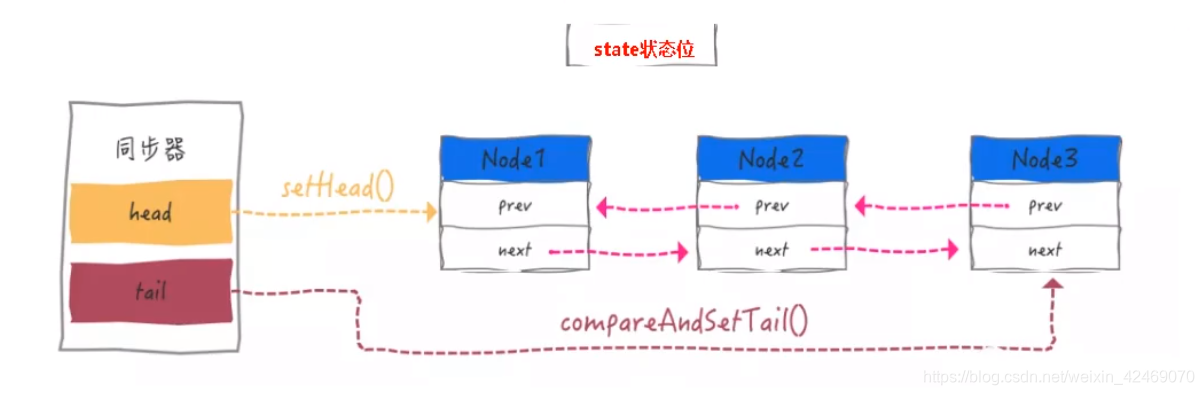
AQS源码深度解读01
从ReentrantLock开始解读 AQS
Lock接口的实现类,基本都是通过【聚合】了一个【队列同步器】的子类完成线程访问控制的
ReentrantLock的原理:
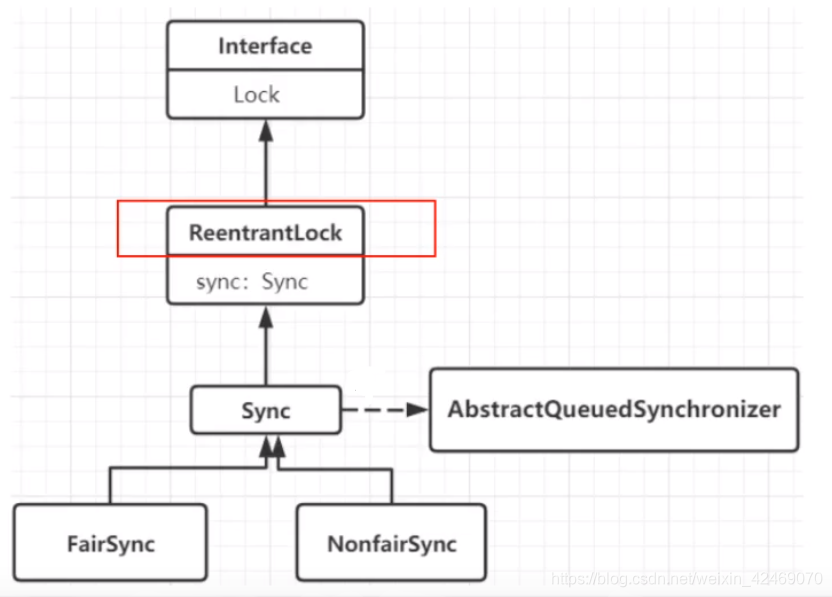
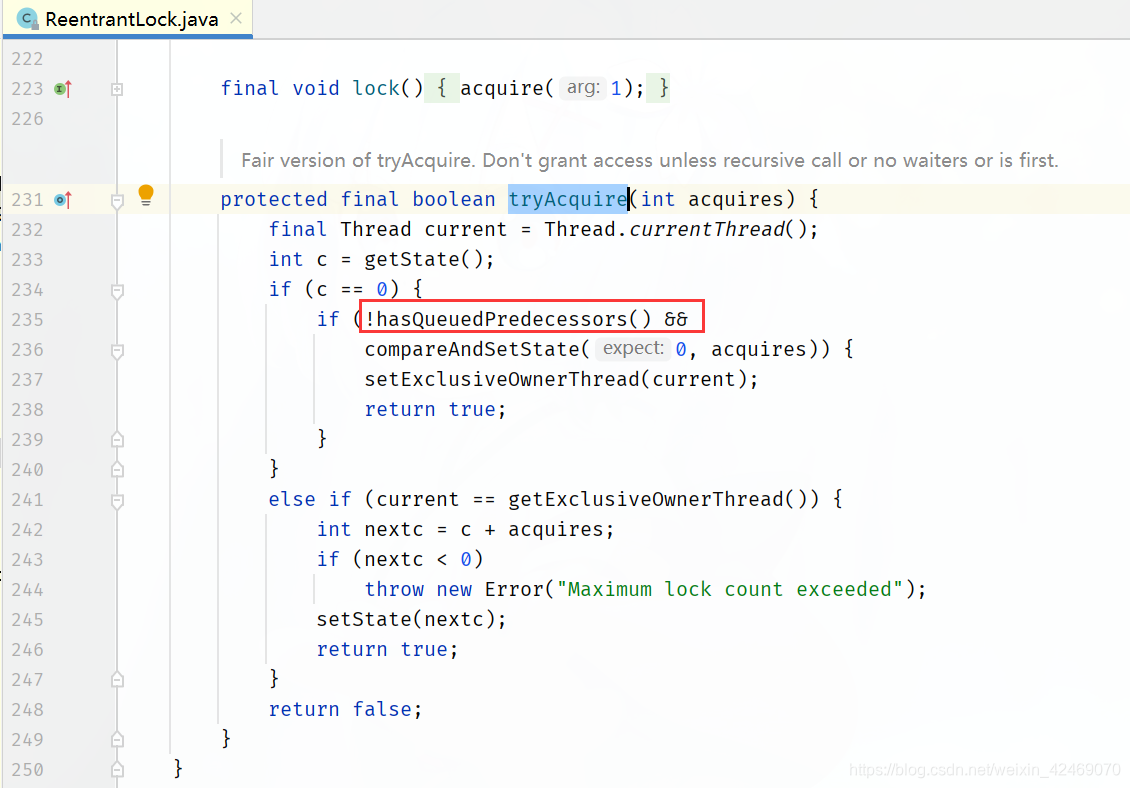
从最简单的lock方法开始看看公平和非公平:
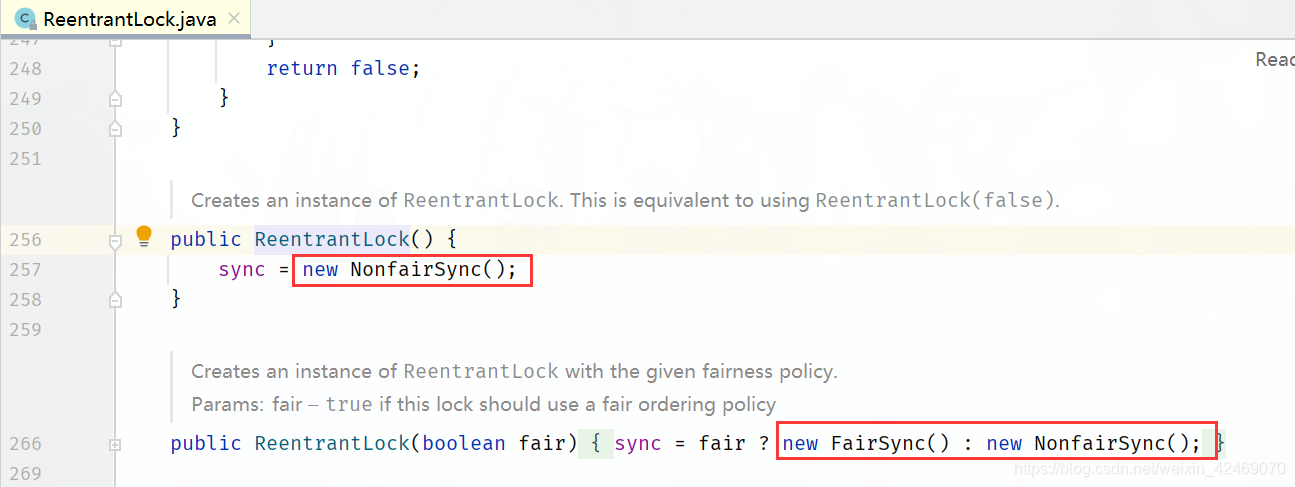
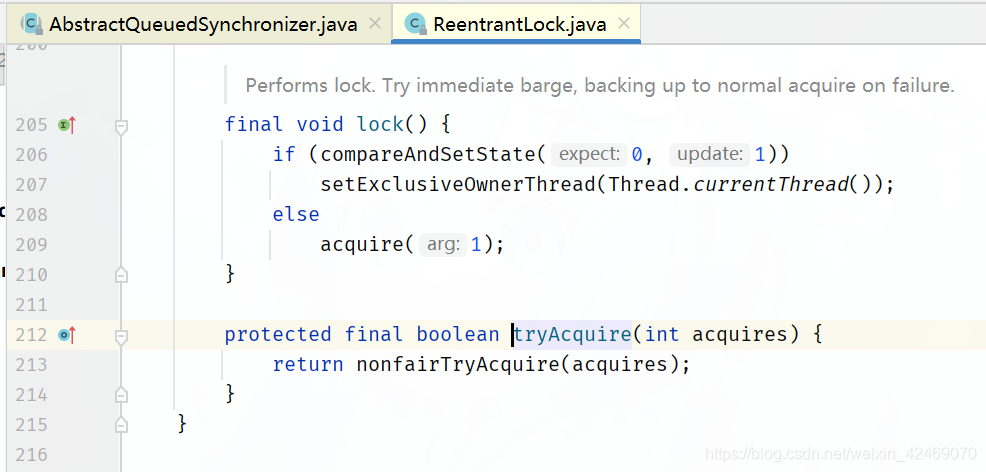
公平锁(tryAcquire):
非公平锁(nonfairTryAcquire):
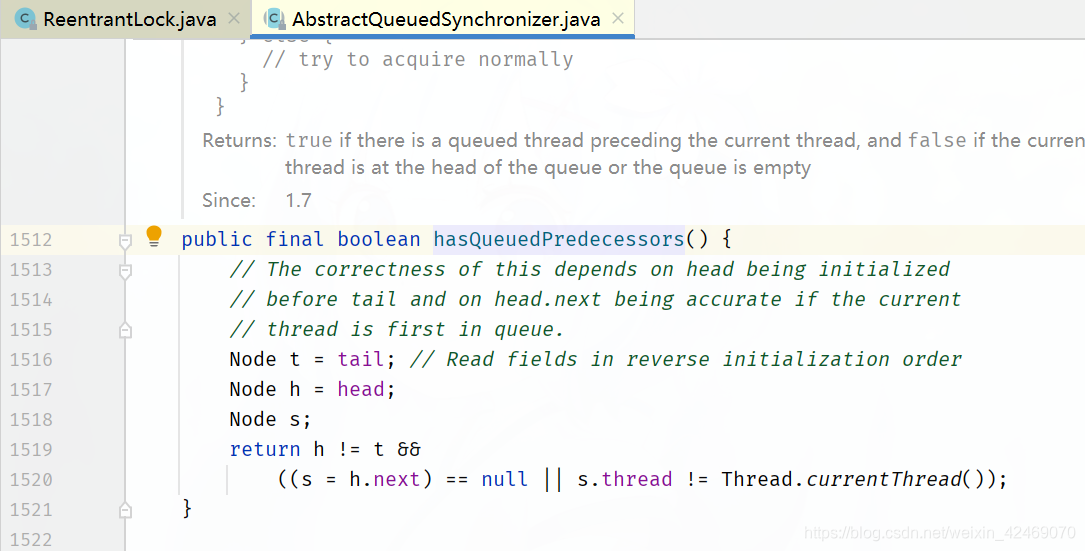
可以明显看出公平锁与非公平锁的 lock() 方法唯一的区别就在于公平锁在获取同步状态时多了一个限制条件:hasQueuedPredecessors()
hasQueuedPredecessors是公平锁加锁时判断等待队列是否存在有效节点的方法
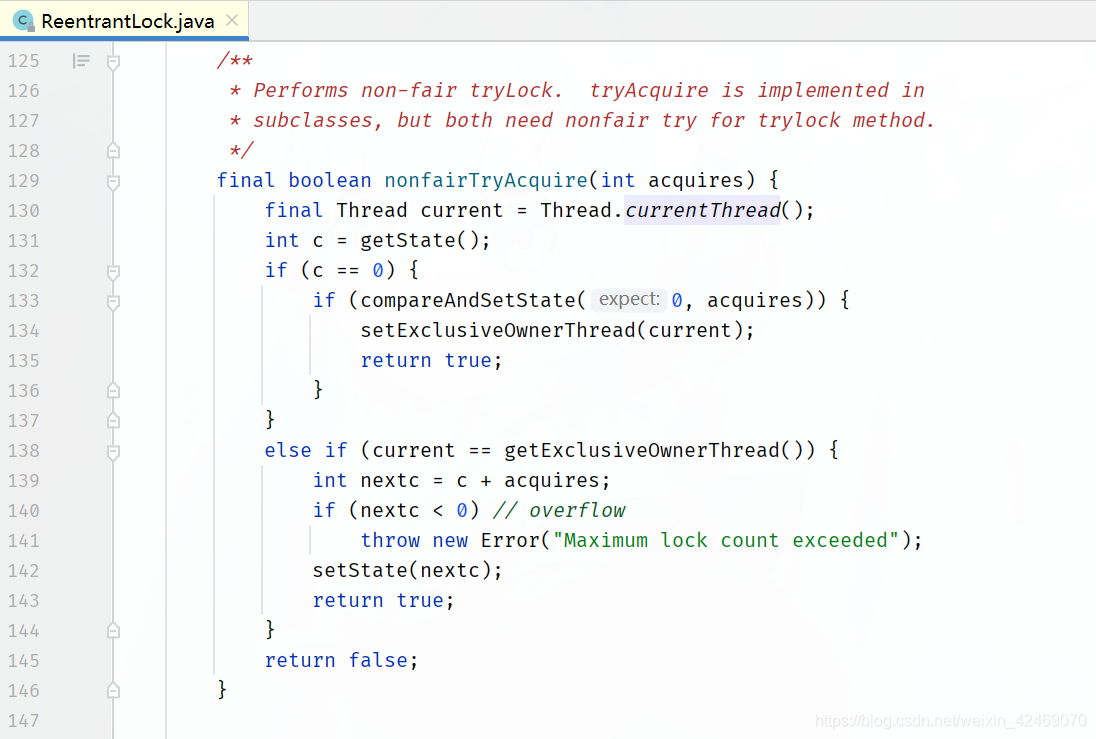
非公平锁,方法lock():
对比公平锁和非公平锁的 tryAcquire() 方法的实现代码,其实差别就在于非公平锁获取锁时比公平锁中少了一个判断 !hasQueuedPredecessors()
hasQueuedPredecessors() 中判断了是否需要排队,导致公平锁和非公平锁的差异如下:
公平锁:公平锁讲究先来先到,线程在获取锁时,如果这个锁的等待队列中已经有线程在等待,那么当前线程就会进入等待队列中;
非公平锁:不管是否有等待队列,如果可以获取锁,则立刻占有锁对象。也就是说队列的第一个排队线程在unpark(),之后还是需要竞争锁(存在线程竞争的情况下)
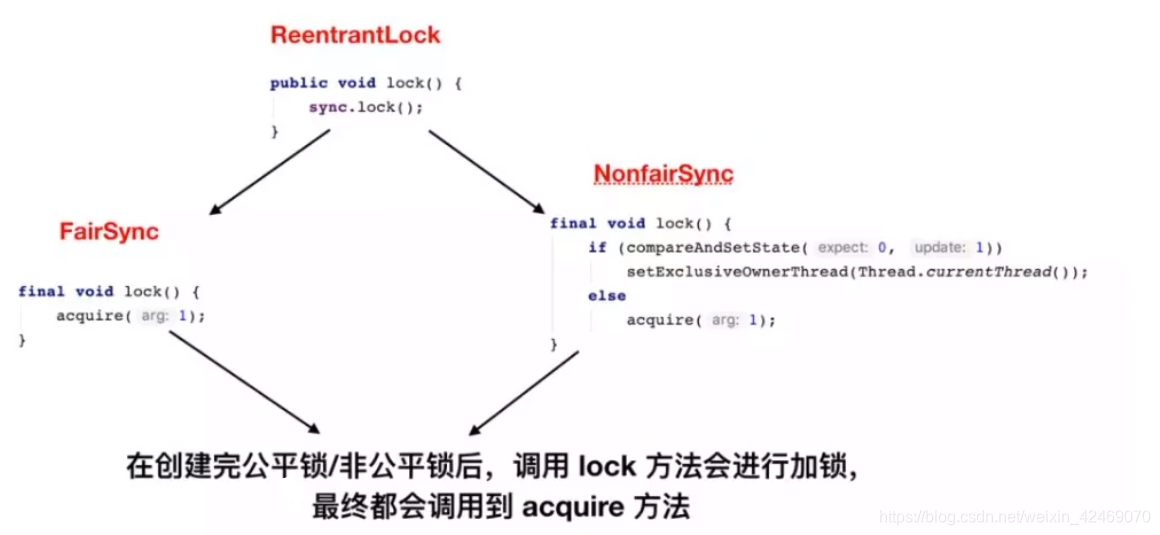
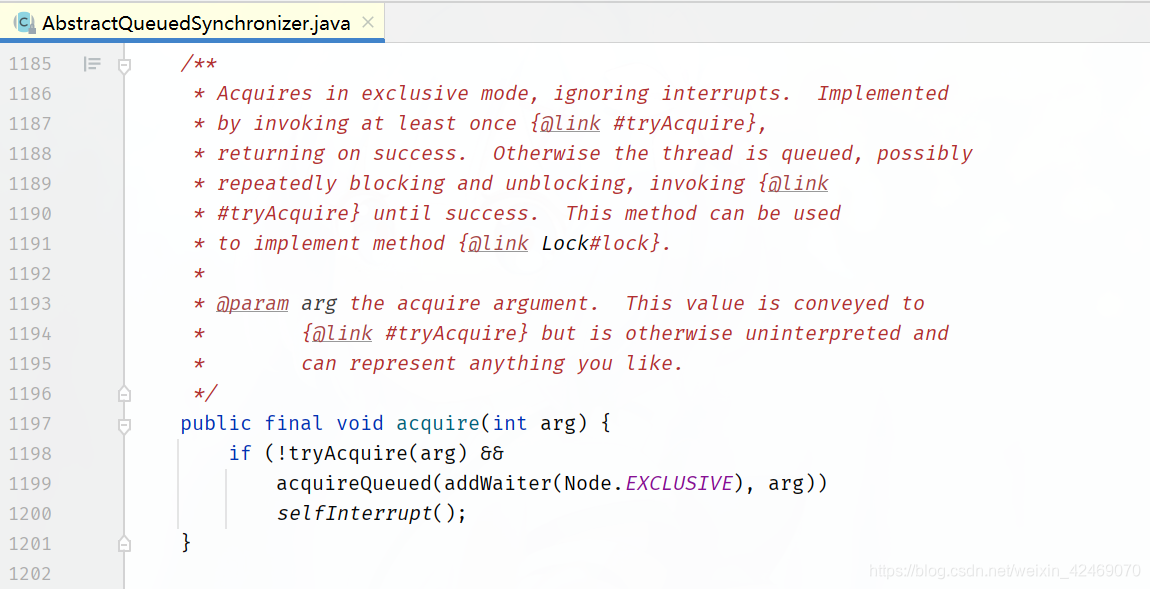
整个ReentrantLock 的加锁过程,可以分为三个阶段:
- ①尝试加锁;
- ②加锁失败,线程入队列;
- ③线程入队列后,进入阻赛状态。
AQS源码深度解读02
ReentrantLock代码演示:
public class AQSDemo {
public static void main(String[] args) {
ReentrantLock lock = new ReentrantLock();
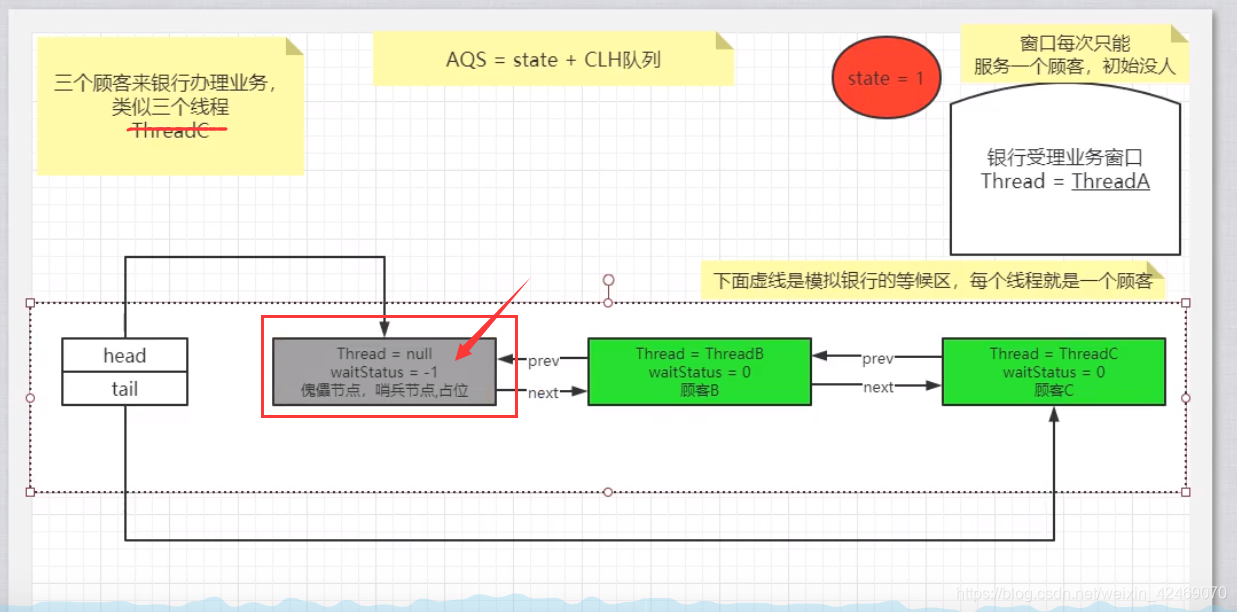
//带入一个银行办理业务的案例来模拟我们的AQS如何进行线程的管理和通知唤醒机制
//3个线程模拟3个来银行网点,受理窗口办理业务的顾客;
//A顾客就是第一个顾客,此时受理窗口没有任何人,A可以直接去办理
new Thread(()->{
lock.lock();
try{
System.out.println(Thread.currentThread().getName() + "A thread come in");
//模拟办理业务时间 20 分钟
try { TimeUnit.MINUTES.sleep(20); } catch (InterruptedException e) { e.printStackTrace(); }
} finally {
lock.unlock();
}
}, "A").start();
//第2个顾客,第2个线程---->,由于受理业务的窗口只有一个(只能一个线程持有锁),此代B只能等待,
// 进入候客区
new Thread(()->{
lock.lock();
try{
System.out.println(Thread.currentThread().getName() + "B thread come in");
} finally {
lock.unlock();
}
}, "B").start();
//第3个顾客,第3个线程---->,由于受理业务的窗口只有一个(只能一个线程持有锁),此代C只能等待,
// 进入候客区
new Thread(()->{
lock.lock();
try{
System.out.println(Thread.currentThread().getName() + "C thread come in");
} finally {
lock.unlock();
}
}, "C").start();
}
}
程序理解图:
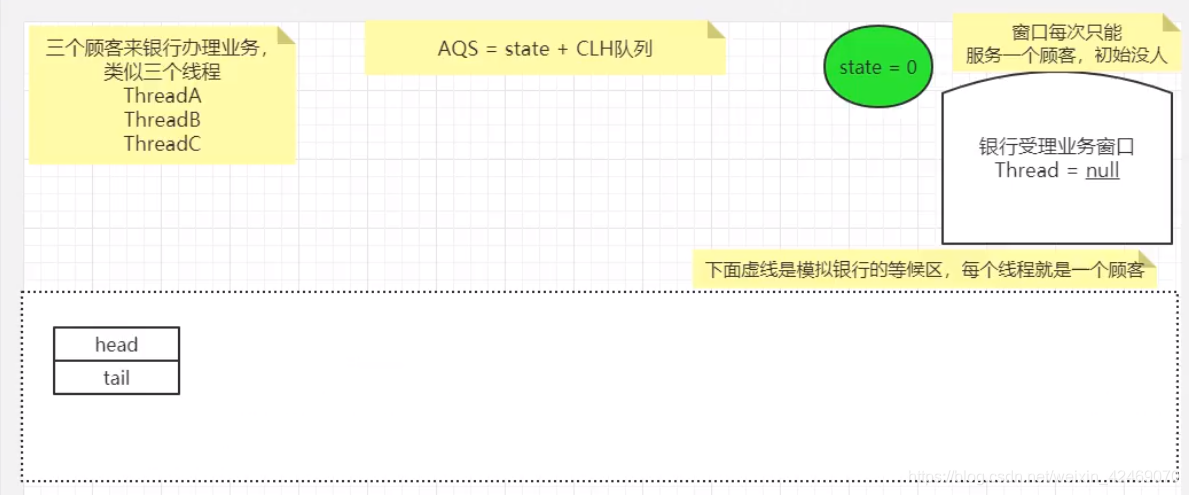
第一个线程A执行, lock.lock();
//A顾客就是第一个顾客,此时受理窗口没有任何人,A可以直接去办理
new Thread(()->{
lock.lock();
try{
System.out.println(Thread.currentThread().getName() + "A thread come in");
//模拟办理业务时间 20 分钟
try { TimeUnit.MINUTES.sleep(20); } catch (InterruptedException e) { e.printStackTrace(); }
} finally {
lock.unlock();
}
}, "A").start();
进入ReentrantLock.lock()方法;
进入抽象abstract void lock();方法,
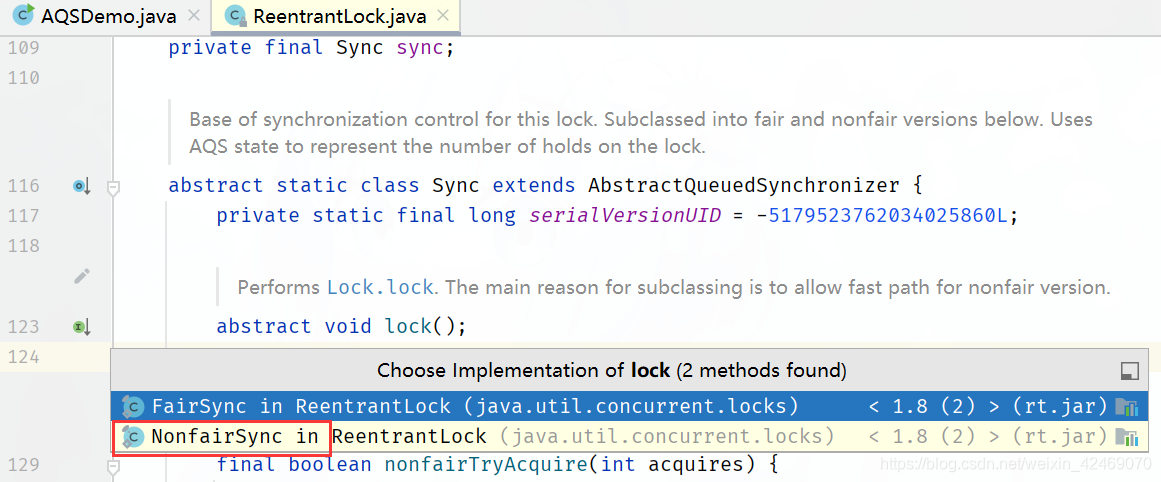
进入NonfairSync内部类继承Sync,lock()方法
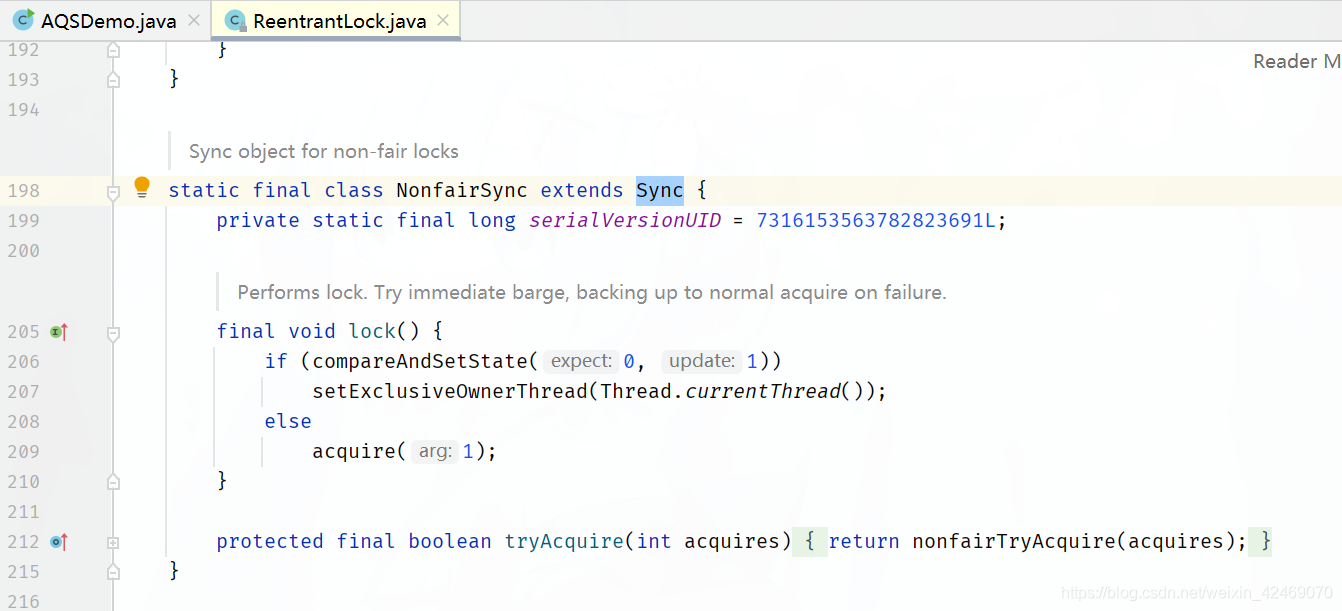
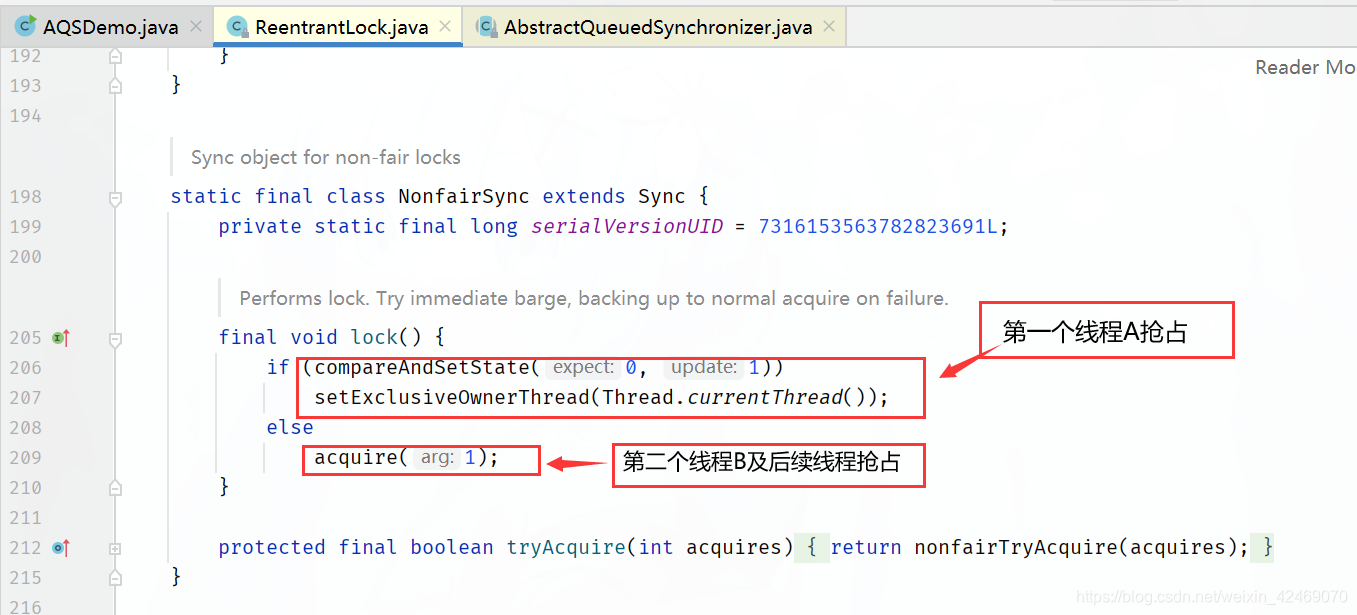
这里的 if (compareAndSetState(0, 1))语句执行是为true(因为是一个进来status=0 执行compareAndSetState比较并交换结果为true)
执行setExclusiveOwnerThread(Thread.currentThread());方法,放入当前线程

执行线程A后的理解图:

第二个线程B执行, lock.lock();
//A顾客就是第一个顾客,此时受理窗口没有任何人,A可以直接去办理
new Thread(()->{
lock.lock();
try{
System.out.println(Thread.currentThread().getName() + "A thread come in");
//模拟办理业务时间 20 分钟
try { TimeUnit.MINUTES.sleep(20); } catch (InterruptedException e) { e.printStackTrace(); }
} finally {
lock.unlock();
}
}, "A").start();
到NonfairSync的lock()方法时候
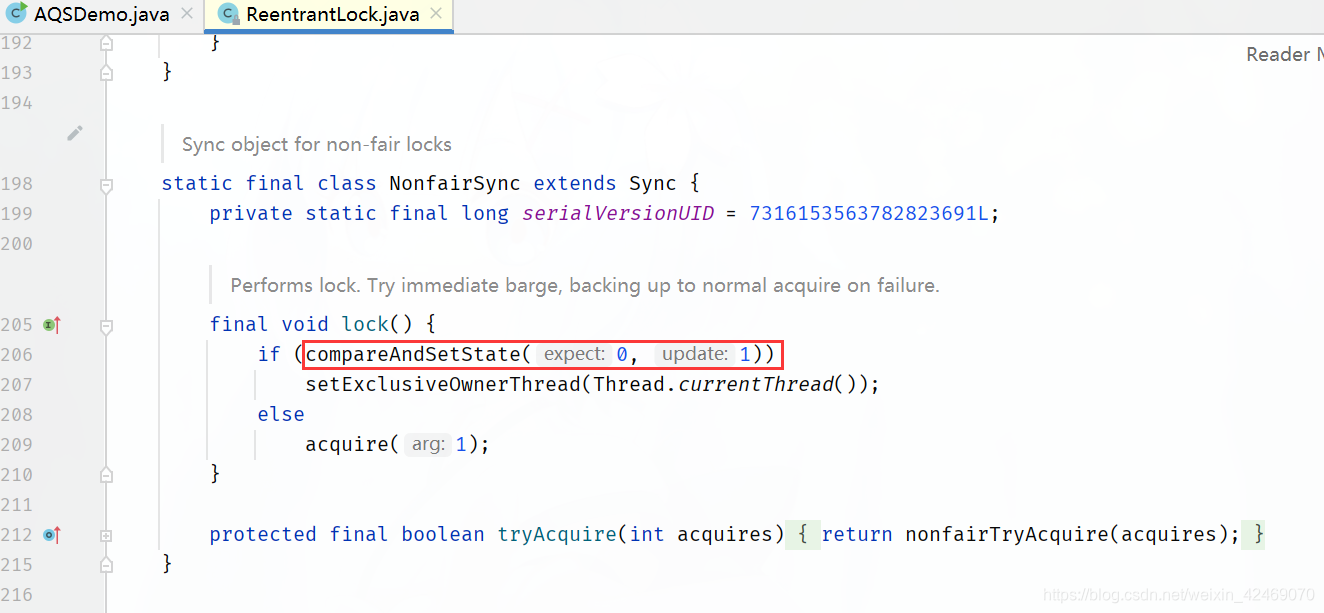
由于 if (compareAndSetState(0, 1))语句执行为false(因为第一个线程A已经把status状态0改成1,比较并交换结果失败),进入acquire(1);方法
NonfairSync执行情况:
AQS源码深度解读03
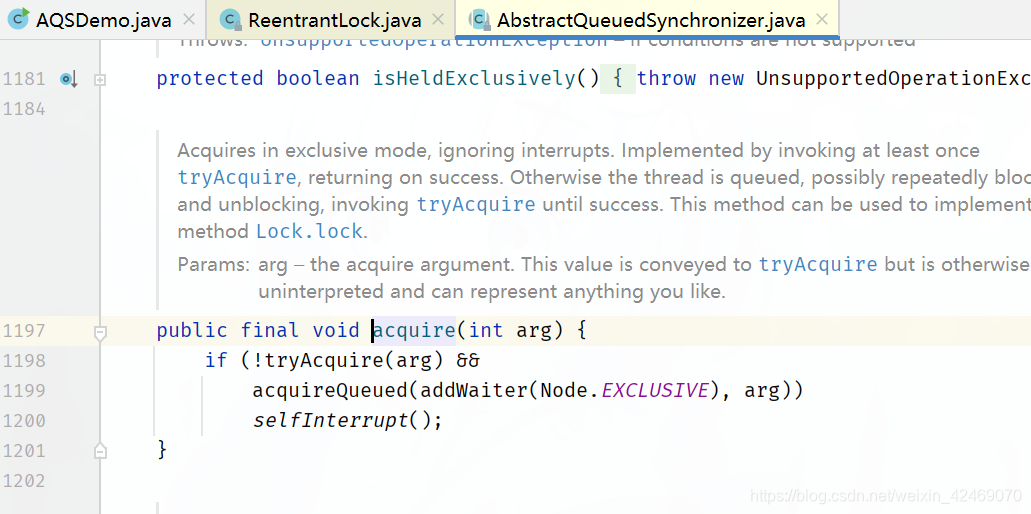
第二个线程B执行到:AbstractQueuedSynchronizer.acquire()方法这
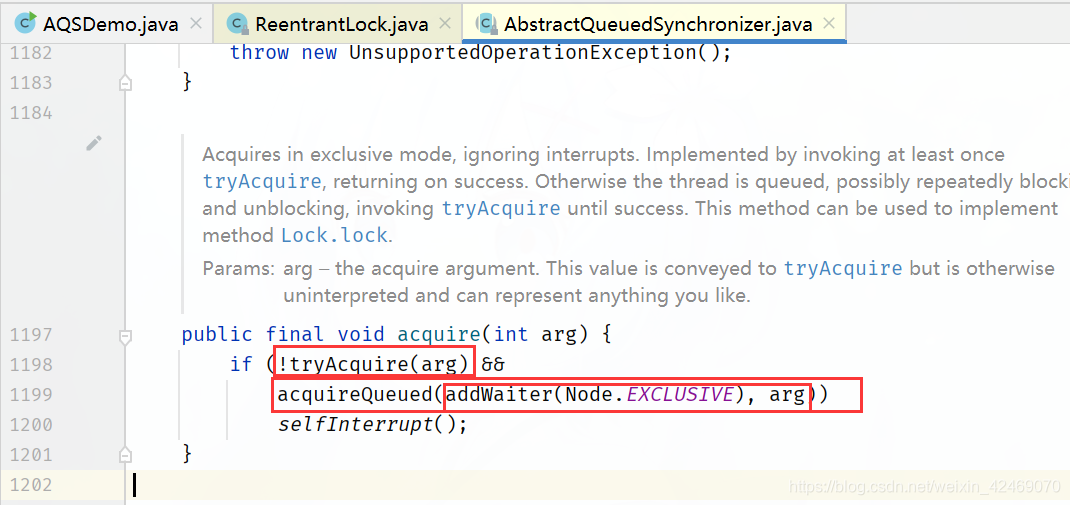
这里有三个方法tryAcquire()、addWaiter()、acquireQueued()
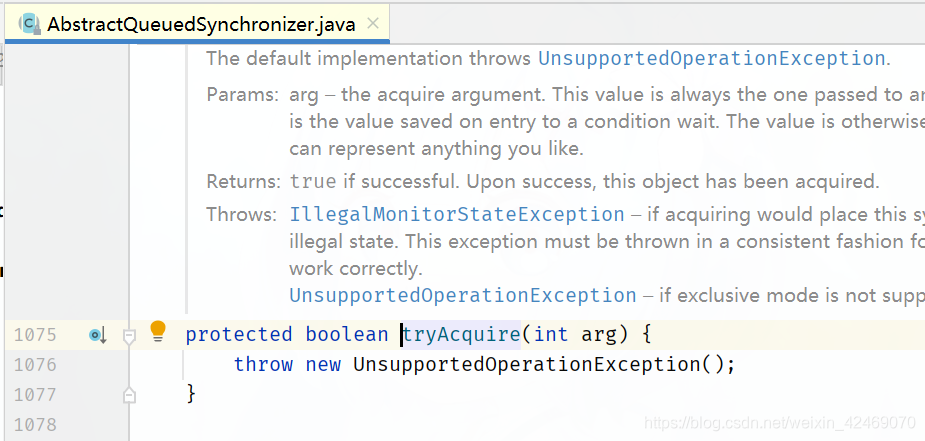
先进入第一个tryAcquire()方法:
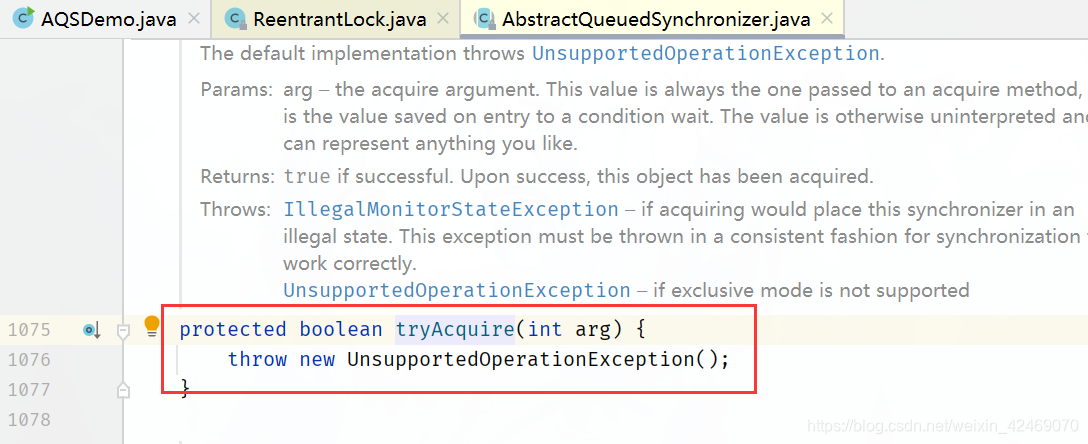
但是这里AbstractQueuedSynchronizer父类直接抛出异常?!,看看子类的继承
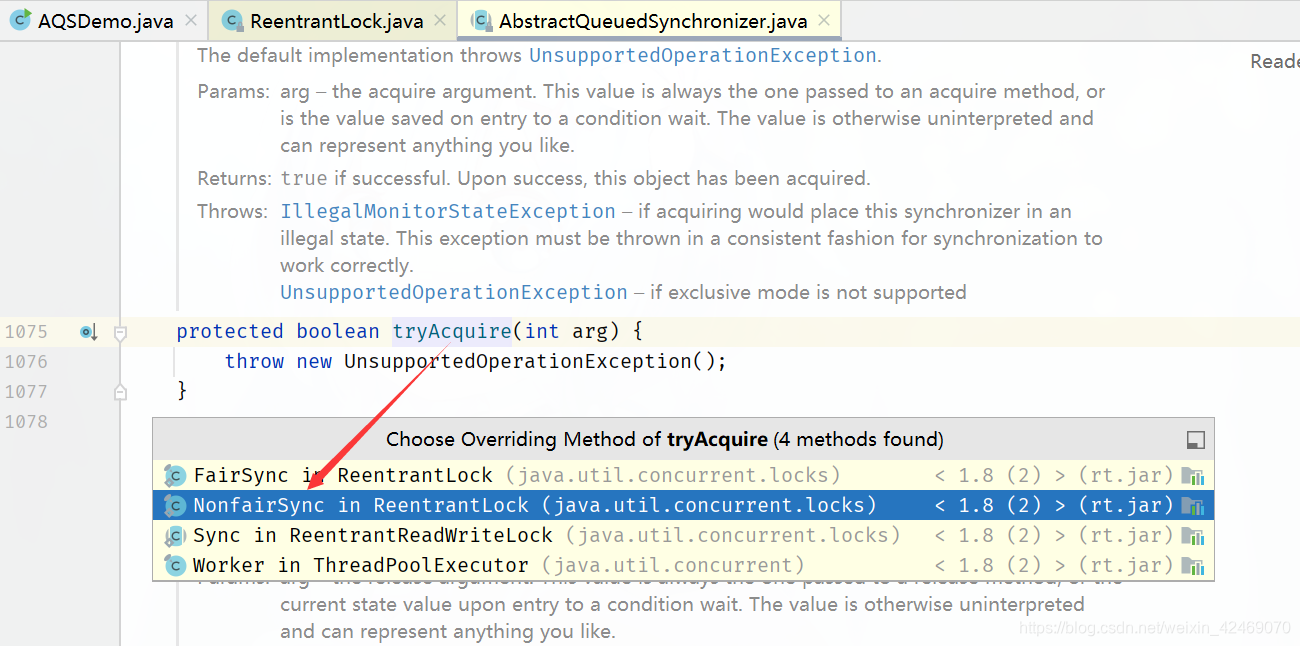
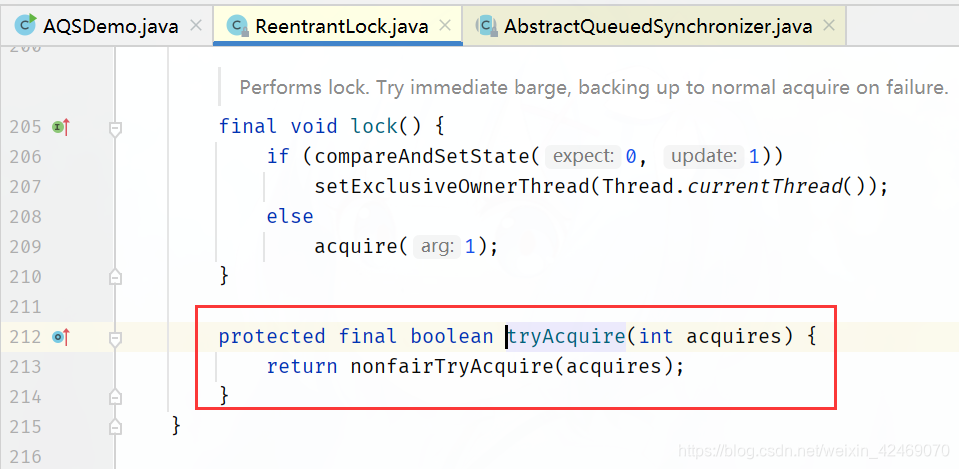
tryAcquire()方法又调用nonfairTryAcquire()方法
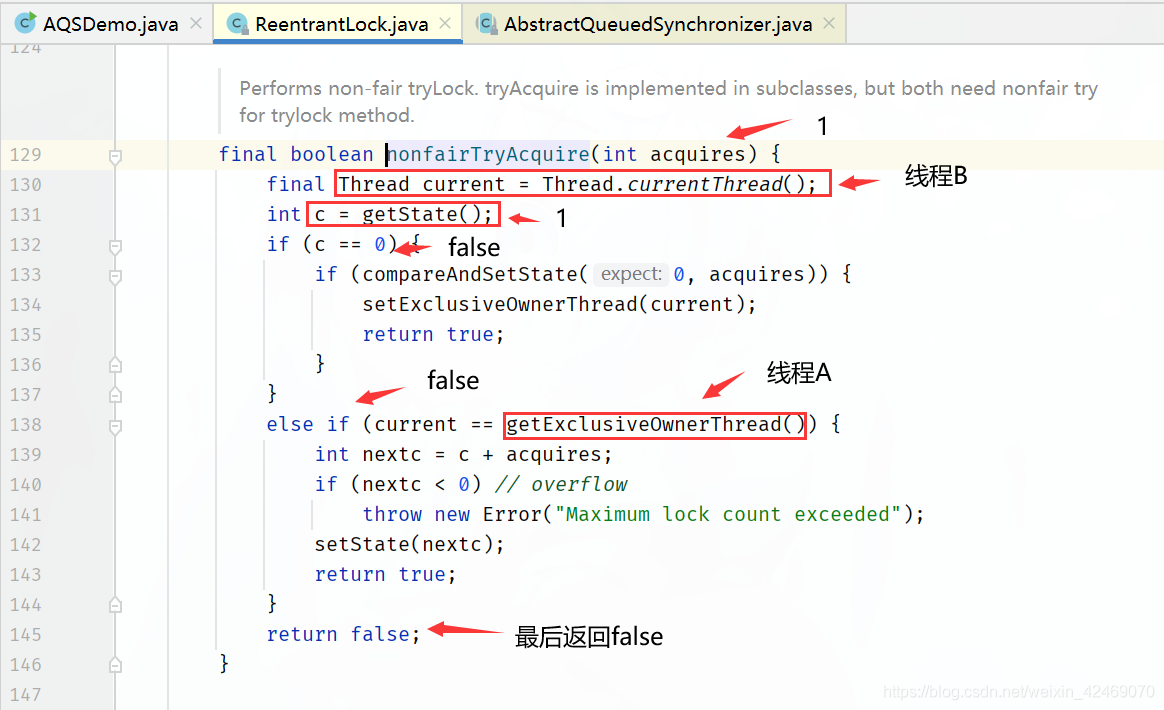
tryAcquire()方法返回false,最后执行 !false = true
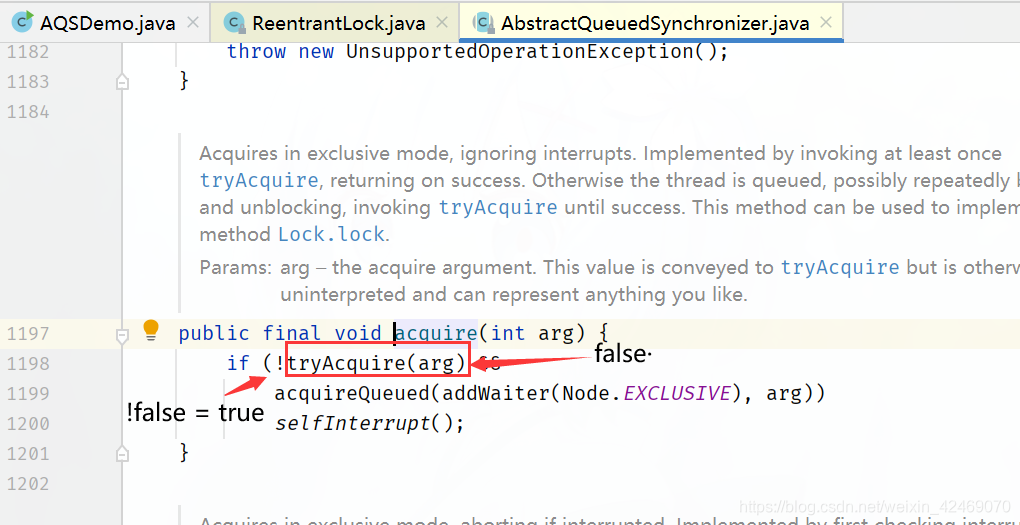
AQS源码深度解读04
线程B继续走第二个addWaiter()方法:
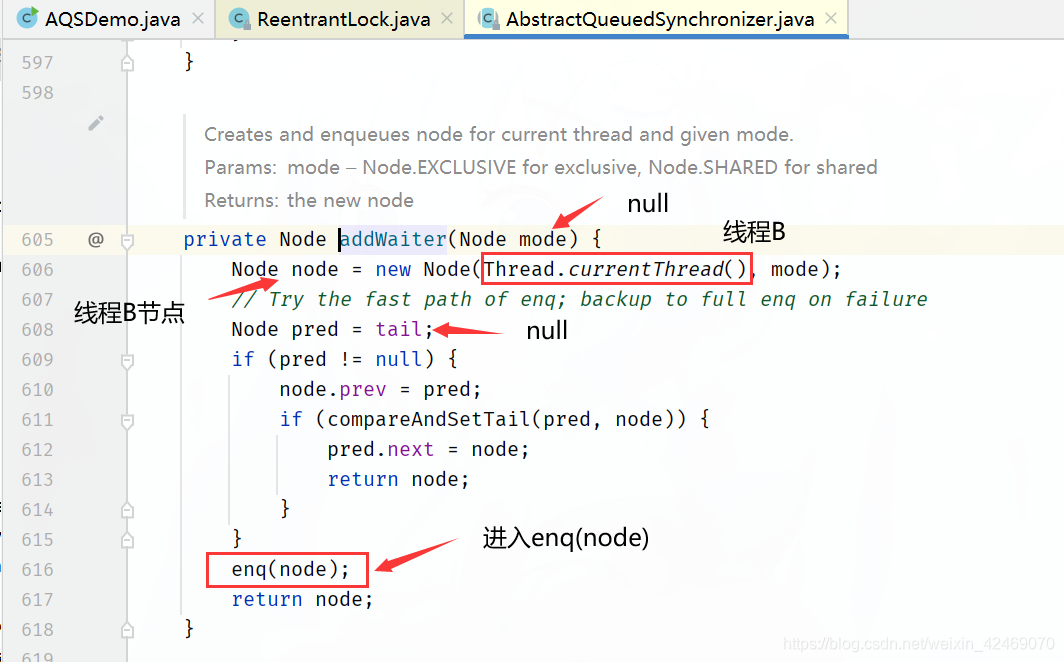
进入enq(node);方法

compareAndSetHead方法
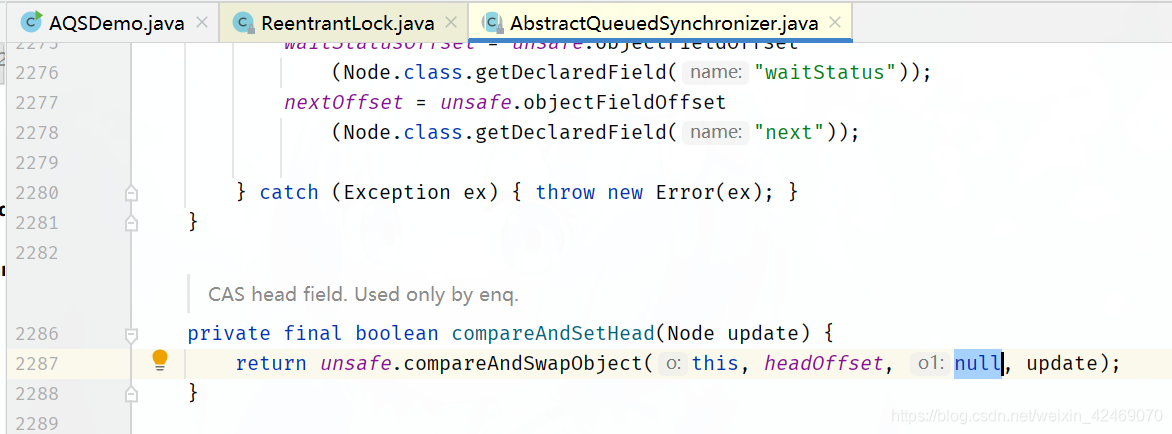
理解图:
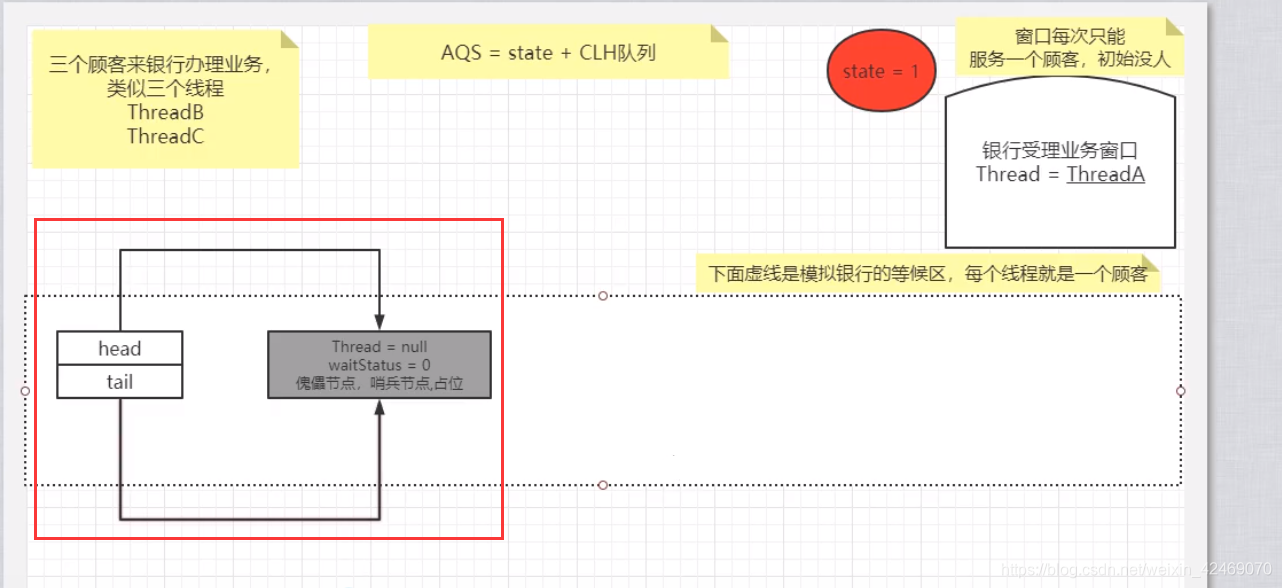
上述enq()方法for循环第一次循环是初始化node头尾信息(哨兵节点,占位)
继续执行循环第二次:

理解图:
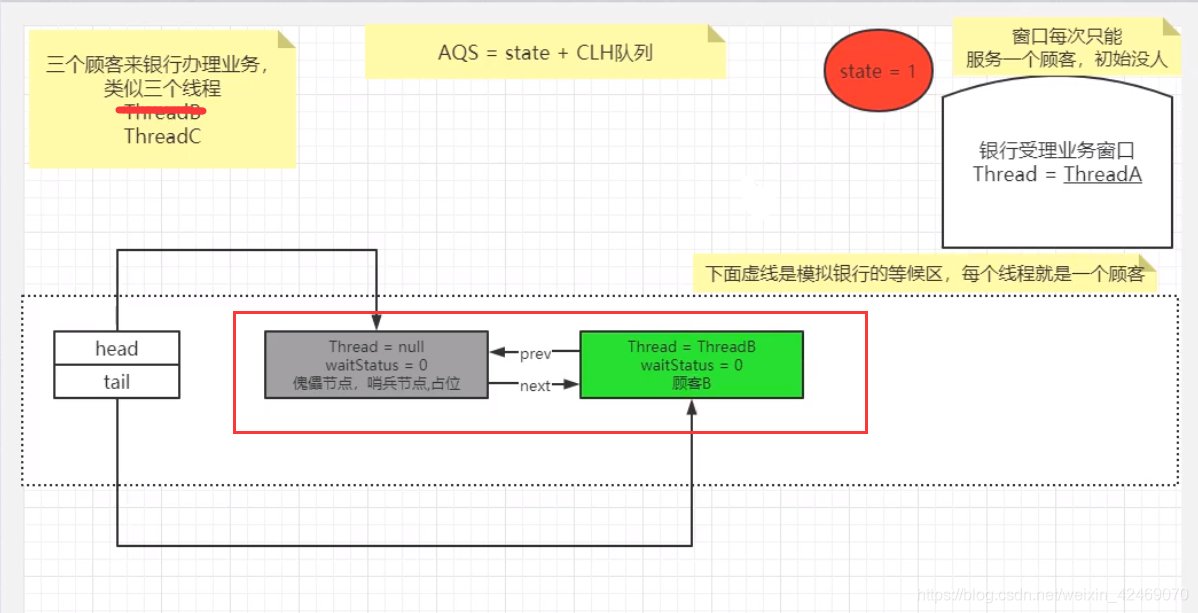
AQS源码深度解读05
同理:线程C的执行和线程B执行流程相同,但是在addWaiter()方法执行流程有点不同

理解图:
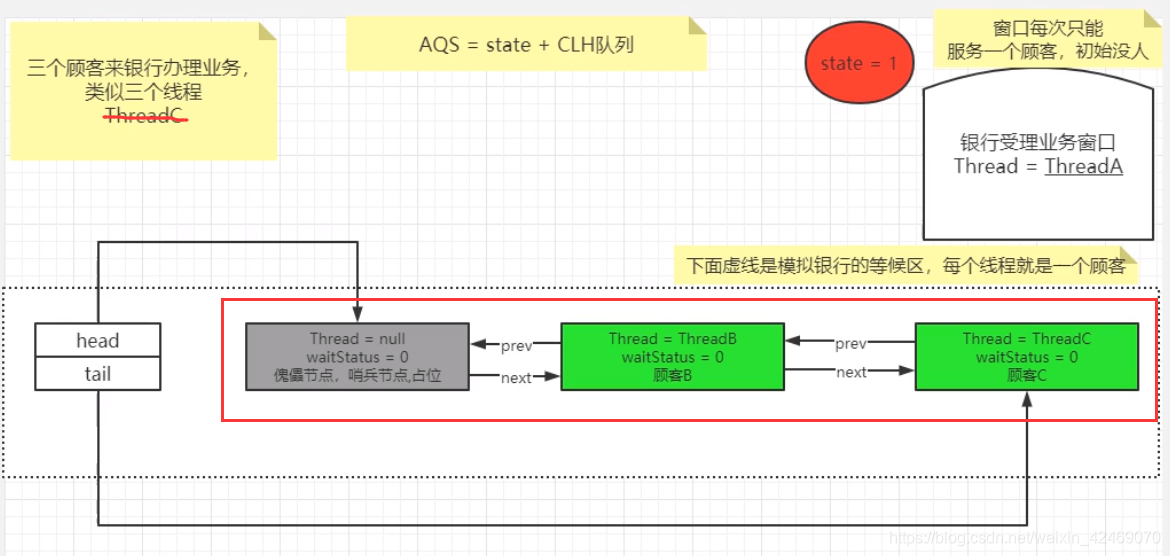
双向链表中,第一个节点为虚节点(也叫哨兵节点),其实并不存储任何信息,只是占位。真正的第一个有数据的节点,是从第二个节点开始的。
AQS源码深度解读06
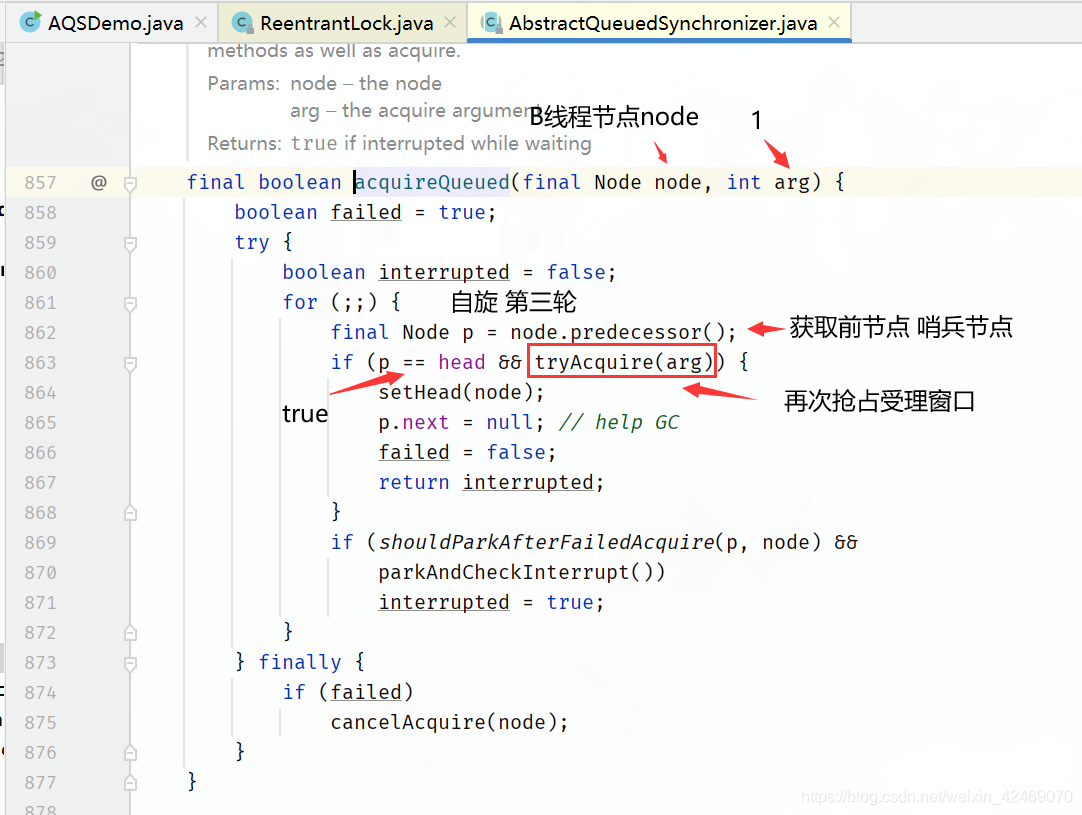
AbstractQueuedSynchronizer.acquire()方法里的执行第三个方法acquireQueued()
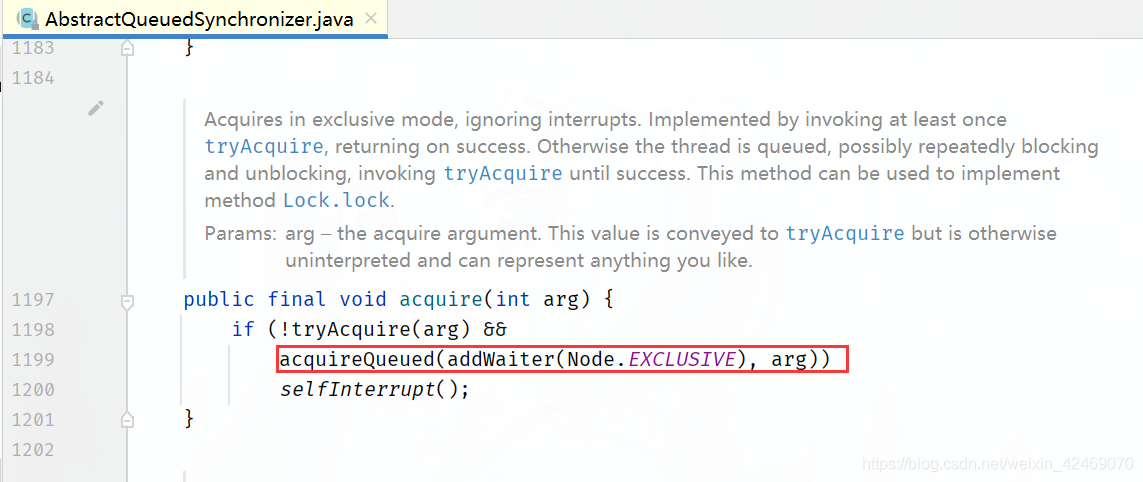
acquireQueued()方法
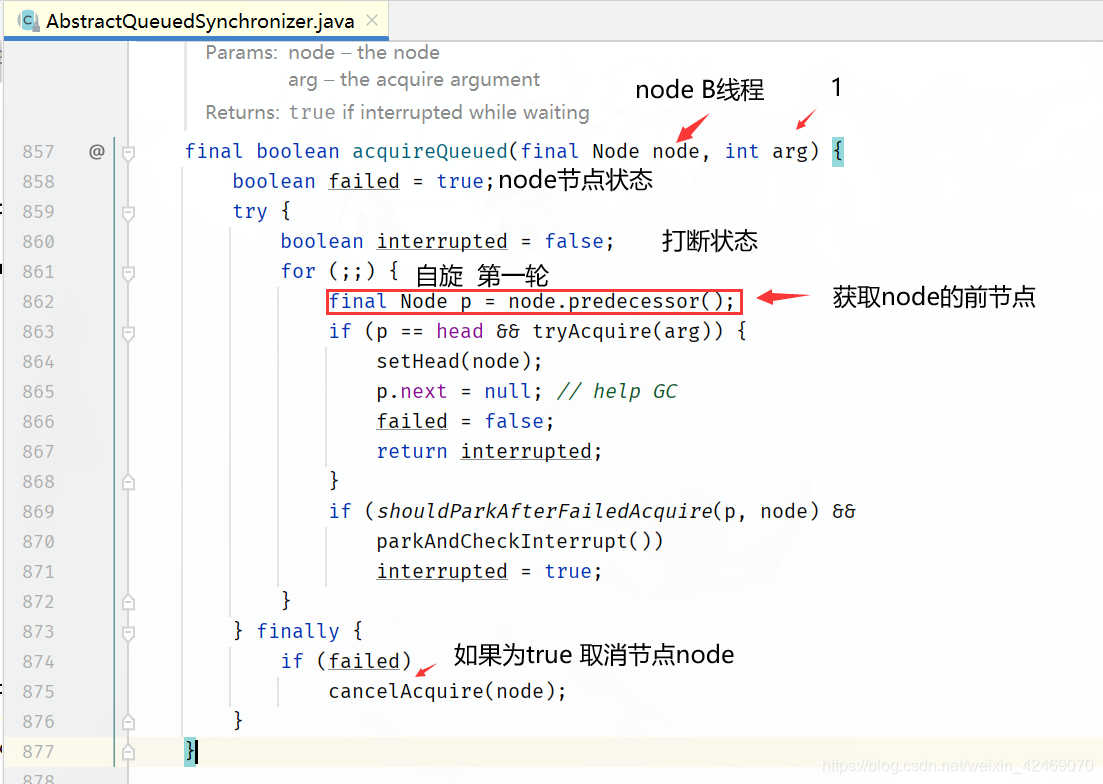
执行final Node p = node.predecessor();方法:

回到acquireQueued()方法for循环里
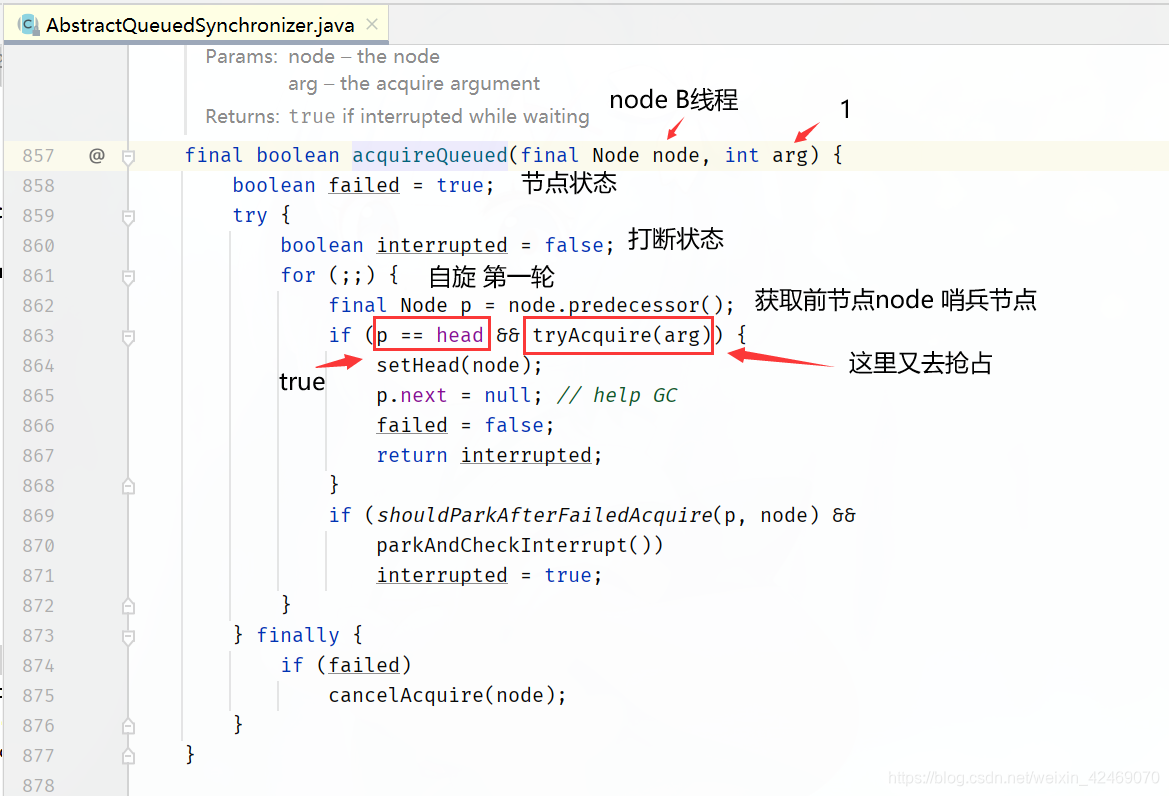
执行tryAcquire(arg)方法:
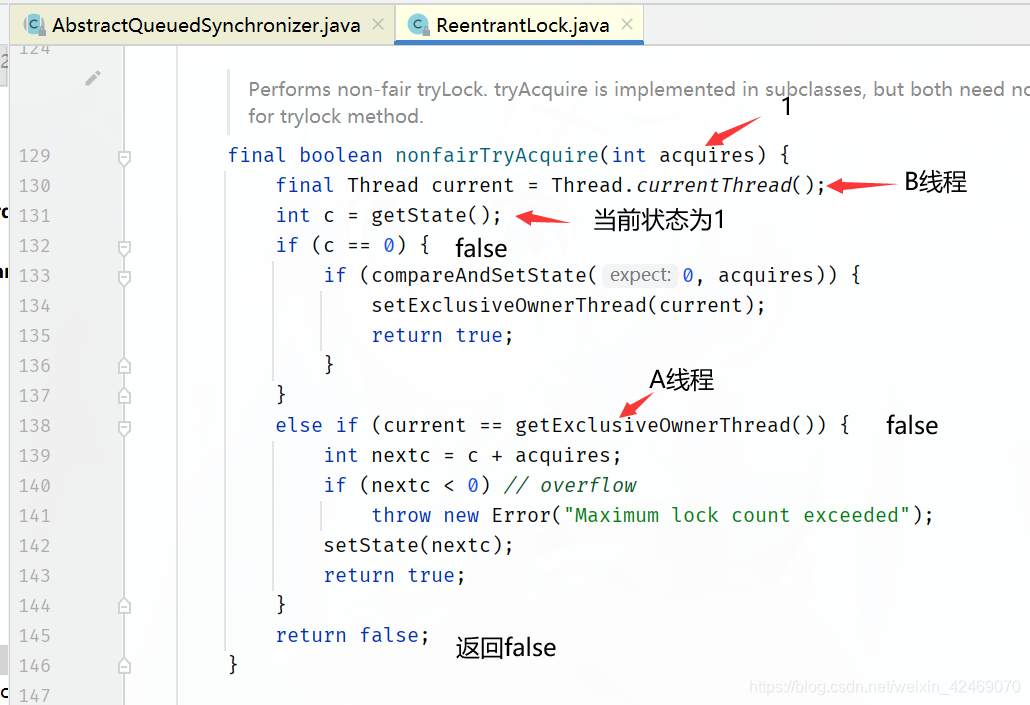
执行tryAcquire(arg)方法:

执行tryAcquire(arg)方法:
执行nonfairTryAcquire()方法:
回到acquireQueued()方法for循环里:
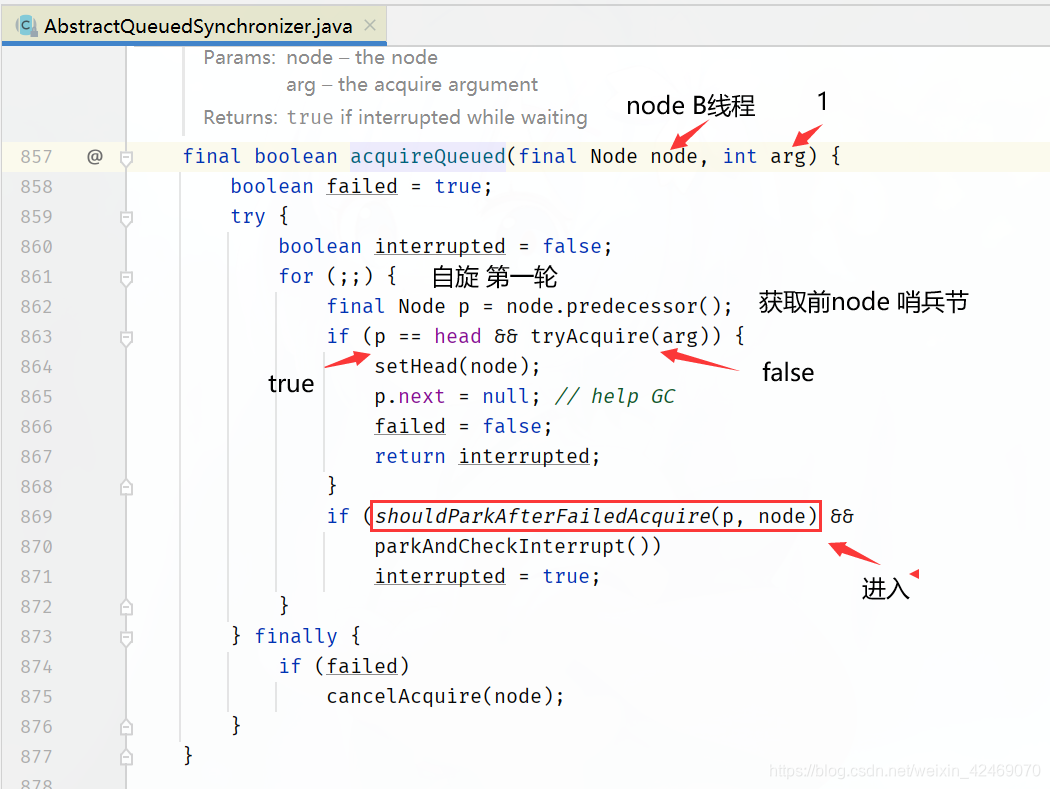
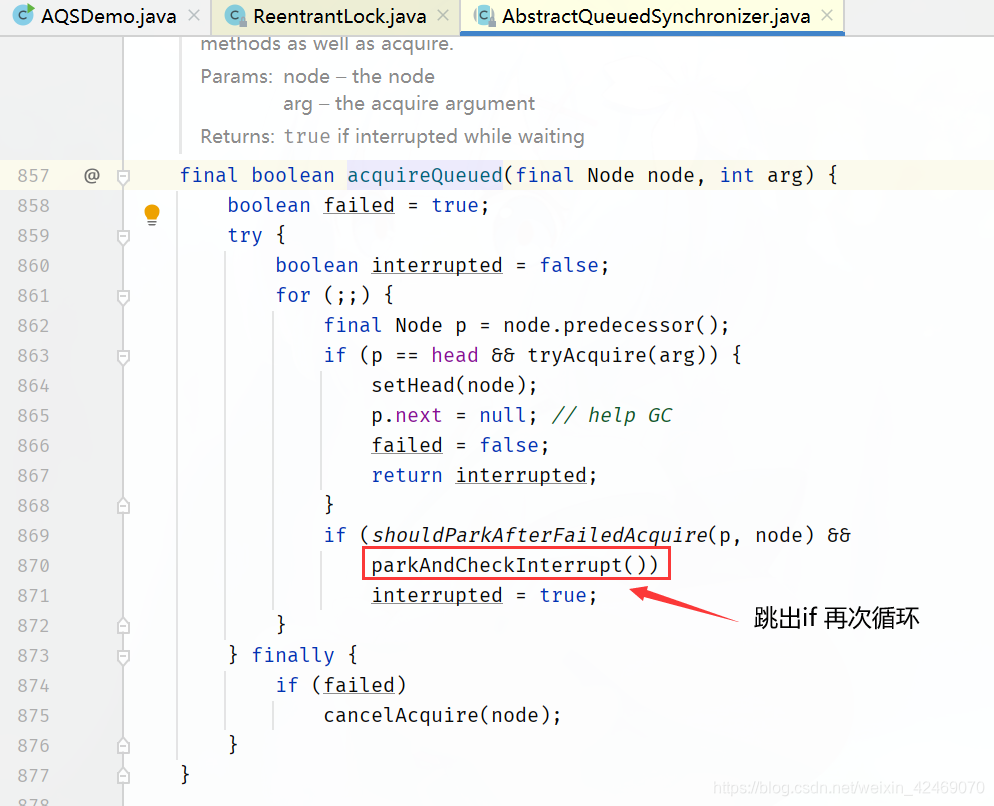
执行shouldParkAfterFailedAcquire(p, node)方法:
理解图:
回到acquireQueued()方法for循环里:
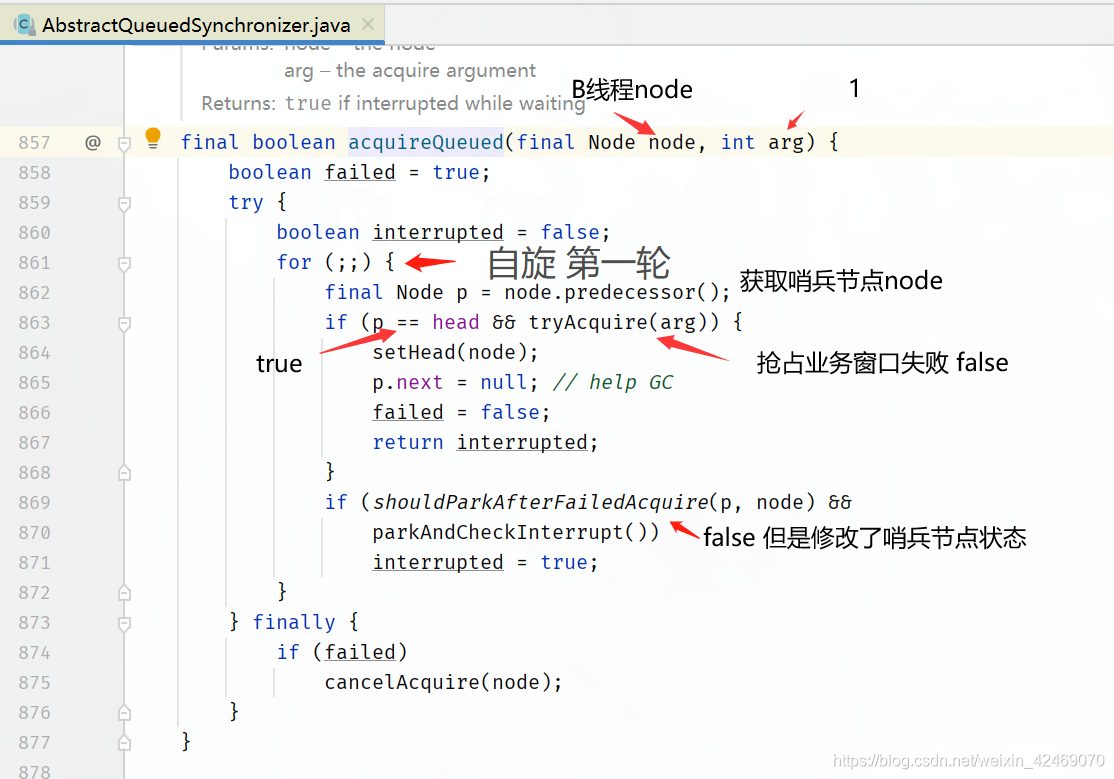
执行acquireQueued()方法for循环里:第二轮
执行shouldParkAfterFailedAcquire(p, node)方法:
回到acquireQueued()方法for循环里:
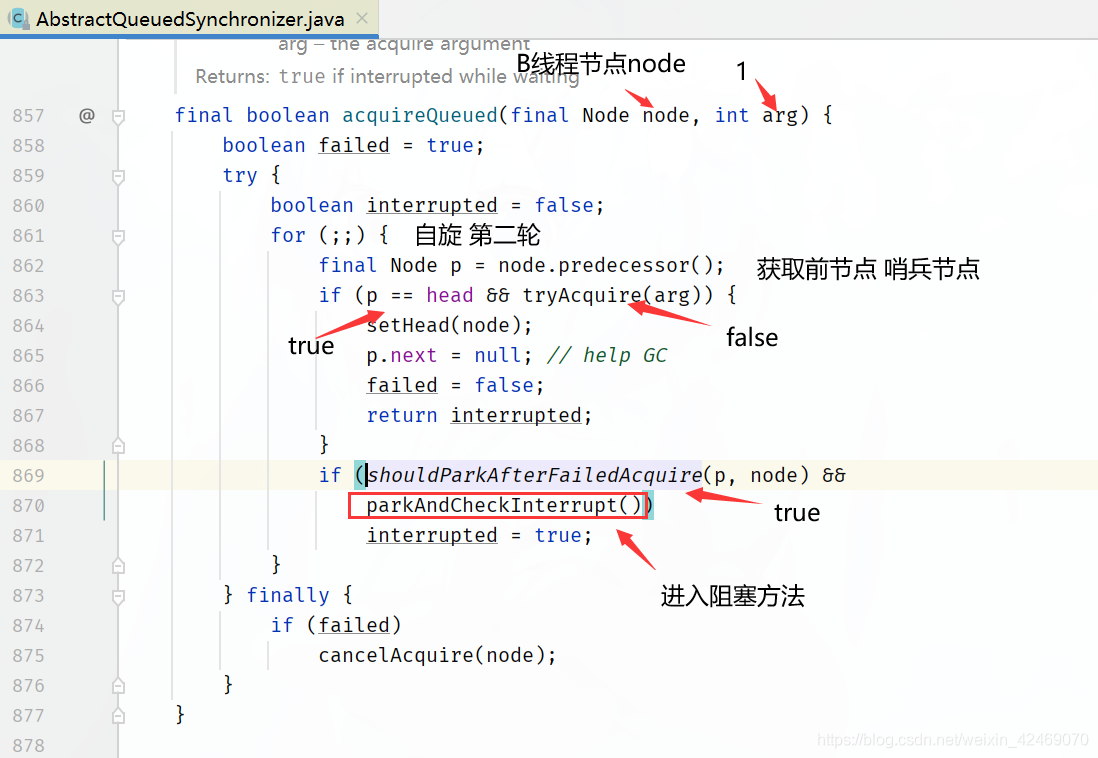
执行parkAndCheckInterrupt()方法:
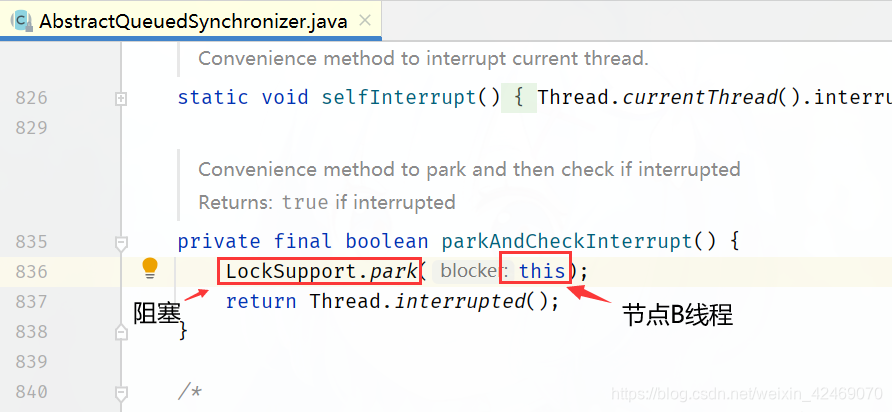
这里才真正入队列里(在候客区里)B线程被阻塞起来
回到acquireQueued()方法for循环里:
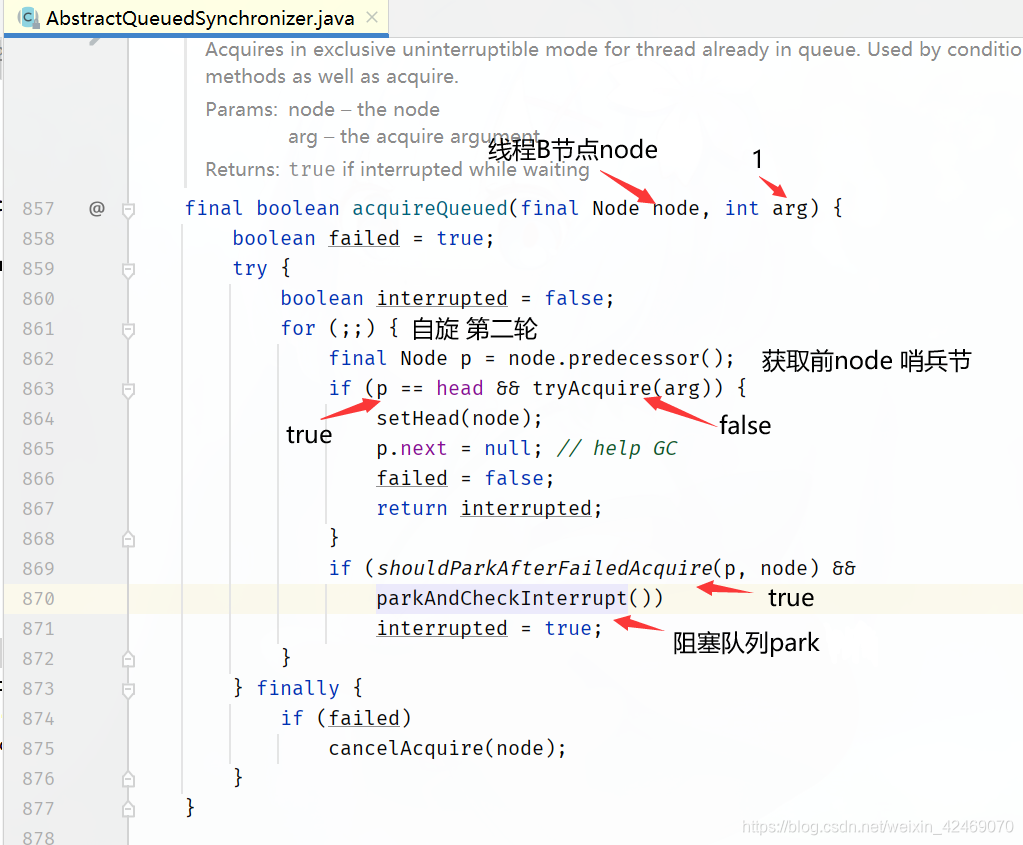
同理C线程进来也是同样操作LockSupport.park(this);被阻塞起来
B、C线程在parkAndCheckInterrupt()方法阻塞
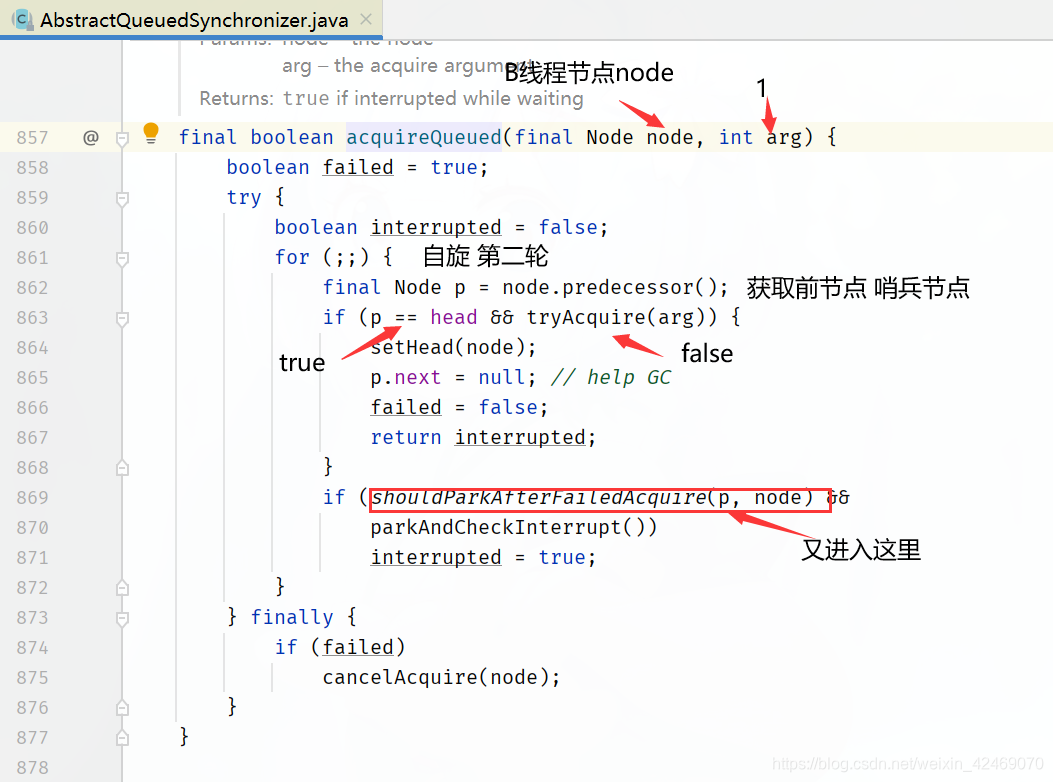
AQS源码深度解读07
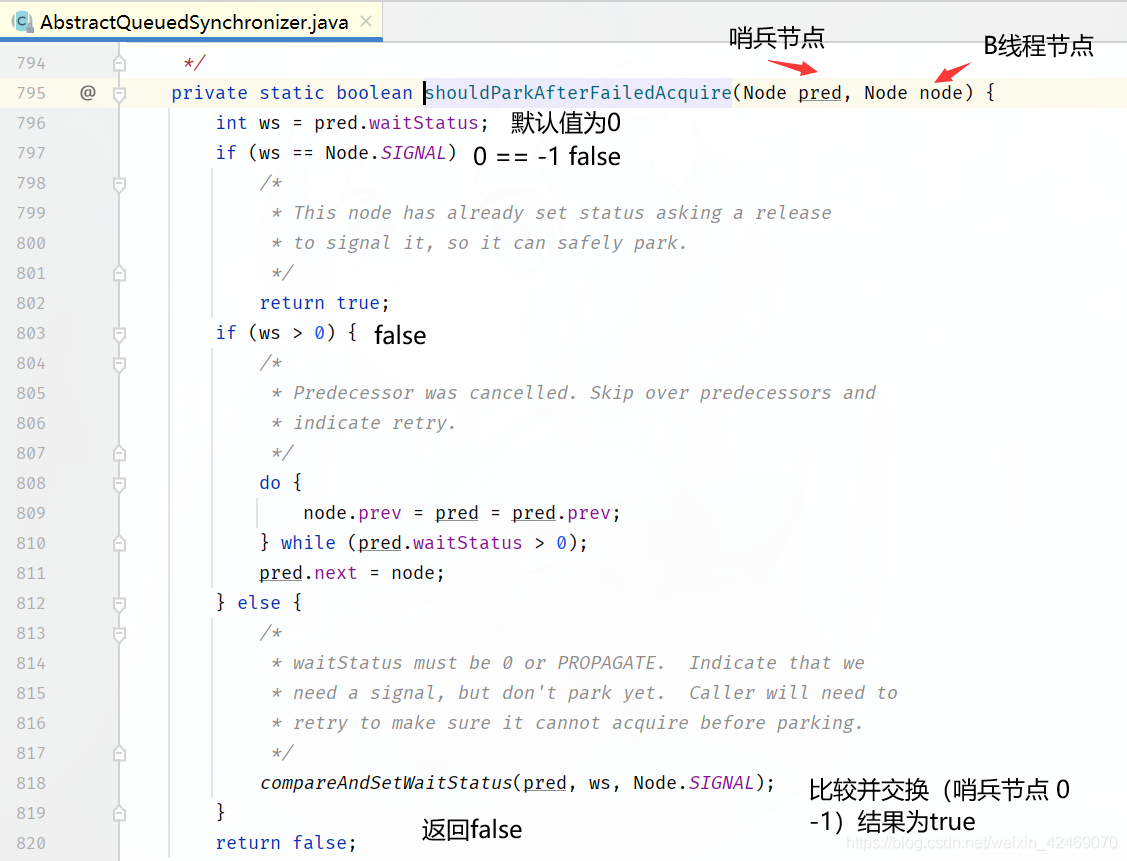
看看shouldParkAfterFailedAcquire(p, node)方法:
/**
* Checks and updates status for a node that failed to acquire.
* Returns true if thread should block. This is the main signal
* control in all acquire loops. Requires that pred == node.prev.
*
* @param pred node's predecessor holding status
* @param node the node
* @return {@code true} if thread should block
*/
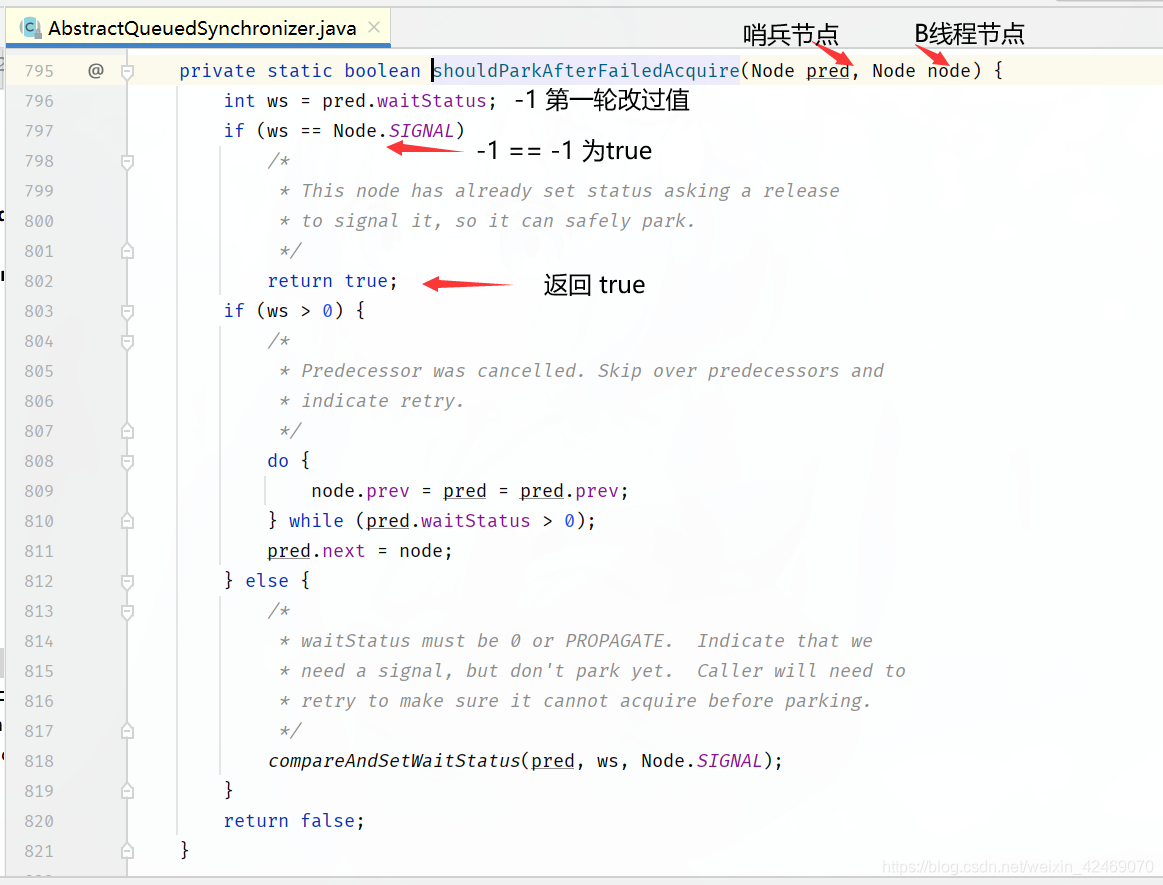
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
// 获取当前节点的状态
int ws = pred.waitStatus;
// 如果是 SIGNAL 状态(-1):即等待被占用的资源释放,直接返回true
// 准备继续调用 parkAndCheckInterrupt() 方法
if (ws == Node.SIGNAL)
return true;
// ws 大于0 说明是 CANCELLED 状态(线程取消了)
if (ws > 0) {
// 循环判断前驱节点的前驱节点是否为 CANCELLED 状态,忽略改状态的节点,重新连接队列
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
// 将当前节点的前驱节点设置为 SIGNAL 状态,用于后续唤醒操作
// 程序第一次执行到这里返回false,还会进行外层第二次循环,最终从代码第7行返回
AndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
如果前驱节点的 waitStatus 是SIGNAL 状态,即 shouldParkAfterFailedAcquire()方法返回 true
程序会继续向下执行 parkAndCheckInterrupt() 方法 ,用于将当前线程挂起
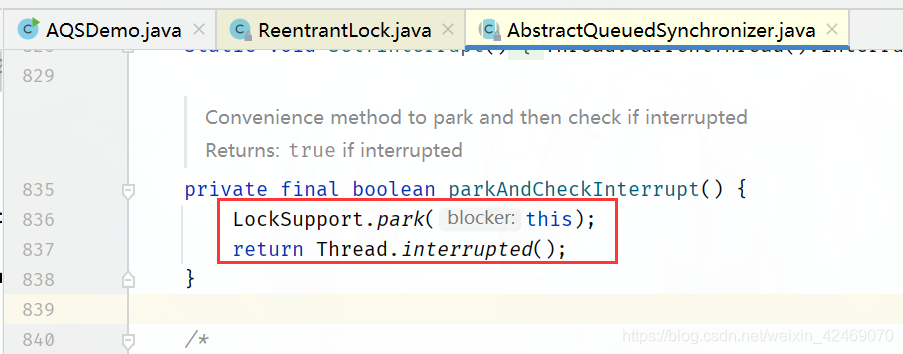
parkAndCheckInterrupt()方法
/**
* Convenience method to park and then check if interrupted
*
* @return {@code true} if interrupted
*/
private final boolean parkAndCheckInterrupt() {
// 线程挂起,程序不会继续向下执行
LockSupport.park(this);
// 根据 park 方法 API 描述,程序在下述三种情况会继续向下执行
// 1、被 unpark
// 2、被中断(interrupt)
// 3、其他不合逻辑的返回才会继续向下执行
// 因上述三种情况程序执行至此,返回当前线程的中断状态,并清空中断状态
// 如果由于被中断,改方法会返回 true
return Thread.interrupted();
}
终于,当线程A执行lock.unlock();方法:
//A顾客就是第一个顾客,此时受理窗口没有任何人,A可以直接去办理
new Thread(()->{
lock.lock();
try{
System.out.println(Thread.currentThread().getName() + "A thread come in");
//模拟办理业务时间 20 分钟
try { TimeUnit.MINUTES.sleep(20); } catch (InterruptedException e) { e.printStackTrace(); }
} finally {
lock.unlock();
}
}, "A").start();
进入ReentrantLock.unlock()方法
进入AbstractQueuedSynchronizer.release(int arg)方法:
进入tryRelease(arg)方法:
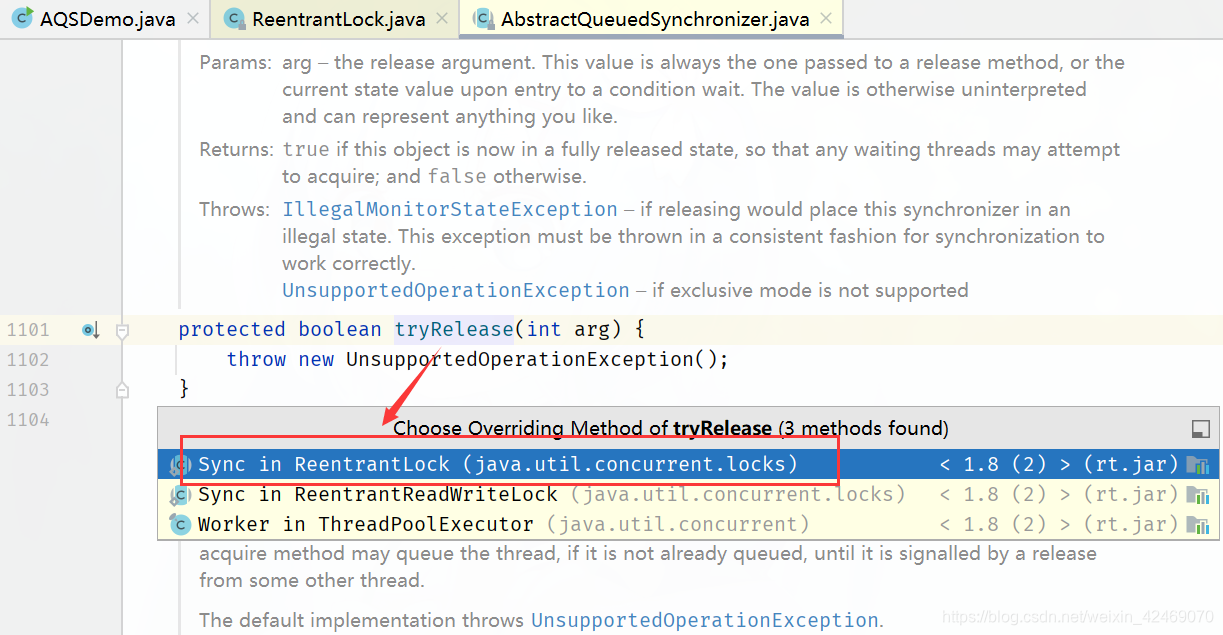
进入ReentrantLock.tryRelease(int releases)方法:
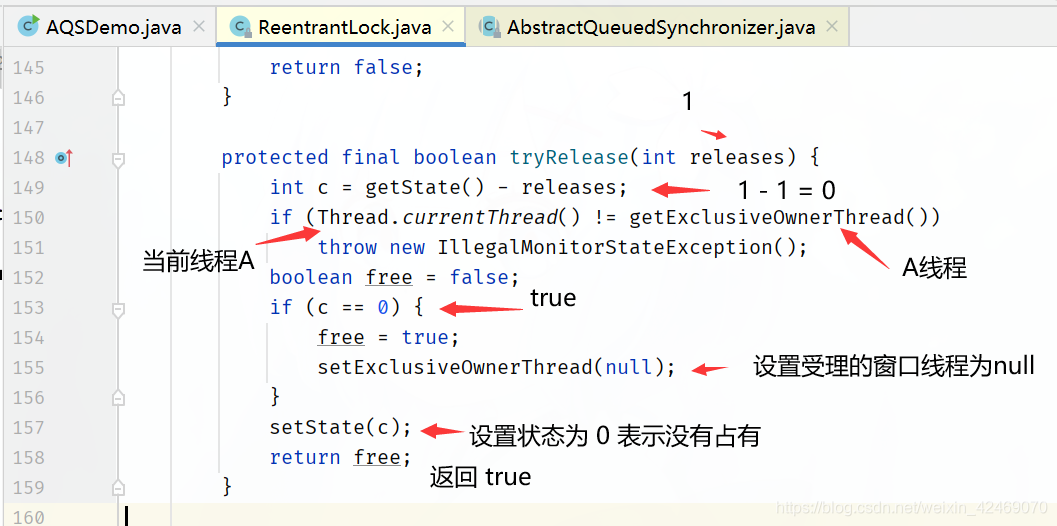
理解图:
返回AbstractQueuedSynchronizer.release(int arg)方法:
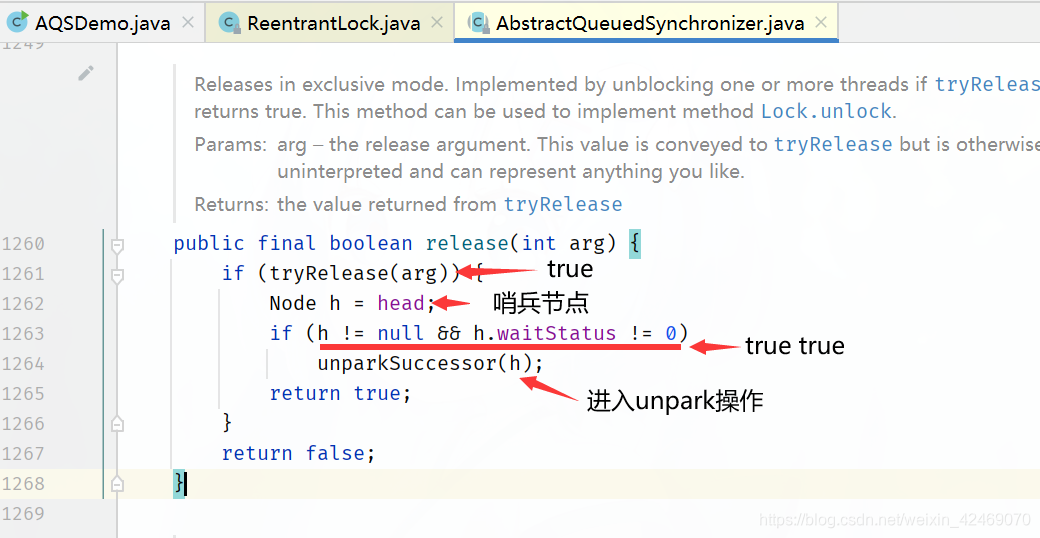
进入unparkSuccessor(h);方法:
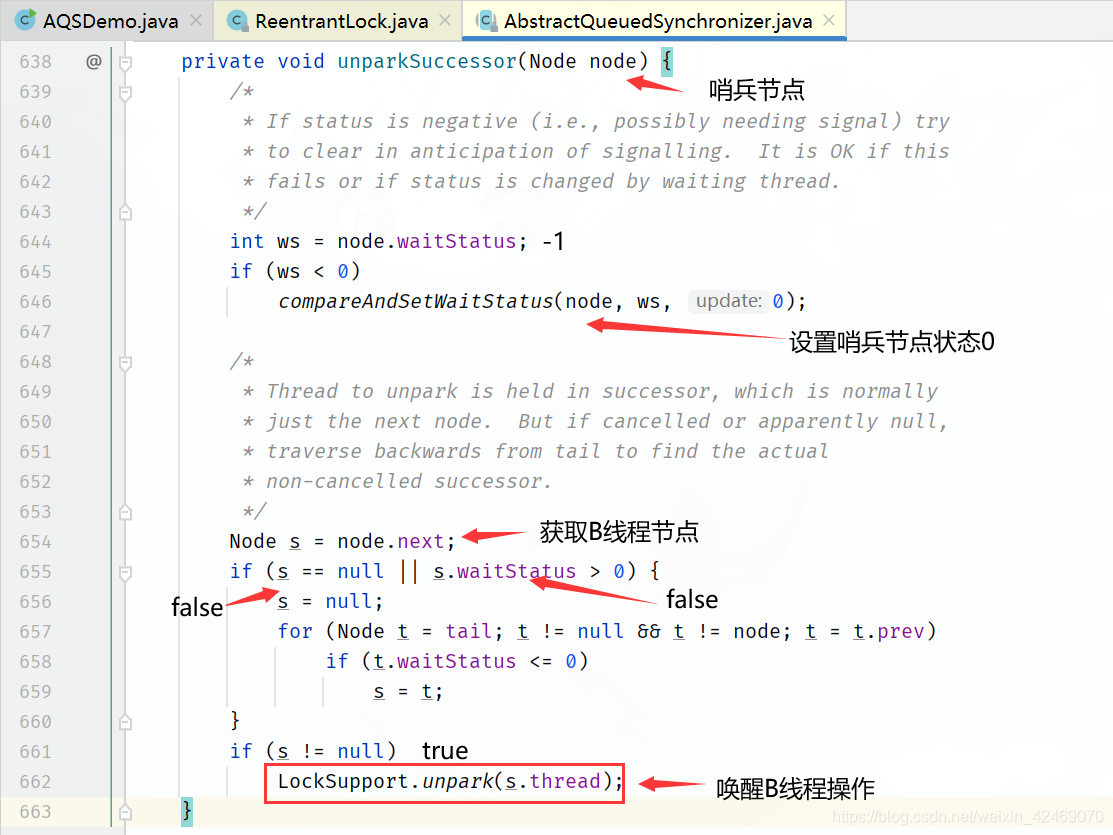
回到B线程被阻塞的parkAndCheckInterrupt()方法:
回到acquireQueued()方法for循环里:
进入tryAcquire(int arg)方法:
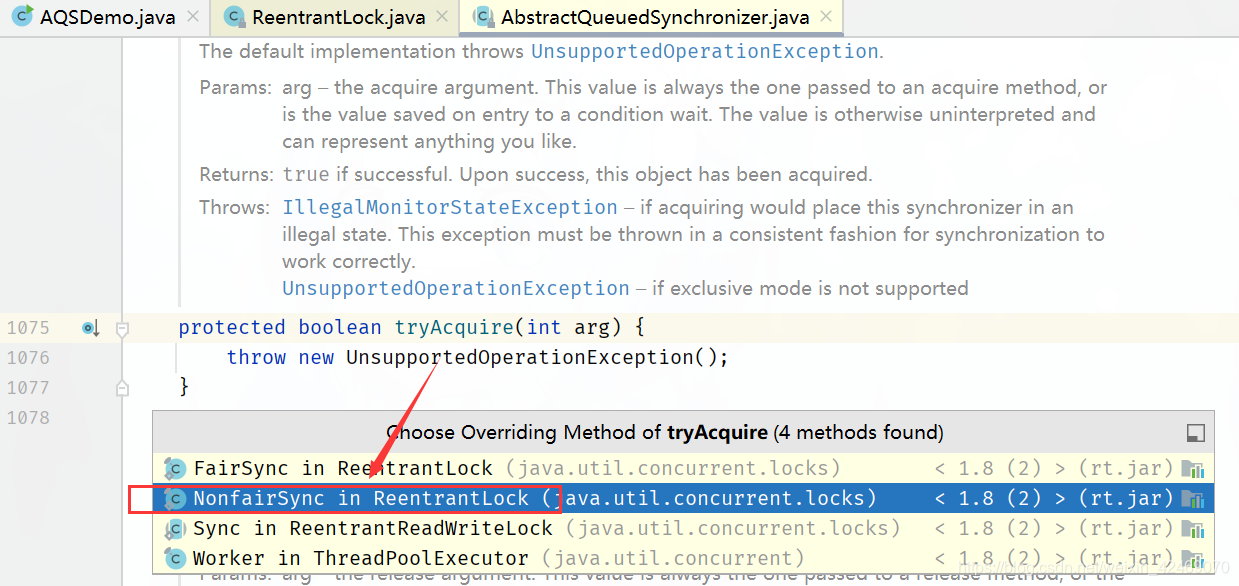
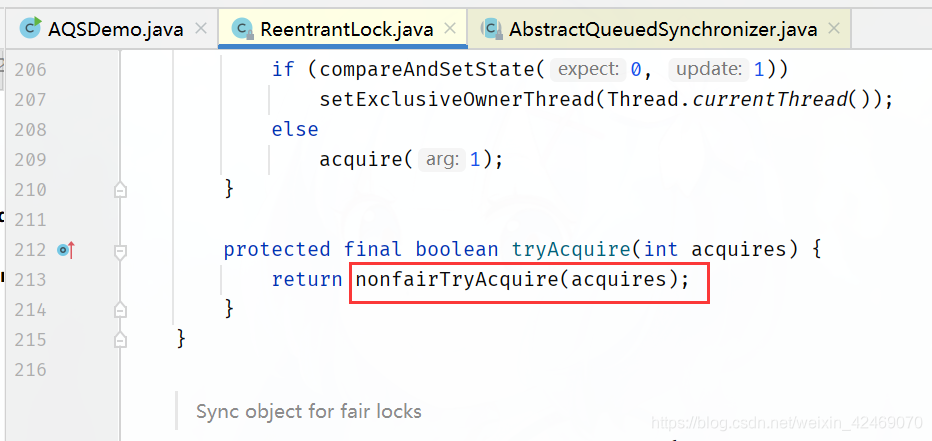
进入ReentrantLock.nonfairTryAcquire(acquires)方法:
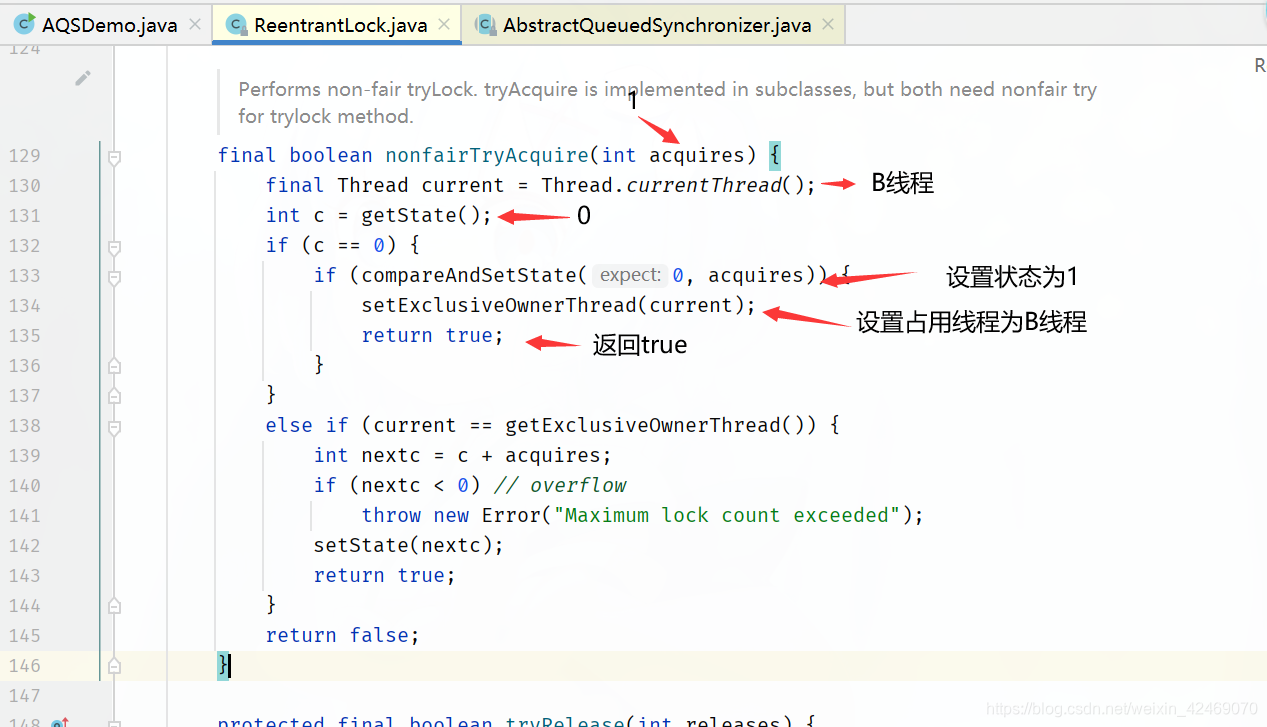
理解图:

回到acquireQueued()方法for循环里:
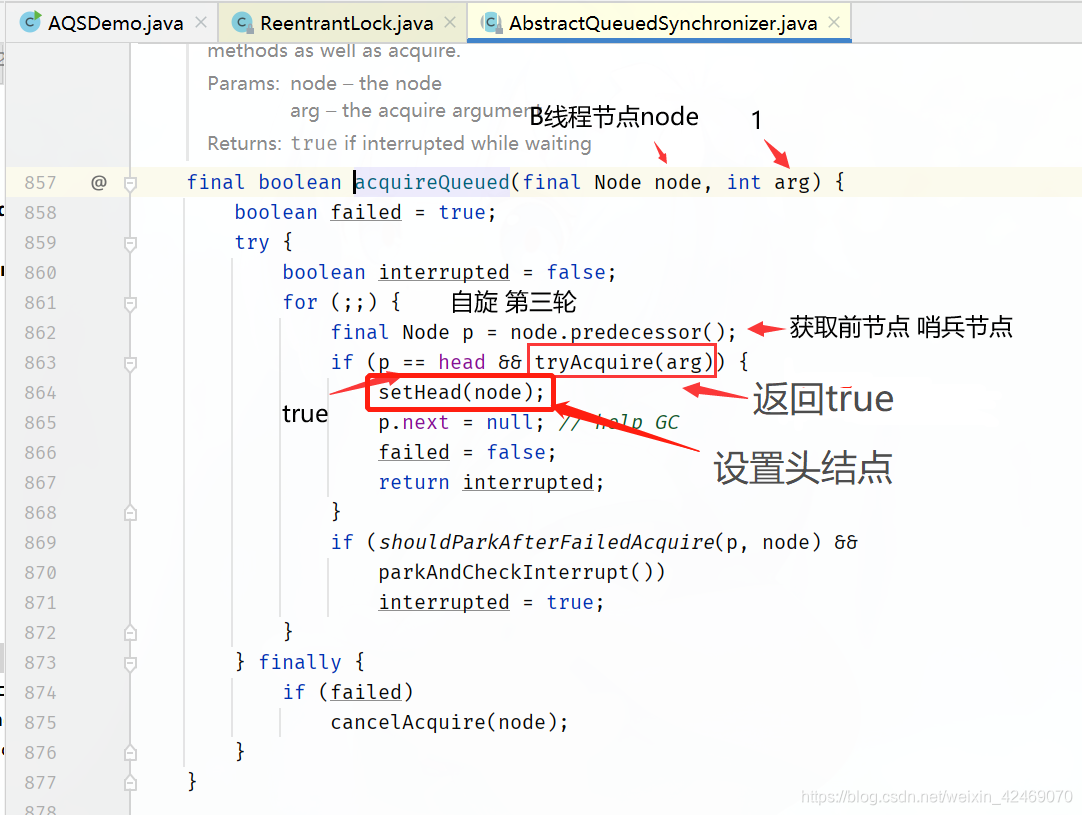
进入setHead(Node node)方法:
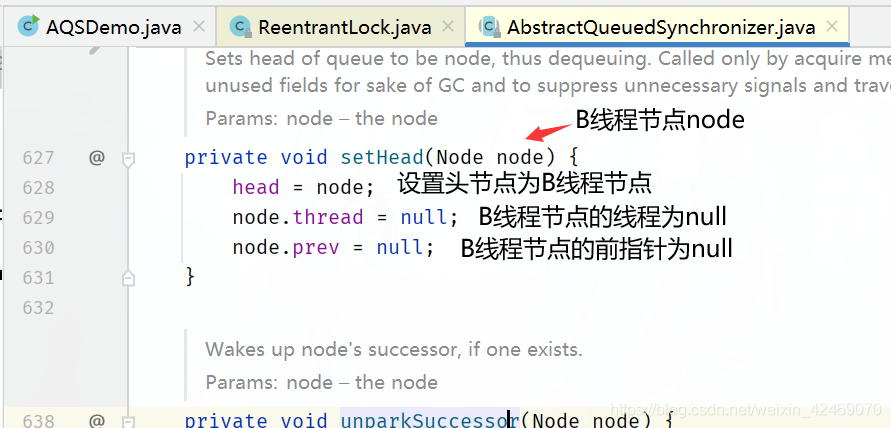
回到acquireQueued()方法for循环里:
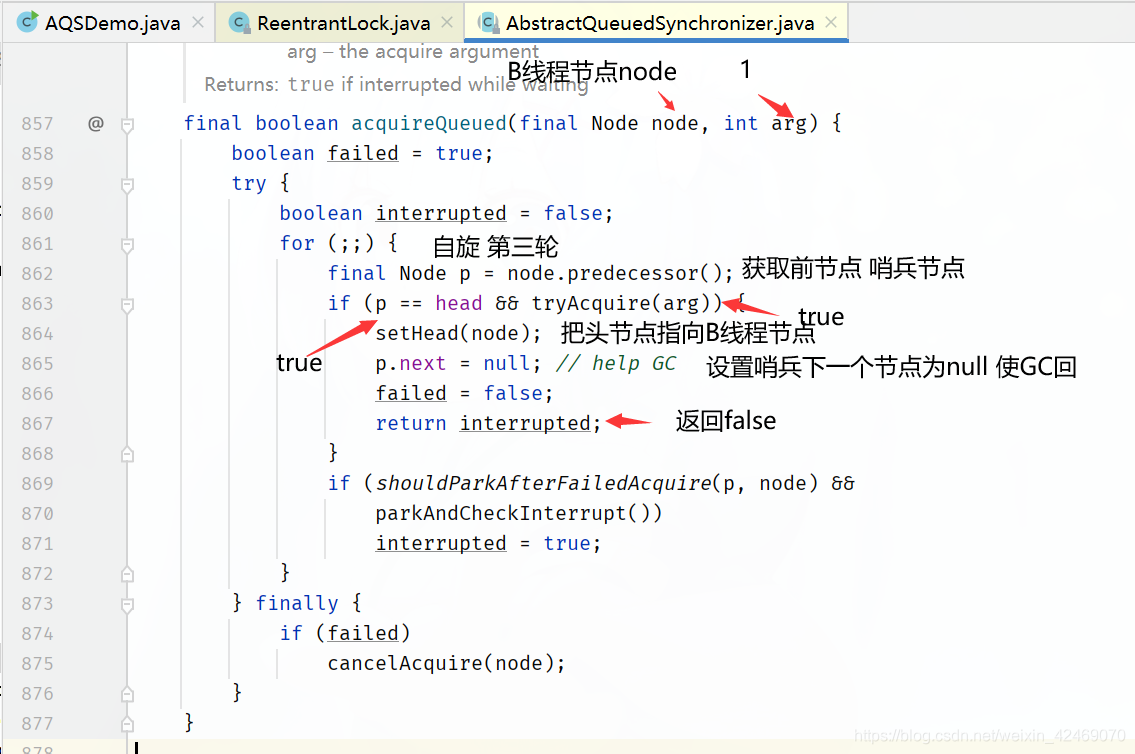
理解图:
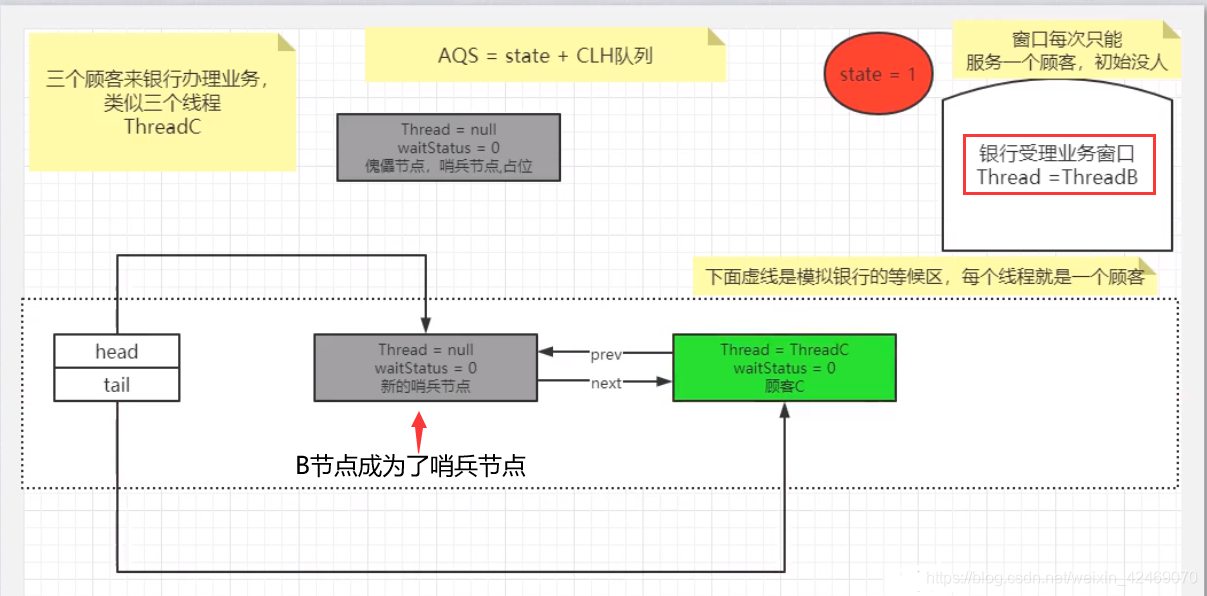
同理C线程也是同样的操作
三、Spring
Aop的题目说明要求
AOP常用注解:
Before前置通知:目标方法之前执行After后置通知:目标方法之后执行(始终执行)AfterReturning返回后通知:执行方法结束前执行(异常不执行)AfterThrowing异常通知:出现异常时候执行Around环绕通知:环绕目标方法执行
面试题:你肯定知道spring,那说说aop的全部通知顺序springboot或springboot2对aop的执行顺序影响?
说说你使用aop中碰到的坑?
spring4下的aop测试案例
新建springboot工程:
pom文件:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.5.19.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.zzp</groupId>
<artifactId>springboot4</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>testspringboot4</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!-- <version>1.5.9.RELEASE</version〉 ch/qos/Logback/core/joran/spi/JoranException解决方案-->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.1.3</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-access</artifactId>
<version>1.1.3</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.1.3</version>
</dependency>
<!-- wewb+actuator -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!-- jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.1.0</version>
</dependency>
<!-- Spring Boot AOP技术-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<!-- redisson -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.4</version>
</dependency>
<!-- 一般通用基础配置 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
这里使用 :spring4+springboot1.5.9
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.5.19.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
启动类:
@SpringBootApplication
public class MainApplication {
public static void main(String[] args) {
SpringApplication.run(MainApplication.class, args);
}
}
CalcService接口类:
public interface CalcService {
int div(int x, int y);
}
CalcServiceImpl实现类:添加@Service注解
@Service
public class CalcServiceImpl implements CalcService {
@Override
public int div(int x, int y) {
int result = x / y;
System.out.println("===>CalcServiceImpl被调用,计算结果为:" + result);
return result;
}
}
新建一个切面类MyAspect并为切面类新增两个注解:
@Aspect指定一个类为切面类@Component纳入Spring容器管理
MyAspect类code:
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.*;
import org.springframework.stereotype.Component;
@Aspect
@Component
public class MyAspect {
@Before("execution(public int com.zzp.springboot.service.Impl.CalcServiceImpl.*(..))")
public void beforeNotify(){
System.out.println("********* @Before我是前置通知");
}
@After("execution(public int com.zzp.springboot.service.Impl.CalcServiceImpl.*(..))")
public void afterNotify(){
System.out.println("********* @After我是后置通知");
}
@AfterReturning("execution(public int com.zzp.springboot.service.Impl.CalcServiceImpl.*(..))")
public void afterReturningNotify(){
System.out.println("********* @AfterReturning我是返回后通知");
}
@AfterThrowing("execution(public int com.zzp.springboot.service.Impl.CalcServiceImpl.*(..))")
public void afterThrowingNotify(){
System.out.println("********* @AfterThrowing我是异常通知");
}
@Around("execution(public int com.zzp.springboot.service.Impl.CalcServiceImpl.*(..))")
public Object aroundNotify(ProceedingJoinPoint proceedingJoinPoint) throws Throwable {
Object retValue = null;
System.out.println("********* @Around我是环绕通知之前AAA");
retValue = proceedingJoinPoint.proceed();
System.out.println("********* @Around我是环绕通知之后BBB");
return retValue;
}
}
在test包下添加测试类:
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.boot.SpringBootVersion;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.core.SpringVersion;
import org.springframework.test.context.junit4.SpringRunner;
import javax.annotation.Resource;
@SpringBootTest
@RunWith(SpringRunner.class)
public class AopTest {
@Resource
private CalcService calcService;
@Test
public void testAop4() {
System.out.println("spring版本: " + SpringVersion.getVersion() + "\t" + "springboot版本: " + SpringBootVersion.getVersion());
System.out.println("===========================================");
calcService.div(10, 2);
}
}
spring4下的aop测试结果
继续上一个测试案例
执行@Test:结果
spring版本: 4.3.22.RELEASE springboot版本: 1.5.19.RELEASE
===========================================
********* @Around我是环绕通知之前AAA
********* @Before我是前置通知
===>CalcServiceImpl被调用,计算结果为:5
********* @Around我是环绕通知之后BBB
********* @After我是后置通知
********* @AfterReturning我是返回后通知
修改测试类,让其算术异常:
calcService.div(10, 0);
执行结果:
spring版本: 4.3.22.RELEASE springboot版本: 1.5.19.RELEASE
===========================================
********* @Around我是环绕通知之前AAA
********* @Before我是前置通知
********* @After我是后置通知
********* @AfterThrowing我是异常通知
java.lang.ArithmeticException: / by zero
at com.zzp.springboot.service.Impl.CalcServiceImpl.div(CalcServiceImpl.java:11)
AOP执行顺序:
- 正常执行:@Before(前置通知) ==> @After(后置通知) ==> @AfterReturning(正常返回)
- 异常执行:@Before(前置通知) ==> @After(后置通知) ==> @AfterThrowing(方法异常)
spring5下的aop测试
修改pom文件 :spring5+springboot2.3.3
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.3.RELEASE</version>
<!-- <version>1.5.19.RELEASE</version>-->
<relativePath/> <!-- lookup parent from repository -->
</parent>
切换spring5+springboot2.3.3,test包有报错:
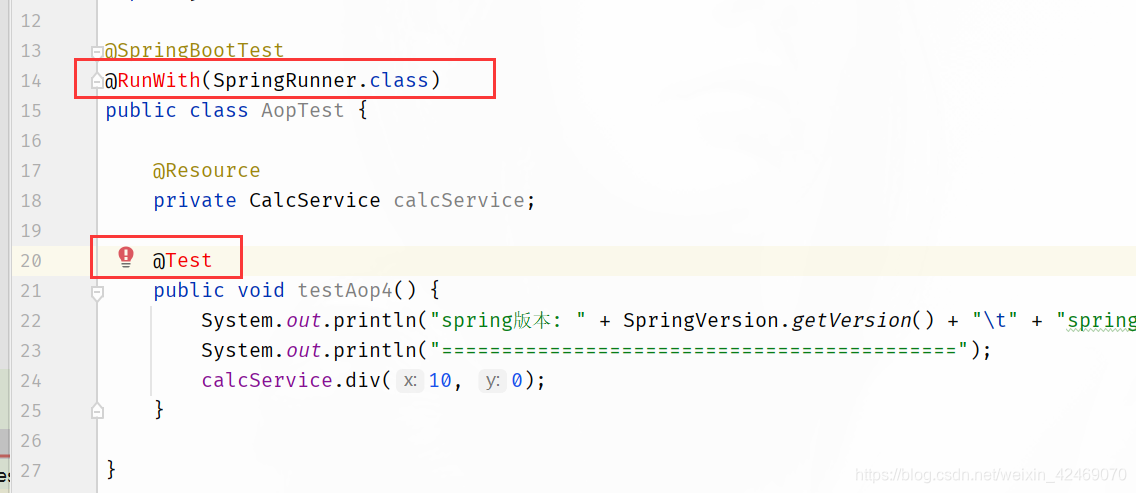
注释或者删除@RunWith(SpringRunner.class)注解
@Test注解使用 import org.junit.jupiter.api.Test;包
正常流程测试:
calcService.div(10, 2);
执行结果:
spring版本: 5.2.8.RELEASE springboot版本: 2.3.3.RELEASE
===========================================
********* @Around我是环绕通知之前AAA
********* @Before我是前置通知
===>CalcServiceImpl被调用,计算结果为:5
********* @AfterReturning我是返回后通知
********* @After我是后置通知
********* @Around我是环绕通知之后BBB
异常流程测试:
calcService.div(10, 0);
执行结果:
spring版本: 5.2.8.RELEASE springboot版本: 2.3.3.RELEASE
===========================================
********* @Around我是环绕通知之前AAA
********* @Before我是前置通知
********* @AfterThrowing我是异常通知
********* @After我是后置通知
java.lang.ArithmeticException: / by zero
at com.zzp.springboot.service.Impl.CalcServiceImpl.div(CalcServiceImpl.java:11)
AOP执行顺序:
- 正常执行:@Before(前置通知) ==> @AfterReturning(正常返回) ==>@After(后置通知)
- 异常执行:@Before(前置通知) ==> @AfterThrowing(方法异常) ==>@After(后置通知)
spring循环依赖题目说明
什么是循环依赖?
多个bean之间相互依赖,形成了一个闭环。
比如:A依赖于B、B依赖于C、C依赖于A。
代码示例:
public class T1 {
class A{
B b;
}
class B{
C c;
}
class C{
A a;
}
}
通常来说,如果问Spring容器内部如何解决循环依赖,一定是指默认的单例Bean中,属性互相引用的场景。
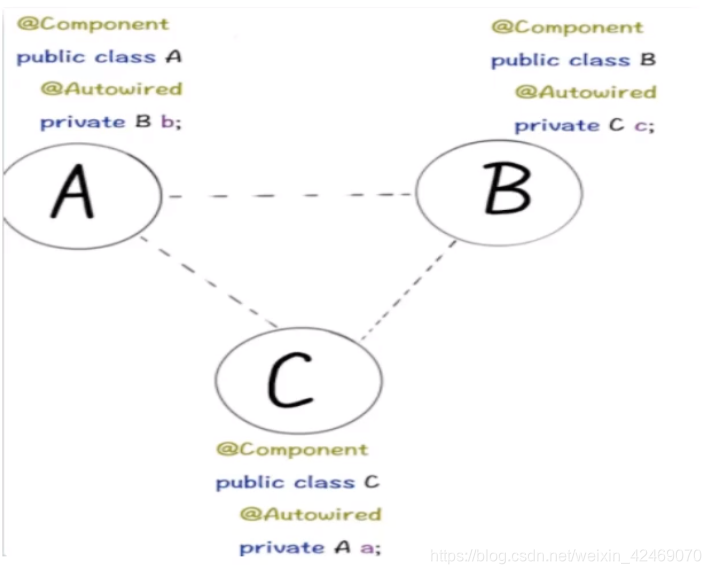
两种注入方式对循环依赖的影响
翻译:

结论:
我们AB循环依赖问题只要A的注入方式是setter且singleton,就不会有循环依赖问题。
spring循环依赖纯java代码验证案例
Spring容器循环依赖报错演示BeanCurrentlyInCreationException
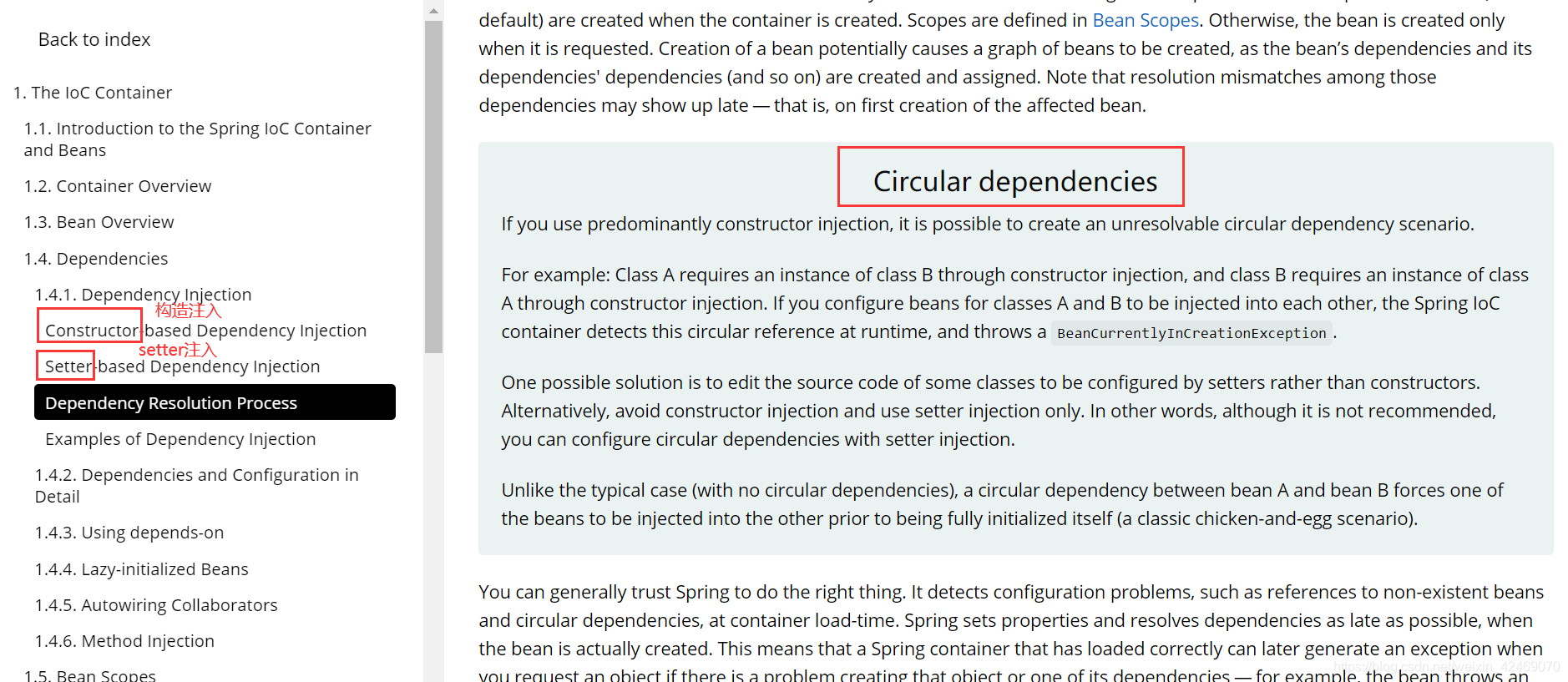
官网说明:循环依赖现象在spring容器中注入依赖的对象,有2种情况
- 构造器方式注入依赖(不可行)
- 以set方式注入依赖(可行)
构造器方式注入依赖:
代码演示:
ServiceA类:
@Component
public class ServiceA {
private ServiceB serviceB;
public ServiceA(ServiceB serviceB){
this.serviceB = serviceB;
}
}
ServiceB类:
@Component
public class ServiceB {
private ServiceA serviceA;
public ServiceB(ServiceA serviceA){
this.serviceA = serviceA;
}
}
ClientConstructor类:
public class ClientConstructor {
public static void main(String[] args){
new ServiceA(new ServiceB(new ServiceA()));
}
}
但是ClientConstructor类编译报错:
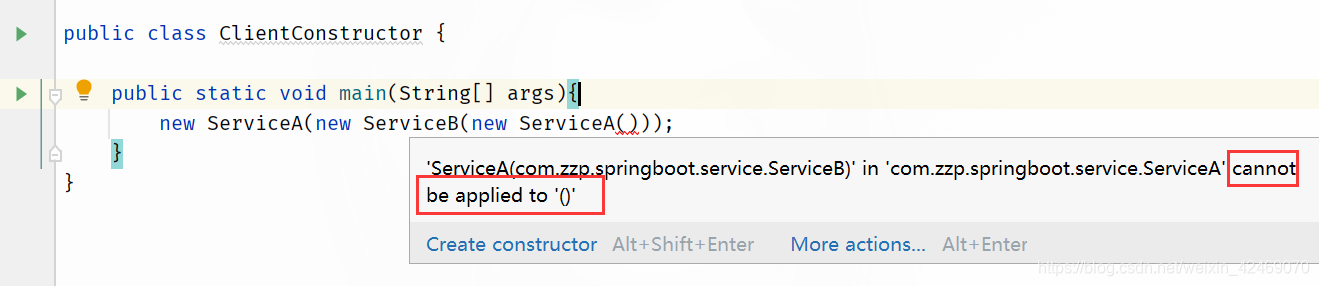
上述结论:
构造器循环依赖是无解的,
你想让构造器注入支持循环依赖,是不存在的
就像俄罗斯套娃娃:

以set方式注入依赖
ServiceAA类:
@Component
public class ServiceAA {
private ServiceBB serviceBB;
public void setServiceBB(ServiceBB serviceBB){
this.serviceBB = serviceBB;
System.out.println("AA 里面设置了 BB");
}
}
ServiceBB类:
@Component
public class ServiceBB {
private ServiceAA serviceAA;
public void setServiceAA(ServiceAA serviceAA){
this.serviceAA = serviceAA;
System.out.println("BB 里面设置了 AA");
}
}
ClientSet类:
public class ClientSet {
public static void main(String[] args){
//创建serviceAA
ServiceAA a = new ServiceAA();
//创建serviceBB
ServiceBB b = new ServiceBB();
//将serviceA入到serviceB中
b.setServiceAA(a);
//将serviceB法入到serviceA中
a.setServiceBB(b);
}
}
执行结果:
BB 里面设置了 AA
AA 里面设置了 BB
spring循环依赖bug演示
code-java基础编码演示:
A类:
public class A {
private B b;
public B getB(){
return b;
}
public void setB(B b){
this.b = b;
}
public A(){ // A 无参构造
System.out.println("---A created success");
}
}
B类:
public class B {
private A a;
public A getA() {
return a;
}
public void setA(A a) {
this.a = a;
}
public B(){ // B无参构造
System.out.println("---B created success");
}
}
ClientCode类:
public class ClientCode {
public static void main(String[] args) {
A a = new A();
B b = new B();
b.setA(a);
a.setB(b);
}
}
执行结果:
---A created success
---B created success
spring容器演示:
先引入spring容器applicationContext.xml文件:
<?xml version="1.0" encoding="UTF-8" ?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-4.0.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-4.0.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-4.0.xsd">
<bean id="a" class="com.zzp.springboot.service.A" scope="singleton">
<property name="b" ref="b"/>
</bean>
<bean id="b" class="com.zzp.springboot.service.B" scope="singleton">
<property name="a" ref="a"/>
</bean>
</beans>
bean 属性的scope="singleton"默认是单例
ClientSpringContainer测试类:
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class ClientSpringContainer {
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
A a = context.getBean("a",A.class);
B b = context.getBean("b",B.class);
}
}
执行结果:
20:44:20.324 [main] DEBUG o.s.c.s.ClassPathXmlApplicationContext - Refreshing org.springframework.context.support.ClassPathXmlApplicationContext@33a10788
20:44:20.473 [main] DEBUG o.s.b.f.xml.XmlBeanDefinitionReader - Loaded 2 bean definitions from class path resource [applicationContext.xml]
20:44:20.502 [main] DEBUG o.s.b.f.s.DefaultListableBeanFactory - Creating shared instance of singleton bean 'a'
---A created success
20:44:20.516 [main] DEBUG o.s.b.f.s.DefaultListableBeanFactory - Creating shared instance of singleton bean 'b'
---B created success
修改applicationContext.xml 的bean属性scope="prototype"
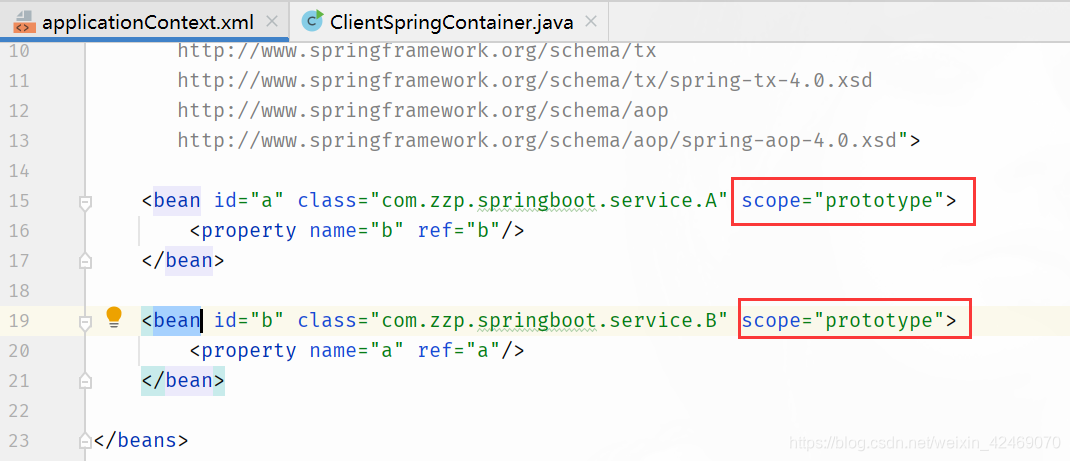
再执行ClientSpringContainer测试类:结果抛出BeanCurrentlyInCreationException异常

