







1. 埋点相关文档:
埋点涉及到的各种平台
XX平台:抓取实时埋点日志
正则平台:埋点case正则表达式
XX监控平台:关注埋点监控日报
BI埋点数据监控平台:大盘数据
XX报警平台:但暂不支持正则报警,待RD完善
2. 搜索埋点测试方法
2.1 什么是埋点
埋点又称为“数据采集”,例如在APP端埋点可以将此APP中的用户行为、APP性能、设备信息、交互信息等进行自定义收集,所以将采集数据的这一过程称之为埋点。公司内部埋点是发生在数据结论之前的一种行为,在拿到某个数据之前一定要进行埋点,例如向大数据部门提数据需求之前要先向产品部门提埋点需求,只有埋点需求执行完成,才会产生和记录到需要的数据,再由大数据部门来实现需求的数据落地
根据链接中spm和scm的组合,我们就能追踪到这条链接,是由什么内容提供方提供的,并且由用户在哪个指定页面的指定位置点击产生的。通过spm和scm的组合效果评估,能知道什么位置投放什么内容效果最好,什么样的内容投放在什么位置效果最佳,从而达到将合适的内容推送到合适的位置的效果。后期根据FBI数据统计得知大盘数据
2.2 埋点的分类
目前业务日志分为两大类
-
系统自动采集的页面浏览(PV, Page View)日志. 这部分日志在页面被浏览器打开时自动发送, 一般不需要用户和前端开发干预
-
其他自定义日志. 这部分日志不会自动发出, 而是由开发同学自己编写代码, 在用户执行了某些交互(如点击, 滑动, 键盘输入)或者触发某些条件(如游戏通关播放过场动画, 视频播放到某个特殊时点)时 , 通过调用日志接口主动上报日志(或直接发送日志到日志服务器).
点击埋点和曝光埋点和页面埋点
- 点击埋点
- 用户进行了点击等交互操作后的埋点
- 曝光埋点
- 整体页面曝光:页面被展示时的埋点
- 局部页面曝光:模块或坑位出现在视口时的埋点
2.3 埋点测试的验证模式及分析
4个重要步骤:行为触发->上报埋点->读取埋点->验证埋点
2.3.1 行为触发
点击、暴露某个控件,离开某个页面等,可以认为是一次行为。触发行为可以通过手工和自动化脚本
2.3.2 上报埋点
触发行为后,自然就要相应的上报一次埋点,上报埋点本身是从sdk进行上报的,可以研究下工作原理和其上报的链路
2.3.3 读取埋点
要对埋点进行实时校验,就要实时获取到埋点
搞清楚sdk是如何上报的埋点的,就可以去对其拦截,从而拉取到实时的埋点日志,并对其做一些标记,以此来做校验
2.3.4 验证埋点
当行为和埋点日志都被感知到并采集到后,可以根据数据的特征、时间、链路信息等去进行关联行为及埋点事件,并根据场景进行验证
背景
由于搜索埋点数据过于老化,导致统计方面的一些工作的不方便。经过产品评估后决定需要重构部分埋点字段的参数,所以搜索的iOS端和Android端开始了一段
全部埋点的测试之路
面临的困难
Ø❎每次测试任务量巨大,要求QA覆盖全部46个类型卡片,100+种状态
Ø❎埋点日志字段较多。曝光埋点每个日志多达300+key value
Ø❎埋点测试每个季度不能出一个bug,不允许出错
Ø❎流量分散,老的SDK中包含大量且复杂的版本控制逻辑
Ø❎埋点由客户端下发,容错率和迭代效率较低
解决办法
Ø✅ 技术侧:通过链路配置和场景路由,将不同场景的流量分发致对应的处理链路
Ø✅ 技术侧:编写scheme解析器:支持脚本动态解析、执行自定义方法、谓词逻辑判断; scheme之间支持继承和引用下发数据全组件化,通过组件化数据结构实现埋点的下发
Ø✅ 技术侧:从场景、版本、ab、xx四个维度进行scheme路由, 实现引擎数据到组件化结构的全自动解析
Ø✅QA 侧(以下均为):Mock数据,构造全部产品形态,避免卡片下线、卡片类型难以查找等情况,辅助测试埋点
Ø✅ 结合埋点治理平台,抓取埋点日志
Ø✅ 接入正则平台,正则表达式判断部分key value
Ø✅ 设计埋点日志数据对比脚本,提升测试效率
Ø✅ 接入XX监控平台,采样监控搜索埋点
Ø✅ 接入XX报警平台
Ø✅ 接入XX 设计监控SQL
Ø✅ 开发读取数据库的埋点日志的脚本,分场景判断
3. 埋点-客户端服务端交互
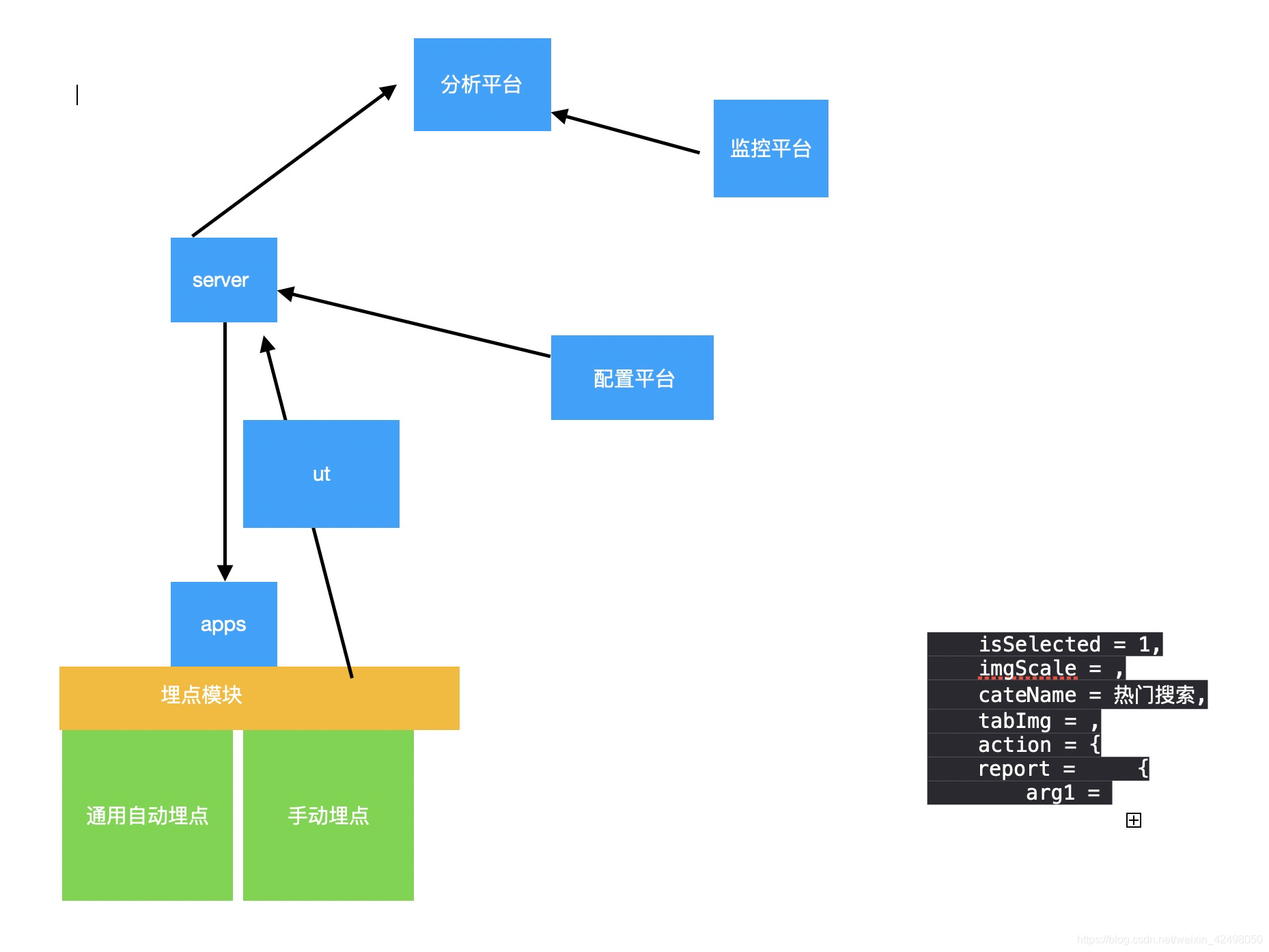
埋点现状
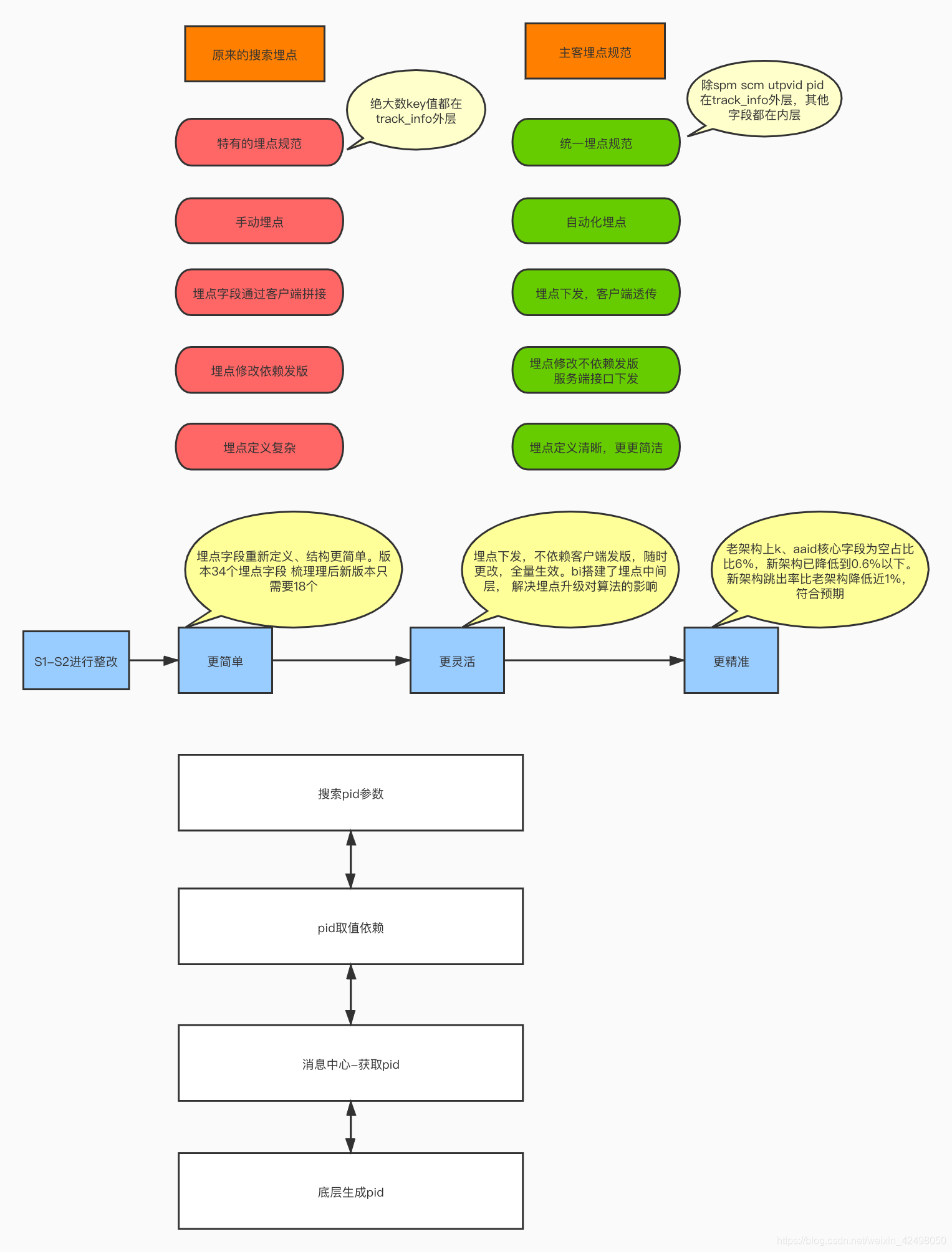
4. 埋点测试历程
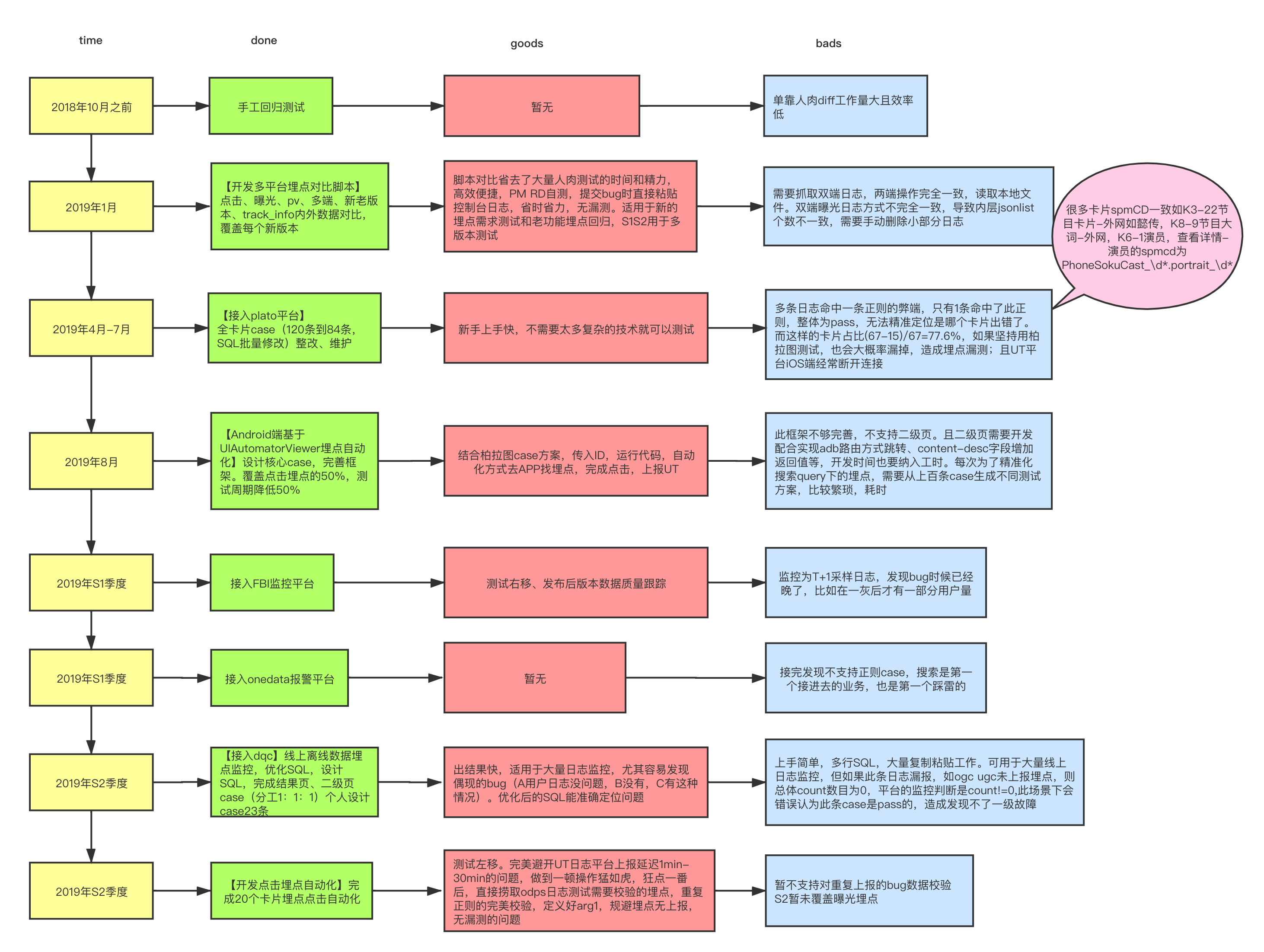
4.1 客户端
Ø❎2018年10月:单靠人肉diff工作量大且效率低
Ø❎2019年S1上季度:接入正则平台,正则case测试埋点,SQL批量创建共67条case + 开发埋点对比脚本(点击 曝光 新老版本 新老架构 track_info内外迁移)
好处-正则平台:新手上手快,不需要太多复杂的技术就可以测试
弊端-正则平台:先从UT平台以为spmCD作为埋点的唯一ID捞取日志,再去正则平台匹配规则,但由于搜索卡片的特殊性,很多卡片spmCD一致如K3-22XX,K8-9XXX,K6-1XX,XX的spmcd为XXCast_\d*.portrait_\d* 也就是说如果UT 应该5个日志命中一条正则但只有4个命中了,整体为pass,无法精准定位是哪个卡片出错了。而这样的卡片占比(67-15)/67=77.6%,如果坚持用正则平台测试,也会大概率漏掉,造成埋点漏测;且UT平台iOS端经常断开连接
好处-脚本:日志一一对比省去了大量人肉测试的时间和精力,高效便捷,PM RD自测,提交bug时直接粘贴控制台日志,省时省力,无漏测。适用于新的埋点需求测试和老功能埋点回归
弊端-脚本:需要抓取双端日志,两端操作完全一致,读取本地文件。双端曝光日志方式不完全一致,导致内层jsonlist个数不一致,需要手动删除小部分日志
Ø❎ 2019年S1下季度:接入XX监控平台
好处:测试右移、发布后版本数据质量跟踪
弊端:监控为T+1采样日志,发现bug时候已经晚了,比如在一灰后才有一部分用户量
Ø❎ 2019 S1下季度:接入XX报警平台
弊端: 接完发现不支持正则case,搜索是第一个接进去的业务,也是第一个踩雷的
Ø❎ 2019 S2季度:线上全量搜索埋点监控:接入XX,优化SQL
弊端-dqc:上手简单,多行SQL,大量复制粘贴工作。可用于大量线上日志监控,但如果此条日志漏报,如ogc ugc未上报埋点,则总体count数目为0,平台的监控判断是count!=0,此场景下会错误认为此条case是pass的,造成发现不了一级故障
好处-dqc:出结果快,适用于大量日志监控,尤其容易发现偶现的bug(A用户日志没问题,B没有,C有这种情况)。优化后的SQL比较能准确定位问题
Ø❎一灰前埋点回归测试:读取线上日志,按版本和utdid维护捞取日志并解析,提取公共的参数校验,报警信息接入钉钉机器人,基于Spring Boot开发接口,报警信息数据入库,与组内同学业务共建,开发前端,最终做成平台
4.2 服务端
Ø❎RD:2019年2月服务端将老接口XX改为XX,埋点字段spm scm trackInfo内的部分字段等由服务端下发,减少客户端冗余的代码,出了问题后端上线,比较灵活,对线上数据影响小
Ø❎QA:冒烟平台case设计,监控接口action.report下埋点字段的下发
4.3 历程总结
埋点回归:双端纯手工(4PD)-> 正则平台(2PD)-> 埋点对比脚本(1PD)-> 埋点回归自动化(0.5PD)
监控:T+1 -> FBI T+1 -> 15min
5. 目标
业务方面:搜索核心指标和每个季度的重点工作,提前发现埋点类问题,保障线上不出问题
技术方面:沉淀出埋点自动化方法,从而达到提效,解放人力
5.1 提效之多端日志对比脚本

Ø测试覆盖以下 3 个测试版本
ü1119版本治理一期:
•新老版本埋点数据分别约 10045 行
•埋点BUG总数 105 个
ü1217版本埋点双端统计
•埋点BUG总数 40 个
ü0107版本:
•手工测试平均1h/2个埋点,双端卡片44个,也就是44h/88个埋点,测试全部点击埋点耗时,44h=5.5pd,还不包括曝光埋点。。。
•脚本测试,设计脚本2pd,测试3pd=24h/88个埋点,提效(44-24)h/44 = 45.5%
•埋点BUG总数 67 个
ü后续每个版本……….
Ø优点
ü方便组内QA验证埋点,提高效率;使用简单,已为PM开通git权限
Ø缺点:没有实现完全自动化
3. QA贡献:
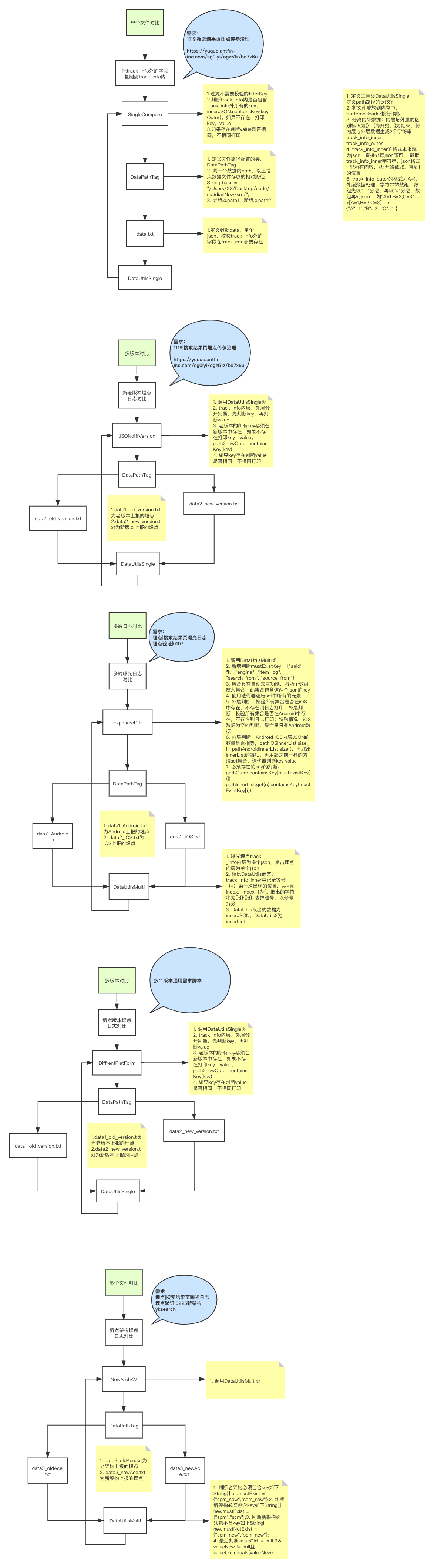
3.1 多端日志对比脚本
设计思想:
