







目录
历程

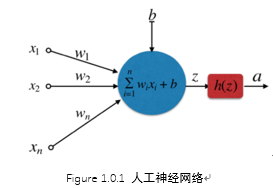
人工神经网络
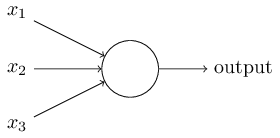
右图的圆圈就代表一个感知器。它接受多个输入(x1,x2,x3...),产生一个输出(output),
为了简化模型, 约定每种输入只有两种可能:1 /0。
所有输入都是1--条件都成立--输出--1;
所有输入都是0--条件都不成立--输出--0。
按照假设,输出只有两种结果:0和1。但是,模型要求w或b的微小变化,会引发输出的变化。如果只输出0和1,未免也太不敏感了,无法保证训练的正确性,因此必须将"输出"改造成一个连续性函数.

为什么要是深度神经网而不是”肥胖“(宽度)神经网络---参数
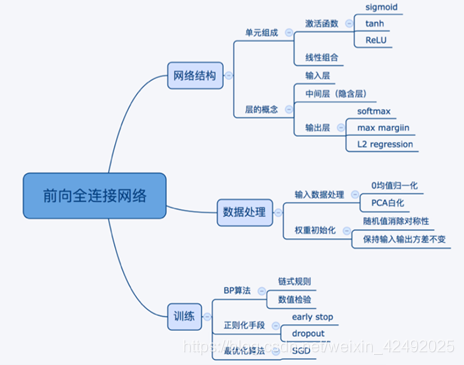
激活函数
需要原因:就是使神经网络具有拟合非线性函数的能力,使其具有强大的表达能力
万能近似定理:一个前馈神经网络如果具有线性层和至少一层具有"挤压"性质的激活函数(如signmoid等),给定网络足够数量的隐藏单元,它可以以任意精度来近似任何从一个有限维空间到另一个有限维空间的borel可测函数
要有带有“挤压”性质的激活函数”:
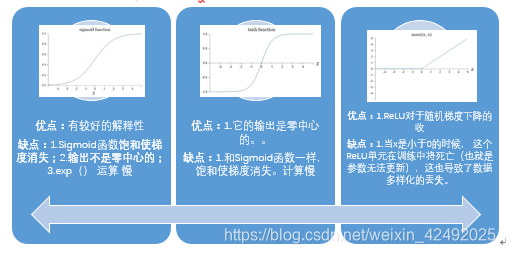
怎么用激活函数
用ReLU非线性函数。注意设置好学习率可以监控你的网络中死亡的神经元占的比例。
模型参数

损失函数—交叉熵
为什么用交叉熵而不用平方损失?

平方:偏导数受激活函数的导数影响 ,sigmoid 的导数在输出接近 0 和 1 的时候 是非常小的,这会导致一些实例在刚开始训练时学习得非常慢
交叉熵:权重学习的速度受到 σ(z) − y 影响,更大的误差,就有更快的学习速度,还避免了二次代价函数方程中因 σ′(z) 导致的学习缓慢
CNN
由来:图像领域,28*28*1的图片进行处理,采用15个神经元,会有784*15*10+15+10=117625个参数
CNN将输入数据看成三维的张量 (Tensor), 之前的NN把输入数据看作向量
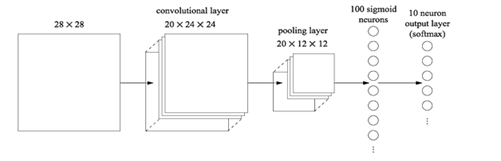
Figure 0.1 CNN
Convolution (卷积)
本质:提取图像不同频段的特征,可降低参数数量;稀疏交互防止过拟合;参数共享,减小存储需求
更本质是积分,将时域->频域相乘-反变换->时域的积分