小结论:
-
默认的单例(Singleton)的场景是支持循环依赖的,不报错
-
原型(Prototype)的场景是不支持循环依赖的,会报错
重要结论(spring内部通过3级缓存来解决循环依赖)
DefaultSingletonBeanRegistry
第一级缓存(也叫单例池)singletonObjects:存放已经经历了完整生命周期的 Bean 对象
第二级缓存:earlySingletonObjects,存放早期暴露出来的 Bean 对象,Bean 的生命周期未结束(属性还未填充完)
第三级缓存:Map<String, ObjectFactory<?>> singletonFactories,存放可以生成 Bean 的工厂
源码:
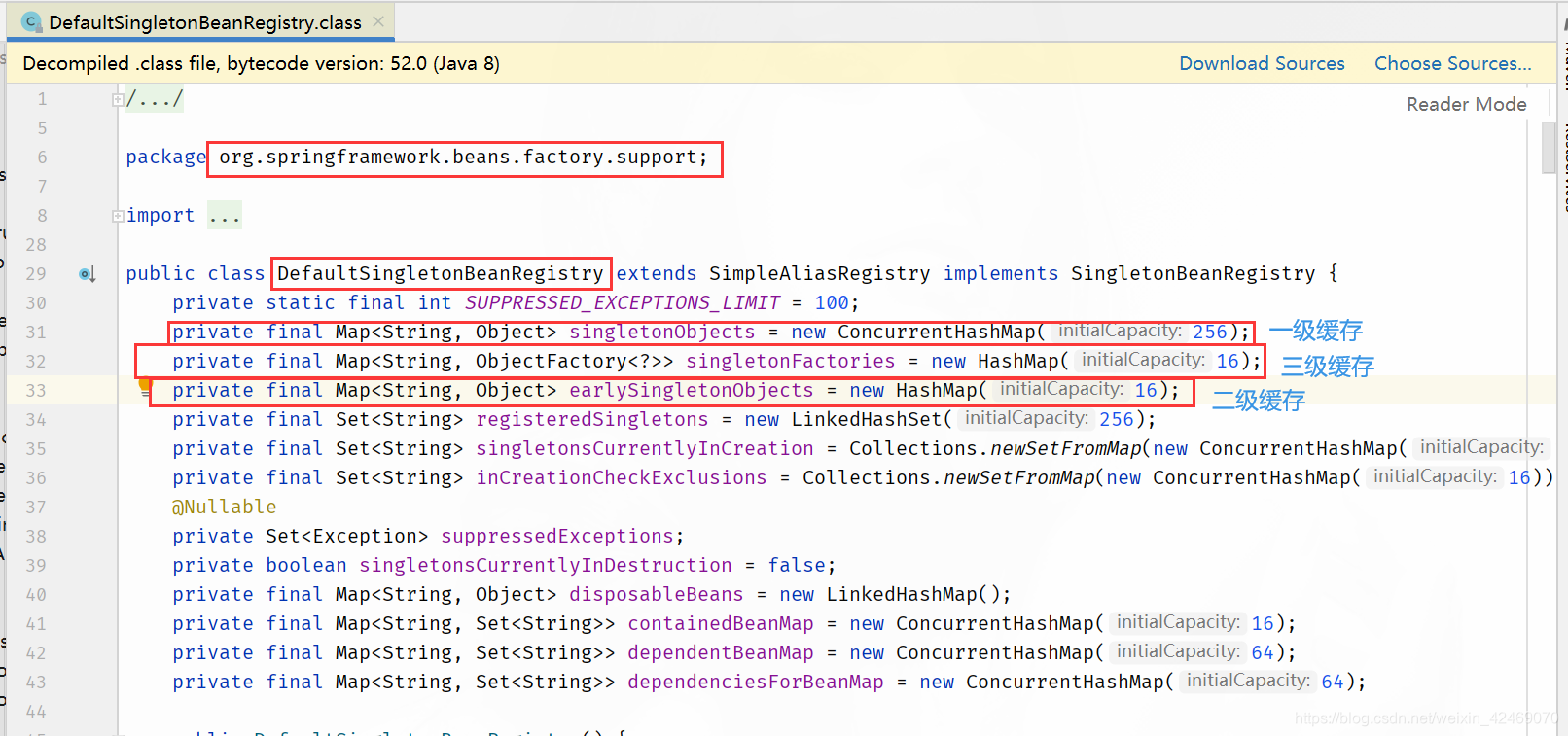
只有单例的 bean 会通过三级缓存提前暴露来解决循环依赖的问题,而非单例的 bean,每次从容器中获取一个对象,都会重新创建,所以非单例的 bean是没有缓存的,不会将其放到三级缓存中。
spring循环依赖debug前置知识
-
实例化:
内存中申请一块内存空间(new 对象)
比如:租赁好房子,自己的家具东西还没有搬家进去 -
初始化属性填充
完成属性的各种赋值
比如:装修、家电家具进场
3个Map和四大方法,总体相关对象:
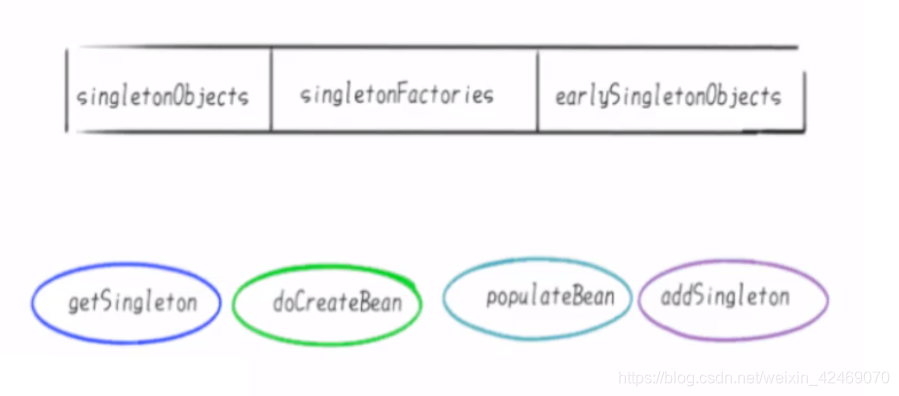
第一层 singletonObjects 存放的是已经初始化好了的 bean,
第二层 earlySingletonObjects 存放的是实例化了,但是未初始化的 bean,
第三层 singletonFactories 存放的是 FactoryBean。但是A类实现了 FactoryBean,那么依赖注入的时候不是A类,而A类产生的 Bean
/**
* 单例对象缓存:bean 名称 -- bean 实例,即:所谓的单例池
* 表示已经经历了完整生命周期的 Bean 对象
* <b>第一级缓存<b/>
*/
private final Map<String, Object> singletonObjects = new ConcurrentHashMap(256);
/**
* 早期的单例对象的高速缓存: bean 名称 -- 实例
* 表示 Bean 的生命周期还没走完(bean 的属性还未填充)就把这个 Bean 存入缓存中
* 也就是实例化但为初始化的 bean 被放入该缓存里
* <b>第二级缓存<b/>
*/
private final Map<String, Object> earlySingletonObjects = new HashMap(16);
/**
* 单例工厂的高速缓存: bean 名称 -- ObjectFactory
* 表示存放生成 bean 的工厂
* <b>第三级缓存<b/>
*/
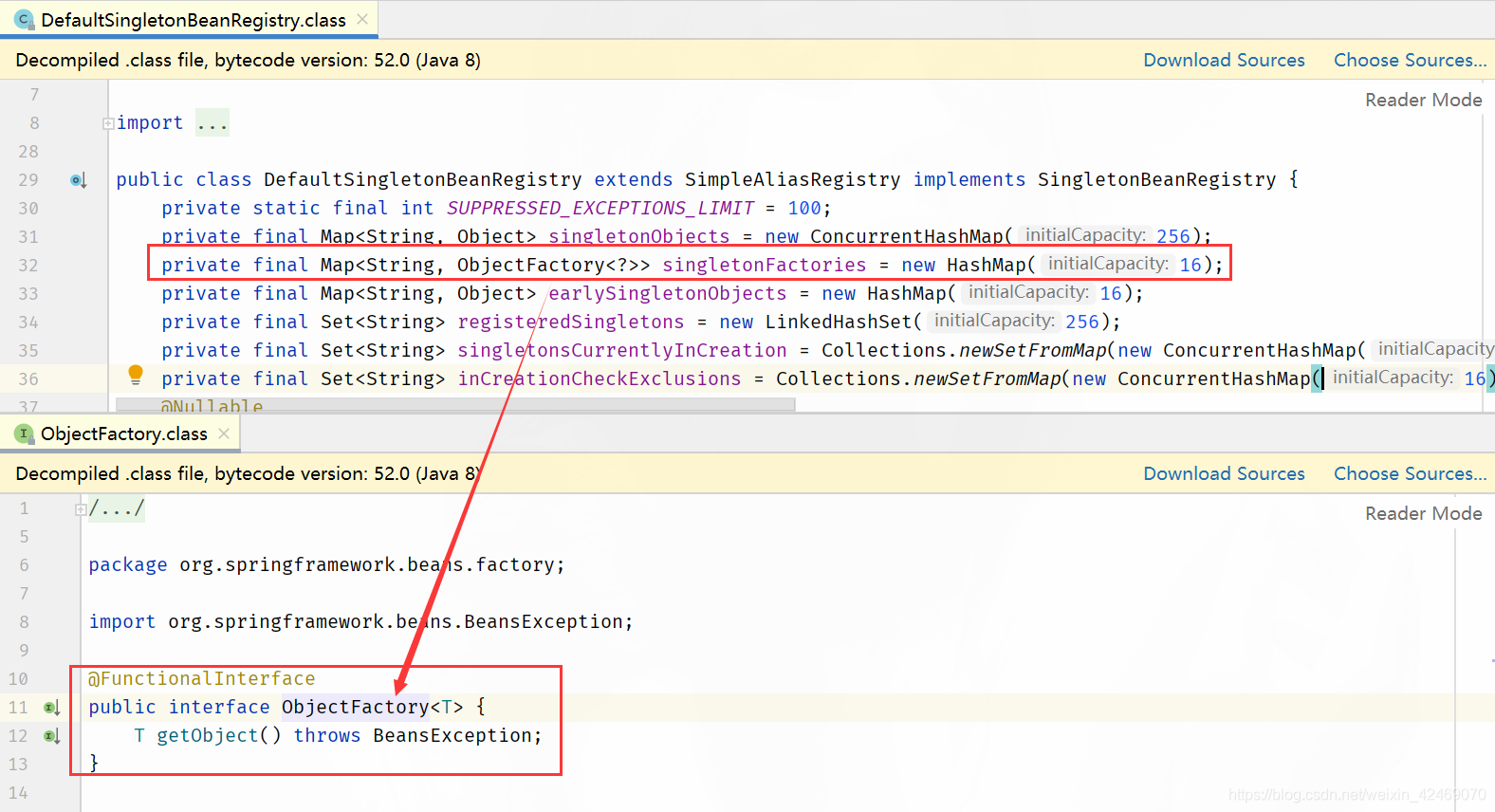
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap(16);
A / B两对象在三级缓存中的迁移说明:
1、A 创建过程中需要 B,于是 A 将自己放到三级缓里面,去实例化 B。
2、B 实例化的时候发现需要 A,于是 B 先查一级缓存,没有,再查二级缓存,还是没有,再查三级缓存,找到了 A 然后把三级缓存里面的这个 A 放到二级缓存里面,并删除三级缓存里面的 A。
3、B 顺利初始化完毕,将自己放到一级缓存里面(此时B里面的A依然是创建中状态),然后回来接着创建 A,此时 B 已经创建结束,直接从一级缓存里面拿到 B,然后完成创建,并将 A 自己放到一级缓存里面。
spring循环依赖debug源码01
A/B两对象在三级缓存中的迁移说明:
回到ClientSpringContainer类,debug运行:
new ClassPathXmlApplicationContext()断点:
步入:
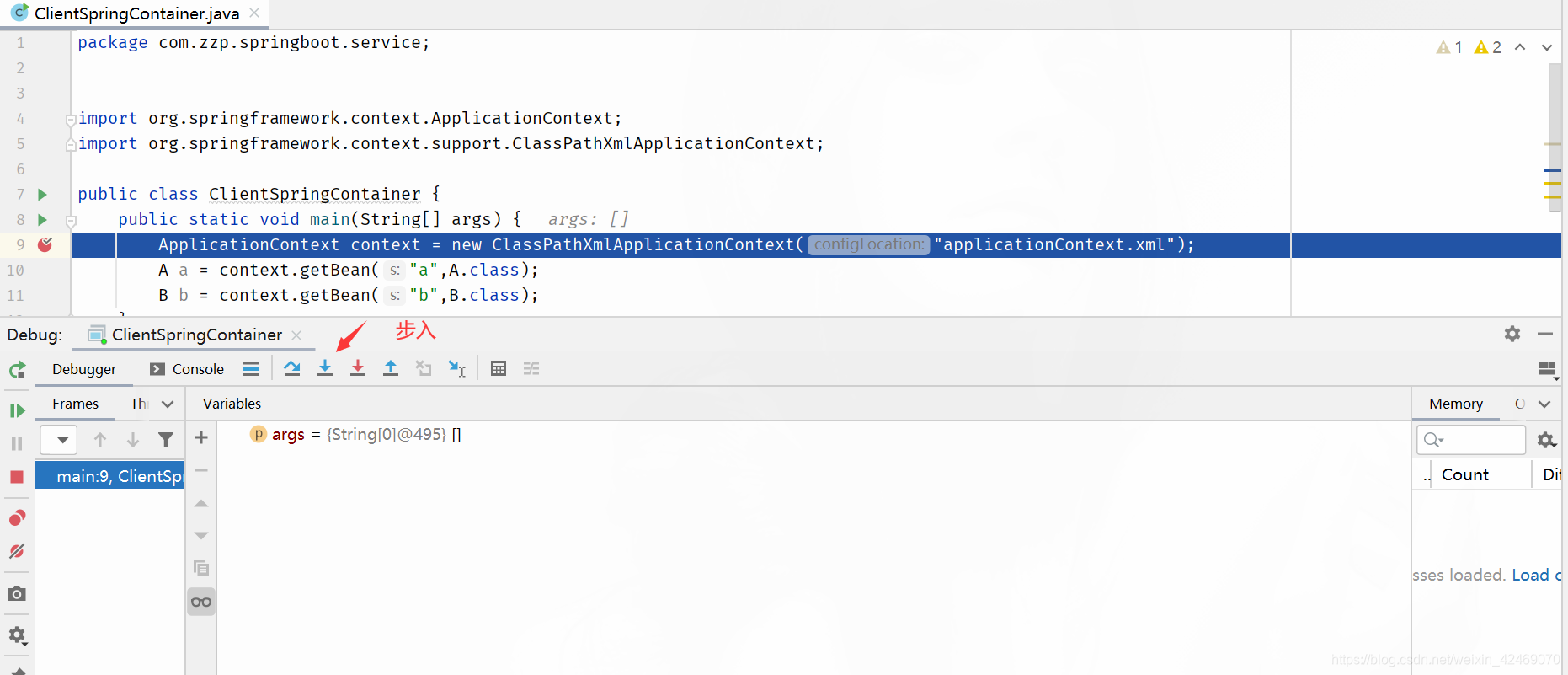
跳出:
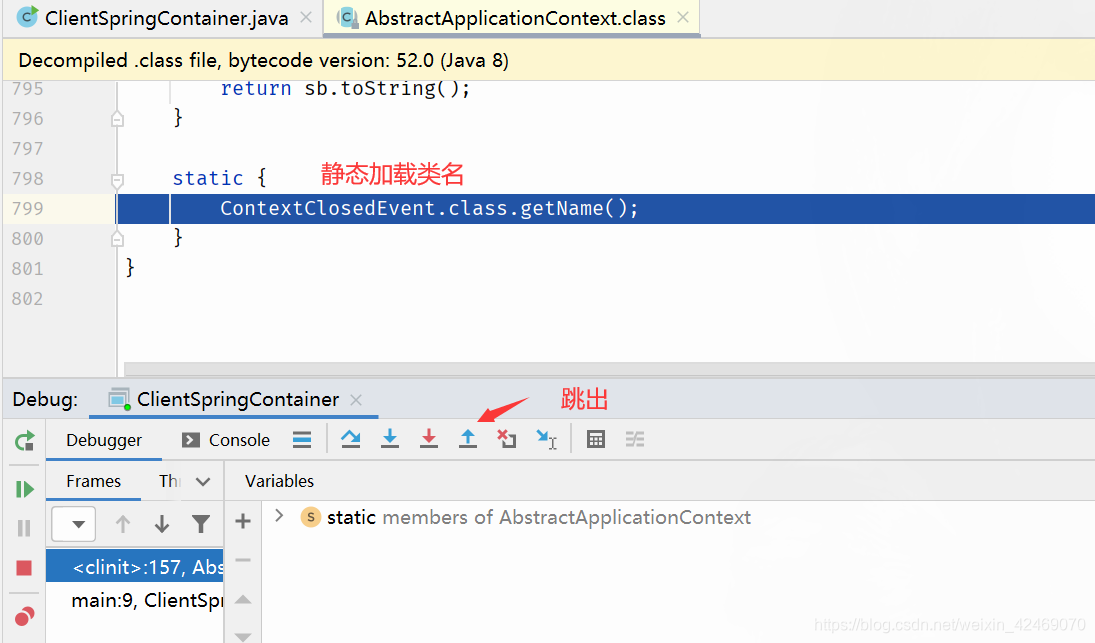
步入:
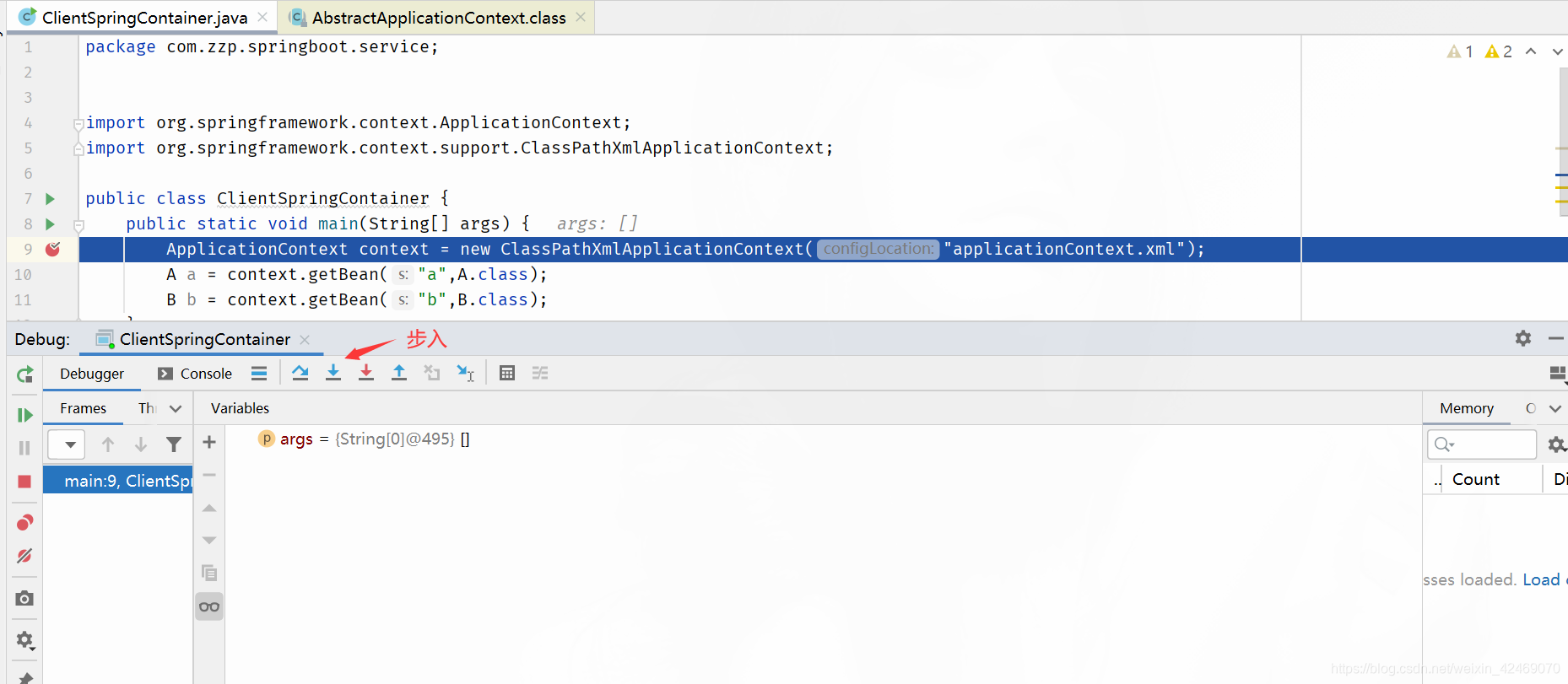
步入:
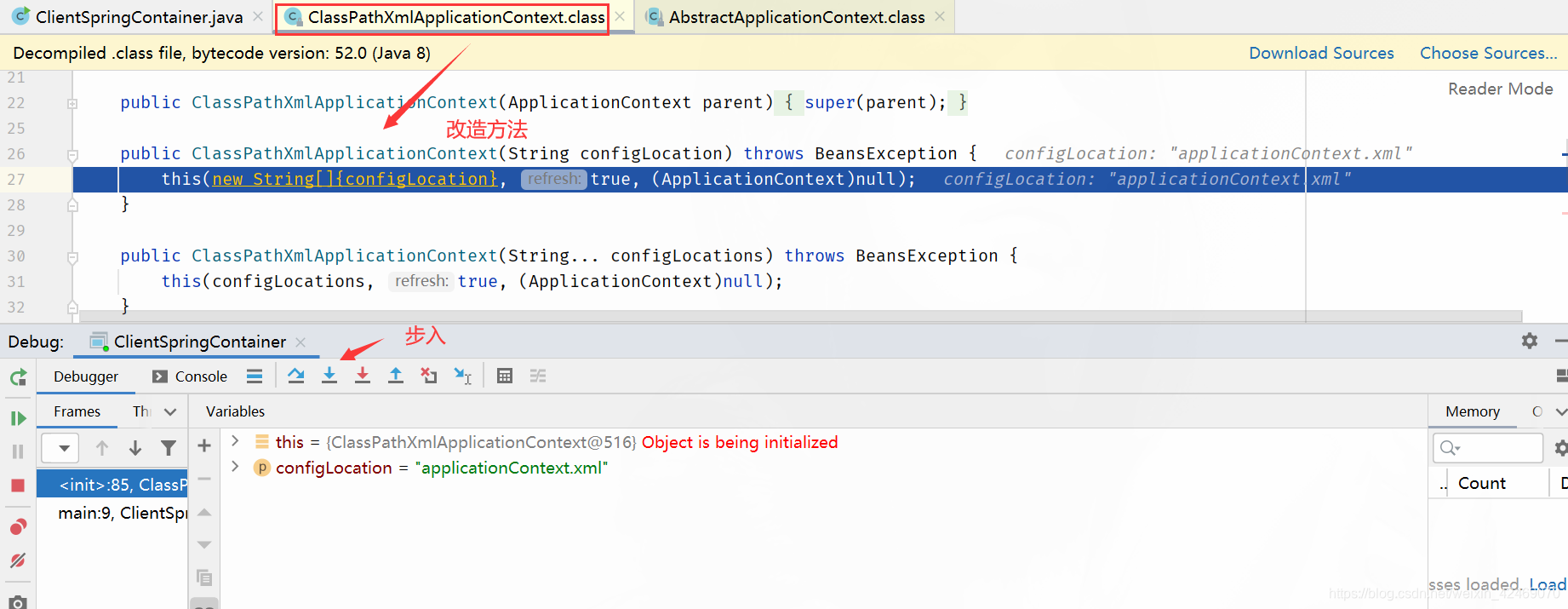
refresh()断点:refresh()方法是spring的核心,在其中完成了容器的初始化;
步入:
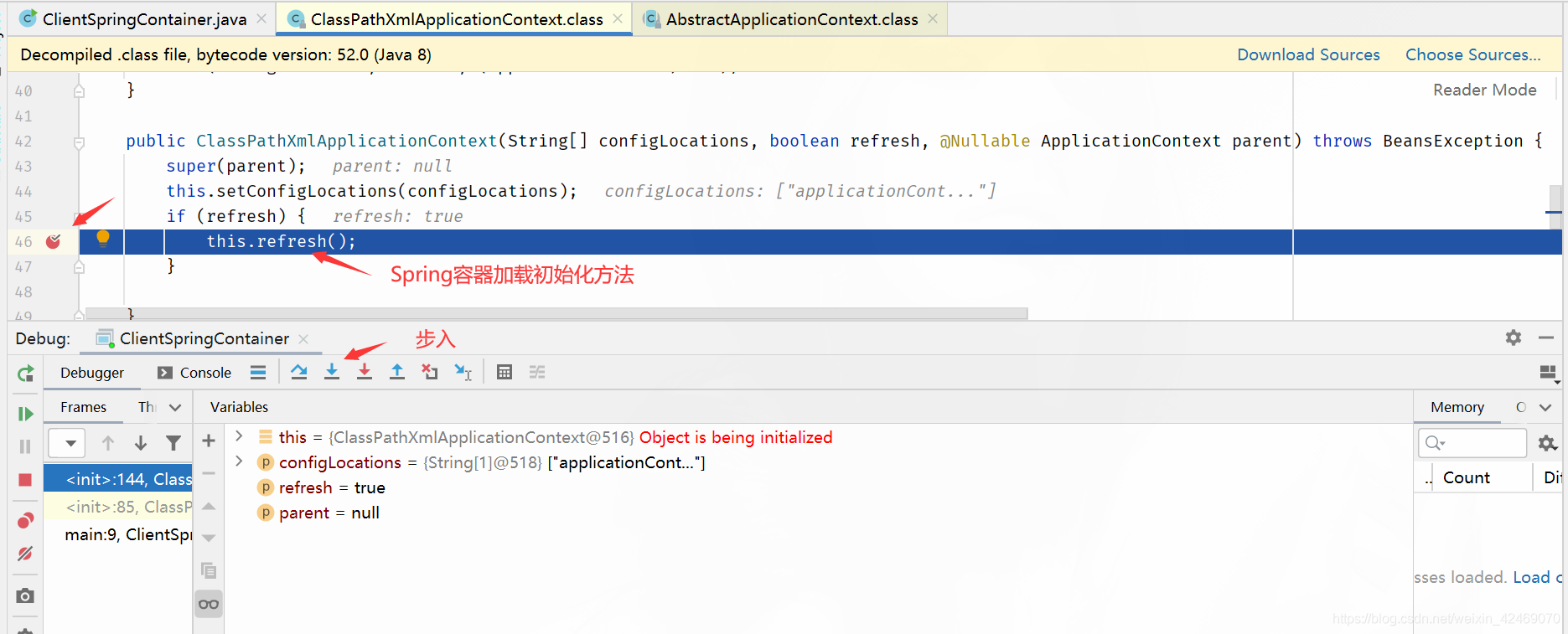
步过:
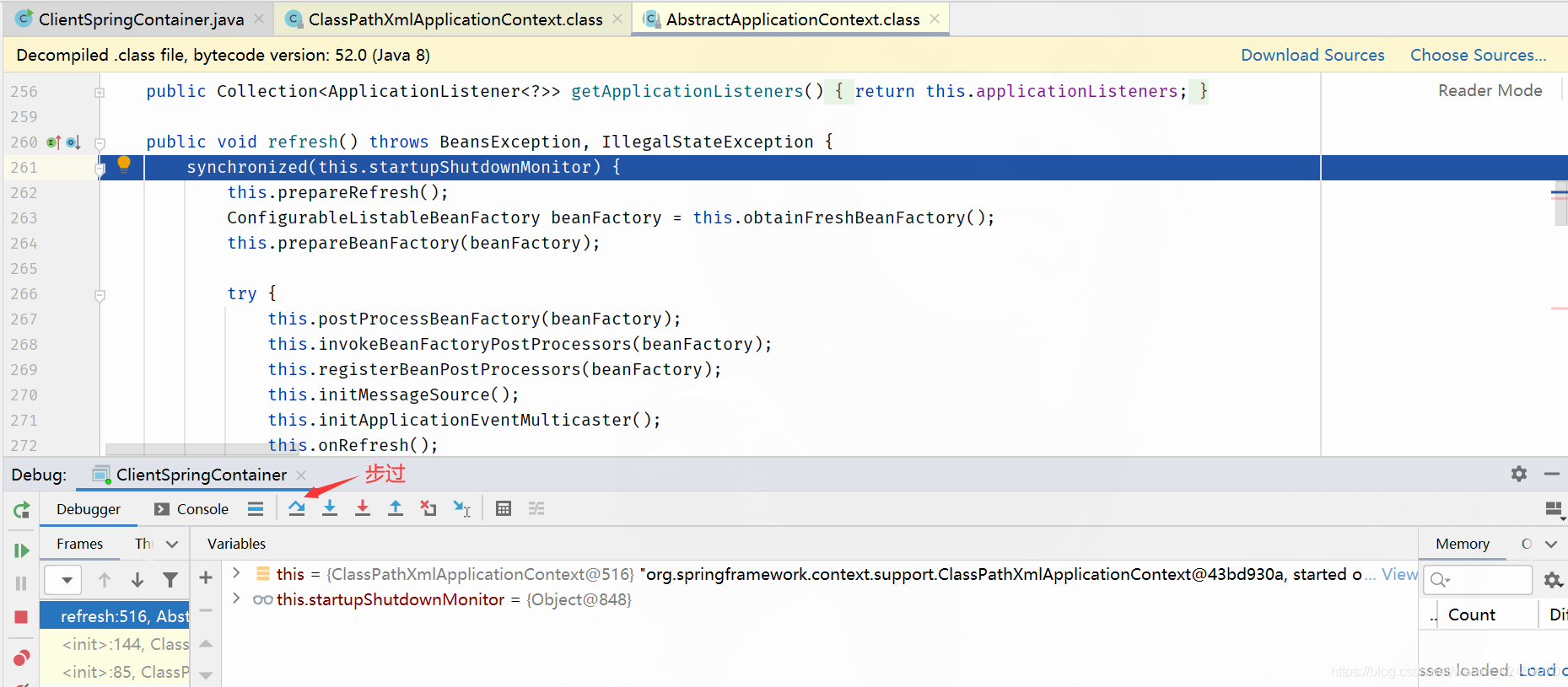
finishBeanFactoryInitialization()断点:
finishBeanFactoryInitialization()方法就是完成Bean工厂初始化的入口
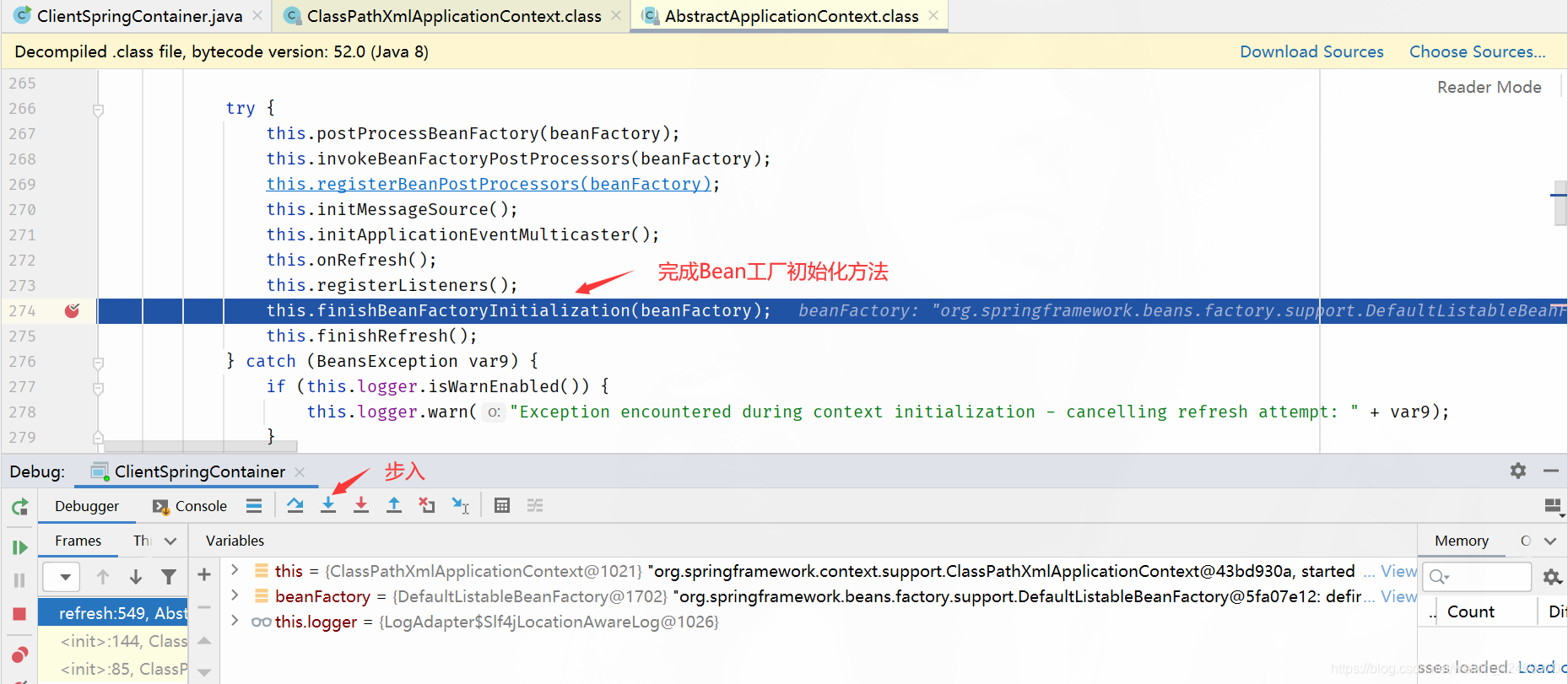
步入:
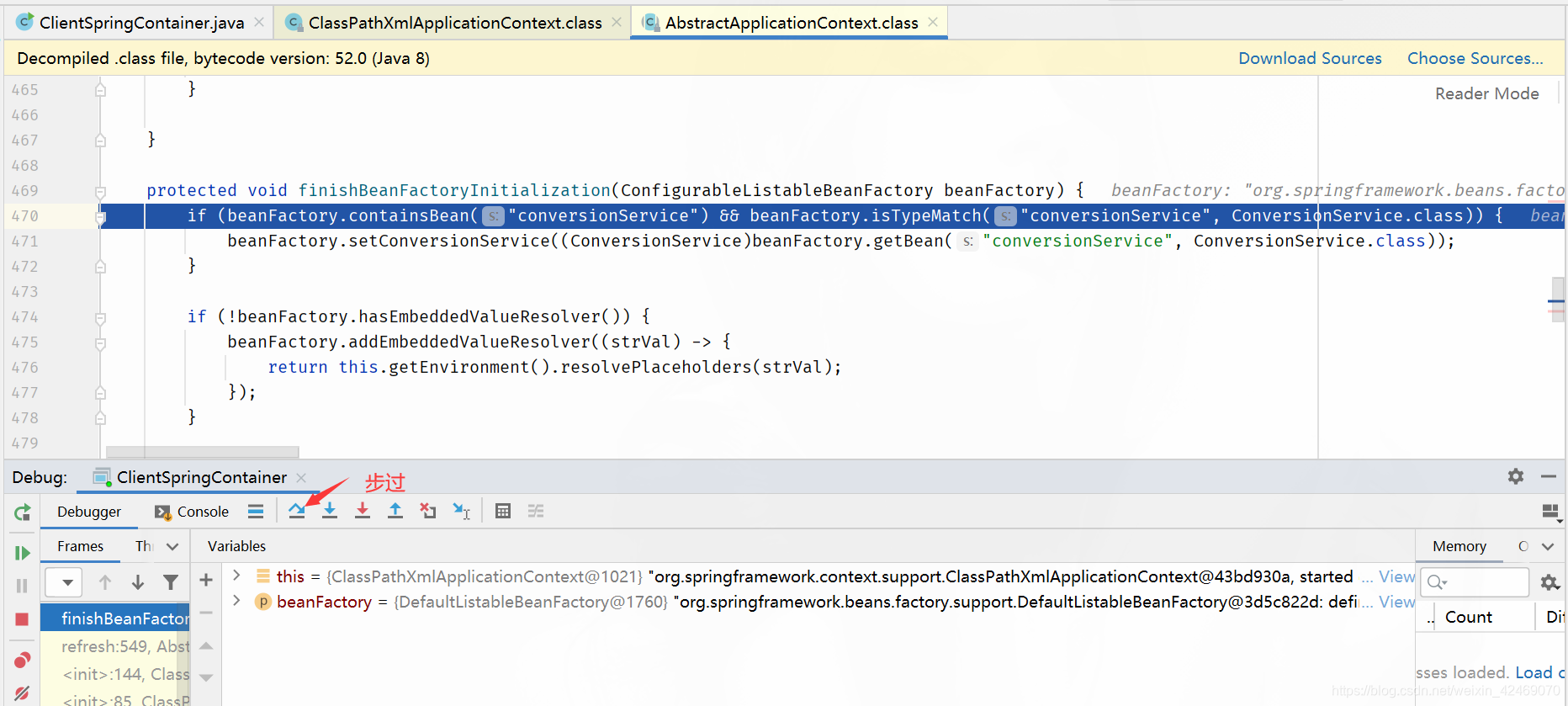
spring循环依赖debug源码02
继续上一节流程
preInstantiateSingletons()断点:预实例化单例
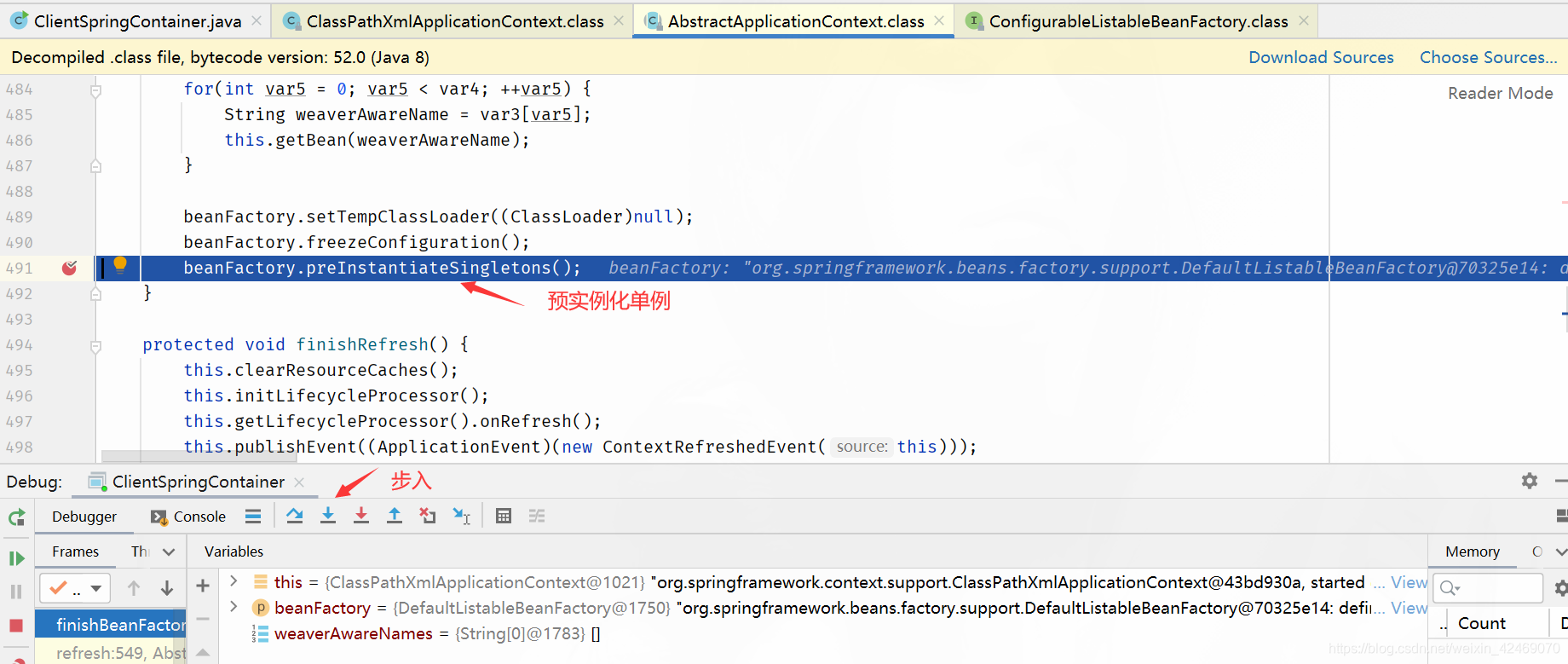
步入:
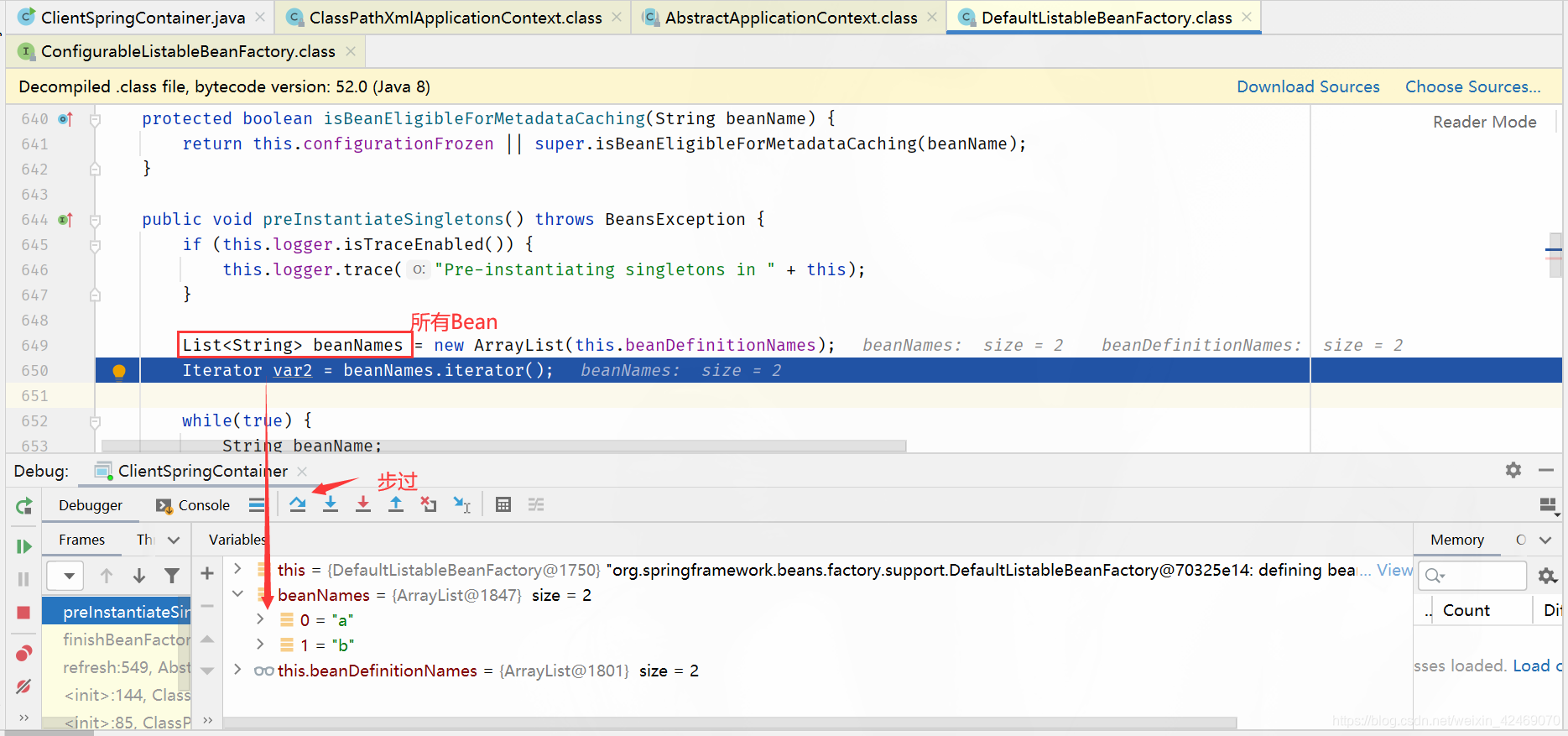
步过:
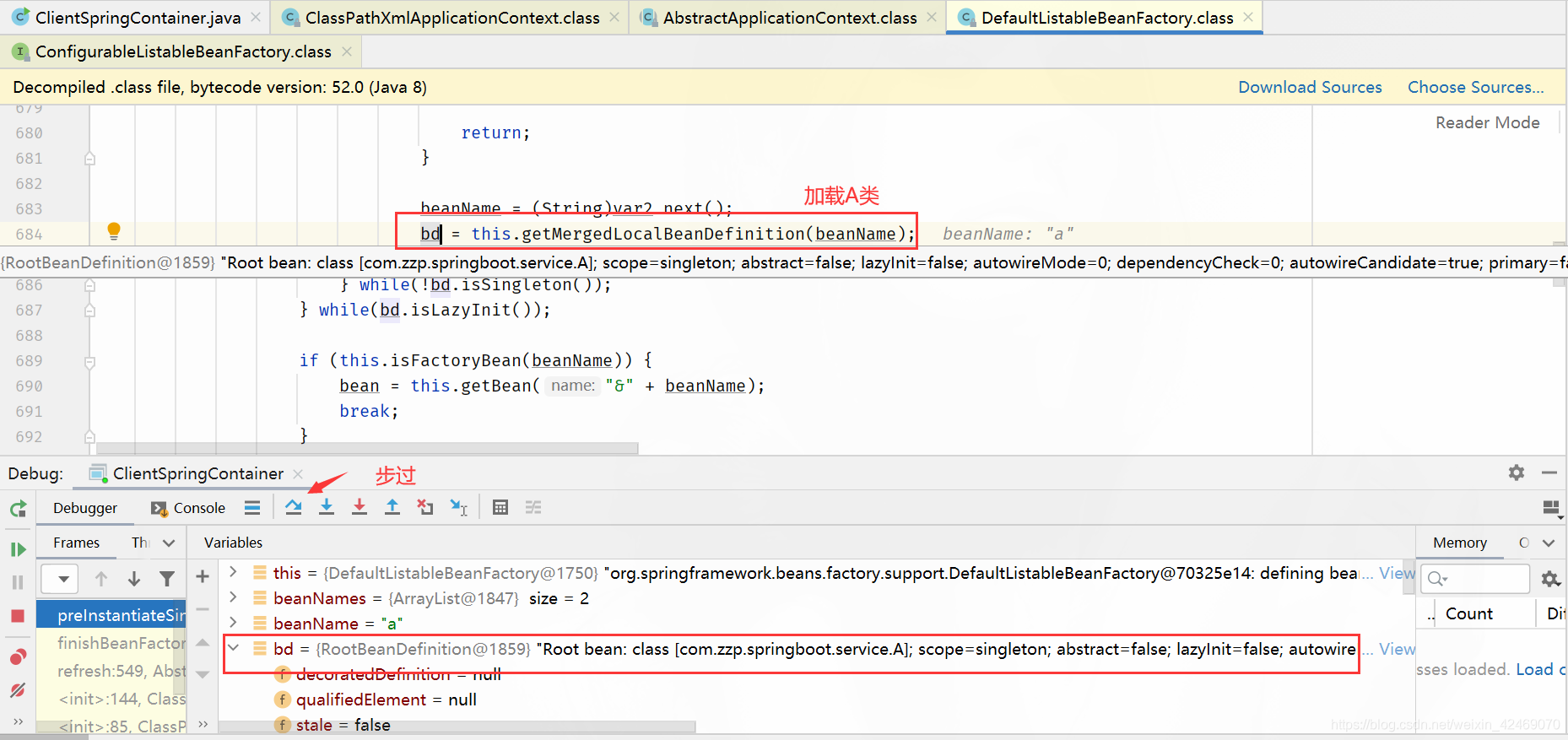
getBean()断点:从Spring IOC容器中获取bean实例
步入:
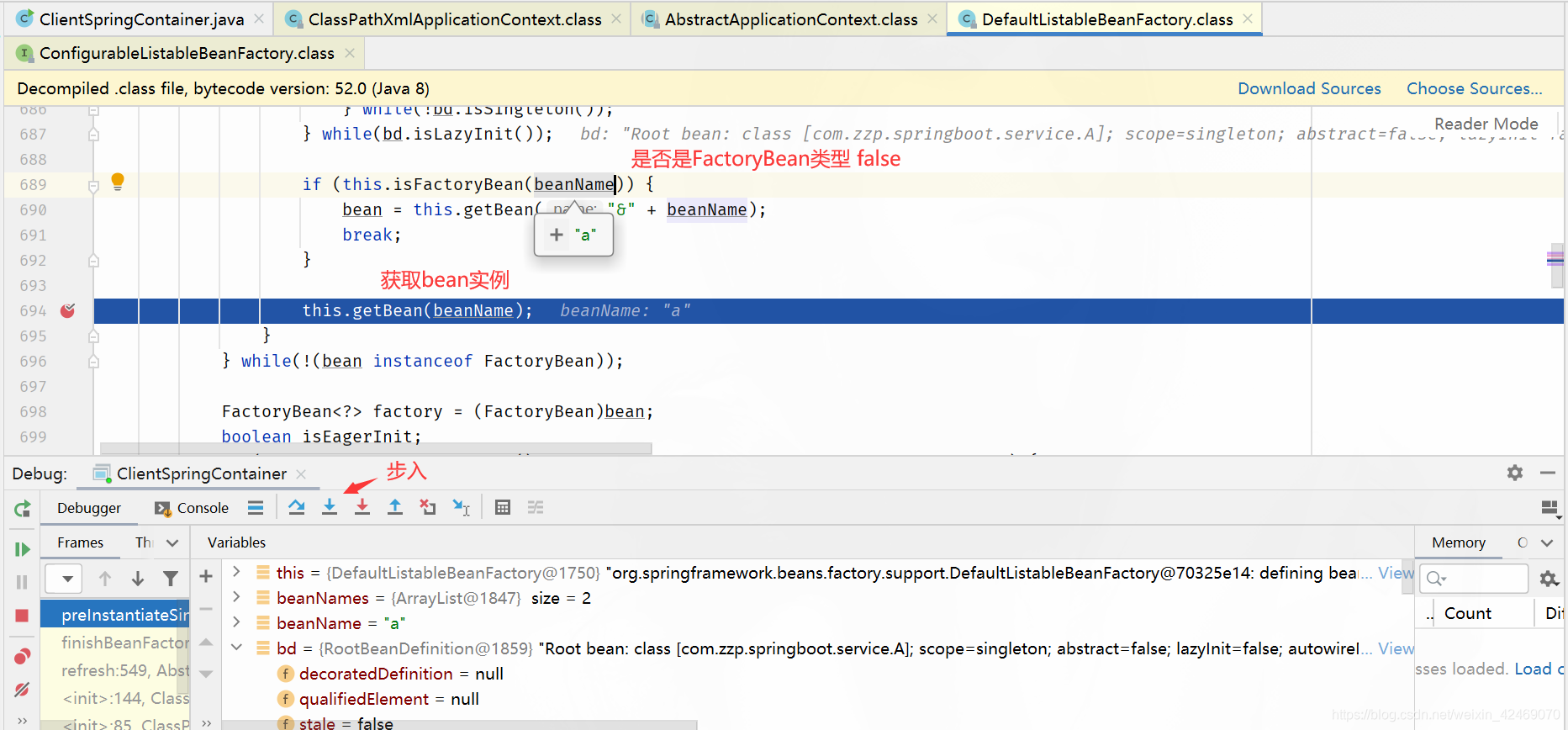
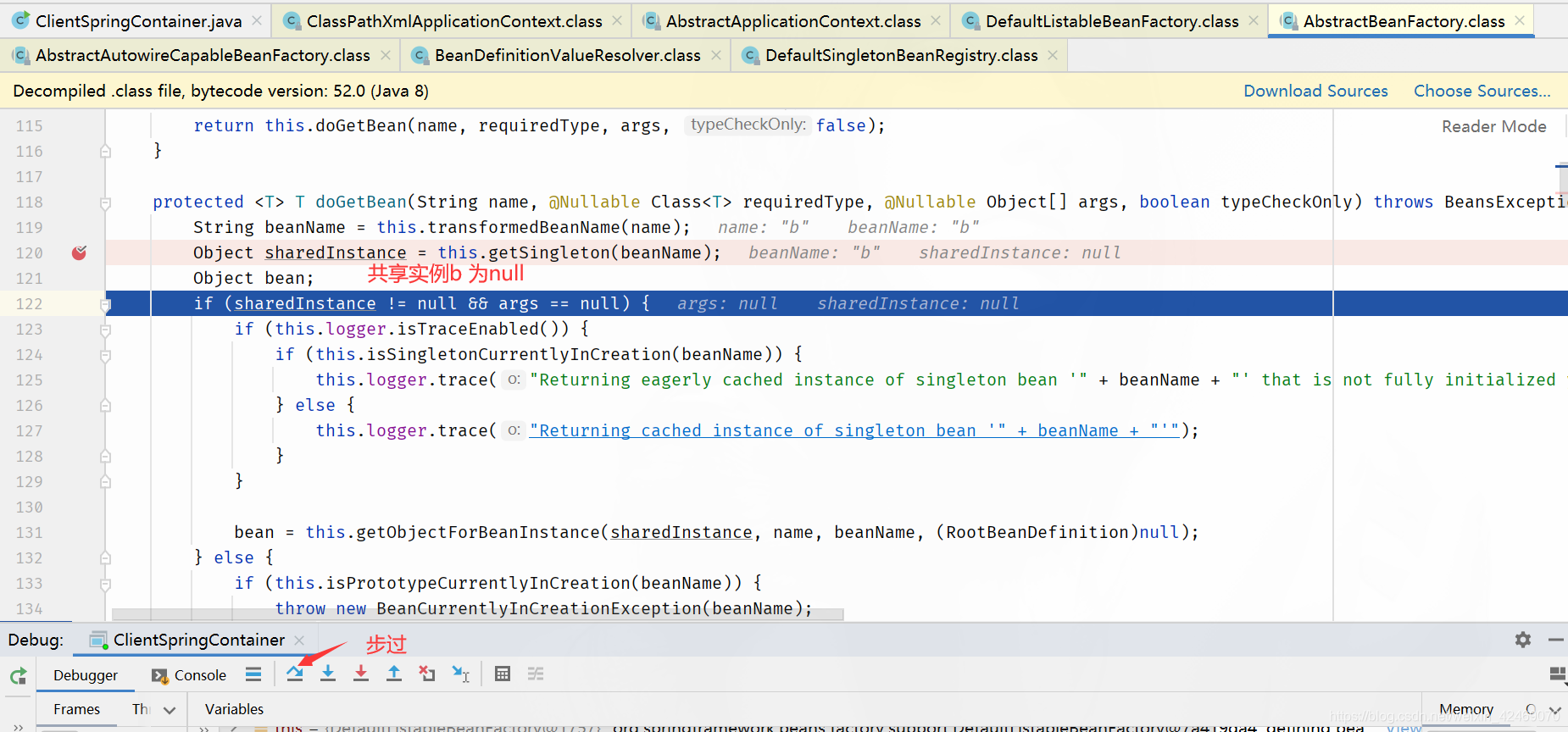
doGetBean():向IOC容器获取被管理Bean的过程
步入:
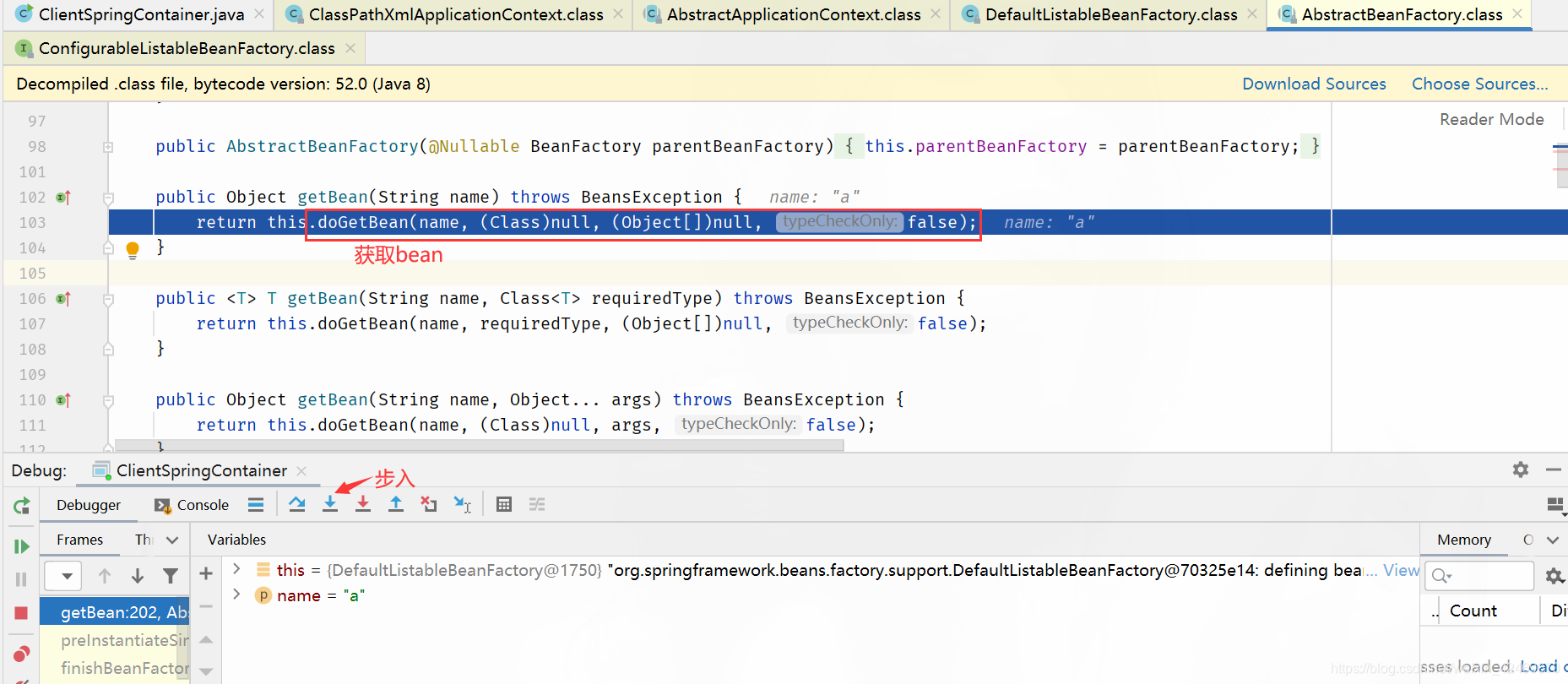
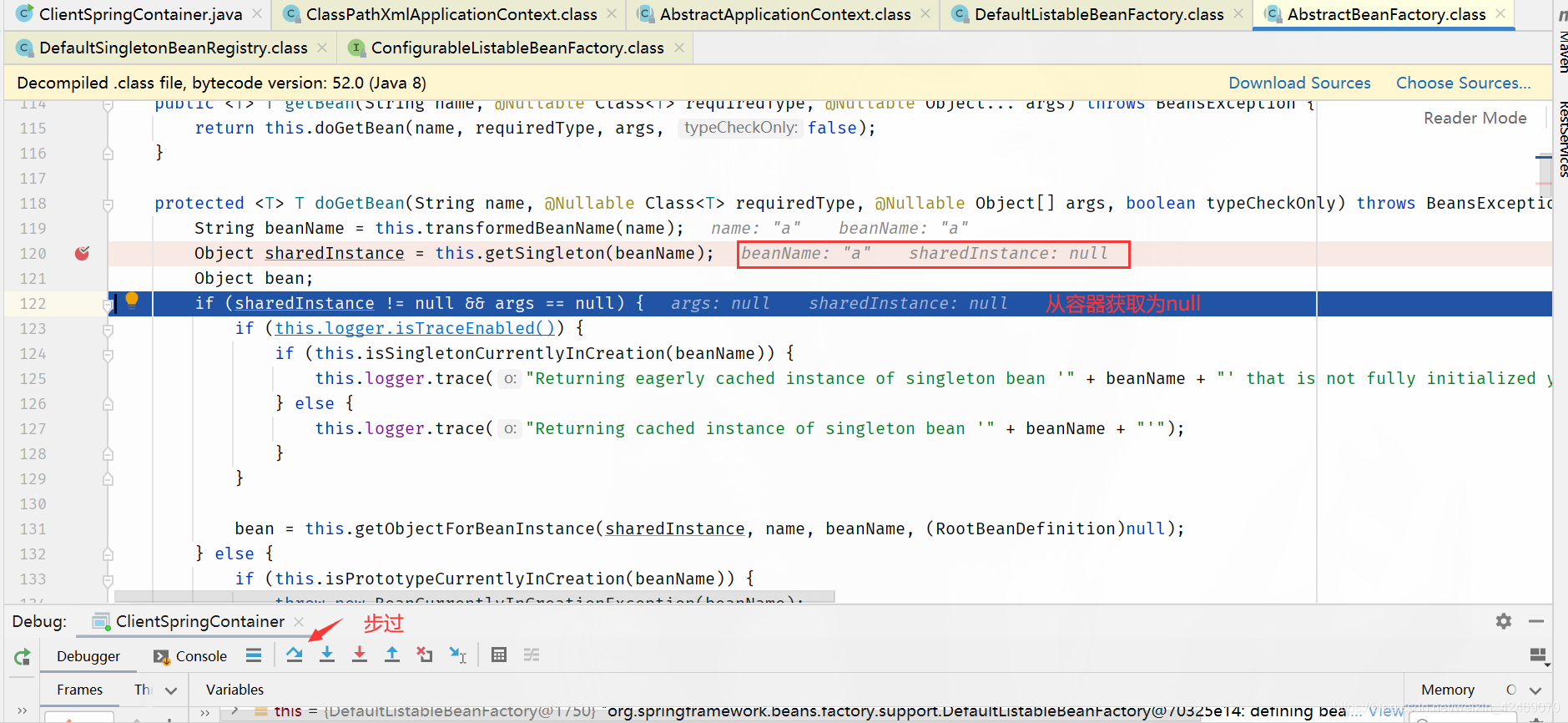
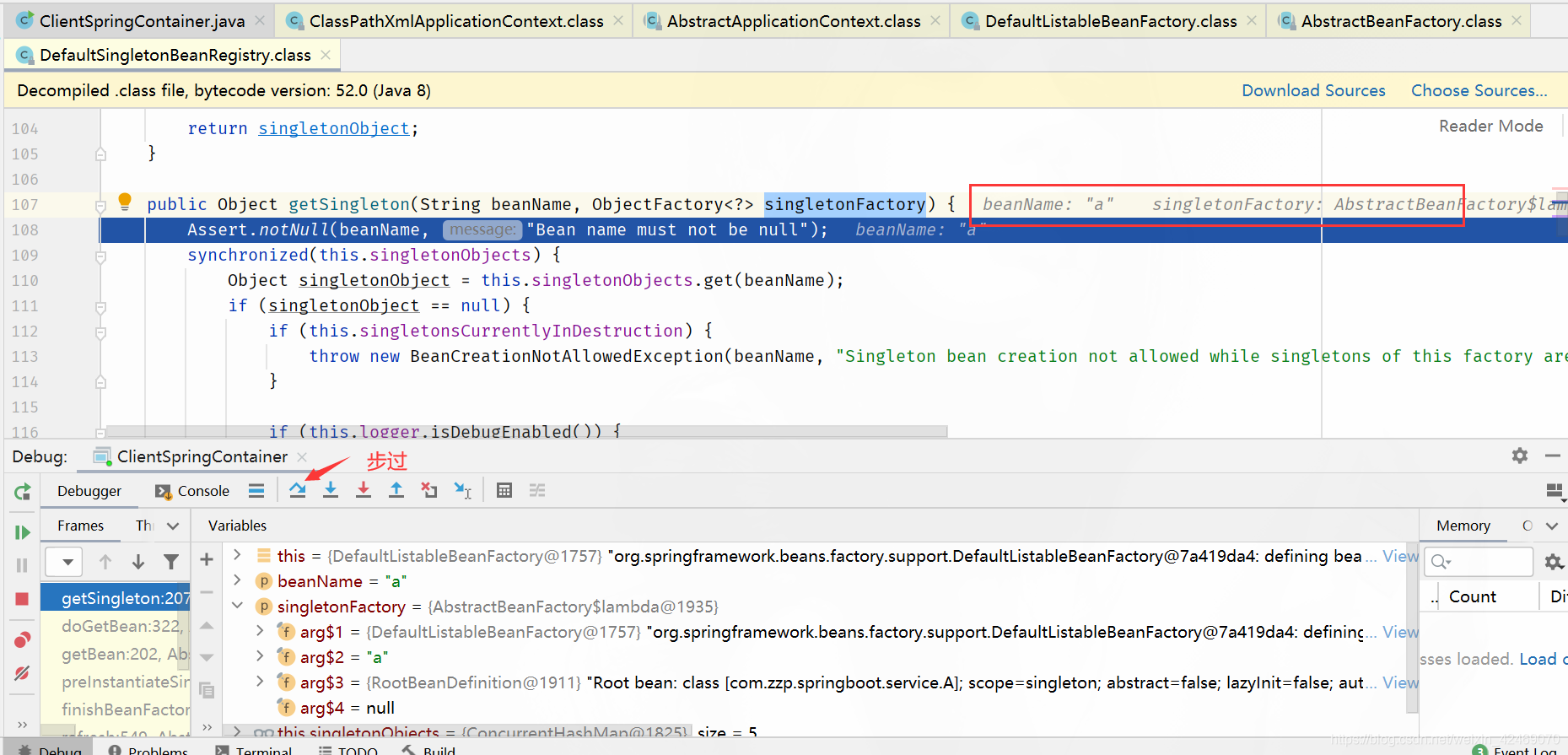
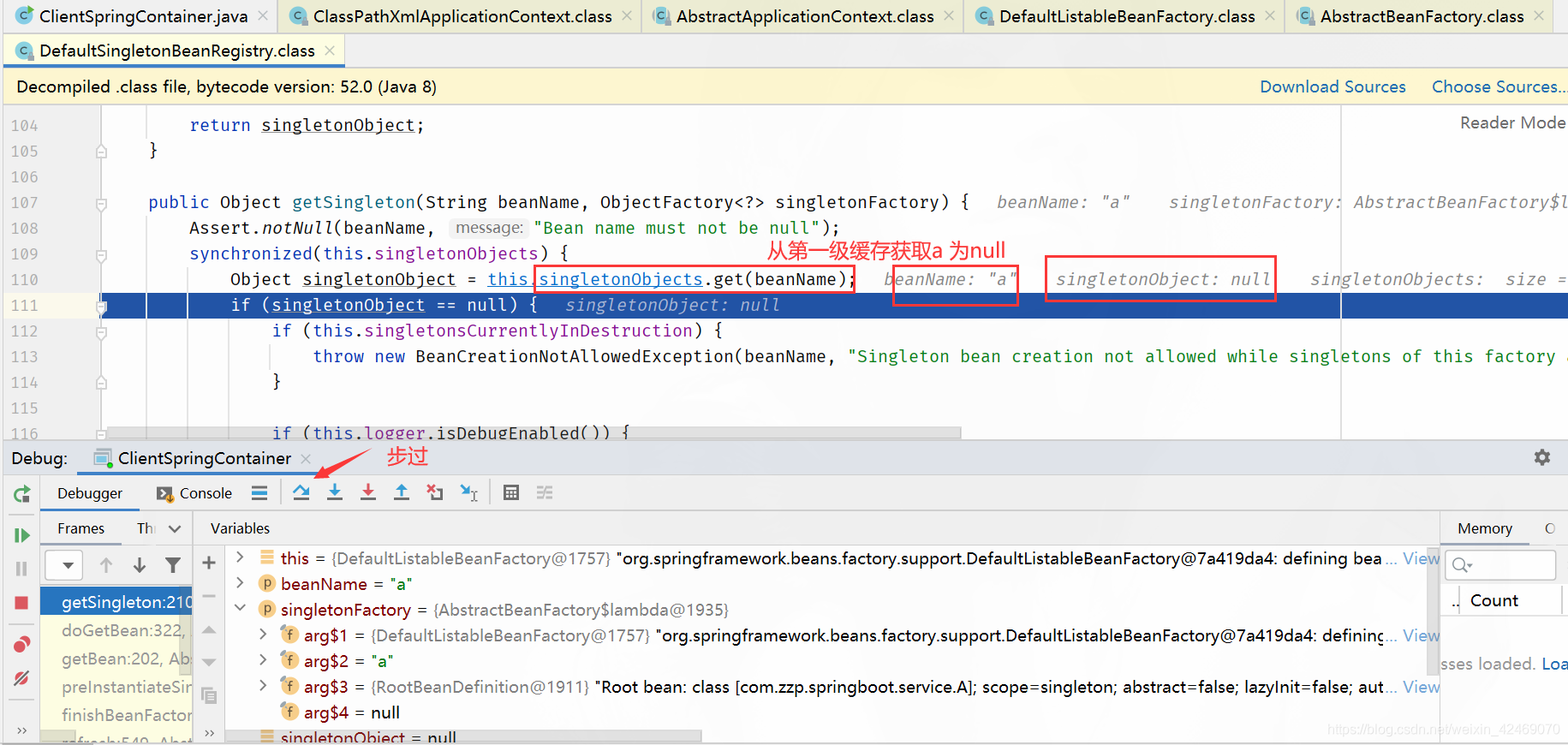
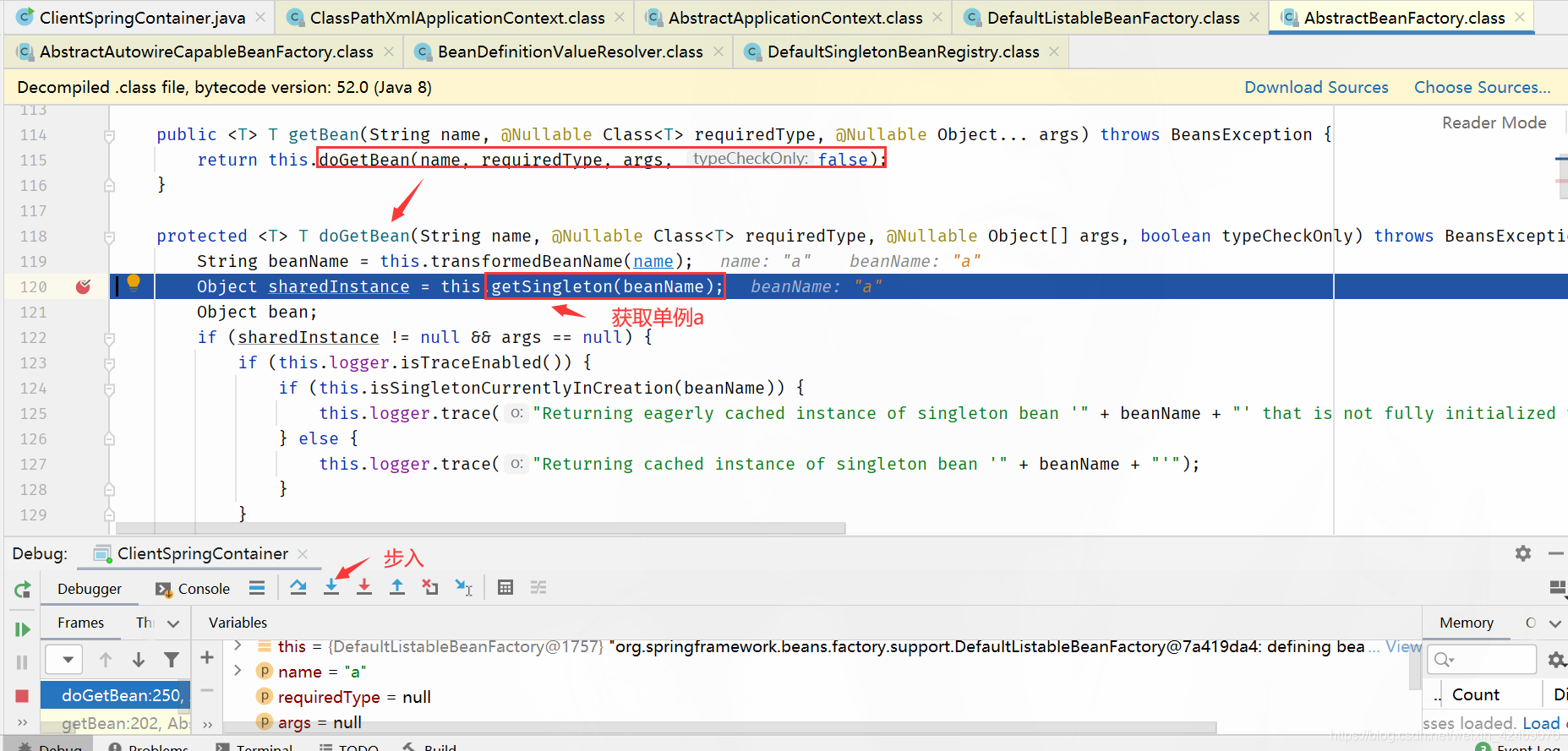
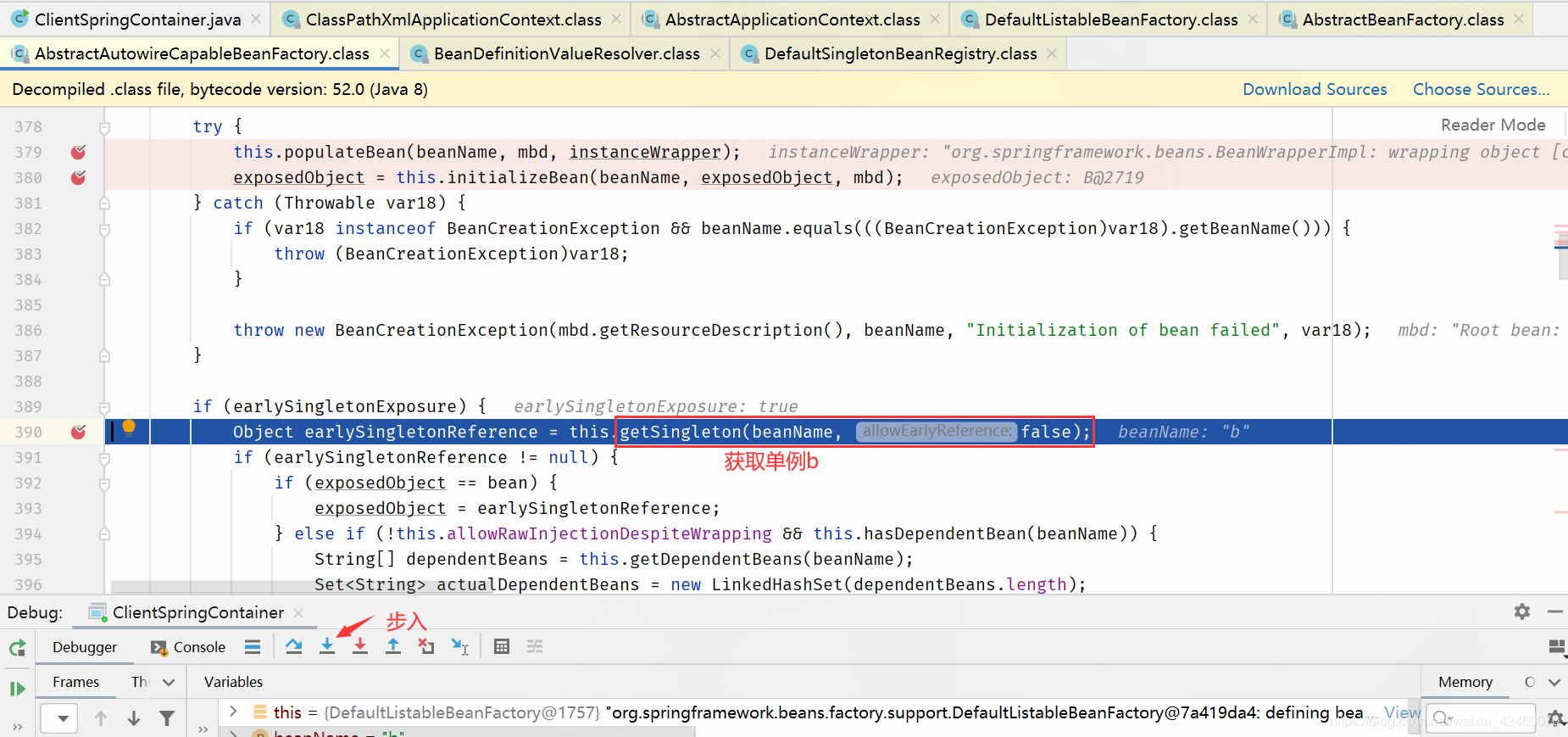
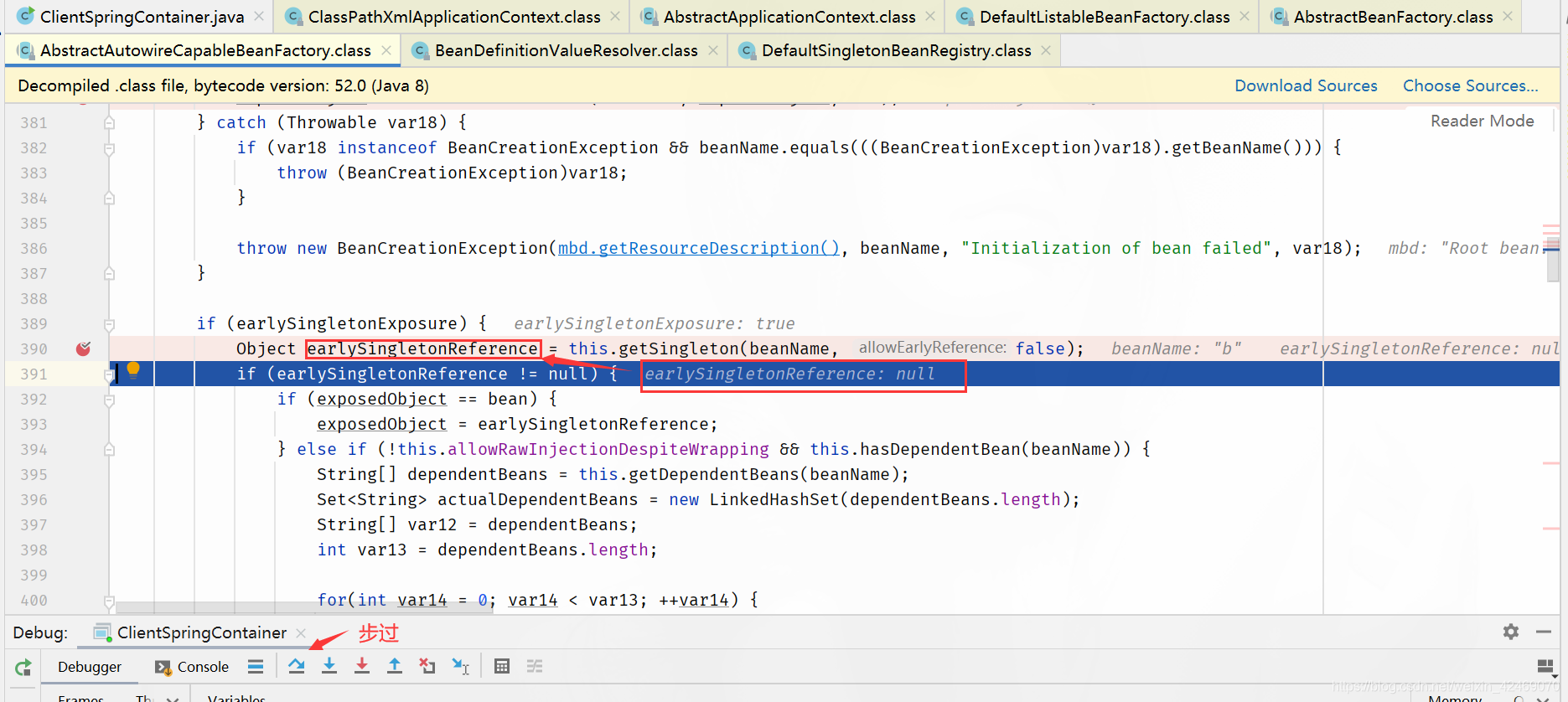
getSingleton()断点:获取单例(第一个方法)
singletonObjects.get(beanName)断点:从第一级缓存获取bean
步入:
| 缓存 | A | B |
|---|---|---|
| 第一级缓存(singletonObjects) | null | null |
| 第二级缓存(earlySingletonObjects) | null | null |
| 第三级缓存(singletonFactories) | null | null |
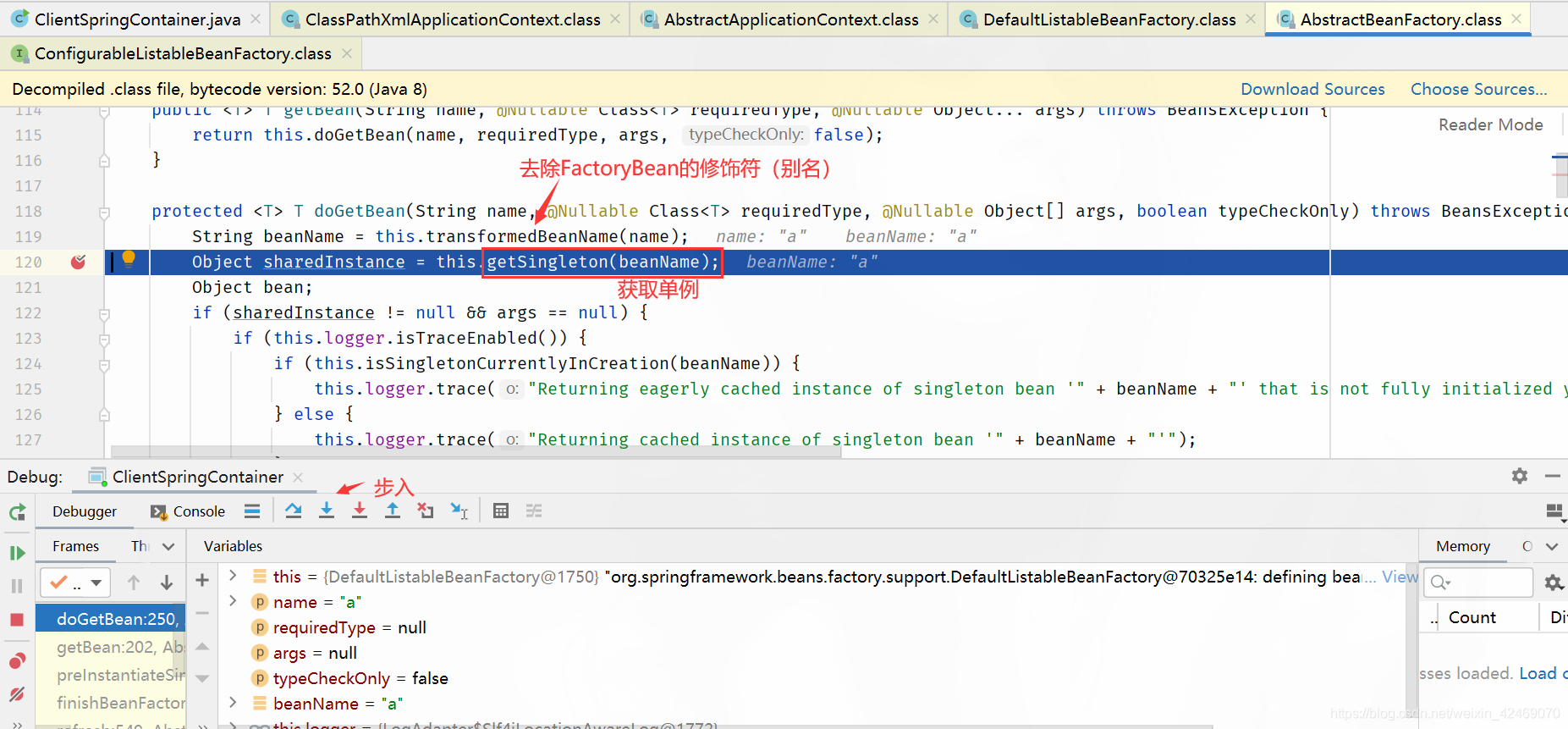
步过:
步过:
步过:
步过:
步过:
步过:
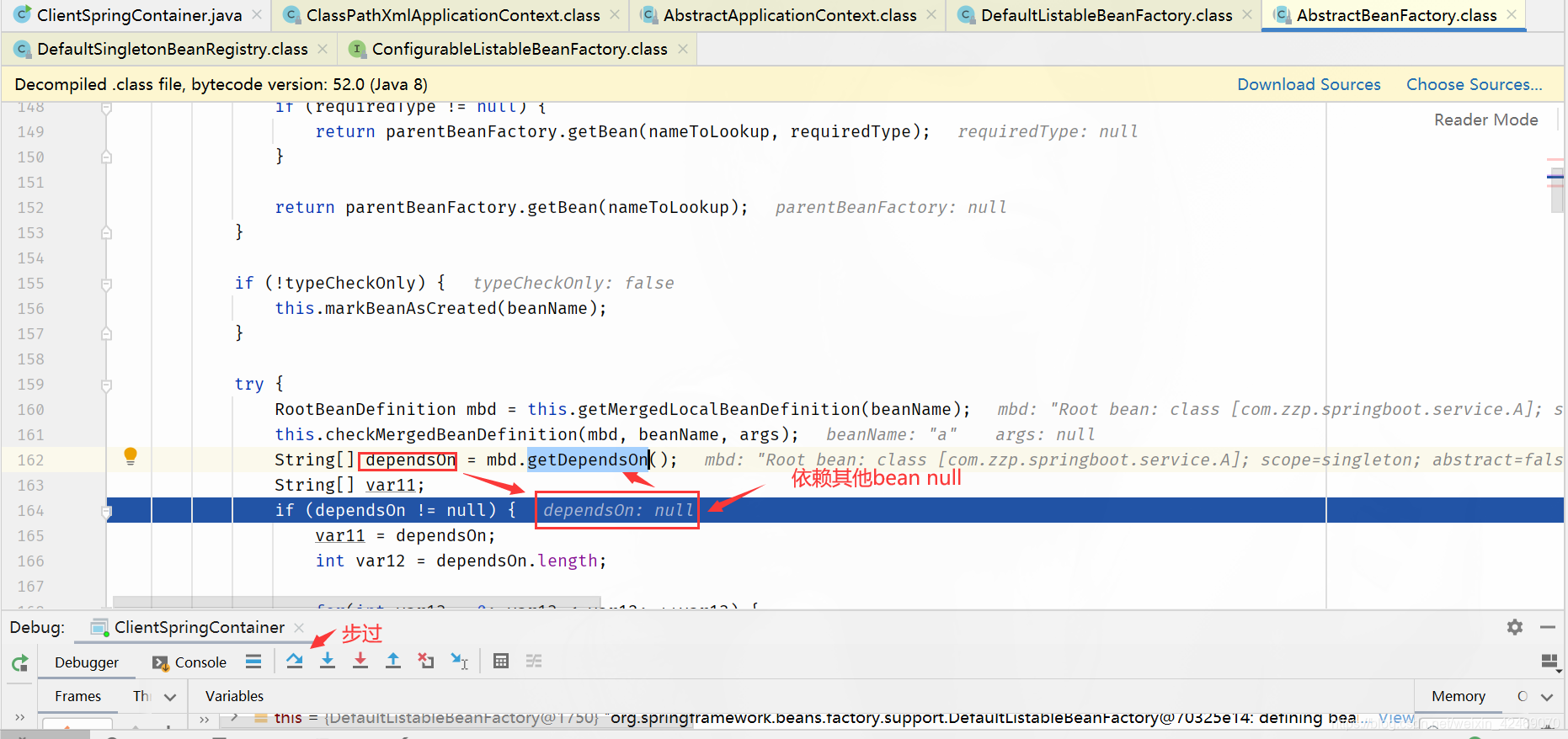
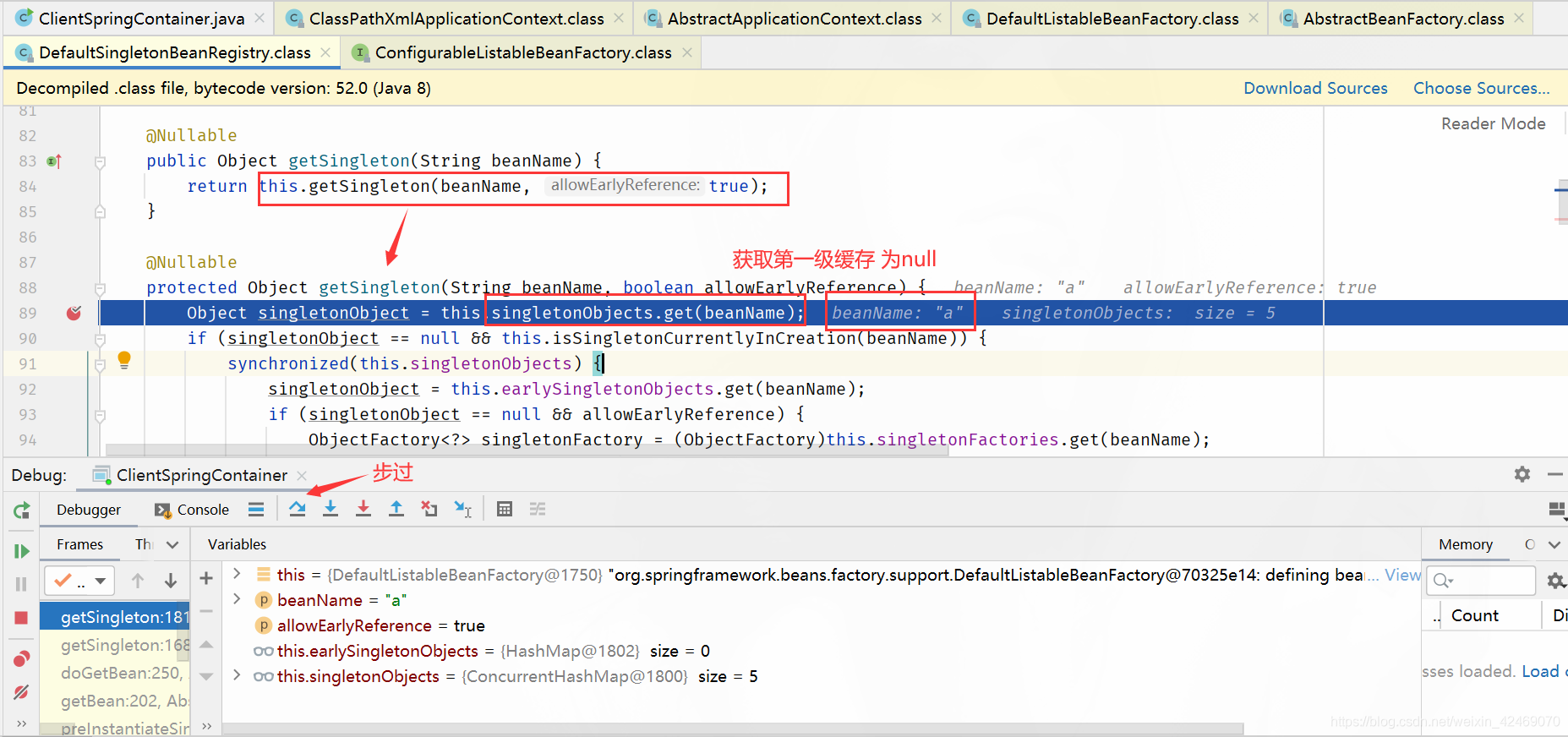
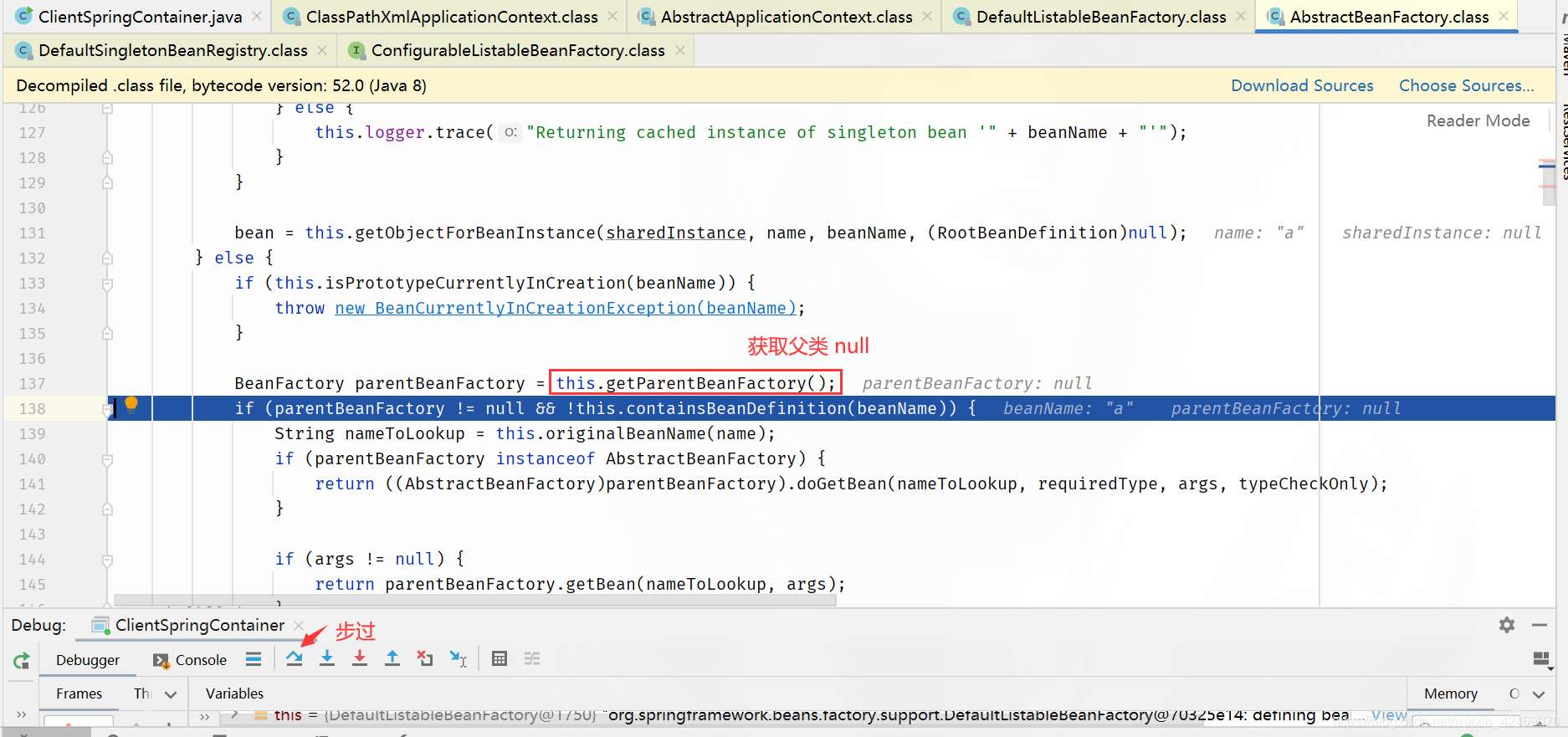
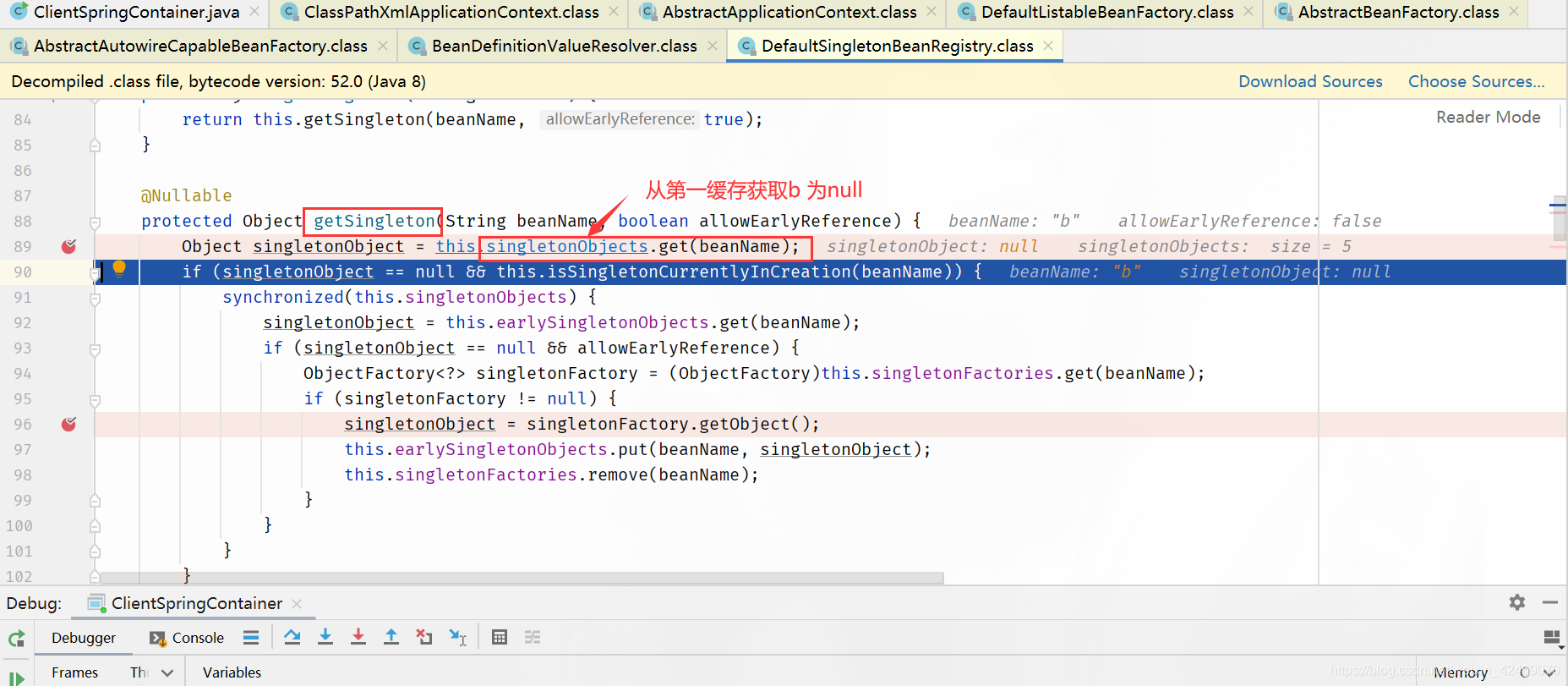
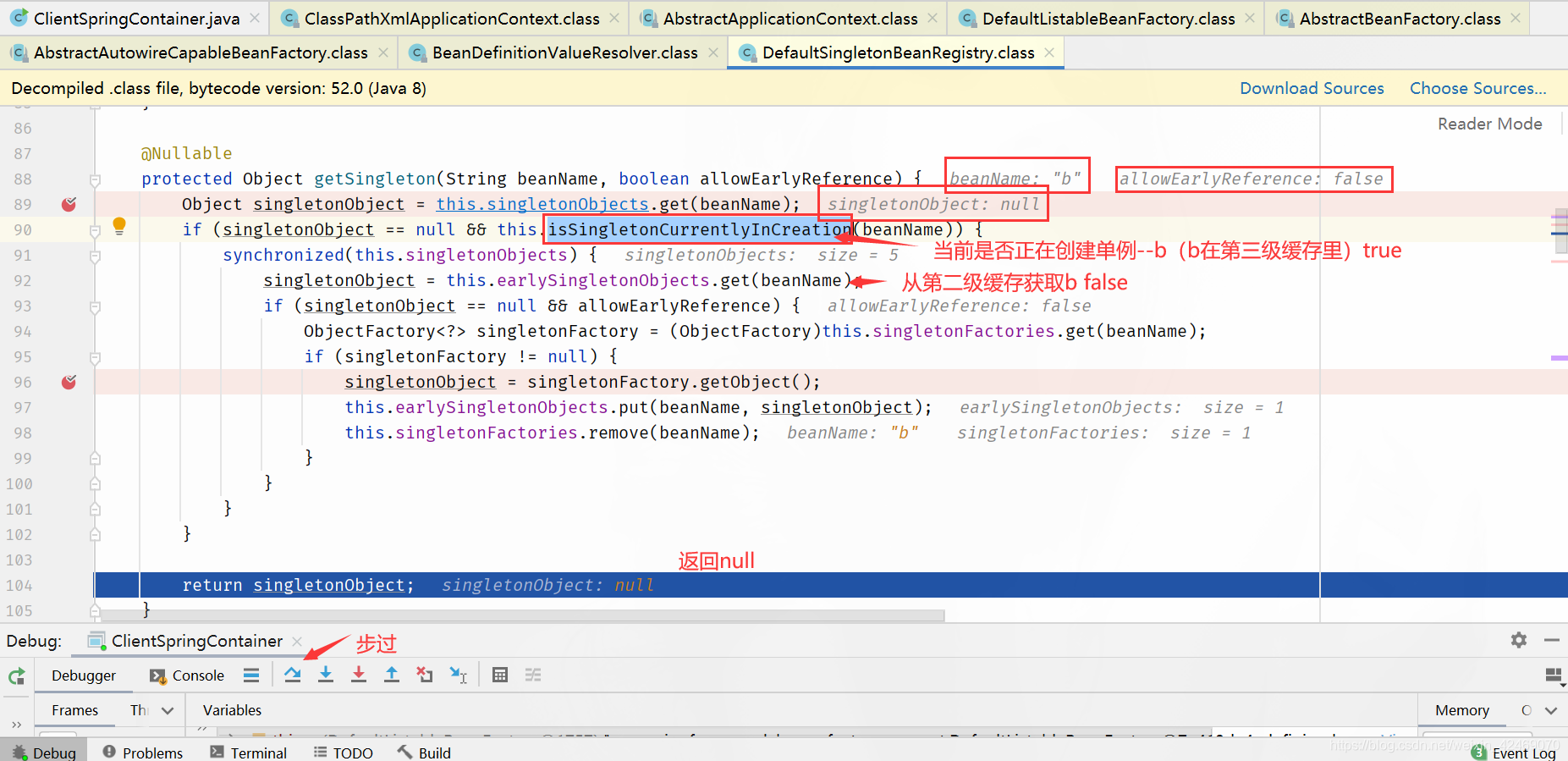
getSingleton()断点:获取单例(第一个方法)
spring循环依赖debug源码03
继续上一节
在getSingleton()断点:获取单例(第一个方法)
步入:
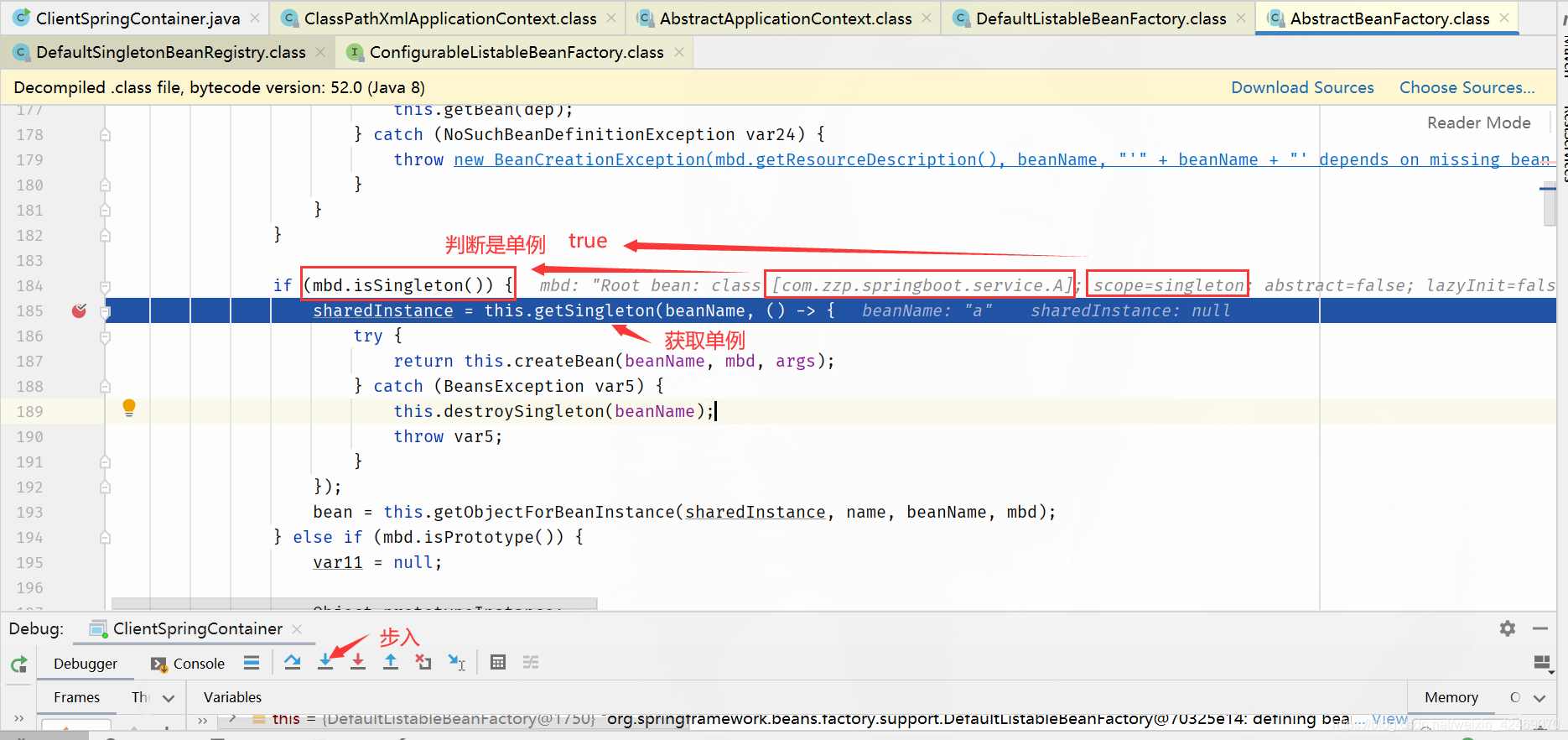
步过:
singletonFactory.getObject()断点:获取第三级缓存工厂

