







我们在使用爬虫的时候,时不时需要爬取一些图片。而Scrapy这个强大的框架给我们提供了内置的图片管道类,我们可以直接使用,或者根据需要进行覆盖重写。
下面我们以爬取P站的图片为例,进行讲解ImagesPipline的使用。
网页分析

我们要爬取这些图片,再通过相关推荐跟进url

编写项目
首先我们需要创建一个项目
切换到项目目录,bash输入:
scrapy startproject papzhan
项目结构如下:
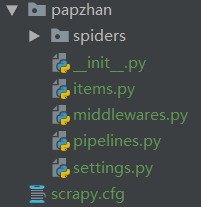
cd到spiders目录,输入以下命令生成蜘蛛文件
scrapy genspider -t crawl pzhan moe.005.tv
要使用Scrapy内置的图片管道,items.py必须要指定image_urls和images
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class PapzhanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#固定写法
image_urls = scrapy.Field()
images = scrapy.Field()
无需改动piplines.py文件,需要修改settings.py文件
# 注释掉robots协议
# ROBOTSTXT_OBEY = True
#编写你的请求头
USER_AGENT = ""
#启用scrapy内置的图片管道
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline': 1,
}
#指定存储图片的路径
IMAGES_STORE = "./p站"
最后编写pzhan.py文件,如下:
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from papzhan.items import PapzhanItem
class PzhanSpider(CrawlSpider):
name = 'pzhan'
allowed_domains = ['moe.005.tv']
start_urls = ['http://moe.005.tv/80480.html']
#跟进规则
rules = (
Rule(LinkExtractor(allow=r'http://moe.005.tv/',restrict_xpaths=('//div[@class="zhuti_w_list"]/ul/li')), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = PapzhanItem()
item["image_urls"] = response.xpath('//div[@class="content_nr"]/div/img/@src').extract()
yield item
编写完毕。在命令行输入
scrapy crawl pzhan
运行爬虫
可以看到在我们指定的p站文件夹下面生成了一个full文件夹
full文件夹下就是我们爬取到的图片了,图片的名字是根据图片url加密生成的,无需我们关心图片的命名。

以上就是Scrapy内置的图片管道类的使用了,是不是非常方便?当然,如果对于图片的命名有要求,或者需要分类成不同的文件夹就需要重写图片管道类了。
那么如何重写ImagesPipline呢?
我们先来分析需求
每一组图片是有一个标题的,但是每一张图片没有名字,所以名字我们还是采用根据url加密的方式,而将每一组图保存到相应的文件夹,那么我们就需要拿到每一组图片的url列表和每一组图片的标题

items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class PapzhanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_urls = scrapy.Field()
images = scrapy.Field()
image_name = scrapy.Field()
piplines.py
import os
from scrapy.utils.python import to_bytes
import hashlib
from scrapy.pipelines.images import ImagesPipeline
from scrapy import Request
class mypipelines(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item["image_urls"]:
yield Request(url=image_url, meta={"item": item})
def file_path(self, request, response=None, info=None):
## start of deprecation warning block (can be removed in the future)
def _warn():
from scrapy.exceptions import ScrapyDeprecationWarning
import warnings
warnings.warn('ImagesPipeline.image_key(url) and file_key(url) methods are deprecated, '
'please use file_path(request, response=None, info=None) instead',
category=ScrapyDeprecationWarning, stacklevel=1)
# check if called from image_key or file_key with url as first argument
if not isinstance(request, Request):
_warn()
url = request
else:
url = request.url
# detect if file_key() or image_key() methods have been overridden
if not hasattr(self.file_key, '_base'):
_warn()
return self.file_key(url)
elif not hasattr(self.image_key, '_base'):
_warn()
return self.image_key(url)
## end of deprecation warning block
#对每一张图片的url进行加密
image_guid = hashlib.sha1(to_bytes(url)).hexdigest() # change to request.url after deprecation
#每一组图片的标题名
image_name = request.meta["item"]["image_name"].replace("/"," ").replace("\\"," ")
#如果文件夹不存在则创建文件夹
if not os.path.exists("full/{}".format(image_name)):
os.makedirs("full/{}".format(image_name))
return 'full/{}/{}.jpg'.format(image_name, image_guid)
settings.py
# 注释掉robots协议
# ROBOTSTXT_OBEY = True
#编写你的请求头
USER_AGENT = ""
#启用自己编写的图片管道
ITEM_PIPELINES = {
'papzhan.pipelines.mypipelines': 1,
}
#指定图片的存储路径
IMAGES_STORE = "./p站"
pzhan.py
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from papzhan.items import PapzhanItem
class PzhanSpider(CrawlSpider):
name = 'pzhan'
allowed_domains = ['moe.005.tv']
start_urls = ['http://moe.005.tv/80480.html']
rules = (
Rule(LinkExtractor(allow=r'http://moe.005.tv/',restrict_xpaths=('//div[@class="zhuti_w_list"]/ul/li')), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = PapzhanItem()
# item["image_name"] = response.xpath('//h1/text()').extract_first()
item["image_urls"] = response.xpath('//div[@class="content_nr"]/div/img/@src').extract()
item["image_name"] = response.xpath('//div[@class="content_w_box"]/h1/text()').extract_first()
yield item
最后运行爬虫,看到full文件夹下的图片被分类放在了相应文件夹下
,完成需求。

作为应用最为广泛的爬虫框架,Scrapy同样还内置了文件管道,感兴趣的朋友可以查阅Scrapy官方文档
今天的分享就到这里了,希望大家能够有所收获,欢迎关注,一起进步~















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









