







《智能计算系统》——神经网络基础
线性回归
为什么会用到线性回归?
线性回归作为机器学习方法的一种基础理论,也是最简单的机器学习方法,使用线性回归,找到一些点的集合背后的规律,进而更好的理解机器学习的原理。
示例:
线性回归主要分为一元线性回归与多元线性回归,接下来以各种因素对房屋售价的影响作为例子来进行展示:
一元线性回归(使用tensorflow实现)
训练步骤:
1. 导入所需要的库
2. 确定训练数据(导入数据或者随机生成数据) (包含数据的归一化处理,min-max标准 化,使结果值映射到[0 ,1]之间)
3. 随机生成初始变量:权重w,偏置b。
4. 接着创建线性模型 y=wx+b。
5. 还需要创建损失函数loss (例子中使用的是均方误差损失函数)
6. 再使用随机梯度下降算法优化损失函数 (这里使用了GradientTape自动求导)
1. 导入所需要的包
import tensorflow as tf
import numpy as np
import pandas as pd
2. 确定训练数据
# 训练数据
data_ = pd.read_csv('ex1data2.csv', delimiter=',',names=['square','number','price'])
X_ = np.array(data_['square'])
Y_= np.array(data_['price'])
# 数据处理:缩小比例,提升精度,简单实现标准化:min-max标准化(Min-Max Normalization)
X = (X_-X_.min())/(X_.max()-X_.min())
Y = (Y_-Y_.min())/(Y_.max()-Y_.min())
n_samples = X.shape[0] # 获取训练数据的大小,读取矩阵的长度,shape[0]就是读取第一维度数据
3. 随机初始化变量:权重w,偏置b
# 随机初始化权重,偏置
np.random.seed(20)#设定随机数种子,保证每次生成w,b都是一样的
W = tf.Variable(np.random.randn(),name="weight1")
b = tf.Variable(np.random.randn(),name="bias")
4. 定义线性回归模型
# 定义回归模型:线性回归(Wx+b)
def linear_regression(x):
return W * x + b
5. 定义损失函数(MSE:Mean Squared Error)
均方误差是指参数估计值与参数真值之差平方的期望值;
MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。
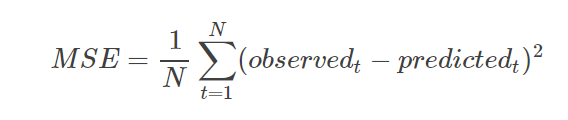
# 定义损失函数:MSE
def mean_square(y_pred,y_true):
return tf.reduce_sum(tf.pow(y_pred-y_true,2)) /(2*n_samples)
6. 优化损失函数:SGD(随机梯度下降法)
# 使用随机梯度下降对损失函数进行优化
optimizer = tf.optimizers.SGD(learning_rate) # learning——rate设置为0.1
# 优化过程
def run_optimization():
# 将计算封装在GradientTape中以实现自动微分
with tf.GradientTape() as g:
pred = linear_regression(X) #调用回归模型函数进行预测
loss = mean_square(pred,Y) #调用损失函数
# 计算梯度
gradients = g.gradient(loss,[W,b])
# 按gradients更新 W 和 b
optimizer.apply_gradients(zip(gradients,[W,b]))
7. 训练过程
# 针对给定训练步骤数开始训练
for step in range(1,training_steps + 1): #training——step设置为1000
# 运行优化函数,以更新W和b值
run_optimization()
# 每隔dispaly_step的间隔打印一次
if step % display_step == 0: #display——step设置为50
pred = linear_regression(X)
loss = mean_square(pred, Y)
print("step:{}, loss:{}, W:{},b: {}".format(step, loss, W.numpy(),b.numpy()))
8. 预测
x_test=130
predict=linear_regression(x_test)
print('预测值是:{}'.format(predict))
9. 结果显示


多元线性回归(使用sklearn实现)
训练步骤:
1. 导入所需要的包
2. 确定训练数据
3. 划分训练集
4. 数据标准化
5. 进行训练
6. 检验精准度
1. 导入所需要的包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import linear_model, metrics
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
2. 确定训练数据
# 确定训练数据
data_ = pd.read_csv('ex1data2.csv', delimiter=',',names=['square','number','price'])
used_features=['square','number']
X_ = np.array(data_[used_features])
Y_ = np.array(data_['price'])
3. 划分训练集
#划分训练集
X_train, X_test, Y_train, Y_test = train_test_split(X_, Y_, test_size=0.3, random_state=1)
4. 数据标准化
# 数据标准化
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test = ss.transform(X_test)
Y_train = ss.fit_transform(Y_train.reshape(-1,1))
Y_test = ss.transform(Y_test.reshape(-1,1))
5. 进行训练
# 进行训练,方程求解
model = linear_model.LinearRegression()
model.fit(X_train , Y_train)
print('权重w:{} 截w距b:{}'.format(model.coef_,model.intercept_))
6. 检验精准度
# 检验模型准确度
Y_pred = model.predict(X_test)
MSE = metrics.mean_squared_error(Y_test, Y_pred)
RMSE = np.sqrt(metrics.mean_squared_error(Y_test, Y_pred))
print('MSE:',MSE)
print('RMSE:',RMSE)
7. 预测
# 预测
x_test=[[130,3]]
y_pred = model.predict(x_test)
print('预测结果:{}'.format(y_pred))
8. 结果
权重:[[ 0.92527503 -0.05996435]] 截距b:[-2.40027546e-16]
MSE: 0.4341356897741185
RMSE: 0.658889740225266
预测结果:[[120.16582573]]