createBean()断点:创建bean
步入:
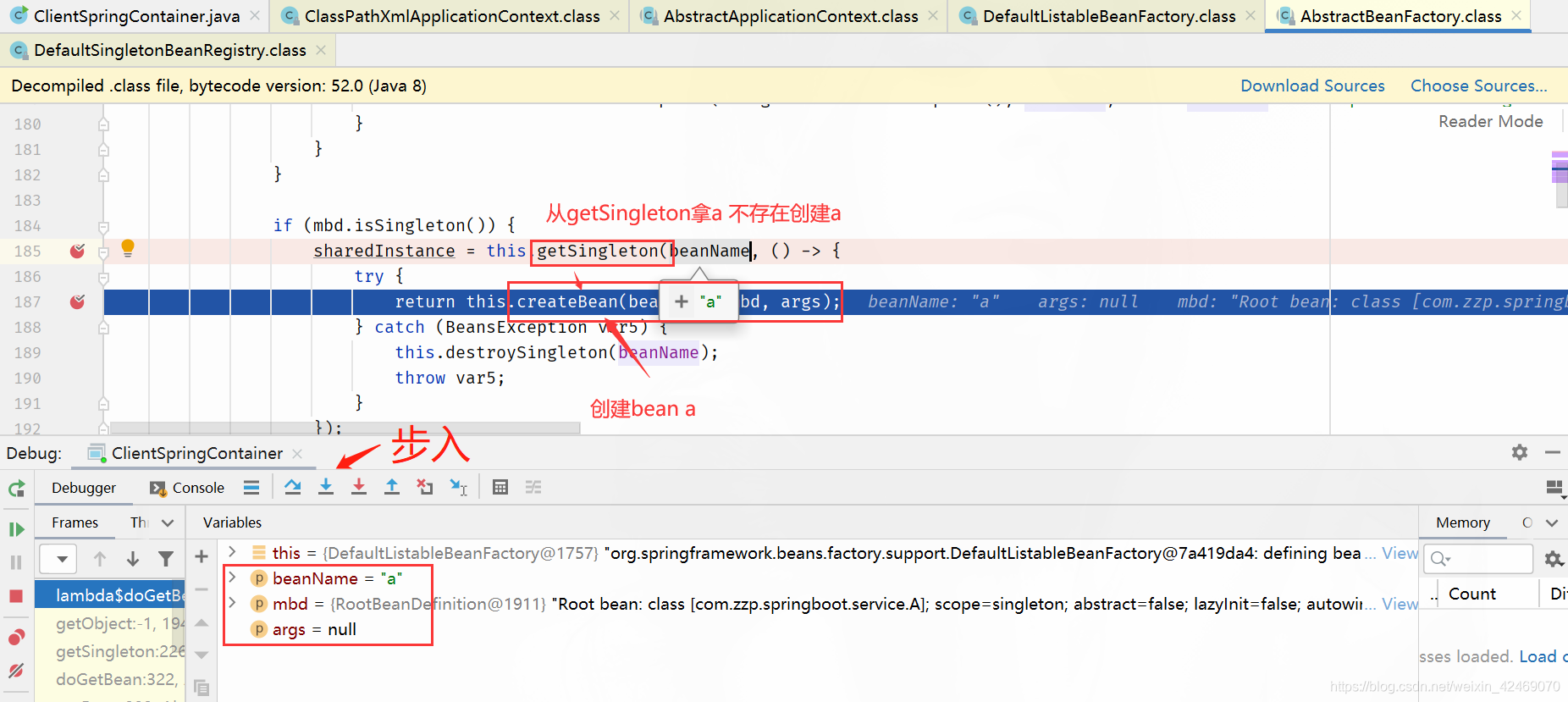
步入:
步过:
doCreateBean():创建bean(第二个方法)
步过:
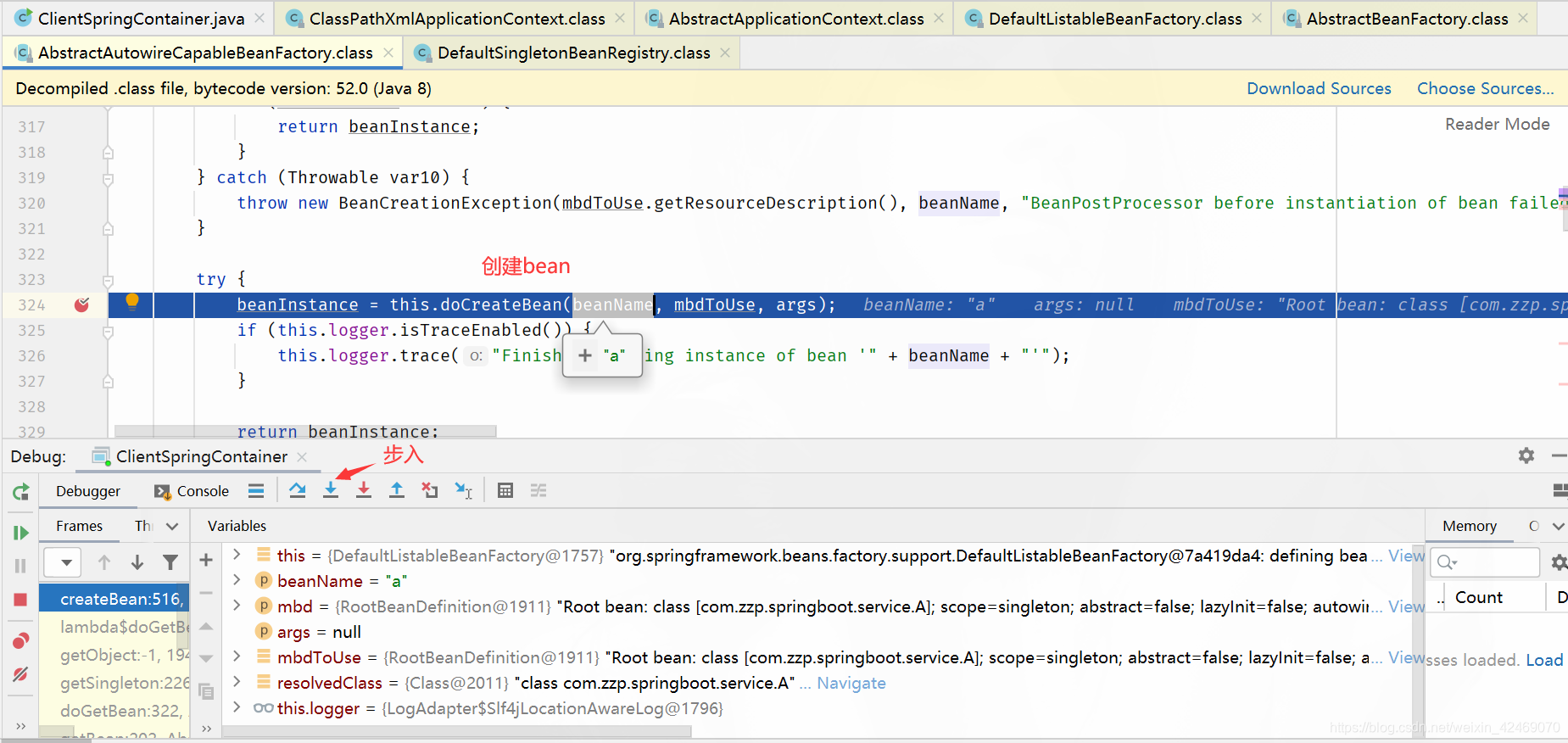
步入:
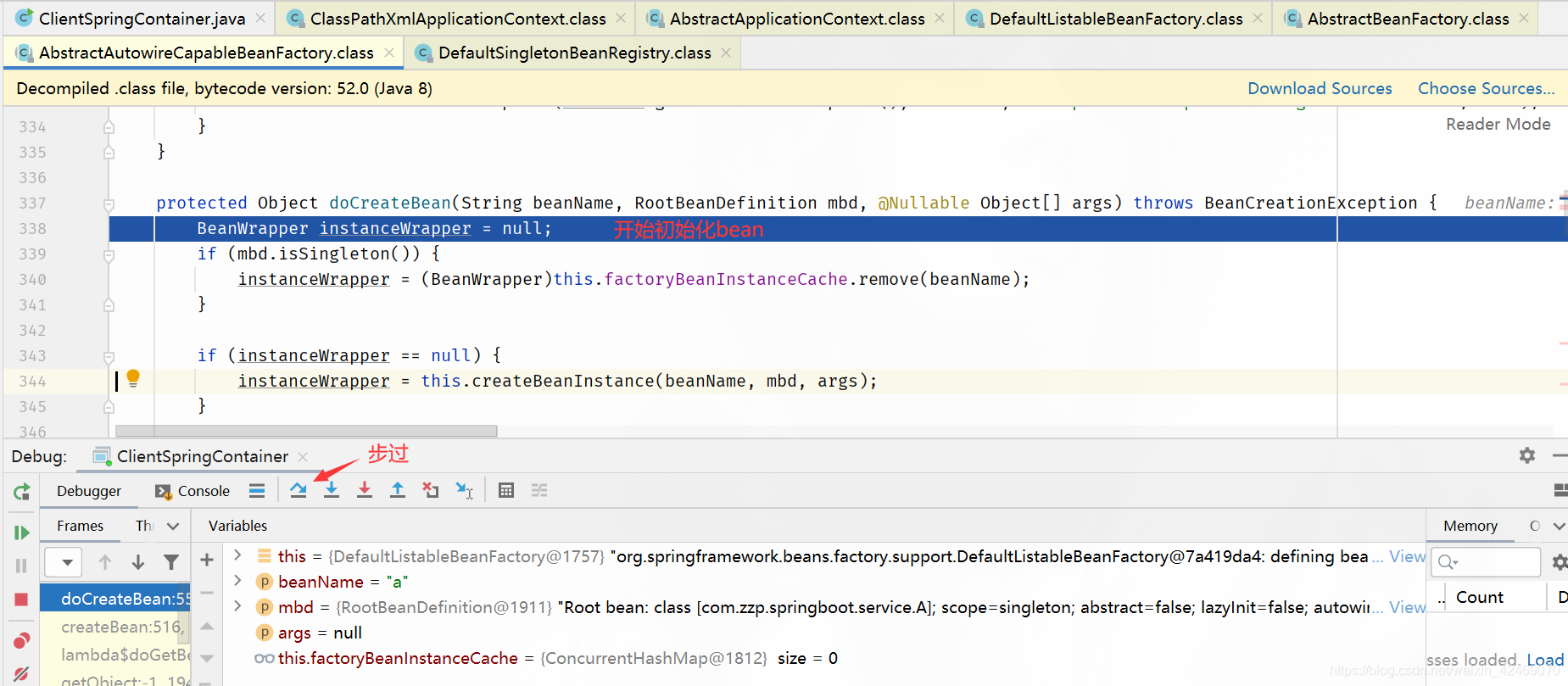
步过:
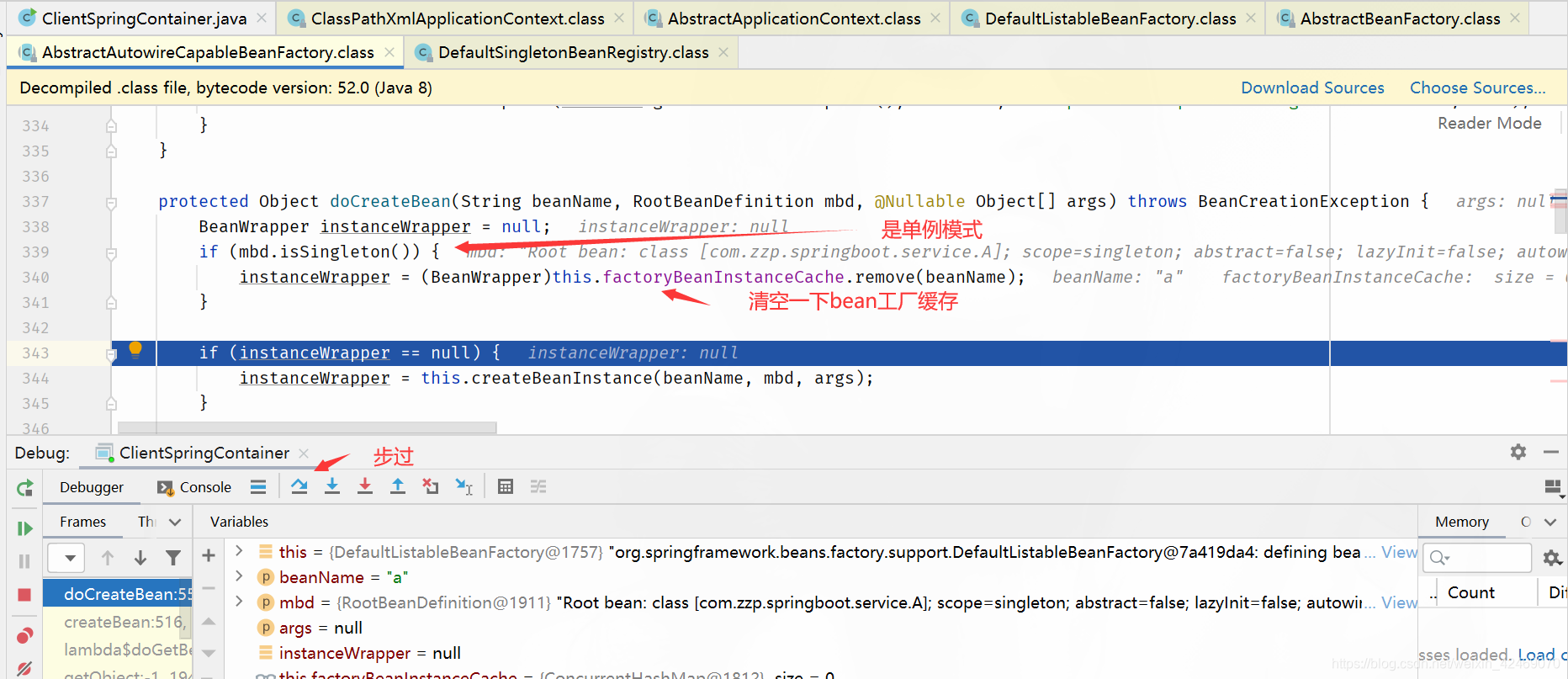
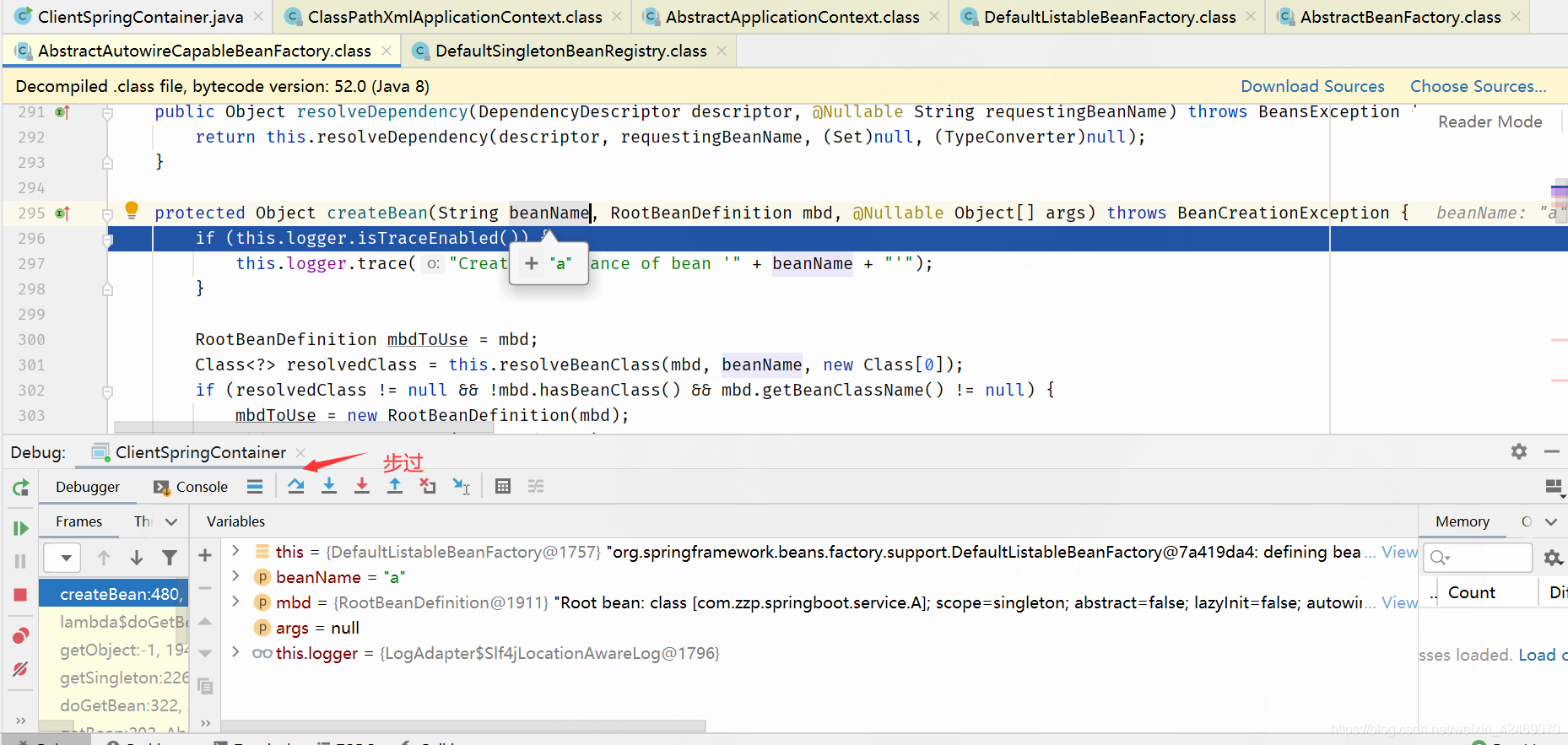
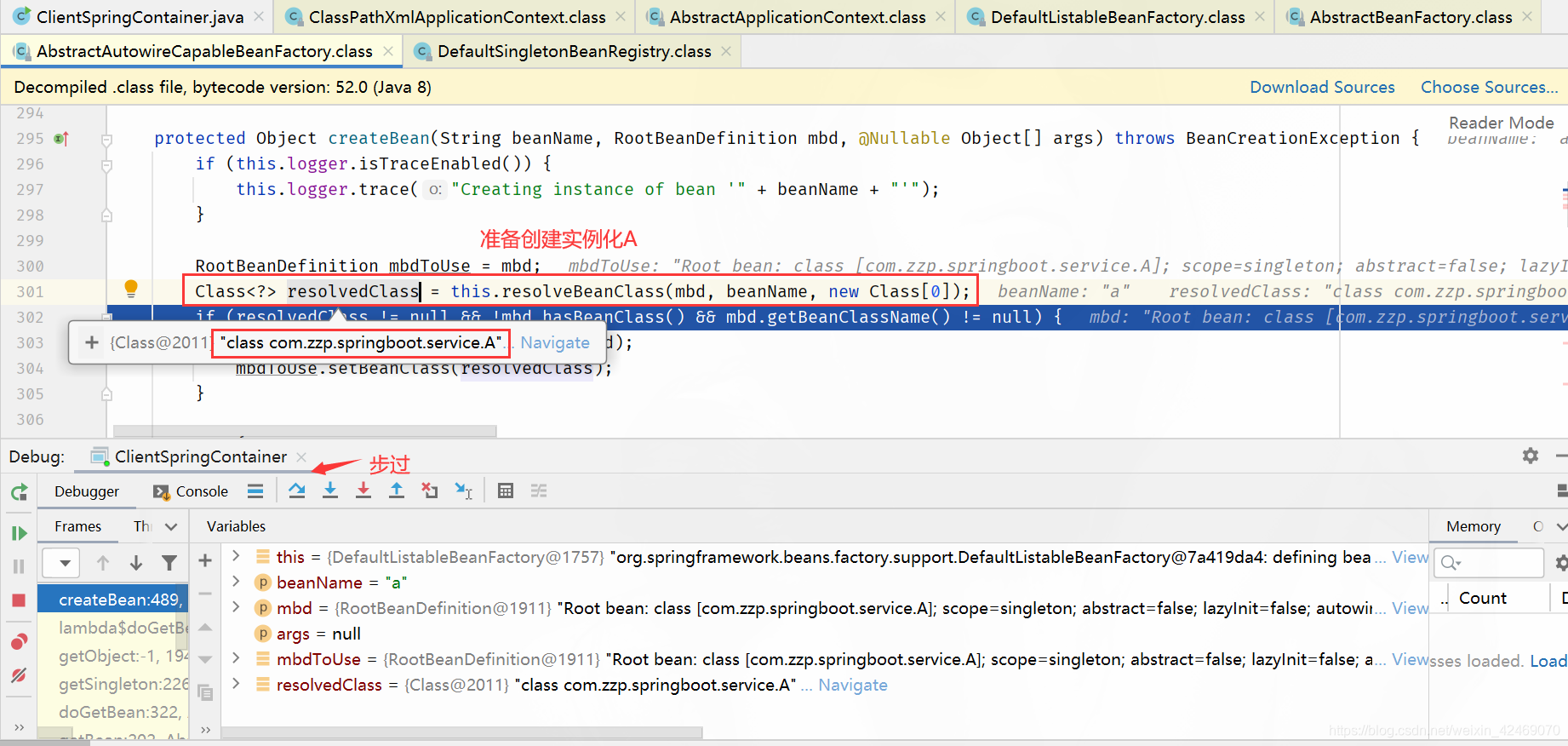
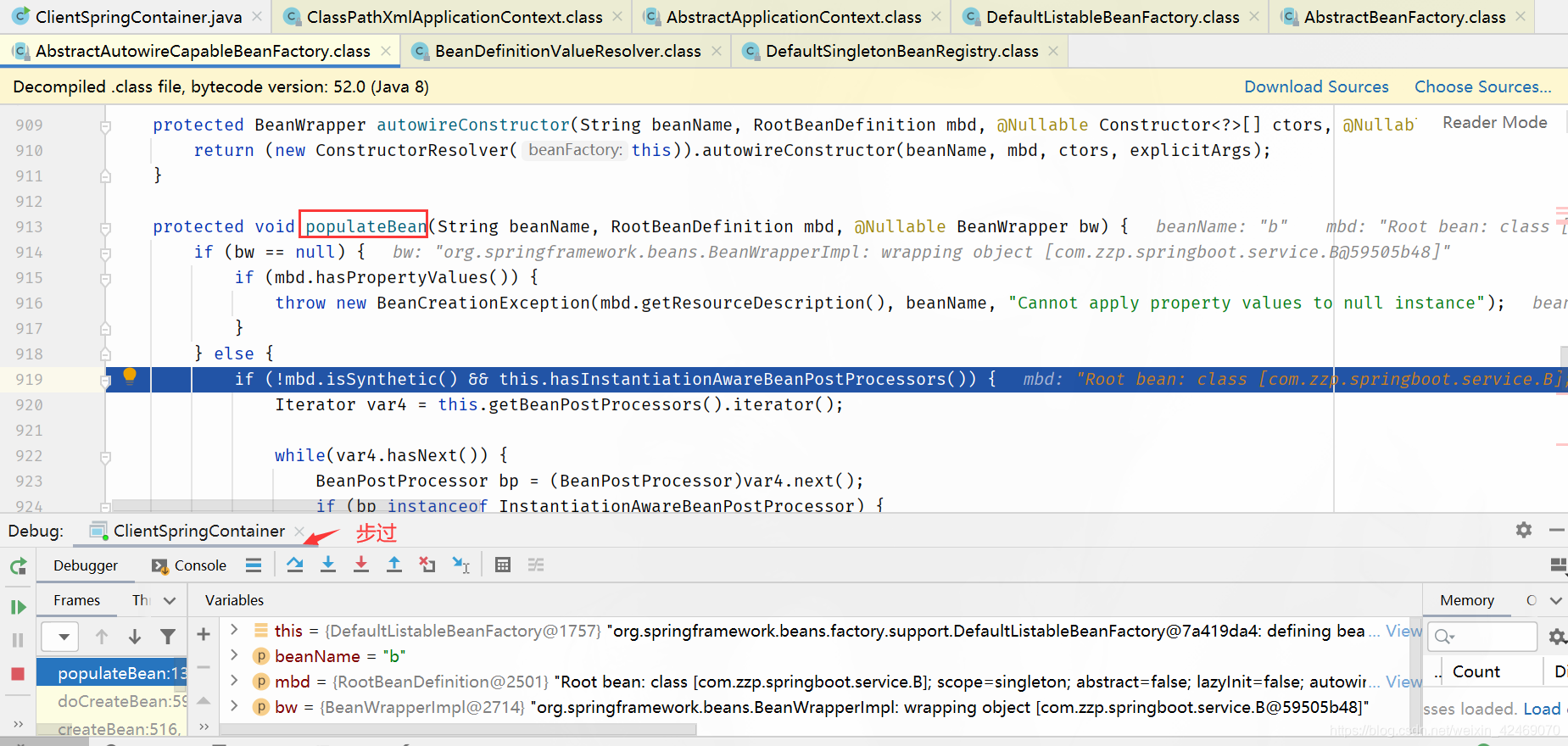
createBeanInstance()断点:创建bean实例:
步过:
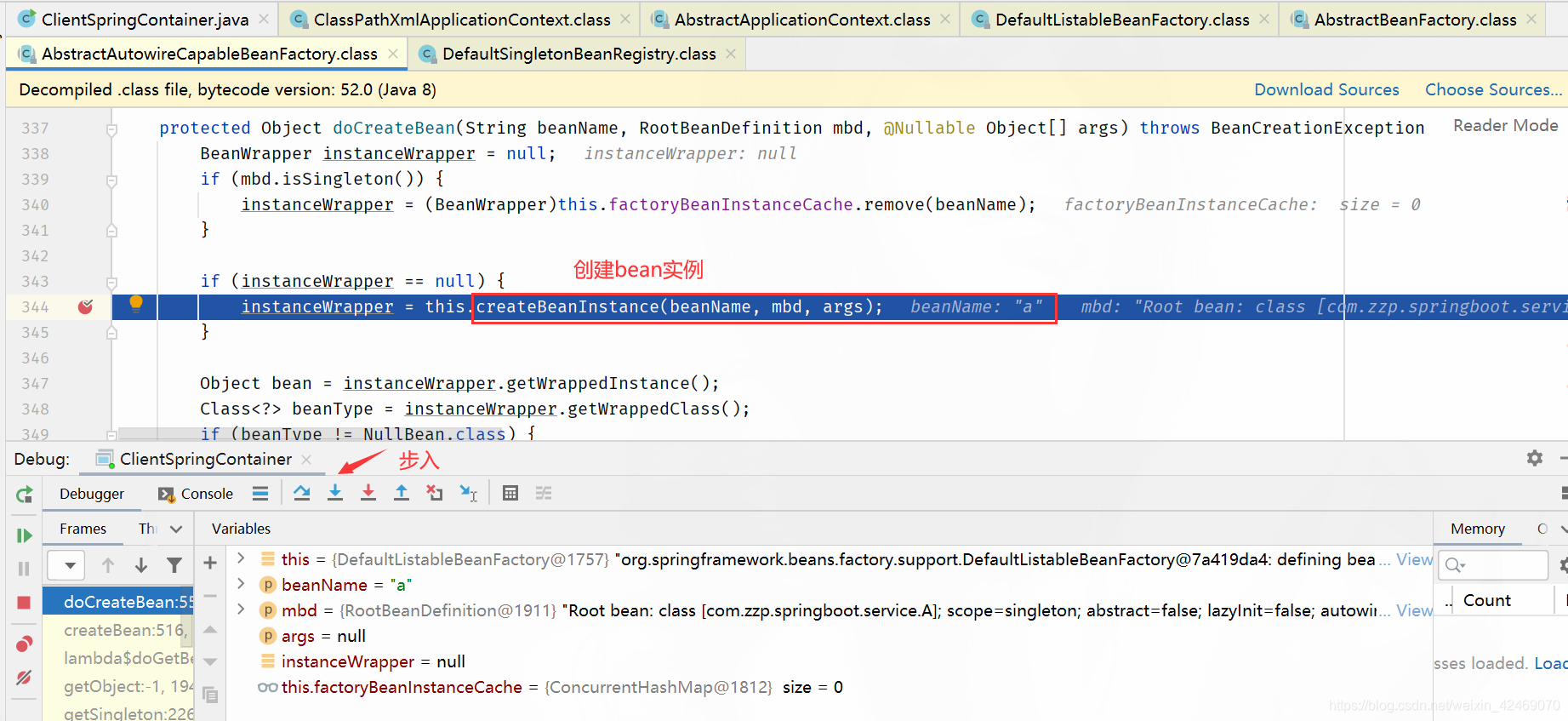
步入:
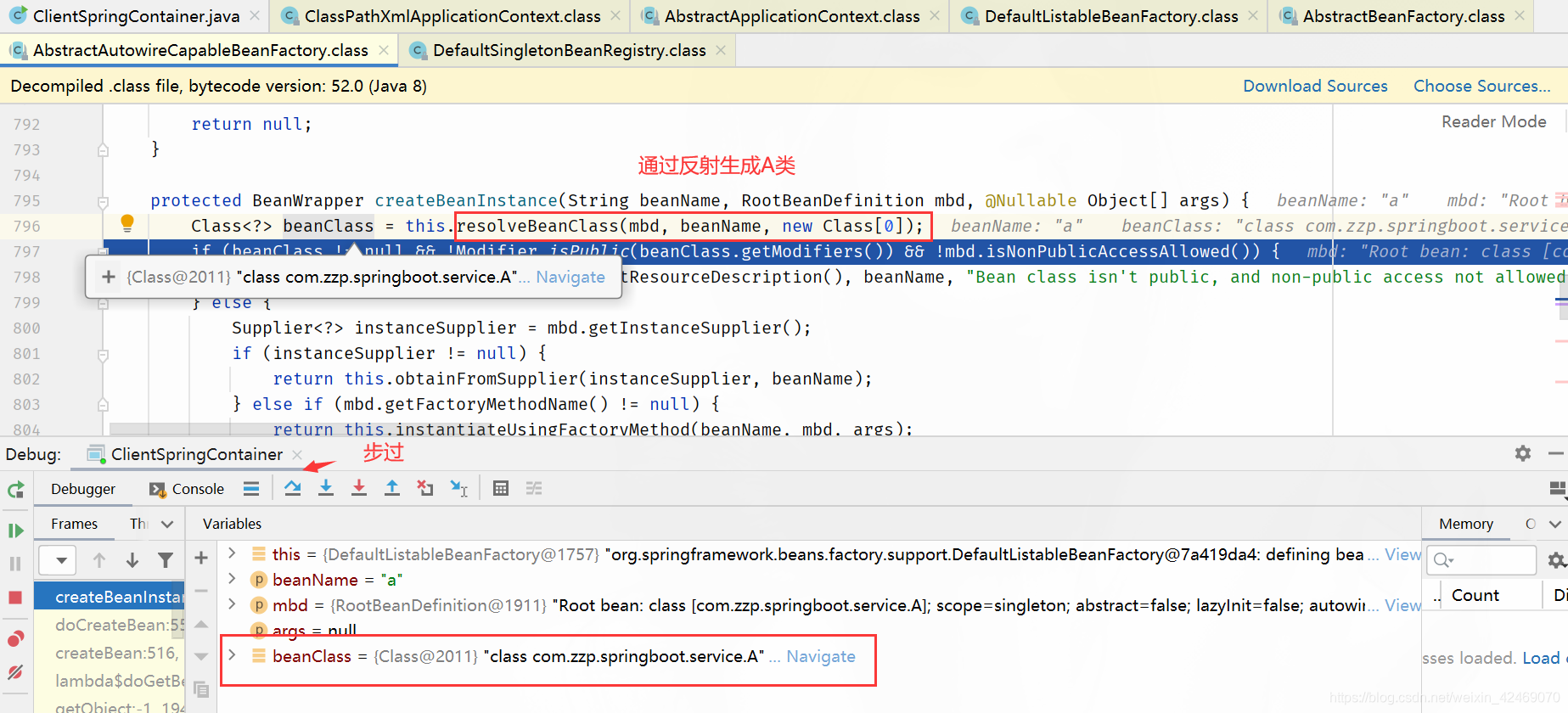
步过:
步过:
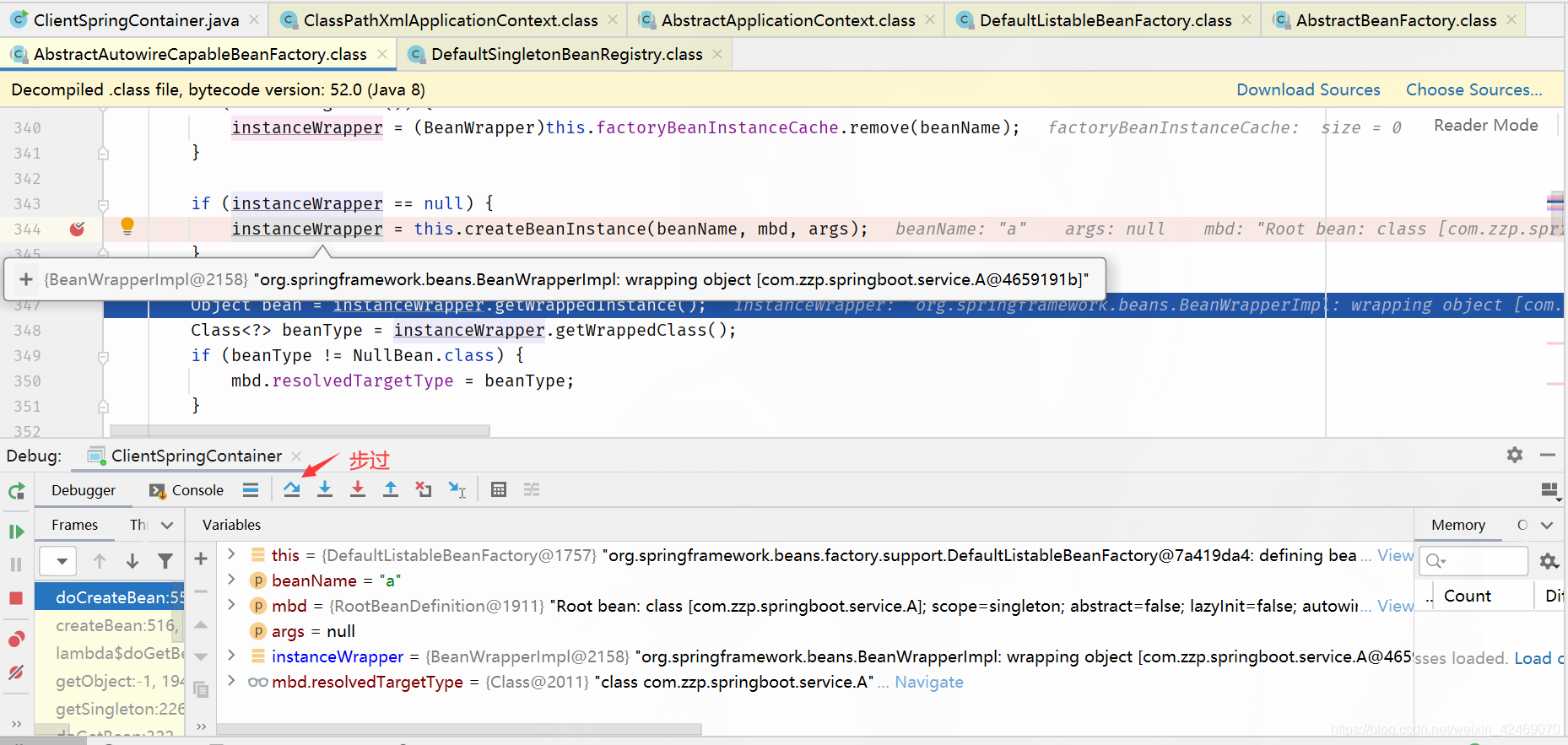
步过:

步过:
步过:
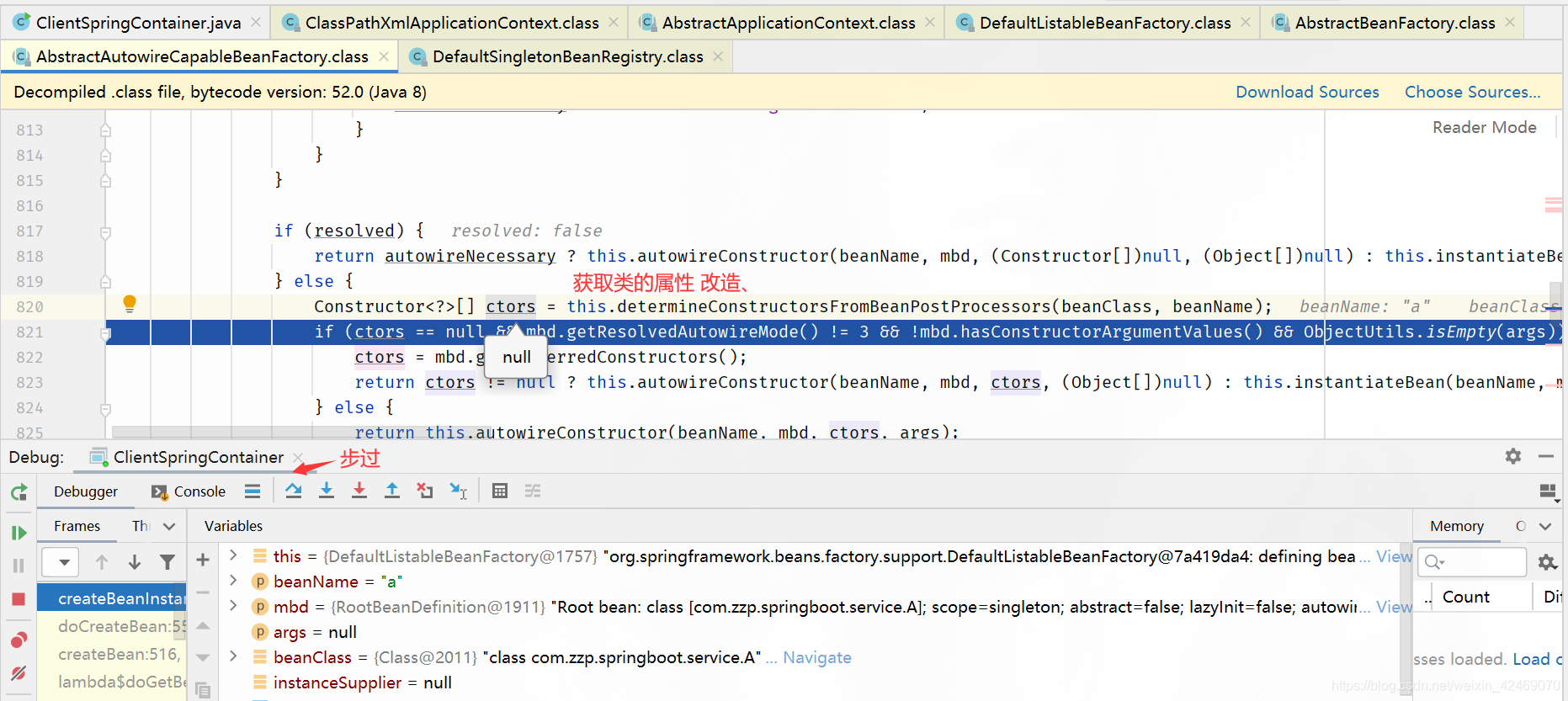
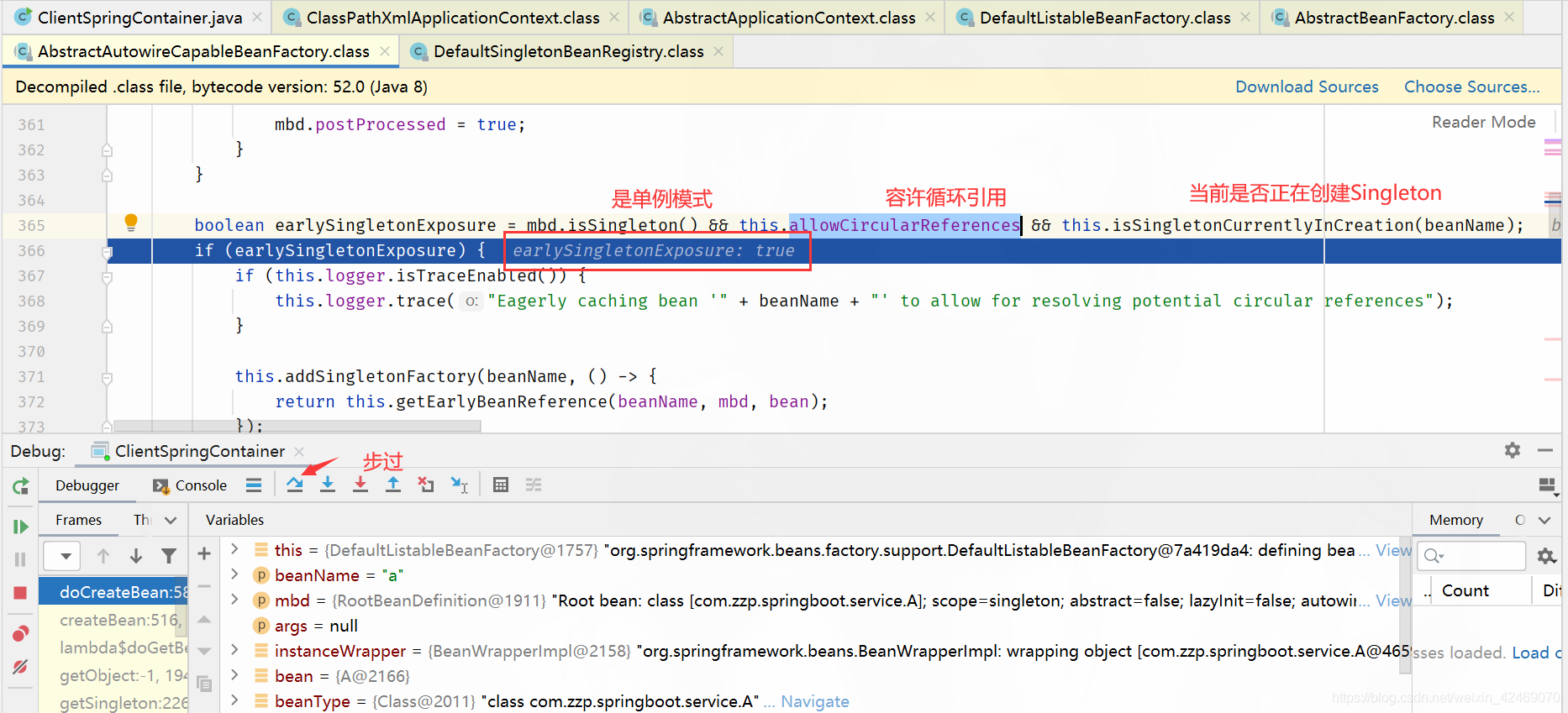
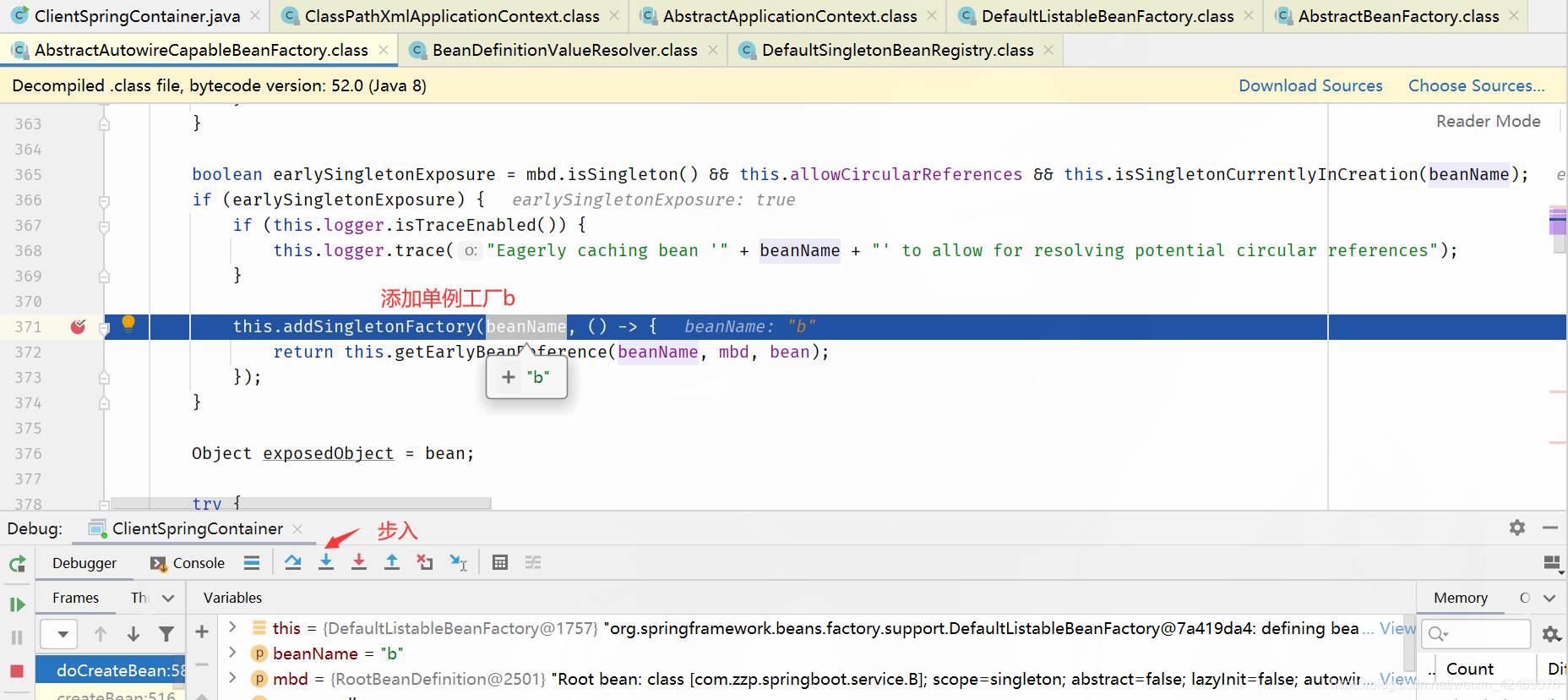
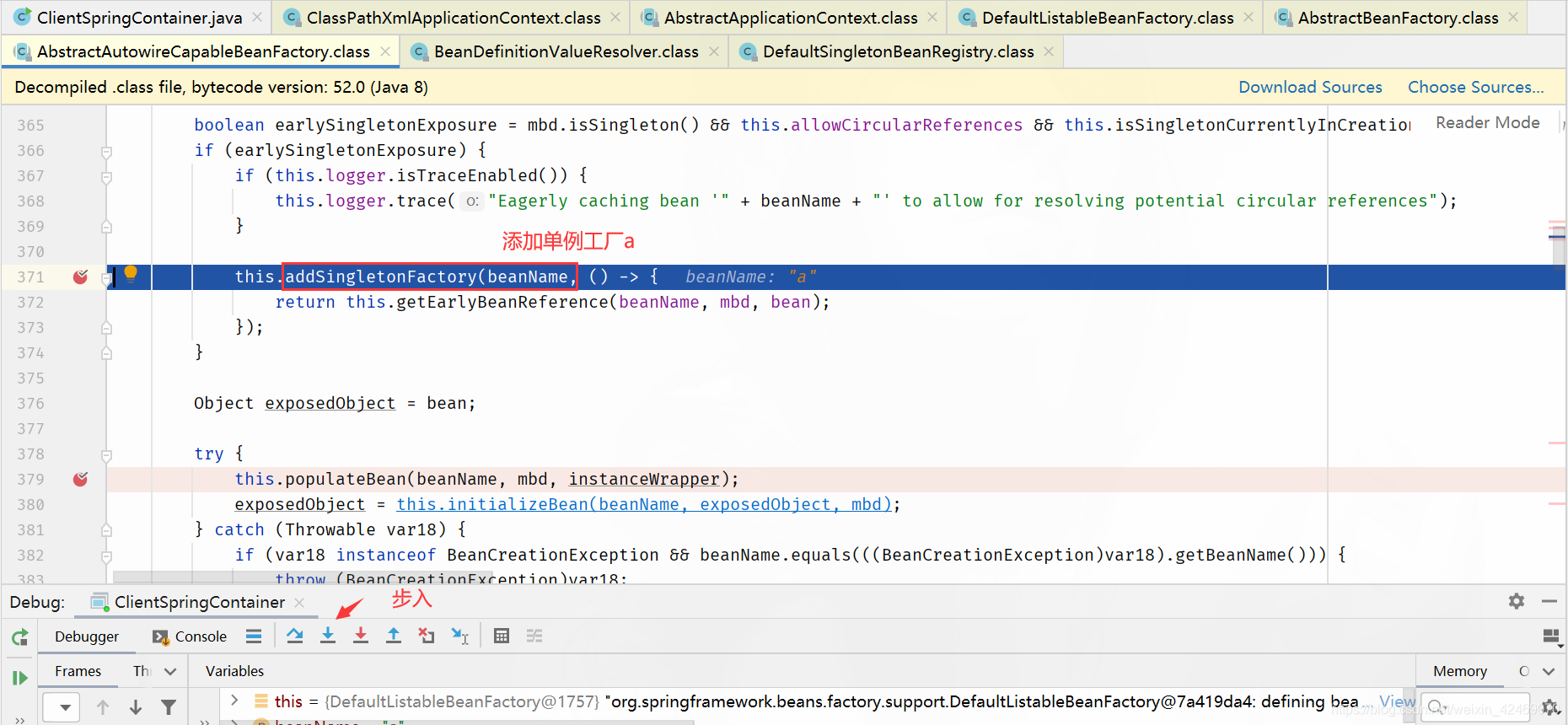
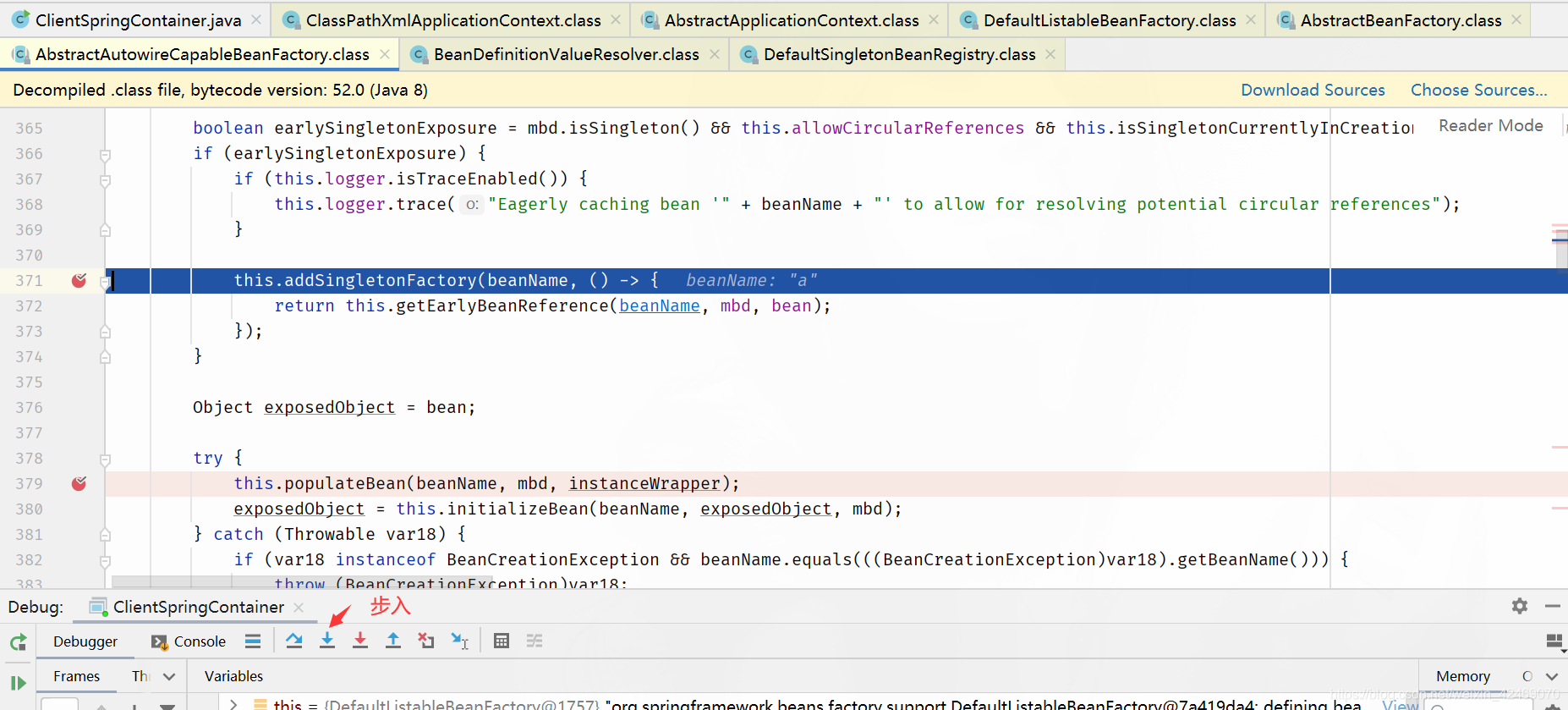
addSingletonFactory()断点:添加单例工厂
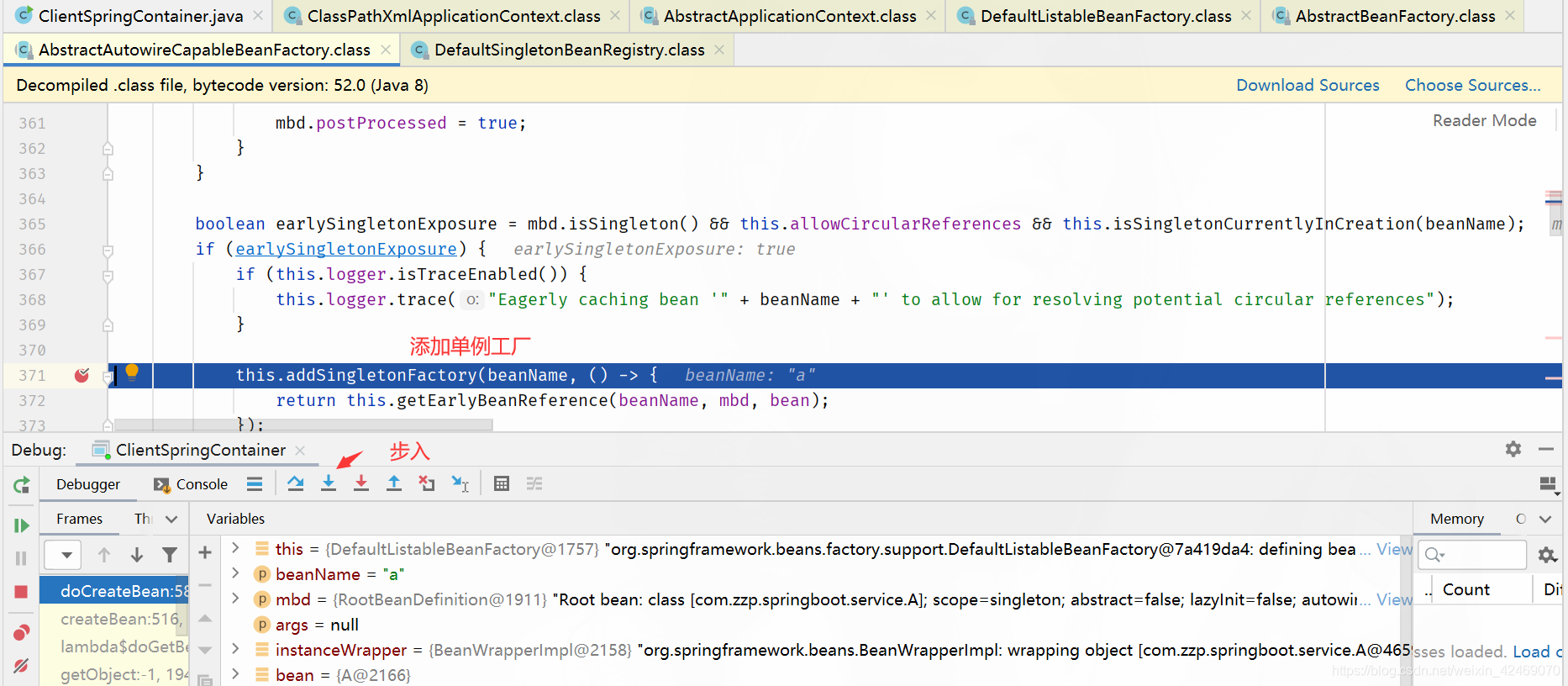
步入:
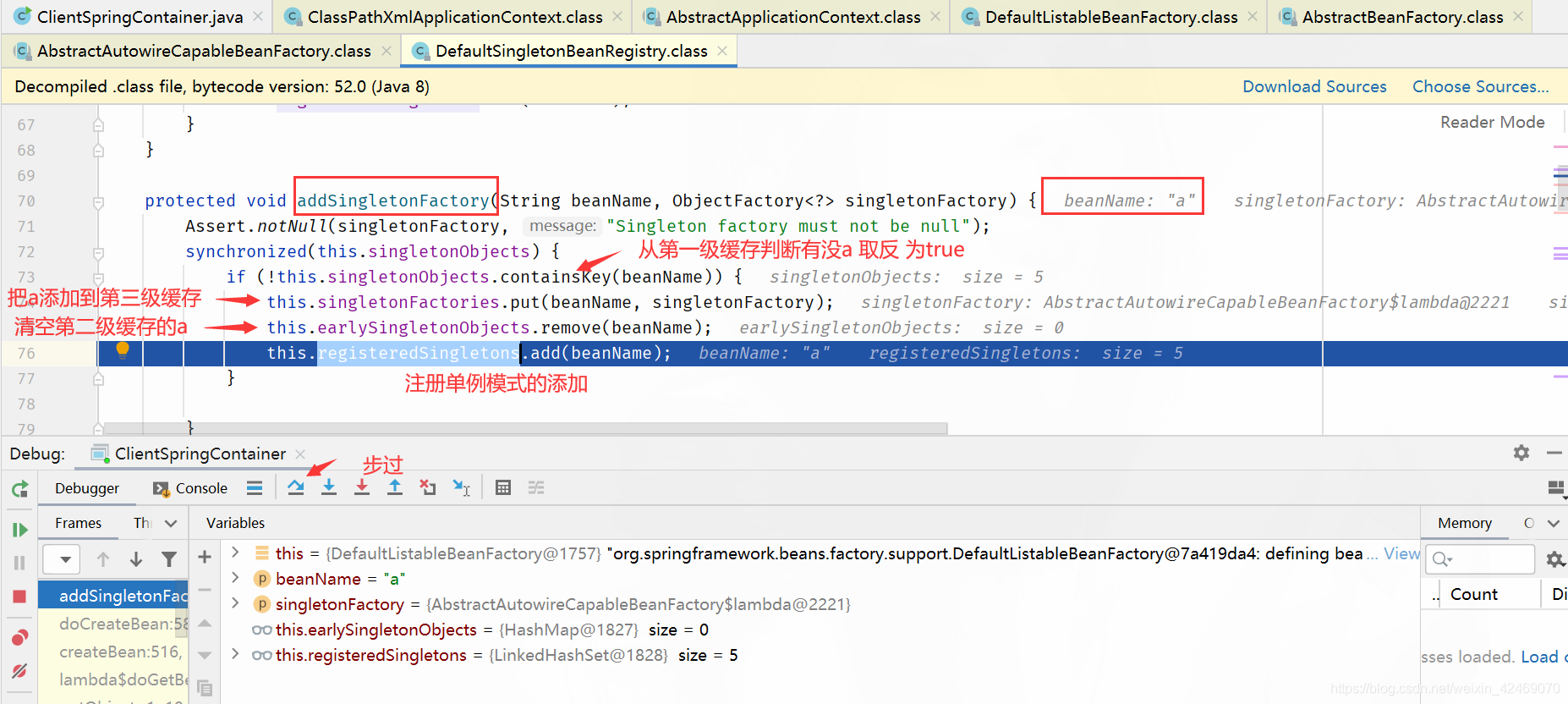
查看缓存:
| 缓存 | A | B |
|---|---|---|
| 第一级缓存(singletonObjects) | null,null | null,null |
| 第二级缓存(earlySingletonObjects) | null,null | null,null |
| 第三级缓存(singletonFactories) | a,lambda表达式 | null,null |
步过:
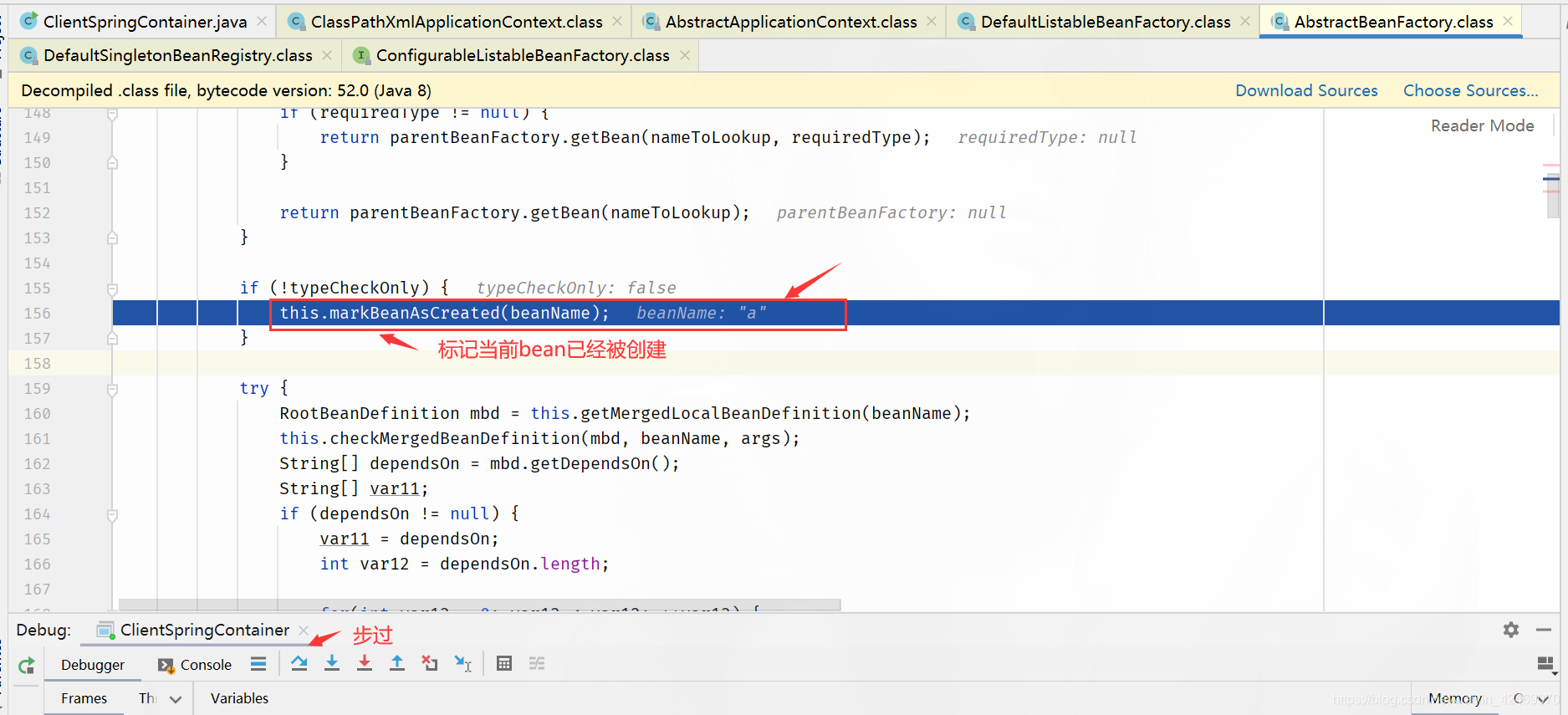
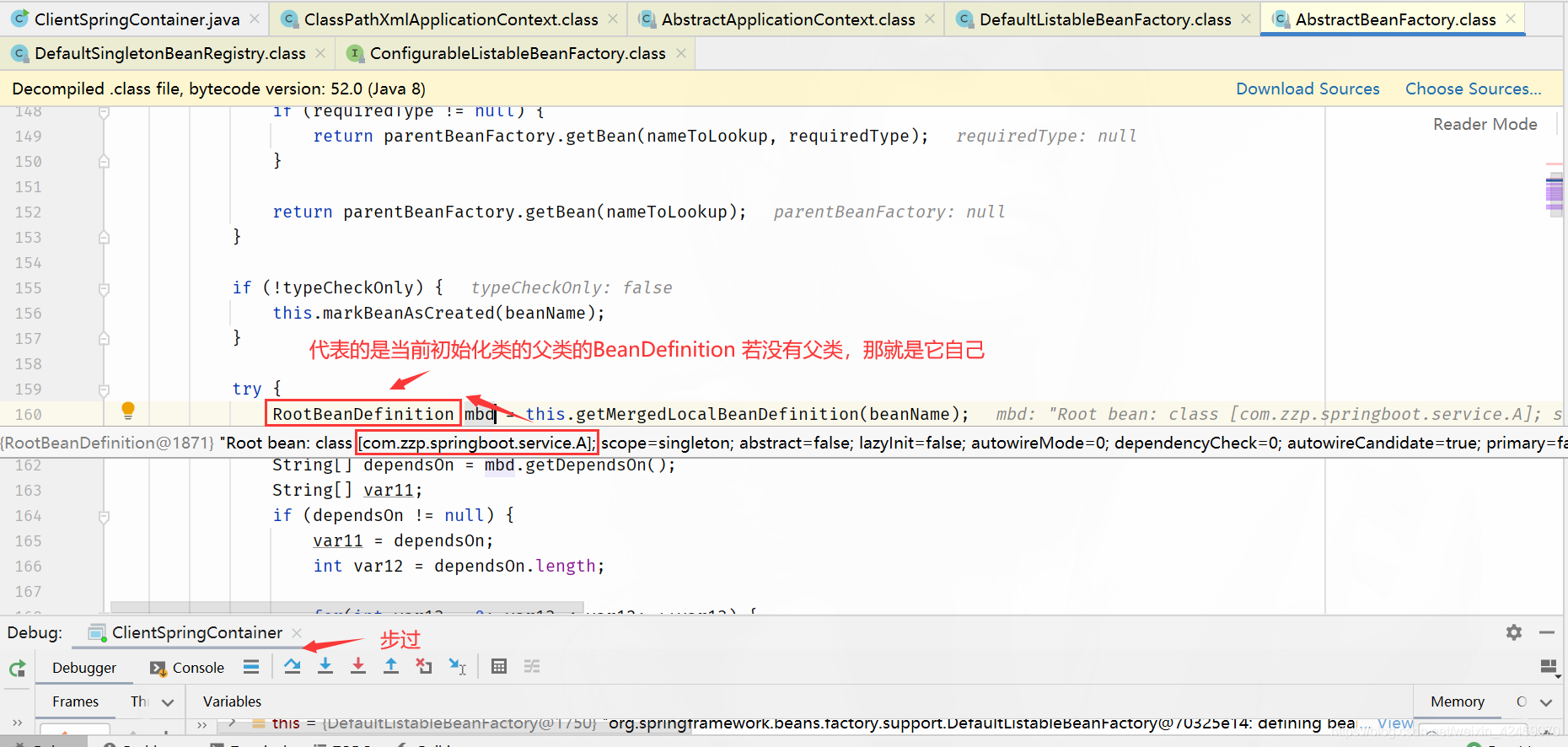
populateBean()断点:属性填充(第三个方法)

