







一、深入Git内幕研究的引子介绍
从这一讲往后,我们会不少讲,是进入这个git课程的最后一块内容,就是git内幕原理
简单带一句,我现在的一个授课思想,刚开始学习一个技术,必须先短平快引入,入门要快,把这个技术最核心需要用到的一些东西,用一点简单的demo带一些,快速的就入门了
在入门的同时,用的是那个技术最核心的一些东西,直接把这个技术最最根本,最最基础的原理,给大家阐明
刚有个感觉,体验,功能背后的一套比较根本的原理是那样子的,三个区域
就是纯实战驱动,这个技术在实际企业中是怎么来运用的,如果是类似maven,git这种技术,是没法做项目实战的,融入在我们后面的大项目里的,贯穿了整个做项目的环节
但是我们可以把企业中常见的一个一个的实战场景,应用场景,反过来推出,我现在有这么一个企业里的而应用场景,需求,问题,然后呢,我的git技术有哪个命令或者说是功能,可以解决他??
每个技术讲解完之后,每个git的命令,如果有可能,再给大家带一带,深入剖析一下命令背后的原理。功能分支工作流实战切入,分支那一套的内幕原理,后面的一系列的命令
实战驱动,深入原理
收尾的那一段,精华,比如说git,其实它是有自己的一套内幕原理的,非常深入的去探索一下git内幕里的原理,把深入的最后一块东西给讲好,整个这个技术学习,完美
(1)学习一些开源技术背后的原理和思想
(2)加深你的技术内功,会用一大堆技术有什么用?但是如果你对很多技术背后的内幕原理和整体上的架构设计思想,都很精通,那么你的技术内功会很强悍 => 你在后面做项目的时候,设计,解决问题,得心应手 => 内功越深厚,你以后在学习类似技术,或者其他技术的时候,速度就会更快
(3)直接能够提升你的以后做自己项目时候的技术能力 => 吸收了很多开源技术的设计思想,架构,方案,机制 => 运用到了你自己的项目里,你会发现很多问题和场景,都可以吸取他们的思想去解决
(4)如果你的很多技术内功很深厚的,就业,职场发展 => 99个程序员的简历上写的都是熟悉spring boot,spring cloud等技术的使用,有过什么什么经验 => 深入阅读过spring boot和spring cloud的源码,对其架构体系和设计原理较为精通 => BAT,简历上的亮点 => 面试的时候,如果你能把这些深入的东西讲出来,架构师,技术专家,高级工程师,BAT,中小型公司,都会有很大的优势
一张思维导图带你梳理清楚学习到的技术体系,maven课程,反馈都很好
授人以鱼不如授人以渔:学习方法,如何去自己去未来更加深入的研究和学习相关的技术,自己如何能够走得越来越远
包括我之前讲的很多讲,Git高阶实战技巧,讲了一大通,“废话”,精华
光讲技术,是没什么稀奇的
稀奇的是,我在公司里什么场景下,是怎么用这个技术的,经验,会花很多时间去给大家铺垫各种git命令讲解之前的场景,那些东西我认为比git命令更重要,几十个git命令,你都不知道用来干嘛的,过了2个月,保证你全部忘记
记忆曲线,如果脑海中有个场景,有个图片帮助你记忆,你的记忆的遗忘会慢很多,记忆清晰很多,记忆的时间会长很多
我觉得,知其然而知其所以然,你不要光学,你为什么要学,你学了以后有什么用
BAT,晋级答辩,职级体系,升级打怪
每次去要网上晋升一级的时候,非常强调你的思考的能力,你不要告诉我你做了什么?你告诉我,你为什么要做,你为什么要这样做,你这样做了以后效果是什么,作用是什么?
技术评审委员会的成员之一,参加过很多初中高级工程师的晋级答辩,工程师,what,我做了什么
技术工程师,必须要懂得思考,梳理,总结,抽象,提取。为什么做,为什么要这样做,这样做以后我对公司的产出是什么,价值是什么,业务的促进是什么
软素质真正强悍的人,才可以去做技术经理,技术总监,CTO,CEO
1.1、Git内幕研究的一个思路
git add,git commit,git push,这些命令背后在干什么?git内幕原理
不是纯讲,要在动手实践中,去给大家讲请清楚这些命令背后的原理是什么?
porcelain命令,这些命令,指的就是类似git add,日常开发中,程序员会直接使用的git命令
这些porcelain命令底层都是调用的一些git的底层命令,plumbing命令,实际上是不是给我们用的,是给git的那些高阶命令去用的
我们在这里讲解git add这些高阶命令背后的原来,是带着大家动手实践去体验一下底层的命令是用来干嘛的,当你把那些对应的底层命令都学会之后,明白那些底层命令在干什么,接着你就会瞬间明白,git add,git commit这些高阶命令,你在执行的时候,他们背后在干什么 => 内幕原理,你就全部清楚了
1.2、.git目录研究
平时我们如果执行git init之后,就会生成一个.git目录,其中就是git存放所有数据的地方。如果我们拷贝这个.git目录,那么就相当于备份了一个完整的git项目的数据。
在.git目录中,有如下一些内容:
config
description
HEAD
hooks/
info/
objects/
refs/