神经网络训练:正向传播与反向传播
训练步骤:
1. 对权重矩阵进行初始化
2. 进行正向传播,计算输入到隐层,隐层到输出层之间的数据
3. 计算初始误差
4. 进行反向传播,对输出到隐层,隐层到输入层之间的权重进行优化,并更新权重
5. 进行正向传播,计算输入到隐层,隐层到输出层之间的数据
6. 计算误差
7. 重复进行4—6直至误差接近于0,找到最优权重
1. 对权重矩阵进行初始化
# 初始化一些参数
l = 0.1 #学习率
numIter = 30000 #迭代次数
w1 = [[0.15, 0.20], [0.25, 0.30]] # 输入层到隐藏层权重
w2 = [[0.40, 0.45], [0.50, 0.55]] # 隐藏层到输出层权重
b1 = 0.35
b2 = 0.60
x = [0.05, 0.10]
y = [0.01, 0.99]
2. 进行正向传播,计算输入到隐层,隐层到输出层之间的数据

隐层在激活函数之前的输出:

上面得到的三个数分别做sigmoid计算,得到隐层的输出:
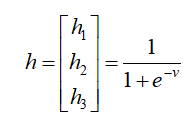
# 正向传播,dot函数是常规的矩阵相乘
v1 = np.dot(w1, x) + b1
h1 = sigmoid(v1) # 得到隐层输出
v2 = np.dot(h1,w2) + b2
h2 = sigmoid(v2) # 得到输出层输出
3. 计算初始误差(MSE)
#计算初始误差
loss = tf.losses.MSE(y, h2)
print( 'init_y:{},init_loss:{}'.format(h2,loss))
4. 进行反向传播,对输出到隐层,隐层到输入层之间的权重进行优化,并更新权重,权值调整的过程,也就是网络的学习训练过程
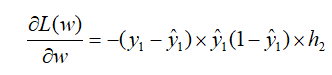
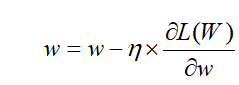
# 分为两次
# 第一次是输出层对隐藏层
deta2 = np.multiply(-(y-h2), np.multiply(h2, 1-a2))
# 第二次是隐藏层对输入层
deta1 = np.multiply(np.dot(np.array(w2).T, deta2), np.multiply(h1, 1-h1))
# 反向更新权重w2
for i in range(len(w2)):
w2[i] = w2[i] - l * h1 * deta2[i]
# 反向更新权重w1
for i in range(len(w1)):
w1[i] = w1[i] - l * np.array(x) * deta1[i]
5. 继续进行正向传播,计算输入到隐层,隐层到输出层之间的数据
# 继续正向传播
v1 = np.dot(w1, x) + b1
h1 = sigmoid(v1)
v2 = np.dot(w2, h1) + b2
h2 = sigmoid(v2)
6. 计算误差
loss = tf.losses.MSE(y,h2)
if (n%1000==0):
print('step:{},y:{},loss:{}'.format(n,h2,loss))
7. 重复进行4—6直至误差接近于0,找到最优权重
使用一个循环进行不断的迭代更新,找到最优w,使损失函数最小
for n in range(numIter):
# 分为两次
# 第一次是输出层对隐藏层
deta2 = np.multiply(-(y-h2), np.multiply(h2, 1-h2))
# 第二次是隐藏层对输入层
deta1 = np.multiply(np.dot(np.array(w2).T, deta2), np.multiply(h1, 1-h1))
# 更新权重
for i in range(len(w2)):
w2[i] = w2[i] - l * h1 * deta2[i]
# 更新权重
for i in range(len(w1)):
w1[i] = w1[i] - l * np.array(x) * deta1[i]
# 继续正向传播
v1 = np.dot(w1, x) + b1
h1 = sigmoid(v1)
v2 = np.dot(w2, h1) + b2
h2 = sigmoid(v2)
loss = tf.losses.MSE(y,h2)
if (n%1000==0):
print('step:{},y:{},loss:{}'.format(n,h2,loss))
8. 结果
#初始权重以及损失函数
init_y:[0.75689851 0.76768012],init_loss:0.3036417624204682
#训练25000次得到的权重以及损失函数
step:22000,y:[0.02194797 0.97811127],loss:0.00014204801047167987
step:23000,y:[0.02153953 0.97851125],loss:0.00013257612909867159
step:24000,y:[0.02115844 0.97888487],loss:0.00012402846669869828
step:25000,y:[0.02080184 0.97923484],loss:0.00011628435812534168















 1886
1886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