Pooling
作用
- 整合特征-降维
- 保证某种不变性(旋转、平移、伸缩、对称)(文字:获得定长输出)
- 减少计算量
- 提高感受野大小
方式
- Max—保留纹理(减小卷积层参数误差造成估计均值偏移)
- Mean—保留背景(减低邻域大小受限造成的估计值方差)
- Stochastic
Zero Padding
有时候会将输入数据用0在边缘进行填充,零填充可以控制输出数据的尺寸(最常用的是保持输出数据的尺寸与输入数据一致)
Fully Connected Layer
作用
如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。FC可视作模型表示能力的“防火墙”,特别是在源域与目标域差异较大的情况下,FC可保持较大的模型capacity从而保证模型表示能力的迁移。
RNN
循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据
BPTT算法是针对循环层的训练算法,它的基本原理和BP算法是一样的,也包含同样的三个步骤:
- 前向计算每个神经元的输出值;
- 反向计算每个神经元的误差项值,它是误差函数E对神经元j的加权输入的偏导数;
- 计算每个权重的梯度。
最后再用随机梯度下降算法更新权重。
递归神经网络 (RNN)
代表循环网络的另一个扩展,它被构造为深的树状结构而不是RNN的链状结构,因此是不同类型的计算图
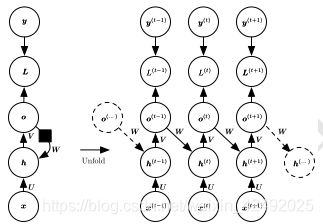
递归神经网络的权重和偏置项在所有的节点都是共享的
架构
Hopfield
Hopfield 网络实质上是二进制的,各个神经元要么打开(激活),要么关闭(未激活)
能够学习(通过Hebbian学习)多种模式,并且在输入中存在噪声的情况下收敛以回忆最接近的模式。Hopfield 网络不适合用来解决时域问题
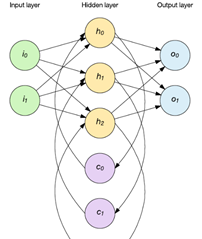
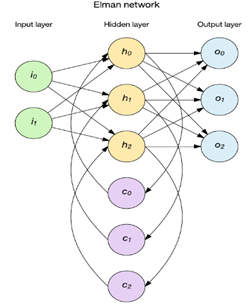
简单递归网络
两种流行方法是 Elman 和 Jordan 网络
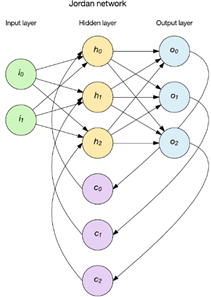
LSTM&GRU
权重爆炸可能引起权重振荡。梯度消失又导致网络调参失去方向感
梯度截断有助于处理爆炸的梯度;为了解决消失的梯度和更好地捕获长期依赖,一种方法是使用LSTM以及其他自循环和门控机制;另一个想法是正则化或约束参数,以引导信息流
- LSTM 通过引入巧妙的可控自循环,以产生让梯度能够得以长时间可持续流动的路径避免长期依赖问题,关键就是细胞状态
- GRU 它将忘记门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态,和其他一些改动
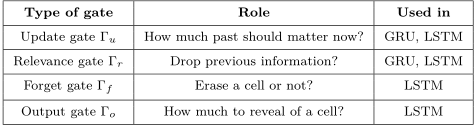
-

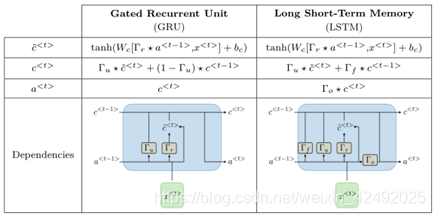
由于传统的RNN存在梯度弥散问题或梯度爆炸问题,导致第一代RNN基本上很难把层数提上去,因此其表征能力也非常有限,应用上性能也有所欠缺。于是,胡伯提出了LSTM,通过改造神经元,添加了遗忘门、输入门和输出门等结构,让梯度能够长时间的在路径上流动,从而有效提升深度RNN的性能。














 1215
1215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