description文件仅仅是由Git WebUI程序去使用的,我们一般不用去管这个文件
config文件包含了这个git项目的所有配置项
info目录中包含了我们在.gitignore文件中定义的不需要git追踪的那些被排除掉的文件
hooks目录中包含了我们的client-side或者是server-side的钩子脚本
其实上面那些都不是最重要的,最重要的是这几个东西:HEAD文件,indexes文件,objects目录,以及refs目录。
objects目录存储了git中所有的数据,refs目录中存储了所有的指针(包括了branch,tag,remote,等等,指向了objects目录中的数据),HEAD指向了当前我们所处的分支指针,indexes文件存储了暂存区中的内容。
把接下来的课程听懂之后,你就会了解常见的git命令背后的原理,还有git命令结合.git目录的存储相关的原理
二、在动手实践中掌握提交代码的内幕原理
2.1git数据存储机制
2.1.1git hash-object初体验
git的数据存储格式实际上是一种非常简单的key-value存储格式。就是说,git支持将任何东西存储到其数据库中,一般就是存储文件的内容,然后用一个key值来引用它。
(1)首先随便找一个目录,初始化为git项目:
git init

此时去.git/objects目录中检查一下,发现只有两个子目录,info和pack,没有任何文件,此时数据库是空的。
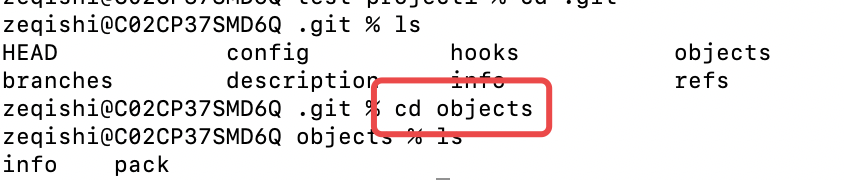
用下面命令,可以手动将一个字符串作为value存储到git的数据库(objects,git的数据库,用了比较简单的方式去存储)中去,会看到返回了一个hash值来引用那个字符串value:
echo 'hello world' | git hash-object -w --stdin

解释一下上面的命令:
git hash-object就是git的一个底层命令,一般我们是不会直接用的,一般都是git add,git commit之类的命令在调用这种底层命令。
git hash-object命令,默认的表现是这样的,接受一个value,然后针对这个value返回一个hash值,默认是不将value写入自己的数据库的
但是使用了-w之后,git就会将value写入数据库之中,同时用hash值作为key来引用那个value对应的文件。同时–stdin指的是从命令行接收value,也就是echo ‘test content’中的test content。如果不使用–stdin,那么要求是在hash-object之后跟一个文件名,它就会将一个文件作为value存储到数据库中去,然后返回一个hash值。
git返回的是SHA-1 hash值,是40位的字符串,是根据文件内容计算出来的一个checksum,校验和。
2)git的文件存储机制(轻量级索引机制)
你往git里存储一个文件,git一定会根据文件的内容计算一个40位的hash值出来,作为那个文件的名称,也是指针,40位hash值就可以来引用这个文件。存储的时候,40位hash的头2位,会作为目录名称放在objects里面,然后那个存储的文件会放在那个目录中,文件名是40位hash值的后38位。

大家来思考一下,git作为一个高性能的版本控制系统,一大特点就是性能超高,在切换分支的时候,都需要进行大量的磁盘读写,磁盘存储机制是比较值得我们注意的
将40位hash值的头2位作为目录,其实你可以认为是一种轻量级的索引机制
这样的话,有一个好处,就是每次你要根据一个hash值定位一个数据的时候,直接根据头2位先定位到一个目录,然后再在这个目录下去查找,linus写git的时候,就是用了一种非常轻量级的文件索引机制
直接查看git存储的文件的内容是不ok的,我们后面会讲解要用git专用的底层命令来查看
3)git cat-file体验
使用下面的命令可以查看刚存储进去的文件值,git cat-file是另外一个底层命令,就是专门用来查看存储到git中的文件的内容的:
git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4

4)一个文件的多个版本存储机制的体验
下面的命令可以将一个文件存储到git数据库中:
echo 'version 1' > test.txt
git hash-object -w test.txt
echo 'version 2' > test.txt
git hash-object -w test.txt

git会将一个文件的多个不同版本,以完整快照的方式存储在objects数据库中,每个版本都用一个单独的文件来存储,每个版本的文件都有一个不同的hash值。查看每个版本存储的情况:

使用下面的命令可以查看.git/objects中所有的文件:find .git/objects -type f

接着可以试着将这个文件给删除,然后从git数据库中再恢复回来这个文件:
rm -rf test.txt
git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
cat test.txt

也就是说,我们只要将数据存储到了git中,那么就不用担心丢失了,随时都可以找回来这个文件的任意一个版本
我们用下面的命令可以查看一下git中存储的文件的类型,默认都是blob:
git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
这里,我们就发现跟之前给大家讲解的那个原理就可以串起来了,因为实际的文件的内容,每个文件的版本快照,会作为一个blob object存储在git数据库中
git数据库,git仓库,database,repository
5)梳理一下
实际上,就是一个文件的不同的版本,都会用一个完整的快照的形式,作为一个单独的文件存储在git数据库中,所谓的完整快照,每个版本,都是用一个文件存储这个版本的完整的内容的。每个版本的文件内容,都是通过blob object的类型存储在git数据库中的。
2.1.2 tree object
git有另外一种object叫做tree object,每次将一堆文件的一个版本存储到git仓库中,都是用blob object来存储那些文件的版本,然后用一个tree object来引用多个blob object。tree object通常会包含指向其他多个blob的指针,或者是其他tree object的指针。用下面的命令,可以查看master分支指针指向的那个tree object:
git cat-file -p master^{tree}
git通常是基于暂存区中的内容来创建一个tree object的,我们首先需要在暂存区中加入一些内容,然后可以试着手动创建一个tree object。可以将仓库中存储的某个commit object的内容放入暂存区中:
git update-index --add --cacheinfo 100644 83baae61804e65cc73a7201a7252750c76066a30 test.txt

