







java零基础Ⅲ-- 4.Mysql基础
MySQL安装配置
MySQL数据库的安装和配置
mysql5.5 mysql5.6 mysql5.7(稳定) mysql8 更高版本
软件下载
Mysql5.7 地址: https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.19-winx64.zip
特别说明
如果安装过 Mysql 过程中,出错了或者想重新再来一把
sc delete mysql [删除已经安装好的 mysql:慎重]
安装步骤
说明注意: zip 安装文件是压缩文件,和 .exe 安装文件是一样的,要严格的按照
下面的步骤来执行
1、下载后会得到 zip 安装文件
2、解压的路径最好不要中文和空格
3、解压到 E:\xxxMysql\mysql-5.7.19-winx64 目录下【根据自己的情况来指定目录】
4、添加环境变量:电脑 - 属性 - 高级系统设置 - 环境变量,在 Path 环境增加 mysql 的安装目录 \bin 目录下,如下图

5、在 E:\mysql\mysql5.7 目录下创建 my.ini 文件,需要我们直接创建
[client]
# 客户端 3306端口
port=3306
# 字符集设置 utf8
default-character-set=utf8
[mysqld]
# mysqld服务
# 设置为自己 MYSQL 的安装目录
basedir=E:\mysql\mysql5.7\
# 设置为MYSQL的数据目录,这个目录是系统创建
datadir=E:\mysql\mysql5.7\data\
port=3306
character_set_server=utf8
# 跳过安全检查 不用密码可以登录
skip-grant-tables

6、使用管理员身份打开 cmd ,并切换到 E:\mysql\mysql5.7\bin 目录下,执行
mysqld -install
安装服务
7、初始化数据库:
mysqld --initialize-insecure --user=mysql
如果执行成功,会生成 data 目录
8、启动 mysql 服务:
net start mysql
【停止 mysql 服务指令:net stop mysql】
9、进入 mysql 管理终端:
mysql -u root -p 【当前 root 用户密码为 空】
10、修改 root 用户密码
user mysql; [代码使用数据库]
update user set authentication_string=password('123456') where user='root' and Host='localhost';
解读:上面的语句就是修改 root 用户密码为 123456
注意:在后面需要待 分号,回车即可执行该指令
执行:flush privileges; 刷新权限
退出:quit
11、修改 my.ini 文件,再次进入就会进行权限验证了
# 跳过安全检查,注销后,需要输入正确的用户名和密码
#skip-grant-tables
12、重写启动 mysql
net stop mysql
net start mysql
提示:该指令需要退出 mysql,在 Dos 下执行
13、再次进入 Mysql,输入正确的用户名和密码
mysql -u root -p
输入密码,进入 mysql

使用命令行窗口连接MYSQL数据库
1、mysql -h 主机ip -P 端口 -u 用户 -p密码
(1)-p密码:不要有空格
(2)-p后面没有写密码,回车后要求输入密码
(3)如果没有写 -h 主机,默认是本机
(4)如果没有写 -P 端口,默认是3306
(5)在实际工作中,3306端口号一般会修改
2、登录前,保证服务启动
启动mysql数据库常用方式:[Dos命令]
1、服务方式启动(界面)
2、net stop mysql服务名
3、net start mysql服务名

Navicat 安装和使用
介绍:图形化MySQL管理软件

下载&安装&使用
Navicat 地址:http://www.navicat.com.cn/products
Navicat 安装非常简单,基本上是傻瓜式安装:
1、下载后会得到 exe 安装文件
2、使用管理员身份安装
3、安装到 E:\xxx\Navicatxx 目录下【根据自己的情况来指定目录】
4、双击运行,配置连接

5、输入正确的密码即可登录 MySQL
SQLyog 安装和使用
介绍:图形化MySQL管理软件

下载&安装&使用
SQLyog 下载地址:https://sqlyog.en.softonic.com
SQLyog 安装非常简单,基本上是傻瓜式安装:
1、下载后会得到 SQLyog-13.1.8-0.x64Trial.exe 安装文件
2、使用管理员身份安装
3、安装 E:\SQLyog 目录下 【根据自己的情况来指定目录】
4、双击运行,配置连接

5、输入正确的密码即可登录 MySQL【保证mysql服务是运行状态】
数据库
数据库三层结构 - 破除MySQL秘密
1、所谓安装Mysql数据库,就是在主机安装一个数据库管理系统(DBMS),这个管理程序可以管理多个数据库。DBMS(database manage system)
2、一个数据库中可以创建多个表,以保存数据(信息)。
3、数据库管理系统(DBMS)、数据库和表的关系如下图所示:

示意图:

数据在数据库中的存储方式

SQL语句分类
- DDL:数据定义语句 [create 表,库…]
- DML:数据操作语句 [增加 insert,修改 update,删除 delete]
- DQL:数据查询语句 [select]
- DCL:数据控制语句 [管理数据库:比如用户权限 grant revoke]
创建数据库
CREATE DATABASE [IF NOT EXISTS] db_name
[create_specification [, carete_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name
1、CHARACTER SET:指定数据库采用的字符集,如果不知道字符集,默认utf8
2、COLLATE:指定数据库字符集的校对规则(常用 utf8_bin[区分大小写]、utf8_general_ci[不区分大小写] 注意默认是 utf_general_ci)

注意:数据库的字符为 gbk 是本地 my.ini 文件配置成 gbk
练习:
1、创建一个名称为 zzp_db01的数据库
2、创建一个使用 utf8字符集的 zzp_db02数据库
3、创建一个使用utf8字符集,并带校对规则的 zzp_db03数据库
# 演示数据库的操作
# 删除数据库指令
drop database zzp_db01;
# 1、创建一个名称为 zzp_db01的数据库
create database zzp_db01;
# 2、创建一个使用 utf8字符集的 zzp_db02数据库
create database zzp_db02 character set utf8;
# 3、创建一个使用utf8字符集,并带校对规则的 zzp_db03数据库
create database zzp_db03 character set utf8 collate utf8_bin;


校对规则 utf8_bin 区分大小写 默认 utf8_general_ci 不区分大小写 演示效果:
在zzp_db03 和 zzp_db02 数据库创建t1表,内容数据如下:
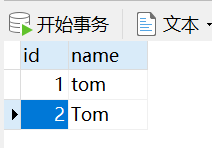
# 校对规则 utf8_bin 区分大小写 默认 utf8_general_ci 不区分大小写
# 下面是一条查询的sql,
# select 查询 * 代表所有字段 from 从哪个表
# where 从哪个字段 name = 'tom' 查询名字是 tom
select * from t1 where name = 'tom';
字符集 utf8_bin

字符集 utf8_general_ci

查看、删除数据库
显示数据库语句:
SHOW DATABASES
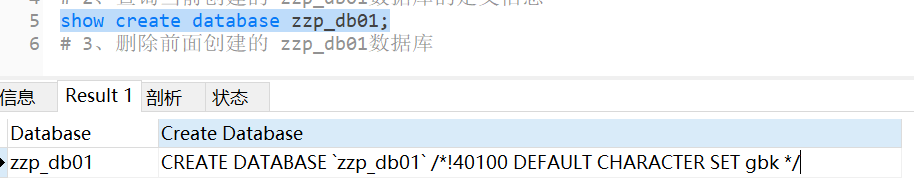
显示数据库创建语句:
SHOW CREATE DATABASE db_name;
数据库删除语句[慎用]:
DROP DATABASE [IF EXISTS] db_name;
练习:
1、查询当前数据库服务器中的所以数据库
2、查询当前创建的 zzp_db01数据库的定义信息
3、删除前面创建的 zzp_db01数据库
# 演示删除和查询数据库
# 1、查询当前数据库服务器中的所以数据库
show databases;
# 2、查询当前创建的 zzp_db01数据库的定义信息
show create database zzp_db01;
# 说明:在创建数据库,表的时候,为了规避关键字,可以使用反引号解决
#create database `create`;
# 3、删除前面创建的 zzp_db01数据库
drop database `create`;
drop database `zzp_db01`;


备份恢复数据库
备份数据库(注意:在DOS执行)命令行
mysqldump -u 用户名 -p -B 数据库1 数据库2 数据库n > 文件名.sql[全路径]
恢复数据库(注意:进入Mysql命令行在执行)
Source 文件名.sql
练习:
databases03.sql 备份 zzp_db02 和 zzp_db03,并恢复
# 练习:databases03.sql 备份 zzp_db02 和 zzp_db03,并恢复
# 备份,要在Dos下执行 mysqldump指令,其实在mysql安装目录\bin
# 这个备份的的文件,就是对应的sql语句
mysqldump -u root -p -B zzp_db02 zzp_db03 > f:\\data\\bak.sql
# 删除数据库
drop database zzp_db02;
drop database zzp_db03;
# 恢复数据库(注意:进入Mysql命令行在执行)
source f:\\data\\bak.sql
# 第二个恢复方法,直接将bak.sql的内容放到navicat/SQLyog查询编译器中,执行



备份恢复数据库的表
备份库的表
# 备份
mysqldump -u 用户名 -p密码 数据库 表1 表2 表n > d:\\文件名.sql
# 恢复
source d:\\文件名.sql
练习:
# 备份 数据库的表数据
mysqldump -u root -p zzp_db02 t1 > f:\\data\\t1.sql
# 恢复 数据库的表数据 (注意要先进入 zzp_db02 库在执行命令)
source f:\\data\\t1.sql



表
创建表
CREATE TABLE table_name
(
field1 datatype;
field2 datatype;
field3 datatype;
)character set 字符集 colllate 校对规则 engine 存储引擎;
说明:
field:指定列名
datatype:指定列类型(字段类型)
character set:如不指定则为所在数据库字符集
colllate:如不指定则为所在数据库校对规则
engine:存储引擎
注意:zzp_db02创建表时,要根据保存的数据创建相应的列,并根据数据的类型
定义相应的列类型。例如:user表
id 整形
name 字符串
password 字符串
birthday 日期
# 指令创建表
create table if not exists `user`(
`id` int,
`name` varchar(255),
`password` varchar(255),
`birthday` date
)character set utf8 collate utf8_bin engine innodb;
Mysql常用数据类型(列类型)
| 分类 | 数据类型 | 说明 |
|---|---|---|
| 数值类型 | BIT(M) | 位类型。M指定位数,默认值是1,范围1-64 |
| 数值类型 | TINYINT [UNSIGNED] 占1个字节 | 带符号的范围-128到127。无符号0到255。默认是有符号 |
| 数值类型 | SMALLINT [UNSIGNED] 占2个字节 | 带符号是 负的 2^15 到 2^15-1,无符号 0 到 2^16-1 |
| 数值类型 | MEDIUMINT [UNSIGNED] 3个字节 | 带符号是 负的 2^23 到 2^23-1,无符号 0 到 2^24-1 |
| 数值类型 | INT [UNSIGNED] 4个字节 | 带符号是 负的 2^31 到 2^31-1,无符号 0 到 2^32-1 |
| 数值类型 | BIGINT [UNSIGNED] 8个字节 | 带符号是 负的 2^63 到 2^63-1,无符号 0 到 2^64-1 |
| 数值类型 | ||
| 数值类型 | FLOAT [UNSIGNED] | 占空间4个字节 |
| 数值类型 | DOUBLE [UNSIGNED] | 表示比float精度更大的小数,占用空间8个字节 |
| 数值类型 | DECIMAL(M,D) [UNSIGNED] | 定点数 M指定长度,D表示小数点的位数 |
| 文件、二进制类型 | CHAR(size) char(20) | 固定长度字符串最大255 |
| 文件、二进制类型 | VARCHAR(size) char(20) | 可变长度字符串 0~65535 [即:2^16-1] |
| 文件、二进制类型 | BLOB LONGBLOB | 二进制数据 BLOB 0~2^16-1 LONGBLOB 0~2^32-1 |
| 文件、二进制类型 | TEXT LONGTEXT | 文本 Text 0~2^16 LONGTEXT 0~2^32 |
| 时间日期 | DATE/DATETIME/TimeStamp | 日期类型(YYYY-MM-DD)(YYYY-MM-DD HH:MM:SS),TimeStamp表示时间戳,它作用于自己记录inset、update操作时间 |


数值型(整数)的基本使用
1、说明,使用规范:在能够满足需求的情况下,尽量选择占用空间小的类型
| 类型 | 字节 | 最小值 | 最大值 |
|---|---|---|---|
| (带符号的/无符号的) | (带符号的/无符号的) | ||
| TINYINT | 1 | -128 | 127 |
| 0 | 255 | ||
| SMALLINT | 2 | -32768 | 32767 |
| 0 | 65535 | ||
| MEDIUMINT | 3 | -8388608 | 8388607 |
| 0 | 16777215 | ||
| INT | 4 | -2147483648 | 2147483647 |
| 0 | 4294967295 | ||
| BIGINT | 8 | -9223372036854775808 | 9223372036854775807 |
| 0 | 18446744073709551615 |
2、应用实例
# zzp_db02库 使用tinyint 来演示范围 有符号 -128~127 没有符号 0-255
# 说明:表字符集,校对规则,存储引擎,使用默认的
create table `t2`( `id` TINYINT );
# 1. 如果没有指定 unsigned,则 TINYINT就是有符号的
# 这个一个非常简单的添加语句
insert into t2 values ( -129 ); # 报错 超出字段范围
select * from t2;


3、如何定义一个无符号的整数
create table t10 (id tinyint);//默认是有符号
create table t11 (id tinyint unsigned);//无符号的
# 演示无符号创建表 unsigned 0 - 255
create table `t3` (`id` tinyint unsigned);
insert into t3 values (-1); # 错误 超出范围
insert into t3 values (256);# 错误 超出范围
select * from t3;

数值型(bit)的使用
1、基本使用
mysql> create table t04 (num bit(8));
mysql> insert into t04 (1,3);
mysql> insert into t04 values (2,65);
# 演示bit类型使用
# 1. bit(m) m 在范围 1- 64 之间
# 2. 添加数据 范围 你给定的位数确定,比如 m=8 表示一个字节 0~255
# 3. 显示按照bit
# 4. 查询时,仍然可以按照数来查询
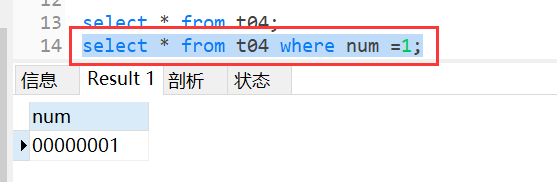
create table t04 (num bit(8));# 0~255
insert into t04 values (1);
insert into t04 values (3);
insert into t04 values (255);
insert into t04 values (256); # 错误 超出范围
select * from t04;
select * from t04 where num =1;


2、细节说明
bit字段显示时,按照 位的方式显示- 查询的时候仍然可以使用 添加的数值
- 如果一个值只有 0,1 可以考虑使用 bit(1),可以节约空间
- 位类型。M指定位数,默认值1,范围 1~64
- 使用不多
数值型(小数)的基本使用
1、FLOAT/DOUBLE [UNSIGNED]
Float 单精度精度,Double 双精度
2、DECIMAL[M,D] [UNSIGNED]
- 可以支持更加精确的小位数。M 是小数位数(精度)的总数,D 是小数点(标度)后面的位数
- 如果 D 是0,则值没有小数点或分数部分。M 最大65。D 最大是30。如果 D被省略,默认是0。如果 M被省略,默认是10。
- 建议:如果希望小数的精度高,推荐使用decimal
3、案例演示
# 演示decimal类型、float、double使用
# 创建表
CREATE TABLE t05(
num1 FLOAT,
num2 DOUBLE,
num3 DECIMAL(30,20)
);
# 添加数据
INSERT INTO t05 VALUES(88.12345678912345,88.12345678912345,88.12345678912345);
SELECT * FROM t05;
# decimal可以存放很大的的数
CREATE TABLE t06(num DECIMAL(65));
INSERT INTO t06 VALUES(86456486465465464451648656168465156486651845316846116845168456);
SELECT * FROM t06;
CREATE TABLE t07(num BIGINT UNSIGNED);
INSERT INTO t07 VALUES(86456486465465464451648656168465156486651845316846116845168456); # 错误 数据超出 BIGINT UNSIGNED 范围



字符串的基本使用
CHAR(size)
固定长度字符串 最大 255字符
VARCHAR(szie)
可变长度字符串 最大 65535字节【utf8编码最大 65535/3=21844字符 1-3个字节用于记录大小】
应用案例:
# 演示字符串类型使用 char varchar
# 注释的快捷键 ctrl + /
-- CHAR(size)
-- 固定长度字符串 最大 255字符
-- VARCHAR(szie)
-- 可变长度字符串 最大 65535字节【utf8编码最大 65535/3=21844字符 1-3个字节用于记录大小】
-- 如果表的编码是 utf8 varchar(size) size = (65535-3)/3 = 21844
-- 如果表的编码是 gbk varchar(size) size = (65535-3)/2 = 32766
create table t08 (
`name` char(255) # char 类型 最大 255
);
create table t09 (
`name` varchar(21844) # varchar 类型 最大 21845-1
);



