







记一次Spark任务Driver端问题排查
Spark任务提交Client模式报错找不到依赖,换成Cluster模式就乖乖听话了,这问题其实很简单。
一、问题出现
这次是给某运营商的新项目,客户提供了两个集群分别用于测试和生产,运维组搭建好大数据集群环境后,我们开始安排部署前后台及大数据分析程序。
因为当前的程序版本此前在多个集群有过部署,所以按部就班直接放上所有文件,调整好conf配置,脚本启动……就是这么简单的一个流程,却出了一个摸不着头脑的问题。
众所周知,Spark提交任务分两种模式——cluster和client,两种的区别后头我再单独写一篇文章说明,在这里出现的问题就和这个知识相关了。
首先是以默认的client模式提交运行,方便查看Driver端的日志,毕竟新环境可能会有水土不服的情况,结果是很快就迎来了报错:
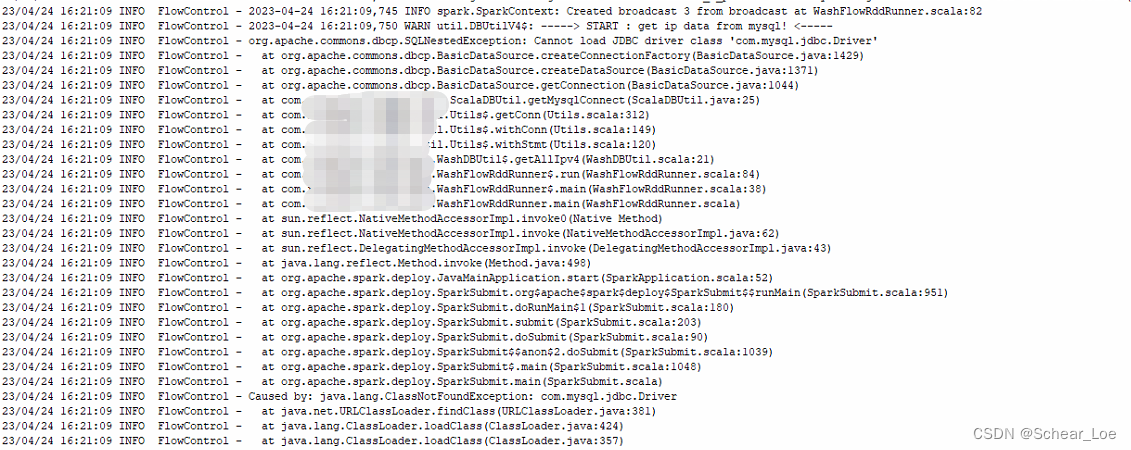
二、问题排查
因为当时同时还在做别的事情,这边草草看了一眼简单判断没有加入–jars的参数,就感觉问题解决了,可是过了半天回头一看还是不行,依然报这个错。当时大脑有些短路,直接改了cluster模式运行,又过了挺久回头看了一眼,发现竟然ok了。
到这里其实基本知道问题的根源,应该就是本地的环境出了问题,spark任务提交后,本地的Driver程序使用的环境变量缺少了相关的依赖,但毕竟集群组件维护并不在我的管辖范围内,我还是请来了运维组的大佬帮忙排查。
大佬先逐步排查了基本配置,表示配置项基本没问题;然后切换进spark的安装目录,找到jars目录查看里面的文件,果然是没有需要的jdbc的包,问题到这也就算是定位到了根本原因。
三、解决及后话
把需要用到的jar包拖进spark的jars里面之后,任务正常运行没有出现过问题,但其实这里有个问题,如果有很多依赖,需要把它们都拖到spark的安装目录下吗?听起来不太合理,但其实spark运行时可以通过参数指定环境变量,示例如下:
spark.driver.extraClassPath=/path/to/driver/classpath:${SPARK_HOME}/jars/*
spark.executor.extraClassPath=/path/to/executor/classpath:${SPARK_HOME}/jars/*
使用这两个参数,就可以灵活控制spark的环境变量,但不太建议小白这么操作,因为可能会带来别的问题,比如丢失了部分原有的环境变量。。。
如果有其它方法可以解决,欢迎评论区沟通哟!~
20210601 补充
儿童节快乐!
近期又出现这个问题,而且上述手段不能解决,于是又探索到一个新的知识
因为部署环境为yarn,所以排除上述可能性之后,我把目光放在了yarn身上,果然找到了一个运行环境调用的lib文件夹:
/path/to/yarn/share/hadoop/yarn/lib
小伙伴需要把‘path/to/yarn’更换成真实的yarn路径,然后把需要用到的依赖包放进去,就可以了。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