git update-index:底层命令,一般是git add命令去调用的,将数据库中存储的某个blob数据的引用放到暂存区中
–add:因为暂存区中还没有这个文件,你可以认为这个文件是第一次进入暂存区,所以需要这个选项
–cacheinfo:不是从工作区中加入文件放到暂存区,是从git仓库(git数据库)中加入文件
100644 mode:这种模式的意思是,这个是一个普通的文件
接着使用下面的命令基于暂存区中的内容,创建一个tree object:
git write-tree:将暂存区中的内容创建为一个tree object,tree object也是放入了git仓库,主要是包含了对一个blob obejct的引用

git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
下面我们再加入一个new.txt文件放入暂存区中,同时将test.txt文件的另外一个版本放入暂存区中,再次创建一个tree object:
echo 'new file' > new.txt
git update-index --add new.txt,这个就是将工作区里的内容直接放入暂存区和仓库里面
git update-index --add --cacheinfo 100644 860ab83ec58187da2fbb592c7ab2665f6cd68a95 test1.txt 这是将test.txt文件的另外一个版本放到暂存区里面
此时远程仓库里面就是v1版本的代码

git write-tree
git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341

此时会发现这个tree object对应着两个文件
下面的命令可以从仓库中读取一个tree object放入暂存区,然后再基于这个tree object创建一个新的tree object出来:
所谓的将仓库里的东西读出来放到暂存区,实际上只是将一些引用放到暂存区,但是blob,tree,实际还是存储在objects中的
git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
git write-tree
git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
此时tree object包含两个文件和一个tree object,如果将这个tree object的数据恢复到工作区中,就会有两个文件和一个叫做bak的文件夹,bak文件夹中也包含了一个文件。
2.1.3commit object
随着你不断的在工作区中编写代码,然后呢,每次如果执行了一些相关的操作,可以将当前这个时刻,有变化的文件的版本都存储到git仓库中,同时放入暂存区中。
此时,暂存区中,没有变化的文件,还是保持着之前的版本;有变化的文件,暂存区中会存放最新版本的blob对应的引用
然后,如果此时创建一个tree object,就是基于暂存区中当前所有的文件的版本的blob,创建一个tree
此时,这个tree object就代表了这个项目的所有代码的此时此刻的一个完整的快照
现在我们实际上是有3个tree object,分别代表了项目的不同时刻的快照。但是此时此刻,我们有个文件,就是不知道那些tree object是谁添加的,为什么添加,什么时候添加的,什么都不知道。
但是,光有tree object是不够的
此时就需要commit object了。
用下面的命令,基于已有的tree object创建一个commit object,同时给这个commit object一个提交备注:
echo ‘first commit’ | git commit-tree d8329f
然后查看一下这个commit object,会发现包含了一个tree object,同时又作者,提交日期,以及提交备注:
git cat-file -p fdf4fc3

commit object的含义很简单,就是指向了一个tree object,而那个tree object指向了多个blob,其实这个tree object就代表了某一时刻项目中所有代码文件的快照版本,同时那个commit object包含了作者、提交时间、提交备注,此外还包含了指向上一次commit object的指针。
同样的,我们可以为另外两颗tree object分别创建一个commit object,代表了另外两次提交:
echo ‘second commit’ | git commit-tree 0155eb -p fdf4fc3
echo ‘third commit’ | git commit-tree 3c4e9c -p cac0cab
此时相当于我们就有了三次跟真实一样的提交了,可以用git log来查看一下提交历史:
git log --stat
就会看到最近的3次提交
其实上面的实验步骤就彻底揭示了git的底层原理了git add和git commit命令执行时使用的就是上面那些低级别的命令:
git add:相当于是将你的有修改的文件作为一个新的版本,采用单独的blob文件存储到仓库中去,同时将仓库中的文件更新到暂存区中
git commit:相当于就是将暂存区中的文件快照,也就是对应的blob指针创建一个tree object,写入仓库中,同时再创建一个commit object包含了提交人/提交时间/提交备注,来指向那个tree object,代表了一次提交对应的仓库快照
blob、tree和commit,三种object都是作为一个独立的文件在objects目录中存储的,存储时的子目录命名和文件名,都是基于hash值来的
最后用一张图来说明,到目前为止,整个commit object、tree object和blob的关系。
2.1.4SHA-1 hash值如何计算
首先blob的内容分为两块,一个是header,一个是content。header就是类型+空格+长度+\u0000。然后会用header+content来计算出一个SHA-1校验和,作为hash值。
2.1.5梳理一下
git update-index --add 文件名:其实就是,我们在工作区里修改了文件以后,会用这个底层命令,将工作区中有修改的文件的一个版本,放入git仓库中作为一个blob去存储这个版本,同时将这个blob的引用放入暂存区中
多次有git update-index之后,git仓库中会存储项目中每个文件的所有版本,同时在暂存区中保留了每个文件的最新版本,没有变化的就保留值钱的版本
执行git write-tree,就可以针对暂存区中当前项目的最新版本,创建一个tree object,引用项目中所有的文件当前此时此刻的一个版本对应的blob,tree object,就代表了项目当前的一个完整快照版本
接着执行git commit-tree,就可以基于这个tree object创建一个commit object,包含了tree object的创建人,创建时间,备注信息,等等,作为一次提交
2.1.6将上层命令和底层命令结合起来
1)我们首先在工作里各种新增、修改文件
2)我们执行git add --all .这个命令:此时会将工作区中有变化的文件,作为一个新的版本,直接存储到git仓库中去,作为一个blob来存储;同时在暂存区中加入这些最新版本的blob的引用,替换同一个文件之前在暂存区中的版本
git update-index
3)我们执行git commit,同时给出一个提交备注:此时会针对暂存区中现在的所有的版本,创建一个tree object,作为项目此时此刻的一个快照版本,放入仓库;另外再创建一个commit object,包含了提交人,提交时间,提交备注,来引用这个tree object
4)到此为止,完成一次git add和git commit
5)整个git内幕原理,剖析的非常清楚了
2.1.7最后再来一张图,结合命令,演示一下
1)编写两个文件,test1.txt和test2.txt
2)git add --all .
将两个文件的第一个版本,作为两个blob保存到了Git仓库中,同时也放入了暂存区中