步入:
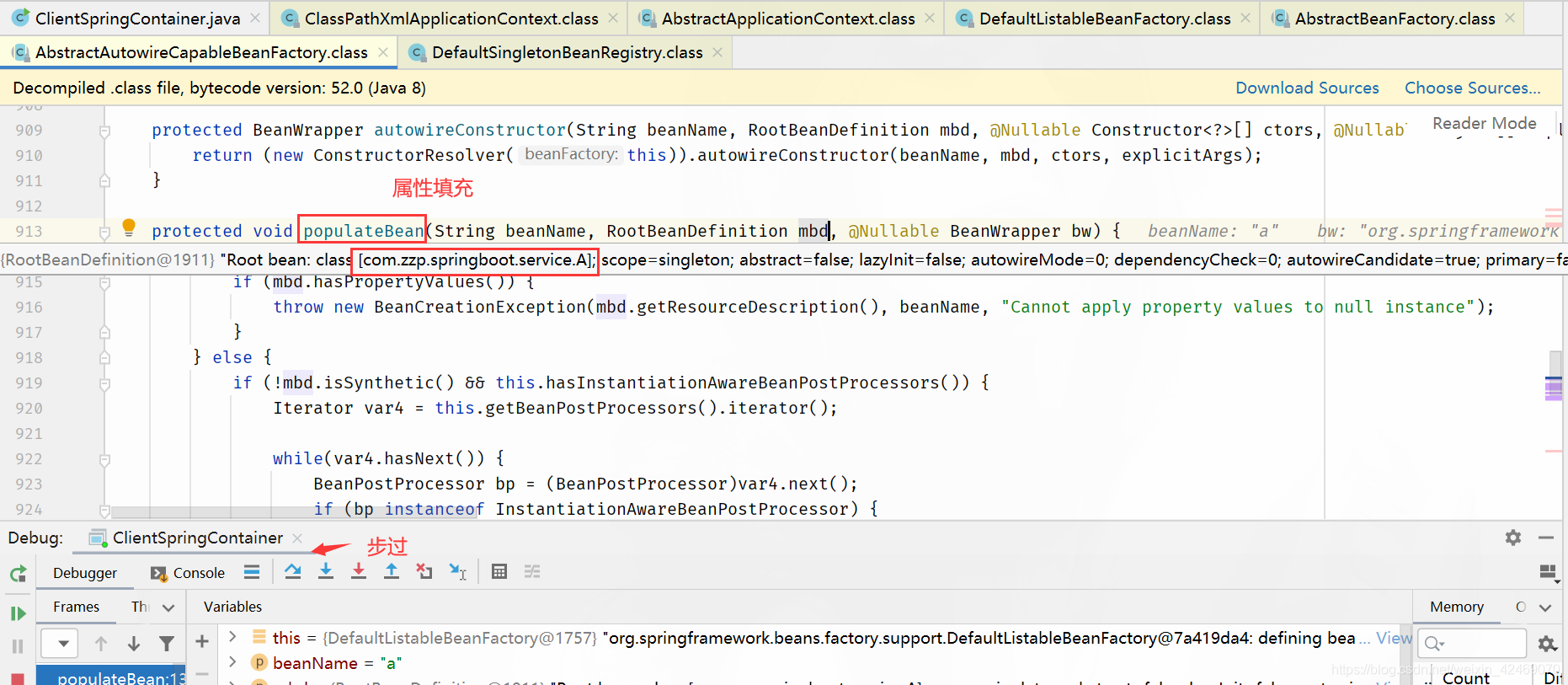
步过:
步过:
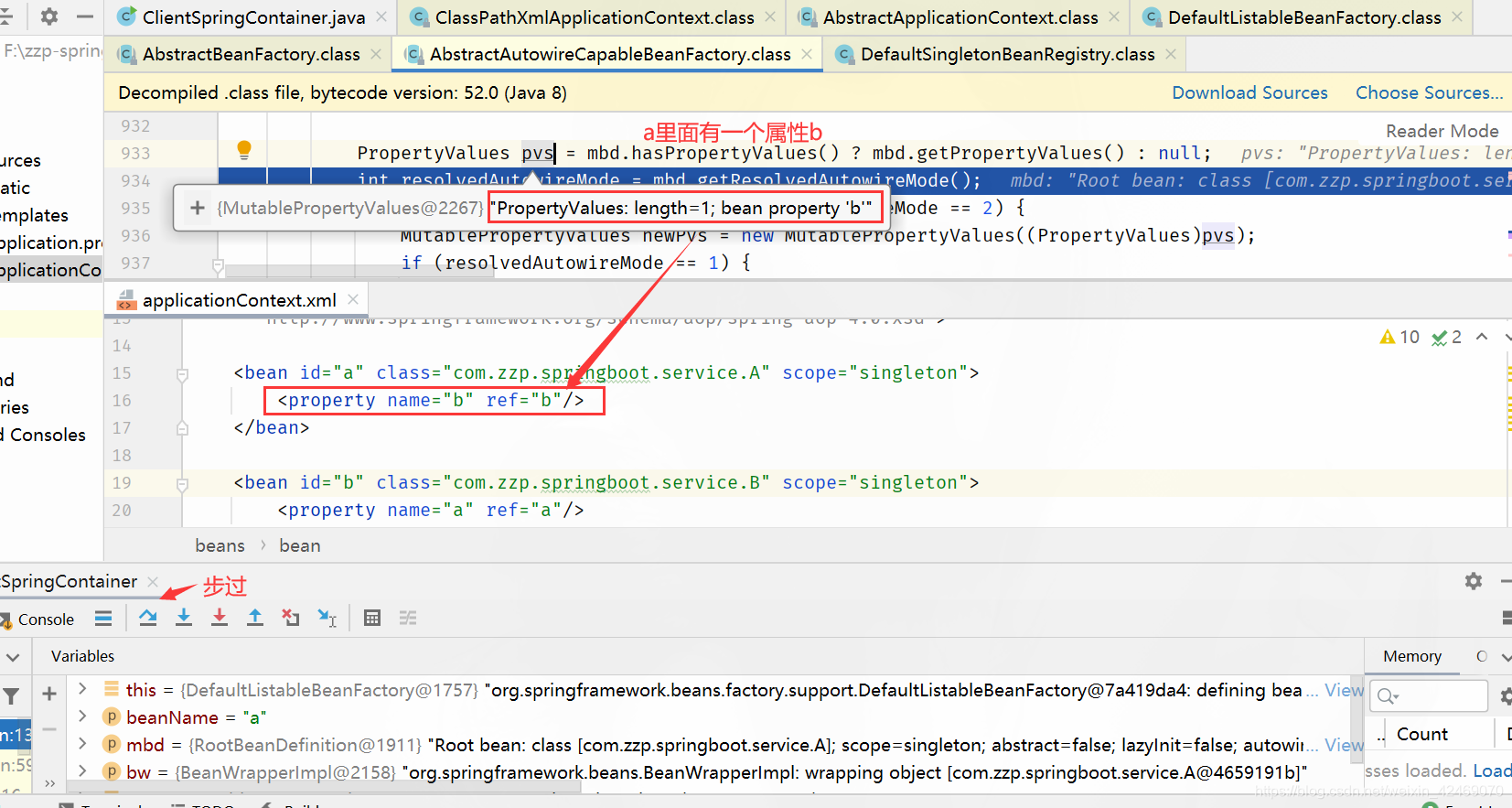
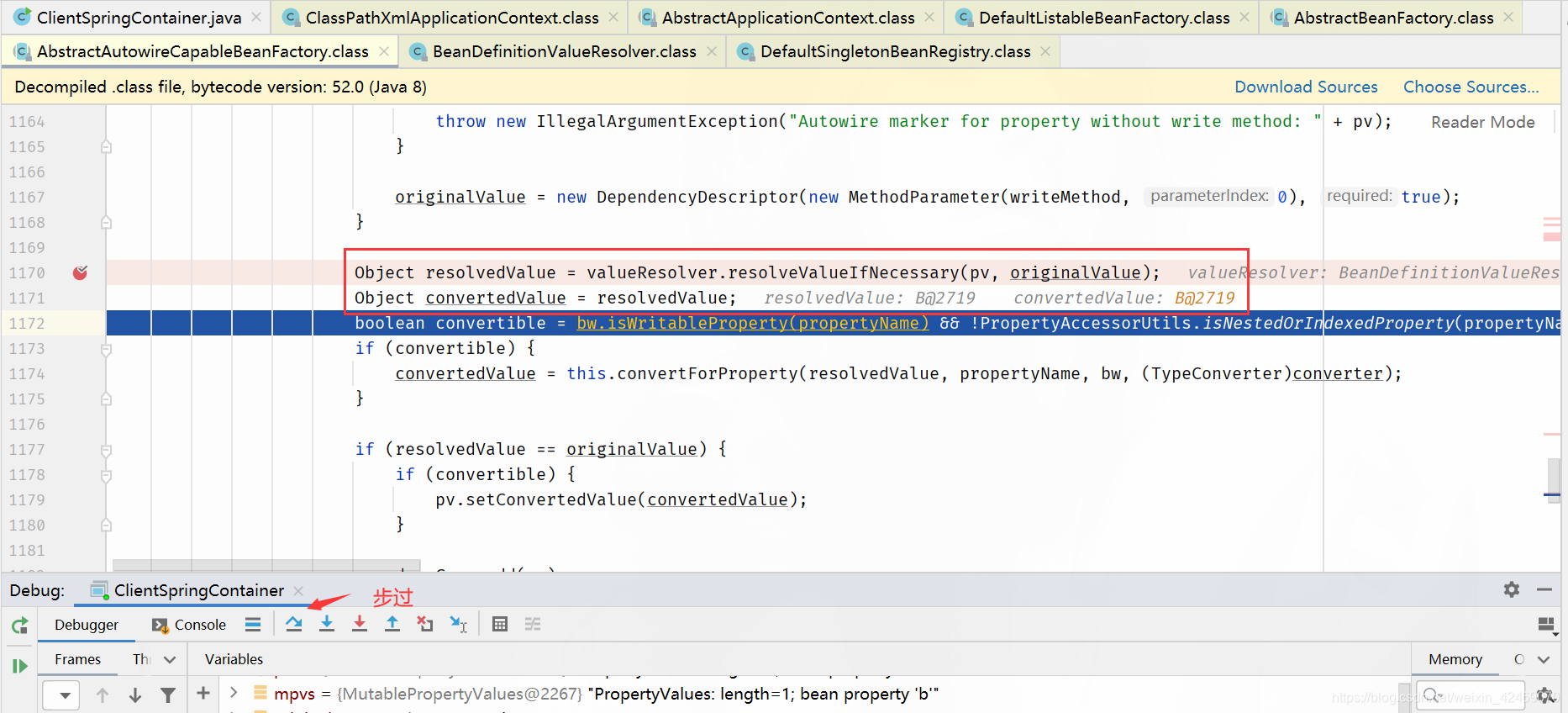
applyPropertyValues()断点:属性注入
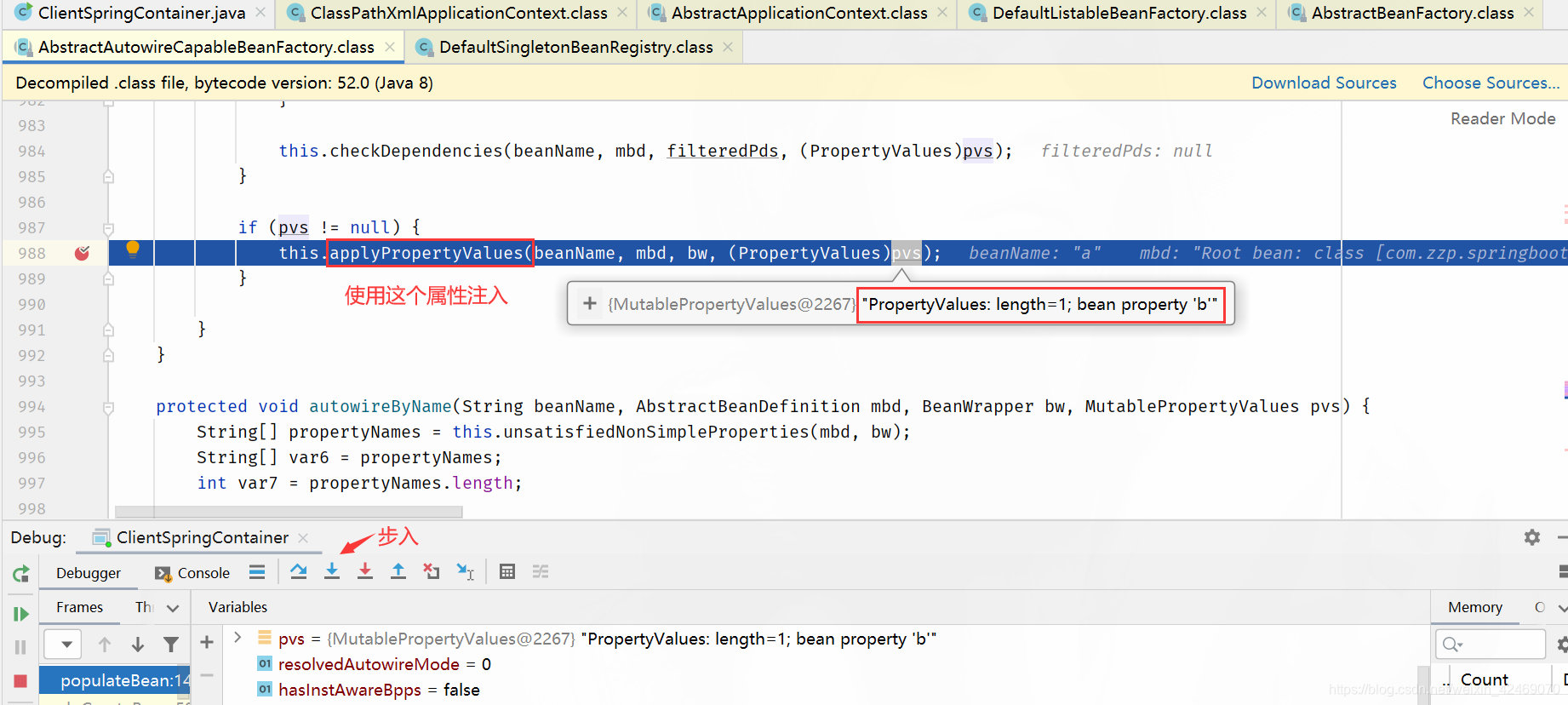
步入:
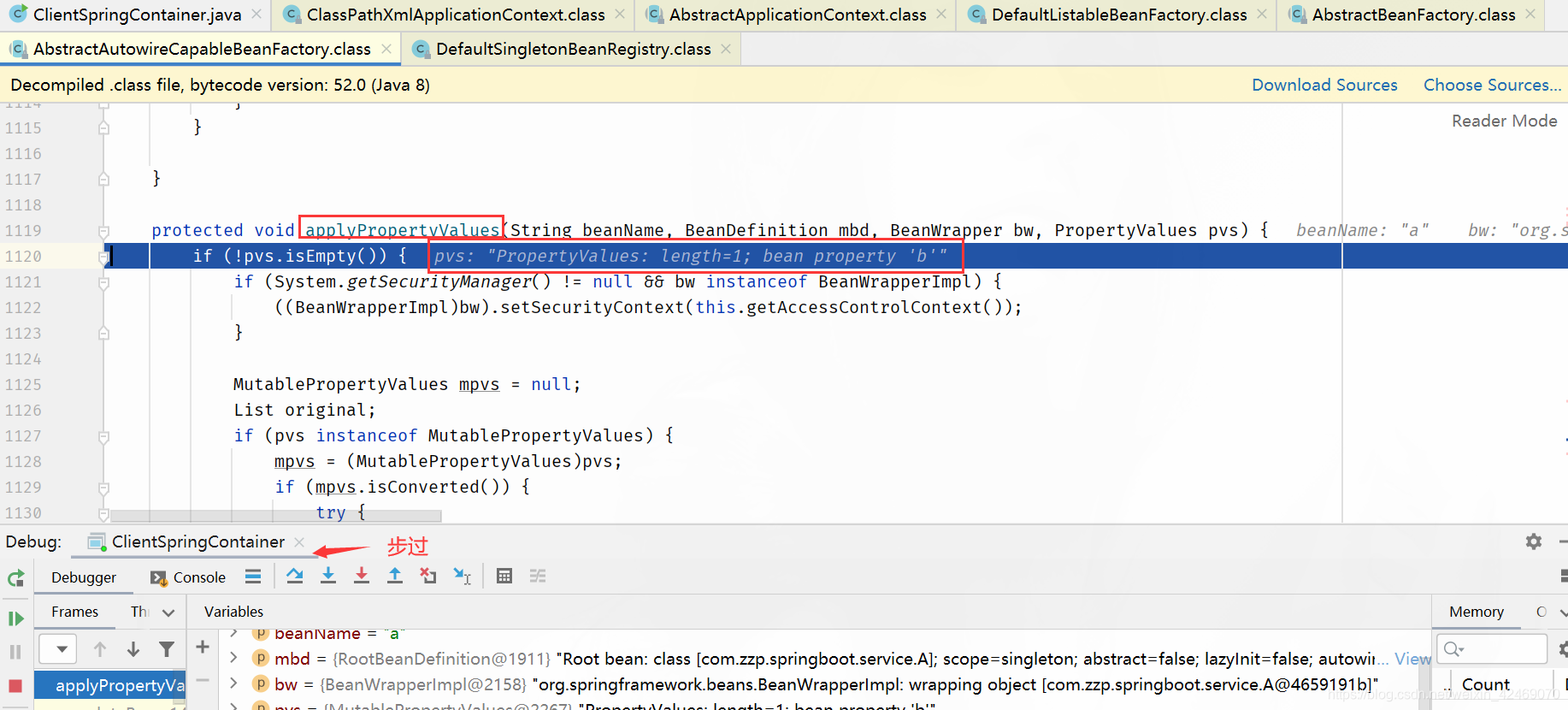
步过:
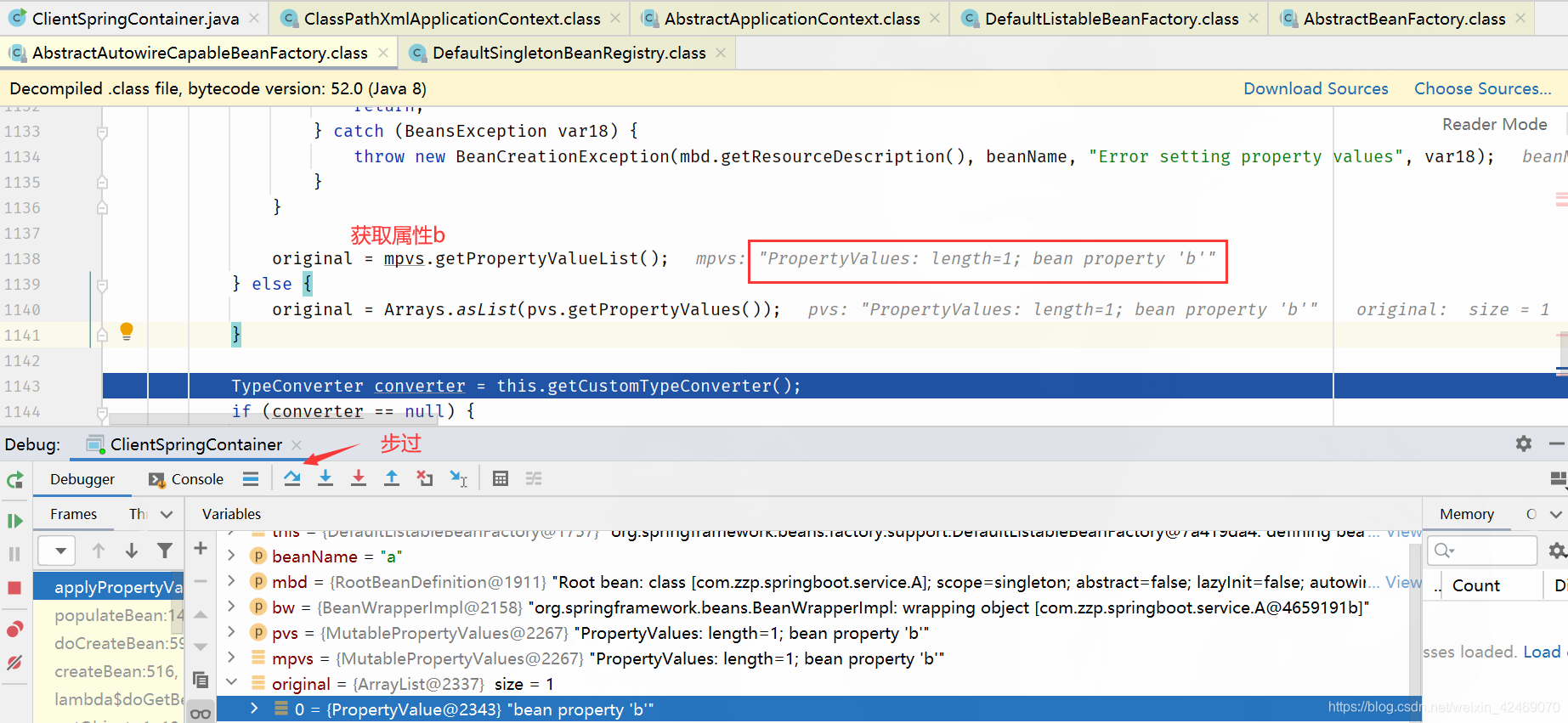
步过:
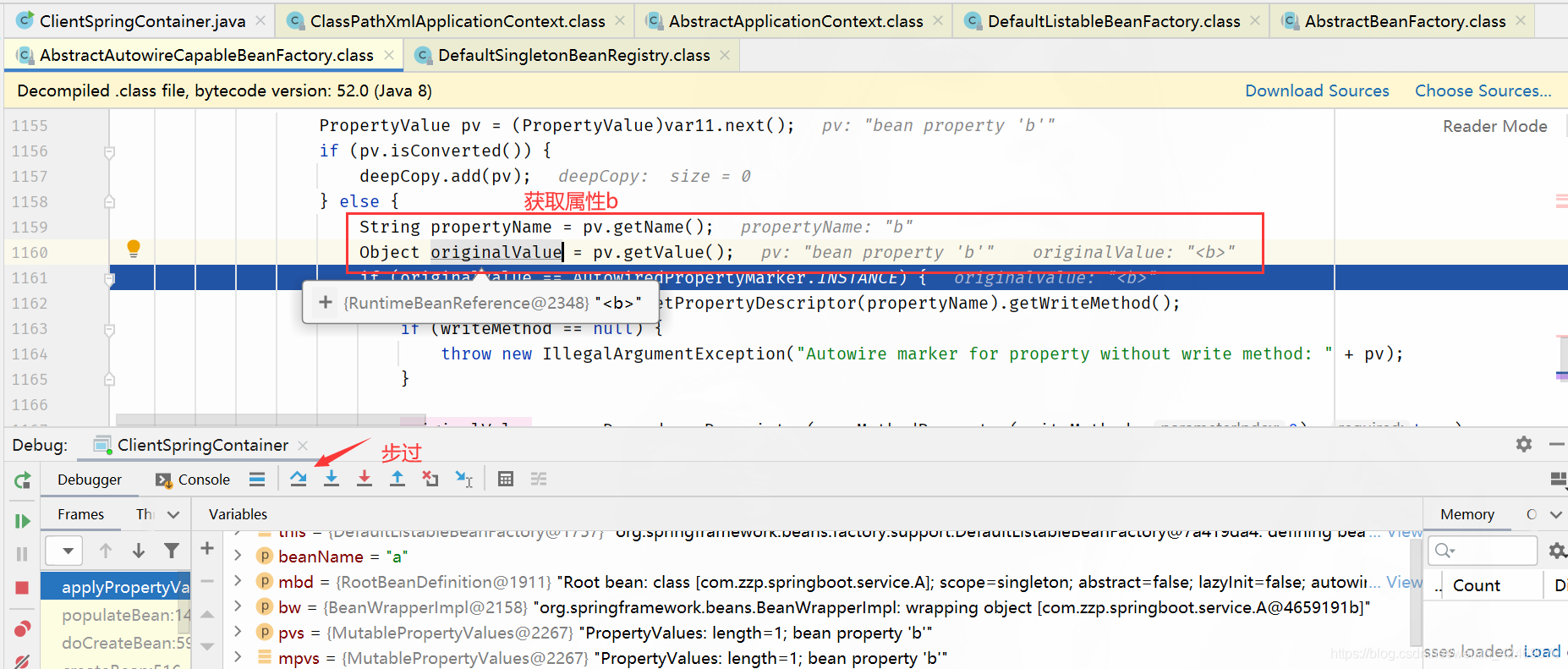
步过:
resolveValueIfNecessary断点:必要时解析值(解析属性值)
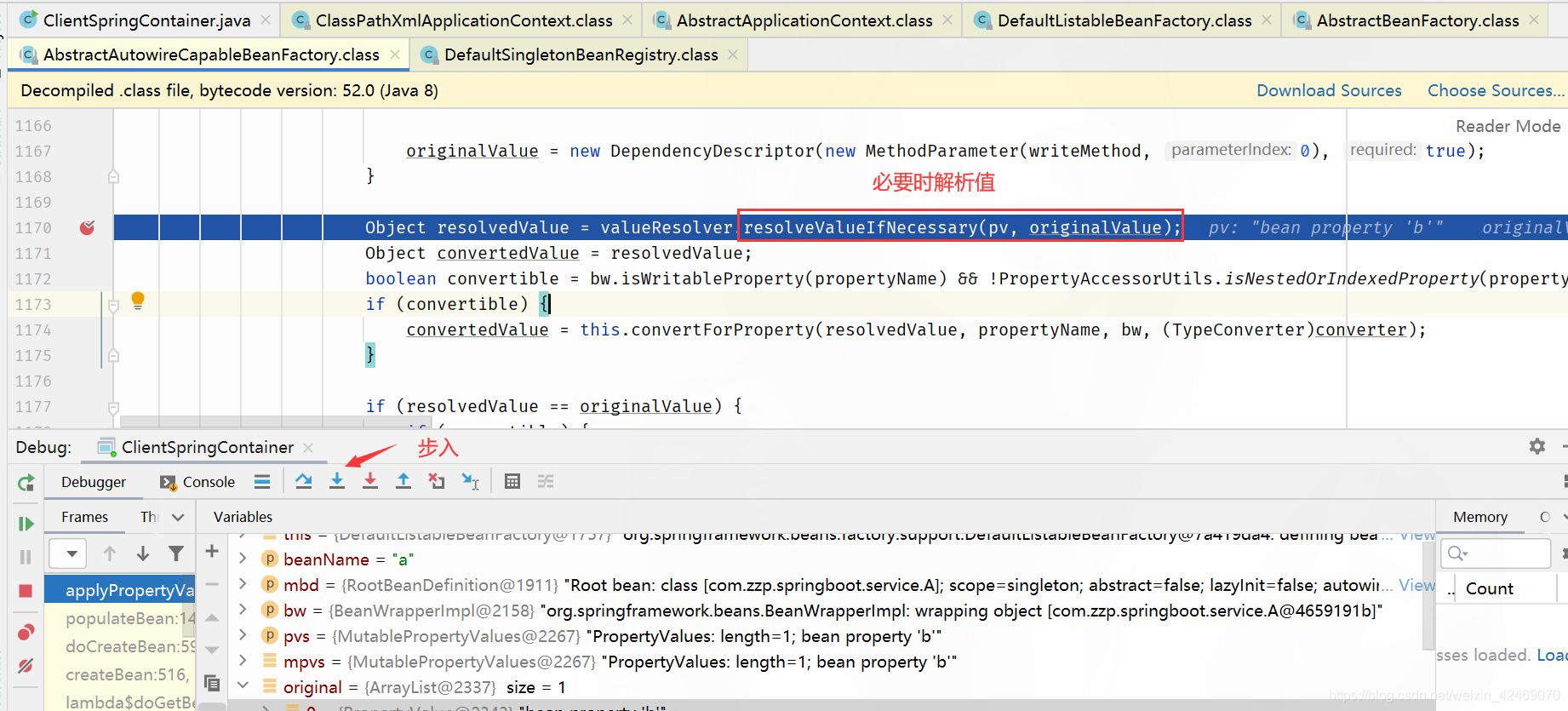
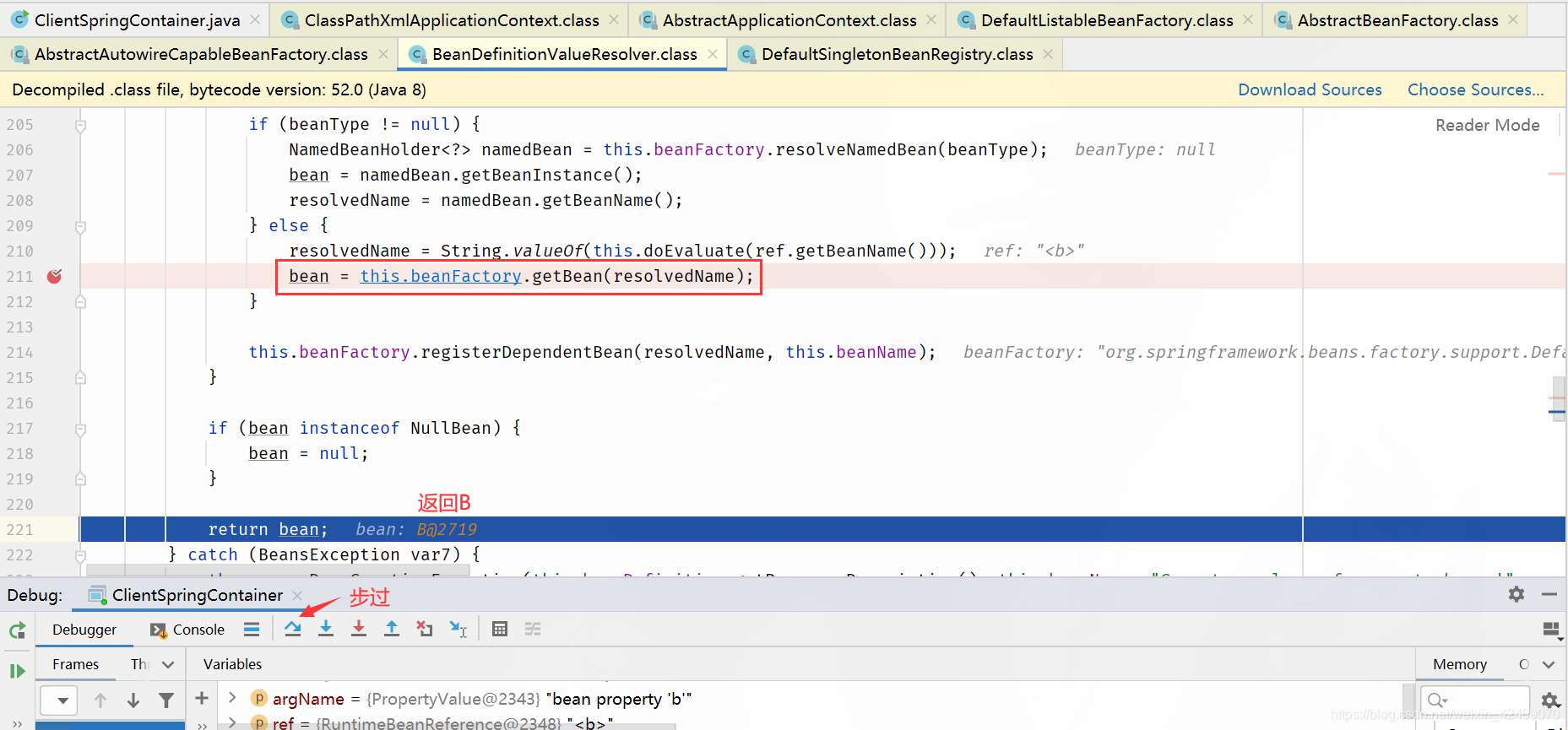
步入:
resolveReference()断点:解决引用属性
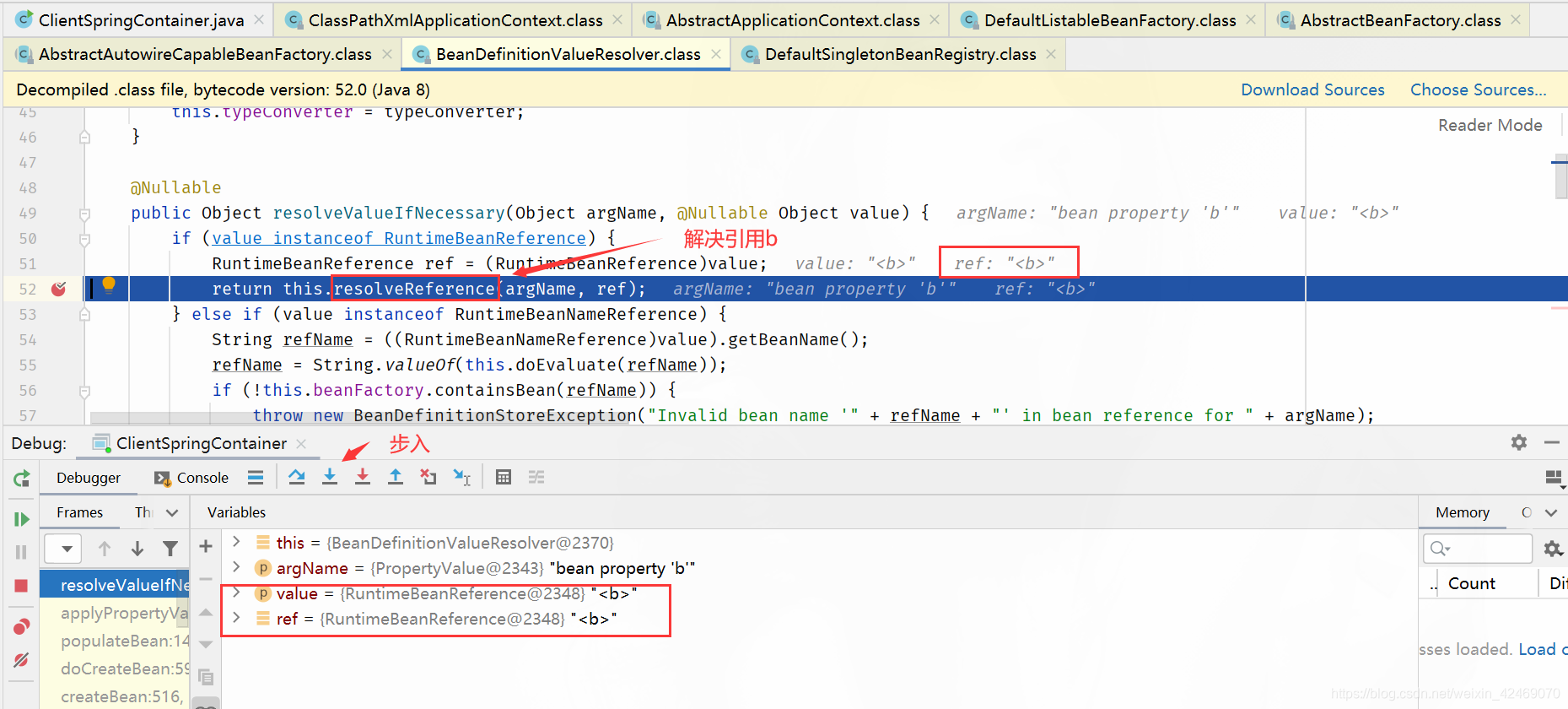
步入:
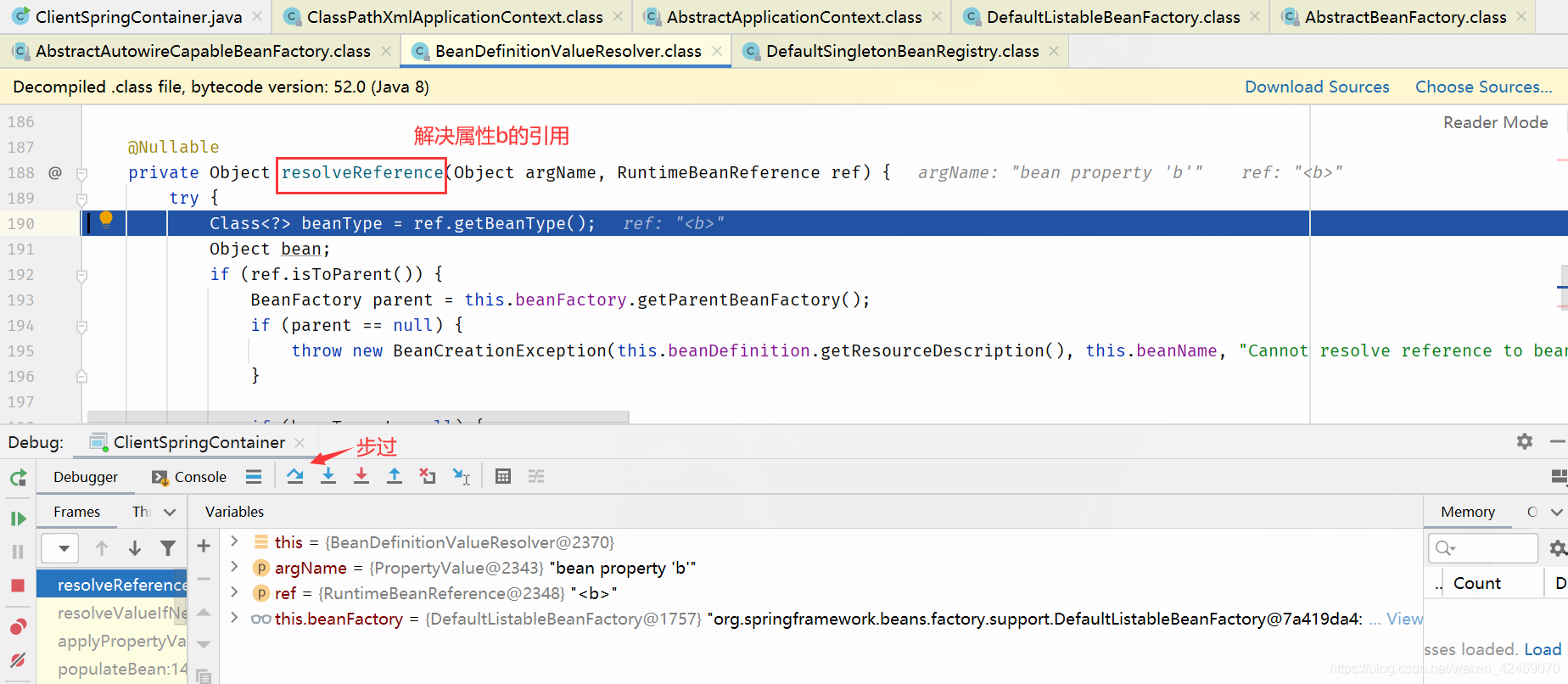
步过:
getBean()断点:获取bean
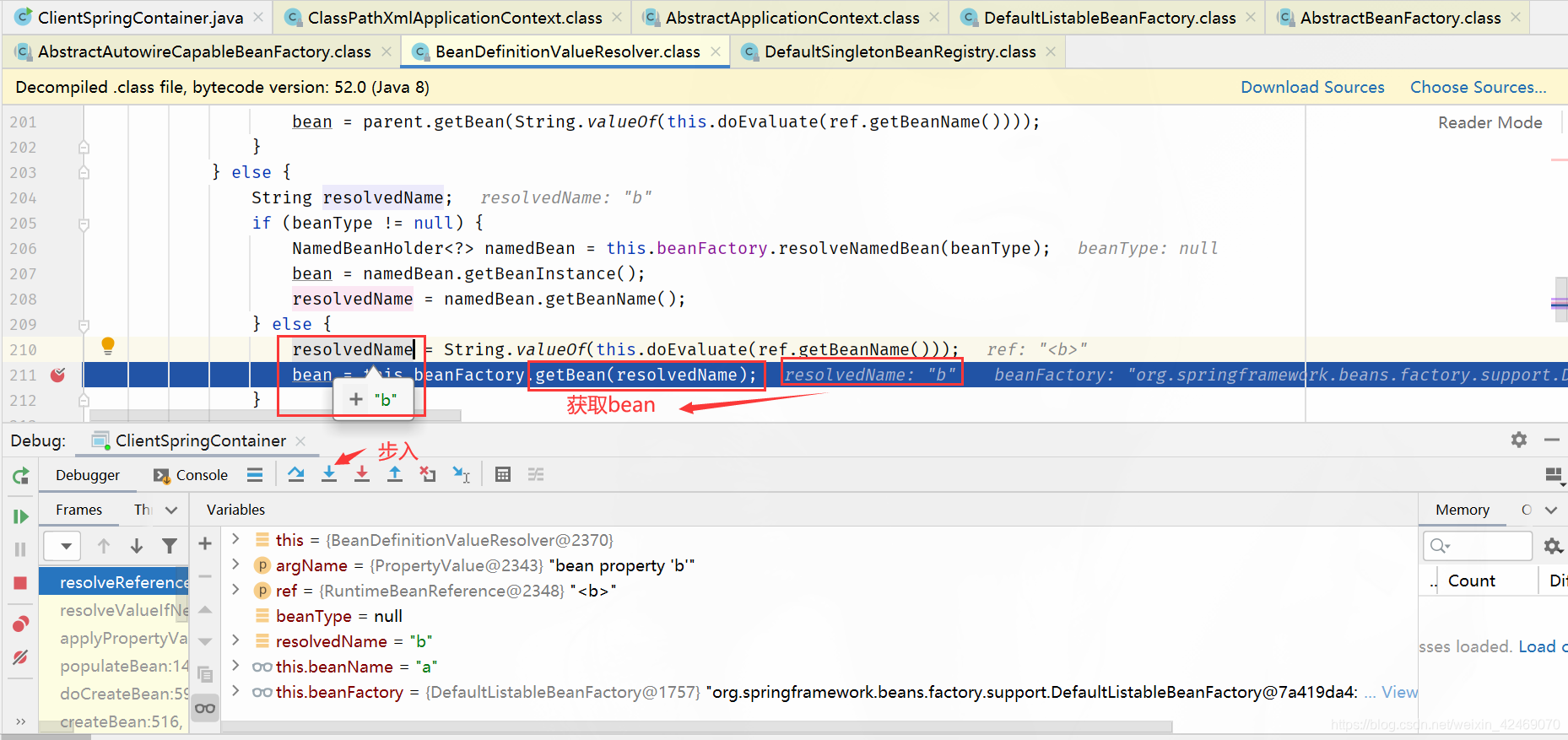
doGetBean():向IOC容器获取被管理Bean的过程
步入:
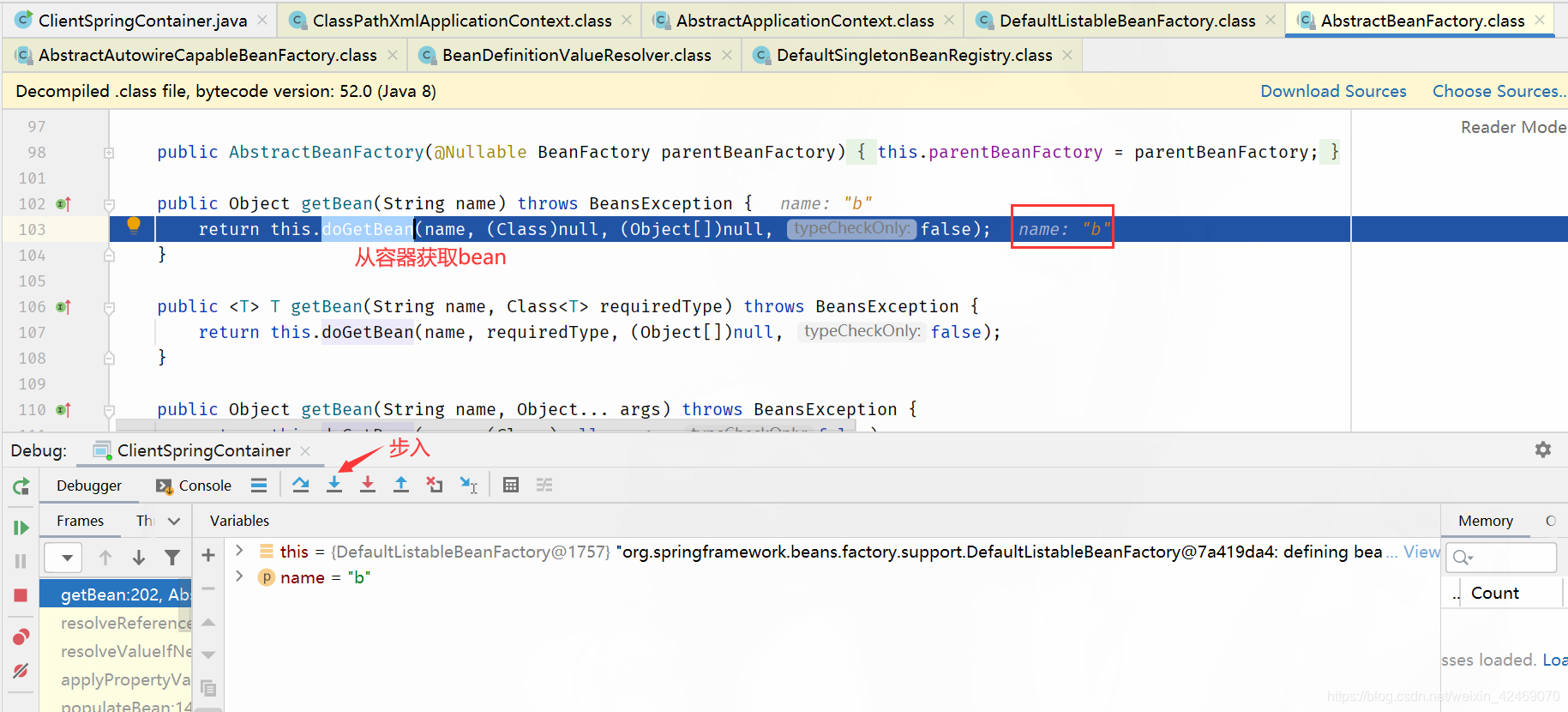
步入:
getSingleton():获取单例
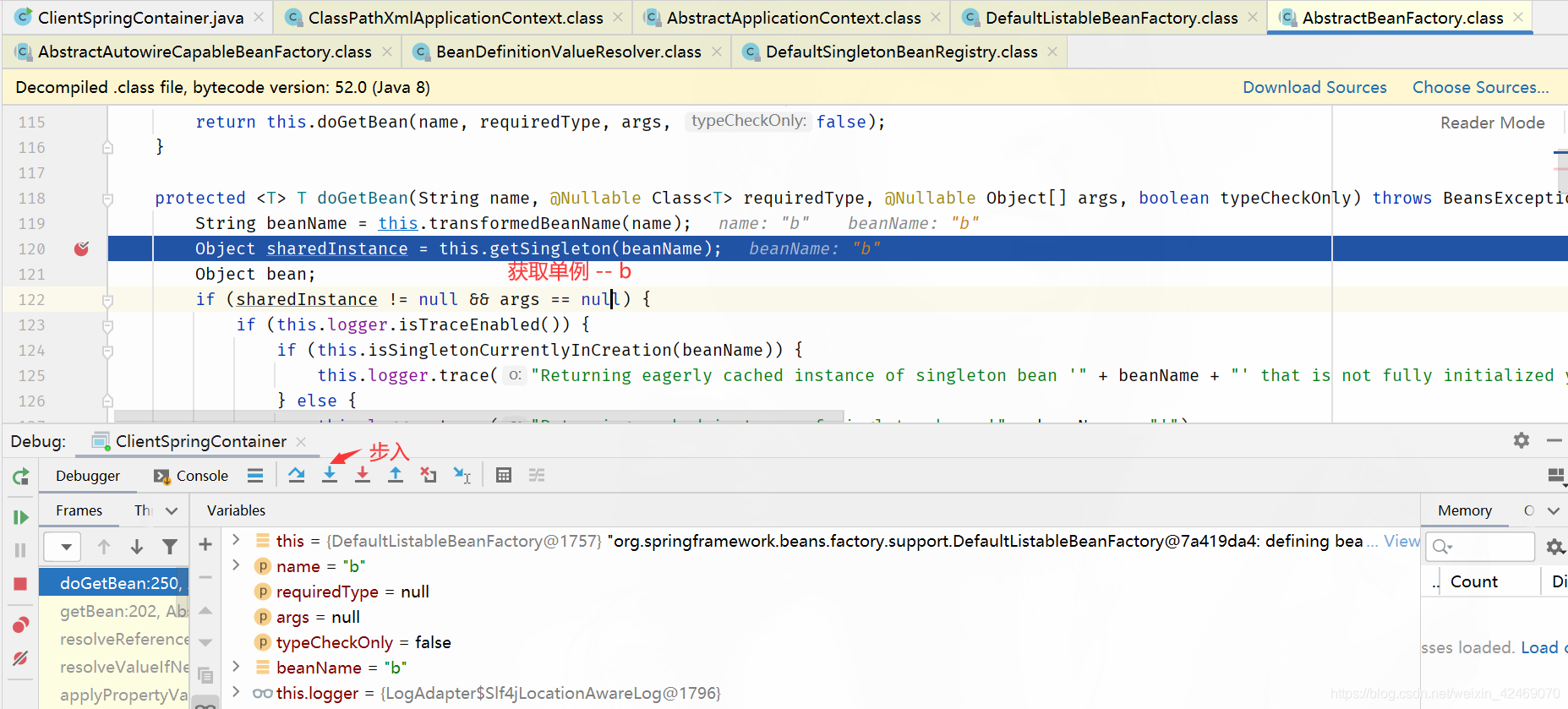
步入:
步过:
步过:
步过:
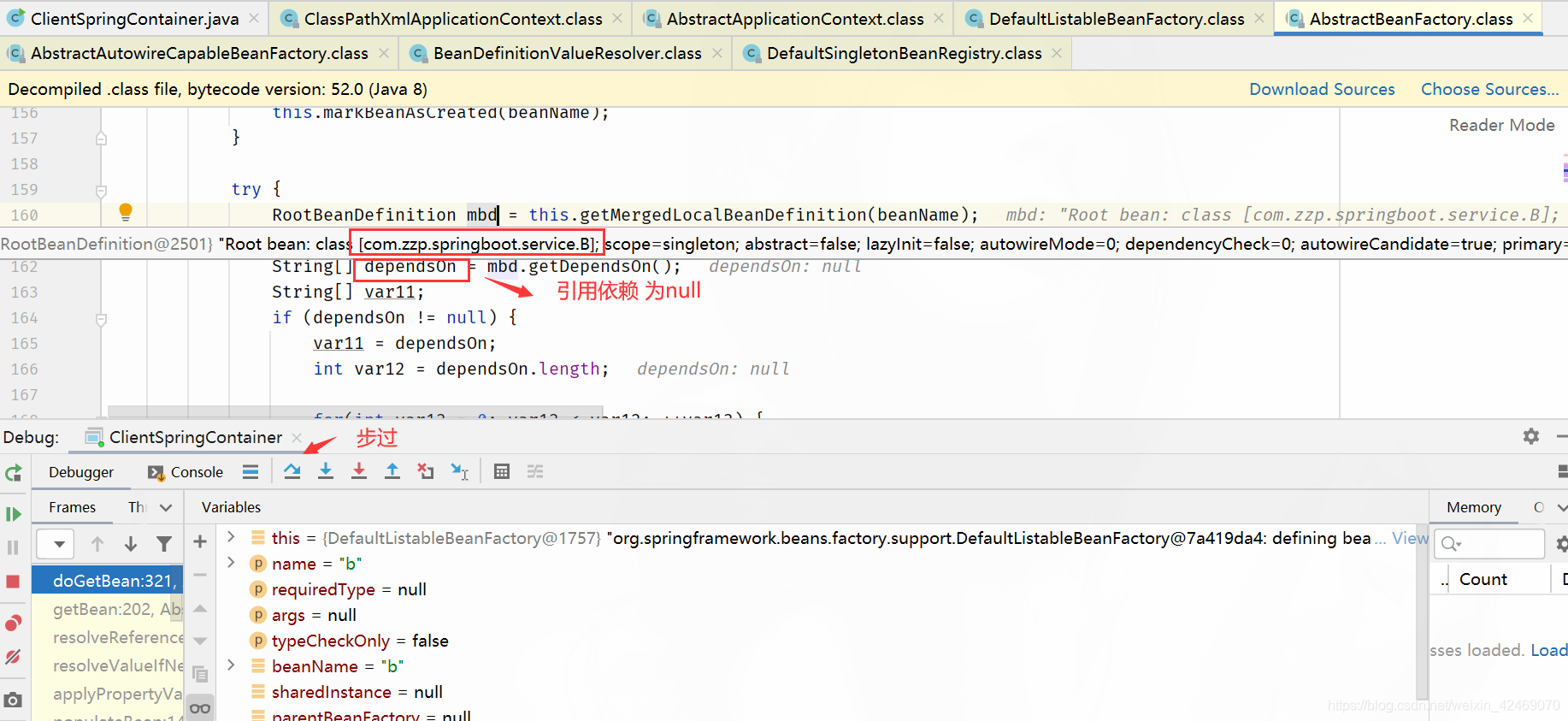
步过:
getSingleton():获取单例

步入:
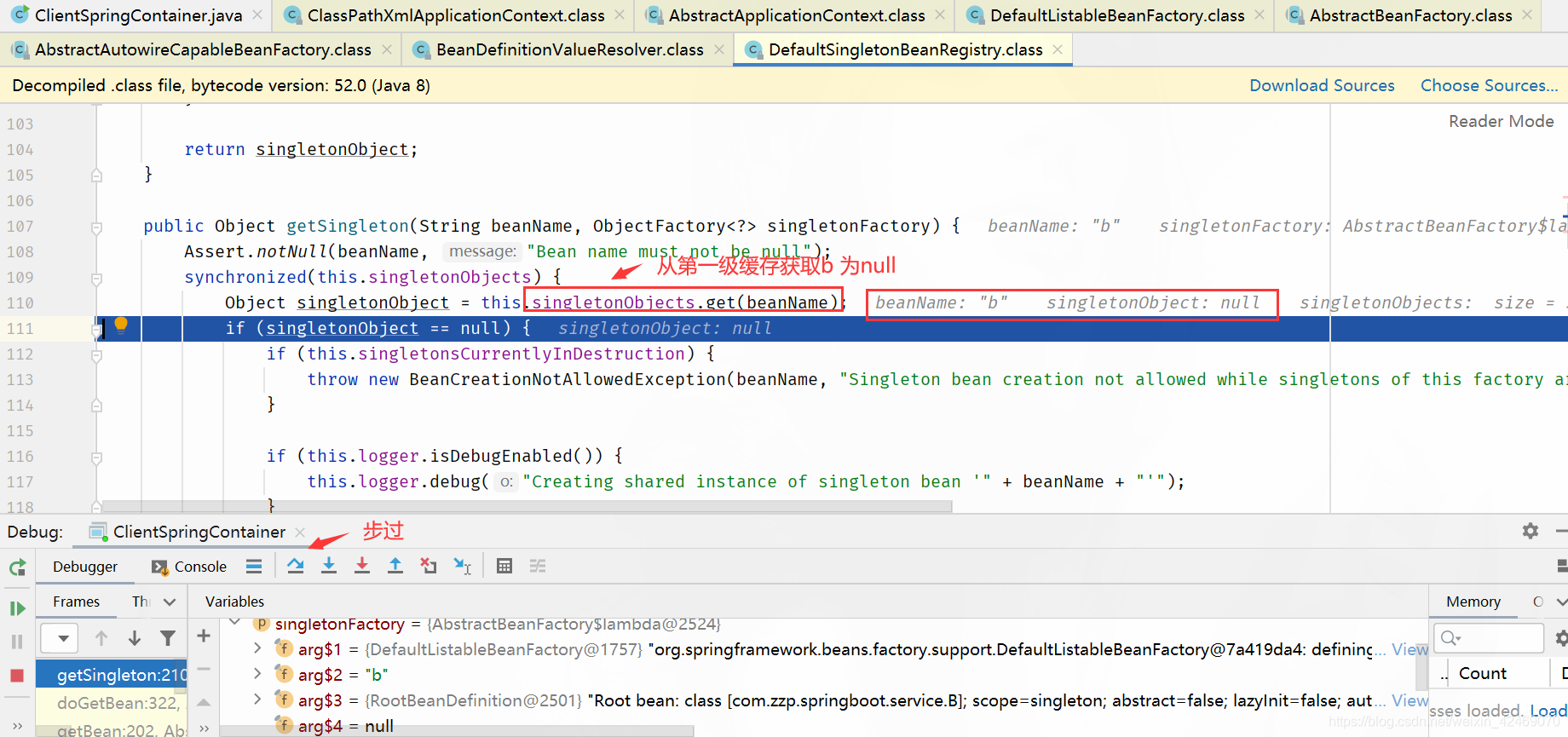
步过:

步入:
createBean():创建bean
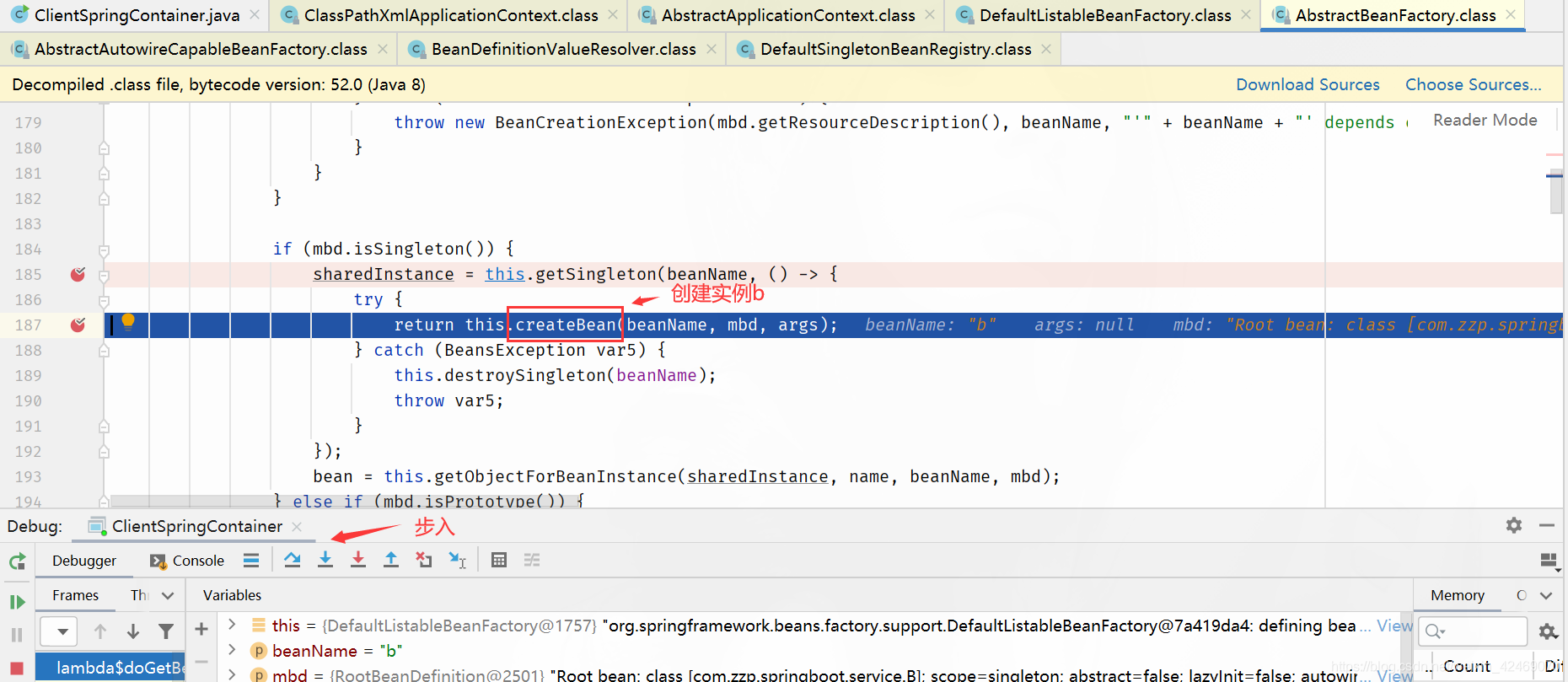
步入:
步过:
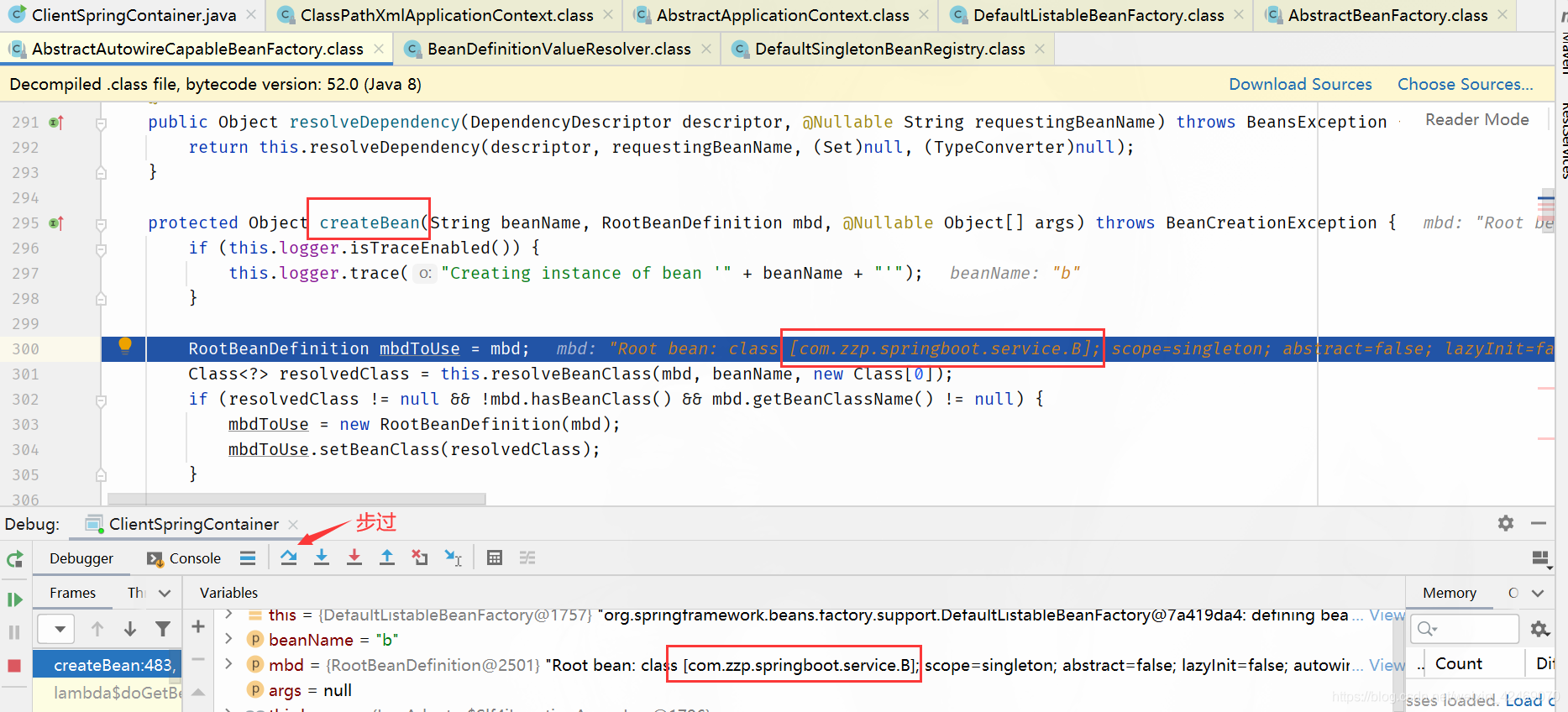
doCreateBean():创建bean(第二个方法)
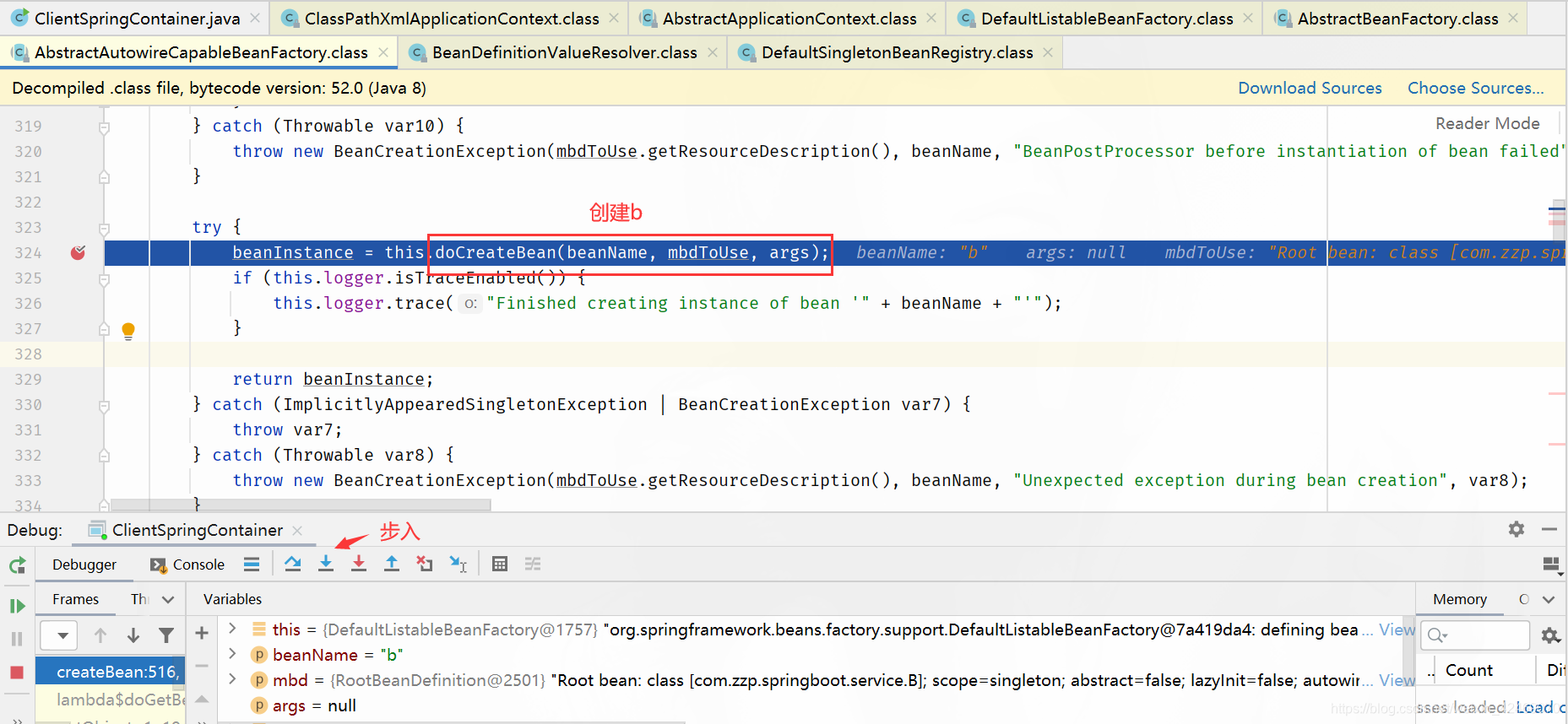
步入:
createBeanInstance():创建bean实例:
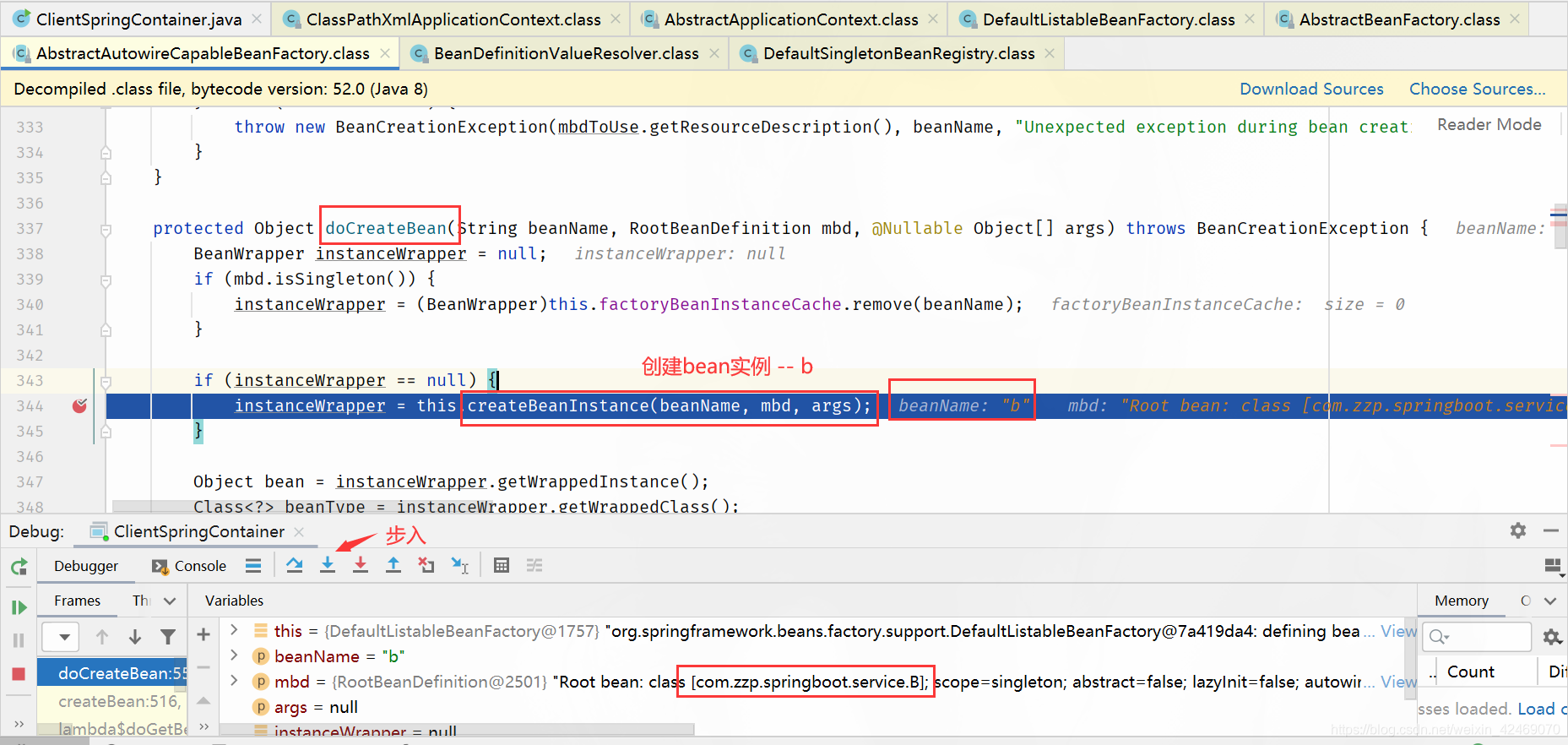
步入:
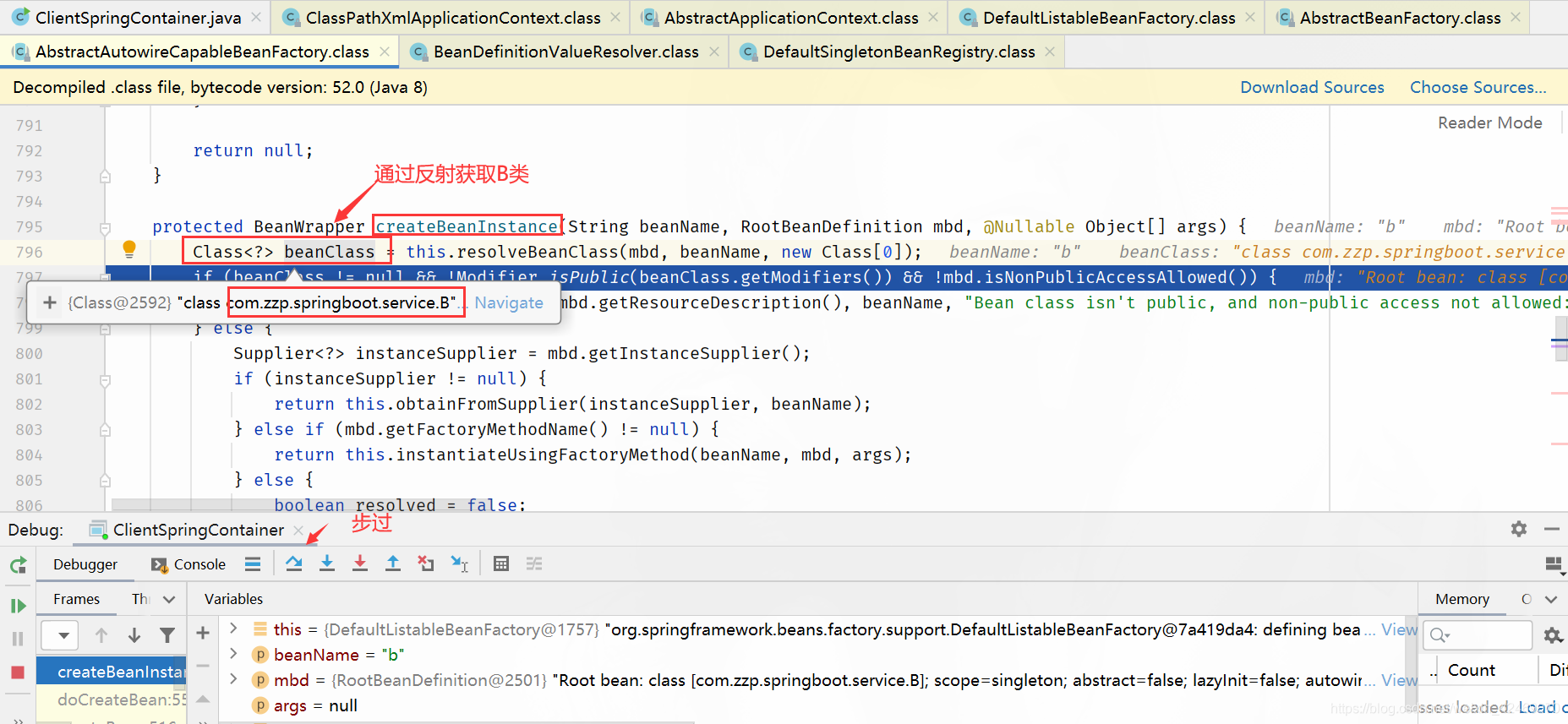
步过:
步过:
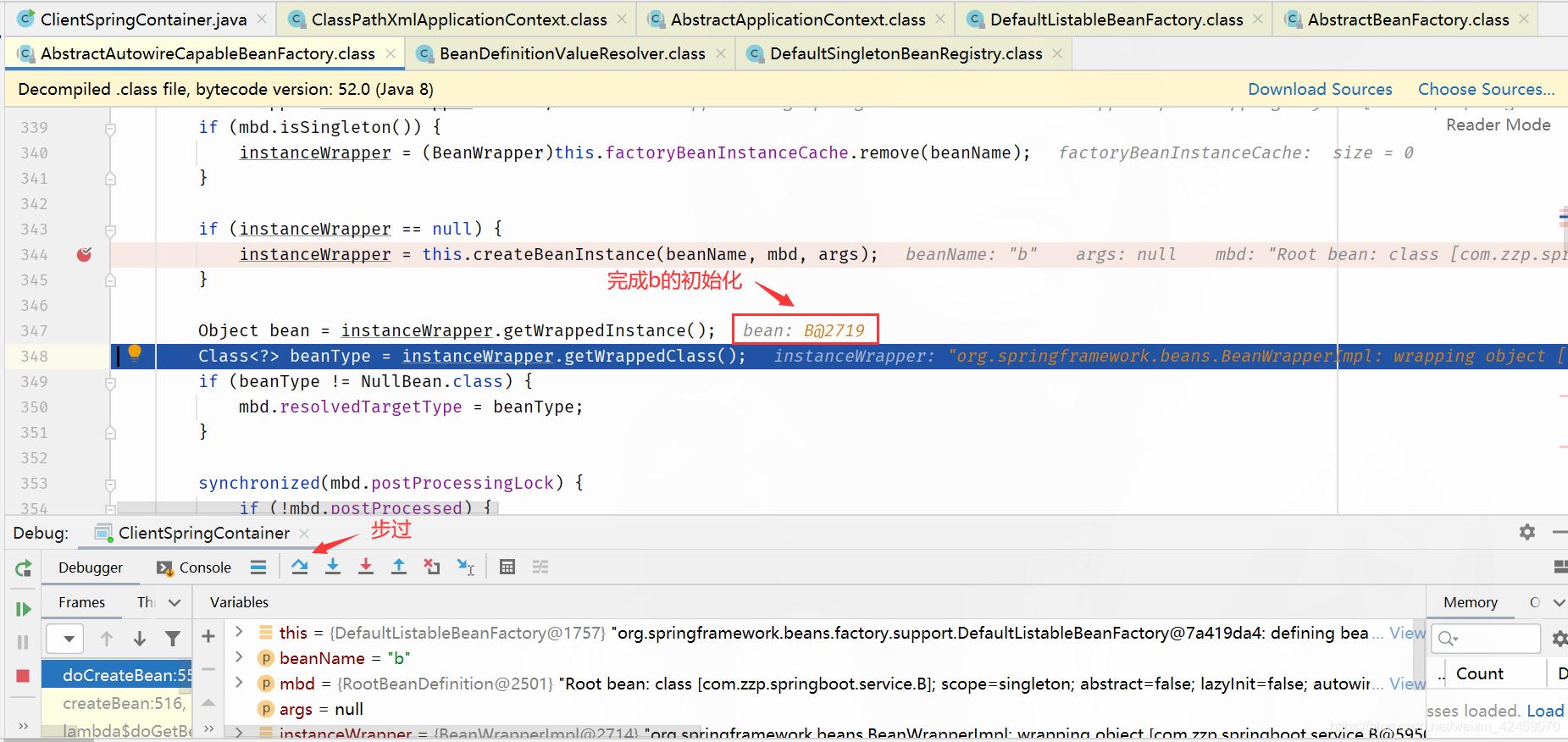
addSingletonFactory():添加单例工厂
步入:
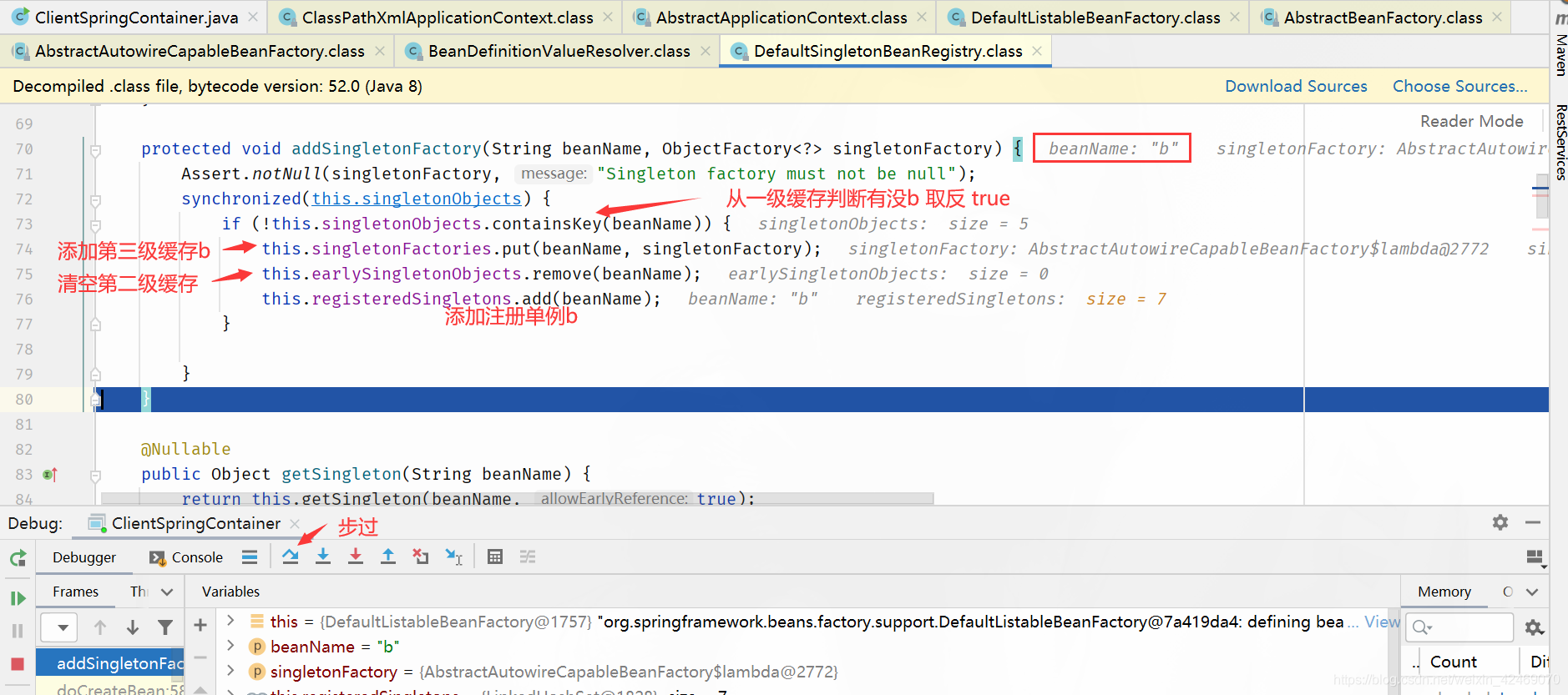
查看缓存:
| 缓存 | A | B |
|---|---|---|
| 第一级缓存(singletonObjects) | nulll | null |
| 第二级缓存(earlySingletonObjects) | null | null |
| 第三级缓存(singletonFactories) | a,lambda表达式 | b,lambda表达式 |
步过:
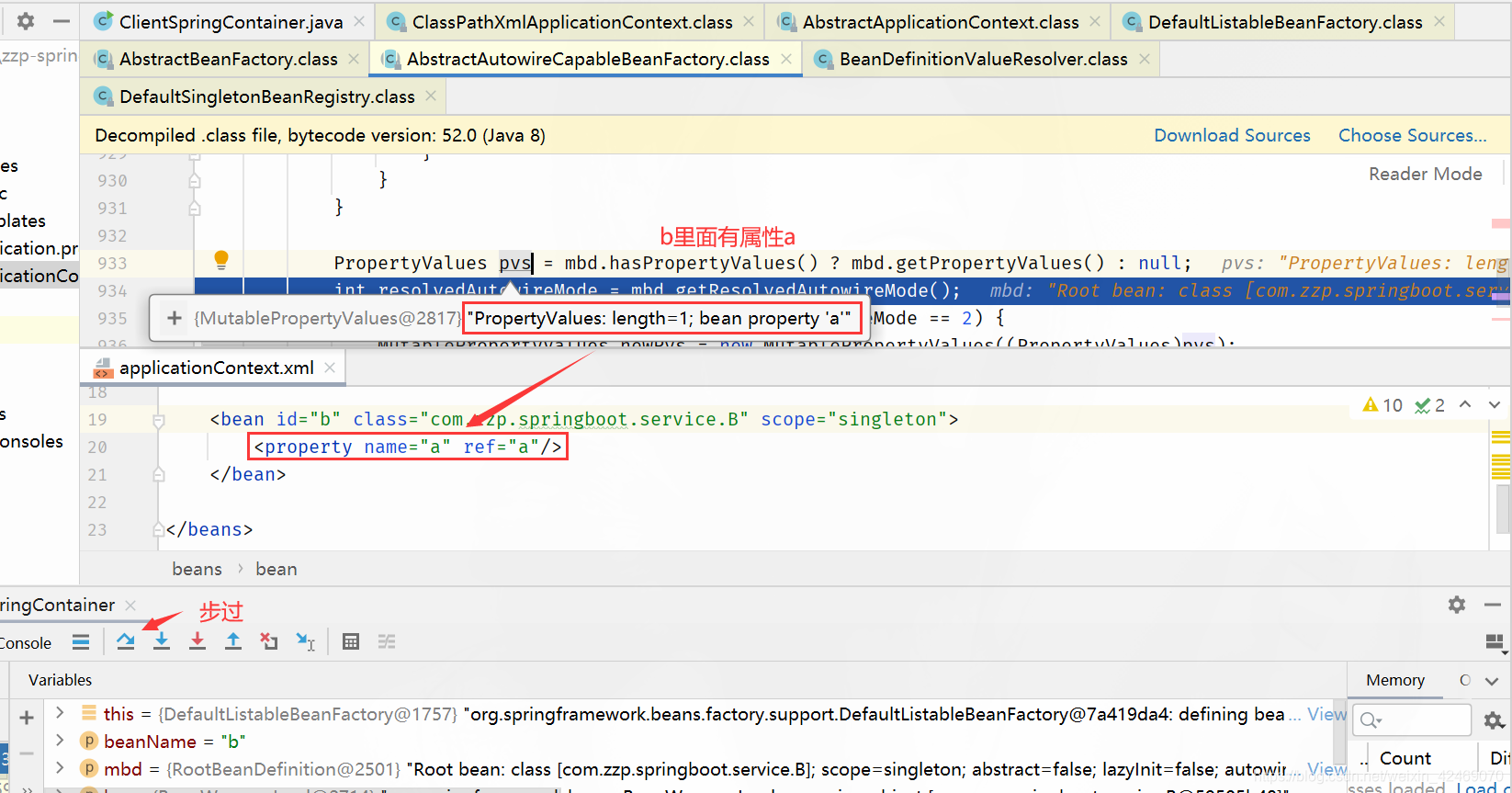
populateBean():属性填充
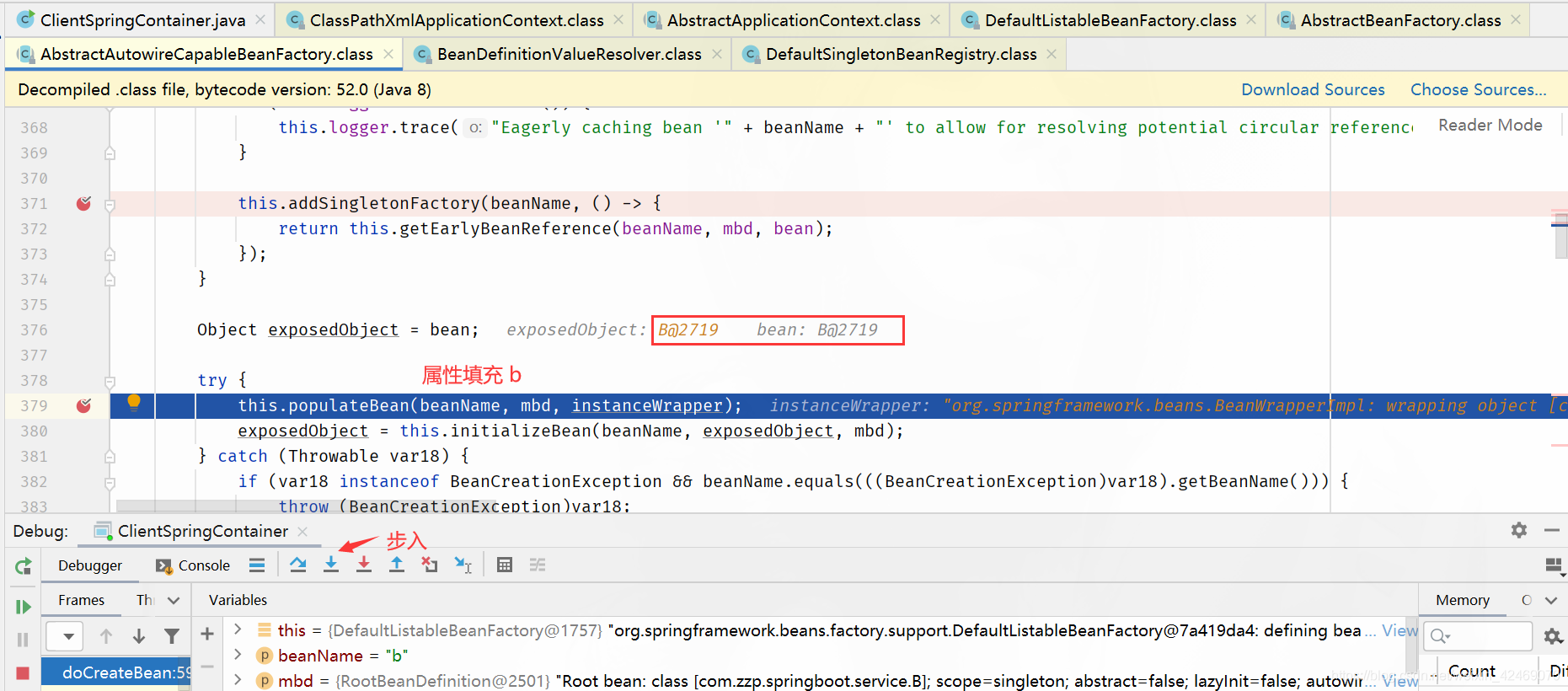
步入:
步过:
步过:
applyPropertyValues():属性注入
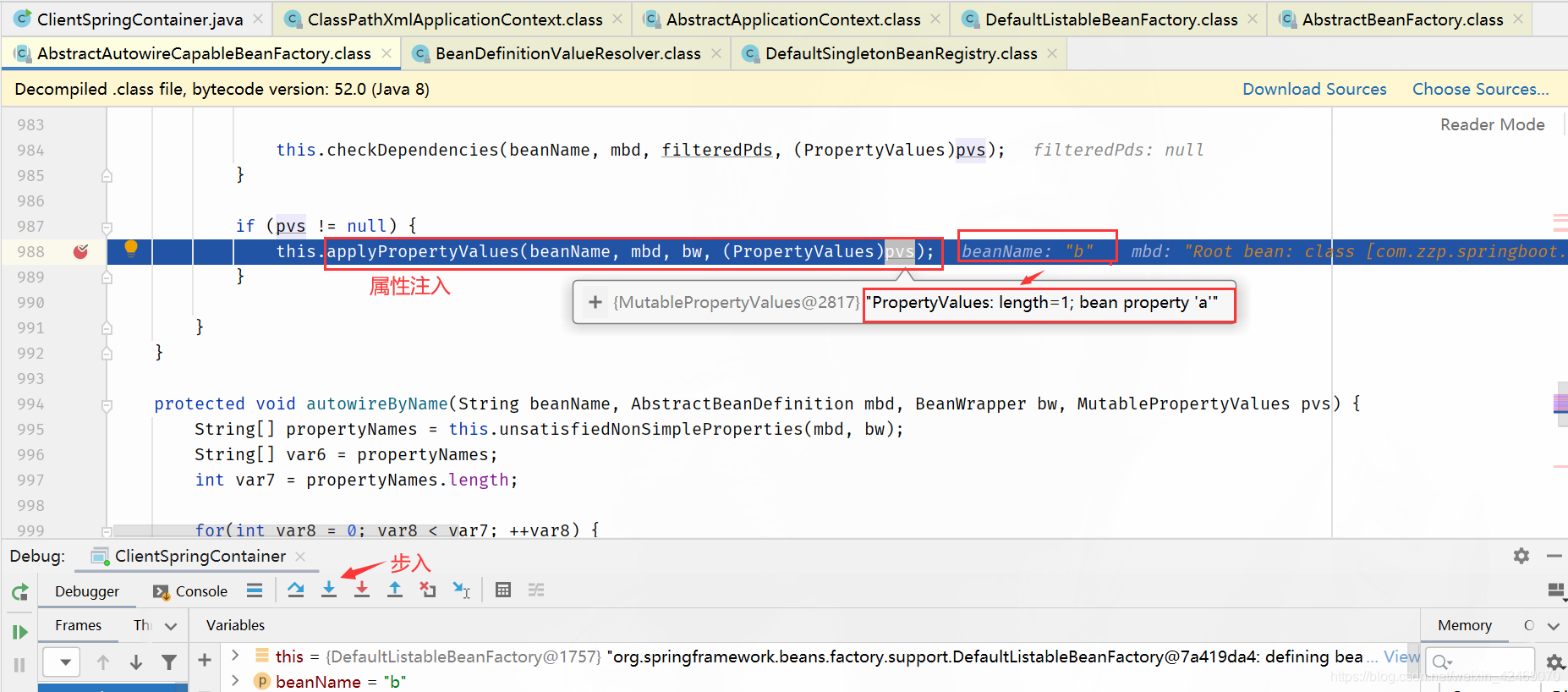
步入:
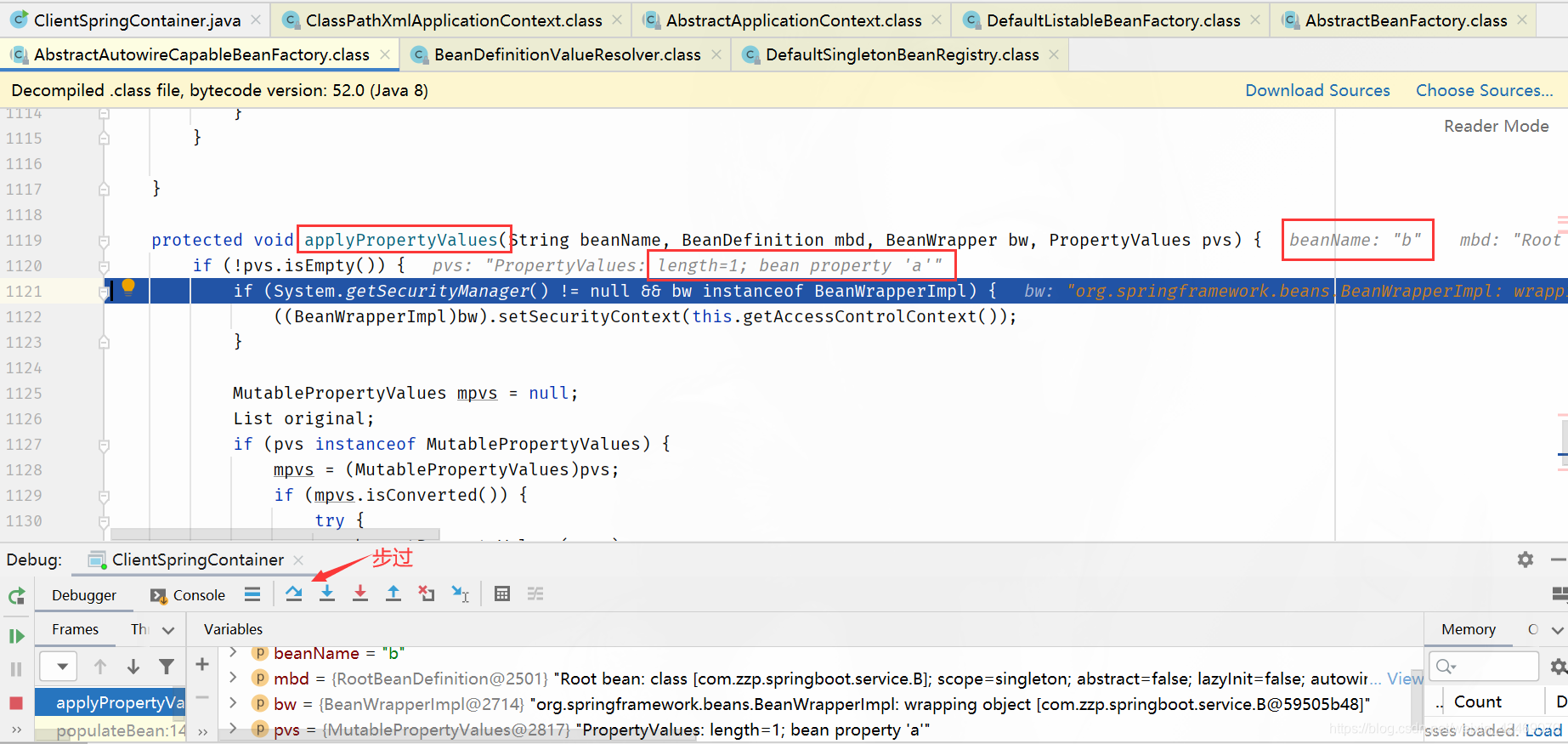
步过:
步过:
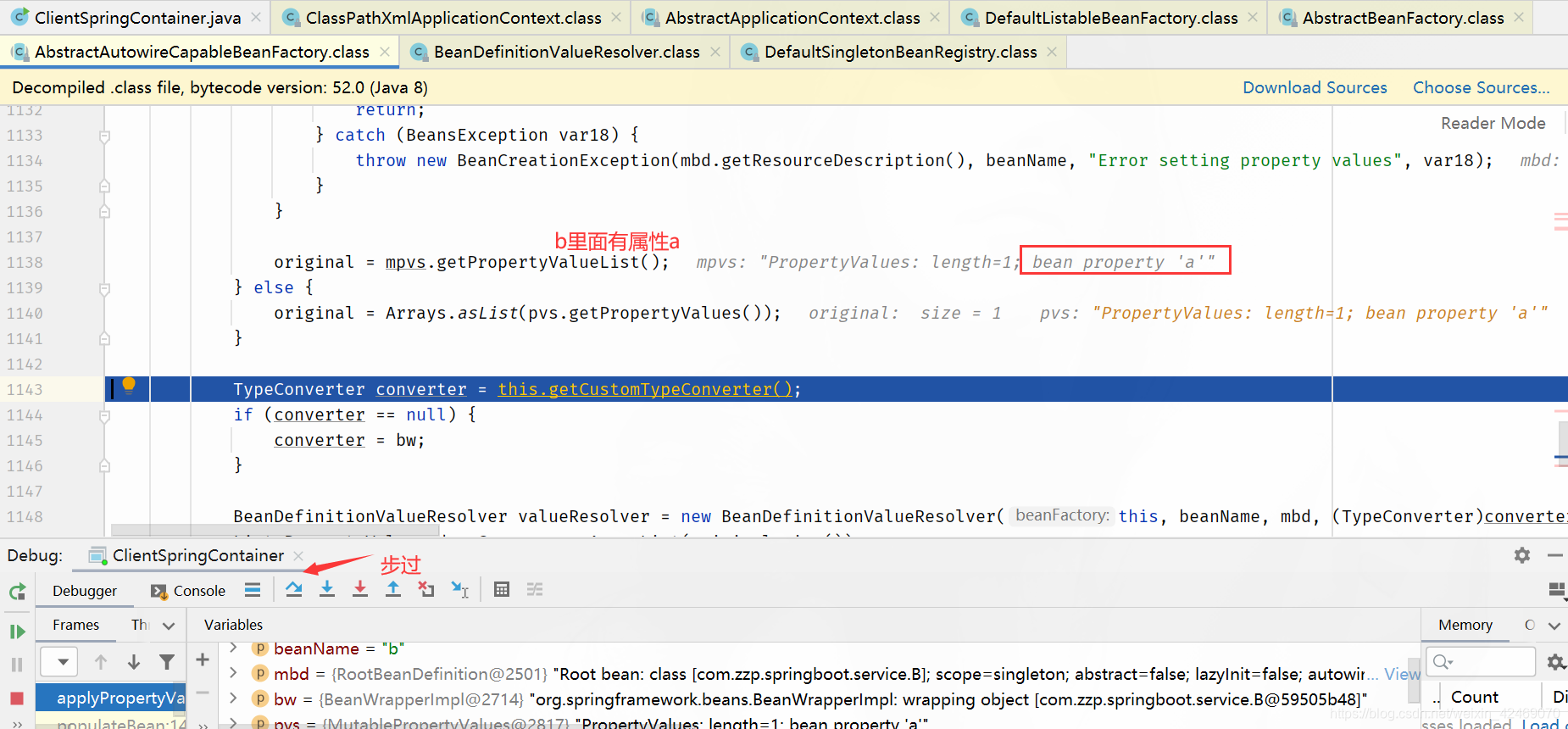
resolveValueIfNecessary:必要时解析值(解析属性值)
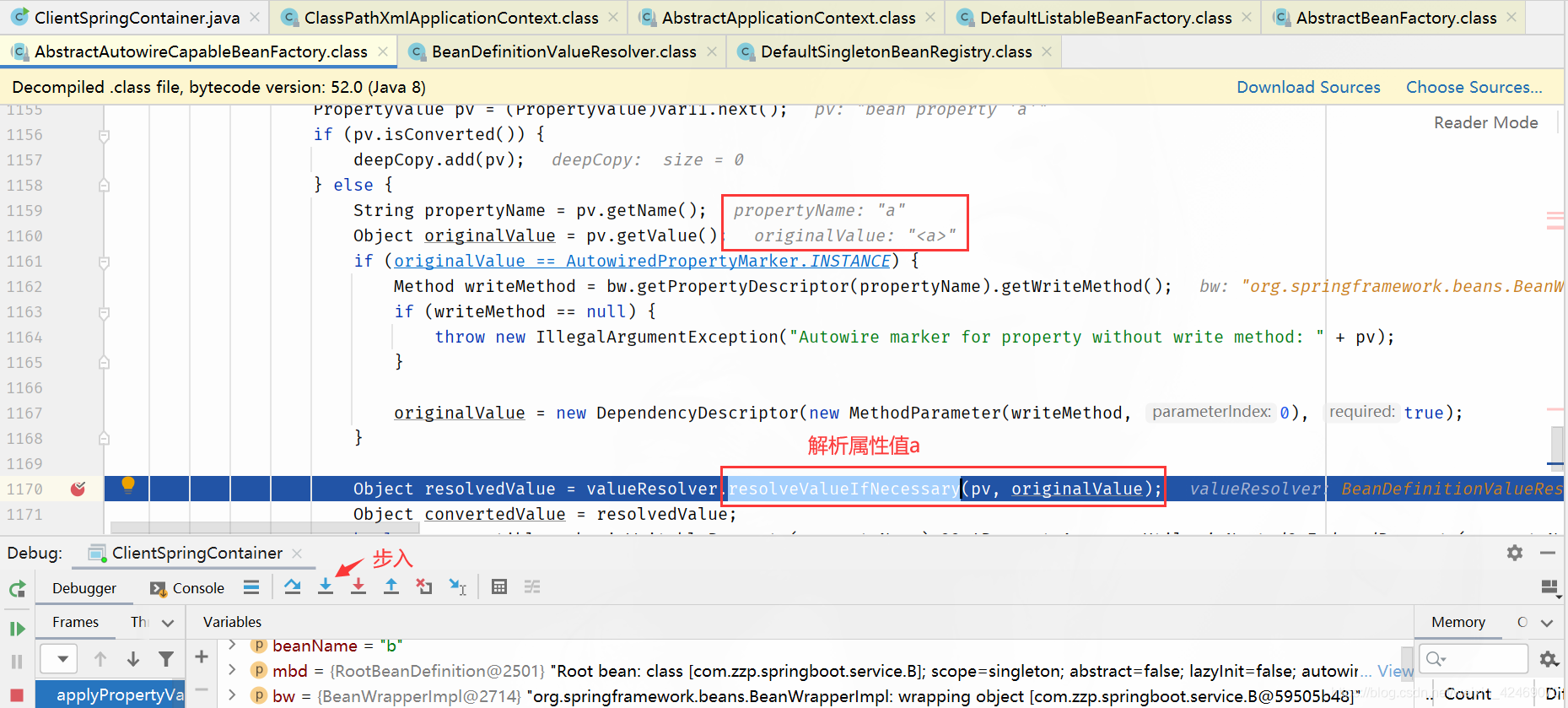
步入:
resolveReference():解决引用属性
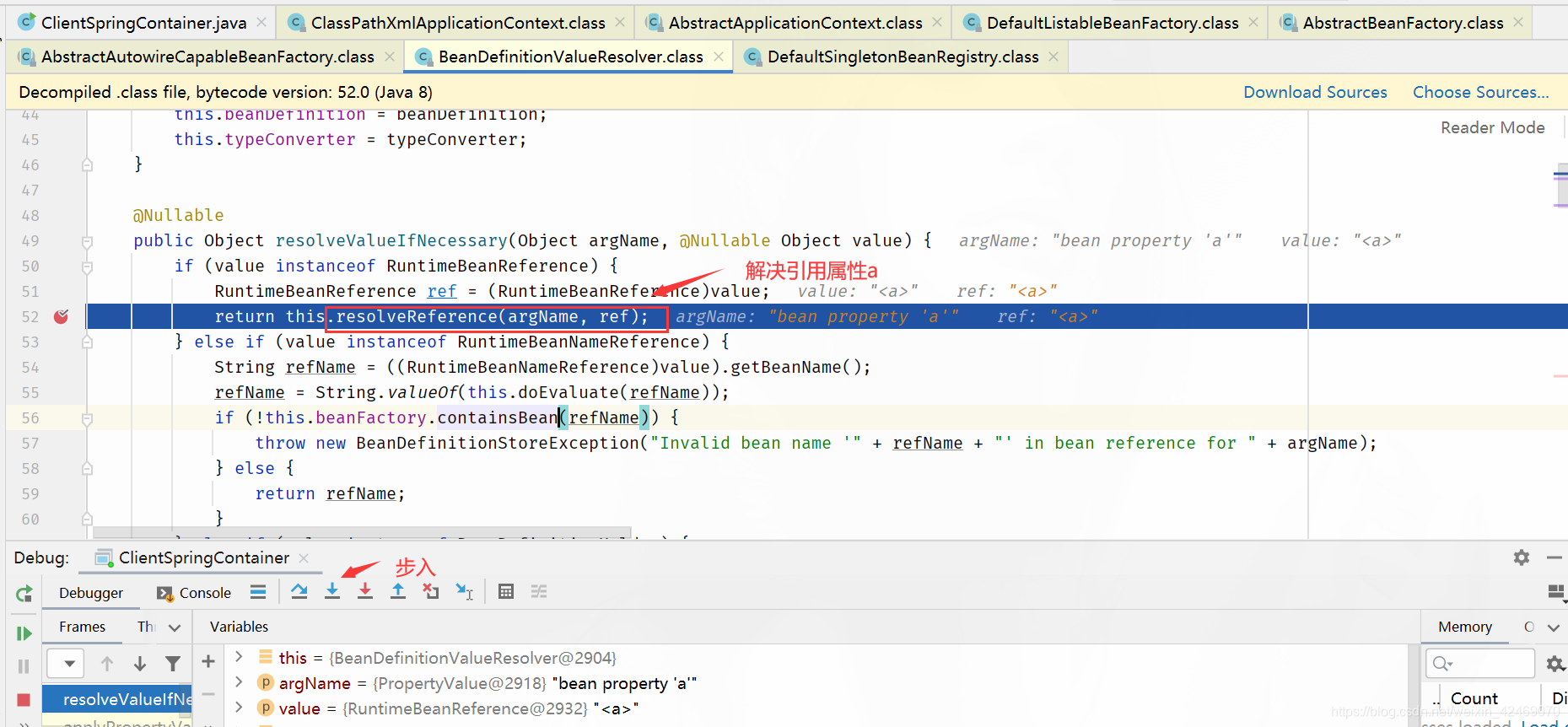
步入:
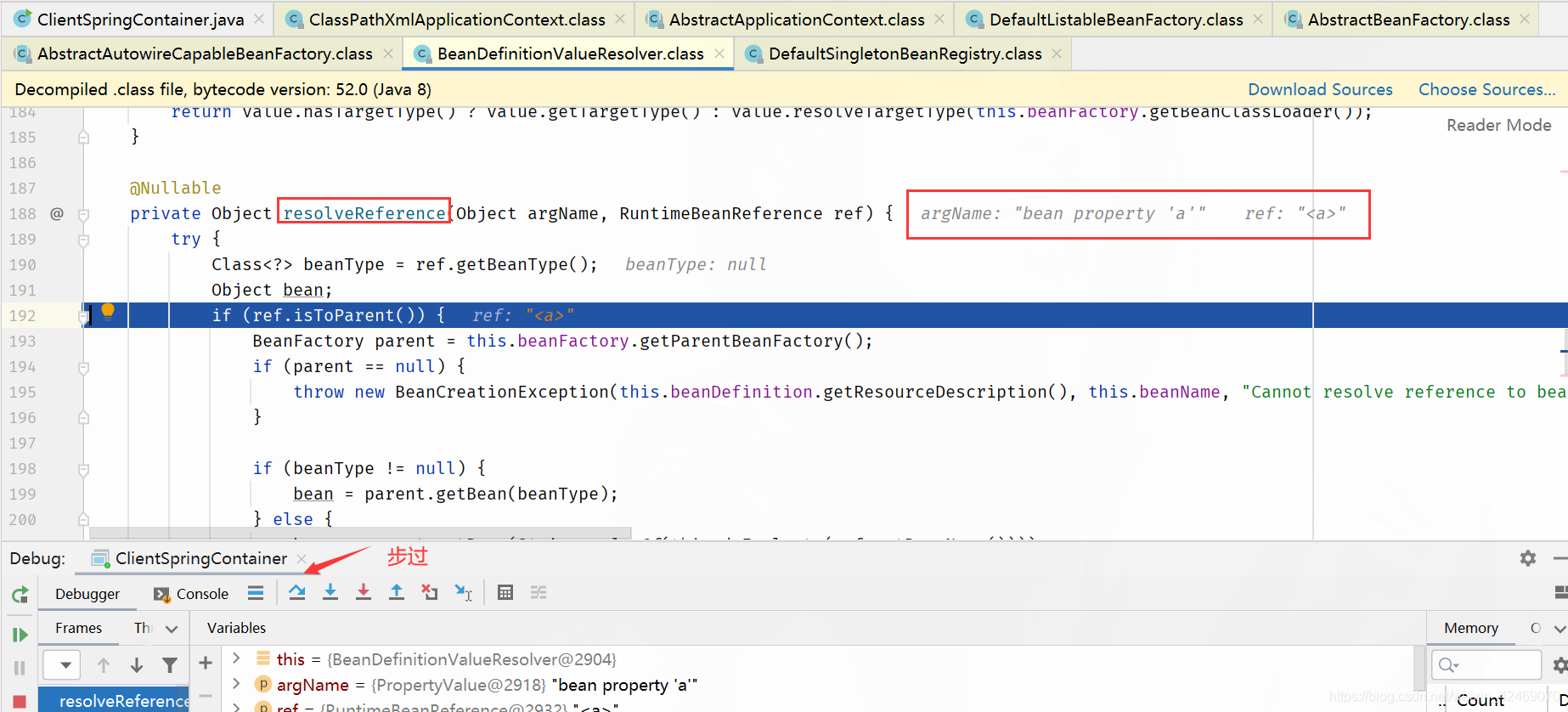
步过:
getBean():获取bean

步入:
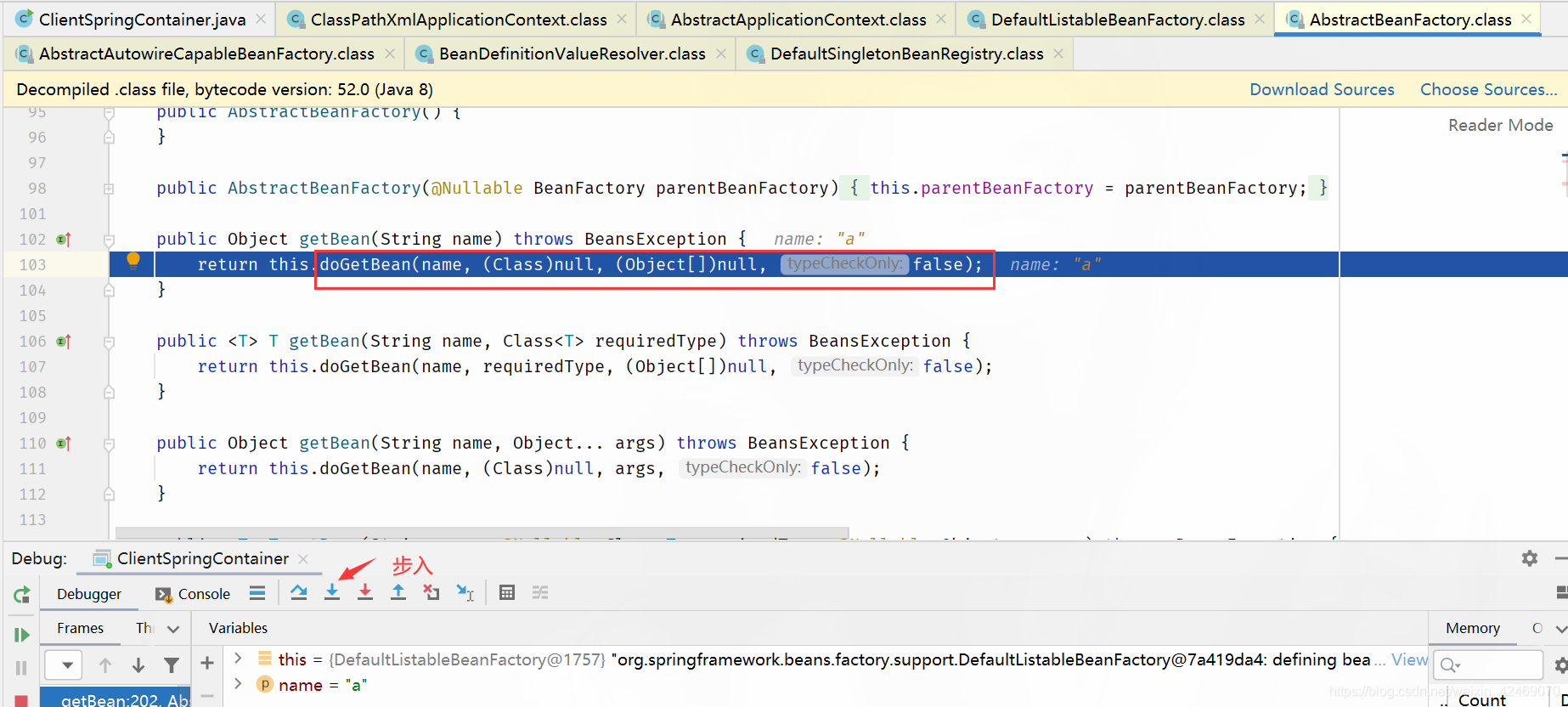
步入:
getSingleton():获取单例
步入:
步过:
步过:
步入:
步入:
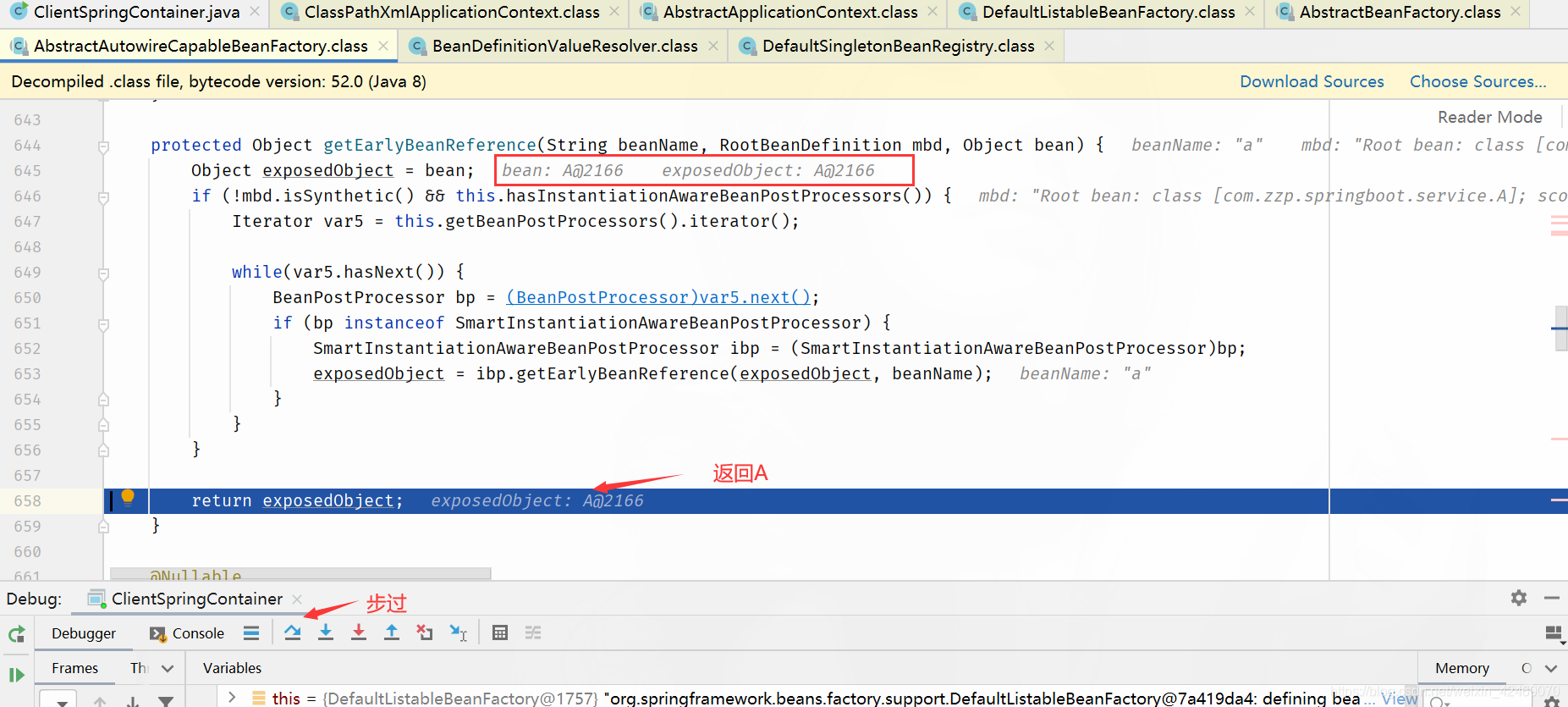
步过:
步入:
步过:

查看缓存:
| 缓存 | A | B |
|---|---|---|
| 第一级缓存(singletonObjects) | nulll | null |
| 第二级缓存(earlySingletonObjects) | a,A@2166 | null |
| 第三级缓存(singletonFactories) | null | b,lambda表达式 |
步过:
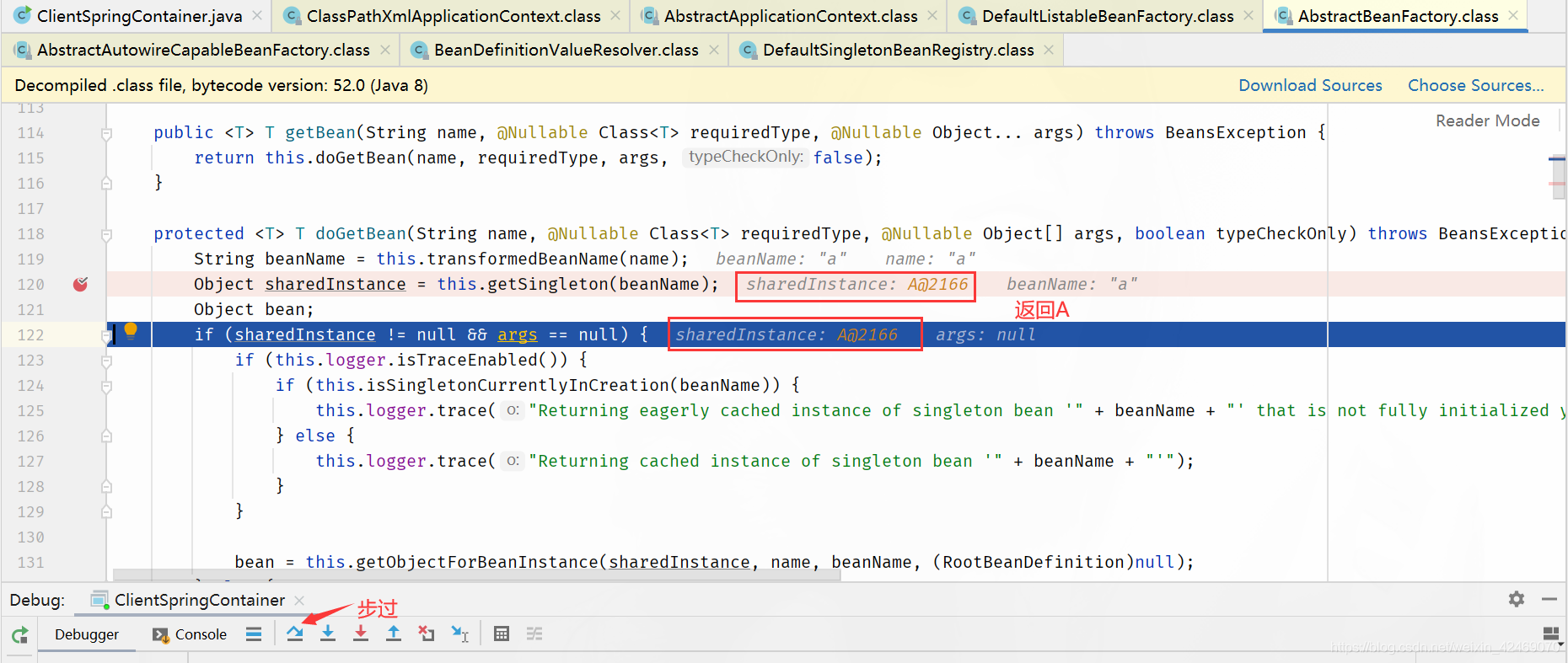
步过:
步过:
步过:
步过:
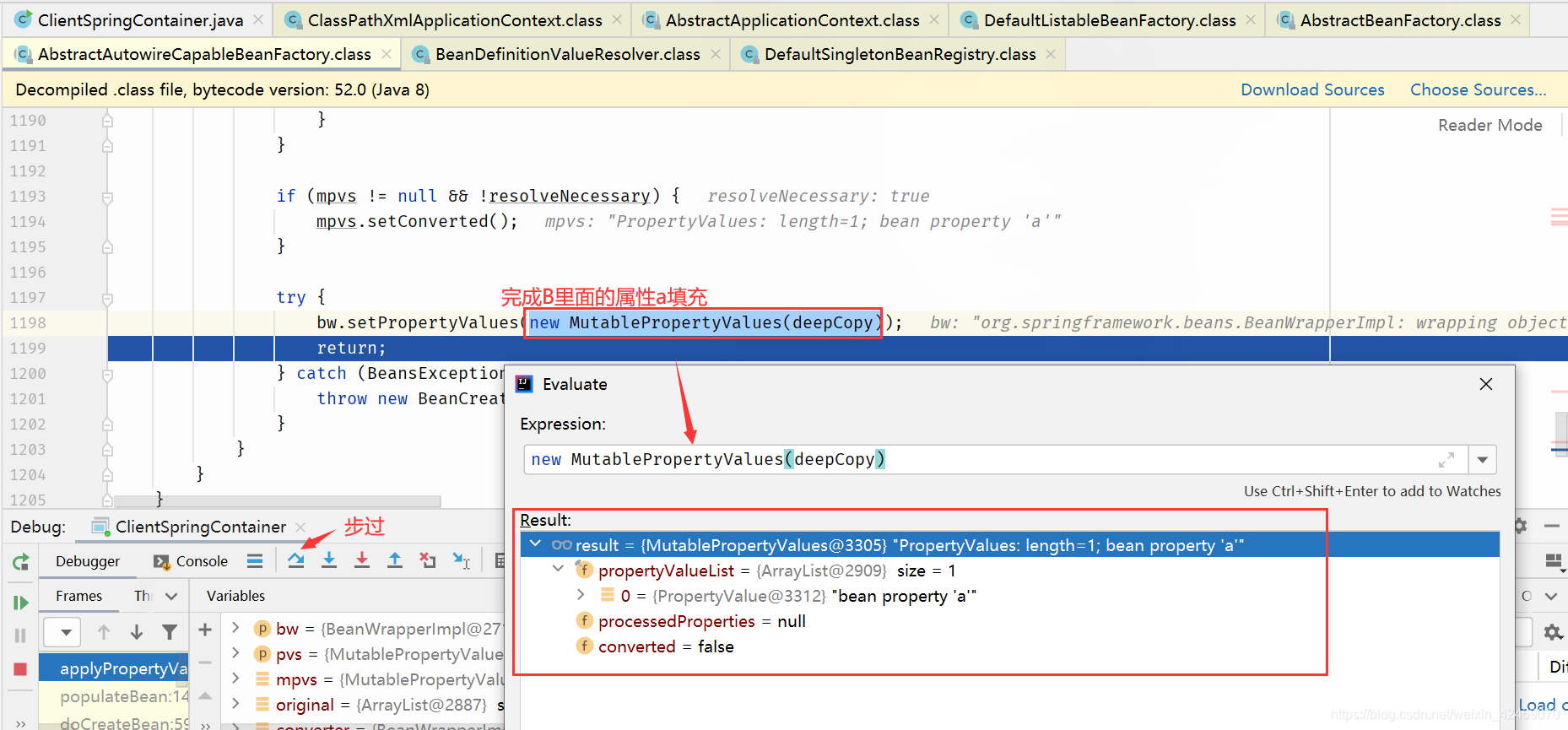
步过:
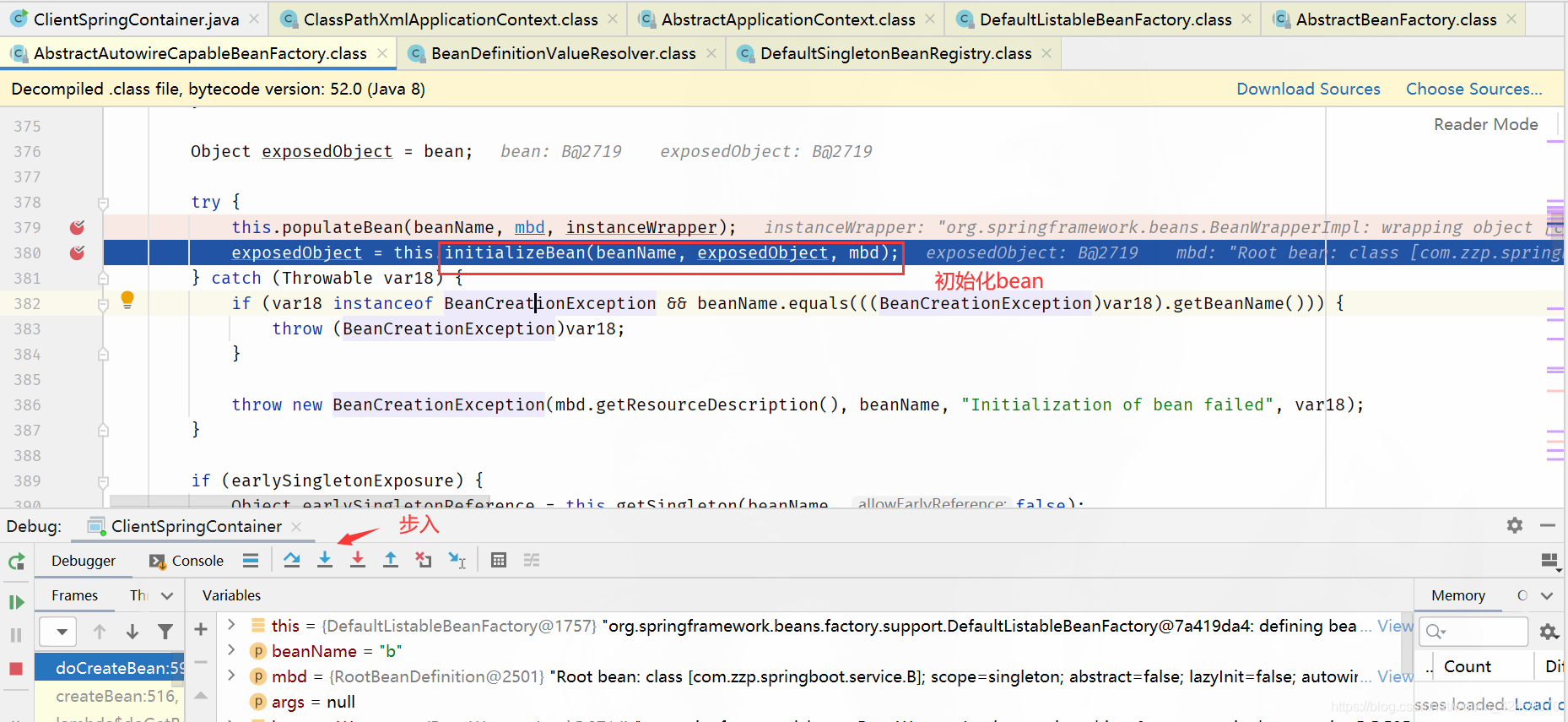
步入:
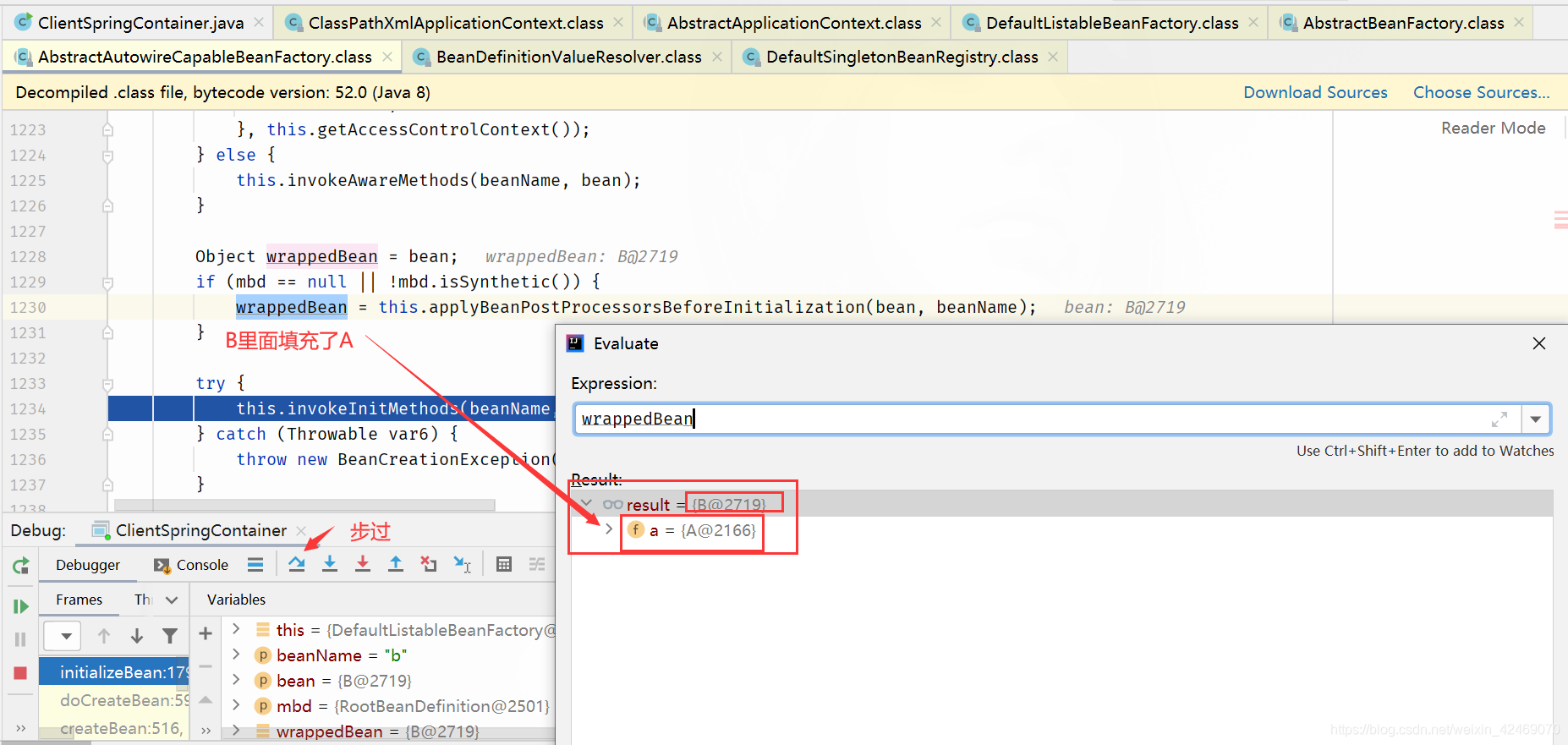
步过:
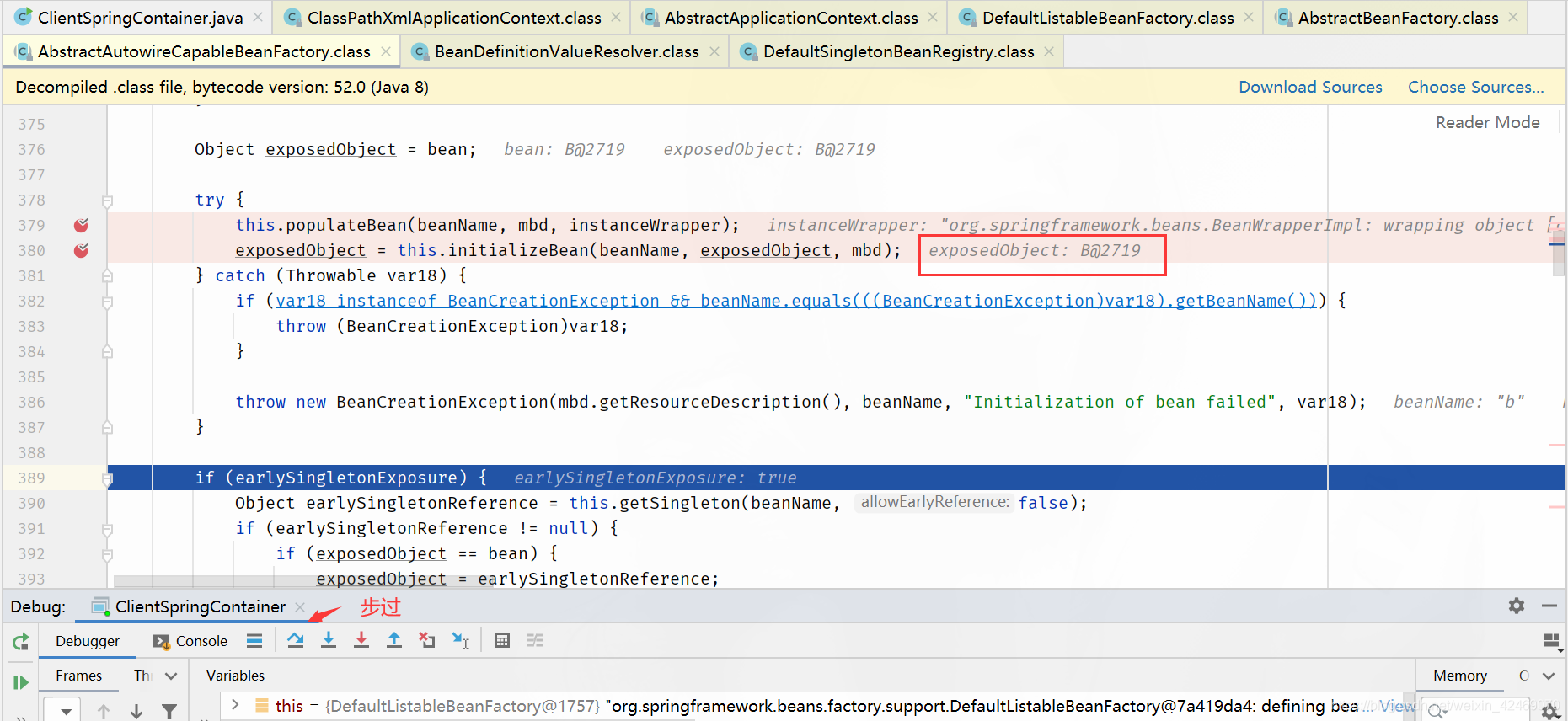
步过:
getSingleton():获取单例
步入:
步过:
步过:
步过:
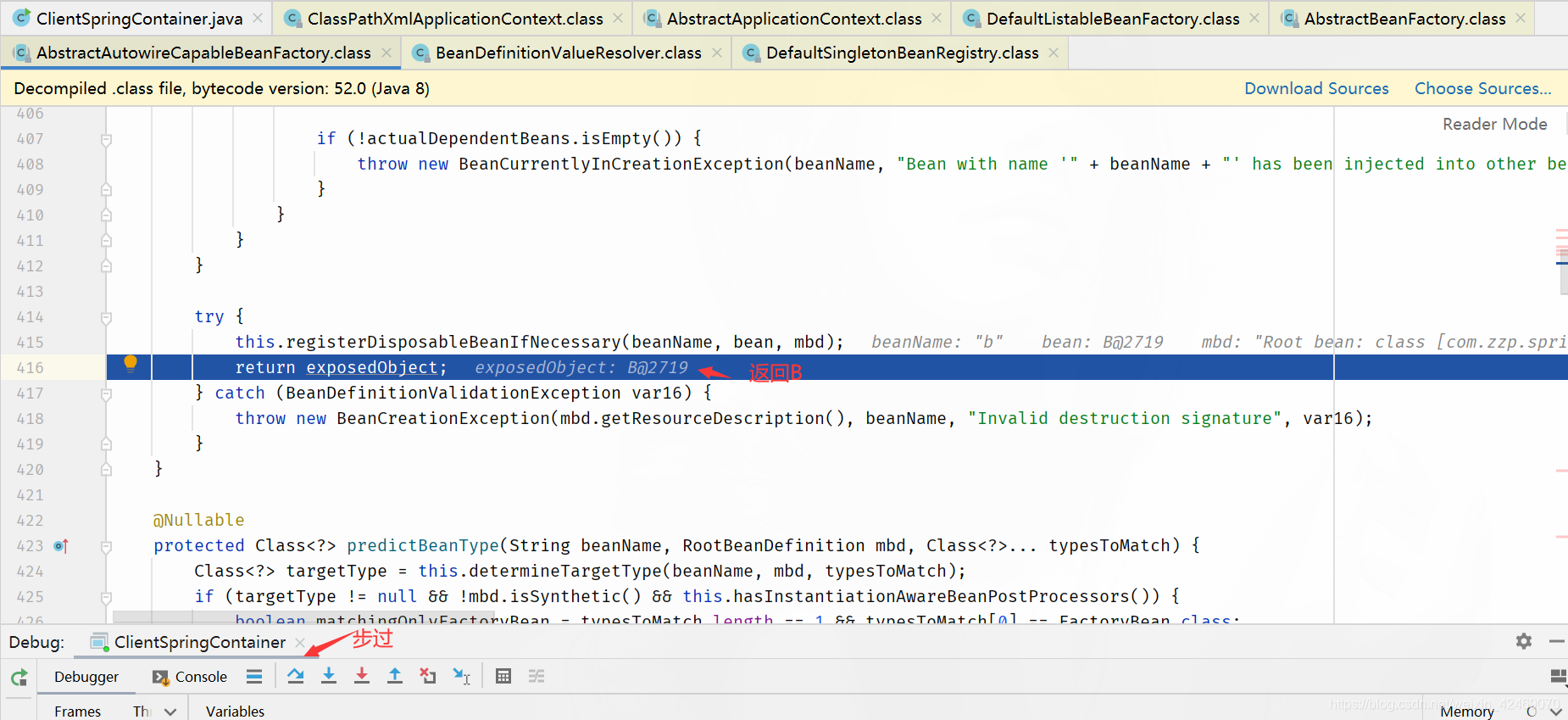
步过:
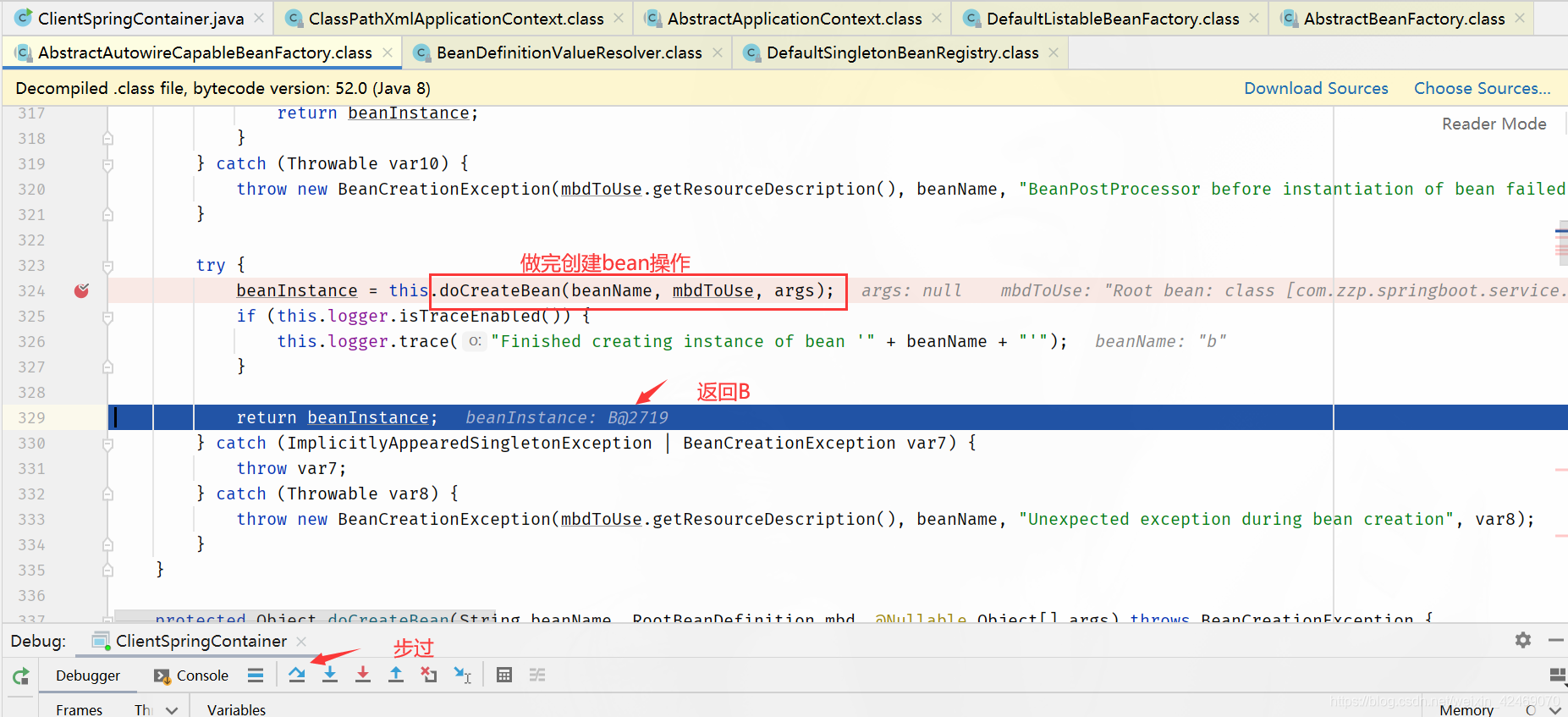
步过:
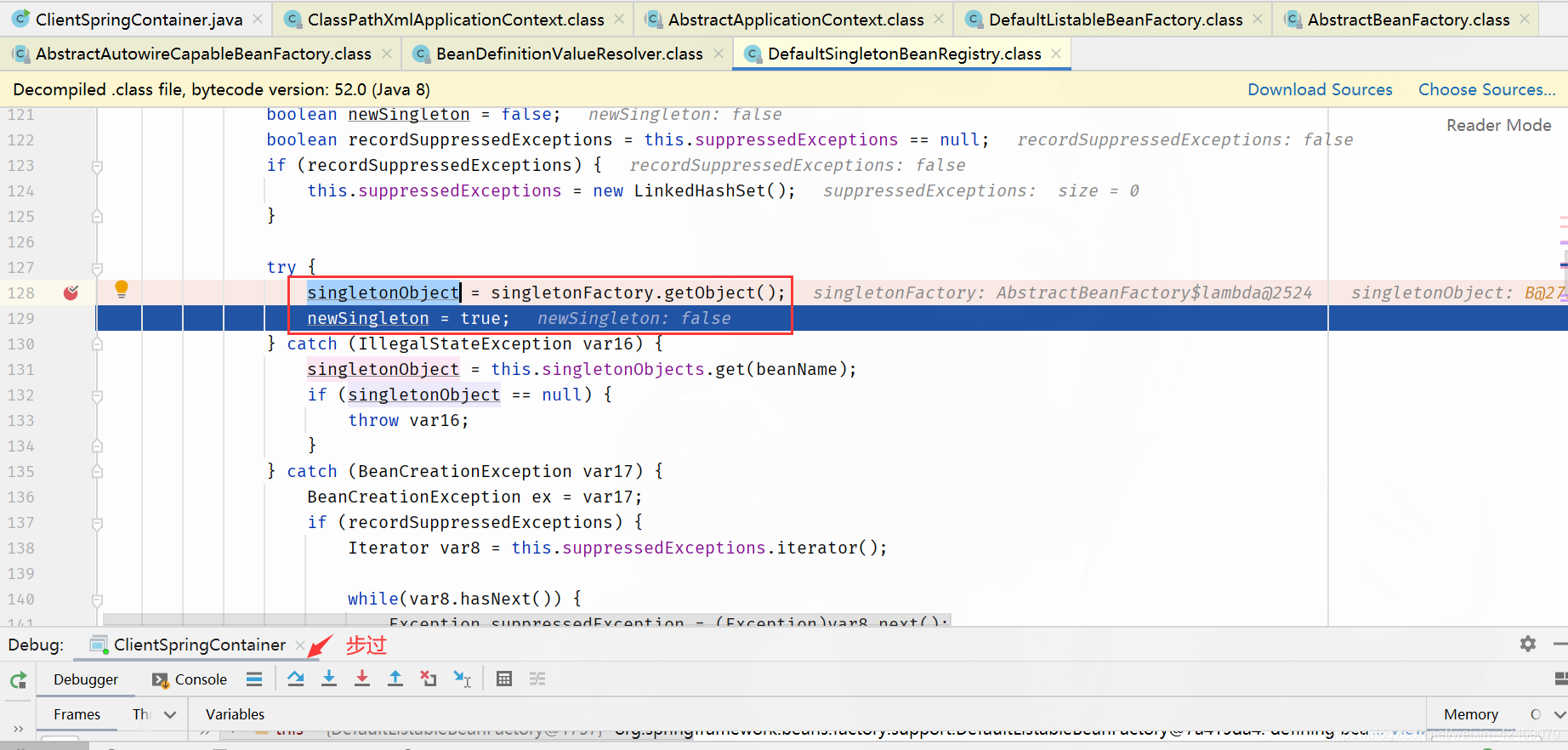
步过:
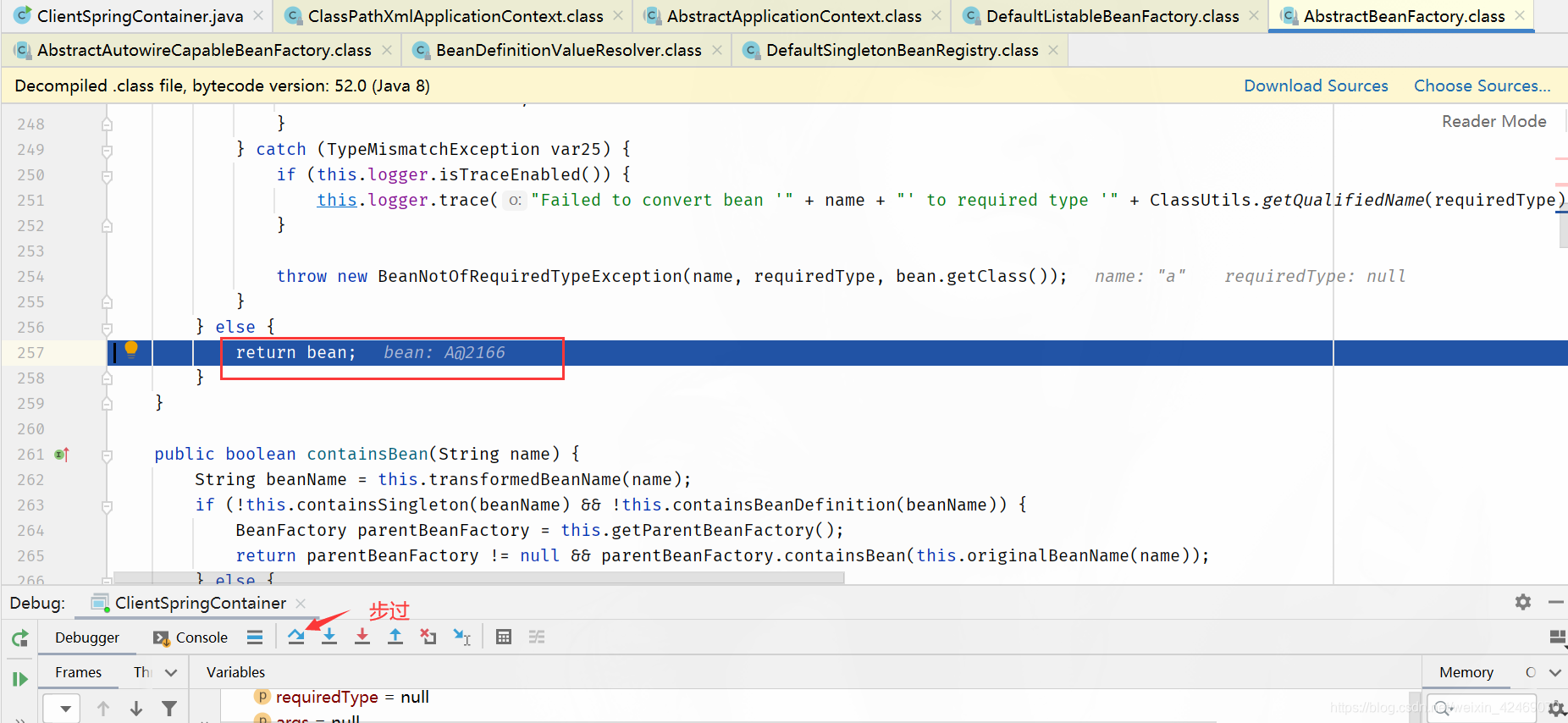
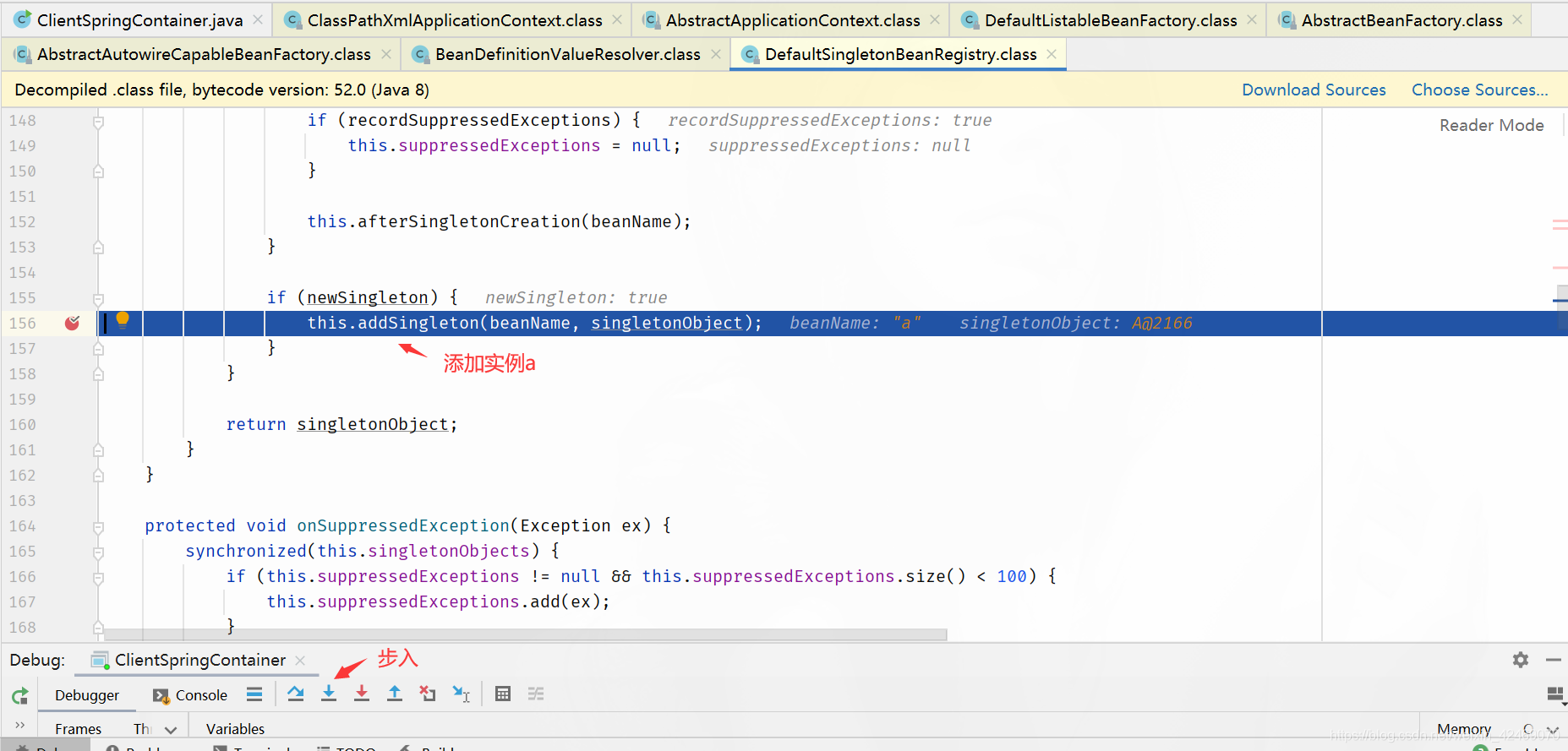
addSingleton()断点:添加单例(第四个方法)
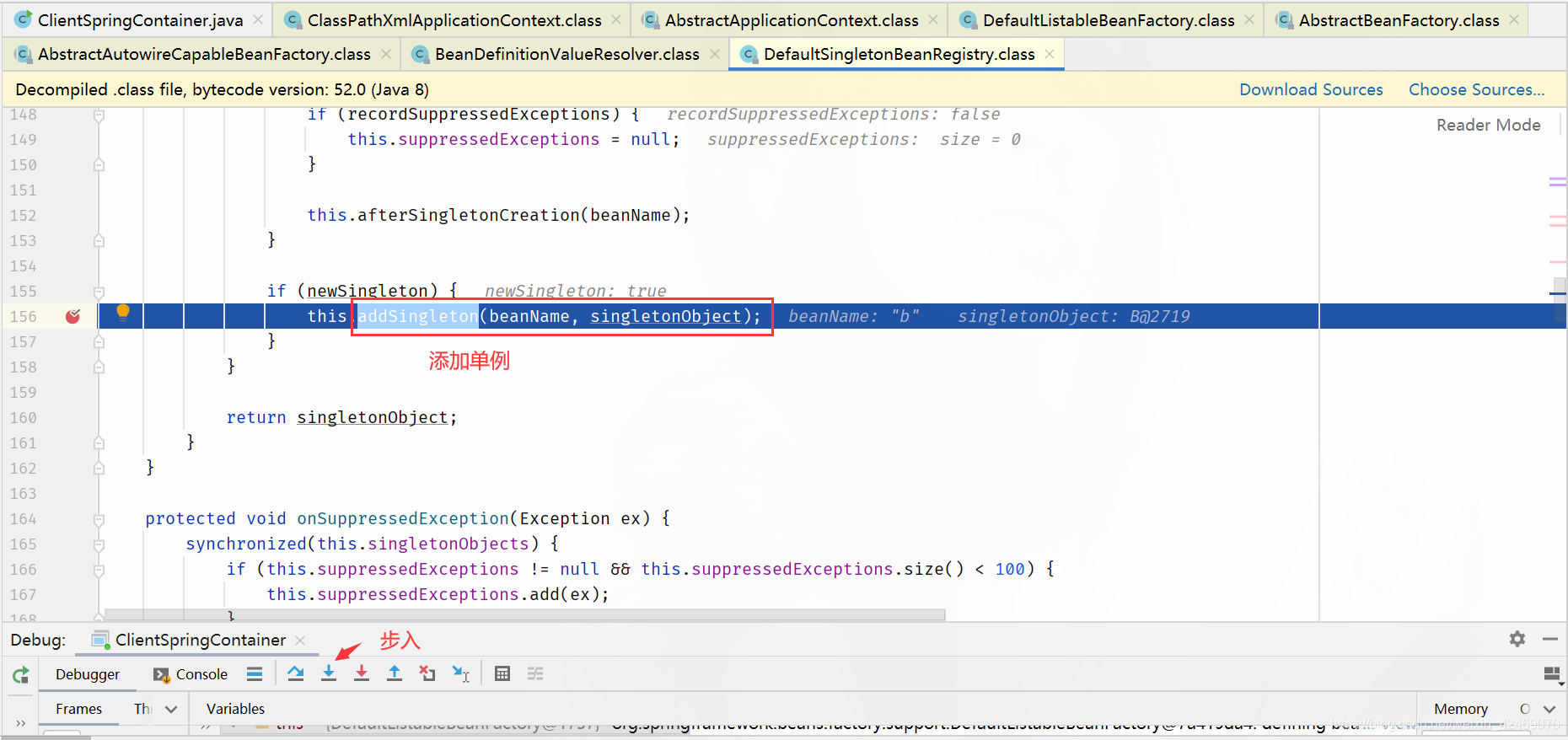
步入:
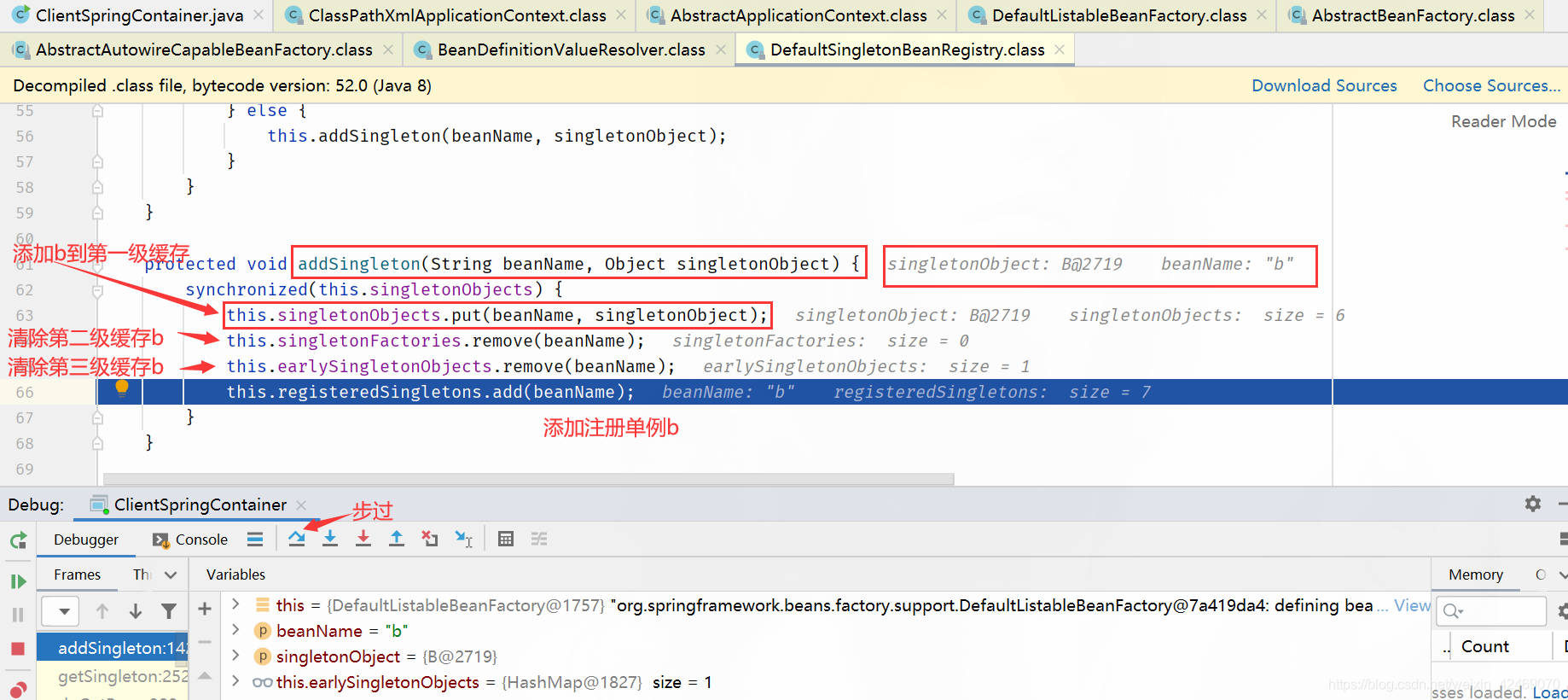
查看缓存:
| 缓存 | A | B |
|---|---|---|
| 第一级缓存(singletonObjects) | nulll | b,B@2179 |
| 第二级缓存(earlySingletonObjects) | a,A@2166 | null |
| 第三级缓存(singletonFactories) | null | null |
步过:
步过:
步过:
步入:
步过:
步过:
步过:
步过:
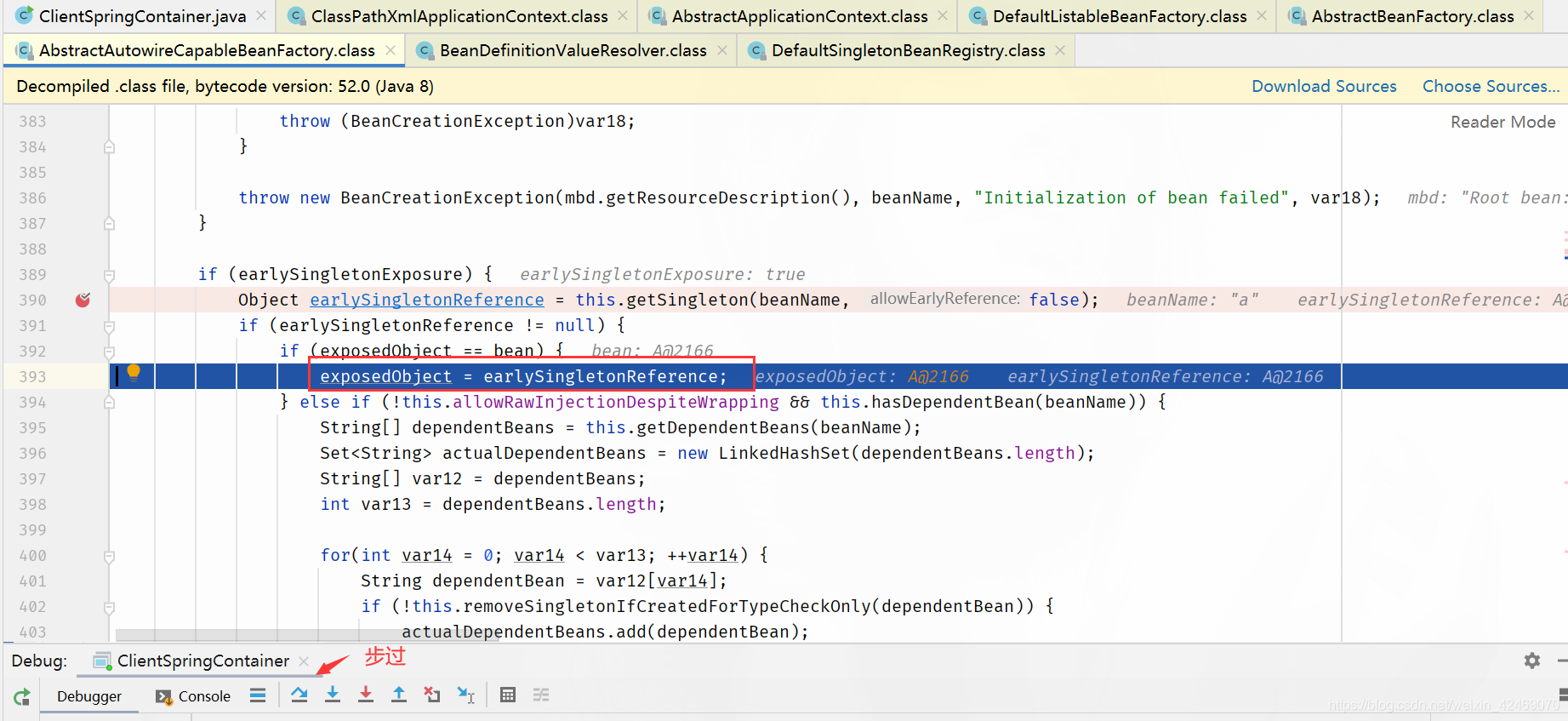
步过:
步过:
步过:

步过:
addSingleton():添加实例(第四个方法)
步入:
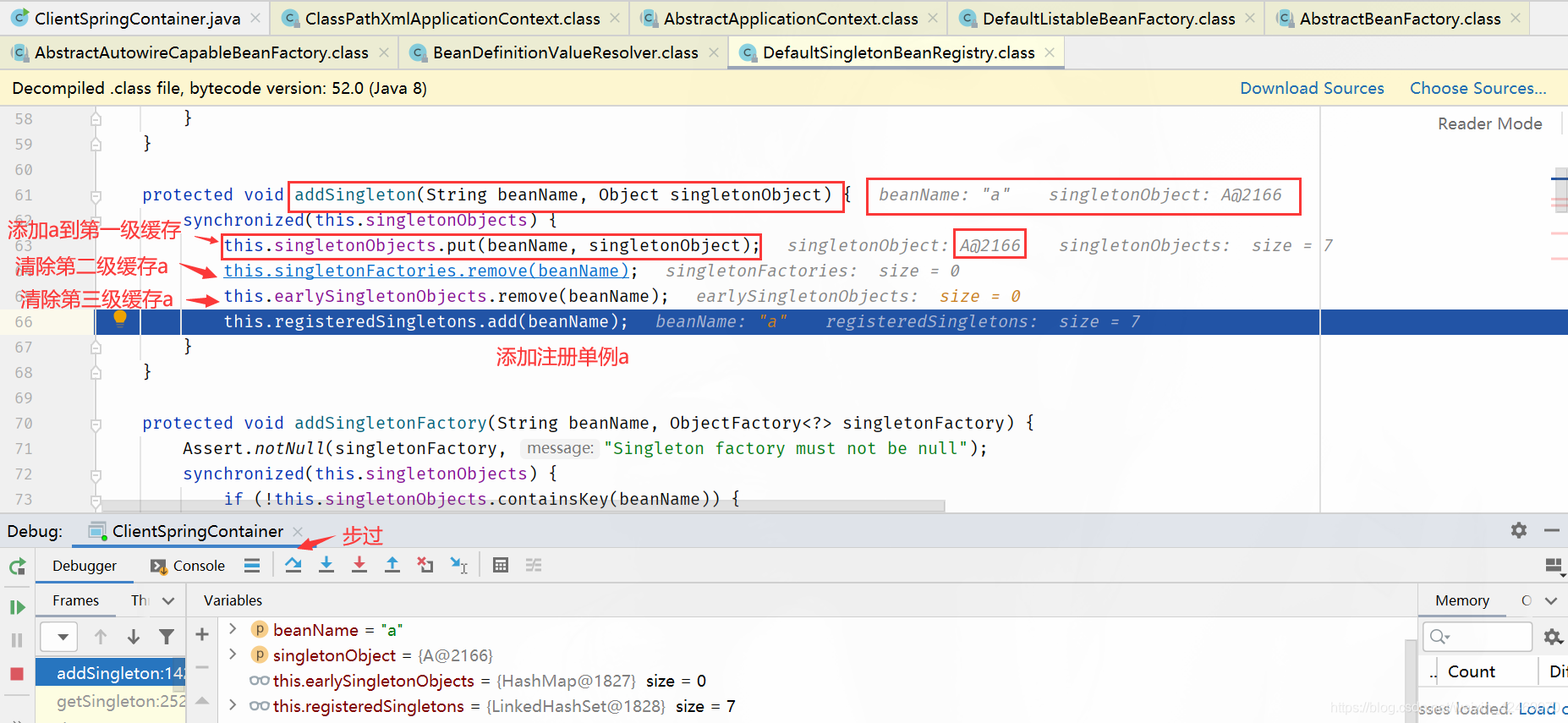
查看缓存:
| 缓存 | A | B |
|---|---|---|
| 第一级缓存(singletonObjects) | a,A@2166 | b,B@2179 |
| 第二级缓存(earlySingletonObjects) | null | null |
| 第三级缓存(singletonFactories) | null | null |
步过:
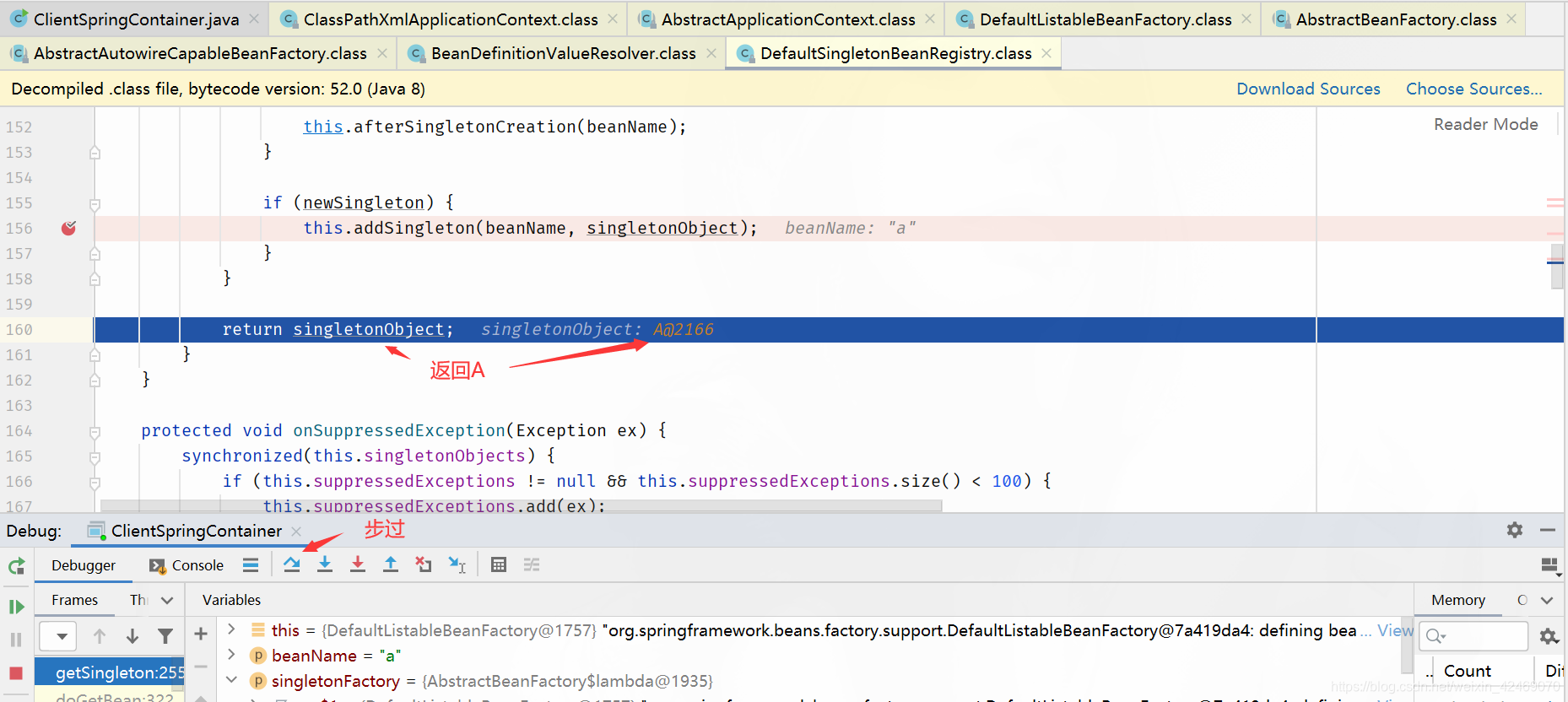
步过:
步过:
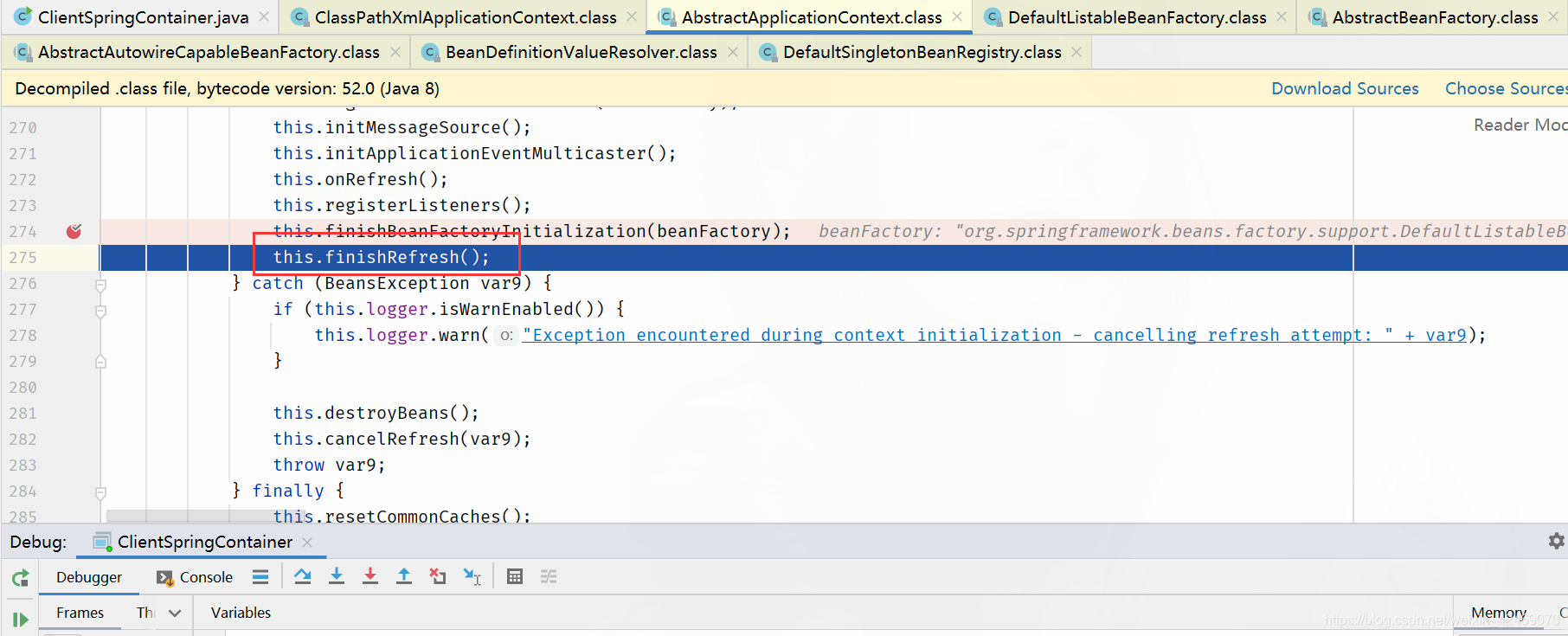
spring循环依赖debug源码04
再次 解读:A / B两对象在三级缓存中的迁移说明
1、A 创建过程中需要 B,于是 A 将自己放到三级缓里面,去实例化 B
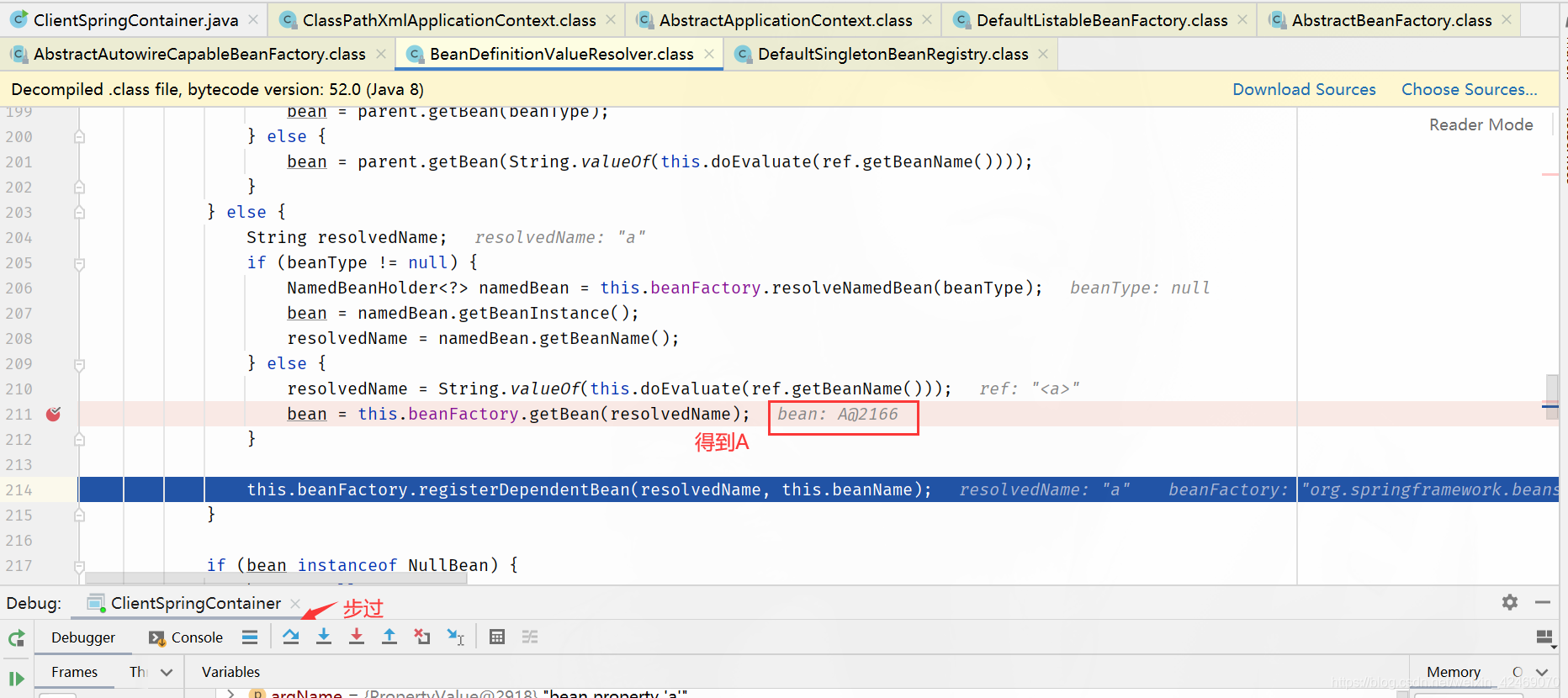
2、B 实例化的时候发现需要 A,于是 B 先查一级缓存,没有,再查二级缓存,还是没有,再查三级缓存,找到了 A 然后把三级缓存里面的这个 A 放到二级缓存里面,并删除三级缓存里面的 A。
3、B 顺利初始化完毕,将自己放到一级缓存里面(此时 B 里面的 A 依然是创建中状态),然后回来接着创建 A,此时 B 已经创建结束,直接从一级缓存里面拿到 B,然后完成创建,并将 A 自己放到一级缓存里面。
spring循环依赖小总结
Spring创建 bean 主要分为两个步骤,创建原始 bean 对象,接着去填充对象属性和初始化
每次创建 bean 之前,我们都会从缓存中查下有没有该 bean,因为是单例,只能有一个
当我们创建 beanA 的原始对象后,并把它放到三级缓存中,接下来就该填充对象属性了,这时候发现依赖了 beanB,接着就又去创建 beanB,同样的流程,创建完 beanB 填充属性时又发现它依赖了 beanA 又是同样的流程,
不同的是:
这时候可以在三级缓存中查到刚放进去的原始对象 beanA,所以不需要继续创建,用它注入 beanB,完成 beanB 的创建
既然 beanB 创建好了,所以 beanA 就可以完成填充属性的步骤了,接着执行剩下的逻辑,闭环完成
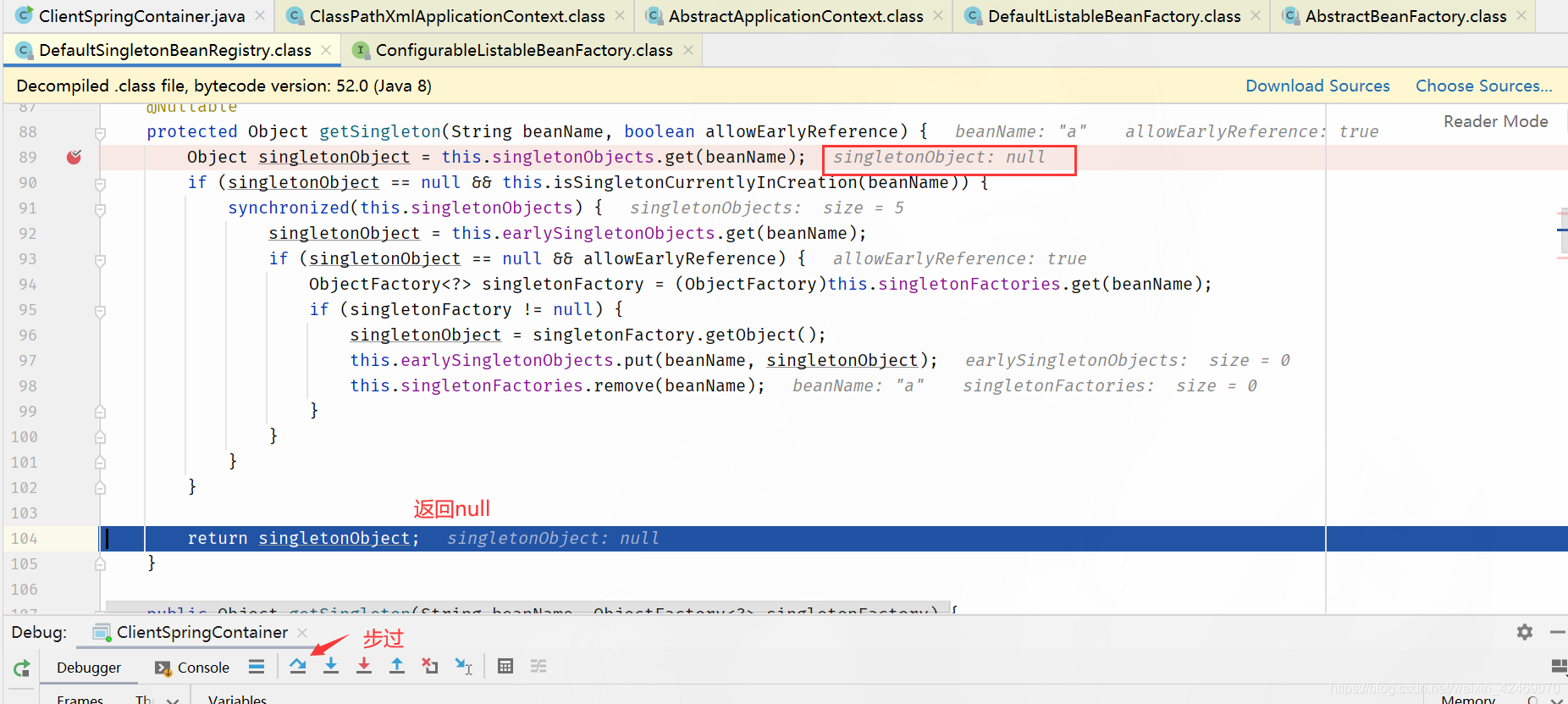
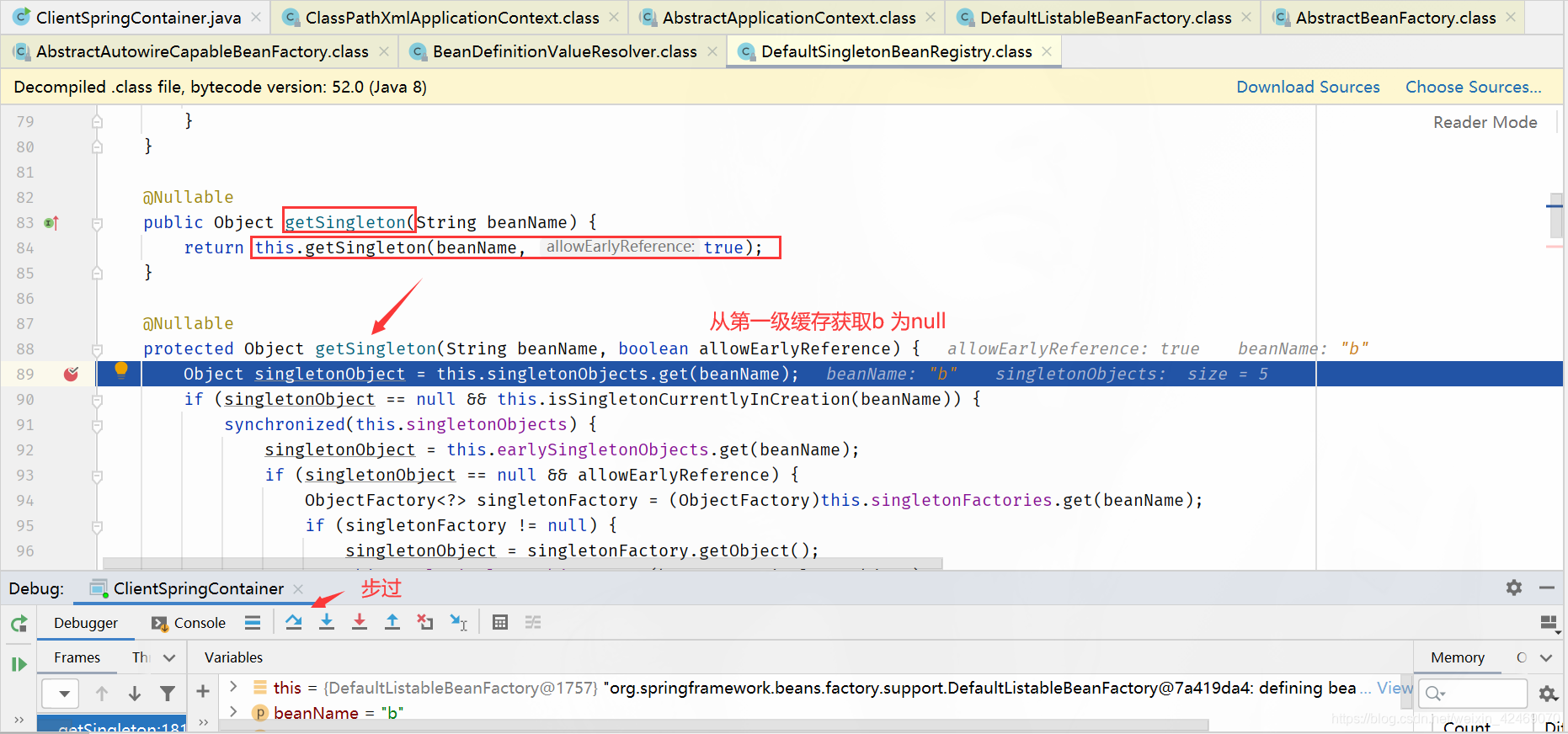
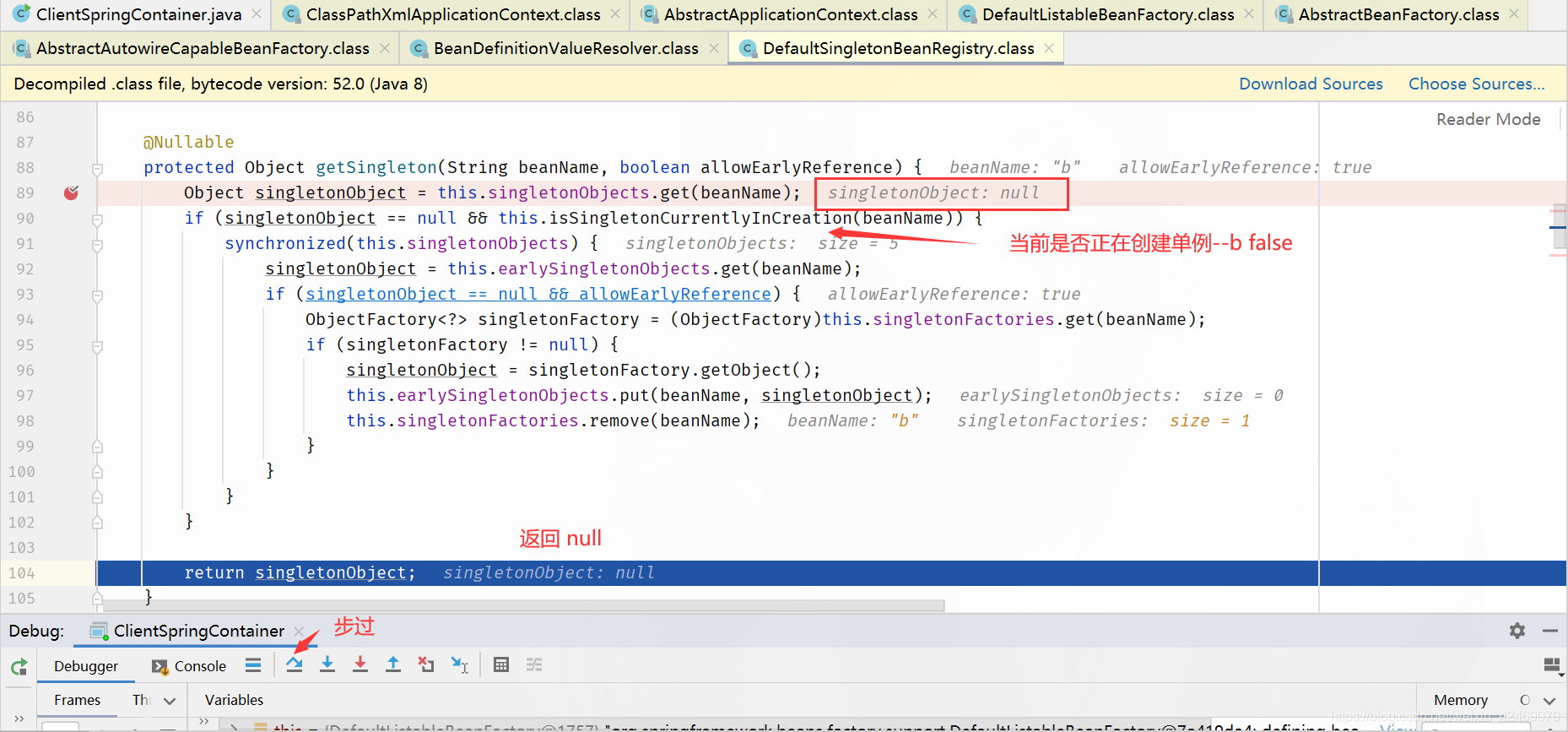
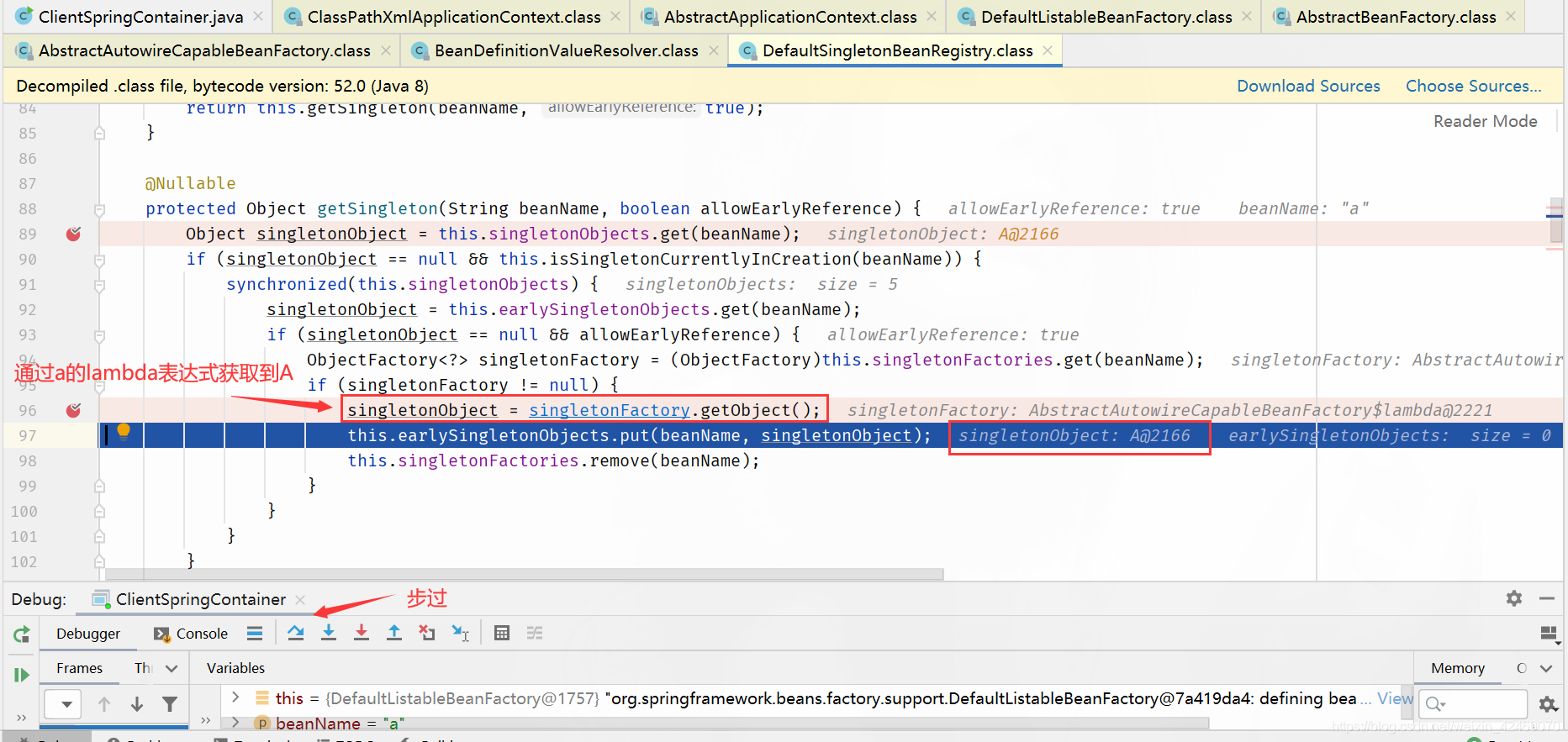
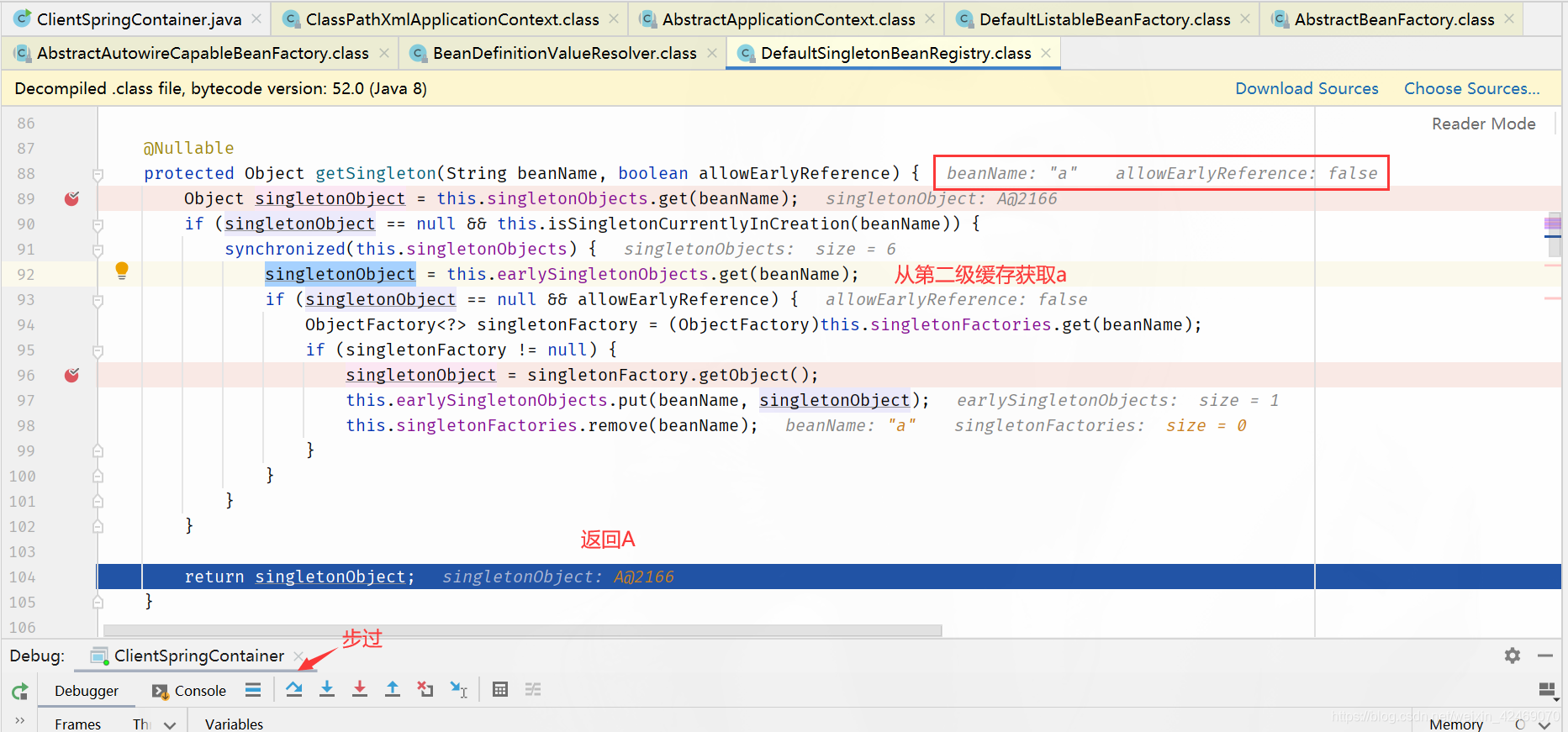
DefaultSingletonBeanRegistry.getSingleton()源码其中一个方法:
package org.springframework.beans.factory.support;
...
public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry{
...
@Nullable
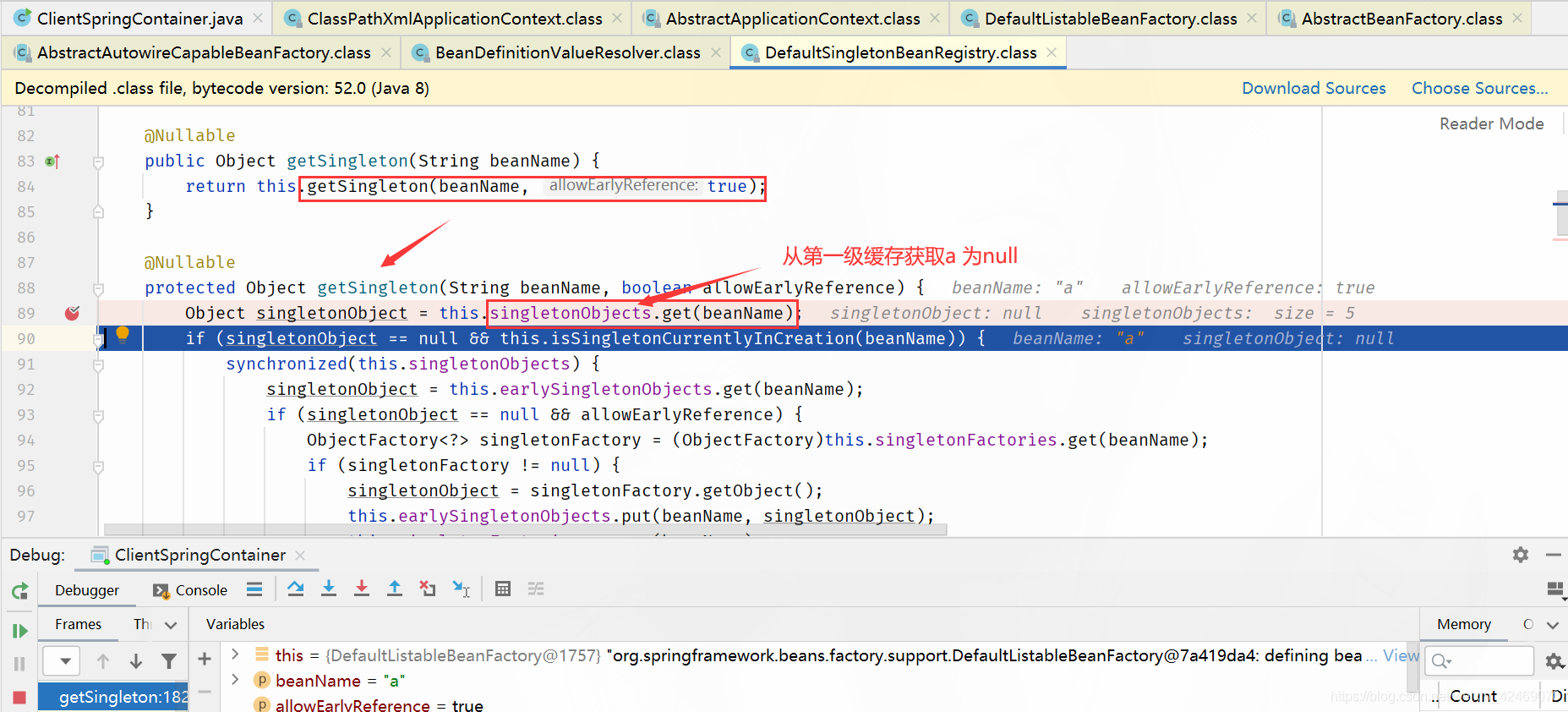
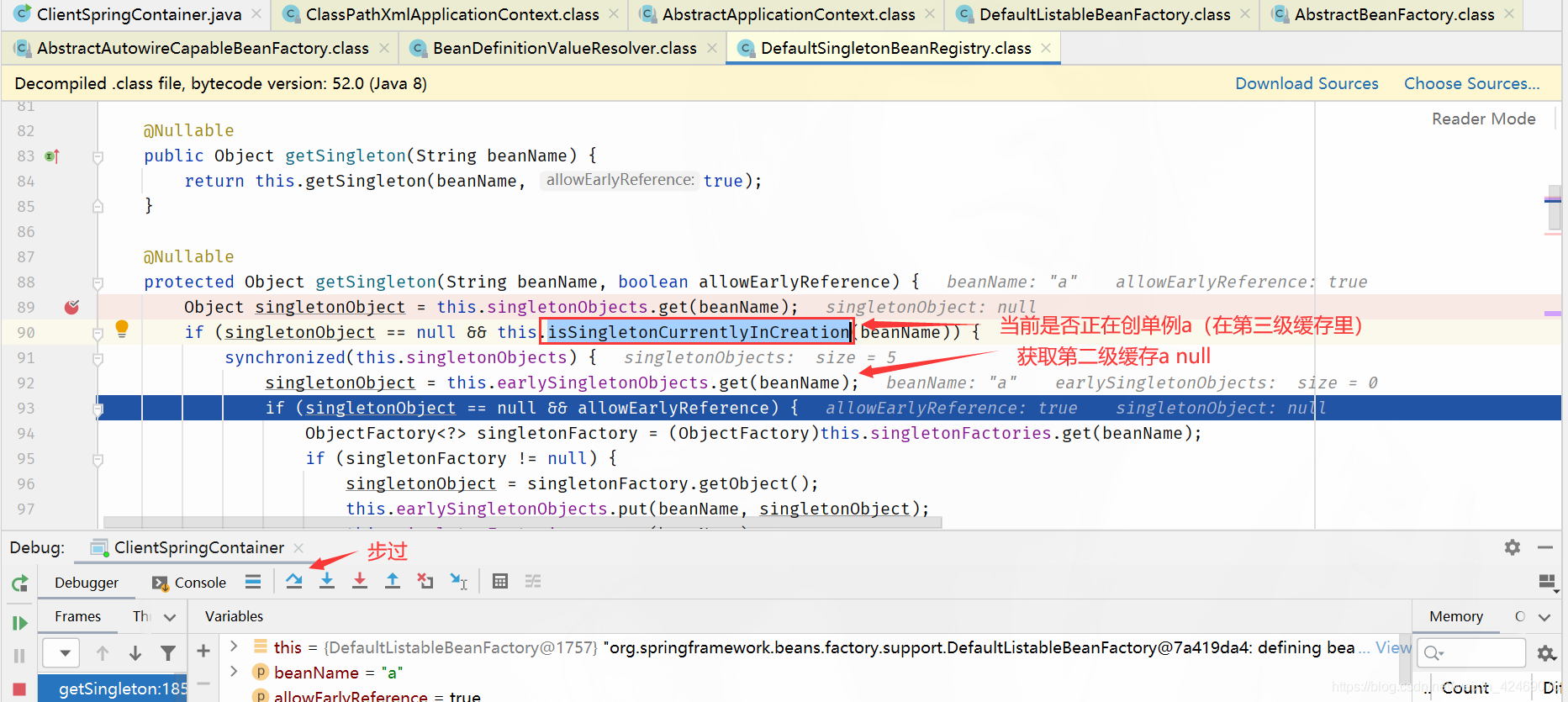
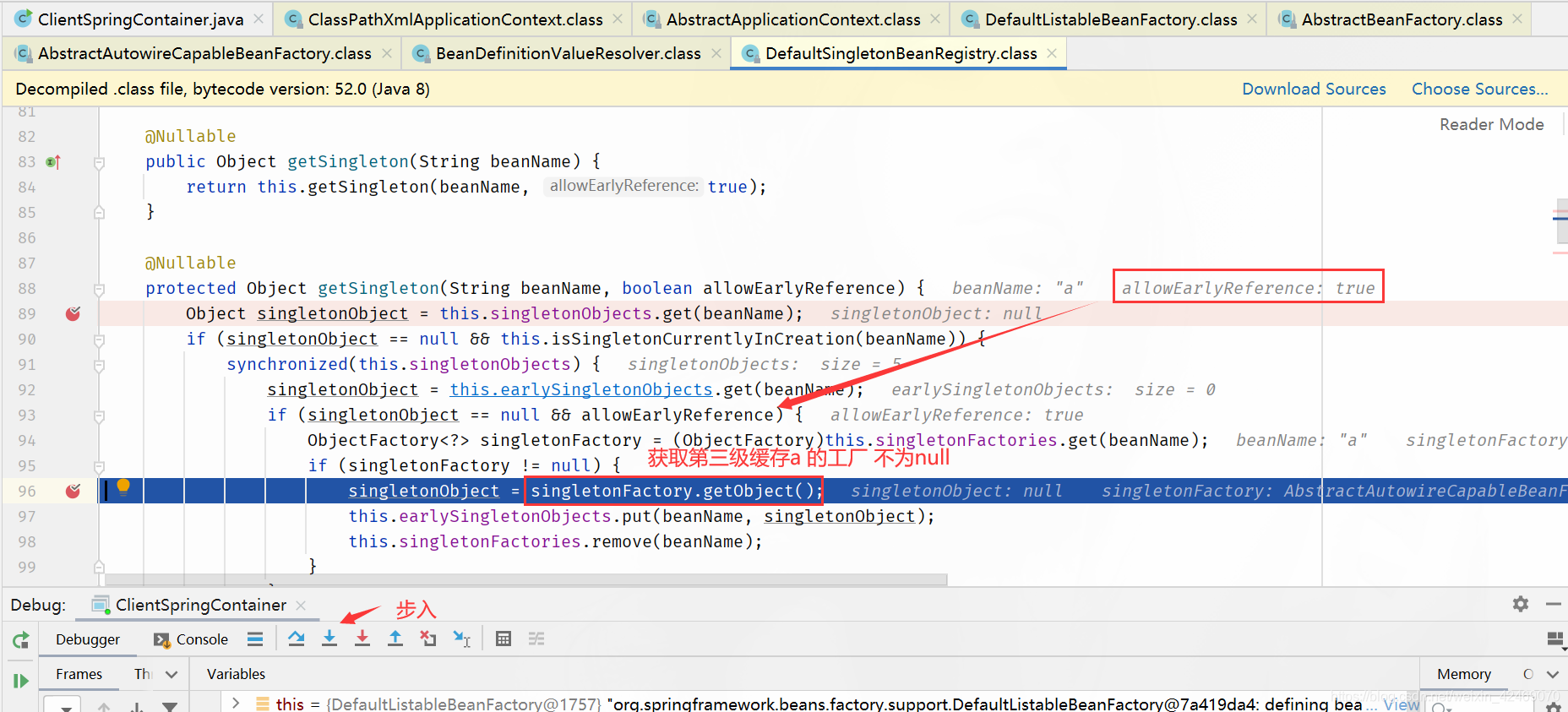
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 从 singletonObjects 获取实例,singletonObjects 中的实例都是准备好的 bean 实例,可以直接使用(一级缓存)
Object singletonObject = this.singletonObjects.get(beanName);
// isSingletonCurrentlyInCreation() 判断当前单例 bean 是否正在创建中
if (singletonObject == null && this.isSingletonCurrentlyInCreation(beanName)) {
synchronized(this.singletonObjects) {
// 一级缓存没有,就去二级缓存找
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
// 二级缓存没有,就去三级缓存找
ObjectFactory<?> singletonFactory = (ObjectFactory)this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 三级缓存有的话,就把它移动到二级缓存
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
......
}
Spring 解决循环依赖依靠的是 Bean 的"中间态"这个概念,而这个中间态指的是已经实例化但还没初始化的状态 ---->半成品。
实例化的过程又是通过构造器创建的,如果 A 还没创建好出来怎么可能提前曝光,所以构造器的循环依赖无法解决。
Spring 为了解决单例的循坏依赖问题,使用了三级缓存:
其中一级缓存为单例池(singletonObjects)。
二级缓存为提前曝光对象(earlySingletonObjects)
三级级存为提前曝光对象工厂(singletonFactories) 。
假设A、B循环引用,实例化 A 的时候就将其放入三级缓存中,接着填充属性的时候,发现依赖了 B,同样的流程也是实例化后放入三级缓存,接着去填充属性时又发现自己依赖 A,这时候从缓存中查找到早期暴露的 A,没有AOP 代理的话,直接将 A 的原始对象注入 B,完成B 的初始化后,进行属性填充和初始化,这时候 B 完成后,就去完成剩下的 A 的步骤,如果有 AOP 代理,就进行 AOP 处理获取代理后的对象 A,注入 B,走剩下的流程。
Debug的步骤—> Spring解决循环依赖的过程:
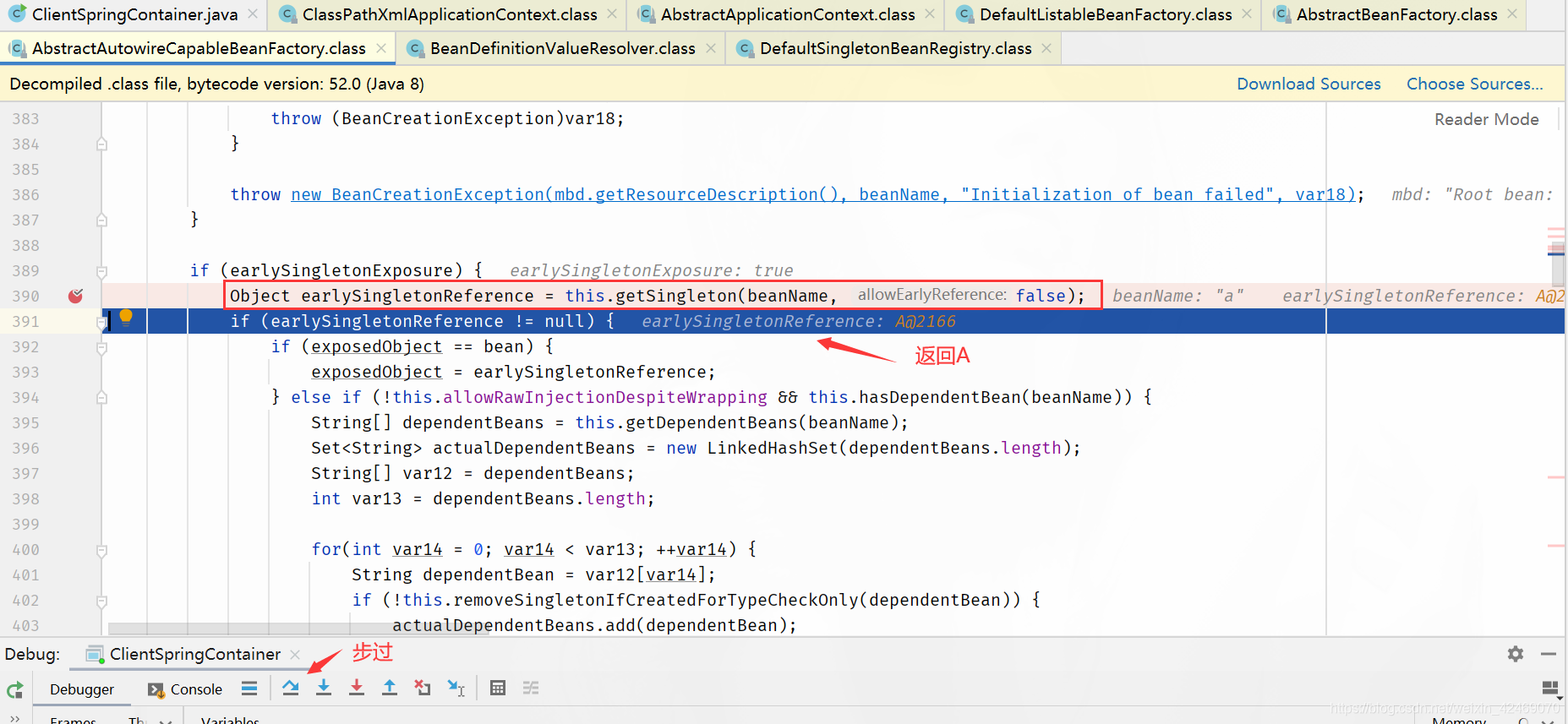
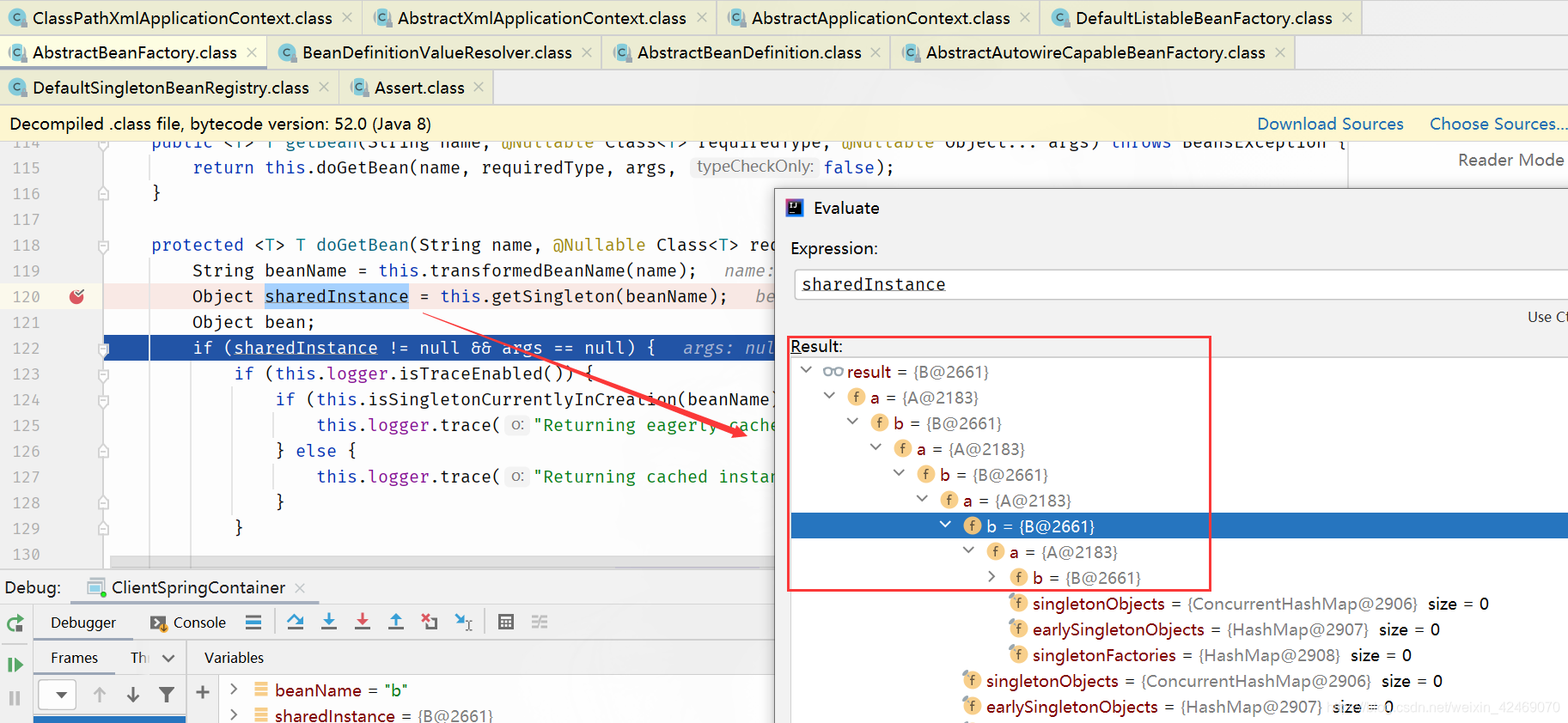
1. 调用doGetBean()方法,想要获取beanA,于是调用getSingleton()方法从缓存中查找beanA
2. 在getSingleton()方法中,从一级缓存中查找,没有,返回null
3. doGetBean()方法中获取到的beanA为null,于是走对应的处理逻辑,调用getSingleton()的重载方法(参数为ObjectFactory的)
4. 在getSingleton()方法中,先将beanA_name添加到一个集合中,用于标记该bean正在创建中。然后回调匿名内部类的creatBean方法
5. 进入AbstractAutowireCapableBeanFactory#doCreateBean,先反射调用构造器创建出beanA的实例,然后判断:是否为单例、是否允许提前暴露引用(对于单例一般为true)、是否正在创建中(即是否在第四步的集合中)。判断为true则将beanA添加到【三级缓存】中
6. 对beanA进行属性填充,此时检测到beanA依赖于beanB,于是开始查找beanB
7. 调用doGetBean()方法,和上面beanA的过程一样,到缓存中查找beanB,没有则创建,然后给beanB填充属性
8. 此时 beanB依赖于beanA,调用getSingleton()获取beanA,依次从一级、二级、三级缓存中找,此时从三级缓存中获取到beanA的创建工厂,通过创建工厂获取到singletonObject,此时这个singletonObject指向的就是上面在doCreateBean()方法中实例化的beanA
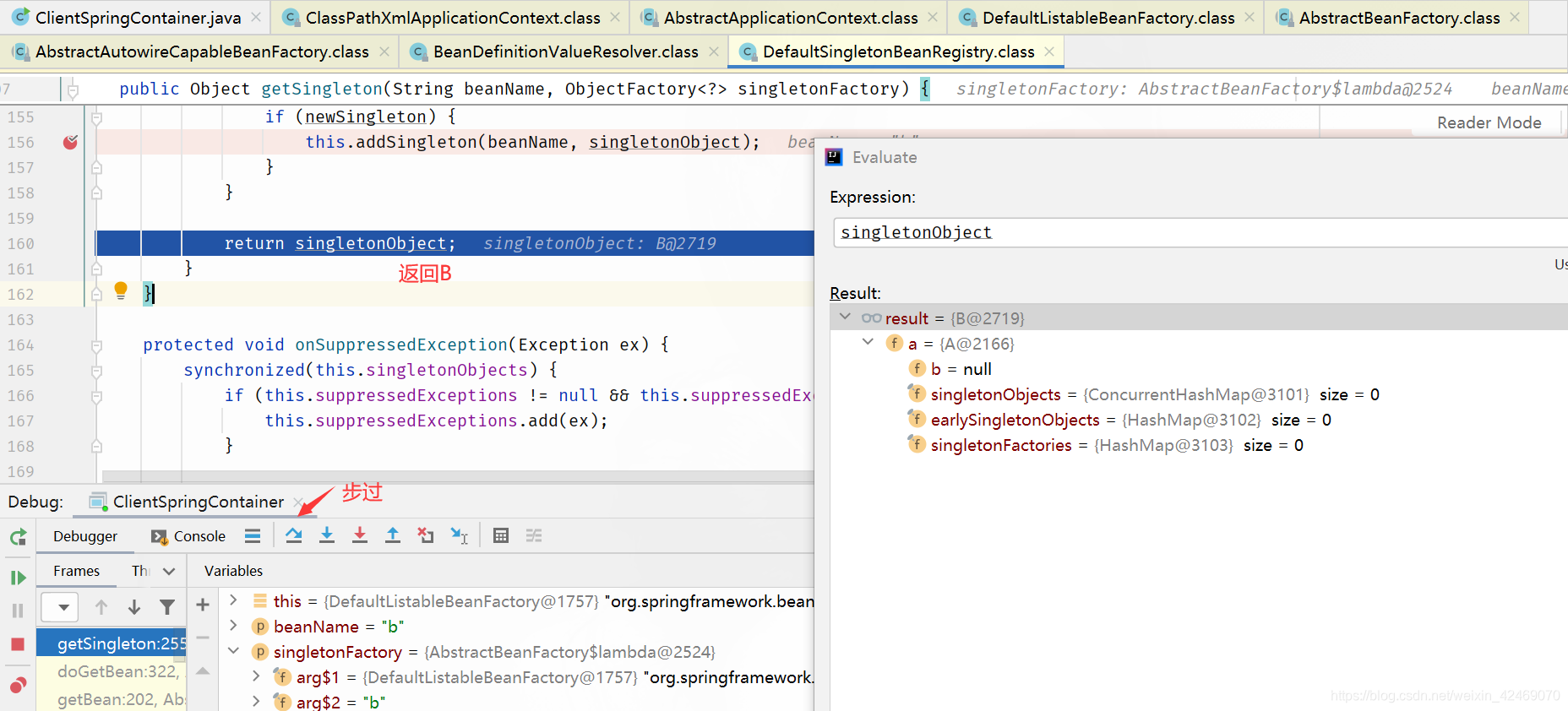
9. 这样beanB就获取到了beanA的依赖,于是beanB顺利完成实例化,并将beanA从三级缓存移动到二级缓存中
10.随后beanA继续他的属性填充工作,此时也获取到了beanB,beanA也随之完成了创建,回到getSingleton()方法中继续向下执行,将beanA从二级缓存移动到一级缓存中
四、Redis
redis版本升级说明
Linux系统最好安装redis6.0.8+版本的
Redis官网
Redis中文网
查看redis版本
redis-server --version
redis-server -v
或者登陆redis 输入命令info
info
redis两个小细节说明
8大数据类型:
- 1.String(字符类型)
- 2.Hash(散列类型)
- 3.List(类别类型)
- 4.Set(集合类型)
- 5.SortedSet(有序集合类型,简称zset)
- 6.Bitmap(位图)
- 7.HyperLogLog(统计)
- 8.GEO(地理)
备注:
命令不区分大小写,而key是区分大小写的

help @类型名词
help @string #查看string类型的所有命名
127.0.0.1:6379> help @string
APPEND key value
summary: Append a value to a key
since: 2.0.0
BITCOUNT key [start end]
summary: Count set bits in a string
since: 2.6.0
BITFIELD key [GET type offset] [SET type offset value] [INCRBY type offset increment] [OVERFLOW WRAP|SAT|FAIL]
summary: Perform arbitrary bitfield integer operations on strings
since: 3.2.0
BITOP operation destkey key [key ...]
summary: Perform bitwise operations between strings
since: 2.6.0
BITPOS key bit [start] [end]
summary: Find first bit set or clear in a string
since: 2.8.7
DECR key
summary: Decrement the integer value of a key by one
since: 1.0.0
DECRBY key decrement
summary: Decrement the integer value of a key by the given number
since: 1.0.0
GET key
summary: Get the value of a key
since: 1.0.0
GETBIT key offset
summary: Returns the bit value at offset in the string value stored at key
since: 2.2.0
GETRANGE key start end
summary: Get a substring of the string stored at a key
since: 2.4.0
GETSET key value
summary: Set the string value of a key and return its old value
since: 1.0.0
INCR key
summary: Increment the integer value of a key by one
since: 1.0.0
INCRBY key increment
summary: Increment the integer value of a key by the given amount
since: 1.0.0
INCRBYFLOAT key increment
summary: Increment the float value of a key by the given amount
since: 2.6.0
MGET key [key ...]
summary: Get the values of all the given keys
since: 1.0.0
MSET key value [key value ...]
summary: Set multiple keys to multiple values
since: 1.0.1
MSETNX key value [key value ...]
summary: Set multiple keys to multiple values, only if none of the keys exist
since: 1.0.1
PSETEX key milliseconds value
summary: Set the value and expiration in milliseconds of a key
since: 2.6.0
SET key value [EX seconds] [PX milliseconds] [NX|XX]
summary: Set the string value of a key
since: 1.0.0
SETBIT key offset value
summary: Sets or clears the bit at offset in the string value stored at key
since: 2.2.0
SETEX key seconds value
summary: Set the value and expiration of a key
since: 2.0.0
SETNX key value
summary: Set the value of a key, only if the key does not exist
since: 1.0.0
SETRANGE key offset value
summary: Overwrite part of a string at key starting at the specified offset
since: 2.2.0
STRLEN key
summary: Get the length of the value stored in a key
since: 2.2.0
127.0.0.1:6379>
string类型使用场景
最常用:
- set key value
- get key
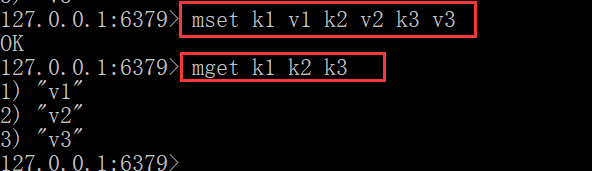
同时设置/获取多个键值:
- mset k1 v1 k2 v2
- mget k1 k2
数值增减:
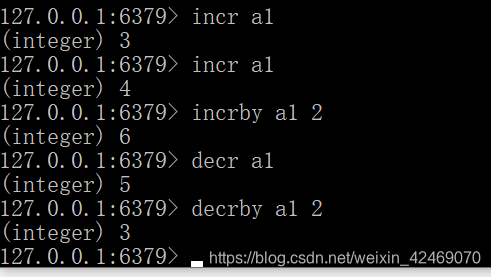
- 递增数字 – incr key
- 增加指定的整数 – incrby key increment
- 递减数值 – decr key
- 减少指定的整数 – decrby key decrement
获取字符串长度:
- strlen key
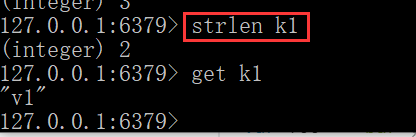
分布式锁:
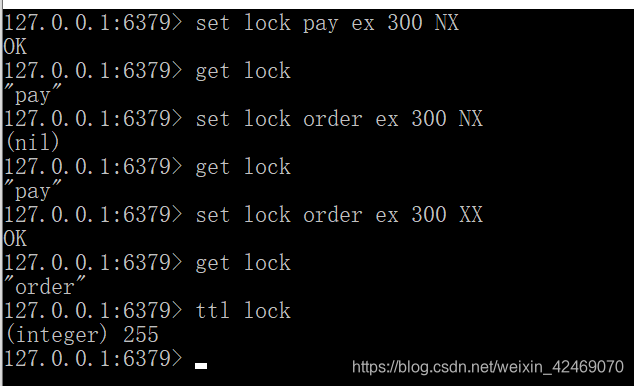
- setnx key value
- set key value [EX seconds] [PX milliseconds] [NX|XX]
- EX:key在多少秒之后过期
- PX:key在多少毫秒之后过期
- NX:当key不存在的时候,才创建key,效果等同于setnx
- XX:当key存在的时候,覆盖key
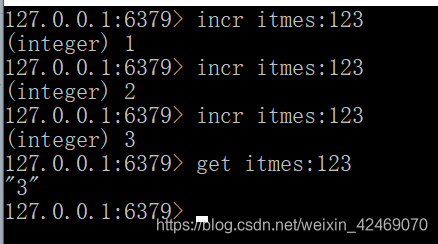
应用场景:
比如某商品的收藏数:可以使用 incr items:sku get items:sku
hash类型使用场景
redis的hash类型对应java的数据类型:
Map<String,Map<Object,Object>>
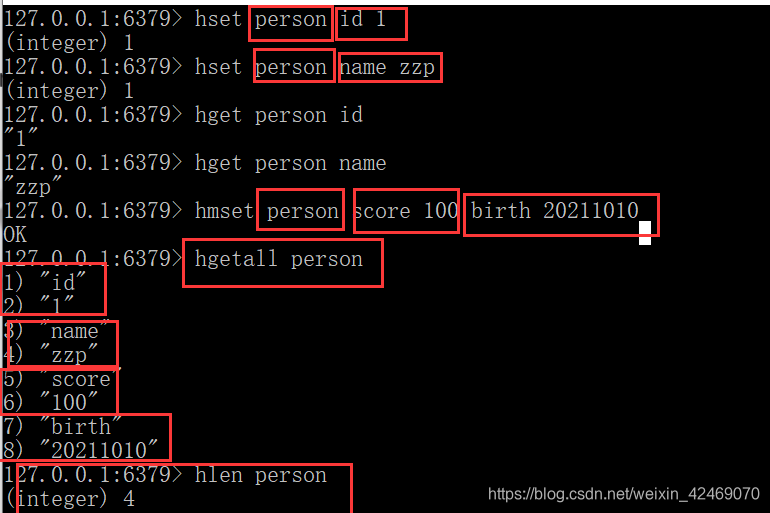
一次设置一个字段值:hset key field value
一次获取一个字段值: hget key field
一次设置多个字段值:hmset key field value [field value …]
一次获取多个字段值:hmget key field [field …]
获取所有字段值:hgetall key
获取某个key内的全部数量:hlen key
删除一个key:hdel key field
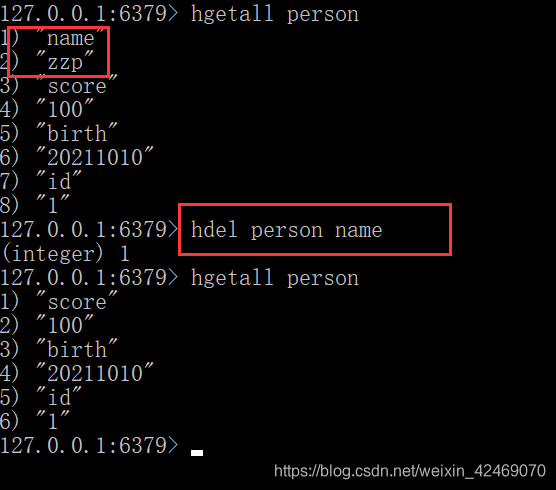
应用场景:
购物车早期,当前小中厂可用:
新增商品: hset shopcar:zzp001 3344 1
新增商品: hset shopcar:zzp001 3355 1
增加商品数量: hincrby shopcar:zzp001 3355 1
商品总数: hlen shopcar:zzp001
全部选择: hgetall shopcar:zzp001
实例:
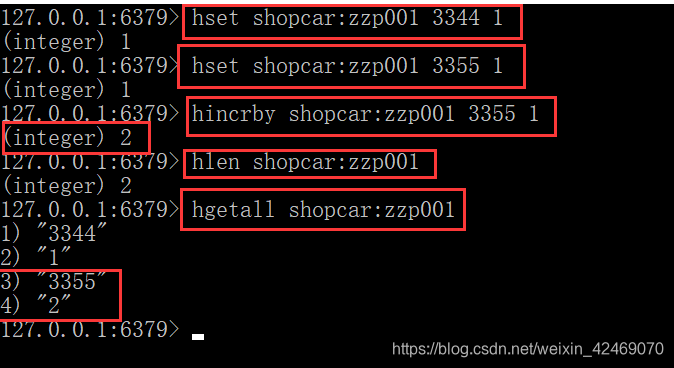
list类型使用场景
向列表左边添加元素:lpush key value [value …]
向列表左边释放一个元素:lpop key value [value …]
向列表右边添加元素:rpush key value [value …]
向列表右边释放一个元素:rpop key value [value …]
查看列表:lrange key startNumber stopNumber
获取列表中元素的个数:llen key
应用场景:
微信文章订阅公众号
1.微信号zzp111关注作者A和作者B
2.作者A和作者B分别发布了文章 11和22,然后就会安装进zzp111的List
lpush zzp111 11 22
3.查看微信号zzp111的订阅的全部文章,类似分页,下面0~10就是一次显示10条
lrange zzp111 0 10
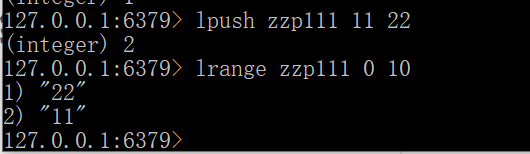
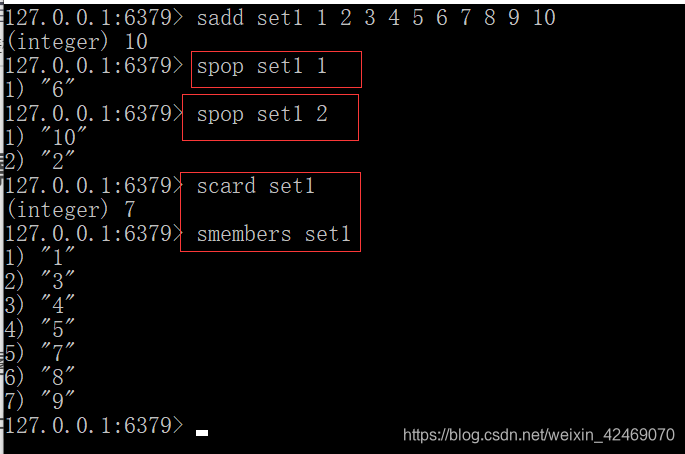
set类型使用场景
添加元素:sadd key member [member …]
删除元素:srem key member [member …]
获取集合中的所有元素:smembers key
判断元素是否在集合中:sismember key member
获取集合中的元素个数:scard key
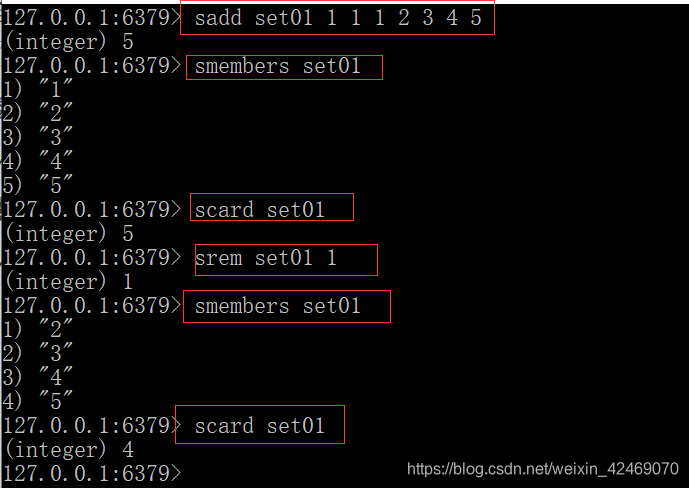
从集合中随机弹出一个元素,元素不删除:srandmember key [数字]
srandmember set01 #不写数字 默认为1个
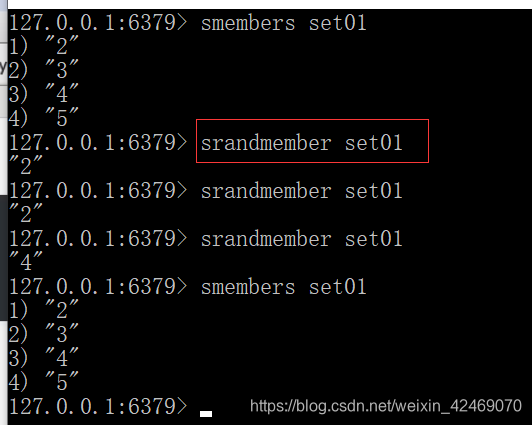
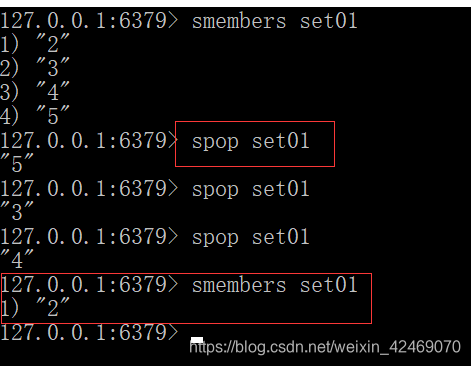
从集合中随机弹出一个元素,出一个删一个:spop key [数字]
spop set01 #不写数字 默认为1个
集合运算:
-
集合的差集运算A - B
属于A但不属于B的元素构成的集合
sdiff key [key …]
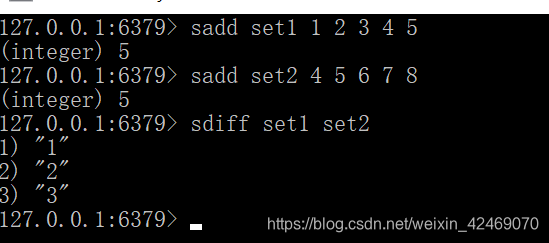
-
集合的交集运算A ∩ B
属于A同时也属于B的共同拥有的元素构成的集合
sinter key [key …]
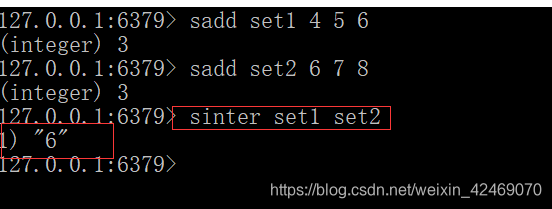
-
集合的并集运算A U B
属于A或者属于B的元素合并后的集合
sunion key [key …]
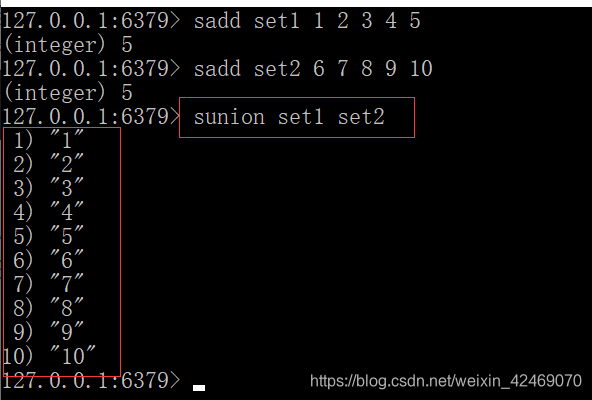
应用场景:
-
微信抽奖小程序
1.添加1~10数字分别代表用户
2.使用spop 命令(删除用户) 一等奖1个 二等奖2个 或者 使用srandmember 命令(不删除用户)
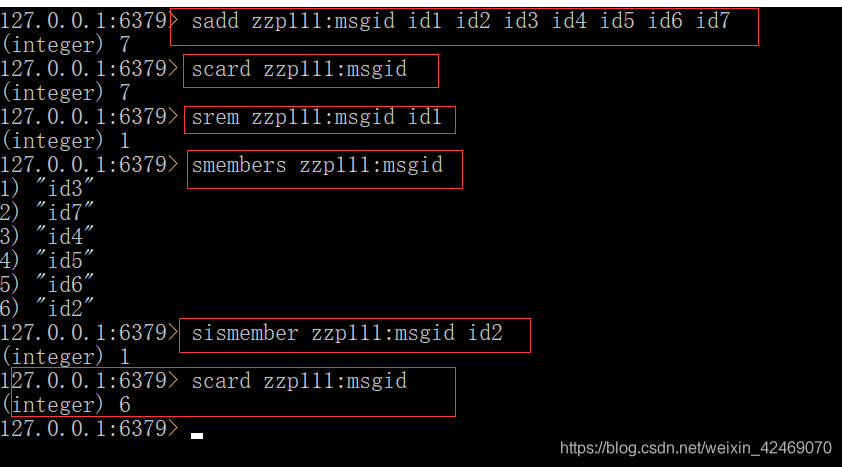
-
微信朋友圈点赞
1.微信号zzp111发布一条信息id
2.新增点赞:sadd zzp111:msgid 点赞用户1 点赞用户2 …
3.取消点赞: srem zzp111:msgid 点赞用户1
4.展现所有点赞过的用户:smembers zzp111:msgid
5.点赞用户数量统计:scard zzp111:msgid
6.判断某个朋友是否对楼主点赞过:sismember zzp111:msgid 点赞用户1
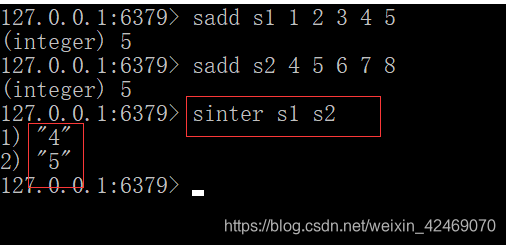
-
微博好友关注社交关系
共同关注的人: sinter s1 s2
我关注的人也关注他(大家爱好相同):
sismember s1 1
sismember s2 1
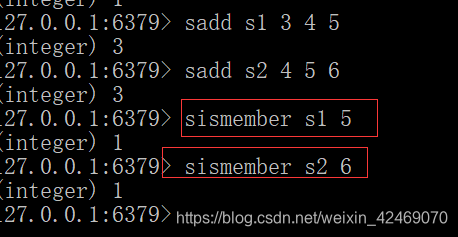
-
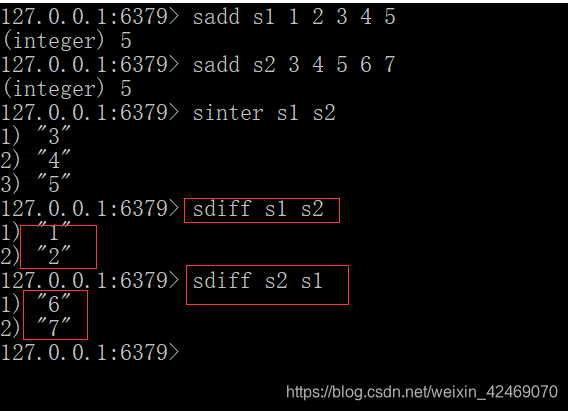
QQ内推可能认识的人
一个qq为参考点取差集:sdiff s1 s2
zset类型使用场景
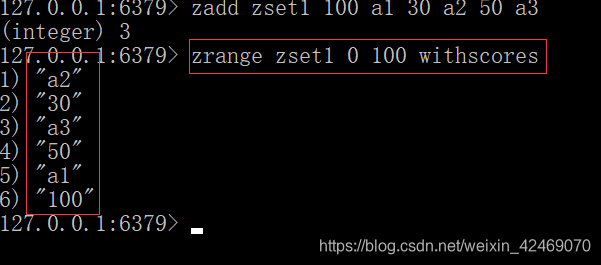
向有序集合中加入一个元素和该元素的分数
添加元素:zadd key score member [score member …]