1. 整体设计:目前读取本地日志进行多端、多版本、单个json、jsonlist对比
src:entrance、utils、jsonDiff、localPathLog、logPath
2. entrance为读取UT平台接口返回的最新日志
2.1 utils为解析点击(单个json)、曝光埋点(jsonlist)日志格式
2.2 jsonDiff.SingleCompare为track_info内外key value的对比,必须存在的key 不需要校验的value如"aaid", "k", "engine", "item_log"的过滤
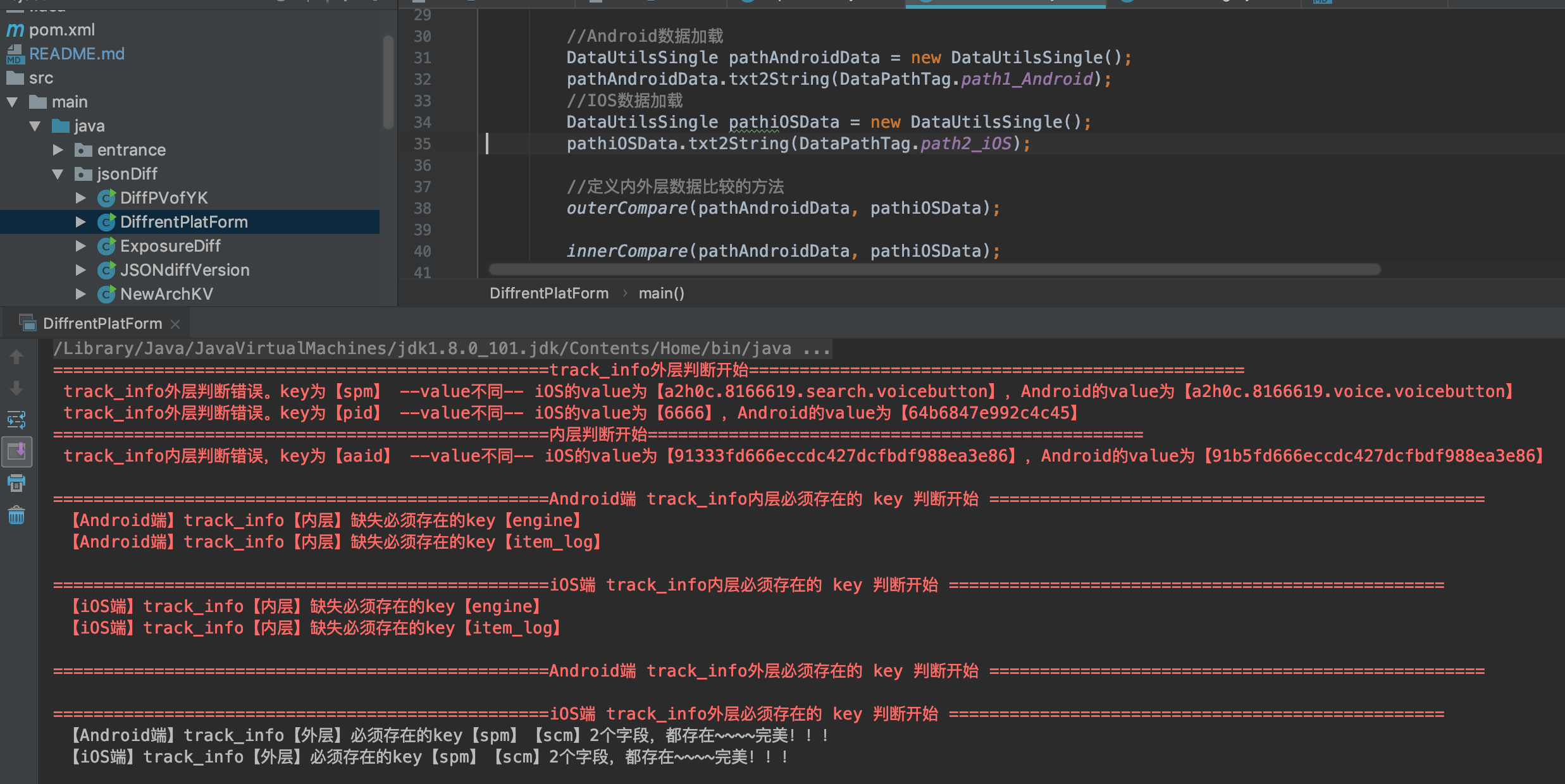
2.3 jsonDiff.DiffrentPlatForm为多端的日志对比,将两个数组放入集合,此集合包含这两个json的key。分内外层判断
内外层判断,校验所有集合是否在iOS Android中存在,不存在则日志打印
定义日志数据data.txt等文件(单个json,校验track_info外的字段在track_info都要存在)、data1_old(老版本上报的埋点)、
data2_new(新版本上报的埋点)
2. 定义第一个类DataPathTag,老版本path1、新版本path2、同一个数据内path,以上埋点数据文件存放的相对路径
3. 定义第二个类DataUtilsSingle是单个json(点击日志)工具类:将文件流放到内存中,BufferedReader按行读取,
3.1 分离内外数据 3.1.1 内层与外层的区别标识为{},{为开始,}为结束,将内层与外层数据生成2个字符串track_info_outer、
track_info_inner, 找到track_info_inner第一个"="的下标,截取字符串,可强转为json
3.1.2 外层判断是否包含}
3.2 内层、外层数据转换 3.2.1 track_info_inner的格式本来就为json,所以直接处理json即可, 截取track_info_inner字符串,
json格式{}里所有内容,从{开始截取,直到}的位置,最后一位为"," { "searchtab":"0", "pageName":"page_searchresults", "group_num":38, }
3.2.2 track_info_outer的格式为A=1 外层数据处理,字符串转数组,数组先以","分隔,再以"="分隔,数组再转json,
如"A=1,B=2,C=3"-->[A=1,B=2,C=3]-->{"A":"1","B":"2","C":"1"}, object_id=dbb0ecb3786549098484, object_title=一出好戏, srid=1,
4. 定义第三个类DataUtilsMulti是多个json,即jsonlist(曝光埋点)工具类:把日志按track_info内外转化为json进行解析
5. 第四个类JSONdiffVersion是新老数据的比较。调用DataUtilsSingle类,内层、外层分开判断,先判断key,再判断value
老版本的所有key必须在新版本中存在,如果不存在打印key,value。如果存在判断value是否相同,不相同打印
5. 第五个类SingleCompare是单个版本上报的数据校验,判断track_info内是否包含track_info外所有的key
如果不存在,打印key,value。如果存在判断value是否相同,不相同打印
6. 第六个类NewArchKV是新老架构埋点数据的对比
track_info内层判断:
校验老版本track_info内层层必须不存在{"newArch"};
校验新版本track_info内层层必须存在{"newArch"};
外层判断:
校验老版本track_info外层必须存在{"spm_new","scm_new"};
新版本track_info外层必须存在{"spm","scm"};
新版本track_info外层必须不存在{"spm_new","scm_new"};
且新版本spm scm的value与老版本的spm_new scm_new的value必须一致
7. 第七个类DiffrentPlatForm是判断不同平台 如 iOS Android iPad等多端或者多版本单个json的点击埋点日志,RD请参考自测
8. 第八个类ExposureDiff是判断不同平台 如 iOS Android iPad等多端或者多版本多个json(jsonlist)的曝光埋点日志,RD请参考自测
9. 增加BI要求必须存在的key的校验,共10个字段
待优化的地方:目前只支持从UT平台抓取日志手动拷贝到txt文件作对比。后续改为双端一致的操作,读取UT接口最新的日志多对比
1.value中存在两个==,取第一个
2.value中存在:的情况,如曝光埋点_KG卡片(即UGC大词)"tagvalue":"2:0;1:0",json解析的时候出错
3.Android最后的日志为track_info的json格式,需要在日志后面手动加英文逗号,再执行脚本
//内外层数据分离,用【{】表示track_info内层数据开始,用【},】表示track_info内层数据结束。有的埋点数据内层有"utparam":"{
"yk_abtest\":\"592:1381\"
}",这种数据,不能以}作为内层结束判断的标识
track_info={
"k":"名侦探柯南",
"object_num":3,
"aaid":"074d90da3c8602ec629104ee7a57e796",
"utparam":"{
\"yk_abtest\":\"592:1381\"
}",
"newArch":"1",
"object_title":"30-60分钟",
"source_from":"home"
},
spm=a2h0c.8166622.PhoneSokuFilter.sfilter_3,
scm=20140669.search.filter.filter_30-60分钟,
pid=64b6847e992c4c45
流程图
脚本运行结果
提交bug到bug系统(为了数据脱敏,暂不附截图~~~总之很方便)
5.2 提效之线上埋点监控
示例Demo
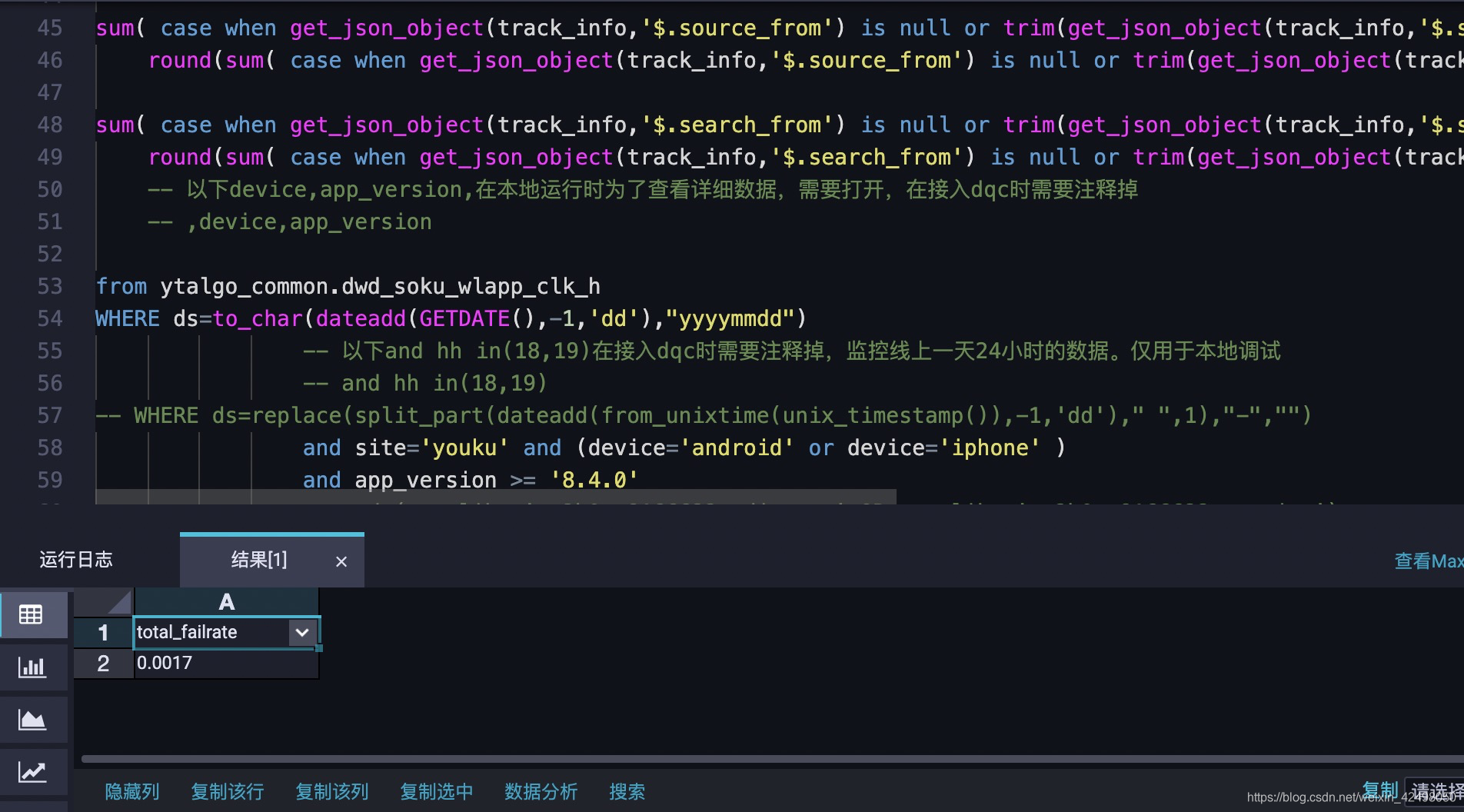
搜索结果页-二方卡spm遍历值条件下,10个核心埋点字段为空的占比统计,总和为0 ---pass
各项字段占比分别为0 ---pass
--odps sql
--********************************************************************--
--author:本人
--create time:2019-12-25 16:13:23
--********************************************************************--
--以下SQL的as也可以去掉
-- //通用需求正则平台必须存在的key的校验
-- public static String[] mustExistKeyOuter = {"spm", "scm"};
-- public static String[] mustExistKeyInner = {"soku_test_ab", "engine", "item_log", "aaid", "k", "source_from", "search_from"};
-- set odps.sql.type.system.odps2=true;
-- select date_format(CURRENT_TIMESTAMP(),"%Y%M%D") from dual;
select
-- 以下device,app_version,total_failrate在本地运行时为了查看详细数据,需要打开,在接入dqc时需要注释掉
-- device,app_version,
-- round(spm_rate +scm_rate +track_info_rate+ soku_test_ab_rate+ engine_rate+ item_log_rate+ aaid_rate+ k_rate+ source_from_rate+ search_from_rate ,4)
-- as total_failrate FROM (select
sum( case when spm is null or trim(spm)='' then 1 else 0 end) as spm_null, sum(1) as log_total,