3)git commit -m “第一次提交”
基于暂存区里的两个文件的第一个版本,创建了一个tree
然后基于提交信息创建了一个commit,引用了那个tree,此时这个commit就代表当前这个项目此时此刻的一个完整的版本

然后通过find .git/objects/ -type -f查看有哪些提交文件

接着分别查看这几个object。先看看最后一个12b54f4:

可以看到他是一个commit object。接着看倒数第二个object,git cat-file -p a158e71

可以看到他是一个blob接着看第2个object,git cat-file -p e495bd5d

可以看到他包含了两个blog,他是一个tree object。接着看第一个object:git cat-file -p 3b18e512

他是一个object。
4)修改test1.txt位第二个版本
5)git add --all .
将test1.txt的第二个版本作为blob存储到git仓库中
同时将test1.txt的第二个版本覆盖了暂存区中的test1.txt的第一个版本

此时的操作截图如下:

可以看到此时多出了一个839088523c9734c8ffcd324cd5ed0509a88919cb这个object。
6)git commit -m “第二次提交”
创建了一个tree,引用了test1.txt的第二个版本,test2.txt的第一个版本
另外创建了一个commit,引用了那个tree,代表了此时此刻项目的一个完整的版本
此时可以看到3e3bb8f9cffbeb1c62d9cc536ec999124c1e4a6f这个object是新增的commit object

此时可以看到3e3bb8f这个comit object,它引用了83908852和a158e71c这两个object,
7)每个commit,就是当前项目的一个完整的快照版本,包含了项目的所有文件的一个最新版本
8)为什么大公司里,规范项目里,对git commit都有要求的,不要随便瞎提交,都是完成一个完整的功能或者模块之后再提交一次,尤其是每天提交一次,或者每天提交多次,每次代表了一个完整的功能和模块
9)整个你的项目的提交历史,就是项目版本的变迁的一个完整的历史,每个commit都代表引入了一个新的功能或者是模块

三、在动手实践中掌握Git指针的内幕原理
.git/objects里面的内容是怎么回事儿,跟git hash-object/git update-index/git write-tree/git commit-tree等底层命令的关系是怎么回事儿,底层命令跟git add和git commit命令结合起来是怎么回事儿,图解
git提交那一块,你完全掌握了底层的内幕原理了
除了存储那些数据,git里面有很多种指针,tree/commit里面本来就含有指针,指向其他的blob或者是tree,暂存区里面也是指针
分支、HEAD、tag、remote
.git/refs这个目录里面的内容

3.1分支指针
如果我们要查看某个commit,那么还是要知道它的hash值,然后用git log hash_value来查看这个commit。但是这还是很麻烦,所以最好是可以有个文件存储那个hash值,然后我们直接用一个较为简单的名称来引用。
.git/refs目录中,有几个子目录,包括了heads和tags两个子目录,在这里就有各种指向objects中的指针。
.git/refs/heads目录下,有一个master文件,实际上是git自动创建一个初始的分支,分支其实就是一个指针而已,指向了某个commit object的,在master文件中就包含了一个40位的hash值,当前就是指向了最近一次commit object

.git/refs/heads目录下,会包含很多个文件,就是每次创建一个分支,就会在这个里面对应新建一个文件,文件名称就是分支的名称,文件里的内容就是分支指针当前指向的那个commit object的hash值,代表着这个分支当前指向了哪个commit object
我们下面动手实践一下,用git底层的命令,看看,我们手动去创建分支会是什么样的效果
我们可以用下面的命令创建一个名叫feature/001的指针,指向了第一次提交的commit object
echo 1a410efbd13591db07496601ebc7a059dd55cfe9 > .git/refs/heads/feature/001