字符串使用细节
1、细节1
char(4) 这个 4 表示字符数(char最大255),不是字节数,不管是中文还是字母都放四个,按字符计算
varchar(4) 这个 4 表示字符数,不管是字母还是中文都以定义好的表的编码来存放数据。
不管是 中文还是英文字母,都是最多存放4个,是按照字符来存放的
# 演示字符串类型的使用细节
# char(4) 和 varchar(4) 这个4表示的是字符,而不是字节,不区分字符是汉字还是字母数字
create table t10 (`name` char(4));
insert into t10 values("zzp先生"); # 错误 超出 4 范围
create table t11 (`name` varchar(4));
insert into t11 values("zzp先生"); # 错误 超出 4 范围


2、细节2
char(4) 是定长(固定的大小),就是说,即使你 插入 “aa”,也会占用 分配的4个字符;
varchar(4) 是变长(变化的大小),就是说,如果你插入了 “aa”,实际占用空间大小并不是4个字符,而是按照实际占用空间来分配(说明:varchar本身还需要占用 1-3个字节来记录存放内容的长度)
L(实际数据大小) + (1~3)字节
3、细节3
什么时候使用 char,什么时候使用varchar
(1)如果数据是定长,推荐使用char,比如md5的密码,邮编,手机号,身份证号码等。char(32)
(2)如果一个字段的长度是不确定,我们还有varchar,比如留言、文章
查询速度:char > varchar
4、细节4
在存放文本时,也可以使用Text 数据类型,可以将TEXT列视为VARCHAR列,
注意 Text 不能有默认值,大小 0-2^16 字节
如果希望存放更多字符,可以选择
MEDIUMTEXT 0-2^24 或者 LONGTEXT 0-2^32
# 如果 varchar 不够用,可以考虑使用mediumtext,longtext
# 如果想简单点,可以使用直接使用 text
CREATE TABLE t12 (`content` TEXT,`content2` MEDIUMTEXT, `content3` LONGTEXT);
INSERT INTO t12 VALUES("zzp先生","zzp先生100","zzp先生100000~~");
SELECT * FROM t12;

日期类型的基本使用
CREATE TABLE birthday(
t1 DATE,
t2 DATETIME,
t3 TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
timestamp:时间戳
mysql > INSERT INFO birthday (t1,t2) VALUES('2022-11-11','2022-11-11 10:10:10');
# 演示时间相关的类型
# 创建一张表, date、datetime、timestamp
create table t13(
birthday date, -- 生日
jobtime datetime, -- 记录年月日 时分秒
login_time timestamp not null default current_timestamp on update current_timestamp -- 登录时间 更新时 更新时间
);
insert into t13(birthday,jobtime) values('2022-11-11','2022-11-11 10:10:10');
-- 如果我们更新 t13的表某天记录 login_time列会自动的以当前时间进行更新
select * from t13;
drop table t13

日期类型的细节说明
TimeStamp在Insert和Update时,会自动更新
创建表练习
创建一个员工表 emp,选用适合的数据类型
| 字段 | 属性 |
|---|---|
| id | 整形 |
| name | 字符型 |
| sex | 字符型 |
| birthday | 日期型(date) |
| entry_date | 日期型(date) |
| job | 字符型 |
| Salary | 小数型 |
| resume | 文本型 |
# 创建表练习
-- 字段 属性
-- id 整形
-- name 字符型
-- sex 字符型
-- birthday 日期型(date)
-- entry_date 日期型(date)
-- job 字符型
-- Salary 小数型
-- resume 文本型
create table `tmp`(
`id` int,
`name` varchar(32),
`sex` char(1),
`birthday` date,
`entry_date` datetime,
`job` varchar(32),
`salary` double,
`resume` TEXT
)charset utf8 collate utf8_bin engine innodb;
-- 添加一条数据
insert into `tmp`
values(100,'小妖怪','男','2000-11-11','2010-11-11 11:11:11',
'巡山的',3000,'大王叫我来巡山');
select * from `tmp`;

修改
使用 ALTER TABLE 语句追加,修改,或者删除列语法
添加列
ALTER TABLE table_name
ADD (column datatype [DEFAULT expr])
[, column datatype] ...);
修改列
ALTER TABLE table_name
MODIFY (column datatype [DEFAULT expr])
[, column datatype] ...);
删除列
ALTER TABLE table_name
DROP (column);
查看表的结构:desc 表名;-- 可以查看表的列
修改表名:Rename table 表名 to 新表名
修改表字符集:alter table 表名 character set 字符集;
应用实例
- 员工表emp的上增加一个image列,varchar类型(要求在resume后面)
- 修改job列,使其长度为60
- 删除sex列
- 表名该为employee
- 修改表的字符集utf-8
- 列名name修改为user_name
-- 员工表emp的上增加一个image列,varchar类型(要求在resume后面)
alter table `emp`
add image varchar(32) not null default '' -- image列 默认为 空
after `resume`; -- 在resume后面
-- 修改job列,使其长度为60
alter table `emp`
modify job varchar(60) not null default '';
-- 删除sex列
alter table `emp`
drop sex;
-- 表名该为employee
rename table `emp` to `employee`;
-- 修改表的字符集utf-8
alter table `employee` character set utf8;
-- 列名name修改为user_name
alter table `employee`
change `name` `user_name` varchar(32) not null default '';
-- 显示表的结构,可以查看表的所有列
desc `employee`;

CRUD
数据库C[create]R[read]U[update]D[delete]语句
1、Insert语句 (添加数据)
2、Update语句 (更新数据)
3、Delete语句 (删除数据)
4、Select语句 (查找数据)
Inset
使用 INSERT 语句向表中插入数据
INSERT INTO table_name [(column [, column...])]
VALUES (value [, value...])
快速入门案例:
1、创建一张商品表 goods(id int, goods_name varchar(10), price double);
2、添加2条记录
# 练习 insert 语句
-- 1、创建一张商品表 goods(id int, goods_name varchar(10), price double);
create table `goods`(
`id` int,
`goods_name` varchar(10),
`price` double
);
-- 2、添加2条记录
insert into `goods` (id, goods_name, price)
values (10,'苹果手机',5000);
insert into `goods` (id, goods_name, price)
values (20,'小米手机',2000);
desc `goods`;
select * from `goods`;

Insert 细节说明
1、插入的数据应与字段的数据类型相同。比如: 把 ‘abc’ 添加到 int 类型会报错
2、数据的长度应在列的固定范围内,例如:不能将一个长度为80的字符串加入到长度为40的列中
3、在values中列的数据位置必须与被加入的列的排列位置对应。
4、字符和日期类型应包含在单引号中。
5、列可以插入空值[前提是该字段允许为空],insert into table value(null)
6、insert into table_name (列名..) values (),(),() 形式添加多态记录
7、如果是给表中的所有字段添加数据,可以不写前面的字段名称
8、默认值的使用,当不给某个字段值时,如果有默认值就会添加默认值,否则报错
# 说明 insert 语句的细节
-- 1、插入的数据应与字段的数据类型相同。比如: 把 ‘abc’ 添加到 int 类型会报错
insert into `goods` (id, goods_name, price)
values ('abc','华为手机',3000); # 错误 'abc'类型不匹配
-- 2、数据的长度应在列的固定范围内,例如:不能将一个长度为80的字符串加入到长度为40的列中
insert into `goods` (id, goods_name, price)
values (40,'vovo手机vovo手机vovo手机vovo手机',2000); # 错误 Data too long for column 'goods_name'
-- 3、在values中列的数据位置必须与被加入的列的排列位置对应。
insert into `goods` (id, goods_name, price)
values ('vovo手机',40,3000); # 错误 Incorrect integer value: 'vovo手机' for column 'id'
-- 4、字符和日期类型应包含在单引号中。
insert into `goods` (id, goods_name, price)
values (40,vovo手机,2000); # 错误 Unknown column 'vovo手机' in 'field list'
-- 5、列可以插入空值[前提是该字段允许为空],insert into table value(null)
insert into `goods` (id, goods_name, price)
values (40,'华为手机',null); # Column 'price' cannot be null
-- 6、insert into table_name (列名..) values (),(),() 形式添加多态记录
insert into `goods` (id, goods_name, price)
values (50,'三星手机',2300),(60,'诺基亚手机',1800);
-- 7、如果是给表中的所有字段添加数据,可以不写前面的字段名称
insert into `goods` values (60,'菠萝手机',800);
-- 8、默认值的使用,当不给某个字段值时,如果有默认值就会添加默认值,否则报错
-- 如果某个列 没有指定 not null,那么当添加数据时,没有给定值,则会默认给null
-- 如果我们希望指定某个列的默认值,可以在创建表时指定 比如: `price` duble not null default 100
insert into `goods` (id, goods_name)
values (60,'格力手机');
SELECT * from `goods`;
Update
使用 update语句修改表中的数据
UPDATE table_name
set col_name1 = expr1 [, col_name2 = expr2 ...]
[ where where_definition]
基本使用
要求:
在上面创建的employee表中修改表中的记录
1、将所有员工薪水改为5000元
2、将姓名 小妖怪 的员工薪水修改为3000元
3、将 老妖怪 的薪水在原来的基础上增加1000元
-- 演示 update语句
-- 在创建的employee表中修改表中的记录
-- 1、将所有员工薪水改为5000元。[如果没有带where 条件,会修改所有的记录,要小心!]
update employee set salary = 5000;
-- 2、将姓名 小妖怪 的员工薪水修改为3000元
update employee set salary = 3000 where user_name = '小妖怪';
-- 3、将 老妖怪 的薪水在原来的基础上增加1000元
insert into `employee` values(200,'老妖怪','1990-11-11','2000-11-11 10:10:10',
'捶背的',5000,'给大王捶背的','123.jpg');
update employee set salary = salary + 1000 where user_name = '老妖怪';
select * from employee;

使用细节
1、UPDATE语法可以用新值更新原有表行的各列
2、SET子句指示要修改哪些列和要给予哪些值
3、WHERE子句指定应更新哪些行。如果没有WHERE子句,则更新所有的行(记录),因此要慎用!
4、如果需要修改多个字段,可以通过 set 字段1=值1, 字段2=值2...
Delete
使用 delete语句删除表中数据
delete from table_name
[where where_definition]
快速入门案例:
- 删除表中名称为 '老妖怪’的记录
- 删除表中所有记录
-- delete 语句演示
-- 删除表中名称为 '老妖怪’的记录
delete from `employee` where user_name = '老妖怪';
-- 删除表中所有记录,要慎重!
delete from `employee`;
使用细节
1、如果不使用where子句,将删除表中所有记录
2、Delete语句不能删除某一列的值(可以使用update 设为 null 或者 ‘’)
3、使用delete语句仅删除记录,不删除表本身。如果删除表,使用 drop table语句。drop table 表名;
Select
基本语法
SELECT [DISTINCT] *| {colnum1, colnum2, colnum3...}
FROM table_name
注意事项
1、Select 指定查询哪些列的数据
2、column指定列名
3、*号代表查询所有列
4、From 指定查询哪张表
5、DISTINCT 可选,指显示结果时,是否去掉重复数据
练习
1、查询表中所有学生的信息
2、查询表中所有学生的姓名和对应的英语成绩
3、过滤表重复数据 distinct
4、要查询的记录,每个字段相同,才会去重
# 创建新的表(student)
create table `student`(
`id` int not null default 1,
`name` varchar(20) not null default '',
`chinese` float not null default 0.0,
`english` float not null default 0.0,
`math` float not null default 0.0
);
insert into `student`(id,name,chinese,english,math) values (1,'zzp先生',89,78,90);
insert into `student`(id,name,chinese,english,math) values (2,'张飞',67,98,56);
insert into `student`(id,name,chinese,english,math) values (3,'宋江',87,78,77);
insert into `student`(id,name,chinese,english,math) values (4,'关羽',88,98,90);
insert into `student`(id,name,chinese,english,math) values (5,'赵云',82,84,67);
insert into `student`(id,name,chinese,english,math) values (6,'欧阳锋',55,85,45);
insert into `student`(id,name,chinese,english,math) values (7,'黄蓉',75,65,30);
-- 1、查询表中所有学生的信息
select * from `student`;
-- 2、查询表中所有学生的姓名和对应的英语成绩
select `name`,`english` from `student`;
-- 3、过滤表重复数据 distinct
select distinct english from `student`;
-- 4、要查询的记录,每个字段相同,才会去重
select distinct `name`,english from `student`;
使用表达式对查询的列进行运算
SELECT *| {column1 | expression, column2 | expression, ...}
FROM table_name
在select语句中可以使用as语句
SELECT column_name as 别名 from 表名;
练习
1、统计每个学生的总分
2、在所有学生总分加10分的情况
3、使用别名表示学生分数
-- slect 语句使用
-- 1、统计每个学生的总分
select `name`, (chinese + english + math) from `student`;
-- 2、在所有学生总分加10分的情况
select `name`, (chinese + english + math + 10) from `student`;
-- 3、使用别名表示学生分数
select `name` as '名字', (chinese + english + math + 10) as total_score from `student`;