round(sum(casewhen spm isnullortrim(spm)=''then1else0end)/sum(1),4)as spm_rate,
sum( case when scm is null or trim(scm)=' ' then 1 else 0 end) as scm_null,
round(sum (case when scm is null or trim(scm)=' ' then1 else 0 end) /sum(1),4) as scm_rate,
sum( case when track_info is null or trim(track_info)=' ' then 1 else 0 end) as track_info_null,
round(sum(case when track_info is null or trim(track_info)=' ' then 1 else 0 end)/sum(1),4)as track_info_rate,
sum(case when get_json_object(track_info,'$.soku_test_ab') is null or trim(get_json_object(track_info,'$.soku_test_ab'))=' ' then 1 else 0 end) as soku_test_ab_null,
round(sum(case when get_json_object(track_info,'$.soku_test_ab') is null or trim(get_json_object(track_info,'$.soku_test_ab'))=' ' then 1 else0 end)/sum(1),4) as soku_test_ab_rate,
sum( case when get_json_object(track_info,'$.engine') is null or trim(get_json_object(track_info,'$.engine'))=' ' then 1 else 0 end) as engine_null,
round(sum(case when get_json_object(track_info,'$.engine') is null or trim(get_json_object(track_info,'$.engine'))=' ' then 1 else0 end)/sum(1),4) as engine_rate,
sum( case when get_json_object(track_info,'$.item_log') is null or trim(get_json_object(track_info,'$.item_log'))='' then 1 else 0 end) as item_log_null,
round(sum(case when get_json_object(track_info,'$.item_log') is null or trim(get_json_object(track_info,'$.item_log'))=''then1else 0 end)/sum(1),4) item_log_rate,
sum( case when get_json_object(track_info,'$.aaid') is null or trim(get_json_object(track_info,'$.aaid'))=' ' then 1 else 0 end) as aaid_null,
round(sum(case when get_json_object(track_info,'$.aaid') is null or trim(get_json_object(track_info,'$.aaid'))=' ' then 1 else 0 end)/sum(1),4) as aaid_rate,
sum( case when get_json_object(track_info,'$.k') is null or trim(get_json_object(track_info,'$.k'))=' ' then 1 else 0 end) as k_null,
round(sum(case when get_json_object(track_info,'$.k') is null or trim(get_json_object(track_info,'$.k'))=' ' then 1 else 0 end) / sum(1),4) as k_rate,
sum( case when get_json_object(track_info,'$.source_from') is null or trim(get_json_object(track_info,'$.source_from'))=' ' then 1 else 0 end) as source_from_null,
round(sum(case when get_json_object(track_info,'$.source_from') is null or trim(get_json_object(track_info,'$.source_from'))= ' ' then1 else 0 end) / sum(1),4) as source_from_rate,
sum( case when get_json_object(track_info,'$.search_from') is null or trim(get_json_object(track_info,'$.search_from'))='' then 1 else 0 end) as search_from_null,
round(sum(case when get_json_object(track_info,'$.search_from') is null or trim(get_json_object(track_info,'$.search_from'))=' ' then 1 else 0 end) / sum(1),4) as search_from_rate
-- 以下device,app_version,在本地运行时为了查看详细数据,需要打开,在接入dqc时需要注释掉
,device,app_version
from database.table_name
WHERE ds=to_char(dateadd(GETDATE(),-1,'dd'),"yyyymmdd")
-- 以下and hh in(18,19)在接入dqc时需要注释掉,监控线上一天24小时的数据。仅用于本地调试
and hh in(18,19)
-- WHERE ds=replace(split_part(dateadd(from_unixtime(unix_timestamp()),-1,'dd')," ",1),"-","")
and site='xx' and (device='android'or device='iphone')
and app_version >='8.3.0'
-- and (spm like '%a2h0c.8166622.rdirect%' OR spm like '%a2h0c.8166622.rmovie%')
-- and (original_spm like '%a2h0c.8166622.xx%' OR original_spm like '%a2h0c.8166622.xx%' OR original_spm like '%a2h0c.8166622.PhoneSokuPromote%')
and(original_spm like'%a2h0c.8166622.xx%'OR original_spm like'%a2h0c.8166622.xx%'OR original_spm like'%a2h0c.8166622.xx%')
-- and (original_scm like '%20140669.xx.xx%' OR original_scm like '%20140669.xx.xx%' OR original_scm like '%xx.xx.xx%')
-- and spm like '%a2h0c.8166622.rdirect%' and (xx REGEXP (.*a2h0c\.8166622\.(xx|xx).*)