接着用下面的命令,就可以查看master指向的commit object之前的commit历史
git log --pretty=oneline feature/001
总结一下,git里面的分支的内幕原理,大家就彻底清除了,新建一个分支是很轻量级的一个事情,不是像其他的版本控制系统那样,新建一个分支,是将所有的文件内容和版本都拷贝一份
其实在git中,提交历史,blob+tree+commit,是最核心的,所有的数据都是通过这个方式来存储一份
然后呢?新建一个分支,实际上就是在.git/refs/heads下面新建对应的目录和文件,在文件里面维护一个指针,一个hash值,指向了.git/objects中某个commit object的hash值
通常不建议直接自己手动修改refs文件的内容,可以用下面的命令更新某个refs文件指针指向的commit object:
git update-ref refs/heads/feature/001 1a410efbd13591db07496601ebc7a059dd55cfe9
其实上面就已经揭示出来了,这就是git中的分支机制的根本原理,分支就是指针而已,分支指针指向了不同的commit object。用下面的命令可以再创建一个test分支,让其指向某个commit object:
git update-ref refs/heads/test cac0ca
实际上我们如果执行git branch命令,就是执行update-ref命令,创建那个分支对应的文件,然后文件内容就是对应的commit object的SHA-1 hash值。
删除一个分支很简单的,就是删除.git/refs/heads下面的分支对应的目录和文件即可
3.2HEAD指针
HEAD文件中,保存了对某个分支指针的引用,其实就是某个分支对应的文件。
HEAD其实也是一个文件,但是也是一个指针,这个HEAD呢,就是指向了当前你所处的那个分支而已,保存的是refs/heads下面的分支对应的目录和文件名
比如当前你在master分支,那么HEAD文件中的内容就是refs/heads/master,代表了HEAD当前指向了master分支
再比如当前你在feature/001分支,那么在HEAD文件中,内容就是refs/heads/feature/001,代表了HEAD当前指向了feature/001分支
因此如果我们比如在master分支上,创建并且切换到了另外一个分支,那么此时会根据HEAD找到当前分支文件,再找到当前分支指向的commit object,那么新建的分支就会同样指向那个commit object。
从比如master分支切换到feature/001分支,实际上就是一个非常轻量级的操作
(1)HEAD文件里的内容,从refs/heads/master,变为refs/heads/feature/001,代表着HEAD指针指向了feature/001分支
(2)将feature/001分支指向的那个commit对应的tree,对应的那些blob对应的文件版本的内容,一次性从仓库里恢复到工作区中,工作区中所有文件的版本和内容,会变成那个分支指向的commit当时的那个快照版本
每次切换分支之后,HEAD都会指向那个分支的文件
可以通过git checkout命令+cat .git/HEAD命令结合起来,然后就可以看到每次切换后的HEAD值
每次我们执行一次git commit操作,都会新建一个commit object出来,然后会让当前分支指向最新的commit object。
通过下面的命令可以读取和修改HEAD文件的指针:
git symbolic-ref HEAD
git symbolic-ref HEAD refs/heads/test
到这里为止,.git/refs下面最重要的东西就讲解完了,分支和HEAD
分支就是一个文件,保存了指向的commit的40位hash置
HEAD也是一个文件,保存了指向的那个分支对应的文件名称
(3)tag object
其实除了blob、tree和commit三种object之外,还有一种object就是tag object。tag object是指向某个commit object的,包含了标签时间,标签名称,等等。而且tag object永远就指向创建时指定的那个commit object,不能修改。
我们可以通过下面的命令创建一个轻量级的tag object
就只是一个指针而已,在refs/tags下面,会有一个tag名称对应的文件,然后里面就是那个tag指向的commit的40位hash值
git tag v1.0:轻量级的tag,直接就指向了当前分支指向的那个commit object,就是在refs/tags下面搞一个问加你,作为一个指针而已
git update-ref refs/tags/v1.0 cac0cab538b970a37ea1e769cbbde608743bc96d
当然也可以创建一个带备注的标签:git tag -a v1.1 -m ‘test tag’
此时查看cat .git/refs/tags/v1.1,会发现返回的不是我们指定的那个commit object,是另外一个新创建的tag object的SHA-1 hash
git cat-file -p 9585191f37f7b0fb9444f35a9bf50de191beadc2
再次查看那个tag object的hash值,此时可以显示出来其指向的那个commit object,同时包含了tag的创建时间、创建人、备注,等等信息。
(4)remote
最后一种引用类型,就是remote。
如果我们添加了一个remote,同时push了一些东西到那个remote,git会在refs/remotes中保留对每个分支,最近一次push到远程服务器对应的commit。
比如下面的命令:
git remote add origin git@github.com:schacon/simplegit-progit.git
git push origin master
cat .git/refs/remotes/origin/master
查看一下上面的文件,会看到一个SHA-1 hash值,就是这个分支最近一次push到服务器的object commit的SHA-1 hash值。
FETCH_HEAD,就是最近一次fetch下来的每个分支对应的commit hash值,就在这个里面
(5)梳理一下
分支:.git/refs/heads
HEAD:.git/HEAD
tag:.git/refs/tags
remote:.git/refs/remotes
FETCH_EHAD:.git/FETCH_HEAD
四、在动手实践中掌握Git文件合并的内幕原理
我们来通过一个大文件的存储以及git对这个文件多版本存储的优化,作为例子,来看一看git对大量的文件在存储上是如何做优化的
用下面的命令将一个大文件存入git中:
curl https://raw.githubusercontent.com/mojombo/grit/master/lib/grit/repo.rb > repo.rb
git checkout master
git add repo.rb
git commit -m ‘added repo.rb’
然后看一下master指向的commit object对应的tree object包含的内容,master分支指向了一个commit object,commit object是指向了一个tree object,tree object指向了此时此刻项目中所有文件的一个最新版本
git cat-file -p master^{tree}