在where子句中经常使用的运算符
| 名称 | 运算符 | 说明 |
|---|---|---|
| 比较运算符 | > < <= >= = <>/!= | 大于、小于,大于(小于)等于,不等于 |
BETWEEN ...AND... | 显示在某一区间的值 | |
IN(set) | 显示在int列表中的值,例: in (100,200) | |
LIKE '张pattern' NOT LIKE '' | 模糊查询 | |
IS NULL | 判断是否为空 | |
| 逻辑运算符 | and | 多个条件同时成立 |
or | 多个条件任一成立 | |
not | 不成立,例:wher not (salary>100); |
使用where子句,进行过滤查询
1、查询姓名为赵云的学生成绩
2、查询英语成绩大于90分的同学
3、查询总分大于200分的使用同学
4、查询math大于60 并且(and)id大于4的学生成绩
5、查询英语成绩大于语文成绩的同学
6、查询总分大于200分 并且 数学成绩小于语文成绩的,姓赵的学生
-- 1、查询姓名为赵云的学生成绩
select * from `student` where `name` = '赵云';
-- 2、查询英语成绩大于90分的同学
select * from `student` where english > 90;
-- 3、查询总分大于200分的使用同学
select * from `student` where (chinese + english + math) > 200;
-- 4、查询math大于60 并且(and)id大于4的学生成绩
select * from `student` where math > 60 and id > 4;
-- 5、查询英语成绩大于语文成绩的同学
select * from `student` where english > chinese;
-- 6、查询总分大于200分 并且 数学成绩小于语文成绩的,姓赵的学生
-- 赵% 表示 名字以 赵 开头的就可以
select * from `student` where (chinese + english + math) > 200
and math < chinese and `name` like '赵%';
-- 查询英语分数在 80-90 之间的同学
select * from `student` where english >= 80 and english <= 90;
-- 或者 使用 between..and... 是闭区间
select * from `student` where english between 80 and 90;
-- 查询数学分数在 89,90,91的同学
select * from `student` where math = 89 or math = 90 or math = 91;
-- 或者使用 in
select * from `student` where math in (89,90,91);
-- 查询所有姓李的学生成绩
select * from `student` where `name` like '赵%';
-- 查询数学>80,语文>80的同学
select * from `student` where math > 80 and chinese > 80;
-- 查询语文分数在 70-80之间的同学
select * from `student` where chinese between 70 and 80;
-- 查询总分数为 189,190,191的同学
select * from `student` where (chinese + english + math) in (189,190,191);
-- 查询所有姓李 或者 姓宋 的学生成绩
select * from `student` where `name` like '李%' or `name` like '宋%';
-- 查询数学比语文多30分的同学
select * from `student` where (math - chinese) > 30;
使用 order by 子句排序查询结果
SELECT column1, column2, column3, ...
FROM table_name
order by column asc|desc, ...
1、Order by 指定排序的列,排序的列即可以是表中的列名,也可以是select语句后指定的列名/别名
2、Asc 升序[默认]、Desc 降序
3、ORDER BY 子句应对应于SELECT语句的结尾
练习:
- 对数学成绩排序后输出【升序】
- 对总分按从高到底排序输出【降序】
- 对姓李的学生成绩排序输出【升序】
-- 演示 order by使用
-- 对数学成绩排序后输出【升序】
select * from `student` order by math asc;
-- 对总分按从高到底排序输出【降序】 -- 使用别名排序
select `name`, (chinese + english + math) as total_score from `student`
order by total_score desc;
-- 对姓李的学生成绩排序输出【升序】
select * from `student` where `name` like '张%' order by math;
函数
统计函数
count
Count 返回行的总数
Select count(*)|count(列名) from table_name
[where where_definition]
练习:
统计一班级有多少学生?
统计数学成绩大于90的学生有多少个?
统计总分大于250的人数有多少?
count(*) 和 count(列) 区别
-- 演示mysql的统计函数的使用
-- 统计一班级有多少学生?
select count(*) from student;
-- 统计数学成绩大于90的学生有多少个?
select count(*) from student where math >= 90;
-- 统计总分大于250的人数有多少?
select count(*) from student where (math + english + chinese) > 250;
-- count(*) 和 count(列) 区别
-- 解释:count(*) 返回满足条件的记录的行数
-- count(列):统计满足条件的某个列有多少个,但是会排除 为null的情况
create table `t14` (`name` varchar(20));
insert into t14 values ('tom');
insert into t14 values ('jack');
insert into t14 values ('mary');
insert into t14 values (null);
select count(*) from t14; -- 4
select count(`name`) from t14; -- 3
sum
Sum函数返回满足where条件的行的和 - 一般使用在数值列
Selete sum(列名) {, sum(列名) ...} from table_name
[where where_definition]
练习:
统计一个班级数学总成绩?
统计一个班级语文、英语、数学各科的总成绩
统计一个班级语文、英语、数学的成绩总和
统计一个班级语文成绩平均分
注意:sum仅对数值起作用,没有意义,对多列求和,","号不能少。
# 演示sum函数的使用
-- 统计一个班级数学总成绩?
select sum(math) from student;
-- 统计一个班级语文、英语、数学各科的总成绩
select sum(math) as '数学',sum(english) as '英语',sum(chinese) as '语文' from student;
-- 统计一个班级语文、英语、数学的成绩总和
select sum(math + english + chinese) from student;
-- 统计一个班级语文成绩平均分
select sum(chinese) / count(*) from student;
avg
AVG函数返回满足where条件的一列的平均值
Select avg(列名) {, avg(列名) ...} from table_name
[where where_definition]
练习:
求一个班级数学平均分
求一个班级总分平均分
# 演示avg函数的使用
-- 求一个班级数学平均分
select avg(math) from student;
-- 求一个班级总分平均分
select avg(math + english + chinese) from student;
Max/min
Max/min函数返回满足where条件的一列的最大/最小值
Selete max(列名) from table_name
[where where_definition]
练习:求班级最高分和最低分(数值范围在统计中特别有用)
# 演示max/min函数的使用
-- 求班级最高分和最低分
select max(math + english + chinese),min(math + english + chinese) from student;
-- 求出班级数学最高和最低发
select max(math ),min(math) from student;
group by
使用group by 子句对列进行分组【先创建测试表】
SELECT column1, column2, column3... FROM table_name
group by column
having
使用having子句对分组后额结果进行过滤
SELECT column1, column2, column3...
FROM table_name
group by column having ...
grop by用于查询的j结果分组统计
having子句用于限制分组显示结果
如何显示每个部门的平均工资和最高工资
显示每个部门的每种岗位的平均工资和最低工资
显示平均工资低于2000的部门号和它的平均工资 // 别名
# 部门表
create table `dept`(
`deptno` mediumint unsigned not null default 0,
`dname` varchar(20) not null default '',
`loc` varchar(13) not null default ''
);
insert into `dept` values(10,'ACCOUNTING','NEW YORK'),
(20,'RESEARCH','DELLAS'),(30,'SALES','CHCAGO'),(40,'OPERATIONS','BOSTON');
select * from dept;
# 创建表EMP雇员
create table `emp` (
`empno` mediumint unsigned not null default 0, /*编号*/
`ename` varchar(20) not null default '',/*名字*/
`job` varchar(9) not null default '',/*工作*/
`mgr` mediumint unsigned, /*上级编号*/
`hiredate` date not null, /*入职时间*/
`sal` decimal(7,2) not null, /*薪水*/
`comm` decimal(7,2), /*红利 奖金*/
`deptno` mediumint unsigned not null default 0 /*部门编号*/
);
-- 添加测试数据
insert into `emp` values(7369,'SMITH','CLERK',7902,'1990-12-17',800.00,NULL,20),
(7499,'ALLEN','SALESMAN',7698,'1991-2-20',1600.00,300.00,30),
(7521,'WARD','SALESMAN',7698,'1991-2-22',1250.00,500.00,30),
(7566,'JONES','MANAGER',7839,'1991-4-2',2975.00,NULL,20),
(7654,'MARTIN','SALESMAN',7698,'1991-9-28',1250.00,1400.00,30),
(7698,'BLAKE','MANAGER',7839,'1991-5-1',2850.00,NULL,30),
(7782,'CLARK','MANAGER',7839,'1991-6-9',2450.00,NULL,10),
(7788,'SCOTT','ANALYST',7566,'1997-4-19',3000.00,NULL,20),
(7839,'KING','PRESIDENT',NULL,'1991-11-17',5000.00,NULL,10),
(7844,'TURNER','SALESMAN',7698,'1991-9-8',1500.00,NULL,30),
(7900,'JAMES','CLERK',7698,'1991-12-3',950.00,NULL,30),
(7902,'FORD','ANALYST',7566,'1991-12-3',3000.00,NULL,20),
(7934,'MILLER','CLERK',7782,'1992-1-23',1300.00,NULL,10);
select * from emp;
# 员工级别表
create table `salgrade`(
`grane` mediumint unsigned not null default 0,/*工资级别*/
`losal` decimal(17.2) not null,/*该级别的最低工资*/
`hisal` decimal(17.2) not null /*该级别的最高工资*/
);
insert into salgrade values (1,700,1200);
insert into salgrade values (2,1201,1400);
insert into salgrade values (3,1401,2000);
insert into salgrade values (4,2001,4000);
insert into salgrade values (5,3001,9999);
select * from salgrade;
-- 演示 group by + having
-- 如何显示每个部门的平均工资和最高工资
-- 分析:avg(sal) max(sal)
-- 按照部门分组查询
select avg(sal), max(sal), deptno from emp group by deptno;
-- 显示每个部门的每种岗位的平均工资和最低工资
-- 分析:1.显示每个部门的平均工资和最低工资
-- 2.显示每个部门的每种岗位的平均工资和最低工资
select avg(sal), min(sal), deptno, job from emp
group by deptno,job;
-- 显示平均工资低于2000的部门号和它的平均工资 // 别名
-- 分析:
-- 1. 显示各个部门的平均工资和部门号
select avg(sal), deptno from emp group by deptno;
-- 2. 在1个结果基础上,进行过滤,保留 avg(sal) < 2000
select avg(sal), deptno from emp
group by deptno having avg(sal) < 2000;
-- 3. 使用别名进过滤
select avg(sal) as avg_sal, deptno from emp
group by deptno having avg_sal < 2000;
字符串函数
CHARSET(str) | 返回字符串集 |
|---|---|
CONCAT(string2 [,...]) | 连接字符串 |
| INSTR(string, substring ) | 返回substring在string中出现的位置,没有返回0 |
UCASE(string2) | 转换成大写 |
LCASE(string2) | 转换成小写 |
| LEFT(string2, length)/RIGHT(string2, length) | 从string2中左边/右边起取length个字符 |
LENGTH(string) | string长度[按照字节] |
REPLACE(str, search_str, replace_str) | 在str中用replace_str替换search_str |
| STRCMP(string1, string2) | 逐字符比较两字串大小 |
SUBSTRING(str, postion [, length]) | 从str的position开始【从1开始计算】,取length个字符 |
| LTRIM(string2 ) RTRIM(string2 ) trim | 去除前端空格或后端空格 |
-- 演示字符串相关函数的使用,使用emp表来演示
-- CHARSET(str) 返回字符串集
select charset(ename) from emp;
-- CONCAT(string2 [,...]) 连接字符串 将多个列拼接成一列
select concat(ename,' 工作是 ',job) from emp;
-- INSTR(string, substring ) 返回substring在string中出现的位置,没有返回0,
-- dual:亚元表 系统表 可以作为测试表使用
select instr('zzping','ping') from DUAL;
-- UCASE(string2) 转换成大写
select ucase(ename) from emp;
-- LCASE(string2) 转换成小写
select lcase(ename) from emp;
-- LEFT(string2, length)/RIGHT(string2, length) 从string2中左边/右边起取length个字符
select left(ename, 2) from emp; -- 左边去2个字符
select right(ename, 2) from emp; -- 右边去2个字符
-- LENGTH(string) string长度[按照字节返回长度 中文1-3字节]
select length(ename) from emp;
-- REPLACE(str, search_str, replace_str) 在str中用replace_str替换search_str
-- 如果是 manager 就替换成 经理
select ename, replace(job,'MANAGER','经理') from emp;
-- STRCMP(string1, string2) 逐字符比较两字串大小
select strcmp('zzp','azp') from dual;
-- SUBSTRING(str, postion [, length]) 从str的position开始【从1开始计算】,取length个字符
-- 从ename 列的第一个位置开始取出2个字符
select substring(ename, 1, 2) from emp;
-- LTRIM(string2 ) RTRIM(string2 ) trim 去除前端空格或后端空格
select ltrim(' zzp') from dual;
select rtrim('zzp ') from dual;
select trim(' zzp ') from dual;
练习:
以首字母小写的方式显示所有员工emp的姓名
-- 以首字母小写的方式显示所有员工emp的姓名
-- 方法1
-- 思路 先取出ename 的第一个字符,转成小写
-- 把它和后面的字符串进行拼接输出即可
select concat(lcase(substring(ename,1,1)), substring(ename,2)) as new_name
from emp;
-- 方法2
select concat(lcase(left(ename,1)), substring(ename,2)) as new_name
from emp;
数学函数
ABS(num) | 绝对值 |
|---|---|
| BIN(decimal_number) | 十进制转二进制 |
CEILING(number2) | 向上取整,得到比number2 大的最小整数 |
| CONV(number2, from_base, to_base) | 进制转换 |
FLOOR(number2) | 向下取整,得到比number2 小的最大整数 |
FORMAT(number, decimal_places) | 保留小数位数(四舍五入) |
| HEX(DecimalNumber) | 转成十六进制 |
| LEAST(number, number2 [,…]) | 求最小值 |
| MOD(numerator, denominator) | 求余 |
RAND([seed]) | RAND([seed]) 返回随机数 其范围为 0 <= v <= 1.0 |
注意:rand()返回一个随机浮点值 v,范围 0 到 1 之间(即。其范围为 0 <= v <= 1.0)。若已指定一个整数参数 N,则它被用作种子值,用来产生重复序列。
-- 演示数学相关函数
-- ABS(num) 绝对值
select abs(-10) from dual;
-- BIN(decimal_number) 十进制转二进制
select bin(10) from dual;
-- CEILING(number2) 向上取整,得到比number2 大的最小整数
select ceiling(1.1) from dual; -- 2
-- CONV(number2, from_base, to_base) 进制转换
-- 下面的含义是 8 是十进制的8,转成 2进制 输出
select conv(8, 10, 2) from dual; -- 1000
-- 下面的含义是 8 是十六进制的8,转成 2进制 输出
select conv(8, 16, 2) from dual; -- 8
-- FLOOR(number2) 向下取整,得到比number2 小的最大整数
select floor(1.1) from dual; -- 1
-- FORMAT(number, decimal_places) 保留小数位数(四舍五入)
select format(78.123456, 4) from dual; -- 78.1235
-- HEX(DecimalNumber) 转成十六进制
select hex(11) from dual; -- B
-- LEAST(number, number2 [,…]) 求最小值
select least(0,1,-10,4) from dual; -- -10
-- MOD(numerator, denominator) 求余
select mod(10, 3) from dual; -- 1
-- RAND([seed]) RAND([seed]) 返回随机数 其范围为 0 <= v <= 1.0
-- 说明:1.如果使用 rand() 每次返回不同的随机数,在 0 <= v <= 1.0
-- 2. 如果使用 rand(seed) 每次随机数, 在 0 <= v <= 1.0,如果seed不变,该随机数也不变
select rand(2) from dual;
时间日期
CURRENT_DATE( ) | 当前日期 |
|---|---|
CURRENT_TIME( ) | 当前时间 |
CURRENT_TIMESTAMP( ) | 当前时间戳 |
DATE(datetime) | 返回datetime的日期部分 |
DATE_ADD(date2, INTERVAL d_value d_type) | 在date2中追加上日期或者时间 |
DATE_SUB(date2, INTERVAL d_value d_type) | 在date2上减去一个时间 |
DATEDIFF(date1, date2) | 两个日期差(结果是天) |
| TIMEDIFF(date1, date2) | 两个时间差(多少小时多少分钟多少秒) |
NOW( ) | 当前时间 |
YEAR|Month|DAY|DATE(datetime) FROM_UNIXTIME() unix_timestamp() | 年月日 时间戳 时间格式转换 |
上面函数的细节说明:
1、DATE_ADD()中的 interval 后面可以是 year minute second day等
2、DATE_SUB()中的 interval 后面可以是 year minute second day等
3、DATEDIFF(date1, date2)得到的是天数,而且是date1-date2的天数,因此可以取负数
4、这四个函数的日期类型可以是 date,datetime 或者 timestamp
-- 日期时间相关函数
-- CURRENT_DATE( ) 当前日期
select current_date() from dual;
-- CURRENT_TIME( ) 当前时间
select current_time() from dual;
-- CURRENT_TIMESTAMP( ) 当前时间戳
select current_timestamp() from dual;
# 创建测试表 信息表
create table mes(id int, content varchar(30), send_time datetime);
# 添加记录
insert into mes values(1,'新闻',current_timestamp());
insert into mes values(2,'新闻2',now());
insert into mes values(4,'新闻3','2021-11-11 11:11:11');
select * from mes;
# 应用实例
# 显示使用新闻信息,发布日期只显示 日期,不用显示时间
select id, content, date(send_time) from mes;
# 请查收在10分钟发布的帖子
-- DATE_ADD(date2, INTERVAL d_value d_type) 在date2中追加上日期或者时间
-- DATE_SUB(date2, INTERVAL d_value d_type) 在date2上减去一个时间
select * from mes where date_add(send_time, interval 10 minute) >= now();
select * from mes where date_sub(now(), interval 10 minute) <= send_time;
# 请在mysql 的sql语句中求出 2011-11-11 和 1990-1-1 相差多少天 DATEDIFF(date1, date2) 两个日期差(结果是天)
select datediff('2011-11-11', '1990-01-01') from dual;
# 请在mysql 的sql语句中求出你活了多少天? 比如 1986-11-11 出生
select datediff(now(), '1986-11-11') from dual;
# 如果你能活80岁,求出你还能活多久天? 比如 1986-11-11 出生
-- 先求出活到80岁 时,是什么日期 x
-- 然后在使用 datediff(x,now()): '1986-11-11' -> date
-- interval 80 year: year 可以是 年月日 时分秒
-- '1986-11-11' 可以是 date,datetime,timestamp
select datediff(date_add('1986-11-11', interval 80 year), now()) from dual;
-- DATE(datetime) 返回datetime的日期部分
select date(current_timestamp()) from dual;
select date(now()) from dual;
select date('2021-11-11 11:11:11') from dual;
-- TIMEDIFF(date1, date2) 两个时间差(多少小时多少分钟多少秒)
select timediff('10:11:11','06:10:10') from dual; -- 04:01:01
-- NOW( ) 当前时间
select now() from dual;
-- YEAR|Month|DAY|DATE(datetime)
select year(now()) from dual;
select month(now()) from dual;
select day(now()) from dual;
select year('2013-10-10') from dual;
-- unix_timestamp() 返回的是 1970-1-1 到现在的秒数
select unix_timestamp() from dual;
-- FROM_UNIXTIME() :可以把一个unix_timestamp 秒数[时间戳],转成指定格式的一个日期
-- %Y-%m-%d 格式是规定好的,表示年月日
-- 意义:在开发中,可以存放一个整数,然后表示时间,通过FROM_UNIXTIME转换
--
select from_unixtime(1618483484, '%Y-%m-%d') from dual;
select from_unixtime(1618483484, '%Y-%m-%d %H:%i:%s') from dual;
在实际开发中,我们也经常使用int来保存一个unix时间戳,然后使用 from_unixtime() 进行转换,还是非常有实用价值的
加密和系统函数
USER() | 查询用户 |
|---|---|
| DATABASE() | 数据库名称 |
MD5(str) | 为字符串算出一个MD5 32的字符串,(用户密码)加密 |
| PASSWORD(str) select * from mysql.user \G | 从原文密码 str 计算并返回密码字符串,通常用于对mysql数据库的用户密码加密 |
基本使用:
-- 演示加密函数和系统函数
-- USER() 查询用户
-- 可以查看登录到mysql的有哪些用户,以及登录的IP
select user() from dual; -- 用户@IP地址
-- DATABASE() 查询当前使用的数据库名称
select database() from dual;
select database();
-- MD5(str) 为字符串算出一个MD5 32的字符串,(用户密码)加密
-- root 密码加密 123456 -> 加密md5 -> 在数据库中存放的是加密后的密码
select md5('123456') from dual;
select length(md5('123456')) from dual;
-- 演示用户表,存放密码时,是md5
create table users(
`id` int,
`name` varchar(20) not null default '',
pwd char(32) not null default ''
);
insert into users values(100,'zzp',md5('zzp'));
select * from users;
-- 查询
select * from users where `name`='zzp' and pwd=md5('zzp');
-- PASSWORD(str) -- 加密函数,在MySQL数据库的用户密码就是使用 PASSWORD函数加密
select password('123456') from dual; -- *6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9
-- select * from mysql.user \G 从原文密码 str 计算并返回密码字符串,通常用于对mysql数据库的用户密码
-- 通常用于对mysql数据库的用户密码加密
-- mysql.user 表示 数据库.表
select * from mysql.user;