-- 以下GROUP BY device,app_version在本地运行时为了查看详细数据,需要打开,在接入dqc时需要注释掉
GROUPBY device,app_version
-- )
;
优化前的SQL:
设计上:
mysql也支持聚合的时候加一些条件,不过一般都是数据分析师才会这么搞,或者BI统计的时候用。日常这么写SQL,要被DBA干死的。因为这样很消耗Mysql的cpu,计算也一般都很慢,在线业务跑这种SQL,那接口几秒钟能返回也是够快了,随便几个并发起来了,库都要被拖挂了。
业务上:SQL查询的是A or B or C or D为空的总和计算/total_log,接入监控报警,一旦报警,无法准确定位是哪个字段出错了,可能是A可能是B可能是C,因为计算的是总和出错率。到时候还需要把SQL粘贴到odps,逐一修改判断哪个字段为空
优化后的SQL:
分别计算A为空B为空C为空D为空的出错率,因为最终的监控只能监控一个字段,所以需要sum()输出一个值接入监控系统
校验1个场景下的10个字段,统计,占比,如果哪个字段漏掉了,排查的时候,只需要把监控SQL粘贴到odps去掉sum(*),清晰地看到ABCD各自的失败率占比。哪个字段为空,准确定位
不需要分多个规则配置,不需要分端,减少冗余无效的复制粘贴以及一堆规则的填写,精简化,报错明显
5.3 提效之服务端冒烟case
接口监控
5.4 提效之埋点回归自动化
## 脚本设计思路
脚本部分:
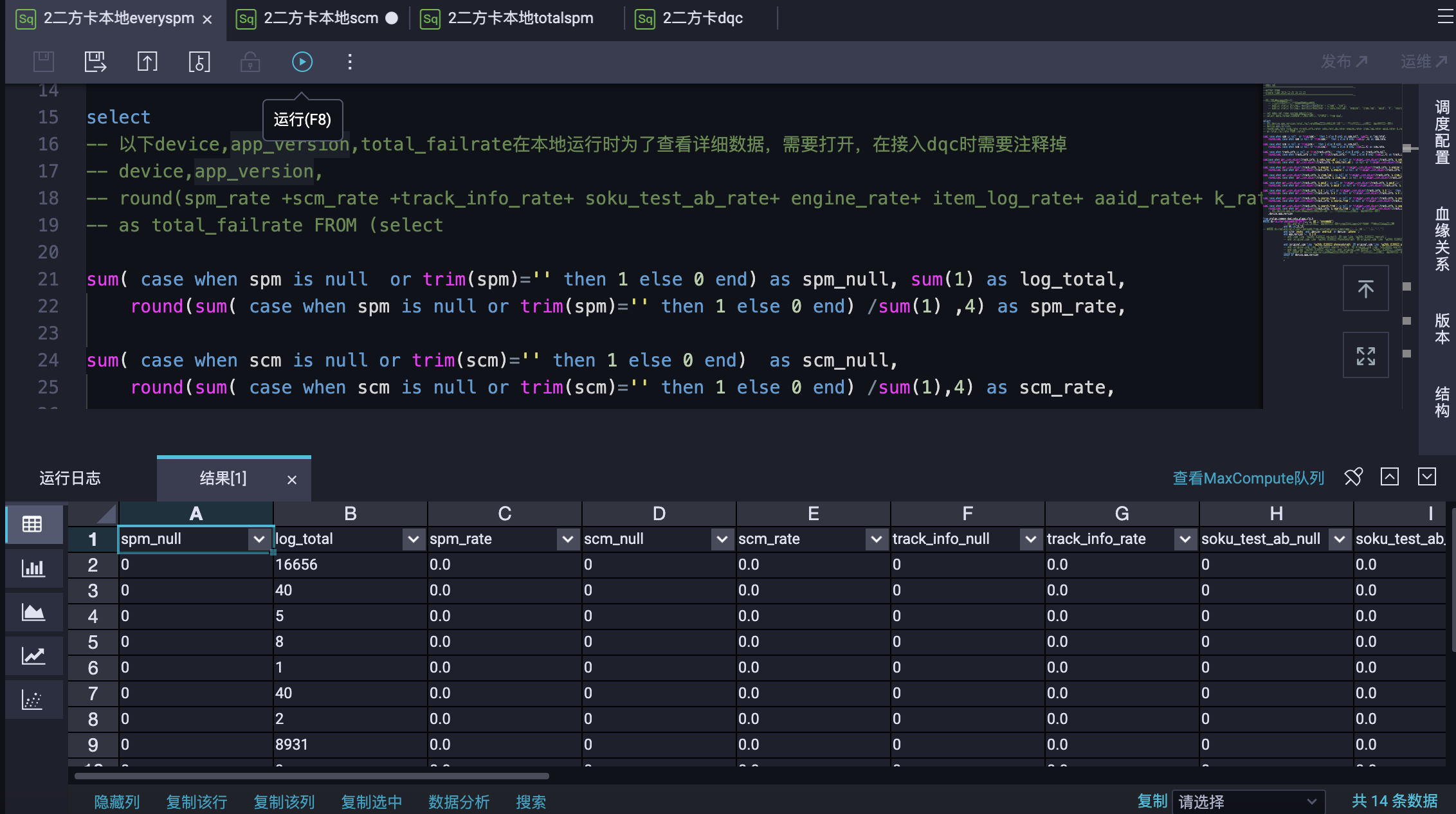
1.根据搜索的独特业务设计SQL(版本维度、utdid维度、ds维度等)读取线上离线表--点击埋点 曝光埋点15分日志钟延迟表,xx_clk_ri(点击)和xx_exp_ri(曝光)
获取每条SQL的查询字段内是否存在content字段(里面为所有日志,origialParam为客户端全部传参)
业务逻辑SQL设计如下:
--可用于预发包(后端连接线上)、灰度环境、线上环境回归测试,线上与预发的utdid不同,别写错了。日志15分钟延迟
SELECT app_version, os,utdid,xx,page,xx,xx,xx,xx,ds,hh,mm FROM ytods.s_yt_log_wl_app_clk_ri
where event_id = '2101' and spm like "%a2h0c%"
-- and page in ("page_searchresults")
and os in ("iPhone OS") and app_version='8.4.0' and
(user_nick ="xx" or utdid="xx")
and site="xx" and ds="20200220" and hh in(16,17) LIMIT 500;
2.使用中间件开发环境-潘多拉
生成工程,配置maven,需要的依赖:com.aliyun.odps、fastjson、httpcore
3.按行读取SQL查询内容,单独处理解析args日志(搜索原始日志,track_info外层和内层),pageAndArg1类为按照页面维度和arg1页面控件维度进行日志判断,
具体日志解析为:找到{开始的位置,截取inner字符串,json格式{}里所有内容,从{开始截取,直到}的位置,以","拆分,获取key value
try {
int firstIndex = args.indexOf("{");
// innerJson可能存在"object_title":"搜索","utparam":"{\"yk_abtest\":\"592:1381\"}"
int lastIndexOf = args.lastIndexOf("}");
//截取inner字符串,json格式{}里所有内容,从{开始截取,直到}的位置
String innerStr = args.substring(firstIndex, lastIndexOf + 1);
String outerStr = args.substring(lastIndexOf + 2);
String[] outer = outerStr.toString().split(",");
innerJSON = JSON.parseObject(innerStr);
outerJSON = new JSONObject();
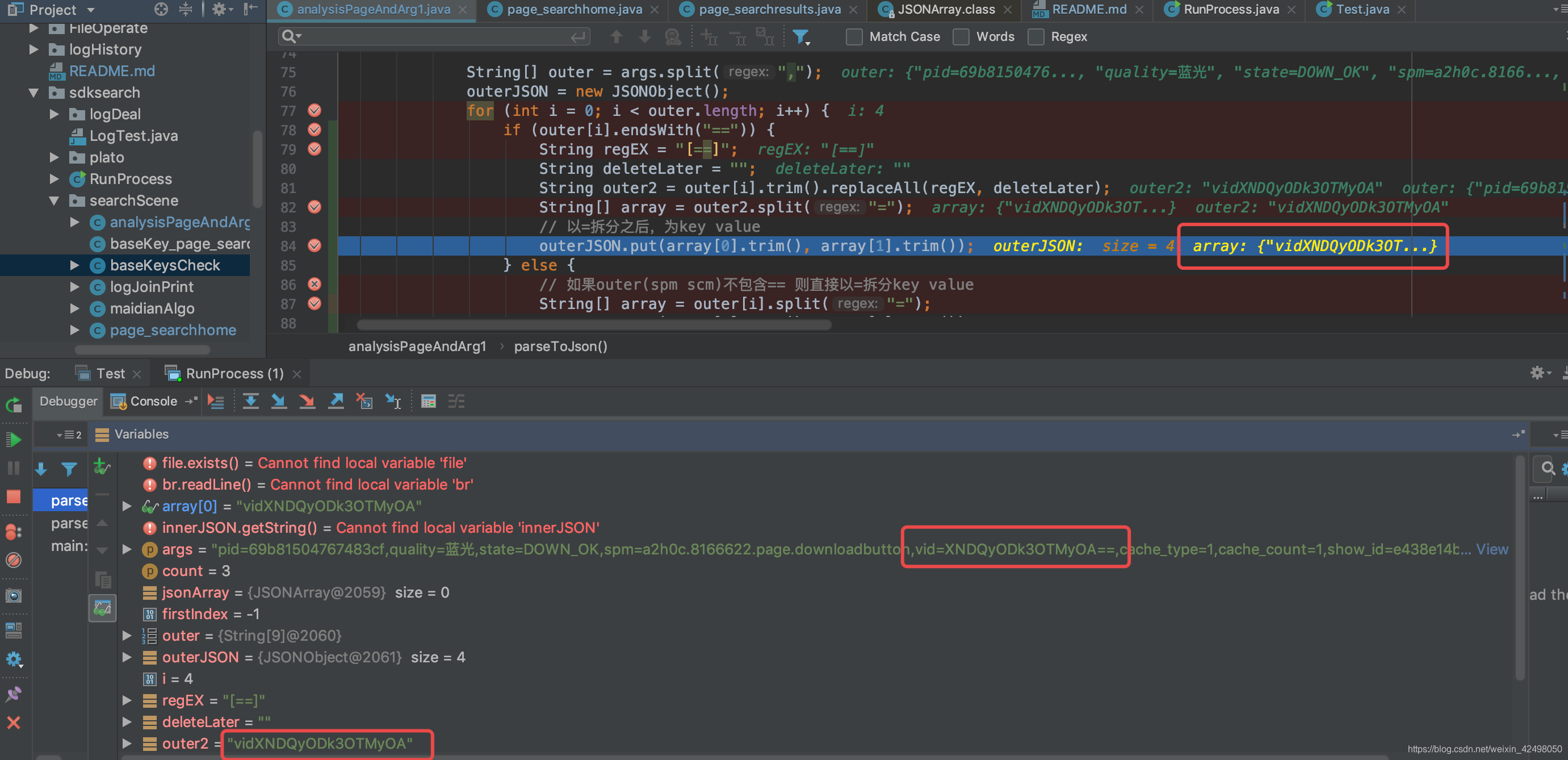
for (int i = 0; i < outer.length; i++) {
String[] array = outer[i].split("=");
// 以=拆分之后,为key value
outerJSON.put(array[0].trim(), array[1].trim());
}
4.根据不同的搜索页面设计不同的类,将公共参数设计为单独的公类供。方便代码维护,一目了然
baseKeysCheck.existKeys(array1, record, count);
5.搜索结果页page_searchresults埋点校验,按照page && k的逻辑定位arg1,根据前3个条件判断spm scm具体的控件位置。如搜索的query变了,请更新此代码里的k
每个卡片在需要校验的算法字段前添加注释,注释分为2部分,前面part1==埋点文档卡片类型+点击区域,如搜索结果页1-26卡片一一对应,面part2=QA的case说明
part1+part2给人的感觉直观,清楚的知道哪部分埋点的测试,测试点,以免漏测
遇到的问题以及分析:
1. 类似xx xx
的scm的B位带空格,UT日志是正确的,入库的时候错了,脚本用trim()方法去空白处理
2. 如果保证不同的卡片命中相同的正则表达式时,只有1条pass就pass,导致漏测了其他卡片的问题?
代码中用page.equals("page_searchresults") && k.equals("鹤唳华亭")筛选对应卡片的全部日志,
这也是与柏拉图的不用之处,正则平台用spmCD作为唯一ID捞取日志。我的增加了上述条件,极为重要的page && k
再根据arg1.equals("xx")定位卡片的详细区域
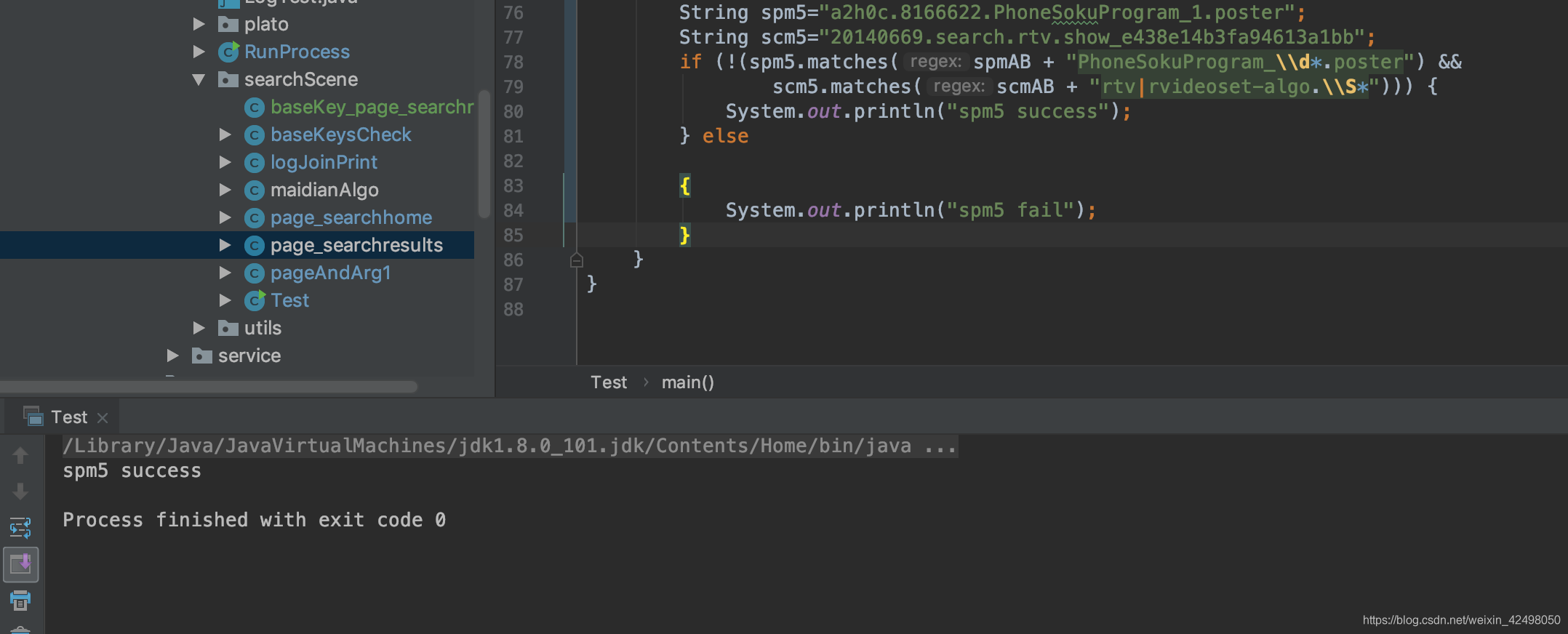
再根据if (!(spm.matches(spmAB + "PhoneSokuProgram_\\d*.poster") && scm.matches(scmAB + "(rtv|rvideoset-algo).\\S*"))) 判断具体的点击位置
最后对每条卡片进行baseKeysCheck.existKeys(array1, record, count);的校验
baseKeysCheck为公共方法判断,具体为BI要求的字段校验
/**
* 通用需求必须存在的算法字段key以及value的判断
* public static String[] mustExistKeyOuter = {"spm", "scm"};
* public static String[] mustExistKeyInner = {"soku_test_ab", "engine", "item_log", "aaid", "k", "source_from", "search_from"};
*/
3. 何保证每条日志都校验,没有漏校验的日志,无logMiss?
if(){
if () {
if () {
} else {
}
baseKeysCheck.existKeys(array1, record, count);
} else if () {
} else
{
System.err.println(arg1Miss() + logPrint(array1, record, count) + "缺失的arg1为:" + arg1);
}
}
设计类logPrint,提供全局公共方法(count app_version event_id page arg1 os utdid user_nick args ds hh),大量减少sout 和 serr天长的日志文案打印
bugDesc() "埋点异常,BUG BUG BUG!!!";
passDesc() "埋点正确,PASS PASS PASS!!!"
arg1Miss() "arg1缺失,未上报,arg1Miss Miss Miss!!!";
4. 日志第4行解析有问题,解析报错?