用下面的命令看一下新加入进去的文件有多大:
git cat-file -s 033b4468fa6b2a9547a70d88d1bbe8bf3f9ed0d5
在文件中加入一些新的内容,然后再次提交:
echo ‘# testing’ >> repo.rb
git commit -am ‘modified repo a bit’:直接将工作区中的修改过的文件加入暂存区,再执行一次提交,但是我一般不常用
再次查看master对应的最新一次commit object对应的tree包含的blob,发现原来的文件换了一个,也就是修改后的文件重新存储了一份
git cat-file -p master^{tree}
总结:哪怕是很大的文件,比如说20kb的一个代码文件,每次改动一点代码,git也是存储改动后的版本对应的一个完整的文件;如果这个20kb的代码文件修改了100次,会怎么样?存储100个版本对应的文件,也就是100个文件,2000kb ~ 2MB。所以这样的话对存储的压力还是蛮大的。。。。
git实际上是可以更加智能的处理这种文件改动的。默认情况下,git会使用loose格式存储文件(loose,松散格式,采取这个文件的每个版本,就存储一个完整的单独的文件),但是一段时间过后,git会将多个loose格式的松散文件打包到一个packfile二进制文件中,来节省磁盘空间。
什么时候git会进行packfile打包的操作呢?两个时机:我们手动执行git gc操作,或者是将文件push到远程服务器的时候,git会看一下loose格式文件是不是太多了,如果是,则进行打包合并。
git gc:garbage collector,jvm gc是不一样的,git用来处理自己的文件的
如果我们将本地的commit数据push到了远程服务器后,就代表远程服务器包含了我们的数据了,此时git就可能会执行一次packfile打包
此时我们可以手动执行一下git gc命令,来看看效果
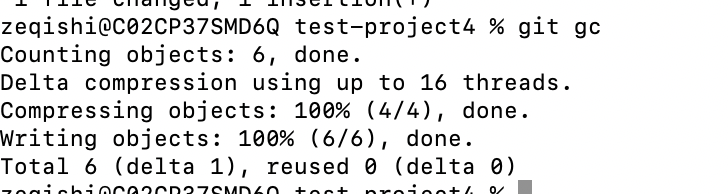
此时再次用下面的命令看一下objects目录下的内容:find .git/objects -type f,之前应该是一堆hash值组成的目录和文件,包含完了十几个object(blob,tree,commit),会发现出现了objects/info/packs和objects/pack等新的目录。
我们是将之前所有的hash值组成的文件打包成了一个packfile文件,进行了压缩以及合并
pack包含了两个文件,一个是packfile包含了打包的所有数据,一个是index文件,包含了每个blob object在packfile中的offset,通过.idx文件标识出每个object在.pack文件里是哪一个部分