流程控制函数
先看两个需求:
1、查询emp 表,如果 comm 是null,则显示0.0
2、如果emp 表 是 CLERK 则显示 职员,如果是 MANAGE 则显示经理,如果是 SALESMAN 则显示 销售人员,其它正常显示
IF(expr1, expr2, expr3) | 如果expr1为true,则返回 expr2 否则返回 expr3 |
|---|---|
| IFNULL(expr1, expr2) | 如果expr1不为NULL,则返回expr1,否则返回expr2 |
SELECT CASE WHEN expr1 THEN expr2 WHEN expr3 THEN expr4 ELSE expr5 END;[类似多重分支] | 如果expr1为true,则返回expr2,如果expr2为true,返回expr4,否则返回 expr5 |
# 演示流程控制语句
-- IF(expr1, expr2, expr3) 如果expr1为true,则返回 expr2 否则返回 expr3
select if(true, '北京','深圳') from dual;
-- IFNULL(expr1, expr2) 如果expr1不为NULL,则返回expr1,否则返回expr2
select ifnull(null,'zzp') from dual;
-- SELECT CASE WHEN expr1 THEN expr2 WHEN expr3 THEN expr4 ELSE expr5 END;[类似多重分支]
-- 如果expr1为true,则返回expr2,如果expr2为true,返回expr4,否则返回 expr5
select case
when true then 'jack' -- jack
when false then 'tom'
else 'lili' end
-- 1、查询emp 表,如果 comm 是null,则显示0.0
-- 说明:判断是否为null 要使用 is null,判断不为null 要使用 is not null
select ename,if(comm is null, 0.0, comm) from emp;
select ename,ifnull(comm, 0.0) from emp;
-- 2、如果emp 表 是 CLERK 则显示 职员,如果是 MANAGE 则显示经理,
-- 如果是 SALESMAN 则显示 销售人员,其它正常显示
select ename, (select case
when job = 'CLERK' then '职员'
when job = 'MANAGER' then '经理'
when job = 'SALESMAN' then '销售人员'
else job end) as 'job' , job
from emp;
mysql查询
加强
介绍:
在前面我们讲过mysql表的基本查询,但是都是对一张表进行的查询,在实际的软件开发中,还远远不够。
下面我们讲解的过程中,将使用前创建 三张表
(emp,dept,salgrade)演示如何进行多表查询
使用 where子句
?如何查找1992.1.1 之后入职的员工
如何使用 like操作符
%:表示0到多个任意字符 _:表示单个任意字符
?如何显示首字母为S的员工姓名和工资
?如何显示第三个字符为大写O的所有员工的员工的姓名和工资
如何显示没有上级的雇员的情况
查询表结构
使用order by子句
?如何按照工资的从低到高的顺序,显示雇员的信息
?按照部门号升序而雇员的工资降序排列,显示雇员信息
-- 查询加强
-- 使用 where子句
-- ?如何查找1992.1.1 之后入职的员工
-- 说明:在mysql中,日期类型可以直接比较,需要注意格式
select * from emp where hiredate > '1992-01-01';
-- 如何使用 like操作符(模糊查询)
-- %:表示0到多个任意字符 _:表示单个任意字符
-- ?如何显示首字母为S的员工姓名和工资
select ename, sal from emp where ename like 'S%';
-- ?如何显示第三个字符为大写O的所有员工的员工的姓名和工资
select ename, sal from emp where ename like '__O%';
-- 如何显示没有上级的雇员的情况
select * from emp where mgr is null;
-- 查询表结构
desc emp;
show create table emp;
-- 使用order by子句
-- ?如何按照工资的从低到高的顺序,显示雇员的信息
select * from emp order by sal asc;
-- ?按照部门号升序而雇员的工资降序排列,显示雇员信息
select * from emp order by deptno asc, sal desc;
分页查询
1、按雇员的id号升序取出,每页显示3条记录,请分别显示 第1页,第2页,第3页
2、基本语法:select ... limit start, rows:表示从 start+1 行开始取,取出rows,start 从0开始计算
3、公式:select .... limit 每页显示记录数 * (第几页 -1), 每页显示记录数
练习:
按雇员的id号降序取出,每页显示5条记录。请分别显示 第3页,第5页 对应的sql语句
-- 分页查询
-- 按雇员的id号升序取出,每页显示3条记录,请分别显示 第1页,第2页,第3页
-- 第1页
select * from emp order by empno
limit 0, 3;
-- 第2页
select * from emp order by empno
limit 3, 3;
-- 第3页
select * from emp order by empno
limit 6, 3;
-- 推导一个公式
select * from emp order by empno
limit 每页显示记录数 * (第几页 -1), 每页显示记录数
-- 按雇员的id号降序取出,每页显示5条记录。请分别显示 第3页,第5页 对应的sql语句
-- 第3页
select * from emp order by empno desc limit 10, 5;
-- 第5页
select * from emp order by empno desc limit 20, 5;
使用分组函数和分组子句
group by
(1)显示每种岗位的雇员总数、平均工资
(2)显示雇员总数,以及获取补助的雇员数
(3)显示管理者的总人数
(4)显示雇员工资的最大差额
-- 增强group by 的使用
-- (1)显示每种岗位的雇员总数、平均工资
select count(*), avg(sal), job from emp group by job;
-- (2)显示雇员总数,以及获取补助的雇员数
-- 思路:获取补助的雇员数 就是 comm 列为非null,就是comm(列),如果该列的值为null,是不会统计的
select count(*), count(comm) from emp;
-- 扩展:统计没有获取补助的雇员数
select count(*), count(if(comm is null, 1, null)) from emp;
select count(*), count(*) - count(comm) from emp;
-- (3)显示管理者的总人数
select count(distinct mgr) from emp;
-- (4)显示雇员工资的最大差额
-- 思路:max(sal) - min(sal)
select max(sal) - min(sal) from emp;
数据分组的总结
如果select语句同时包含有group by, having, limit, order by那么它们的顺序是group by, having, order by, limit
应用案例:
请统计各个部门的平均工资,并且是大于1000的,并且按照平均工资从第高到低排序,取出前两行记录
SELECT column1, column2, column3 ... FROM table_name
group by column
having condition
order by column
limit start, rows;
-- 请统计各个部门 group by 的平均工资,avg
-- 并且是大于1000的 having,并且按照平均工资从第高到低排序 order by,
-- 取出前两行记录 limit
select deptno, avg(sal) as avg_sal from emp
group by deptno
having avg_sal > 1000
order by avg_sal desc
limit 0, 2;
mysql多表查询
笛卡尔集
select * from emp, dept;

emp表有13条记录

dept表有4条记录

在默认的情况下:当两个表查询时,规则如下:
1、从第一张表,取出一行 和第二张的每一行进行组合,返回结果[含有两张表的所有列]
2、一共返回的记录数 第一张表的行数 * 第二张表的的行数 = 13 * 4 = 52
3、这样多表查询默认处理返回的结果,称为 笛卡尔集
4、解决这个表的关键就是写出正确的过滤添加条件 where 需要程序员进行分析

说明
多表查询是指基于两个和两个以上的表查询,在实际应用中,查询单个表可能不能满足你的需求。(使用dept表和emp表练习)
多表查询练习
?显示雇员名,雇员工资及所在的部门名字【笛卡尔集】
小技巧:多表查询的条件不能少于 表的个数-1,否则会出现笛卡尔集
?如何显示部门号为10的部门名、员工名和工资
?显示各个员工的姓名,工资,及其工资的级别
练习:显示雇员名,雇员工资及所在部门的名字,并按部门排序[降序]
-- 多表查询
-- ?显示雇员名,雇员工资及所在的部门名字【笛卡尔集】
# 分析: 1. 雇员名,雇员工资 来自 emp表
# 2. 部门的名字 来自 dept表
# 3. 需求对 emp 和 dept 两表查询
# 4. 当我们需要指定显示某个表的列名时,需要 表.列名
select ename, sal, dname, emp.deptno from emp, dept where emp.deptno = dept.deptno;
-- 小技巧:多表查询的条件不能少于 表的个数-1,否则会出现笛卡尔集
-- ?如何显示部门号为10的部门名、员工名和工资
select ename, sal, dname, emp.deptno from emp, dept
where emp.deptno = dept.deptno and emp.deptno = 10;
-- ?显示各个员工的姓名,工资,及其工资的级别
# 思路:姓名,工资 来自 emp表 13条记录
# 工资的级别 来自 salgrade表 5条记录
select ename, sal, grane from emp, salgrade where sal between losal and hisal;
-- 显示雇员名,雇员工资及所在部门的名字,并按部门排序[降序]
# 思路:雇员名,雇员工资 来自 emp表
# 部门的名字 来自 dept表
select ename, sal, dname, emp.deptno from emp, dept
where emp.deptno = dept.deptno order by emp.deptno desc;
自连接
自连接是指在同一张表的连接查询【将同一张表看做两张表】。
思考题:显示公司员工名字和他的上级的名字
-- 多表查询的 自连接
-- 思考题:显示公司员工名字和他的上级的名字
# 分析:员工名字 在 emp表,上级的名字 emp表
# 员工和上级是通过 emp表的 mgr 列关联的
select woker.ename as '职员', boss.ename as '上级名' from emp woker, emp boss
where woker.mgr = boss.empno;
小结:
自连接的特点:1、把同一张表当做两张表使用; 2、需要给表别名【表名 表别名】;3、如果列名不明确,可以指定列的别名【列名 as 列的别名】
子查询
什么是子查询
子查询是指嵌入在其它sql语句中的select语句,也叫嵌套查询
单行子查询
单行子查询是指只返回一行数据的子查询语句
思考:如何显示与SMITH同一部门的所有员工?
多行子查询
多行子查询指返回多行数据的子查询 使用关键字 in
练习;
如何查询和部门10的工作相同的雇员的名字、岗位、工资、模部门号,但是不含10号部门自己的雇员。
-- 子查询
-- 思考:如何显示与SMITH同一部门的所有员工?
# 分析: 1. 先查询到 SMITH的部门编号得到
select deptno from emp where ename = 'SMITH';
# 2. 把上面的select 语句当做一个子查询来使用
-- 下面的是答案
select * from emp
where deptno = (select deptno from emp where ename = 'SMITH');
-- 练习;
-- 如何查询和部门10的工作相同的雇员的名字、
-- 岗位、工资、模部门号,但是不含10号部门自己的雇员。
# 分析:1.查询10部门有哪些工作
select distinct job from emp where deptno = 10;
# 2.把上面的select 语句当做一个子查询来使用
-- 下面语句是完整的
select ename, job, sal, deptno from emp
where job in (select distinct job from emp where deptno = 10)
and deptno <> 10;
子查询临时表
子查询当做临时表使用
练习:查询ecshop中各个类别中,价格最高的商品
提示:可以将子查询当做一张临时表使用
-- 查询ecshop中各个类别中,价格最高的商品
-- 查询 商品表
select goods_id, cat_id, goods_name, shop_price from ecs_goods;
-- 先得到 各个类别中,价格最高的商品 max + group by cat_id, 当做临时表
-- 把子查询当做一张临时表可以解决很多复杂问题的查询
select cat_id, max(shop_price) from ecs_goods group by cat_id;
-- 下面是完整的语句
select goods_id, ecs_goods.cat_id, goods_name, shop_price from
(select cat_id, max(shop_price) as max_price from ecs_goods group by cat_id) temp,
ecs_goods where temp.cat_id = ecs_goods.cat_id
and temp.max_price = ecs_goods.shop_price;
all和any
在多行子查询中使用all操作符
在多行子查询中使用any操作符
思考:如何显示工资不部门30的所有员工的工资高的员工的姓名、工资和部门号
思考:如何显示工资比部门30的其中一个员工的工资高的员工的姓名、工资和部门号
-- all 和 any的使用
-- 思考:如何显示工资不部门30的所有员工的工资高的员工的姓名、工资和部门号
select ename, sal, deptno from emp
where sal > all(select sal from emp where deptno = 30);
-- 或者
select ename, sal, deptno from emp
where sal > (select max(sal) from emp where deptno = 30);
-- 思考:如何显示工资比部门30的其中一个员工的工资高的员工的姓名、工资和部门号
select ename, sal, deptno from emp
where sal > any(select sal from emp where deptno = 30);
-- 或者
select ename, sal, deptno from emp
where sal > (select min(sal) from emp where deptno = 30);
多列子查询
多列子查序则是指返回多个列数据的子查询语句
练习:请查询 和宋江数学,英语,语文,成绩完全相同的学生
思考:如何查询与smith的部门和岗位完全相同的使用雇员(并且不含allen本人)
(字段1, 字段2,...) = (select 字段1, 字段2 from ...)
-- 多列子查询
-- 思考:如何查询与allen的部门和岗位完全相同的使用雇员(并且不含smith本人)
-- (字段1, 字段2,...) = (select 字段1, 字段2 from ...)
# 分析:1、 得到smith的部门和岗位
select deptno, job from emp where ename = 'ALLEN';
# 2、把上面的查询当做子查询来使用,并且使用多列子查询的语法进行匹配
select * from emp
where (deptno, job) = (select deptno, job from emp where ename = 'ALLEN')
and ename != 'ALLEN';
-- 练习:请查询 和宋江数学,英语,语文,成绩完全相同的学生
select * from student
where (math, english, chinese) = (
select math, english, chinese from student where `name` = '宋江');
子查询练习
在from子句中使用子查询
思考:查询每个部门工资高于本部门平均工资的人的资料
这里要使用到查询的小技巧,把一个子查询当做一个临时表使用
思考:查找每个部门工资最高的人的详细资料
查询每个部门的信息(包括:部门名,编号,地址)和人员数量
思路:
1、先将人员信息和部门信息相关信息显示
2、然后统计
-- 子查询练习
-- 思考:查询每个部门工资高于本部门平均工资的人的资料
# 1. 先得到每个部门的 部门号 和 对应的平均工资
select deptno, avg(sal) as avg_sal from emp group by deptno;
# 2. 把上面的结果当做子查询, 和 emp 进行多表查询
select emp.deptno, ename, sal, avg_sal from emp,
(select deptno, avg(sal) as avg_sal from emp group by deptno) temp
where emp.deptno = temp.deptno and emp.sal > temp.avg_sal;
-- 思考:查找每个部门工资最高的人的详细资料
select emp.deptno, ename, sal, max_sal from emp,
(select deptno, max(sal) as max_sal from emp group by deptno) temp
where emp.deptno = temp.deptno and emp.sal = temp.max_sal;
-- 查询每个部门的信息(包括:部门名,编号,地址)和人员数量
-- 思路:
-- 1、先将人员信息和部门信息相关信息显示
-- 2、然后统计
# 1. 部门名,编号,地址 来自 dept表
# 2. 各个部门的人员数量 =》 构建一个临时表
select count(*), deptno from emp group by deptno;
-- 下面是完整语句
select dname, dept.deptno, loc, per_num as '人数' from dept,
(select count(*) as per_num, deptno from emp group by deptno) temp
where dept.deptno = temp.deptno;
-- 或者还有一种写法 表.* 表示将该表所有列都显示出来
-- 在多表查询中,当多个表的列不重复时,才可以直接写列名
select temp.*, dname, loc from dept,
(select count(*) as per_num, deptno from emp group by deptno) temp
where dept.deptno = temp.deptno;
表复制
自我复制数据(蠕虫复制)
有时,为了对某个sql语句进行效率测试,我们需要海量数据时,可以使用此方法为表创建数据
思考:然后删除掉一张表重复记录
-- 表的复制
-- 为了对某个sql语句进行效率测试,我们需要海量数据时,可以使用此方法为表创建数据
create table my_tab01(
id int, `name` varchar(32), sal double, job varchar(32), deptno int);
desc my_tab01;
select * from my_tab01;
-- 演示如何自我复制
-- 1. 先把emp 表的记录复到 my_tab01
insert into my_tab01(id, `name`, sal, job, deptno)
select empno, ename, sal, job, deptno from emp;
-- 2. 自我复制
insert into my_tab01
select * from my_tab01;
select count(*) from my_tab01;
-- 思考:然后删除掉一张表重复记录
-- 1. 先创建一张表 my_tab02
-- 2. 让my_tab02 有重复的记录
create table my_tab02 like emp; -- 这个语句 把emp表结构(列),复制到 my_tab02
desc my_tab02;
-- 添加数据
insert into my_tab02
select * from emp;
select * from my_tab02;
-- 3. 考虑去重 my_tab02的记录
# 思路:(1)先创建一张临时表 my_temp,该表的结构和 my_tab02一样
create table my_temp like my_tab02;
# (2) 把 my_temp 的记录 通过 distinct 关键字 处理后 把记录复制到 my_temp
insert into my_temp select distinct * from my_tab02;
# (3) 清楚掉 my_tab02 所有记录
delete from my_tab02;
# (4) 把 my_temp 表记录复制到 my_tab02
insert into my_tab02 select distinct * from my_temp;
# (5) drop 掉 临时表 my_temp
drop table my_temp;
合并查询
介绍
有时在实际应用中,为了合并多个select语句的结果,可以使用集合操作符
union、union all
1、union all
该操作符用于取得两个结果集的并集。当使用该操作符时,不会取消重复行。
select ename, sal, job from emp where sal > 2500 union all
select ename, sal, job from emp where job = 'MANAGER';
2、union
该操作符与union all 相似,但是会 自动去掉结果集合中重复的行
select ename, sal, job from emp where sal > 2500 union
select ename, sal, job from emp where job = 'MANAGER';
-- 合并查询
-- union all 就是将两个查询结果合并,不会去重
select ename, sal, job from emp where sal > 2500
union all
select ename, sal, job from emp where job = 'MANAGER';
-- union 就是将两个查询结果合并,会去重
select ename, sal, job from emp where sal > 2500
union
select ename, sal, job from emp where job = 'MANAGER';
mysql表外连接
提出一个问题
1、前面我们学习的查询,是利用 where 子句对两张表或多张表,形成的迪卡尔积进行筛选,根据关联条件,显示所有匹配的记录,匹配不上的,不显示
2、比如:列出部门名称和这些部门的员工名称和工作,同时要求 显示出哪些没有员工的部门
3、使用我们学习过的多表查询的SQL,看看效果如何? --> 外连接
-- 外连接
-- 比如:列出部门名称和这些部门的员工名称和工作,
-- 同时要求 显示出哪些没有员工的部门
-- 使用我们学习过的多表查询的SQL,看看效果如何?
select dname, ename, job from emp, dept
where emp.deptno = dept.deptno order by dname; -- 少了 一个部门
外连接
1、LEFT JOIN .. ON ..左外连接 (如果左侧的表完全显示我们就是说是左连接)
2、RIGHT JOIN .. ON .. 右外连接 (如果右侧的表完全显示我们就是说是左连接)
3、使用左外连接(显示所有人的成绩,如果没有成绩,也要显示该人的姓名和id号)
select ... from 表1 left join 表2 on 条件.. [表1:就是左表 表2:就是右表]
4、使用右外连接(显示所以成绩,如果没有名字匹配,显示空)
select ... from 表1 right join 表2 on 条件.. [表1:就是左表 表2:就是右表]
-- 外连接
-- 比如:列出部门名称和这些部门的员工名称和工作,
-- 同时要求 显示出哪些没有员工的部门
-- 使用我们学习过的多表查询的SQL,看看效果如何?
select dname, ename, job from emp, dept
where emp.deptno = dept.deptno order by dname; -- 少了 一个部门
-- 创建 stu
create table stu(id int,`name` varchar(32));
insert into stu values(1,'jack'),(2,'tom'),(3,'kity'),(4,'nono');
select * from stu;
-- 创建 exam
create table exam(id int,grade int);
insert into exam values(1,56),(2,76),(11,8);
select * from exam;
-- 使用左连接
-- (显示所有人的成绩,如果没有成绩,也要显示该人的姓名和id号)
select `name`, stu.id, grade from stu, exam
where stu.id = exam.id;
-- 改成左外连接
select `name`, stu.id, grade from stu left join exam
on stu.id = exam.id;
-- 右外连接
-- (显示所以成绩,如果没有名字匹配,显示空)
-- 即:右边的表(exam)和左表没有匹配的记录,也会把右表的记录显示出来
select `name`, exam.id, grade from stu right join exam
on stu.id = exam.id;
练习
列出部门名称和这些部门的员工信息(名字和工作),同时列出哪些没有员工的部门
1、使用左外连接实现
2、使用右外连接实现
-- 列出部门名称和这些部门的员工信息(名字和工作),同时列出哪些没有员工的部门
-- 1、使用左外连接实现
select dname, dept.deptno, ename, job from dept left join emp
on dept.deptno = emp.deptno;
-- 2、使用右外连接实现
select dname, dept.deptno, ename, job from emp right join dept
on dept.deptno = emp.deptno;
小结:在实际开发中,我们绝大多数情况下使用的是 前面学过的连接【两表或多表一起查询】
mysql约束
基本介绍
约束用于确保数据库满足特定的商业规则。
在mysql中,约束包括:not null、unique、primary key、foregin key和check五种
primary key(主键)
字段名 字段类型 primary key
用于唯一的标识表行的数据,当定义主键约束后,该列不能重复
-- 主键使用
-- id name email
create table t16(
`id` int primary key, -- 表示id列是主键列
`name` varchar(32),
email varchar(32)
);
-- 主键列的值是不可以重复的
insert into t16 values(1,'jack','jack@sohu.com');
insert into t16 values(2,'tom','tom@sohu.com');
insert into t16 values(1,'zzp','zzp@sohu.com'); -- 错误 Duplicate entry '1' for key 'PRIMARY'
select * from t16;
primary key(主键) - 细节说明
1、primary key不能重复而且不能为null
2、一张表最多只能有一个主键,但可以是复合主键
3、主键的指定方式 有两种
- 直接在字段名后指定:
字段名 primary kek - 在表定义最后写
primary key(列名)
4、使用desc 表名,可以看到primary key的情况
5、提醒:在实际开发中,每个表往往都会设计一个主键。
-- primary key(主键) - 细节说明
-- 1、primary key不能重复而且不能为null
insert into t16 values(null,'zzp','zzp@sohu.com'); -- 错误 Column 'id' cannot be null
-- 2、一张表最多只能有一个主键,但可以是复合主键
create table t18(
`id` int primary key, -- 表示id列是主键列
`name` varchar(32) primary key, -- 错误 Multiple primary key defined
email varchar(32)
);
-- 主键列
create table t18(
`id` int primary key, -- 表示id列是主键列
`name` varchar(32),
email varchar(32)
);
-- 演示复合主键 (id 和 name 做成复合主键)
create table t18(
`id` int,
`name` varchar(32),
email varchar(32),
primary key(id,`name`) -- 这里就是复合主键
) ;
insert into t18 values(1,'tom','tom@sohu.com');
insert into t18 values(1,'jack','jack@sohu.com');
insert into t18 values(1,'tom','xx@sohu.com'); -- 错误违反了复合主键 Duplicate entry '1-tom' for key 'PRIMARY'
select * from t18;
-- 3、主键的指定方式 有两种
-- 直接在字段名后指定:字段名 primary kek
-- 在表定义最后写 primary key(列名)
create table t19(
`id` int,
`name` varchar(32) primary key, -- 直接在字段名后指定:字段名 primary kek
email varchar(32)
);
create table t20(
`id` int,
`name` varchar(32),
email varchar(32),
primary key(`name`) -- 在表定义最后写 primary key(列名)
);
-- 4、使用desc 表名,可以看到primary key的情况
desc t20; -- 查看 t20表结果,显示约束的情况
desc t18;
not null(非空)
如果在列上定义了not null,那么当插入数据时,必须为列提供数据
字段名 字段类型 not null
unique(唯一)
当定义唯一约束后,该列值是不能重复的
字段名 字段类型 unique
unique 细节(注意):
1、如果没有指定 not null,则 unique 字段可以有多个null
2、一张表可以有多个unique字段
-- unique的使用
create table t21(
`id` int unique, -- 表示 id列是不可以重复的
`name` varchar(32),
email varchar(32)
);
insert into t21 values(1,'jack','jack@sohu.com');
insert into t21 values(1,'tom','tom@sohu.com'); -- 错误 Duplicate entry '1' for key 'id'
select * from t21;
-- unique 细节(注意):
-- 1、如果没有指定 not null,则 unique 字段可以有多个null
-- 如果一列(字段),是 unique not null 使用效果类似 primary key
insert into t21 values(null,'tom','tom@sohu.com');
insert into t21 values(null,'tom','tom@sohu.com');-- 成功
insert into t21 values(null,'tom','tom@sohu.com');-- 成功
-- 2、一张表可以有多个unique字段
create table t22(
`id` int unique, -- 表示 id列是不可以重复的
`name` varchar(32) unique,-- 表示 name列是不可以重复的
email varchar(32)
);
desc t22;