经排查为此日志没有track_info,这种的日志(page_searchresults_detailsdetaildownloadbutton)占比极少数,则需要对解析方法单独处理
debug排查问题,在代码中打断点,debug模式运行主函数,在Debugger下,添加或者删除多余的代码
// 如果没有track_info的话,也就是只有外层的spm scm
if (firstIndex == -1) {
String[] outer = args.split(",");
outerJSON = new JSONObject();
for (int i = 0; i < outer.length; i++) {
String[] array = outer[i].split("=");
// 以=拆分之后,为key value
outerJSON.put(array[0].trim(), array[1].trim());
}
innerJSON = new JSONObject();
jsonArray.add(innerJSON);
jsonArray.add(outerJSON);
return jsonArray;
}
5. 如何保证日志中无漏测的埋点,该上报的日志都上报了?
5.1 在RunProcess中,
5.1.1 在开头
// 初始化page_searchresults的arg1
page_searchresults.initList();
5.1.2 在结尾
// 判断最终的集合元素,正常为空,代表每条日志都各自命中了应该有的page&arg1,正确,无BUG!!!
page_searchresults.result();
5.2 在page_searchresults中
5.2.1 在开头
// 定义集合,把搜索page下对应的arg1放到list
public static List<String> list = new ArrayList<>();
需要在odps里捞取用户去重后的arg1,如SELECT distinct(arg1) FROM database.table_name WHERE...
再添加到代码list 以此保证应该上报的日志都上报了(初次定义的时候需要人工在UT平台逐条查看,保证都上报了)
public static void initList() {
// page_searchresults下所有的arg1,如有新增的在此处添加
list.add("xx");
list.add("xx");
list.add("xx");
...
}
// 定义方法,供list集合调用,作为最终的判断埋点日志是否漏测的判断
public static void result() {
System.err.println("搜索结果页埋点故障!!!【page_searchresults_微微一笑很倾城】请检查是否漏测!!!日志中不包含的日志如下==" + list.toString());
}
5.2.2 在结尾
// 遍历每一条日志,把命中的arg1分别从集合移除,如果最终集合的元素为空,则正确,如果有arg1的值,则没有此日志,对应的arg1未上报,BUG!!!
list.remove(arg1);
6. 正则在线多个字符匹配可以添加(A|B|C),需要注意的是,遇到.要用\\转义
String spmAB = "a2h0c\\.8166622\\.";
String scmAB = "20140669\\.search\\.";
如果单一字符则用Regex.quote(spmAB)
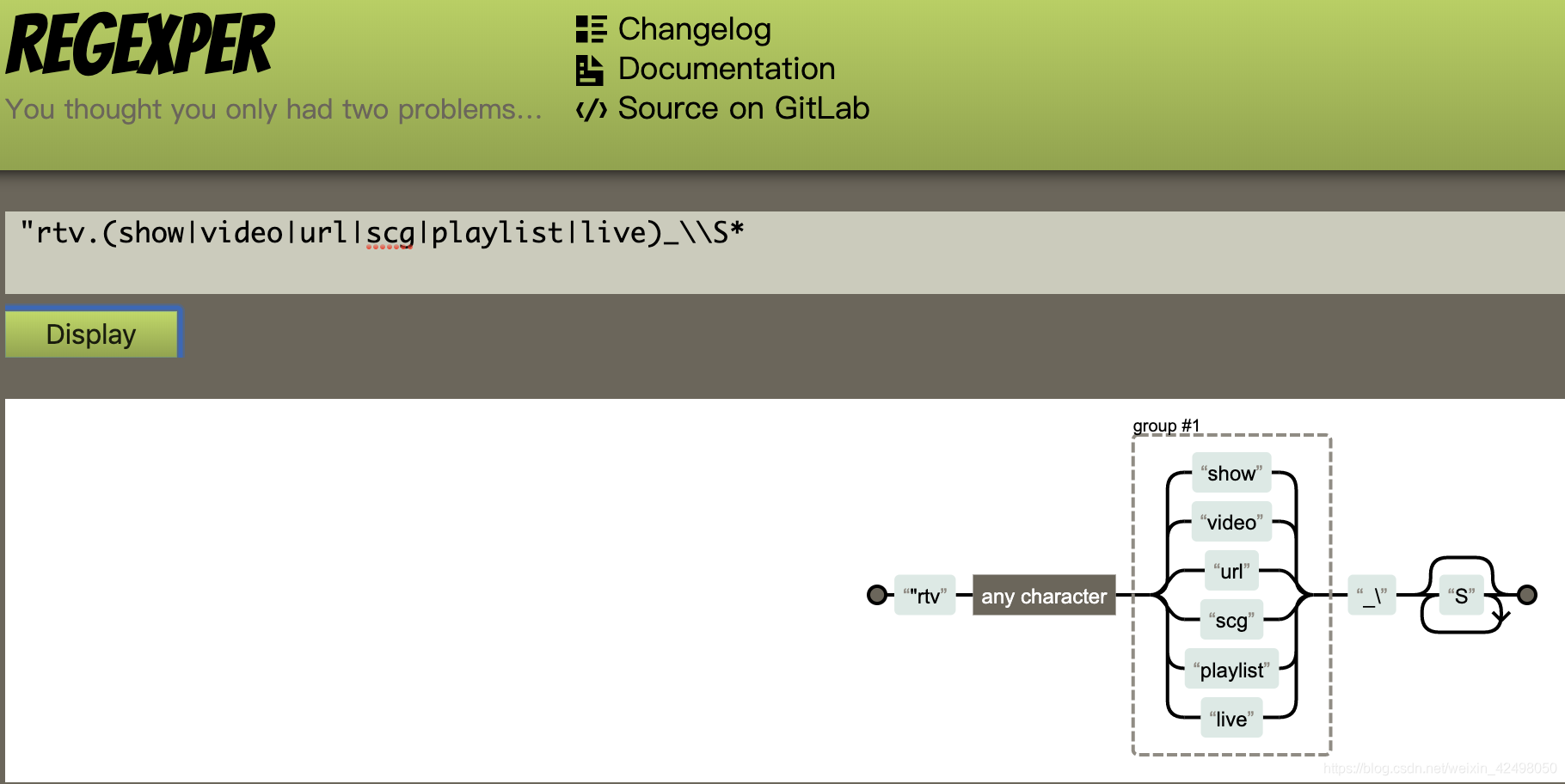
正则表达式的图形网站 https://regexper.com/
7. track_info外层日志按","拆分,但是部分的scmD位含有==
所以需要修改日志解析代码
spm=a2h0c.8166622.xx.selectbutton_2,statisticsTag=7e3f7045e40671fe,scm=20140669.search.xx-algo.xx,utpvid=6,
8. 提取整个page_searchresults xx 的公共埋点区域为单独的方法baseKey_page_searchresults
// 10.分类筛选==点击顶部第一行的"精选|剧集|娱乐|搞笑|文化|自频道|播单"
// 筛选==点击顶部筛选-综合/全部(时长)/全部(清晰度)
// 16.吐槽==翻页,点击底部去吐槽
9. All_cards不同卡片类型入口分支判断 All_arg1List为不同区域的list集合// 通过k区分调用对应卡片的埋点日志类