git做文件存储的优化,两块:多个文件打包成给一个,压缩,二进制格式,packfile,节省空间;在打packfile的时候,就会对我们刚才说的那种情况,大ruby文件,仅仅保留第一个版本对应的完整内容,然后之后的版本都是直接保留的是它的那些delta增量内容,后面的版本就不是全部保留全量内容了,进一步节约空间
git,git gc;git push,自动会做打packfile
实际上,在git进行打包packfile的时候,就会对一个文件的多个版本,仅仅保留其每次增量修改数据,避免对一个文件保留多个全量的版本快照。
用下面的命令看一下:
git verify-pack -v .git/objects/pack/pack-978e03944f5c581011e6998cd0e9e30000905586.idx
会发现ruby大文件,第一个版本仅仅包含9kb的内容,但是第二个版本包含了22kb的内容,所以这里就做了增量处理和优化,仅仅对一个大文件的最新的版本保留了全量的内容,但是对之前的版本都是增量内容
总结一下
(1)git gc / git push,会执行packfile的压缩优化
(2)将.git/objects下的各种object对应的文件,压缩成一个packfile
(3)每个packfile都对应一个.pack文件和一个.idx文件,.pack文件包含了多个object的内容,.idx文件包含了每个object在那个.pack里面的offset偏移量
(4)在打packfile的意义:多个文件合并一个,节省空间:对大文件进行增量处理,仅仅是最新的版本保留全量内容,之前的版本保留增量内容
(5)用git verify-pack -v命令,可以查看.pack文件里包含的具体内容
五、在动手实践中掌握远程分支的内幕原理
对于远程仓库的分支,本地都是有一个对应的分支是追踪那个远程分支的,同时本地还有一个分支是跟本地追踪分支关联起来的
远程仓库:master
本地仓库
1、origin/master,本地追踪分支,跟远程的master完全是需要对应起来的,远程的master指向哪个commit,每次git fetch origin,就会将远程仓库的提交历史拉取到本地跟本地的提交历史进行合并,同时将本地的origin/master指向远程仓库的master指向的那个commit
本地分支(origin/),追踪了远程的分支(),每次git fetch之后,提交历史合并之后,本地分支(origin/*)指向的commit都会跟远程分支保持一致
不只是origin/master,origin/feature/001,origin/feature/002,origin/release/v1.0
2、master,跟origin/master关联起来的
本地的master,是跟本地的origin/master关联起来的,作用是在git pull和git push
(1)如果执行git pull,会执行远程和本地的提交历史进行合并,origin/master会指向远程仓库master指向的那个commit,同时将origin/master指向的commit跟本地的master指向的commit进行合并,合并之后会出现一个新的commit,同时master会指向那个合并后的commit,然后那个origin/master不变还是指向原来的那个commit
git pull,相当于是两个命令:git fetch origin + git merge origin/master
相当于就是将远程仓库的提交历史拉取下来,然后合并在一起,本地的origin/master指向最新的commit,接着将本地的master与origin/master进行合并
1)将远程仓库的提交历史拉取到本地进行合并,一个commit可能会出来多个分叉
2)同时将origin/master跟远程仓库的master指向一个commit
3)将本地的master和origin/master进行合并,可能需要解决冲突
(2)如果执行git push,会将本地的origin/master指向master指向的那个指针,同时会将本地提交历史推送到远程进行合并,然后远程仓库的master分支会指向最新的那个commit
每次执行git remote add命令之后,实际上就会在.git/config文件中加入一段配置,类似下面:
[remote “origin”]
url = git@192.168.31.80:OA/test-project.git
fetch = +refs/heads/:refs/remotes/origin/
[branch “feature/001”]
remote = origin
merge = refs/heads/feature/001
[branch “master”]
remote = origin
merge = refs/heads/master
我们之前跟大家说过,如果你在本地想搞一个跟类似origin/feature/001关联起来的本地分支,让git push和git pull有效果,git checkout -b feature/001 origin/feature/001,这段命令执行之后,就会在.git/config中加入[branch]配置,标注了本地分支跟origin/*追踪分支之间的关联关系
那么什么是refspce呢?实际上就是fetch后面的那串东西,+refs/heads/:refs/remotes/origin/,就是refspce
refs/heads/,代表的是远程仓库被追踪的分支,远程仓库的master
refs/remotes/origin/,代表的是本地仓库用来追踪远程仓库的分支,本地仓库的origin/master分支
+,代表的是在执行git pull的时候,不是要将远程分支和本地分支进行merge么?即使不是fast-forward的类型,是3-way merge也是要去执行的
在执行git remote add命令的时候,本地的git客户端会执行fetch命令获取远程仓库的refs/heads/*下面的分支,然后将其写入本地的refs/remotes/origin/*下面去。所以之前说的那些本地追踪远程的分支,比如origin/master之类的,实际上指的就是refs/remotes/origin/master代表的分支
origin/master等等追踪分支,在本地是放在哪儿的呢?
我们是可以手动指定多个refspce的
根本就不用的下面的语法,介绍一下,refspec指定多个,一般不用
[remote “origin”]
url = https://github.com/schacon/simplegit-progit
fetch = +refs/heads/master:refs/remotes/origin/master
fetch = +refs/heads/qa/:refs/remotes/origin/qa/
[remote “origin”]
url = https://github.com/schacon/simplegit-progit
fetch = +refs/heads/:refs/remotes/origin/
push = refs/heads/master:refs/heads/qa/master
六、GitHub:学习如何维护开源项目以及给开源项目贡献代码
我觉得我现在是没什么太大必要去讲解这块的
因为这个开源项目的贡献,包括自己开源了一个项目,基于github怎么玩儿,也是包含在git课程里的,而且之前我在录制的时候有一个同学就问了我这个问题
1、注册一个github账号
(1)会让你填写一个自己的用户名,我当时因为是给龙果在讲课,roncoo-eshop
2、发布开源一个项目
(1)start a project
(2)将自己本地的一个项目代码上传到github上去
git remote add origin https://github.com/roncoo-eshop/test-project.git
git push -u origin master
(3)管理collabrator,这些人是你的开源项目的重要合作伙伴,他们是可以审核别人提交的pull request代码合并请求的
(4)你自己当然平时可以写代码了
你当然是可以自己拉个什么分支,在那个什么写代码,但是为了维护开源项目的版本
(5)比如你现在要搞一个v1.0版本,拉一个对应的分支出来
(6)接着,包括你在内的所有人都依据下面的流程来对v1.0这个版本进行贡献
3、给开源项目贡献代码
给开源项目贡献代码,跟公司里的是不一样的,不是说直接就可以对某个分支进行push的。是需要执行一个fork,相当于是在自己的账号里,克隆出一份完整的代码,然后自己就在自己命名空间的fork项目里进行拉分支,开发,最后请求到原始开源项目里进行合并。
如果要给某个开源项目进行贡献,通常都是在GitHub上,fork一个开源项目,fork之后这个项目就会有一份副本存在于我们自己的命名空间中,这样我们不需要开源项目的push权限也可以贡献代码了
(1)fork出来一份,在自己的账号里有一个拷贝的项目,同时将自己的ssh key加入github,将fork出来的项目克隆到本地
(2)从fork出来的项目的master分支创建一个自己的分支出来
(3)在那个分支上提交代码
(4)push分支和代码到自己fork出来的项目
(5)在github上提交一个pull request,对开源项目提交
七、Git总结