foreign key(外键)
用于定义主表和从表之间的关系:外键约束要定义在从表上,主表则必须具有主键约束或是unique约束,当定义外键约束后,要求外键列数据必须在主表的主键列存在或是为null
FOREIGN KEY (本表字段名) PEFERENCES
主表名(主键名或unique字段名)
外键示意图:
在学生表插入一条class_id=300 会失败,因为在班级表没有id=300的记录

在班级表删除id=200的记录会失败,因为在学生表有200的记录,
除非先删除学生表的记录,在删除班级表的记录

班级表(主表) – 学生表(外键所在表)

-- 外键演示
-- 创建 班级表 主表
create table my_class(
id int primary key, -- 外键约束要定义在从表上,主表则必须具有主键约束或是`unique`约束
`name` varchar(32) not null default ''
);
-- 创建 学生表 从表
create table my_stu(
id int primary key, -- 学生编号
`name` varchar(32) not null default '',
class_id int, -- 学生所在班级的编号
-- 下面指定外键关系 references:参考/指向
foreign key (class_id) references my_class(id)
);
-- 测试数据
insert into my_class values(100,'java'),(200,'web');
select * from my_class;
insert into my_stu values(1,'tom',100);
insert into my_stu values(2,'jack',200);
-- 下面语句会失败 Cannot add or update a child row: a foreign key constraint fails (`zzp_db02`.`my_stu`, CONSTRAINT `my_stu_ibfk_1` FOREIGN KEY (`class_id`) REFERENCES `my_class` (`id`))
insert into my_stu values(3,'zzp',300); -- 错误 因为300班级不存在
select * from my_stu;
foreign key(外键) – 细节说明
1、外键指向的表的字段,要求是primary key或者是 unique
2、表的类型是innodb,这样的表才支持外键
3、外键字段的类型要和主键字段的类型一致(长度可以不同)
4、外键字段的值,必须在主键字段中出现过,或者为null【前提是外键字段允许为ull】
5、一旦建立主外键的关系,数据不能随意删除了
insert into my_stu values(4,'zzp',null); -- 可以,外键 没有写 not null
-- 一旦建立主外键的关系,数据不能随意删除了
-- Cannot delete or update a parent row: a foreign key constraint fails (`zzp_db02`.`my_stu`, CONSTRAINT `my_stu_ibfk_1` FOREIGN KEY (`class_id`) REFERENCES `my_class` (`id`))
delete from my_class where id = 100; -- 删除不了
check
用于强制行数据必须满足的条件,假定在 sal 列上定义了 check约束,并要求 sal列值在 1000~2000 之间如果不在 1000~2000之间就会提示出错
提示:oracle和sql server均支持check,但是mysql5.7目前还不支持check,只做语法效验,但不会生效
基本语法:列名 类型 check (check条件)
在mysql中实现check的功能,一般在程序中控制,或者通过触发器完成。
-- 演示check的使用
-- mysql5.7目前还不支持`check`,只做语法效验,但不会生效
-- oracle,sql server,这两个数据库是真的生效
-- 测试
create table t23(
id int primary key,
`name` varchar(32),
sex varchar(6) check (sex in ('man','woman')),
sal double check (sal > 1000 and sal <2000)
);
-- 添加数据
insert into t23 values(1,'jack','mid',1); -- 成功
select * from t23;
商店表设计
现有一个商品店的数据库shop_db,记录客户及其购物情况,由下面三个表组成:
商品goods(商品号goods_id,商品名goods_name,单价unitprice,商品类别category,供应商provider)
客户customer(客户号customer_id,姓名name,住址address,电邮email,性别sex,身份证card_id)
购买purchase(购买订单号order_id,客户号customer_id,商品号goods_id,购买数量nums)
1、建表,在定义中要求声明【进行合理设计】:
(1)每个表的主外键
(2)客户的姓名不能为空值
(3)电邮不能够重复
(4)客户的性别【男】【女】check 枚举…
(5)单价unitprice 在 1.0 ~ 9999.99 之间 check
-- 使用约束的练习
-- 创建数据库
create database shop_db;
/*
现有一个商品店的数据库shop_db,记录客户及其购物情况,由下面三个表组成:
商品goods(商品号goods_id,商品名goods_name,单价unitprice,商品类别category,供应商provider)
客户customer(客户号customer_id,姓名name,住址address,电邮email,性别sex,身份证card_id)
购买purchase(购买订单号order_id,客户号customer_id,商品号goods_id,购买数量nums)
1、建表,在定义中要求声明【进行合理设计】:
(1)每个表的主外键
(2)客户的姓名不能为空值
(3)电邮不能够重复
(4)客户的性别【男】【女】check 枚举…
(5)单价unitprice 在 1.0 ~ 9999.99 之间 check
*/
-- 创建商品表
create table goods(
goods_id int primary key,
goods_name varchar(64) not null default '',
untiprice decimal(10.2) not null default 0
check (untiprice >= 1.0 and untiprice <= 9999.99),
category int not null default 0,
provider varchar(64) not null default ''
);
-- 创建客户表
create table customer(
customer_id char(8) primary key, -- 程序员自己定义
`name` varchar(64) not null default '',
address varchar(64) not null default '',
email varchar(64) unique not null,
sex enum('男','女') not null, -- 使用枚举类型,是生效的
card_id char(18)
);
-- 创建购买表
create table purchase(
order_id int unsigned primary key,
customer_id char(8) not null default '', -- 外键约束在后
goods_id int not null default 0, -- 外键约束在后
nums int not null default 0,
foreign key (customer_id) references customer(customer_id),
foreign key (goods_id) references goods(goods_id)
);
desc goods;
desc customer;
desc purchase;
自增长
在某张表中,存在一个id列(整数),我们希望在添加记录的时候,该列从1开始,自动的增长,怎么处理? —》 自增长
基本语法:
字段名 整型 primary key auto_increment
添加 自增长的字段方式
insert into xxx (字段1, 字段2) values (null, '值'...);
insert into xxx (字段2, ...) values ('值1', '值2'...);
insert into xxx values (null, '值'...);
-- 演示自增长的使用
-- 创建表
create table t24(
id int primary key auto_increment,
email varchar(32) not null default '',
`name` varchar(32) not null default ''
);
-- 测试自增长的使用
insert into t24 values(null,'jack@qq.com','jack');
insert into t24 values(null,'tom@qq.com','tom');
insert into t24 (email,`name`) values('zzp@qq.com','zzp');
desc t24;
select * from t24;
自增长使用细节
1、一般来说自增长是和primary key 配合使用的
2、自增长也可以单独使用【但是需要配合一个unique】
3、自增长修饰的字段为整数类型的(虽然小数也可以但是非常非常少这样使用)
4、自增长默认从 1开始,你也可以通过如下命令修改
alter table 表名 auto_increment = 新的开始值;
5、如果你添加数据时,给自增长字段(列)指定的有值,则以指定的值为准,如果指定了自增长,一般来说,就按照自增长的规则来添加
-- 新建表
create table t25(
id int primary key auto_increment,
email varchar(32) not null default '',
`name` varchar(32) not null default ''
);
-- 修改默认的自增长开始值
alter table t25 auto_increment = 100;
insert into t25 values(null,'jack@qq.com','jack');
-- 如果你添加数据时,给自增长字段(列)指定的有值,则以指定的值为准
insert into t25 values(666,'zzp@qq.com','zzp');
select * from t25;
mysql索引
说起提高数据库性能,索引是最物美价廉的东西。不用加内存,不用改程序,不用调sql,查询速度就可能提高百倍千倍。
举例说明索引的好处【构建海量表8000000】
-- 创建测试数据库 tmp
create database tmp;
# 部门表
CREATE TABLE `dept` (
`deptno` MEDIUMINT(8) UNSIGNED NOT NULL DEFAULT '0',
`dname` VARCHAR(20) NOT NULL DEFAULT '',
`loc` VARCHAR(13) NOT NULL DEFAULT ''
) ENGINE=INNODB DEFAULT CHARSET=utf8;
# 员工表
CREATE TABLE `emp` (
`empno` MEDIUMINT(8) UNSIGNED NOT NULL DEFAULT '0',/*编号*/
`ename` VARCHAR(20) NOT NULL DEFAULT '',/*名字*/
`job` VARCHAR(9) NOT NULL DEFAULT '',/*工作*/
`mgr` MEDIUMINT(8) UNSIGNED DEFAULT 0,/*上级编号*/
`hiredate` DATE NOT NULL,/*入职时间*/
`sal` DECIMAL(7,2) NOT NULL,/*薪水*/
`comm` DECIMAL(7,2) DEFAULT NULL,/*红利*/
`deptno` MEDIUMINT(8) UNSIGNED NOT NULL DEFAULT '0'
) ENGINE=INNODB DEFAULT CHARSET=utf8;
# 工资级别表
CREATE TABLE `salgrade` (
`grane` MEDIUMINT(8) UNSIGNED NOT NULL DEFAULT '0',
`losal` DECIMAL(17,0) NOT NULL,
`hisal` DECIMAL(17,0) NOT NULL
) ENGINE=INNODB DEFAULT CHARSET=utf8;
# 测试数据
INSERT INTO salgrade VALUES(1,700,1200);
INSERT INTO salgrade VALUES(2,1201,1400);
INSERT INTO salgrade VALUES(3,1401,2000);
INSERT INTO salgrade VALUES(4,2001,3000);
INSERT INTO salgrade VALUES(5,3001,4000);
DELIMITER $$
# 创建一个函数,名字 rand_string,可以随机返回我指定的某个数字字符串
CREATE FUNCTION rand_string(n INT)
RETURNS VARCHAR(255) # 该函数会返回一个字符串
BEGIN
# 定义了一个变量 chars_str,类型 varchar(100)
# 默认给 chars_str 初始值 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYXZ'
DECLARE chars_str VARCHAR(100) DEFAULT
'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYXZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
# concat 函数:连接函数mysql函数
SET return_str = CONCAT(return_str, SUBSTRING(chars_str, FLOOR(1 + RAND()*52), 1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END $$
# 这里我们又定义了一个函数,返回一个随机的部门号
CREATE FUNCTION rand_num()
RETURNS INT(5)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(10 + RAND()*500);
RETURN i;
END $$
# 创建一个存储过程,可以添加雇员
CREATE PROCEDURE insert_emp(IN START INT(10), IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
# set autocommit = 0 把aitocommit设置成0
# autocommit = 0 含义:不要自动提交
SET autocommit = 0; #默认不提交sql语句
REPEAT
SET i = i + 1;
# 通过前面写的函数随机产生字符串和部门编号,然后加入到emp表
INSERT INTO emp VALUES ((START + i), rand_string(6), 'SALESMAN', 0001, CURDATE(), 2000, 400, 3);
UNTIL i = max_num
END REPEAT;
# commit整体提交所有sql语句,提高效率
COMMIT;
END $$
# 添加8000000数据
CALL insert_emp(100001,8000000)$$
# 命令结束符,再重新设置为;
DELIMITER ;
上面执行耗时可能需要7、8分钟,耐心等待
在本地的文件夹中可以看到生成数据库的表的大小:635M