10. 默认页埋点 A=a,B=b,C=c,track_info={"a":"aa","b":"bb","c":""cc"},D=d,E=e
结果页埋点 track_info={"a":"aa","b":"bb","c":""cc"},A=a,B=b,C=c,D=d,E=e
// 截取outer字符串,A=a,B=b,C=c格式日志,默认页点击埋点在track_info前面、后面均存在outer格式日志,结果页点击埋点仅在track_info后面存在outer格式日志
// 因此,分2部分解析日志,前面part==outerStr1(track_info=为11个字符) 后面part==outerStr2,2部分拼接==outerStr
analysisPageAndArg1
默认页点击埋点
track_info={
"source_from":"home",
"recext":"reqid=xx",
"search_q":"小爸爸2",
"req_id":"reqid=xx",
"soku_test_ab":"a",
"engine":"xx",
"newArch":"1",
"object_num":2,
"object_title":"小爸爸2",
"aaid":"xx",
"show_q":"小爸爸2",
"k":"小爸爸2",
"word_location":1,
"cn":"精选"
},
spm=a2h0c.8166619.xx.title_2,
statisticsTag=1bf9a9e001608b7d,
scm=20140669.search.personalword.keyword_小爸爸2,
utpvid=59,
pid=69b81504767483cf
11. 由于日志太多 UT上报慢,为了更好的排查问题,可以捞取埋点日志缺失或者有err的ARG1对应的ARGS里的
"object_url":"xx&vid=xx==&searchKey=xx",
/maidianRun/mytest
下的IdUtil用base64解密出来vid(ids),再请求video-获取视频id的接口,http://xx?ids=xx
或者直接用summary的接口查解密前的vid,接口为https://xx.com/q/video?id=xx==
后者更简单,由接口看出,待排查的日志为 title: "乡村爱情12 摊上这样的爷爷" 点击此视频所上报产生的日志
=================================================================================================
=================================================================================================
结果页点击埋点
track_info={
"alginfo":"xx",
"group_id":7902690,
"object_type":103,
"group_num":69,
"search_q":"德云社",
"object_title":"播放",
"group_type":2,
"source_from":"home",
"show_q":"德云社",
"aaid":"xx",
"searchtab":"0",
"soku_test_ab":"a",
"k":"如懿传",
"item_log":"xx",
"req_id":"reqid=xx",
"search_from":"1",
"cn":"精选",
"engine":"xx",
"word_location":1,
"object_url":"xx",
"newArch":"1",
"recext":"xx"
},
spm=a2h0c.8166622.xx.playbutton,
statisticsTag=3c1bb32294b381f0,
scm=20140669.search.xx-algo.scg_7902690,
utpvid=28,
pid=69b81504767483cf
该设计的好处:
完美避开UT日志平台上报延迟1min-30min的问题,做到一顿操作猛如虎,狂点一番后,直接捞取odps日志测试需要校验的埋点,重复正则的完美校验,无漏测~
--可用于预发包(后端连接线上)、灰度环境、线上环境回归测试,需要注意的是,线上与预发的utdid不同,别写错了。日志15分钟延迟
SELECT app_version, os,utdid,xx,page,event_id,xx,xx,xx,ds,hh,mm FROM database.table_name
where event_id = '2101' and spm like "%xx%"