按照元素分数从小到大的顺序返回索引从start到stop之间的所有元素:zrange key start stop [WITHSCORES]
获取元素的分数: zscore key member

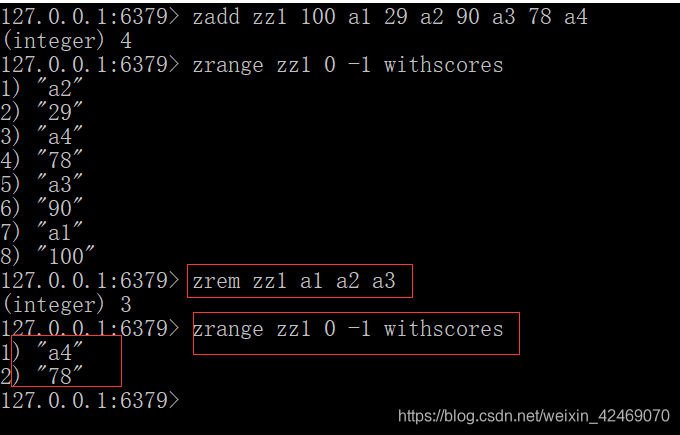
删除元素:zrem key member [member …]
获取指定分数范围的元素:zrangebyscore key min max [WITHSCORES] [LIMIT offset count]
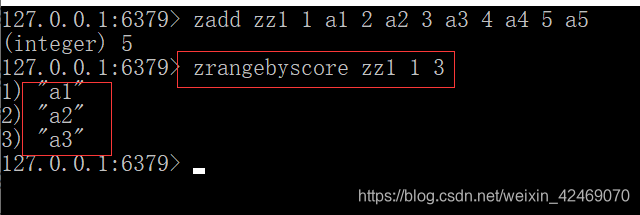
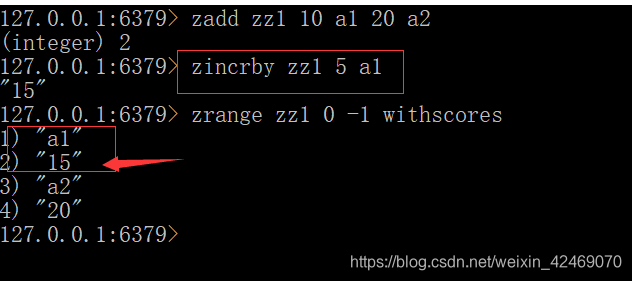
增加某个元素的分数:zincrby key increment member
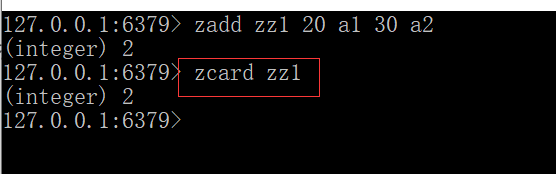
获取集合中元素的数量: zcred key
获得指定分数范围内的元素个数:zcount key min max

删除指定的一个元素或多个元素:zrem key member [member …]
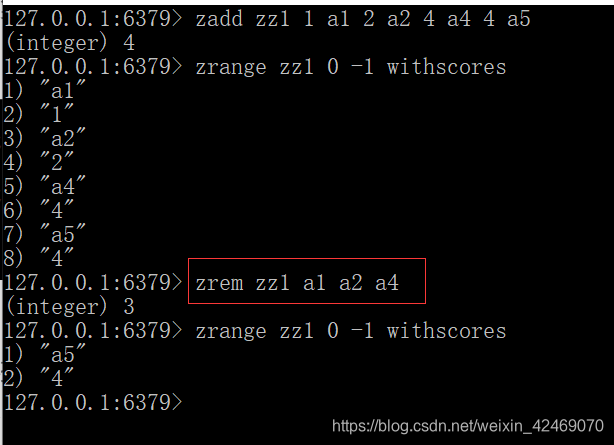
按照排名范围删除元素:zremrangebyrank key start stop
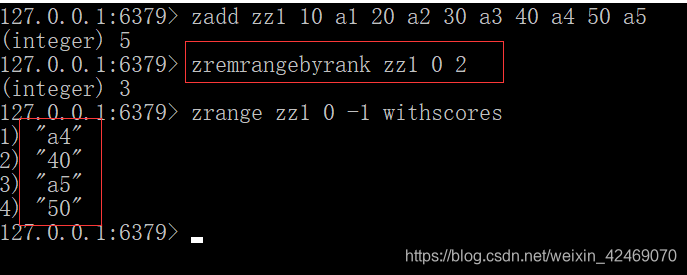
获取元素的排名:
- 从小到大:zrank key member

- 从大到小: zrevrank key member

应用场景:
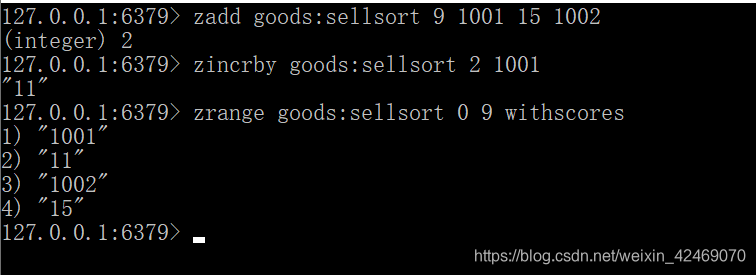
根据商品销售对商品进行排序显示
思路:定义商品销售排行榜(sorted set集合),key为goods:sellsort,分数为商品销售数量。
1、商品编号1001的销量是9,商品编号1002的销量是15。 命令: zadd goods:sellsort 9 1001 15 1002
2、有一个客户又买了2件商品1001,商品编号1001销量加2。 命令: zincrby goods:sellsort 2 1001
3、求商品销量前9名。 命令: zrange goods:sellsort 0 9 withscores
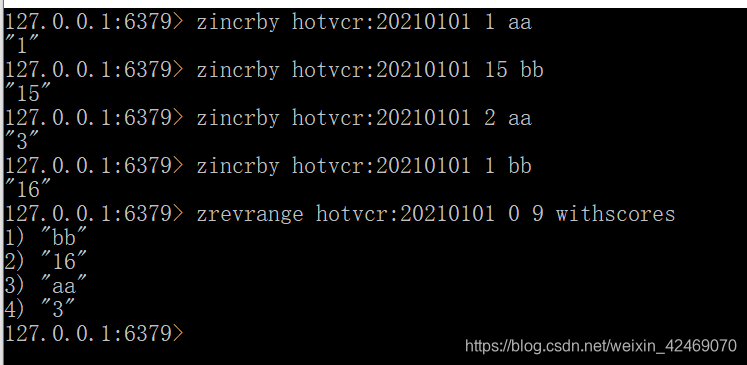
抖音热搜:
1、点击视频:
zincrby hotvcr:20210101 1 aa
zincrby hotvcr:20210101 15 bb
zincrby hotvcr:20210101 2 aa
zincrby hotvcr:20210101 1 bb
2、展示当日排行前10条:
zrevrange hotvcr:20210101 0 9 withscores
boot整合redis搭建超卖程序
使用场景:多个服务间 + 保证同一时刻内 + 同一用户只能有一个请求(防止关键业务出现数据冲突和并发错误)
创建Module: boot-reids01服务端口号1111
改pom文件:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.3.RELEASE</version>
<relativePath/><!-- Lookup parent from reposittory-->
</parent>
<groupId>com.zzp.redis</groupId>
<artifactId>reids01</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>boot-reids01</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!-- web + actuator-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!-- springboot与 redis 整合依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!-- jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.1.0</version>
</dependency>
<!-- springboot-aop 技术 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<!-- redisson -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.4</version>
</dependency>
<!-- 一般通用基础配置 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>2.3.7.RELEASE</version>
<configuration>
<mainClass>com.zpp.redis.BootReids01Application</mainClass>
</configuration>
<executions>
<execution>
<id>repackage</id>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
写YML文件配置:
# 应用名称
spring.application.name=boot-reids01
# 应用服务 WEB 访问端口
server.port=1111
# =============== redis相关配置 =========
# redis 数据库索引(默认为0)
spring.redis.database=0
# redis 服务器地址
spring.redis.host=127.0.0.1
# redis 服务器连接端口号
spring.redis.port=6379
# redis 服务器连接密码
spring.redis.password=123456
# 连接池最大连接数(使用负值表示没有上限) 默认 8
spring.redis.lettuce.pool.max-active=8
# 连接池最大阻塞等待时间(使用负值表示没有时间限制) 默认 -1
spring.redis.lettuce.pool.max-wait=-1
# 连接池中的最大空闲连接 默认 8
spring.redis.lettuce.pool.max-idle=8
# 连接池中的最小空闲连接 默认 0
spring.redis.lettuce.pool.mix-idle=0
配置类:
package com.zpp.redis.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.lettuce.LettuceConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import java.io.Serializable;
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Serializable> redisTemplate(LettuceConnectionFactory connectionFactory){
RedisTemplate<String, Serializable> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(connectionFactory);
// 序列化
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
return redisTemplate;
}
}
主启动:
package com.zpp.redis;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class BootReids01Application {
public static void main(String[] args) {
SpringApplication.run(BootReids01Application.class, args);
}
}
业务类:
package com.zpp.redis.controller;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
@RestController
public class GoodController {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Value("${server.port}")
private String serverPort;
@GetMapping("/buy_goods")
public String buy_goods(){
// get key === 查看库存的数量够不够
String result = stringRedisTemplate.opsForValue().get("goods:001");
int goodsNumber = result == null ? 0 : Integer.valueOf(result);
if(goodsNumber > 0){
int realNumber = goodsNumber -1;
stringRedisTemplate.opsForValue().set("goods:001",String.valueOf(realNumber));
System.out.println("成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort);
return "成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort;
}else {
System.out.println("商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort);
}
return "商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort;
}
}
小测试:
在redis创建key=goods:001,数量100
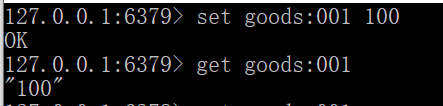
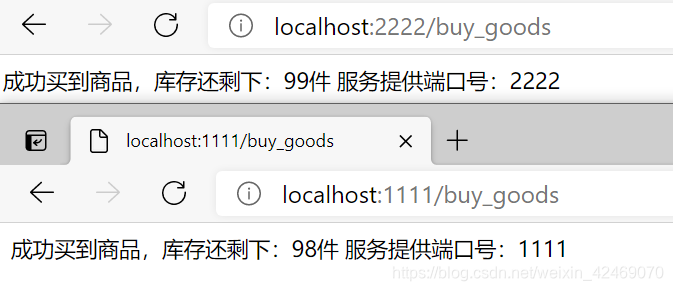
访问:http://localhost:1111/buy_goods
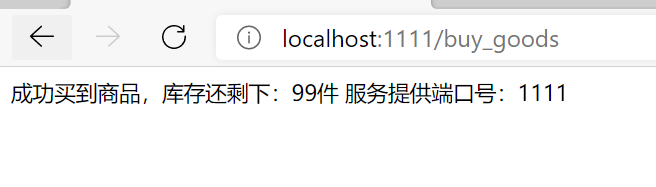
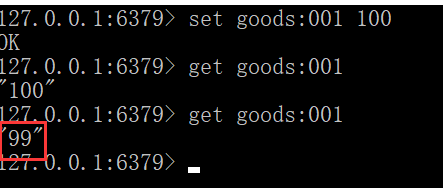
根据boot-reids01服务
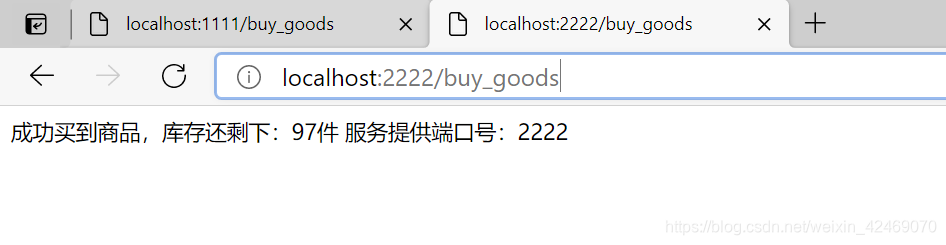
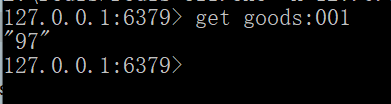
创建Module: boot-reids02服务端口号2222
步骤过程一样,端口号改成2222
测试:http://localhost:2222/buy_goods
redis分布式锁01
问题:单机版没有加锁
没有加锁,并发下数字不对,出现超卖现象
思考:
加synchronized锁 或者 加 ReentrantLock锁?
还是两者都可以?
分析:
synchronized:是java内置关键字,在jvm层面;synchronized无法判断是否获取锁的状态,但是synchronized会自动释放锁(a 线程执行完同步代码会释放锁 ;b 线程执行过程中发生异常会释放锁);用synchronized关键字的两个线程1和线程2,如果当前线程1获得锁,线程2线程等待。如果线程1阻塞,线程2则会一直等待下去,synchronized锁适合代码少量的同步问题
ReentrantLock:java类;Lock可以判断是否获取到锁;Lock需在finally中手工释放锁(unlock()方法释放锁),否则容易造成线程死锁;Lock锁可以使用boolean tryLock(); 或者boolean tryLock(long time, TimeUnit unit) throws InterruptedException;来判断是否获取到锁,如果尝试获取不到锁,线程可以不用一直等待就结束了;
解决:
修改为2.0版
boot-reids01服务和boot-reids02服务在业务类添加锁
使用synchronized锁(这里图简单的)
@GetMapping("/buy_goods")
public String buy_goods(){
synchronized (this){
// get key === 查看库存的数量够不够
String result = stringRedisTemplate.opsForValue().get("goods:001");
int goodsNumber = result == null ? 0 : Integer.valueOf(result);
if(goodsNumber > 0){
int realNumber = goodsNumber -1;
stringRedisTemplate.opsForValue().set("goods:001",String.valueOf(realNumber));
System.out.println("成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort);
return "成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort;
}else {
System.out.println("商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort);
}
return "商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort;
}
}
测试2.0版:http://localhost:1111/buy_goods、http://localhost:2222/buy_goods
redis分布式锁02
使用nginx分布式微服务架构
分布式部署后,单机锁还是出现超卖现象,需要分布式锁
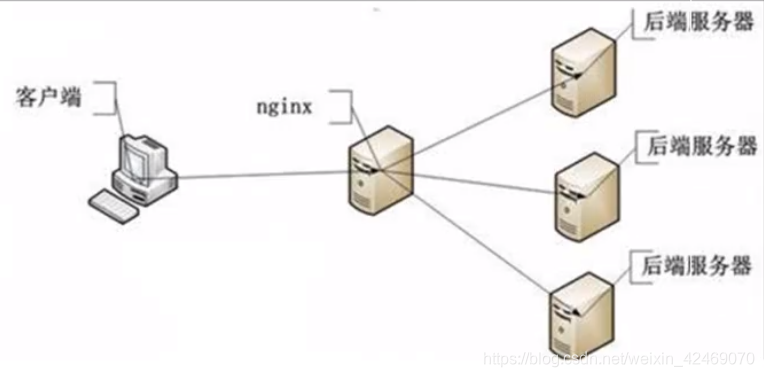
Nginx配置负载均衡:
修改nginx.conf文件
cd /usr/local/nginx/
vi nginx.conf
#gzip on;
upstream mynginx{
server 10.1.121.32:1111 weight=1;
server 10.1.121.32:2222 weight=1;
}
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
#root html;
proxy_pass http://mynginx;
index index.html index.htm;
}
启动nginx
cd /usr/local/nginx/sbin # 进入目录
./nginx -c /usr/local/nginx/conf/nginx.conf #启动
server 10.1.121.32:1111 weight=1;10.1.121.32表示本地window的ip,weight权重
测试nginx轮询,访问:http://192.168.18.131/buy_goods

高并发测试:
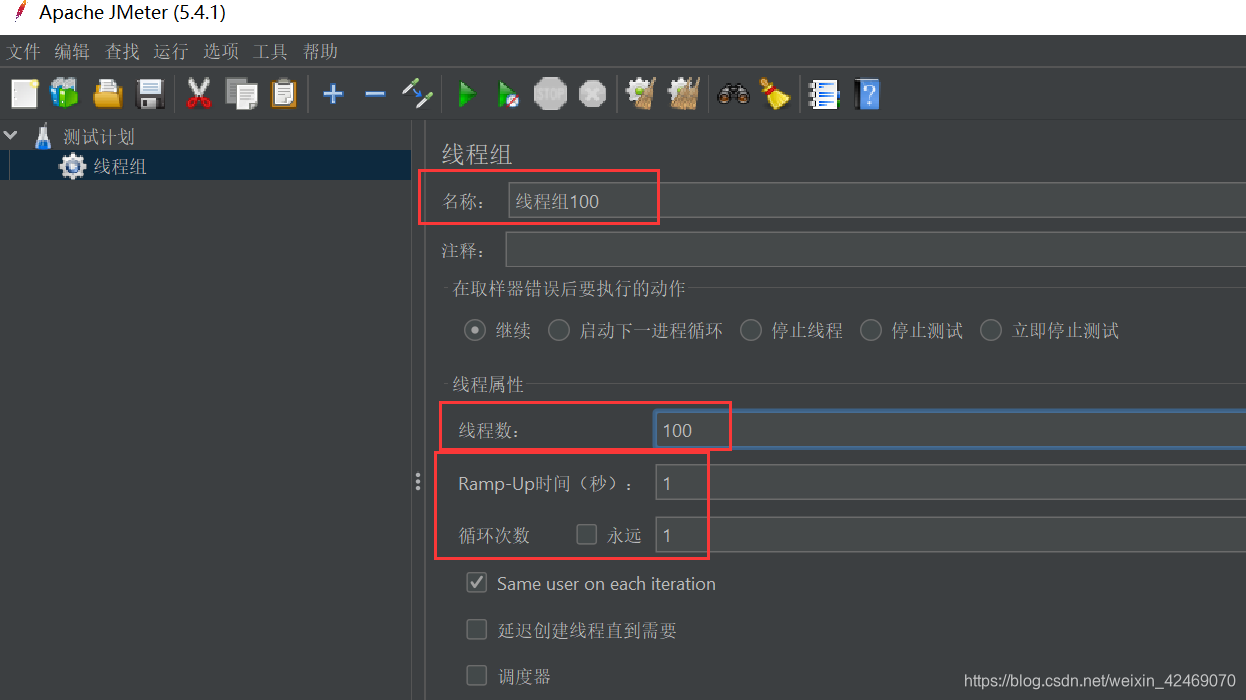
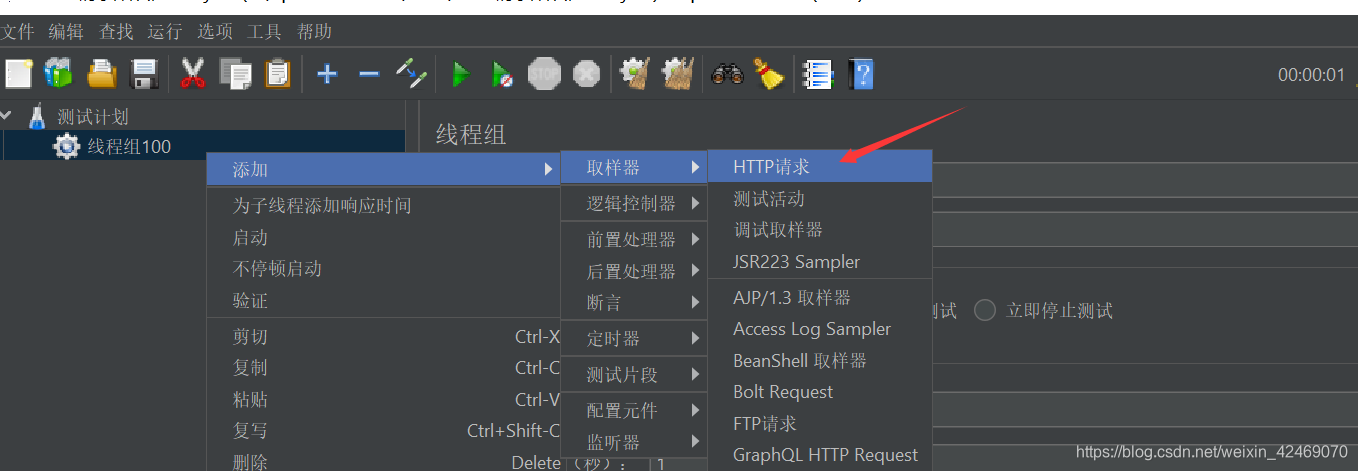
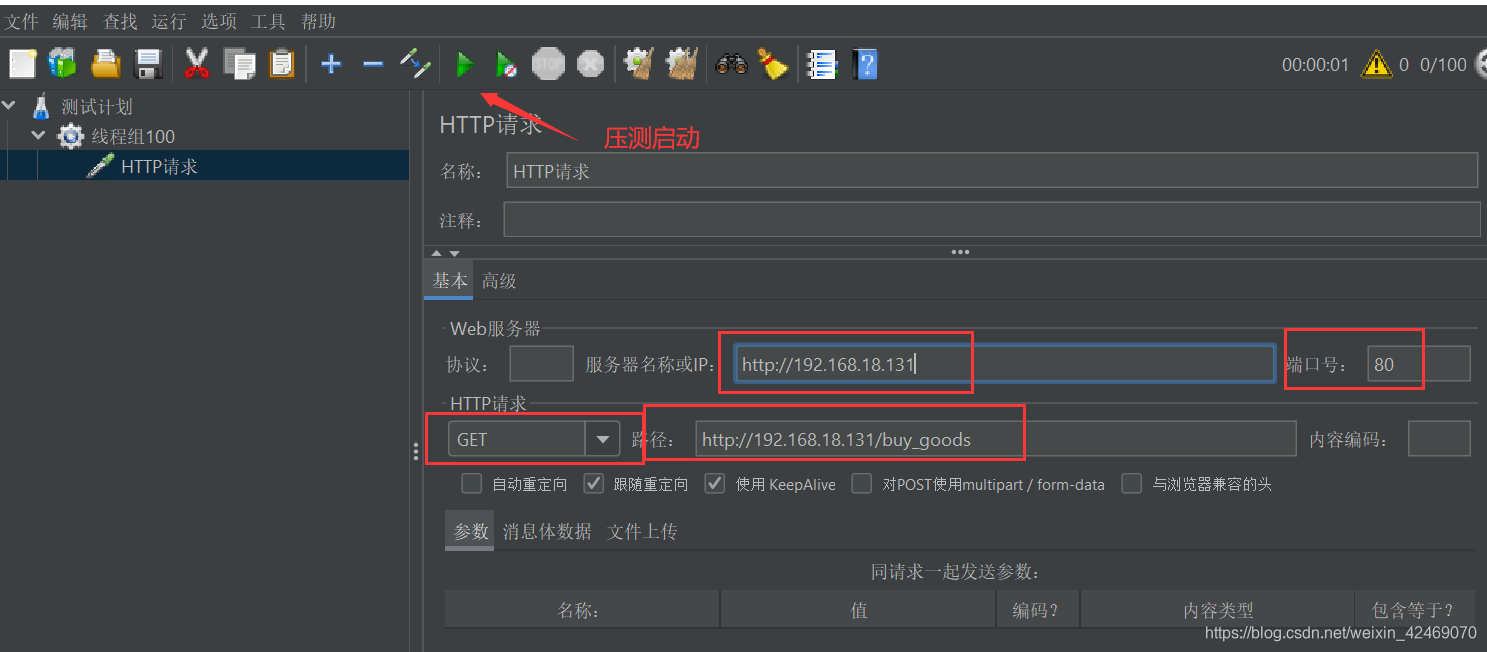
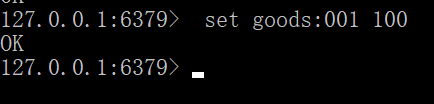
设置reids缓存一百:
清空服务控制台日记:
jmeter压测:
查看后台日记:
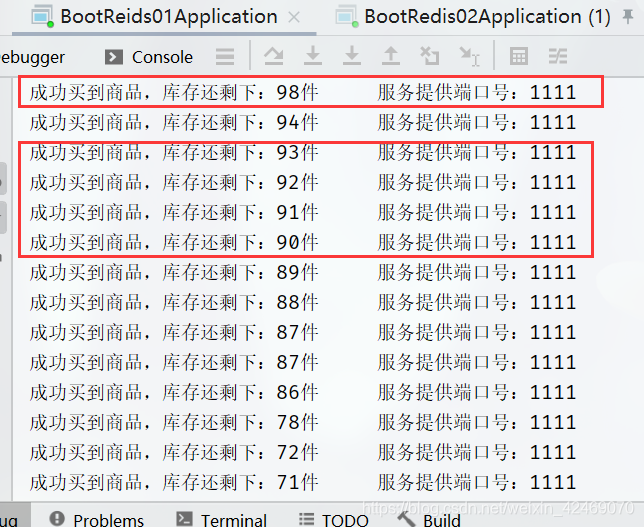

分布式部署后,单机锁还是出现超卖现象。
解决:
Redis具有极高的性能,且其命令对分布式锁支持友好,借助 SET 命令即可实现加锁处理。
SET
EXseconds – Set the specified expire time, in seconds.PXmilliseconds – Set the specified expire time, in milliseconds.NX– Only set the key if it does not already exist.XX– Only set the key if it already exist.

修改2.0版本为3.0版本 + redis分布式锁setnx
@RestController
public class GoodController {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Value("${server.port}")
private String serverPort;
public static final String REDIS_LOCK = "zzpLock";
@GetMapping("/buy_goods")
public String buy_goods(){
String value = UUID.randomUUID() + Thread.currentThread().getName(); // 唯一固定标识
// reids setNX 命令
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(REDIS_LOCK, value);// NX -- Only set the key if it does not already exist.
if(!flag){
return "抢锁失败";
}
// get key === 查看库存的数量够不够
String result = stringRedisTemplate.opsForValue().get("goods:001");
int goodsNumber = result == null ? 0 : Integer.valueOf(result);
if(goodsNumber > 0){
int realNumber = goodsNumber -1;
stringRedisTemplate.opsForValue().set("goods:001",String.valueOf(realNumber));
//删锁
stringRedisTemplate.delete(REDIS_LOCK);
System.out.println("成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort);
return "成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort;
}else {
System.out.println("商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort);
}
return "商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort;
}
}
redis分布式锁03
继续上一节
问题:如果出现异常的话,可能无法释放锁,必须要在代码层面finally释放锁
修改3.0版本 为 4.0版本
加上try ... finally.. 代码块
@RestController
public class GoodController {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Value("${server.port}")
private String serverPort;
public static final String REDIS_LOCK = "zzpLock";
@GetMapping("/buy_goods")
public String buy_goods(){
String value = UUID.randomUUID() + Thread.currentThread().getName(); // 唯一固定标识
try {
// reids setNX 命令
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(REDIS_LOCK, value);// NX -- Only set the key if it does not already exist.
if(!flag){
return "抢锁失败";
}
// get key === 查看库存的数量够不够
String result = stringRedisTemplate.opsForValue().get("goods:001");
int goodsNumber = result == null ? 0 : Integer.valueOf(result);
if(goodsNumber > 0){
int realNumber = goodsNumber -1;
stringRedisTemplate.opsForValue().set("goods:001",String.valueOf(realNumber));
System.out.println("成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort);
return "成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort;
}else {
System.out.println("商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort);
}
return "商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort;
}finally {
//删锁
stringRedisTemplate.delete(REDIS_LOCK);
}
}
}
另一个极端问题:
部署了微服务jar包的机器挂了,代码层面根本没有走到finally这块,没办法保证解锁,这个key没有被删除,需要加入一个过期时间限定key。
解决:
修改4.0版本 为 5.0版本
需要对lockKey有过期时间的设定:stringRedisTemplate.expire(REDIS_LOCK,10L, TimeUnit.SECONDS);
@RestController
public class GoodController {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Value("${server.port}")
private String serverPort;
public static final String REDIS_LOCK = "zzpLock";
@GetMapping("/buy_goods")
public String buy_goods(){
String value = UUID.randomUUID() + Thread.currentThread().getName(); // 唯一固定标识
try {
// reids setNX 命令
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(REDIS_LOCK, value);// NX -- Only set the key if it does not already exist.
// 设置10秒后过期
stringRedisTemplate.expire(REDIS_LOCK,10L, TimeUnit.SECONDS);
if(!flag){
return "抢锁失败";
}
// get key === 查看库存的数量够不够
String result = stringRedisTemplate.opsForValue().get("goods:001");
int goodsNumber = result == null ? 0 : Integer.valueOf(result);
if(goodsNumber > 0){
int realNumber = goodsNumber -1;
stringRedisTemplate.opsForValue().set("goods:001",String.valueOf(realNumber));
System.out.println("成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort);
return "成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort;
}else {
System.out.println("商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort);
}
return "商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort;
}finally {
//删锁
stringRedisTemplate.delete(REDIS_LOCK);
}
}
}
redis分布式锁04
继续上一节
问题:
设置key+过期时间分开了,必须要合并成一行具备原子性。
解决:
修改5.0版本 为 6.0版本
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(REDIS_LOCK, value,10L, TimeUnit.SECONDS);
@RestController
public class GoodController {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Value("${server.port}")
private String serverPort;
public static final String REDIS_LOCK = "zzpLock";
@GetMapping("/buy_goods")
public String buy_goods(){
String value = UUID.randomUUID() + Thread.currentThread().getName(); // 唯一固定标识
try {
// reids setNX 命令 并且 设置10秒后过期
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(REDIS_LOCK, value,10L, TimeUnit.SECONDS);// NX -- Only set the key if it does not already exist.
if(!flag){
return "抢锁失败";
}
// get key === 查看库存的数量够不够
String result = stringRedisTemplate.opsForValue().get("goods:001");
int goodsNumber = result == null ? 0 : Integer.valueOf(result);
if(goodsNumber > 0){
int realNumber = goodsNumber -1;
stringRedisTemplate.opsForValue().set("goods:001",String.valueOf(realNumber));
System.out.println("成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort);
return "成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort;
}else {
System.out.println("商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort);
}
return "商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort;
}finally {
//删锁
stringRedisTemplate.delete(REDIS_LOCK);
}
}
}
业务层面问题:
假如A线程处理时间超过10秒,但是redis超过10秒就把锁删除了,然后B线程进来了,但A线程还在运行,这时候A线程处理完后把B线程的锁删除了,这就会产生很可怕的现象。(张冠李戴,删除了别人的锁)
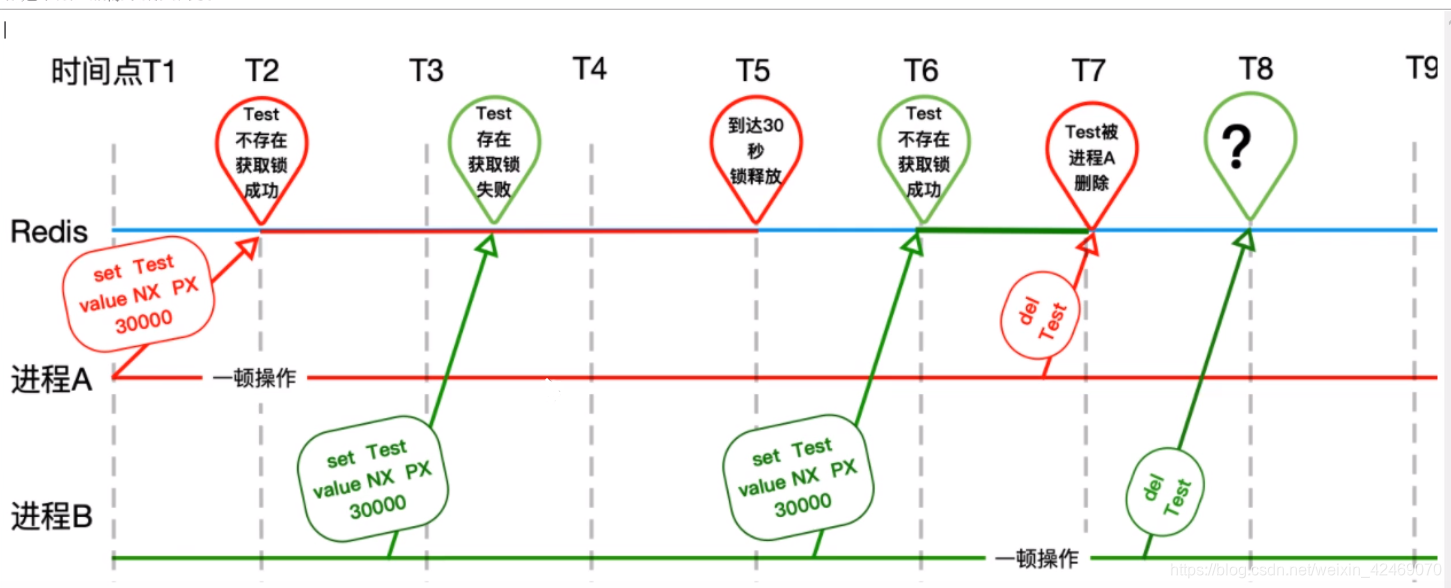
解决:
只能自己删除自己的,不许动别人的。stringRedisTemplate.opsForValue().get(REDIS_LOCK).equals(value)
修改6.0版本 为 7.0版本
@RestController
public class GoodController {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Value("${server.port}")
private String serverPort;
public static final String REDIS_LOCK = "zzpLock";
@GetMapping("/buy_goods")
public String buy_goods(){
String value = UUID.randomUUID() + Thread.currentThread().getName(); // 唯一固定标识
try {
// reids setNX 命令 并且 设置10秒后过期
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(REDIS_LOCK, value,10L, TimeUnit.SECONDS);// NX -- Only set the key if it does not already exist.
if(!flag){
return "抢锁失败";
}
// get key === 查看库存的数量够不够
String result = stringRedisTemplate.opsForValue().get("goods:001");
int goodsNumber = result == null ? 0 : Integer.valueOf(result);
if(goodsNumber > 0){
int realNumber = goodsNumber -1;
stringRedisTemplate.opsForValue().set("goods:001",String.valueOf(realNumber));
System.out.println("成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort);
return "成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort;
}else {
System.out.println("商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort);
}
return "商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort;
}finally {
if(stringRedisTemplate.opsForValue().get(REDIS_LOCK).equals(value)){
//删锁
stringRedisTemplate.delete(REDIS_LOCK);
}
}
}
}
redis分布式锁05
继续上一节
问题:
finally块的判断 + del删除操作不是原子性的

解决:
1、使用redis自身的事务
Redis事务复习:
事务介绍
- Redis的事务是通过MULTI、EXEC、DISCARD和WATCH 这四个命令完成。
- Redis的单个命令都是 原子性 的,所以这里确保事务性的对象是命令集合
- Redis将命令集合序列化确保处于一个事务的命令集合连续且不被打断 的执行
- Redis 不支持回滚 的操作
相关命令
-
MULTI
注: 用于标记事务块的开始
Redis会将后续的命令逐个放入队列中,然后使用 EXEC命令 原子化地执行这个命令序列。
语法: MULTI -
EXEC
在一个 事务中执行所有先前放入队列的命令, 然后恢复正常的连接状态。
语法: EXEC -
DISCARD
清除所有先前在一个事务中放入队列的命令, 然后恢复正常的连接状态。
语法: DISCARD -
WATCH
当某个 事务需要按条件执行时, 就要使用这个命令将给定的 键设置为受监控的 状态
语法: WATCH key [key …]
注:该命令可以实现redis的 乐观锁 -
UNWATCH
清除所有先前为一个事务监控的键。
语法: UNWATCH
MULTI + EXEC 命令(等于批处理)

尽管先把k1设置为 abc 但后来 执行 EXEC 命令 会覆盖k1的值
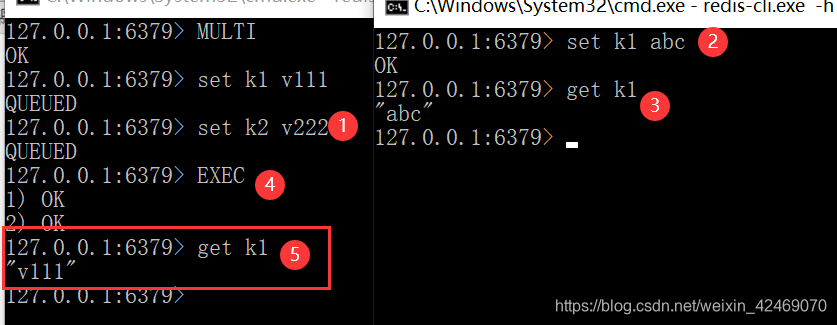
redis分布式锁06
继续上一节
WATCH 命令 实现redis的 乐观锁 不会覆盖已经修改过的数据
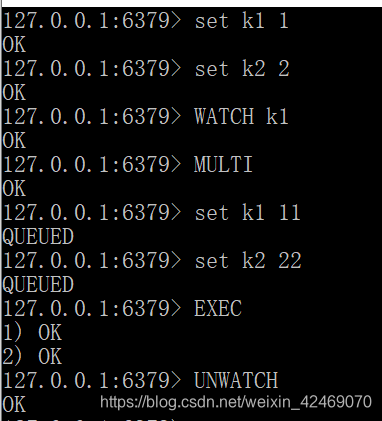
WATCH 命令实现redis的 乐观锁 不会覆盖已经修改过的数据
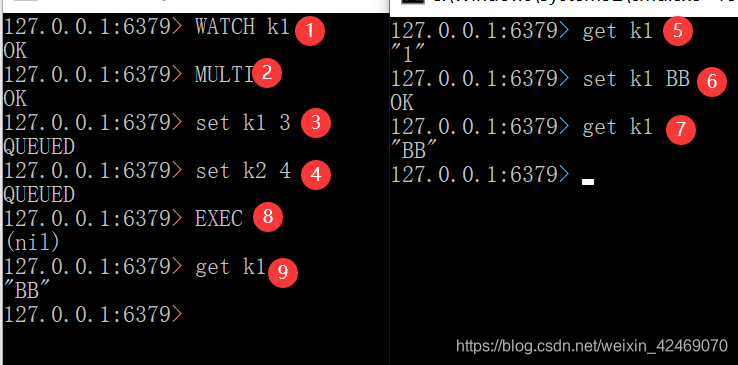
解决之一:
1、使用redis自身的事务
修改7.0版本 为 8.1版本
@RestController
public class GoodController {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Value("${server.port}")
private String serverPort;
public static final String REDIS_LOCK = "zzpLock";
@GetMapping("/buy_goods")
public String buy_goods(){
String value = UUID.randomUUID() + Thread.currentThread().getName(); // 唯一固定标识
try {
// reids setNX 命令 并且 设置10秒后过期
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(REDIS_LOCK, value,10L, TimeUnit.SECONDS);// NX -- Only set the key if it does not already exist.
if(!flag){
return "抢锁失败";
}
// get key === 查看库存的数量够不够
String result = stringRedisTemplate.opsForValue().get("goods:001");
int goodsNumber = result == null ? 0 : Integer.valueOf(result);
if(goodsNumber > 0){
int realNumber = goodsNumber -1;
stringRedisTemplate.opsForValue().set("goods:001",String.valueOf(realNumber));
System.out.println("成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort);
return "成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort;
}else {
System.out.println("商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort);
}
return "商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort;
}finally {
while (true){
stringRedisTemplate.watch(REDIS_LOCK);
if(stringRedisTemplate.opsForValue().get(REDIS_LOCK).equals(value)){
stringRedisTemplate.setEnableTransactionSupport(true);
stringRedisTemplate.multi();
stringRedisTemplate.delete(REDIS_LOCK);
List<Object> exec = stringRedisTemplate.exec();
if(exec == null){
continue;
}
}
stringRedisTemplate.unwatch();
break;
}
}
}
}
redis分布式锁07
继续上一节
解决之一:
1、使用lua脚本
RedisUtils类:
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class RedisUtils {
private static JedisPool jedisPool;
static {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(20);
jedisPoolConfig.setMaxIdle(20);
jedisPool = new JedisPool(jedisPoolConfig,"127.0.0.1",6379);
}
public static Jedis getJedis() throws Exception {
if(null != jedisPool){
return jedisPool.getResource();
}
throw new Exception("JedisPool is not ok");
}
}
Redis调用Lua脚本通过eval命令保证代码执行的原子性
修改8.1版本 为 8.2版本
@RestController
public class GoodController {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Value("${server.port}")
private String serverPort;
public static final String REDIS_LOCK = "zzpLock";
@GetMapping("/buy_goods")
public String buy_goods() throws Exception {
String value = UUID.randomUUID() + Thread.currentThread().getName(); // 唯一固定标识
try {
// reids setNX 命令 并且 设置10秒后过期
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(REDIS_LOCK, value,10L, TimeUnit.SECONDS);// NX -- Only set the key if it does not already exist.
if(!flag){
return "抢锁失败";
}
// get key === 查看库存的数量够不够
String result = stringRedisTemplate.opsForValue().get("goods:001");
int goodsNumber = result == null ? 0 : Integer.valueOf(result);
if(goodsNumber > 0){
int realNumber = goodsNumber -1;
stringRedisTemplate.opsForValue().set("goods:001",String.valueOf(realNumber));
System.out.println("成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort);
return "成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort;
}else {
System.out.println("商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort);
}
return "商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort;
}finally {
Jedis jedis = RedisUtils.getJedis();
String scrpit = "if redis.call(\"get\",KEYS[1]) == ARGV[1]\n" +
"then\n" +
" return redis.call(\"del\",KEYS[1])\n" +
"else\n" +
" return 0\n" +
"end";
try
{
Object eval = jedis.eval(scrpit, Collections.singletonList(REDIS_LOCK), Collections.singletonList(value));
if("1".equals(eval.toString())){
System.out.println("del reids lock ok");
}else {
System.err.println("del reids lock error");
}
}finally {
if(jedis != null){
jedis.close();
}
}
}
}
}
redis分布式锁08
继续上一节
确保redisLock过期时间大于业务执行时间的问题 — Redis分布式锁如何续期?
集群 + CAP对比ZooKeeper
对比ZooKeeper,重点,
CAP模式:
-
RedisAP
redis异步复制造成的锁丢失,比如:主节点没来的及把刚刚set进来这条数据给从节点,就挂了。 -
ZooKeeperCP
CAP:
- C:Consistency(强一致性)
- A:Availability(可用性)
- P:Partition tolerance(分区容错性)
综上所述:
Redis集群环境下,我们自己写的也不OK,直接上RedLock 之 Redisson 落地实现
redis分布式锁09
继续上一节
RedisConfig类添加配置Redisson:
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Serializable> redisTemplate(LettuceConnectionFactory connectionFactory){
RedisTemplate<String, Serializable> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(connectionFactory);
// 序列化
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
return redisTemplate;
}
@Bean
public Redisson redisson(){
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379").setPassword("123456").setDatabase(0);
return (Redisson)Redisson.create(config);
}
}
解决之一:
使用Redisson
修改8.2版本 为 9.0版本
@RestController
public class GoodController {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Value("${server.port}")
private String serverPort;
public static final String REDIS_LOCK = "zzpLock";
@Autowired
private Redisson redisson;
@GetMapping("/buy_goods")
public String buy_goods() throws Exception {
RLock redissonLock = redisson.getLock(REDIS_LOCK);
redissonLock.lock();
try {
// get key === 查看库存的数量够不够
String result = stringRedisTemplate.opsForValue().get("goods:001");
int goodsNumber = result == null ? 0 : Integer.valueOf(result);
if(goodsNumber > 0){
int realNumber = goodsNumber -1;
stringRedisTemplate.opsForValue().set("goods:001",String.valueOf(realNumber));
System.out.println("成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort);
return "成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort;
}else {
System.out.println("商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort);
}
return "商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort;
}finally {
redissonLock.unlock();
}
}
}
测试:
启动nginx,启动boot-reids01、boot-reids02服务,设置reids的key:goods:001的值为100
使用 JMeter压测:
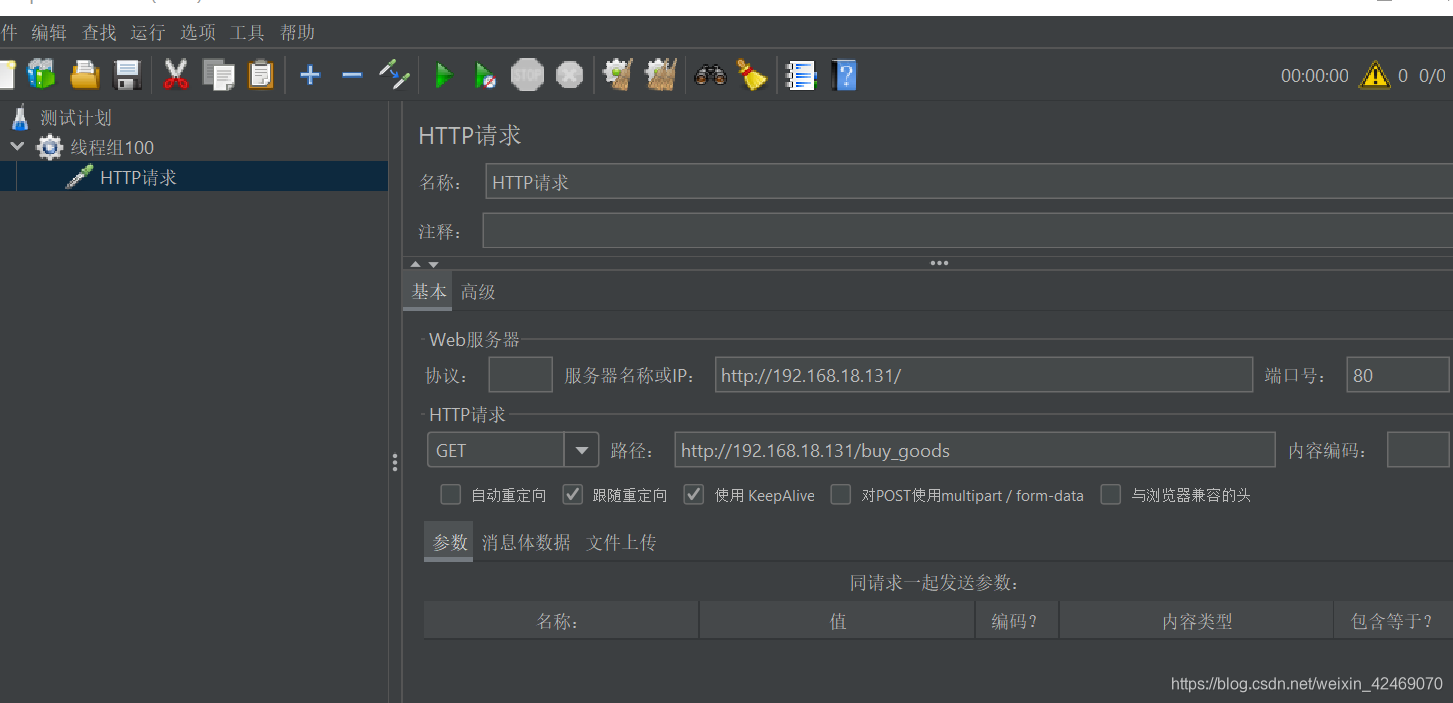
查看后台日记:
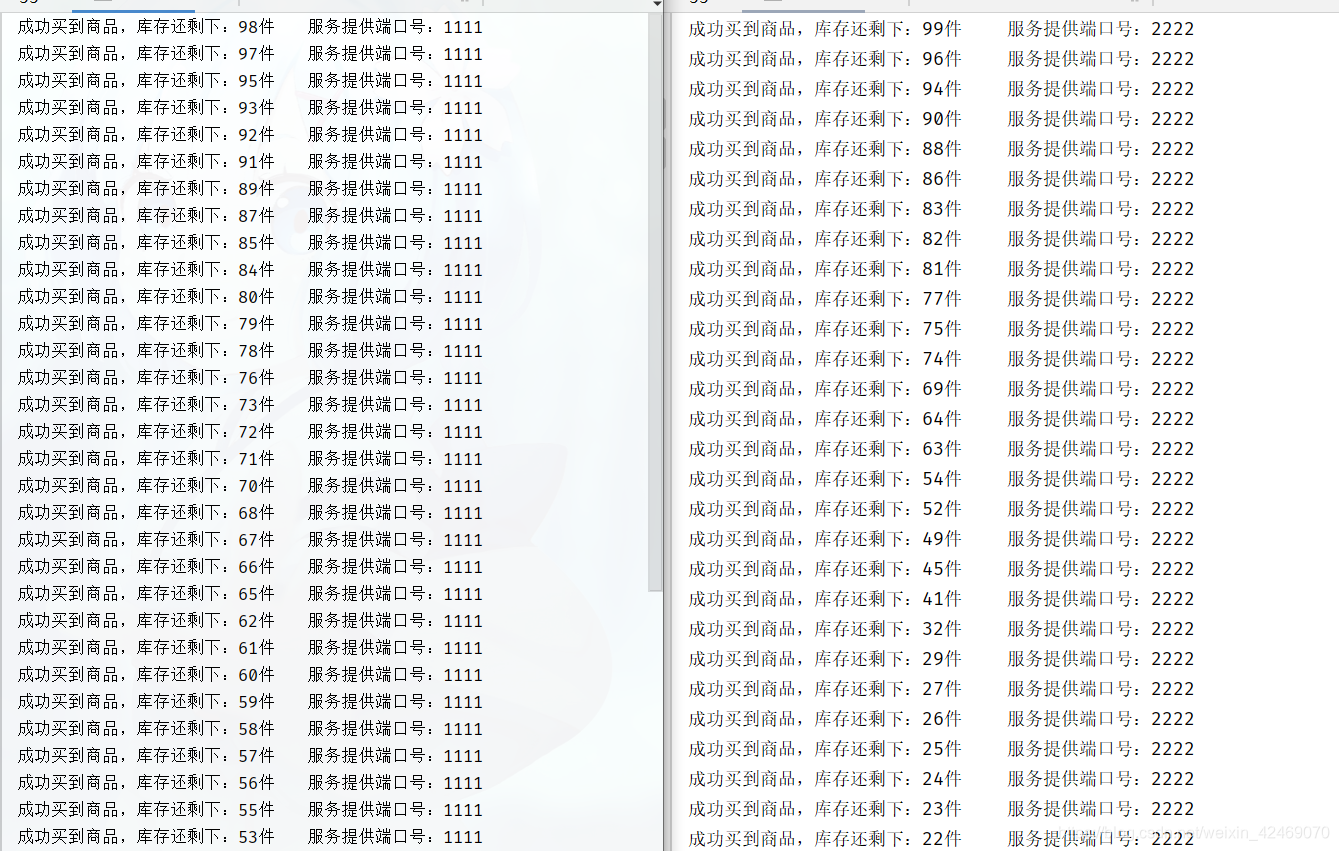
redis分布式锁10
目前到这里感觉很完美了
但是在解锁那里还得再完善一点,否则可能会出现attempt to unlock lock,not loked by current thread by node id
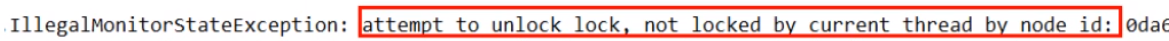
修改9.0版本 为 9.1版本
@RestController
public class GoodController {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Value("${server.port}")
private String serverPort;
public static final String REDIS_LOCK = "zzpLock";
@Autowired
private Redisson redisson;
@GetMapping("/buy_goods")
public String buy_goods() throws Exception {
RLock redissonLock = redisson.getLock(REDIS_LOCK);
redissonLock.lock();
try {
// get key === 查看库存的数量够不够
String result = stringRedisTemplate.opsForValue().get("goods:001");
int goodsNumber = result == null ? 0 : Integer.valueOf(result);
if(goodsNumber > 0){
int realNumber = goodsNumber -1;
stringRedisTemplate.opsForValue().set("goods:001",String.valueOf(realNumber));
System.out.println("成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort);
return "成功买到商品,库存还剩下:" + realNumber + "件 \t 服务提供端口号:" + serverPort;
}else {
System.out.println("商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort);
}
return "商品已经售完/活动结束/调用超时,欢迎下次光临" + "\t服务提供端口" + serverPort;
}finally {
if(redissonLock.isLocked() && redissonLock.isHeldByCurrentThread()){
redissonLock.unlock();
}
}
}
}
redis分布式锁总结回顾
单机版添加synchronized,oK,上分布式不ok
nginx分布式微服务单机锁不行
取消单机版synchronized锁,上reids分布锁setnx
要求:
只加了锁,没有释放锁,出异常的话,可能无法释放锁,必须要在代码层面finally释放锁
特殊情况下:
宕机了,部署了微服务代码层面根本没有走到finally这块,没办法保证解锁,这个key没有被删除,
需要有lockKey的过期时间设定
为redis的分布式锁key,增加过期时间,此外,还必须要 setnx+ 过期时间必须同一行
必须规定只能自己删除自己的锁,不能把别人的锁删除了,防止张冠李戴,1删2,2删3…
redis集群环境下,我们自己写的也不oK直接上 RedLock 之 Redisson 落地实现
redis内存调整默认查看
redis默认内存多少?在哪里查看?如何设置修改?
查看redis最大占用内存;
查看配置文件:
window系统:redis.windows.conf 文件
Linux系统:redis.conf 文件
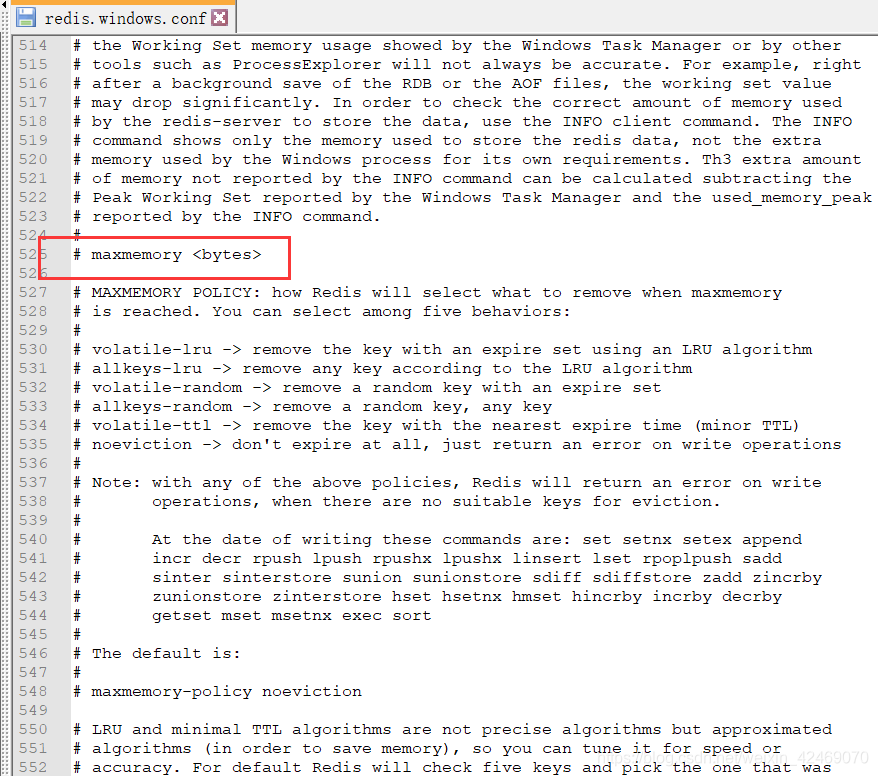
# maxmemory <bytes>
打开配置文件redis.windows.conf的 maxmemory 参数,maxmemory是bytes字节类型,注意转换。
如果不设置最大内存大小或者设置最大内存大小为0,在64位操作系统下不限制内存大小,在32位操作系统下最多使用3GB内存
一般生产上你如何配置?
一般推荐Redis设置内存为最大物理内存的四分之三
如何修改redis内存设置?
-
修改配置文件
比如配置1G:1KB=1024 bytes 1MB=1024 KB 1GB=1024 MB
1G=1024 * 1024 * 1024=1073741824 bytes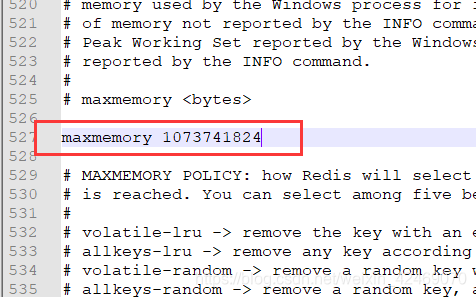
-
通过命令修改
config set maxmemory 1024
config get maxmemory
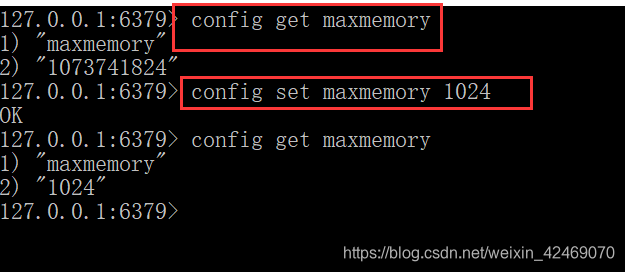
什么命令查看redis内存使用情况?
info memory
redis打满内存OOM
Redis真要打满了会怎么样?
如果Redis内存使用超出了设置的最大值会怎样?
改改配置,故意把最大值设为1个byte试试
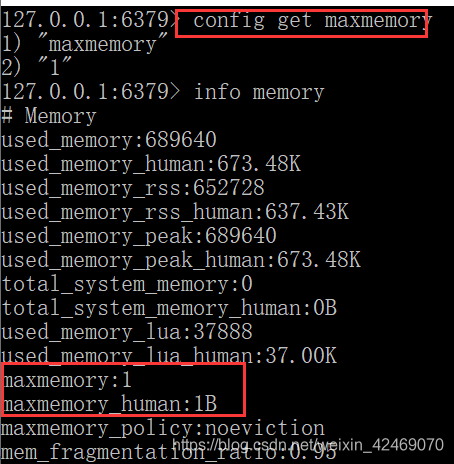

(error) OOM command not allowed when used memory > 'maxmemory'.
结论:
设置 maxmemory 的选项,假如 redis 内存使用达到了上限
没有加上过期时间就会导致数据写满 maxmemory 为了避免类似情况,引出下一节内存淘汰策略
redis内存淘汰策略
继续上一节
往redis里写的数据是怎么没了的?
# MAXMEMORY POLICY: how Redis will select what to remove when maxmemory
# is reached. You can select among five behaviors:
# volatile-lru -> remove the key with an expire set using an LRU algorithm
# allkeys-lru -> remove any key according to the LRU algorithm
# volatile-random -> remove a random key with an expire set
# allkeys-random -> remove a random key, any key
# volatile-ttl -> remove the key with the nearest expire time (minor TTL)
# noeviction -> don’t expire at all, just return an error on write operations
#MAXMEMORY策略:当MAXMEMORY
#到达。您可以从五种行为中选择:
#volatile lru->使用lru算法删除带有expire集的密钥
#allkeys lru->根据lru算法删除任何密钥
#volatile random->删除带有过期集的随机键
#allkeys random->删除随机键,任意键
#volatile ttl->删除过期时间最近的密钥(minor ttl)
#noeviction->完全不过期,只返回写操作错误
默认maxmemory策略是:noeviction
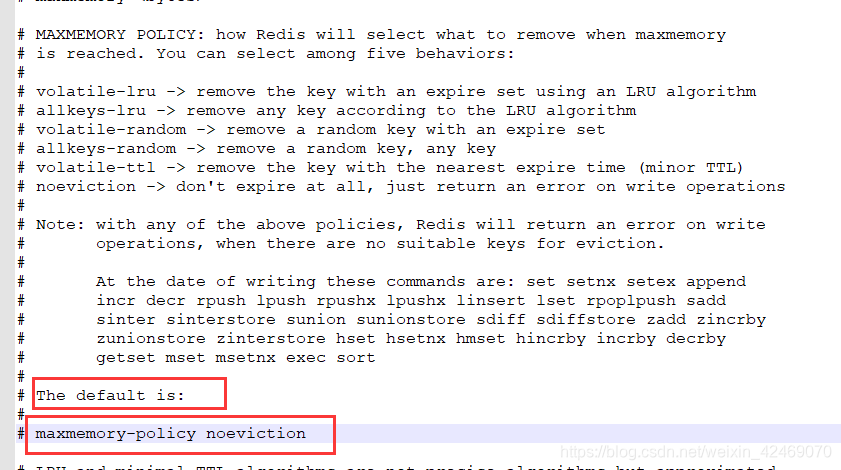
redis过期键的删除策略:
如果一个键是过期的,那它到了过期时间之后是不是马上就从内存中被被删除呢??
如果回答yes,你自己走还是面试官送你?
如果不是,那过期后到底什么时候被删除呢??是个什么操作?
三种不同的删除策略:
- 定时删除 – 总结: 对CPU不友好,用处理器性能换取存储空间(拿时间换空间)
- 惰性删除 – 总结: 对memory不友好,用存储空间换取处理器性能(拿空间换时间)
- 上面两种方案都走极端 – 引用 定期删除
定时删除:
Redis 不可能时时刻刻遍历所有被设置了生存时间的key,来检测数据是否已经到达过期时间,然后对它进行删除。
立即删除能保证内存中数据的最大新鲜度,因为它保证过期键值会在过期后马上被删除,其所占用的内存也会随之释放。但是立即删除对cpu是最不友好的。因为删除操作会占用cpu的时间,如果刚好碰上了cpu很忙的时候,比如正在做交集或排序等计算的时候,就会给cpu造成额外的压力,让CPU心累,时时需要删除,忙死。。。
这会产生大量的性能消耗,同时也会影响数据的读取操作。
惰性删除:
数据到达过期时间,不做处理。等下次访问该数据时,
如果未过期,返回数据;
发现已过期,删除,返回不存在。
惰性删除策略的缺点是,它对内存是最不友好的。
如果一个键已经过期,而这个键又仍然保留在数据库中,那么只要这个过期键不被删除,它所占用的内存就不会释放。
在使用惰性删除策略时,如果数据库中有非常多的过期键,而这些过期键又恰好没有被访问到的话,那么它们也许永远也不会被删除(除非用户手动执行FLUSHDB),我们甚至可以将这种情况看作是一种内存泄漏 – 无用的垃圾数据占用了大量的内存,而服务器却不会自己去释放它们,这对于运行状态非常依赖于内存的Redis服务器来说,肯定不是一个好消息
定期删除
定期删除策略是前两种策略(定时删除和惰性删除)的折中:
定期删除策略每隔一段时间执行一次删除过期键操作,并通过限制删除操作执行的时长和频率来减少删除操作对CPU时间的影响。
周期性轮询redis库中的时效性数据,采用随机抽取的策略,利用过期数据占比的方式控制删除频度
特点1:CPU性能占用设置有峰值,检测频度可自定义设置
特点2:内存压力不是很大,长期占用内存的冷数据会被持续清理
总结:周期性抽查存储空间(随机抽查,重点抽查)
举例:
redis默认每个100ms检查,是否有过期的key,有过期key则删除。注意:redis不是每隔100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis直接进去ICU)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
定期删除策略的难点是确定删除操作执行的时长和频率:如果删除操作执行得太频繁,或者执行的时间太长,定期删除策略就会退化成定时删除策略,以至于将CPU时间过多地消耗在删除过期键上面。如果删除操作执行得太少,或者执行的时间太短,定期删除策略又会和惰性删除束略一样,出现浪费内存的情况。因此,如果采用定期删除策略的话,服务器必须根据情况,合理地设置删除操作的执行时长和执行频率。
上述步骤都过堂了,还有漏洞吗?
1、定期删除时,从来没有被抽查到
2、惰性删除时,也从来没有被点中使用过
上述2步骤 ====>大量过期的key堆积在内存中,导致redis内存空间紧张或者很快耗尽
必须要有一个更好的兜底方案…
内存淘汰策略(Redis 6.0.8+版本 )
noeviction:不会驱逐任何keyallkeys-lru:对所有key使用LRU算法进行删除volatile-lru:对所有设置了过期时间的key使用LRU算法进行删除allkeys-random:对所有key随机删除volatile-random:对所有设置了过期时间的key随机删除volatile-ttl:删除马上要过期的keyallkeys-lfu:对所有key使用LFU算法进行删除volatile-lfu:对所有设置了过期时间的key使用LFU算法进行删除
上面总结:
-
2*4得8
-
2个维度
- 过期键中筛选
- 所有键中筛选
-
4个方面
- LRU
- LFU
- random
- ttl(Time To Live)
-
8个选项
如何配置,修改:
-
命令
config set maxmemory-policy allkeys-lru
config get maxmemory-policy
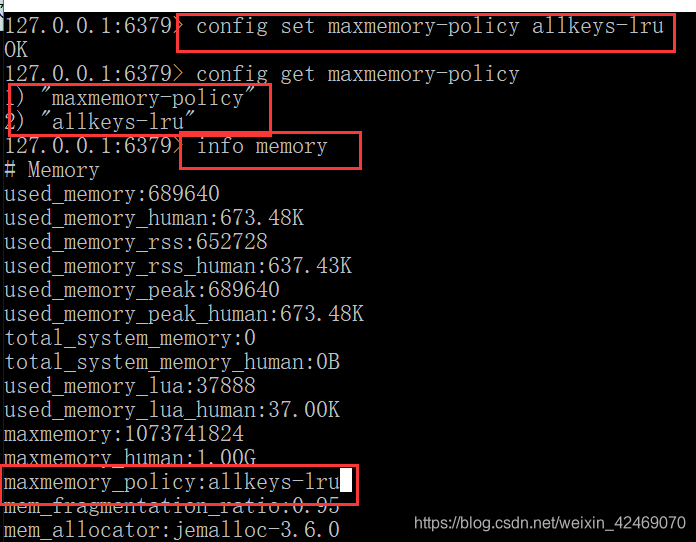
-
配置文件
配置文件redis.conf的maxmemory-policy参数maxmemory-policy allkeys-lru

lru算法简介
LRU是什么?
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,
选择最近最久未使用的数据予以淘汰。
算法来源:
力扣
lru的思想
设计思想:
1、所谓缓存,必须要有读 + 写两个操作,按照命中率的思路考虑,写操作 + 读操作时间复杂度都需要为O(1)
2、特性要求
-
①必须要有顺序之分,一区分最近使用的和很久没有使用的数据排序。
-
②写和读操作一次搞定。
-
③如果容量(坑位)满了要删除最不长用的数据,每次新访问还要把新的数据插入到队头(按照业务你自己设定左右哪一边是队头)
查找快、插入快、删除快,且还需要先后排序---------->什么样的数据结构可以满足这个问题?
你是否可以在 O(1) 时间复杂度内完成这两种操作?
如果一次就可以找到,你觉得什么数据结构最合适?
LRU的算法核心是哈希链表
本质就是 HashMap + DoubleLinkedList
时间复杂度是 O(1),哈希表 + 双向链表的结合体
编码手写如何实现LRU:
巧用LinkedHashMap完成lru算法
继续上一节
案例01:
查考 LinkedHashMap
依赖 JDK
public class LRUCacheDemo<K,V> extends LinkedHashMap<K,V>{
//缓存坑位
private int capacity;
/**
* accessOrder the ordering mode -
* <tt>true</tt> for access-order,
* <tt>false</tt> for insertion-order
*
* @param capacity
*/
public LRUCacheDemo(int capacity) {
super(capacity,0.75F,false);
this.capacity = capacity;
}
/**
* 判断 队列的数量是否大于缓存设置
* @param eldest
* @return
*/
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return super.size() > capacity;
}
public static void main(String[] args) {
LRUCacheDemo lruCacheDemo = new LRUCacheDemo(3);
lruCacheDemo.put(1,"a");
lruCacheDemo.put(2,"b");
lruCacheDemo.put(3,"c");
System.out.println(lruCacheDemo.keySet());
lruCacheDemo.put(4,"d");
System.out.println(lruCacheDemo.keySet());
lruCacheDemo.put(3,"c");
System.out.println(lruCacheDemo.keySet());
lruCacheDemo.put(3,"c");
System.out.println(lruCacheDemo.keySet());
lruCacheDemo.put(3,"c");
System.out.println(lruCacheDemo.keySet());
lruCacheDemo.put(5,"e");
System.out.println(lruCacheDemo.keySet());
}
}
注: accessOrder=true/false 两者的顺序是不一样的
手写LRU
案例2:
不依赖 JDK
public class LRUCacheDemo1 {
// 思路:map 负责查找,构建一个虚拟的双向链表,它里面安装的就是一个个Node 节点,作为载体。
// 第1步:构造一个Node节点,作为数据的载体
class Node<K,V>{
K key;
V value;
Node<K,V> prev;
Node<K,V> next;
public Node(){
this.prev = this.next = null;
}
public Node(K key, V value){
this.key = key;
this.value = value;
this.prev = this.next = null;
}
}
// 第2步:构造一个虚拟的双向链表,里面安防的就是我们的Node
class DoubleLinkedList<K,V>{
Node<K,V> head;
Node<K,V> tail;
// 第2.1步:构造方法
public DoubleLinkedList(){
head = new Node<>();
tail = new Node<>();
head.next = tail;
tail.prev = head;
}
// 第2.2步:添加头
public void addHead(Node<K,V> node){
node.next = head.next;
node.prev = head;
head.next.prev = node;
head.next = node;
}
// 第2.3步:删除节点
public void removeNode(Node<K,V> node){
node.next.prev = node.prev;
node.prev.next = node.next;
node.prev = null;
node.next = null;
}
// 第2.4步:获取最后一个节点
public Node getLast(){
return tail.prev;
}
}
private int cacheSize;
Map<Integer,Node<Integer,Integer>> map;
DoubleLinkedList<Integer,Integer> doubleLinkedList;
public LRUCacheDemo1(int cacheSize){
this.cacheSize = cacheSize;// 坑位
map = new HashMap<>();// 查找
doubleLinkedList = new DoubleLinkedList<>();
}
public int get(int key){
if(!map.containsKey(key)){
return -1;
}
Node<Integer, Integer> node = map.get(key);
doubleLinkedList.removeNode(node);
doubleLinkedList.addHead(node);
return node.value;
}
// savaOrUpdate method
public void put(int key,int value){
if(map.containsKey(key)){ // update
Node<Integer, Integer> node = map.get(key);
node.value = value;
map.put(key,node);
doubleLinkedList.removeNode(node);
doubleLinkedList.addHead(node);
}else {
if(map.size() == cacheSize){ // 坑位满了
Node<Integer, Integer> lastNode = doubleLinkedList.getLast();
map.remove(lastNode.key);
doubleLinkedList.removeNode(lastNode);
}
// 最后是新增
Node<Integer, Integer> newNode = new Node<>(key,value);
map.put(key,newNode);
doubleLinkedList.addHead(newNode);
}
}
public static void main(String[] args) {
LRUCacheDemo1 lruCacheDemo = new LRUCacheDemo1(3);
lruCacheDemo.put(1,1);
lruCacheDemo.put(2,2);
lruCacheDemo.put(3,3);
System.out.println(lruCacheDemo.map.keySet());
lruCacheDemo.put(4,4);
System.out.println(lruCacheDemo.map.keySet());
lruCacheDemo.put(3,3);
System.out.println(lruCacheDemo.map.keySet());
lruCacheDemo.put(3,3);
System.out.println(lruCacheDemo.map.keySet());
lruCacheDemo.put(3,3);
System.out.println(lruCacheDemo.map.keySet());
lruCacheDemo.put(5,5);
System.out.println(lruCacheDemo.map.keySet());
}
}














 1682
1682











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