查询emp数量

随机查询一条emp数据,看响应时长:3.844秒

SELECT COUNT(*) FROM emp;
-- 在没有创建索引时,随机查询一条数据记录
SELECT * FROM emp WHERE empno = 123456;
-- 使用索引来优化一下,体验索引的好处
-- 在没有创建索引前,emp.ibd 文件大小 635m
-- 创建索引后 emp.ibd 文件大小 667m 【索引本身也会占用空间】
-- empno_index 索引名称
-- ON emp (empno) :表示 emp表的 empno列创建索引
CREATE INDEX empno_index ON emp (empno);
创建索引后,emp.ibd 文件变大:

创建索引后,查询速度:0.004秒

是不是建立一个索引就能解决使用问题?
ename上没有建立索引会怎样?
select * from emp where ename = 'axJxC';

索引的原理
没有索引为什么会慢?【因为会全表扫描】
使用索引为什么会快?【会形成一个索引的数据结构,比如:二叉树等等】
索引的代价
- 1、 磁盘占用
- 2、对
dml(update delete insert)语句的效率影响

在项目中,select(90%) 是比 update,delete,insert(10%) 操作更多
索引的类型
1、主键索引,主键自动的为主索引(类型Primary key)
2、唯一索引(UNIQUE)
3、普通索引(INDEX)
4、全文索引(FULLTEXT)[适用于MySAM]
一般开发,不使用mysql自带的全文索引,而是使用:全文搜索 Solr 和 ElasticSearch(ES)
create table t1(
in int primary key, -- 主键,同时也是索引,称为 主键索引
`name` varchar(32)
);
create table t2(
in int unqiue, -- id是唯一的,同时也是索引,称为 unique索引
`name` varchar(32)
);
索引使用
1、添加索引(建测试表 id, name)
create [UNIQUE] index_name on table_name (col_name[(length)] [ASC|DESC], ...)
alter table table_name ADD INDEX [index_name] (index_col_name, ...)
2、添加主键(索引) ALTER TABLE 表名 ADD PRIMARY KEY (列名, ...)
3、删除索引
DROP INDEX index_name ON table_name;
alter table table_name drop index index_name;
4、删除主键索引 比较特别:
alter table table_name drop primary key;
5、查询索引(三种方式)
show index(es) from table_name;
show keys from table_name'
desc tales_name;
-- 演示mysql的索引使用
-- 创建表
create table t25(
id int,
`name` varchar(32)
);
-- 查询表是否有索引
show index from t25;
-- 添加索引
-- 添加唯一索引
create unique index id_index on t25 (id);
-- 添加普通索引方式1
create index id_index on t25 (id);
-- 如何选择索引
-- 1. 如果某列的值,是不会重复的,则优先考虑使用 unique索引,否则使用普通索引
-- 添加普通索引方式2
alter table t25 add index id_index (id);
-- 添加主键索引
-- 直接在创建表 在字段加 primary key
create table t26(
id int primary key,
`name` varchar(32)
);
-- 或者
alter table t26 add primary key (id);
show index from t26;
-- 删除索引
drop index id_index on t25;
-- 删除主键索引
alter table t26 drop primary key;
-- 修改索引,先删除索引,在添加新的索引
-- 查询索引
-- 1. 方式1
show index from t26;
-- 2. 方式2
show indexes from t25;
-- 3. 方式3
show keys from t25;
-- 4. 方式4
desc t25;
小结
哪些列上适合使用索引
1、较频繁的作为查询条件字段应该创建索引
select * from emp where empno = 1;
2、唯一性太差的字段不适合单独创建索引,即频繁作为查询条件
select * from emp where sex = '男';
3、更新非常频繁的字段不适合创建索引
select * from emp where logincount = 1;
4、不会出现在where子句中字段不该创建索引
mysql事务
什么是事务
事务用于保证数据的一致性,它是由一组相关的dml(增,删,改)语句组成,该组的dml语句要么全部成功,要么全部失败。如:转账就要用事务来处理,用以保证数据的一致性。

事务和锁
当执行事务操作时(dml语句),mysql会在表上加锁,防止其它用户改表的数据。
这时用户讲是非常重要的
mysql 数据库控制台事务的几个重要操作
- 1、
start transaction– 开始一个事务 - 2、
savepoint保存点名 – 设置保存点 - 3、
rollback to保存点名 – 回退事务 - 4、
rollback– 回退全部事务 - 5、
commit– 提交事务,所有的操作生效,不能回退
细节:
1、没有设置保存点
2、多个保存点
3、存储引擎
4、开始事务方式
回退事务
在介绍回退事务前,先介绍一下保存点(savepoint)。保存点是事务中的点,用于取消部分事务,当结束事务时,会自动删除该事务所定义所有保存点。
当执行回退事务时,通过指定保存点可以回退到指定的点。
提交事务
使用commit语句可以提交事务,当执行了commit语句之后,会确认事务的变化、结束事务、删除保存点、释放锁、数据生效。当使用commit语句结束事务之后,其它会话[其他连接]将可以查看到事务变化后的新数据[所有数据就正式生效]
-- 事务的一个重要的概念和具体操作
-- 演示
-- 1. 创建一张测试表
create table t27(
id int,
`name` varchar(32)
);
-- 2. 开启事务
start transaction
-- 3. 设置保存点
savepoint a
-- 执行dml操作
insert into t27 values(100,'tom');
select * from t27; -- 1条记录
-- 设置保存点
savepoint b
-- 执行dml操作
insert into t27 values(200,'jack');
select * from t27; -- 2条记录
-- 4. 回退到 b
rollback to b
select * from t27;-- 1条记录
-- 继续回退到 a
rollback to a
select * from t27;-- 0条记录
-- 如果这样 rollback 表示直接回退到事务开始的状态
rollback
-- commit 提交事务,所有的操作生效,不能回退(已删除保存点)
commit
事务细节讨论
1、如果不开始事务,默认情况下,dml操作是自动提交的,不能回滚
2、如果开始一个事务,你没有创建保存点,你可以执行 rollback,默认就是回退到你事务开始的状态
3、你也可以在这个事务中(还没提交时),创建多个保存点。比如:savepoint aa; 执行 dml , savepoint bb;
4、你可以在事务没有提交前,选择回退到哪个保存点。
5、mysql的事务机制需要innodb的存储引擎才可以使用,myisam不好使。
6、开始一个事务 start transaction 或者 set autocommit=off;
-- 事务细节
-- 1. 如果不开始事务,默认情况下,dml操作是自动提交的,不能回滚
insert into t27 values(300,'milan'); -- 自动提交 commit
select * from t27;
-- 2. 如果开始一个事务,你没有创建保存点,你可以执行 rollback,
-- 默认就是回退到你事务开始的状态
start transaction
insert into t27 values(400,'king');
insert into t27 values(500,'scott');
rollback -- 表示直接回退到事务开始的状态
commit
-- 3. 你也可以在这个事务中(还没提交时),创建多个保存点。
-- 比如:savepoint aa; 执行 dml , savepoint bb;
-- 4. 你可以在事务没有提交前,选择回退到哪个保存点。
-- 5. InnoDB 存储引擎支持事务, MyISM 不支持
-- 6. 开始一个事务 start transaction 或者 set autocommit=off;
mysql事务隔离级别
事务隔离级别介绍
1、多个连接开启各自事务操作数据库中数据时,数据库系统要负责隔离操作,以保证各个连接在获取数据时的准确性。
2、如果不考虑隔离性,可能会引发如下问题:
- 脏读
- 不可重复读
- 幻读
查看事务隔离级别
脏读(dirty read):当一个事务读取另外一个事务尚为提交的改变(update,insert,delete)时,产生脏读
不可重复读(nonrepeatable read):同一查询在同一事务中多次进行,由于其他提交事务所做的修改或者删除,每次返回不同结果集,此发生不可重复读。
幻读(phantom read):同一查询在同一事务中多次进行,由于其他提交事务所做的插入操作,每次返回不同的结果集,此时发生幻读。
事务隔离级别
概念: Mysql隔离级别定义了事务与事务之间的隔离程度。
| Mysql隔离级别 | 脏读 | 不可重复读 | 幻读 | 加锁读 |
|---|---|---|---|---|
读未提交(Read uncommitted) | √ | √ | √ | 不加锁 |
读已提交(Read committed) | × | √ | √ | 不加锁 |
可重复读(Repeatable read) | × | × | × | 不加锁 |
可串行化(Serializable) | × | × | × | 加锁 |
说明:√可能出现 ×不会出现
mysql的事务隔离级别 - 案例

下面演示事务隔离级别效果:
查询A控制台的事务隔离级别:

设置B控制台的隔离级别

A控制台和B控制台的隔离级别查询显示,A控制台【可重复读】 B控制台【读未提交】

A、B控制台开启事务

在A控制台创建表(zzp_db02数据库中):
A、B控制台查表:

在A控制台新增一条记录后,B控制台查询[未提交事务](出现脏读)-- 【读未提交隔离级别】

A控制台更新和新增操作,然后提交事务【commit】,B控制台查询结果【未commit提交】(出现 不可重复读 和 幻读)-- 【读未提交隔离级别】

B控制台提交事务:
A控制台在开启事务,B控制台设置隔离级别为 (读已提交)Read committed 并开启事务

A控制台新增一条数据,B控制台查询[未提交事务](不会出现 脏读)-- 【读已提交隔离级别】

A控制台修改一条数据,然后提交事务,B控制台查询[未提交事务](出现 不可重复读 和 幻读)-- 【读已提交隔离级别】

B控制台提交事务:
A控制台在开启事务,B控制台设置隔离级别为 (可重复读)Repeatable read 并开启事务

A控制台新增数据和修改数据,然后提交事务,B控制台查询[未提交事务] (没有出现脏读、不可重复读 和 幻读)-- 【可重复读隔离级别】

B控制台提交事务:
A控制台在开启事务,B控制台设置隔离级别为 (可串行化)Serializable 并开启事务

A控制台新增和修改数据操作,B控制台查不到数据,(卡住)超时显示错误信息 – 【可串行化隔离级别】

A控制台一提交事务,B控制台查询结果 – 【可串行化隔离级别】

-- 演示mysql的事务隔离级别
-- 1. 开启两个mysql控制台
-- 2. 查看当前mysql的隔离级别
select @@tx_isolation;
-- mysql> select @@tx_isolation;
-- +-----------------+
-- | @@tx_isolation |
-- +-----------------+
-- | REPEATABLE-READ |
-- +-----------------+
-- 3.把其中一个控制台的隔离级别设置 Read uncommitted
-- Read committed
-- Repeatable read
-- Serializable
set session transaction isolation level READ UNCOMMITTED;
-- 两个mysql控制台 开启事务
start transaction;
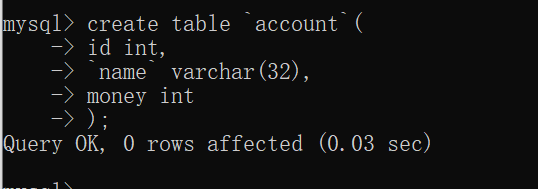
-- 4. 创建表 在zzp_db02数据库中
create table `account`(
id int,
`name` varchar(32),
money int
);
select * from account;
-- 添加记录
insert into account values (100,'tom',1000);
-- 修改
update account set money = 800 where id = 100;
insert into account values (200,'jack',2000);
1、查看当前会话隔离级别
select @@tx_isolation;
2、查看系统当前隔离级别
select @@global.tx_isolation;
3、设置当前会话隔离级别
set session transaction isolation level repeatable read;
4、设置系统当前隔离级别
set global transaction isolation level repeatable read;
5、mysql 默认的事务隔离级别是 repeatable read,一般情况下,没有特殊要求,没有不要修改(因为该级别可以满足绝大部分项目需求)
-- 1、查看当前会话隔离级别
select @@tx_isolation;
-- 2、查看系统当前隔离级别
select @@global.tx_isolation;
-- 3、设置当前会话隔离级别
set session transaction isolation level repeatable read;
-- 4、设置系统当前隔离级别
set global transaction isolation level [你设置的级别];
全局修改,修改 mysql.ini配置文件,在最后面加上
#可选参数有:READ-UNCOMMITTED, READ-COMMITTED, REPEATABLE-READ, SERIALIZABLE
[mysqld]
transaction-isolation = REPEATABLE-READ
mysql事务ACID
事务的acid特性
1、原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
2、一致性(Consistency)
事务必须使数据库从一个一致性状态变换到另外一个一致性状态。
3、隔离性(Isolation)
事务的隔离性是多个用户并发访问数据库时,数据库为每个用户开启事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
4、持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
mysql表类型和存储引擎
基本介绍
1、MySQL 的表类型由存储引擎(Storage Engines)决定,主要包括MyISAM、innoBD、Memory等
2、MySQL 数据表主要支持六中类型,分别是:CSV、Memory、ARCHIVE、MRG_MYISAM、MyISAM、InnoBDB。
3、这六种又分为两类,一类是 “事务安全型”(transaction-safe),比如:InnoDB;其余都属于第二类,称为 “非事务安全型”(non-transaction-safe)【mysiam 和 memory】
显示当前数据库支持所有存储引擎:
show engines;

主要的存储引擎/表类型特点
| 特点 | Myisam | InnoDB | Memory | Archive | |
|---|---|---|---|---|---|
| 批量插入的速度 | 高 | 低 | 高 | 非常高 | |
| 事务安全 | 支持 | ||||
| 全文索引 | 支持 | ||||
| 锁机制 | 表锁 | 行锁 | 表锁 | 行锁 | |
| 存储限制 | 没有 | 64TB | 有 | 没有 | |
| B树索引 | 支持 | 支持 | 支持 | ||
| 哈希索引 | 支持 | 支持 | |||
| 集群索引 | 支持 | ||||
| 数据缓存 | 支持 | 支持 | |||
| 索引缓存 | 支持 | 支持 | 支持 | ||
| 数据可压缩 | 支持 | 支持 | |||
| 空间使用 | 低 | 高 | N/A | 非常低 | |
| 内存使用 | 低 | 高 | 中等 | 低 | |
| 支持外键 | 支持 |
细节说明
这些介绍三种:MyISAM、InnoDB、MEMORY
1、MyISAM不支持事务,也不支持外键,但其访问速度快,对事务完整性没有要求
2、InnoDB存储引擎提供了具体提交、回滚和崩溃恢复能力的事务安全。但是比起
MyISAM存储引擎,InnoDB写的处理效率差一些并且会占用更多的磁盘空间以
保留数据和索引。
3、MEMORY存储引擎使用存在内存中内容来创建表。每个MEMORY表只实际对应
一个磁盘文件。MEMORY类型的表访问非常快,因为它的数据是存放在内存中的,
并且默认使用HASH索引。但是一旦MYSQL服务关闭,表中的数据就会丢失掉,表的结构还在。
三种存储引擎表使用案例
-- innoDB 存储引擎,是前面讲过的
-- 1. 支持事务 2. 支持外键 3. 支持行级锁
-- myisam 存储引擎
create table t28(
id int,
`name` varchar(32)
) engine MYISAM;
-- 1. 添加速度快 2. 不支持外键和事务 3. 支持表级锁
-- 测试事务
start transaction;
savepoint t1;
insert into t28 values(1,'tom');
select * from t28;
rollback to t1; -- 回滚t1
select * from t28; -- 还是有1条记录
-- memory 存储引擎
-- 1. 数据是存储在内存中[关闭mysql服务,数据丢失,但是表结构还在]
-- 2. 执行速度很快(没有IO读写) 3. 默认支持索引(hash表)
create table t29(
id int,
`name` varchar(32)
) engine memory;
insert into t29 values(1,'jack'),(2,'tom'),(3,'zzp');
select * from t29; -- 3条记录
-- 演示效果 关闭开启mysql服务
desc t29;
select * from t29; -- 0条记录
如何选择表的存储引擎
1、如果你的应用不需要事务,处理的只是基本的CRUD操作,那么MyISAM是不二选择,速度快
2、如果需要支持事务,选择InnDB
3、Memory 存储引擎就是将数据存储在内存中,由于没有磁盘I./O的等待,
速度极快。但由于是内存存储引擎,所做的如何修改在服务器重启都将消失。(经典用法 用户的在线状态().)