-- and page in ("page_searchresults")
and os in ("iPhone OS") and app_version='8.4.0' and
(user_nick ="XX" or utdid="XX")
and site="xx" and ds="20200107" and hh in(16,17) LIMIT 500;
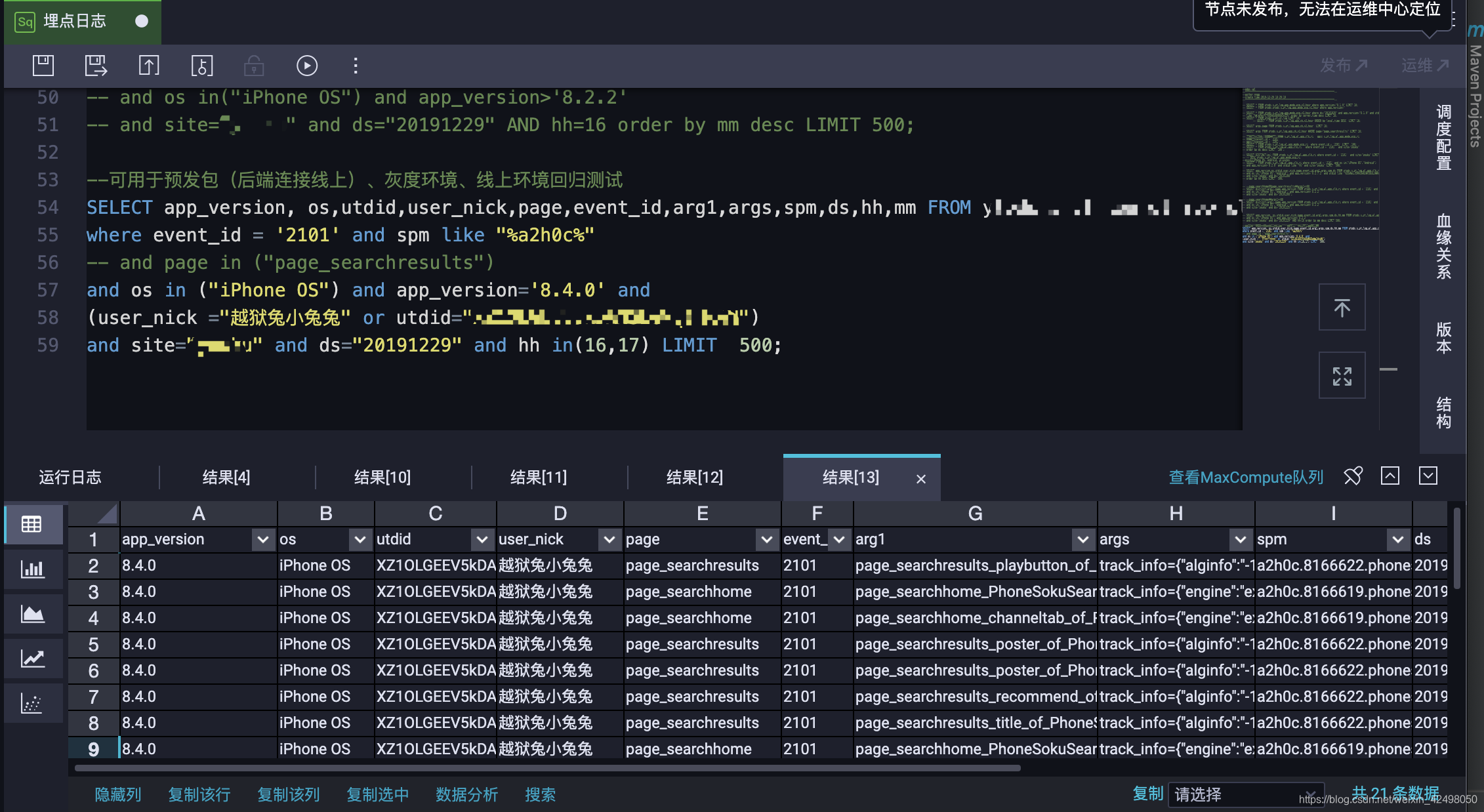
客户端埋点日志如下,需要对BI要求的算法字段解析判断
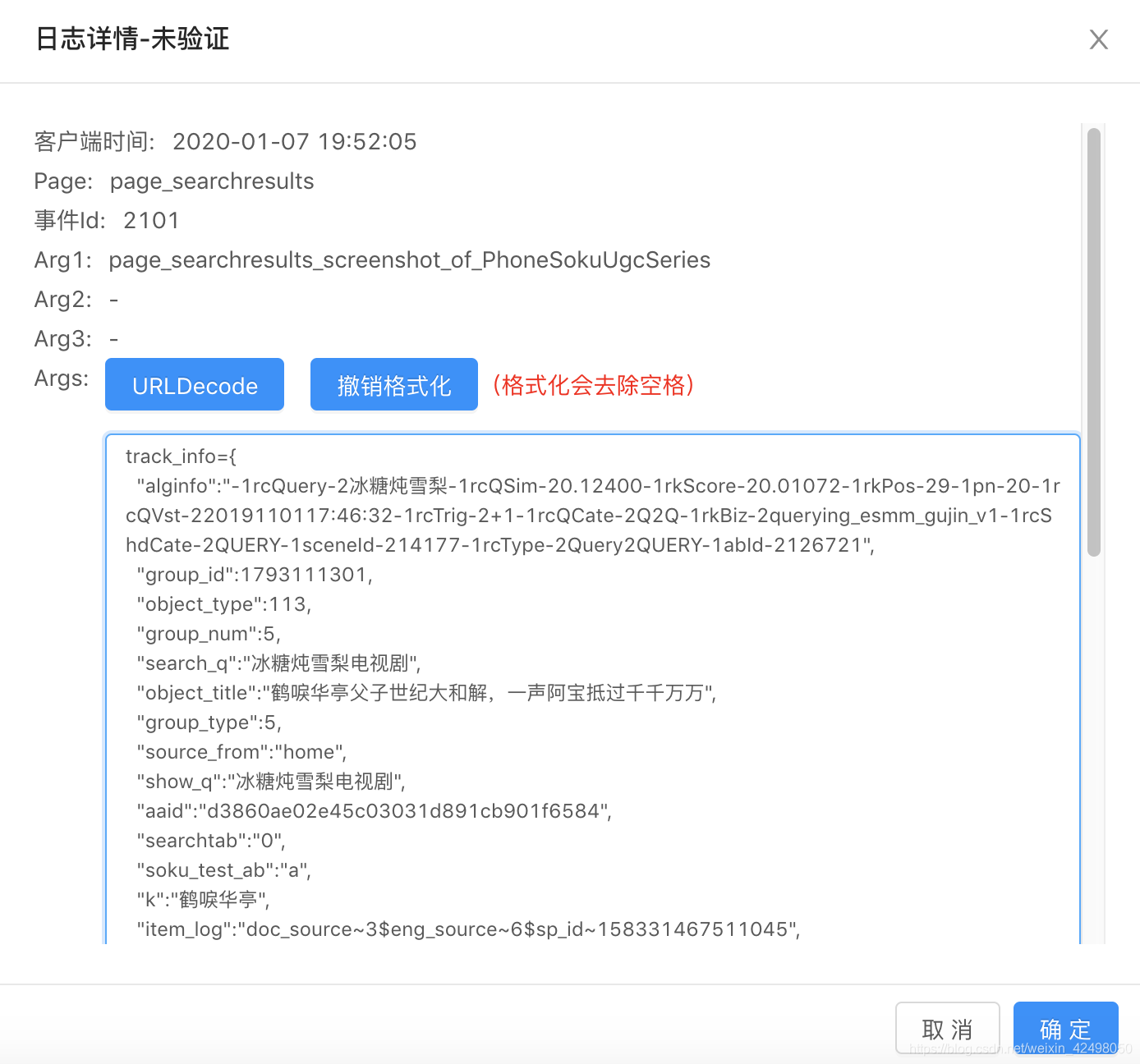
运行结果, 场景:page_searchresults
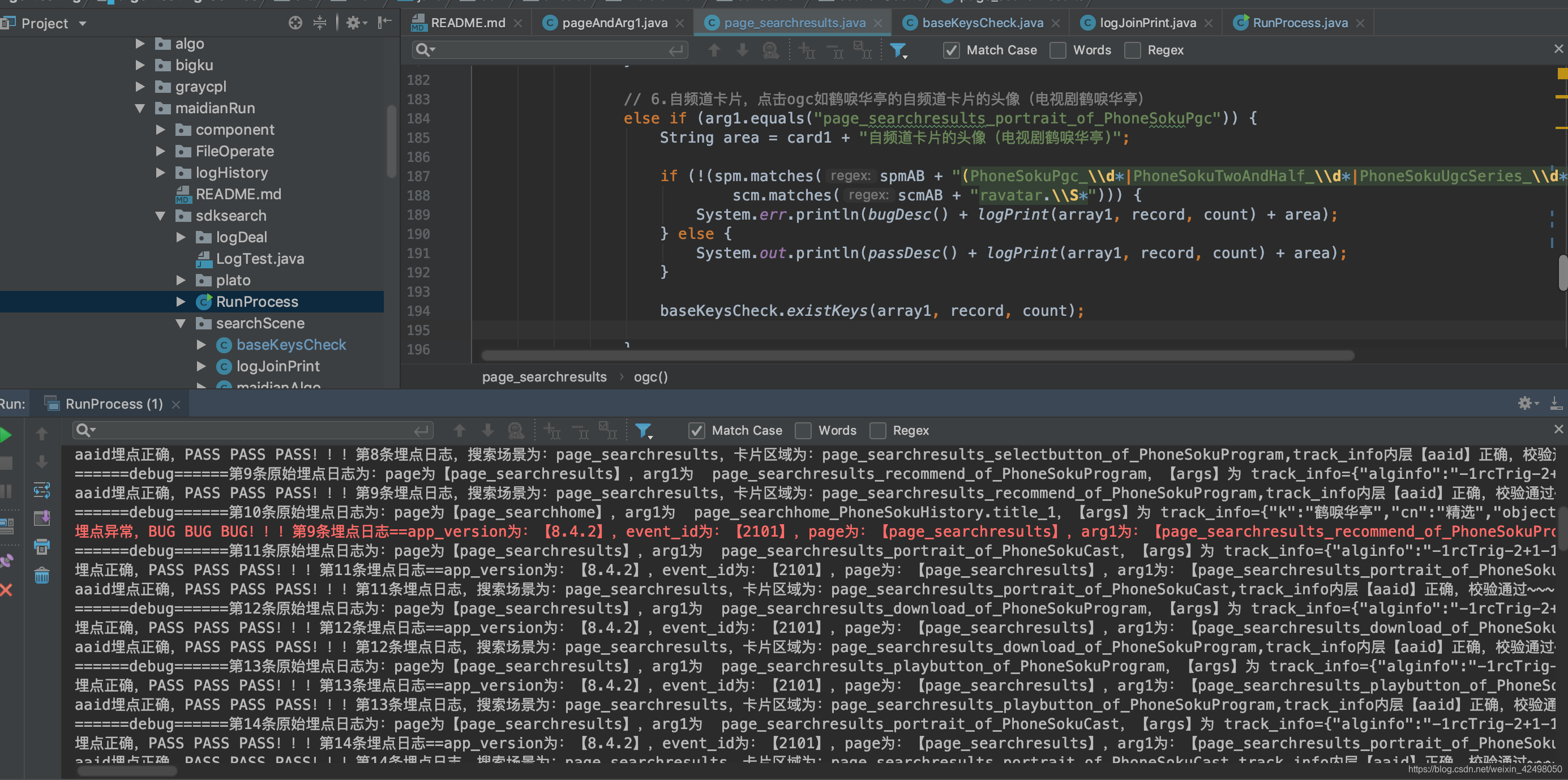
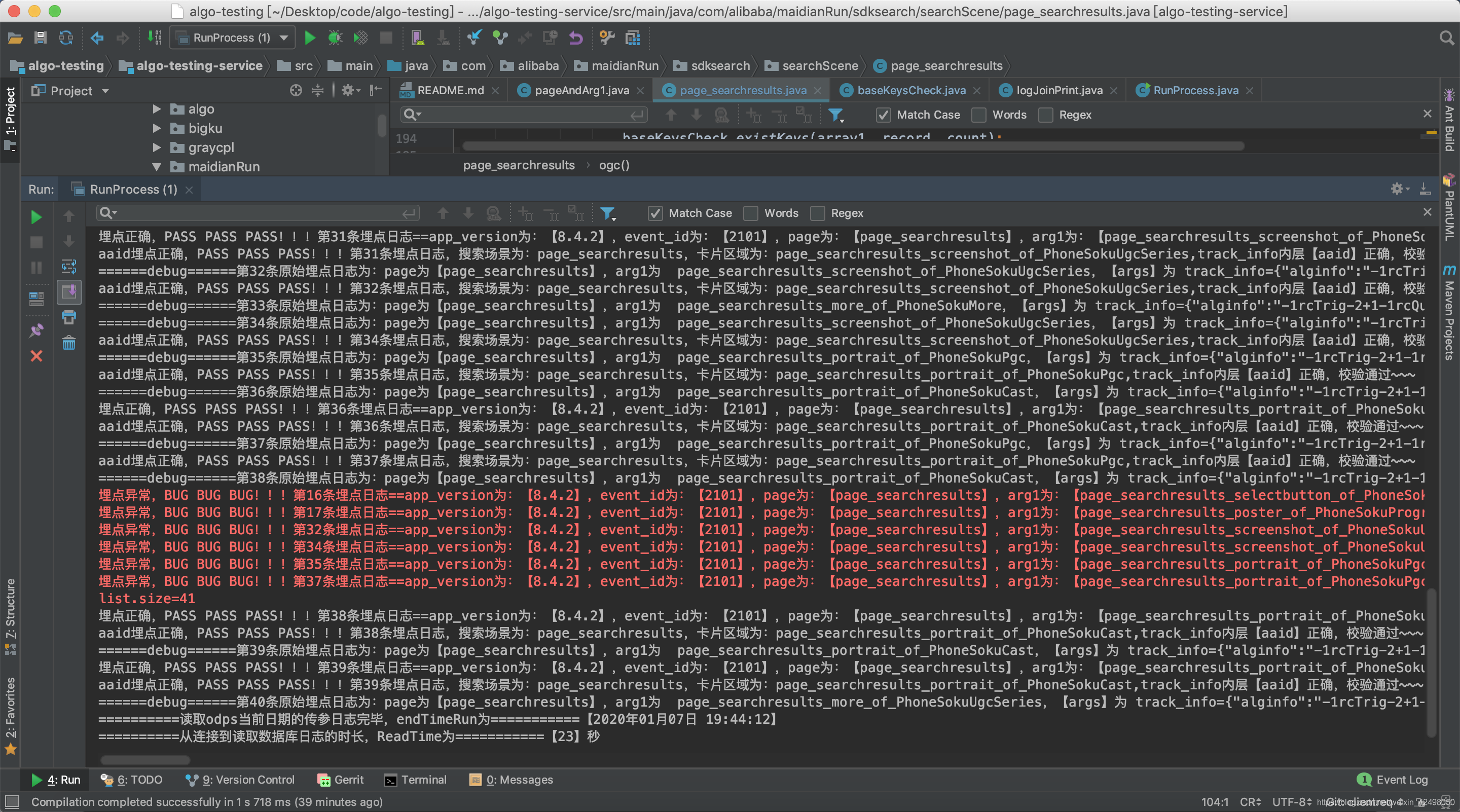
提交bug到bug系统
1. 【iOS】搜索结果页,page_searchresults_recommend_of_PhoneSokuProgram场景下scm的B位多了空格,日志如下,测试代码如下
埋点异常,BUG BUG BUG!!!第2条埋点日志==app_version为:【8.4.2】,event_id为:【2101】,page为:【page_searchresults】,arg1为:【xx】,os为:【iPhone OS】,utdid为:【xx】,user_nick为:【xx】,args为:【track_info={"alginfo":"-1rcTrig-2+1-1rcType-2Query2QUERY-1rcQVst-220191111 21:23:38-1abId-2126721-1rkBiz-2querying_esmm_gujin_v1-1pn-20-1sceneId-214177-1rkPos-26-1rcQSim-20.00700-1rcQCate-2Q2Q-1rkScore-20.01258-1rcQuery-2奉天往事-1rcShdCate-2QUERY","group_id":7916307,"object_type":110,"group_num":3,"search_q":"乡村爱情12上部","object_title":"鹤唳华亭·高甜番外","group_type":1,"source_from":"home","show_q":"乡村爱情12上部","aaid":"1b49dffdd574dcd175d714e8fea85b2f","searchtab":"0","soku_test_ab":"a","source_id":14,"k":"鹤唳华亭","item_log":"eps_t~1$site~14$show_id~dcfa5b70a2d643318dd3$doc_source~1$eng_source~6$sp_id~1154993465549914112$rec_scg_id~7916307$rec_alginfo~-1show_id-2482416-1sceneId-214945-1scg_id-27916307$rec_recext~reqid=0ec081a9-9132-406b-9450-3b4b33c4b076$scg_id~7916307","req_id":"reqid=dfcc84cd-2733-446e-a32a-dab8912f1684","search_from":"3","cn":"精选","engine":"xx","object_num":1,"newArch":"1","recext":"reqid=dfcc84cd-2733-446e-a32a-dab8912f1684"},spm=a2h0c.8166622.xx.recommend_1,statisticsTag=e3e1fc18eb13ebdd,scm=20140669.search.rtv.set_7916307,utpvid=37,pid=xx】,ds为:【20200107】,hh为:【17】,搜索结果页点击【鹤唳华亭】的推荐语
================================================================================================
// 1. 节目卡(正式/专题/花絮),点击ogc如鹤唳华亭的推荐语
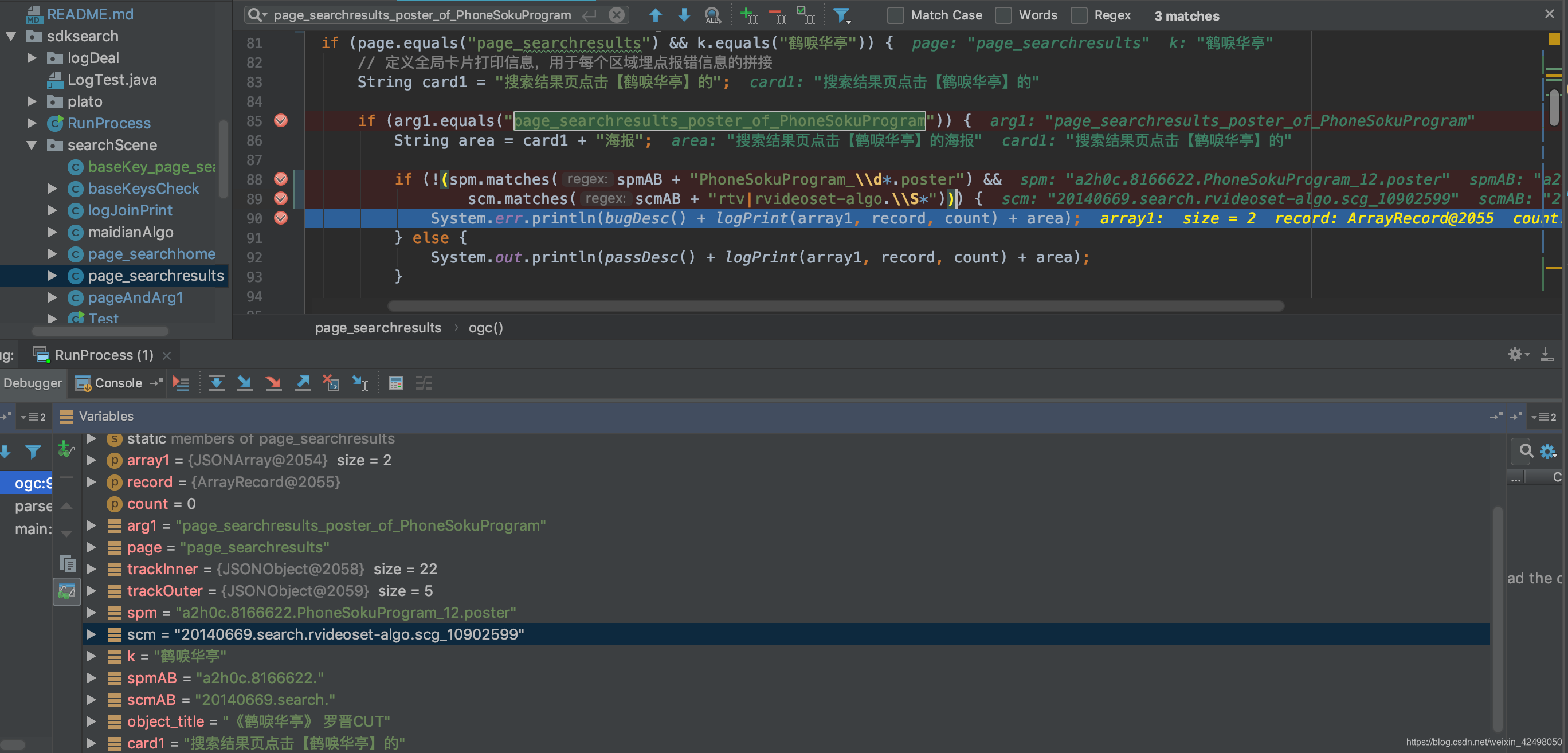
else if (arg1.equals("page_searchresults_recommend_of_PhoneSokuProgram")) {
String area = card1 + "推荐语";