八、授人以渔
是很多同学都给提的一个要求,或者说是一个建议,我平时是怎么学习技术的,然后呢,大家在学习完了课程以后,以后自己对这个技术如何持续学习
1、我是怎么学习git技术的
1)找学习资料:中国人写的书,老外的书被翻译,原版的英文书籍,官方文档,技术博客
第一步:技术博客,你想快速了解和入门一个技术
百度搜索,***教程,***入门教程,***学习,Git教程
找一篇或者几篇精品博客,一定是中国人写的,写的是比较精良的,从下载、安装,案例,一步一步有过程的,确保说,你对这个技术,参照这个博客,一步一步做,可以先入个门,一定能做出来,基本掌握一点东西
告诉大家,看技术博客,只有三个作用:入门;开拓视野;经验总结
2)深入学习,推荐官方文档
过一遍,官方文档,100%过了一遍之后,这个技术就到80%了。
剩下20%,看技术博客,实践经验总结,最重要的,自己在项目中反复实践,通过自己的项目和业务驱动,去考虑如何用这个技术,设计架构,在项目上线之后,积累这个技术实践中遇到的一些问题
这里就有问题了,有的技术官方文档不是很好的
比如这个git,就是类似操作手册之类的东西,用于参考,不用于学习
比如activemq,就是很混乱,没有层次感,没有结构感
还有一个问题,就是官方文档都是纯英文的,就我了解,国内程序员,能无障碍快速阅读英文文档,而且深入透彻理解的,1%,千分之一。一般英语都不太好。
3)书
中国人写的
Git权威指南:这本书我不推荐看,写的很好,但是实在是不太适合学习用
完全学会Git的24堂课:台湾,写的入门,粗糙,没法跟着一步一步做,知识点的总结
老外写的被翻译了
5本:翻译的书,翻译的很烂,我就几乎没见过翻译过来的书让我觉得翻译的很好,语句不通,用词尴尬,味如嚼蜡,很枯燥,看不懂
强烈不推荐看翻译的书
老外写的原版
Pro Git(The second edition):五星推荐,特别棒,最好的一本Git学习的书籍
所以说推荐看这本书,我当时也是把这本书的第一版和第二版都看过,Pro Git这本书
不到1%的工程师,我觉得有能力通过读Pro Git这本书透彻了解Git这个技术
4)到此为止总结一下
大部分,99%的工程师,对git的学习,主要停留于就是那种技术博客级别的一点简单的了解,对各种书籍,官网,几乎没办法做非常深入的学习,对git的掌握都很浅
5)光是上面那些不够
我记得第一次我做直播的时候,有一个同学,问我,老师,你是不是看完官方文档就可以出来讲课?吓人了,当然不是了
光看完上面那些东西,是不足以讲课的,讲出来的课也是照本宣科,照着官方文档讲
6)在实践中,在各种项目中,去大量的运用这个技术,设计架构,采坑,积累经验
7)还不够,此时还差了最后一点点火候,对这个技术,还可以深入的去研究其源码,原理,内幕,底层
入门(技术博客) + 知识体系(官网/英文原版书) + 大量项目实践(采坑,积累经验) + 深入底层(源码、原理、内幕)
8)BAT等大的公司出来的架构师,就是很牛,基本上都是走的我这个线路
快速建立起来一个技术的知识体系:一周之内看完一个技术所有的英文官方文档,或者是原版书籍,大公司硕士以上的名校生学历,英文都很好,国外英国留学回来的,英文是没有问题的
Pro Git,600页,我一周可以看两遍
大量项目实践,小公司里技术实践的环境不是太好,大公司里面,核心项目,几十人上百人协作的那种大项目,高并发,高可用,高性能,稳定性,扩展性,重构,基础架构,最新技术的使用,积累国内,行业内顶尖的一手技术经验
小公司里的同学:不是说每个人都有的机会,尽可能的自己去给自己创造机会i,抓住机会,项目里去实践和积累经验
深入底层和源码:经过大量的技术研究,技术功底是很深厚;对这门技术之前了解的体系已经很透彻了;在项目里有大量的实践和积累 => 源码,原来如此 => 新增对一门技术的深入理解
这里有一个问题
现实问题,技术学习的路径:名校出身的硕士+BAT核心团队工作经历+聪明的头脑,技术可以成长的很快,5年,相当于普通人工作15年都不一定能超过他们
千千万万普通的同学而言,如何去提高技术呢?
1、好好跟着学架构师课程
这次肯定是用100%最大努力,毫无保留的给大家真的兜底讲出来完整的一个BAT架构师技术体系,真实的大型项目,做到的
2、高质量的视频课程
我多年的经验积累,我把整个架构师的技术体系,每一个技术,咬碎嚼烂,讲给大家,对大家是最高效的最好的学习途径
maven:《maven实战》,断断续续,个把月;几天就看完了
git:《Pro Git》英文书,一两个月才搞完;大白话+画图+接地气,讲课程,一周之内就搞定了
你可以直接学习到我的技术体系,和我的经验积累,同时你的学习速度可以提高好多倍
3、自己如何继续去学习技术
git技术,其实你跟着我的视频学完,看两遍之后,不用去看那些书也可以了
(1)如果说你想继续去看,同时磨炼自己读英文文档的能力,《Pro Git》英文版,看一遍,慢慢看,提升你的英文文档的学习能力
(2)git版本不断在变化的,官网 看每个版本的更新的新功能,release notes,看每一个新功能增加了什么东西
(3)你可能会在公司里去做项目,碰到一些问题:找我请教:跟其他同学交流:百度+google,报错,搜索
(4)在公司里大量实践git,自己去搭建gitlab服务器,整个项目选择一种合适的开发工作流去做,日常碰到各种git问题和场景,用高阶技巧去处理,自己反复理解git底层的内幕原理
4、总结一下
对大家而言
(1)学习视频课程,尤其是架构师课程:替代你去读官方文档,英文原版书,效率提高很多倍
(2)实践:吸取我的实践经验,你自己多在项目里去用和实践
(3)深入底层:跟着架构师课程走,我会给你去讲解底层,效率会提高很多
(4)直接采取我的学习方法,我觉得对大部分同学不一定合适;但是如果跟着架构师课程走,那么基本可以达到我的学习方法的效果,加上自己也去进行一些技术的积累,完美















 353
353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