修改存储引擎
alter table '表名' ENGINE = 存储引擎;
视图(view)
看一个需求
emp 表的列信息很多,有些信息是个人重要信息(比如 sal,comm,mgr,hiredate),
如果我们希望某个用户只能查询emp表的(empno、ename,job 和 deptno)信息,
有什么办法? => 视图

基本概念
1、视图是一个虚拟表,其内容有查询定义。同真实的表一样,视图包括列,其数据来自对应的真实表(基表)
2、视图和基表关系的示意图

视图的基本使用
1、创建:create view 视图名 as select 语句
2、修改:alter view 视图名 as select 语句
3、查看:SHOW CREATE VIEW 视图名
4、删除:drop view 视图名1, 视图名2
创建一个视图 emp_view01,只能查询emp表的(empno,ename,job 和 deptno)信息
-- 视图的使用
-- 创建一个视图 emp_view01,只能查询emp表的(empno,ename,job 和 deptno)信息
-- 创建视图
create view emp_view01 as select empno, ename, job, deptno from emp;
-- 查看视图
desc emp_view01;
-- 查询视图emp_view01表
select * from emp_view01;
select empno,job from emp_view01;
-- 修改视图
alter view emp_view01 as select empno, ename, job, sal, deptno from emp;
select * from emp_view01;
-- 查看视图
show create view emp_view01;
-- 删除视图
drop view emp_view01;
视图细节讨论
1、创建视图后,到数据库去看,对应视图只有一个视图结构文件(形式:视图名.frm)
2、视图的数据变化会影响到基表,基表的数据变化也会影响到视图[insert update delete]
----针对前面的雇员管理系统---
create view myview as select empno,ename,job,comm from emp;
select * from myview;
update myview set comm = 200 where empno = 7369;//修改视图,对基表都有变化
update emp set comm = 100 where empno = 7369;//修改基表,对视图也有变化
3、视图中可以在使用视图,数据仍然来自基表
-- 视图细节
-- 1、创建视图后,到数据库去看,对应视图只有一个视图结构文件(形式:视图名.frm)
-- 2、视图的数据变化会影响到基表,基表的数据变化也会影响到视图[insert update delete]
-- 修改视图 会影响到基表
create view myview as select empno,ename,job,comm from emp;
select * from myview;
update myview set job = 'MANAGER' where empno = 7369;
select * from myview;
select * from emp;
-- 修改基表,会影响视图
update emp set job = 'SALESMAN' where empno = 7369;
-- 3、视图中可以在使用视图,比如从myview 视图中,选出两列empno,ename做出新视图
desc myview;
create view myview02 as select empno,ename from myview;
desc myview02;
select * from myview02;
视图最佳实践
1、安全。一些数据表有着重要信息。有些字段是保密的,不能让用户直接看到。这时就可以创建一个视图,在这张视图中只保留一部分字段。这样,用户就可以查询自己需要的字段,不能查看保密的字段。
2、性能。关系数据库的数据常常会分表存储,使用外键将立这些表的之间关系。这时,数据库查询通常会用到连接(JOIN)。这样做不但麻烦,效率相对也比较低。如果建立一个视图,将相关的表和字段组合在一起,就可以避免使用JOIN查询数据。
3、灵活。如果系统中有一张旧的表,这张表由于设计问题,即将被废弃。然而,很多应用都是基于这张表,不易修改。这时就可以建立一张视图,视图中的数据直接映射到 新建 的表。这样,就可以少做很多改动,也达到升级数据表的目的。
视图练习
针对 emp, dept 和 salgrade 这三张表,创建一个视图(emp_view03),可以显示雇员编号,雇员名,雇员部门名称和薪水级别[即使用三张表,创建一个视图]
-- 练习:
-- 针对 emp, dept 和 salgrade 这三张表,创建一个视图(emp_view03),
-- 可以显示雇员编号,雇员名,雇员部门名称和薪水级别[即使用三张表,创建一个视图]
/*
分析:使用三表联合查询,得到结果
将得到的结果,构建成视图
*/
-- 使用三表联合查询,得到结果
select empno, ename, dname, grane from emp, dept, salgrade
where emp.deptno = dept.deptno
and (sal between losal and hisal);
-- 将得到的结果,构建成视图
create view emp_view03 as select empno, ename, dname, grane from emp, dept, salgrade
where emp.deptno = dept.deptno
and (sal between losal and hisal);
desc emp_view03;
select * from emp_view03;
Mysql用户
mysql中的用户,都存储在系统数据库中mysql.user表中

其中user表的重要字段说明:
1、host:允许登录的 “位置”,localhost表示该用户只允许本地登录,也可以指定ip地址,比如:192.168.1.100
2、user:用户名
3、authentication_string:密码,是通过mysql的password()函数加密之后的密码。
创建用户
create user '用户名'@'允许登录位置' identified by '密码'
说明:创建用户,同时指定密码
-- Mysql用户管理
-- 原因:当我们做项目开发时,可以根据不同的开发人员,赋给他相应的Mysql操作权限
-- 所以,Mysql数据库管理人员(root),根据需要创建不同的用户,赋给相应的权限,供开发人员使用
-- 1. 创建新的用户
-- 解读(1)'zzp'@'localhost' 表示用户的完整信息 'zzp' 用户名 'localhost' 登录的IP
-- (2)'zzp' 密码,但是注意 存放 mysql.user表时,是password('zzp') 加密后的密码
create user 'zzp'@'localhost' identified by 'zzp';
-- 查询 password('zzp') 加密后的密码
select password('zzp');
select `host`,`user`,authentication_string from mysql.user;
-- 2. 删除用户
drop user 'zzp'@'localhost';


登录新建的用户:


删除用户
drop user '用户名'@'允许登录位置';
用户修改密码
修改自己的密码:
set password = password('密码');
修改他人密码(需要有修改用户权限):
set password for '用户名' @'登录位置' = password('密码');
-- 修改自己的密码
set password = password('zzp123');
-- 修改其他人的密码,需要权限
-- 如果权限不够,报错:Access denied for user 'zzp'@'localhost' to database 'mysql'
set password for 'zzp'@'localhost' = password('zzp');
mysql中的权限
| 权限 | 意义 |
|---|---|
All/All Privileges | 代表全局或者全数据库对象级别的所有权限 |
Alter | 权限代表允许修改表结构的权限,但必须要求有create和insert权限配合。如果是rename表名,则要求有alter和drop原表, create和insert新表的权限 |
Alter routine | 代表允许修改或者删除存储过程、函数的权限 |
Create | 代表允许创建新的数据库和表的权限 |
Create routine | 代表允许创建存储过程、函数的权限 |
Create tablespace | 代表允许创建、修改、删除表空间和日志组的权限 |
Create temporary tables | 代表允许创建临时表的权限 |
Create user | 代表允许创建、修改、删除、重命名user的权限 |
Create view | 代表允许创建视图的权限 |
Delete | 代表允许删除行数据的权限 |
Drop | 代表允许删除数据库、表、视图的权限,包括truncate table命令 |
Event | 代表允许查询,创建,修改,删除MySQL事件 |
Execute | 代表允许执行存储过程和函数的权限 |
File | 代表允许在MySQL可以访问的目录进行读写磁盘文件操作,可使用的命令包括load data infile,select … into outfile,load file()函数 |
Grant option | 代表允许执行存储过程和函数的权限 |
Index | 代表是否允许创建和删除索引 |
Insert | 代表是否允许在表里插入数据,同时在执行analyze table,optimize table,repair table语句的时候也需要insert权限 |
Lock | 代表允许对拥有select权限的表进行锁定,以防止其他链接对此表的读或写 |
Process | 代表允许查看MySQL中的进程信息,比如执行show processlist, mysqladmin processlist, show engine等命令 |
Reference | 是在5.7.6版本之后引入,代表是否允许创建外键 |
Reload | 代表允许执行flush命令,指明重新加载权限表到系统内存中,refresh命令代表关闭和重新开启日志文件并刷新所有的表 |
Replication client | 代表允许执行show master status,show slave status,show binary logs命令 |
Replication slave | 代表允许slave主机通过此用户连接master以便建立主从复制关系 |
Select | 代表允许从表中查看数据,某些不查询表数据的select执行则不需要此权限,如Select 1+1, Select PI()+2;而且select权限在执行update/delete语句中含有where条件的情况下也是需要的 |
Show databases | 代表通过执行show databases命令查看所有的数据库名 |
Show view | 代表通过执行show create view命令查看视图创建的语句 |
Shutdown | 代表允许关闭数据库实例,执行语句包括mysqladmin shutdown |
Super | 代表允许执行一系列数据库管理命令,包括kill强制关闭某个连接命令, change master to创建复制关系命令,以及create/alter/drop server等命令 |
Trigger | 代表允许创建,删除,执行,显示触发器的权限 |
Update | 代表允许修改表中的数据的权限 |
Usage | 是创建一个用户之后的默认权限,其本身代表连接登录权限 |
给用户授权
基本语法:
grant权限列on库.对象名to‘用户名’@‘登录位置’ 【identified by ‘密码’】
说明:
1、权限列表,多个权限用逗号分开
grant select on ...
grant select, delete, create on ...
grant all 【privileges】on ... //表示赋予该用户在该对象上的所有权限
2、特别说明
*.*:代表本系统中的所有数据库的所有对象(表,视图,存储过程)
库.*:表示某个数据库中所有数据对象(表,视图,存储过程)
3、indentified by可以省略,也可以写出
(1)如果用户存在,就是修改该用户的密码
(2)如果该用户不存在,就是创建该用户!
回收用户授权
基本语法:
revoke权限列表on库.对象名from‘用户名’@‘登录位置’;
权限生效指令
如果权限没有生效,可以执行下面命令
基本语法
flush privileges;
练习
用户管理练习
1、创建一个用户(你的名字,拼音),密码 123,并且只可以从本地登录,不让远程登录mysql
2、创建库和表 table 下的 news类,要求:使用root用户创建
3、给用户分配查看 news 表和添加数据的权限
4、测试看看用户是否有这几个权限
5、修改密码为 abc,要求:使用root用户完成
6、重新登录
7、回收权限
8、使用root用户删除你的用户
root用户
-- 演示 用户权限的管理
-- 创建用户 zzp01 密码 123
create user 'zzp01'@'localhost' identified by '123';
-- 使用root 用户创建 testdb,表 news
create database testdb;
create table testdb.news(
id int,
`content` varchar(32)
);
-- 添加一条数据
insert into testdb.news values (100, 'China News');
select * from testdb.news;
-- 给 zzp01 分配查看 news 表和 添加news的权限
grant select, insert on testdb.news to 'zzp01'@'localhost';
-- 可以增加权限
grant update on testdb.news to 'zzp01'@'localhost';
-- 修改 zzp01的密码为 abc
set password for 'zzp01'@'localhost' = password('abc');
-- 回收 zzp01 用户在 testdb.news 表的所有权限
revoke select, update, insert on testdb.news from 'zzp01'@'localhost';
-- 或者
revoke all on testdb.news from 'zzp01'@'localhost';
-- 删除 zzp01用户
drop user 'zzp01'@'localhost';
zzp01用户
-- 这里在默认情况下,zzp01 用户只能看到一个默认的系统数据库
SELECT * FROM testdb.news;
INSERT INTO testdb.news VALUES (200, 'shanghai News');
-- 能否修改,能否delete
-- 修改报错:UPDATE command denied to user 'zzp01'@'localhost' for table 'news'
UPDATE news SET content = 'chengdu News' WHERE id = 100;
-- 当root 赋予 update 权限后操作
UPDATE news SET content = 'chengdu News' WHERE id = 100; -- 执行成功: 共 1 行受到影响
测试 zzp01用户登录


当root用户赋给zzp01用户权限后,刷新后显示:

当root用户回收zzp01用户所有权限后,刷新:

当root用户删除zzp01用户后,再次连接:

细节说明
1、在创建用户的时候,如果不指定Host,则为%,%表示所有IP都有连接权限
create user xxx;
2、你也可以这样指定
create user 'xxx'@'192.168.1.%' 表示 xxx用户在 192.168.1.* 的IP可以登录mysql
3、在删除用户的时候,如果 host 不是 %,需要明确指定 '用户'@'host值'
-- 说明用户管理细节
-- 1、在创建用户的时候,如果不指定Host,则为%,%表示所有IP都有连接权限
-- create user xxx;
create user 'zzp02';
select `host`,`user` from mysql.user;
-- 2、你也可以这样指定
-- create user 'xxx'@'192.168.1.%' 表示 xxx用户在 192.168.1.* 的IP可以登录mysql
create user 'zzp02'@'192.168.1.%';
-- 3、在删除用户的时候,如果 host 不是 %,需要明确指定 '用户'@'host值'
drop user 'zzp02';
drop user 'zzp02'@'192.168.1.%';
作业
1、选择题:
(1) 以下哪条语句是错误的?D
A. select empno, ename name, sal salary from emp; -- 正确 ename name, sal salary 可以省略 as
B. select empno, ename, sal as salary from emp; -- 正确
C. select ename, sal*12 as "Annual Salary" from emp; -- 正确
D. select eame, sal*12 Annual Salary from emp; -- 错误 sal*12 Annual Salary :sal*12 的别名是Annual 但是后面有空格 Salary 不确定列
(2) 某个用户希望显示补助非空的所有雇员信息,应该使用哪条语句?B
A. select ename, sal, comm from emp where comm <> null; --错误 不应该使用<> (不等于)判断null
B. select ename, sal, comm from emp where comm is not null; -- 正确
C. select ename, sal, comm from emp where comm <> 0; -- 错误 判断不为0
(3) 以下哪条语句是错误的?
A. select ename, sal salary from emp order by sal; -- 正确
B. select ename, sal salary from emp order by salary; -- 正确
C. select ename, sal salary from emp order by 3; -- 错误 order by 3:要指定列或者别名 不能是3
2、写出 查看dept表和emp表的结构 的sql语句
-- 写出 查看dept表和emp表的结构 的sql语句
desc dept;
desc emp;
show create table dept;
show create table emp;
3、使用简单查询语句完成:
(1)显示所有部门名称
(2)显示所有雇员及其全年收入 13(工资+补助),并指定列别名“年收入”
-- (1)显示所有部门名称
select dname from dept;
select 100 + null from dual; -- 注意: xx + null = null
-- (2)显示所有雇员及其全年收入 13(工资+补助),并指定列别名“年收入”
-- 注意:sal + null = null comm需要加非null判断
select ename, (sal + ifnull(comm,0)) *13 as "年收入" from emp;
4、限制查询数据
(1)显示工资超过2850的雇员姓名和工资
(2)显示工资不在 1500和 2850之间的所有雇员及工资
(3)显示编号为7566雇员姓名及所在部门编号
(4)显示部门10号和30号工资超过1500的雇员名及工资
(5)显示无管理员的雇员名及岗位
-- (1)显示工资超过2850的雇员姓名和工资
select ename,sal from emp where sal > 2850;
-- (2)显示工资不在 1500和 2850之间的所有雇员及工资
select ename,sal from emp where sal < 1500 or sal > 2850;
-- 或者
select ename,sal from emp where not (sal >= 1500 and sal <= 2850);
-- (3)显示编号为7566雇员姓名及所在部门编号
select ename, deptno from emp where empno = 7566;
-- (4)显示部门10号和30号工资超过1500的雇员名及工资
select ename, job, sal from emp where (deptno = 10 or deptno = 30)
and sal > 1500;
-- 或者
select ename, job, sal from emp where deptno in (10,30)
and sal > 1500;
-- (5)显示无管理员的雇员名及岗位
select ename, job from emp where mgr is null;
5、排序数据
(1)显示在 1991年2月1号 到 1991年5月1号之间雇用的雇员名,岗位及雇佣日期,并以雇佣进行排序。
(2)显示获得补助的所有雇员名,工资及补助,并以工资降序排序
-- (1)显示在 1991年2月1号 到 1991年5月1号之间雇用的雇员名,岗位及雇佣日期,并以雇佣进行排序。
select ename, job, hiredate from emp where
hiredate >= '1991-01-02' and hiredate <= '1991-05-01'
order by hiredate asc;
-- (2)显示获得补助的所有雇员名,工资及补助,并以工资降序排序
select ename, sal, comm from emp order by sal desc;
6、根据:emp 员工表 写出正确的sql
(1)选择部门30中的所有员工
(2)列出所有办事员(CLERK)的姓名,编号和部门编号
(3)找出佣金高于薪金的员工
(4)找出佣金高于薪金60%的员工
(5)找出部门10中所有经理(MANAGER)和部门20中所有办事员(CLERK)的详细资料
(6)找出部门10中所有经理(MANAGER),部门20中所有办事员(CLERK),还有既不是经理又不是办事员,但其新金大于或等于2000的所有员工详细资料
(7)找出收取佣金的员工的不同工作
(8)找出不收取佣金或收取佣金低于100的员工
(9)找出各月倒数第3天受雇的员工
(10)找出早于12年前受雇的员工
(11)以首字母小写的方式显示所有员工的姓名
(12)显示正好为5个字符的员工的姓名
-- (1)选择部门30中的所有员工
select * from emp where deptno = 30;
-- (2)列出所有办事员(CLERK)的姓名,编号和部门编号
select ename, empno, deptno, job from emp where job = 'CLERK';
-- (3)找出佣金高于薪金的员工
select * from emp where ifnull(comm,0) > sal;
-- (4)找出佣金高于薪金60%的员工
select * from emp where ifnull(comm,0) > sal * 0.6;
-- (5)找出部门10中所有经理(MANAGER)和部门20中所有办事员(CLERK)的详细资料
select * from emp where
(deptno = 10 and job = 'MANAGER') OR (deptno = 20 and job = 'CLERK');
-- (6)找出部门10中所有经理(MANAGER),部门20中所有办事员(CLERK),
-- 还有既不是经理又不是办事员,但其新金大于或等于2000的所有员工详细资料
select * from emp where
(deptno = 10 and job = 'MANAGER') OR (deptno = 20 and job = 'CLERK')
OR (job != 'MANAGER' and job != 'CLERK' and sal >= 2000);
-- (7)找出收取佣金的员工的不同工作
select distinct job from emp where comm is not null;
-- (8)找出不收取佣金或收取佣金低于100的员工
select * from emp where comm is null or ifnull(comm,0) < 100;
-- (9)找出各月倒数第3天受雇的员工
-- 提示:last_day(日期),可以返回改日期所在月份最后一天
-- last_day(日期) - 2 得到日期所有月份的倒数第3天
select last_day('2011-11-11') - 2; -- 20111128
select * from emp where last_day(hiredate) -2 = hiredate;
-- (10)找出早于12年前受雇的员工(即:入职时间超过12年)
select * from emp where date_add(hiredate,interval 12 year) < now();
-- (11)以首字母小写的方式显示所有员工的姓名
select concat(lcase(substring(ename, 1, 1)), substring(ename, 2)) from emp;
-- (12)显示正好为5个字符的员工的姓名
select * from emp where length(ename) = 5;
(13)显示不带有 “R” 的员工的姓名
(14)显示所有员工姓名的前三个字符
(15)显示所有员工额姓名,用a替换所有’A’
(16)显示满10服务年限的员工姓名和受雇日期
(17)显示员工的详细资料,按姓名排序
(18)显示员工的姓名和受雇日期,根据其服务年限,将最老的员工排在最前面
(19)显示所有员工的姓名,工作和薪金,按工作降序排序,若工作相同则按薪金排序
(20)显示所有员工的姓名、加入公司的年份和月份,按受雇日期所在月排序,若月份相同则将最早年份的员工排在最前面
(21)显示在一个月为30天的情况所有员工的日薪金,忽略余数
(22)找出在(任何年月份的)2月受聘的所有员工
(23)对于每个员工,显示其加入公司的天数
(24)显示姓名字段的任何位置包含’A’的所有员工的姓名
(25)以年月日的方式显示所有员工的服务年限
-- (13)显示不带有 "R" 的员工的姓名
select * from emp where ename not like '%R%';
-- (14)显示所有员工姓名的前三个字符
select left(ename,3) from emp;
-- (15)显示所有员工额姓名,用a替换所有'A'
select replace(ename, 'A', 'a') from emp;
-- (16)显示满10服务年限的员工姓名和受雇日期
select ename, hiredate from emp where date_add(hiredate, interval 10 year) <= now();
-- (17)显示员工的详细资料,按姓名排序
select * from emp order by ename asc;
-- (18)显示员工的姓名和受雇日期,根据其服务年限,将最老的员工排在最前面
select ename, hiredate from emp order by hiredate asc;
-- (19)显示所有员工的姓名,工作和薪金,按工作降序排序,若工作相同则按薪金排序
select ename, job, sal from emp order by job desc,sal;
-- (20)显示所有员工的姓名、加入公司的年份和月份,按受雇日期所在月排序,
-- 若月份相同则将最早年份的员工排在最前面
select ename, concat(year(hiredate),'-',month(hiredate)) from emp
order by month(hiredate) asc, year(hiredate) asc;
-- (21)显示在一个月为30天的情况所有员工的日薪金,忽略余数
select ename, floor(sal/30), sal/30 from emp;
-- (22)找出在(任何年月份的)2月受聘的所有员工
select * from emp where month(hiredate) = 2;
-- (23)对于每个员工,显示其加入公司的天数
select ename, datediff(now(), hiredate) from emp;
-- (24)显示姓名字段的任何位置包含'A'的所有员工的姓名
select * from emp where ename like '%A%';
-- (25)以年月日的方式显示所有员工的服务年限
-- 思路:1. 先求出工作了多少天
select ename, datediff(now(), hiredate) from emp;
-- 2. 把天数转换成年月
select ename, floor(datediff(now(), hiredate) / 365) as " 工作的年份",
floor(datediff(now(), hiredate) % 365 / 30 ) as " 工作的月份",
datediff(now(), hiredate) % 31 as " 工作的天数"
from emp;
7、根据:emp员工表,dept部门表,工资 = 薪金sal + 佣金comm 写出正确sql
(1)列出至少有一个员工的所有部门
(2)列薪金比 “SMITH” 多的员工信息
(3)列出受雇日期晚于其直接上级的所有员工
(4)列出部门名称和这些部门员工的员工信息,同时列出那些没有员工的部门
(5)列出所有 “CLERK” (办事员)的姓名及其部门名称
(6)列出最低薪金大于1500的各种工作
(7)列出在部门"SALES"(销售部)工作的员工的姓名
(8)列出薪金高于公司平均薪金的所有员工
-- (1)列出至少有一个员工的所有部门
-- 思路:先查询各个部门有多少人 使用 having 子句过滤
select count(*) as c, deptno from emp
group by deptno having c > 1;
-- (2)列薪金比 “SMITH” 多的员工信息
-- 思路 先查出 SMITH 的sal (子查询),然后其他员工 sal > SMITH 即可
select * from emp where
sal > (select sal from emp where ename = 'SMITH');
-- (3)列出受雇日期晚于其直接上级的所有员工
/*
先把 emp 表 当做两种表 worker,leader
条件 1. worker.hiredate > leader.hiredate
2. worker.mger = leader.empno
*/
select worker.ename as "员工名", worker.hiredate as "员工入职时间",
leader.ename as "上级名称", leader.hiredate as "上级入职时间"
from emp worker, emp leader where worker.hiredate > leader.hiredate
and worker.mgr = leader.empno;
-- (4)列出部门名称和这些部门员工的员工信息,同时列出那些没有员工的部门
/*
这里因为需要显示使用部门,因此考虑使用外连接(左外连接)
*/
select dname, emp.* from dept left join emp on dept.deptno = emp.deptno;
-- (5)列出所有 “CLERK” (办事员)的姓名及其部门名称
select ename, dname, job from emp, dept where emp.deptno = dept.deptno and job = 'CLERK';
-- (6)列出最低薪金大于1500的各种工作
/*
查询各个部门的最低工资
使用having子句过滤
*/
select min(sal) as min_sal, job from emp
group by job having min_sal > 1500;
-- (7)列出在部门"SALES"(销售部)工作的员工的姓名
select ename, dname from emp, dept where emp.deptno = dept.deptno
and dname = 'SALES';
-- (8)列出薪金高于公司平均薪金的所有员工
select * from emp where sal > (select avg(sal) from emp);
(9)列出于 “SCOTT” 从事相同工作的所有员工
(10)列出薪金高于所在部门30的工作的所有员工的薪金的员工姓名和薪金
(11)列出在每个部门工作的员工数量、平均工资和平均服务期限
(12)列出所有员工的姓名、部门名称和工资
(13)列出所有部门的详细信息和部门人数
(14)列出各种工作的最低工资
(15)列出MANAGER(经理)的最低薪金
(16)列出所有员工的年工资,按年薪从低到到排序
-- (9)列出于 “SCOTT” 从事相同工作的所有员工
select * from emp where job = (select job from emp where ename = 'SCOTT');
-- (10)列出薪金高于所在部门30的工作的所有员工的薪金的员工姓名和薪金
-- 先查询出30号部门的最高工资
select ename, sal from emp where sal > (select max(sal) from emp where deptno = 30);
-- (11)列出在每个部门工作的员工数量、平均工资和平均服务期限(时间单位)
select count(*) as "部门员工数量", deptno, avg(sal) as "部门平均工资",
format(avg(datediff(now(), hiredate) / 365),2) as "平均服务期限(年)"
from emp group by deptno;
-- (12)列出所有员工的姓名、部门名称和工资
-- 就是 emp 和 dept 联合查询,连接条件 emp.deptno = dept.deptno
select ename, dname, sal from emp, dept where emp.deptno = dept.deptno;
-- (13)列出所有部门的详细信息和部门人数
-- 1. 先得到各个部门的人数,把下面的结果看成临时表
select count(*) as c, deptno from emp group by deptno;
-- 2. 和 dept表 联合查询
select dept.*, tmp.c as "部门人数" from dept,
(select count(*) as c, deptno from emp group by deptno) tmp
where dept.deptno = tmp.deptno;
-- (14)列出各种工作的最低工资
select min(sal), job from emp group by job;
-- (15)列出MANAGER(经理)的最低薪金
select min(sal), job from emp where job = 'MANAGER';
-- (16)列出所有员工的年工资,按年薪从低到到排序
-- 1. 先得到员工的年工资
select ename, (sal + ifnull(comm, 0)) * 12 year_sal from emp order by year_sal asc;
8、设学校环境如下:一个系有若干个专业,每个专业一年只招一个班,每个班有若干个学生。
现要建立关系于系、学生、班级的数据库,关系模式为:
班CLASS(班号classid、专业名subject、系名deptname、入学年份enrolltime,人数num)
学生STUDENT(学号studentid,姓名name,年龄age,班号classid)
系DEPARTMENT(系号departmentid,系名deptname)
试用SQL语言完成以下功能:
(1)建表,在定义中要求声明:1、每个表的主外键 2、deptname是唯一约束 3、学生姓名不能为空
(2)插入数据如下:
DEPARTMENT(
001,数学;
002,,计算机;
003,化学;
004,中文;
005,经济
)
CLASS(
101,软件,计算机,1995,20;
102,微电子,计算机,1996,30;
111,无机化学,化学,1995,29;
112,高分子化学,化学,1996,25;
121,统计数学,数学,1995,20;
131,现代语言,中文,1996,20;
141,国际贸易,经济,1997,30;
142,国际金融,经济,1996,14
)
STUDENT(
8101,张三,18,101;
8102,钱四,16,121;
8103,王玲,17,131;
8105,李飞,19,102;
8109,赵四,18,141;
8110,李可,20,142;
8201,张飞,18,111;
8302,周瑜,16,112;
8203,王亮,17,111;
8305,董庆,19,102;
8409,赵龙,18,101;
8501。李丽,20,142;
)
(3)完成以下查询功能
(3.1)找出所有性李的学生
(3.2)列出所有开设超过1个专业的系的名字
(3.3)列出人数大于等于30的系的编号和名字
(4)学校又新增加了一个物理系,编号为006
(5)学生张三退学,请相关的表
-- 创建 班CLASS表
create table `class`(
classid int primary key,
`subject` varchar(32) not null default '',
deptname varchar(32), -- 外键字段,在表定义后指定
enrolltime int not null default 1990,
num int not null default 0,
foreign key (deptname) references DEPARTMENT(departname)
);
-- 创建 学生STUDENT表
create table zzp_student(
studentid int primary key,
`name` varchar(32) not null default '',
age int not null default 0,
classid int, -- 外键
foreign key (classid) references `class`(classid)
);
-- 创建 系DEPARTMENT表
create table DEPARTMENT(
departmanetid varchar(32) primary key,
departname varchar(32) unique not null
);
-- 添加 DEPARTMENT表数据
insert into DEPARTMENT values ('001','数学');
insert into DEPARTMENT values ('002','计算机');
insert into DEPARTMENT values ('003','化学');
insert into DEPARTMENT values ('004','中文');
insert into DEPARTMENT values ('005','经济');
select * from DEPARTMENT;
-- 添加 class表数据
insert into `class` values (101,'软件','计算机',1995,20);
insert into `class` values (102,'微电子','计算机',1996,30);
insert into `class` values (111,'无机化学','化学',1995,29);
insert into `class` values (112,'高分子化学','化学',1996,25);
insert into `class` values (121,'统计数学','数学',1995,20);
insert into `class` values (131,'现代语言','中文',1996,20);
insert into `class` values (141,'国际贸易','经济',1997,30);
insert into `class` values (142,'国际金融','经济',1996,14);
select * from `class`;
-- 添加 zzp_student表数据
insert into zzp_student values (8101,'张三',18,101);
insert into zzp_student values (8102,'钱四',16,121);
insert into zzp_student values (8103,'王玲',17,131);
insert into zzp_student values (8105,'李飞',19,102);
insert into zzp_student values (8109,'赵四',18,141);
insert into zzp_student values (8110,'李可',20,142);
insert into zzp_student values (8201,'张飞',18,111);
insert into zzp_student values (8302,'周瑜',16,112);
insert into zzp_student values (8203,'王亮',17,111);
insert into zzp_student values (8305,'董庆',19,102);
insert into zzp_student values (8409,'赵龙',18,101);
insert into zzp_student values (8501,'李丽',20,142);
select * from zzp_student;
-- (3)完成以下查询功能
-- (3.1)找出所有性李的学生
-- 查询 zzp_student 表,使用 like
select * from zzp_student where `name` like "%李%";
-- (3.2)列出所有开设超过1个专业的系的名字
-- 1. 先查询各个系有多少个专业
select count(*) as nums, deptname from `class` group by deptname having nums > 1;
-- (3.3)列出人数大于等于30的系的编号和名字
-- 1. 先查询出各个系有多少人,并得到 >= 30 的系
select sum(num) as nums, deptname from `class` group by deptname having nums >= 30;
-- 2. 将上面的结果看成一个临时表 和 department 联合查询即可
select tmp.*, department.departmanetid from department,
(select sum(num) as nums, deptname
from `class` group by deptname having nums >= 30) as tmp
where department.departname = tmp.deptname;
-- (4)学校又新增加了一个物理系,编号为006
-- 添加一条数据
insert into DEPARTMENT values ('006','物理系');
-- (5)学生张三退学,请相关的表
-- 分析:1. 张三所在班级人数-1 2. 将张三从学生表删除
-- 3. 需要使用事务控制
-- 开启事务
start transaction;
-- 张三所在班级人数-1
update `class` set num = num - 1
where classid = (select classid from zzp_student where `name` = '张三');
-- 将张三从学生表删除
delete from zzp_student where `name` = '张三';
-- 提交事务
commit;















 97
97











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