if (!(spm.equals(spmAB + "PhoneSokuProgram_\\d*.recommend_\\d*") &&
scm.matches(scmAB + "rtv.(set|show|video|url|scg|playlist|live)_\\S*"))) {
System.err.println(bugDesc() + logPrint(array1, record, count) + area);
} else {
System.out.println(passDesc() + logPrint(array1, record, count) + area);
}
baseKeysCheck.existKeys(array1, record, count);
}
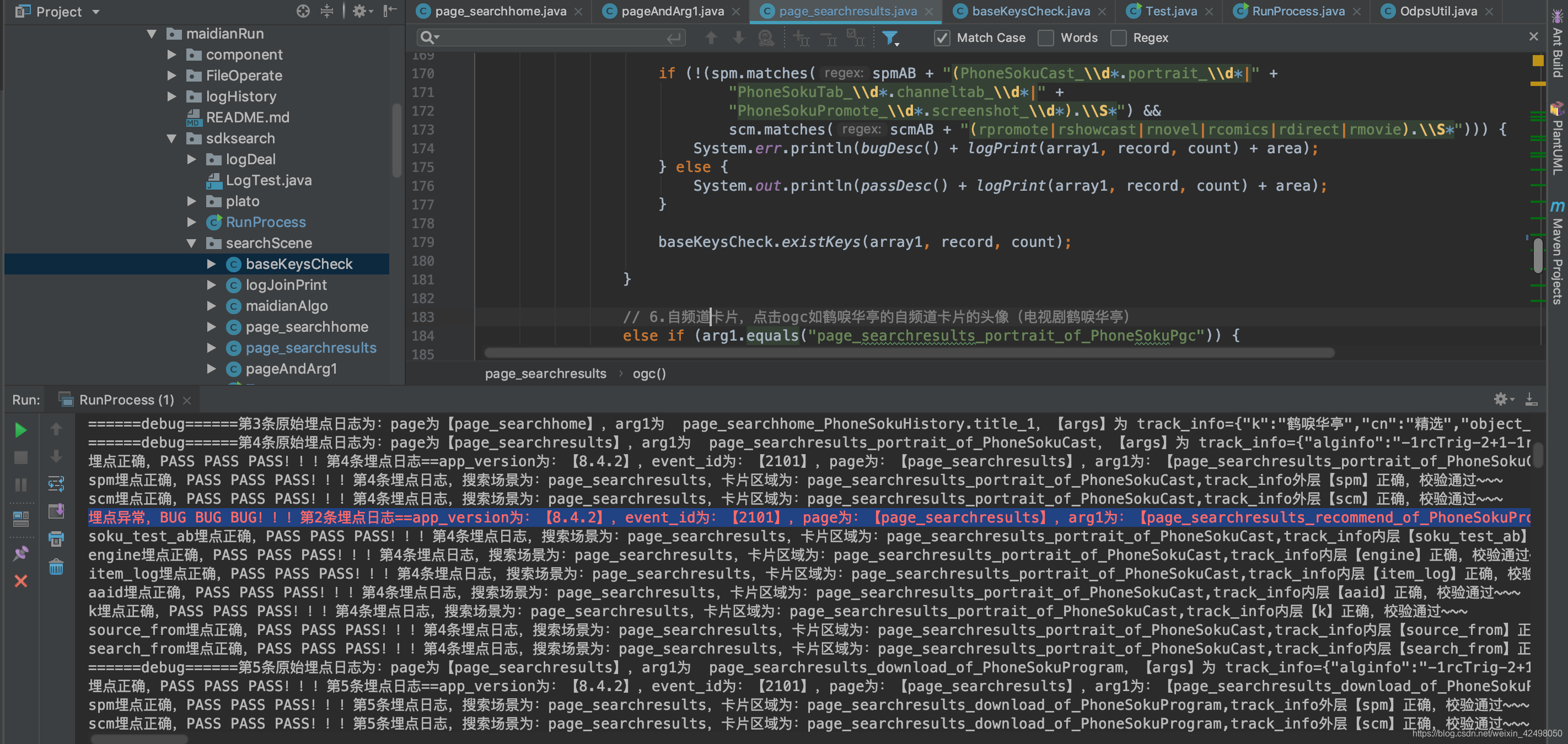

排查原因如下:
类似page_searchresults_poster_of_PhoneSokuProgram page_searchresults_recommend_of_PhoneSokuProgram
的scm的B位带空格,UT日志是正确的,入库的时候错了,脚本用trim()方法去空白处理
完美避开UT日志平台上报延迟1min-30min的问题,做到一顿操作猛如虎,狂点一番后,直接捞取odps日志测试需要校验的埋点
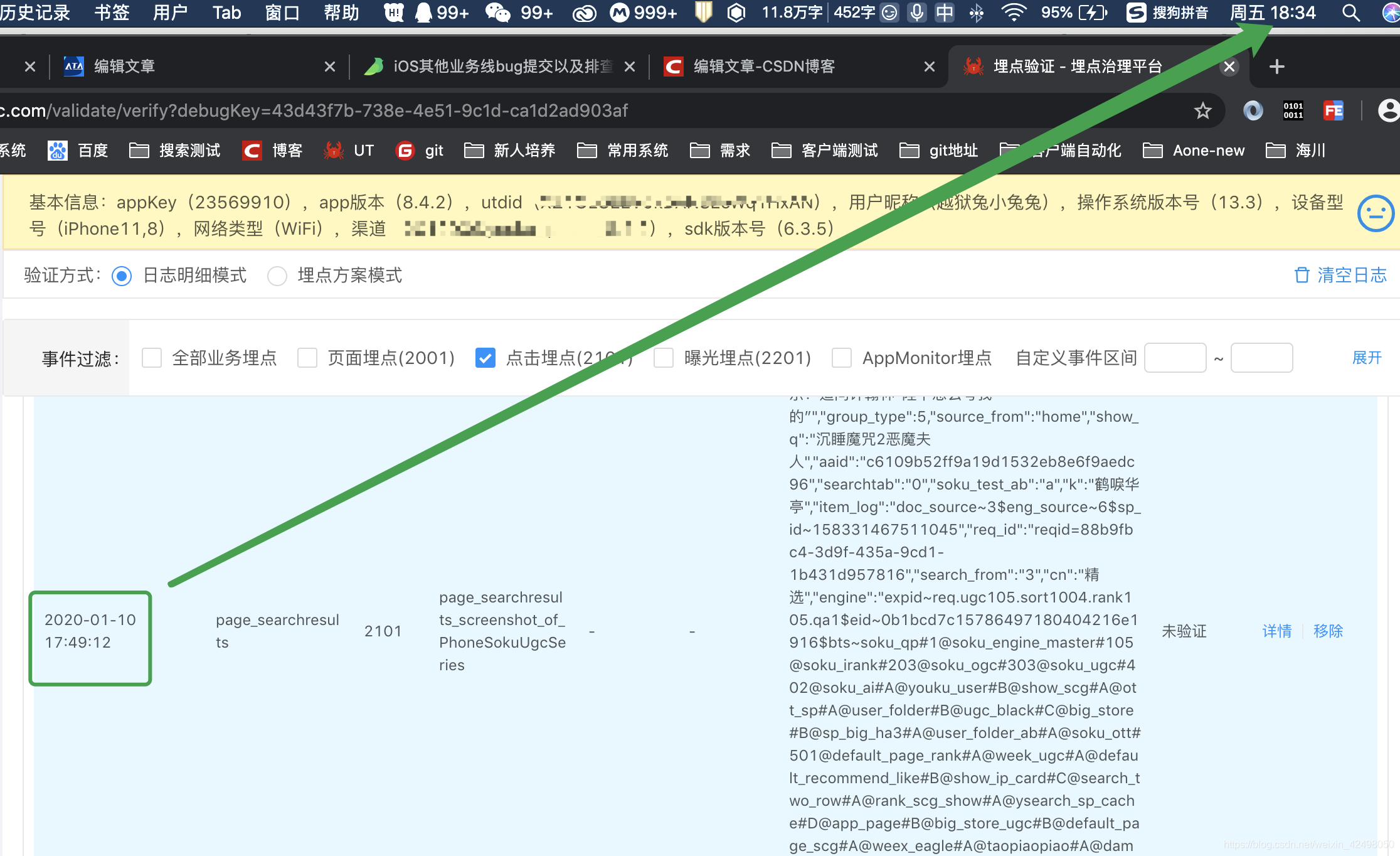
1. debug排查问题,在代码中打断点,debug模式运行主函数,在Debugger下,添加或者删除多余的代码
经排查为日志第4行解析有问题,没有track_info,这种的日志占比极少数,则需要对解析方法单独处理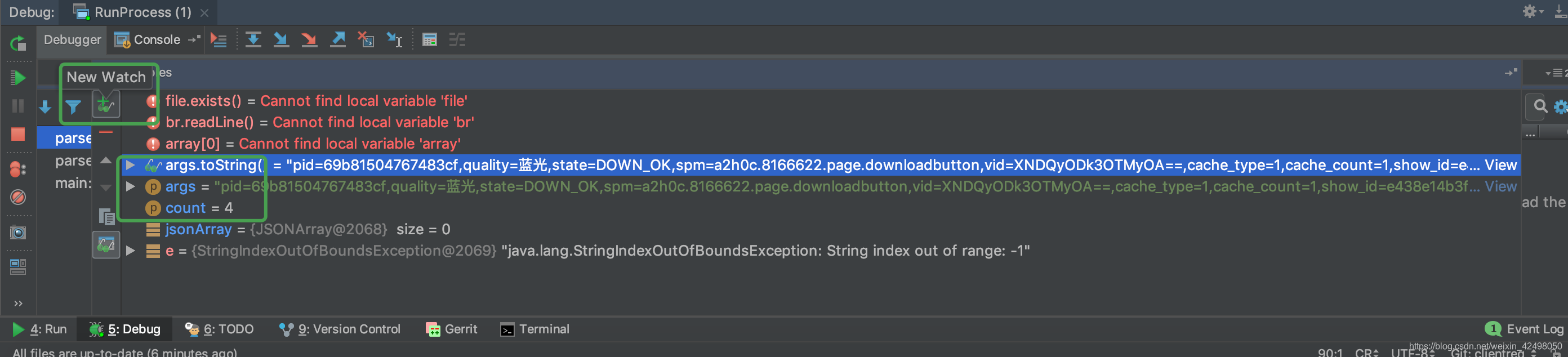
2. 正则
正则在线多个字符匹配可以添加(A|B|C),但代码如果写()则会报错
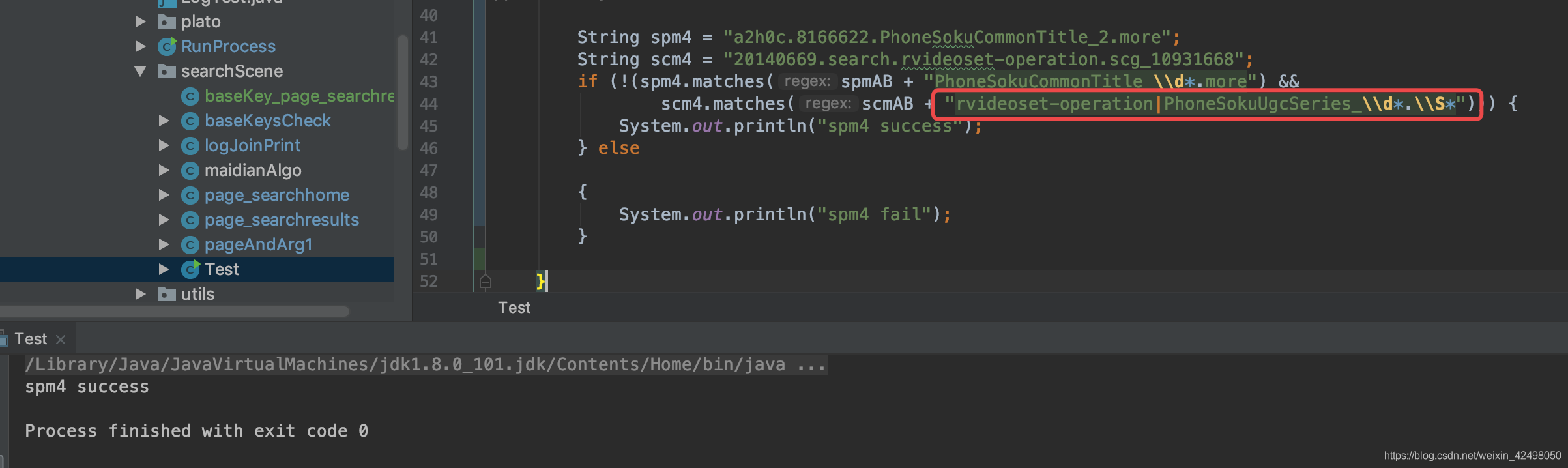
scm4.matches(scmAB + "(rvideoset-operation|PhoneSokuUgcSeries_\\d*).\\S*")
正确的为 scm4.matches(scmAB + "rvideoset-operation|PhoneSokuUgcSeries_\\d*.\\S*"))) {
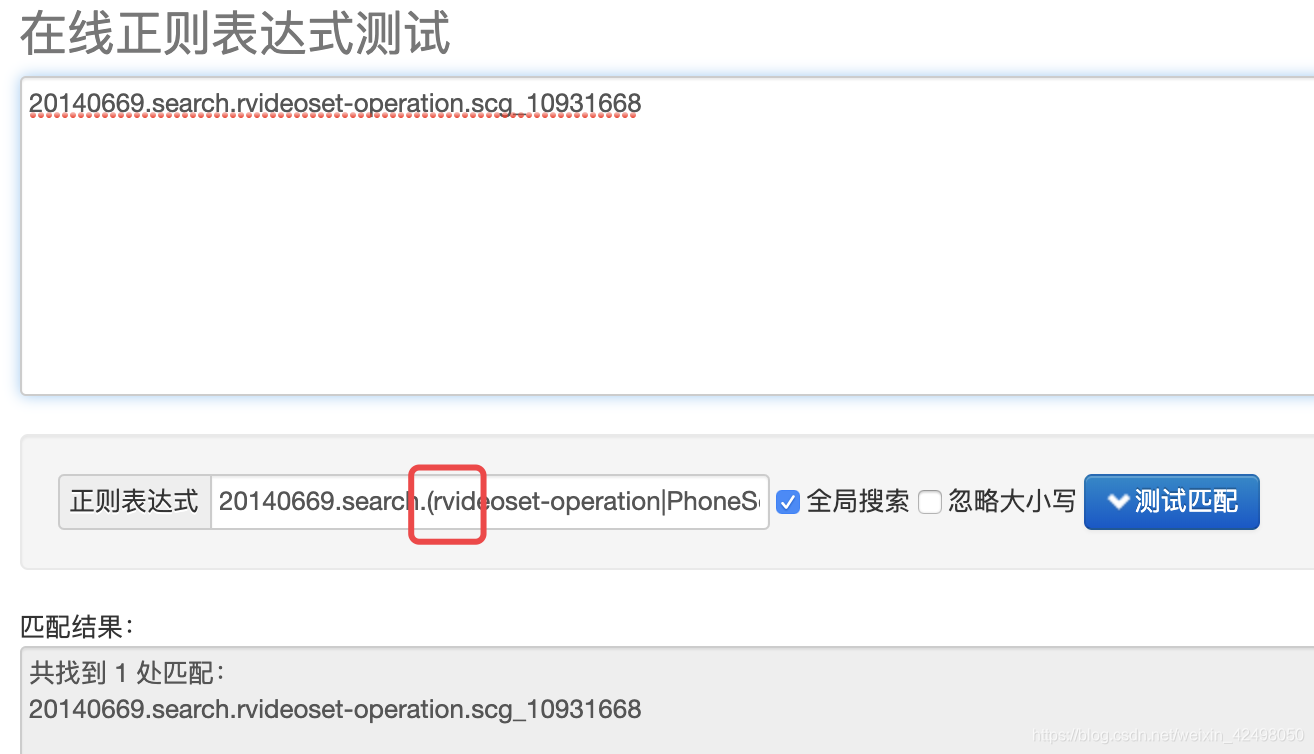
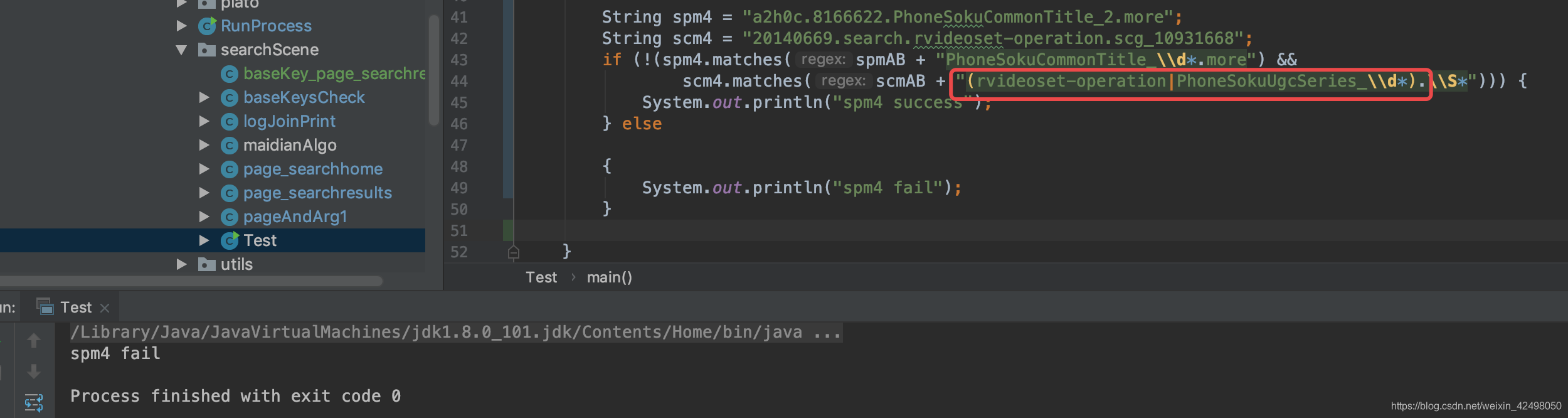
感谢我栋哥给我推荐正则表达式的图形网站 https://regexper.com/
神奇 ,找了一下午原因,正则表达式看着没问题,为啥一直err??看了好久了 。。。。这个放在 TestDemo是pass的,但放在我的业务代码是fail的。因为自己傻缺的把test里的日志打印反了success 和fail反了。。。
如果track_info外层包含scm=20140669.search.rvideoset-algo.video_XNDQ5OTQ4NjgwNA==或者spm=a2h0c.8166622.page.downloadbutton,vid=XNDQyODk3OTMyOA==
则需要把==替换为空,不影响以,拆分的判断
接入定时任务平台:
客户端传参监控:
cd /Users/lishan/Desktop/code/xx-testing/xx-testing-service
mvn compile
mvn exec:java -pl :xx-testing-service -Dexec.mainClass=com.xx.newcpw.sdksearch.RunProcess
搜索埋点自动化:
cd /Users/lishan/Desktop/code/xx-testing/xx-testing-service
mvn compile
mvn exec:java -pl :xx-testing-service -Dexec.mainClass=com.xx.newcpw.sdksearch.RunProcess
git地址2者公用一个:
http://xx.xx.git
分支 clientreq
未完待续。。。。readme 流程图产出,代码完善,接入钉钉报警,错误 正常信息入库,接口开发,前端开发等。。。
解决日志重复上报的问题
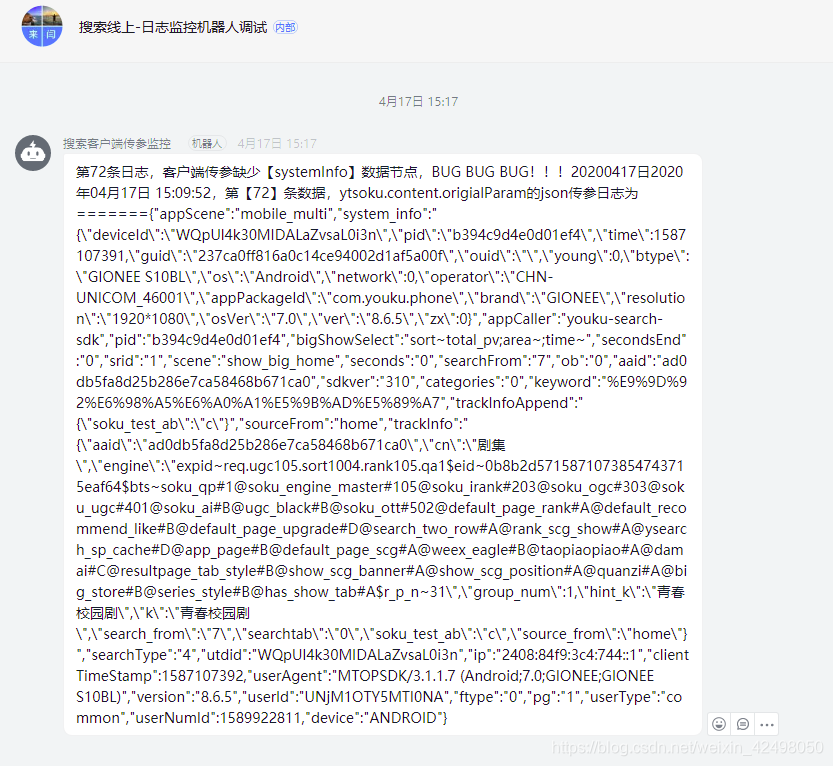
接入钉钉报警的样子


















 7277
7277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











