






资源指标和资源监控
集群系统管理离不开监控,同样的Kubernetes也需要根据数据指标来采集相关数据,从而完成对集群系统的监控状况进行监测。
这些指标总体上分为两个组成:监控集群本身和监控Pod对象,通常一个集群的衡量性指标包括以下几个部分:
节点资源状态:主要包括CPU、内存使用率、磁盘空间、网络带宽。
节点的数量:即时了解集群的可用节点数量可以为用户计算服务器使用的费用支出提供参考。
运行的Pod对象:正在运行的Pod对象数量可以评估可用节点数量是否足够,以及节点故障时是否能平衡负载。
另一个方面,对Pod资源对象的监控需求大概有以下三类:
Kubernetes指标:监测特定应用程序相关的Pod对象的部署过程、副本数量、状态信息、健康状态、网络等等。
容器指标:容器的CPU、内存、磁盘空间、网络带宽、资源需求、资源限制的实际占用情况。
应用程序指标:应用程序自身的内建指标,和业务规则相关
Weave Scope监控集群
Weave Scope 是 Docker 和 Kubernetes 可视化监控工具。Scope 提供了至上而下的集群基础设施和应用的完整视图,用户可以轻松对分布式的容器化应用进行实时监控和问题诊断。对于复杂的应用编排和依赖关系,scope可以使用清晰的图标一览应用状态和拓扑关系。
1、部署Weave Scope
[root@k8s-master01 yaml]# kubectl apply -f "https://cloud.weave.works/k8s/scope.yaml?k8s-version=$(kubectl version | base64 | tr -d '\n')"namespace/weave createdserviceaccount/weave-scope createdclusterrole.rbac.authorization.k8s.io/weave-scope createdclusterrolebinding.rbac.authorization.k8s.io/weave-scope createddeployment.apps/weave-scope-app createdservice/weave-scope-app createddeployment.apps/weave-scope-cluster-agent createddaemonset.apps/weave-scope-agent created[root@k8s-master01 yaml]# kubectl get nsNAME STATUS AGEdefault Active 30dkube-node-lease Active 30dkube-public Active 30dkube-system Active 30dkubernetes-dashboard Active 29dweave Active 38s[root@k8s-master01 yaml]# kubectl get deployment -n weaveNAME READY UP-TO-DATE AVAILABLE AGEweave-scope-app 0/1 1 0 53sweave-scope-cluster-agent 0/1 1 0 53s[root@k8s-master01 yaml]# kubectl get svc -n weaveNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEweave-scope-app ClusterIP 10.108.120.236 80/TCP 71s[root@k8s-master01 yaml]# kubectl get pod -n weave -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESweave-scope-agent-bkc5t 1/1 Running 0 2m8s 192.168.56.10 k8s-master01 weave-scope-agent-l4sb8 1/1 Running 0 2m8s 192.168.56.12 k8s-node02 weave-scope-agent-n4rnd 1/1 Running 0 2m8s 192.168.56.11 k8s-node01 weave-scope-app-bc7444d59-94v94 1/1 Running 0 2m9s 10.244.1.17 k8s-node01 weave-scope-cluster-agent-5c5dcc8cb-gz8v9 1/1 Running 0 2m9s 10.244.1.18 k8s-node01 DaemonSet weave-scope-agent,集群每个节点上都会运行的 scope agent 程序,负责收集数据
Deployment
weave-scope-app,scope 应用,从 agent 获取数据,通过 Web UI 展示并与用户交互。Service
weave-scope-app,默认是 ClusterIP 类型,为了方便已通过kubectl edit修改为NodePort。
[root@k8s-master mainfests]# kubectl edit svc/weave-scope-app -n weave将service的 type: ClusterIP 改为 type: NodePort[root@k8s-master01 yaml]# kubectl get svc -n weaveNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEweave-scope-app NodePort 10.108.120.236 80:31977/TCP 4m19s2、使用 Weave Scope
浏览器访问 http://192.168.56.10:31977/,Scope 默认显示当前所有的 Controller(Deployment、DaemonSet 等)。
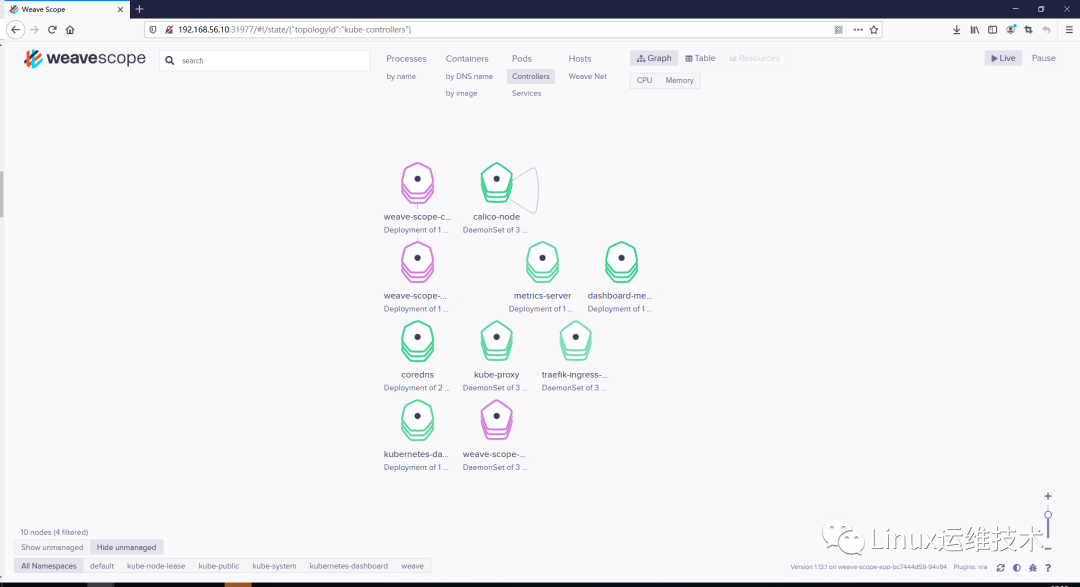
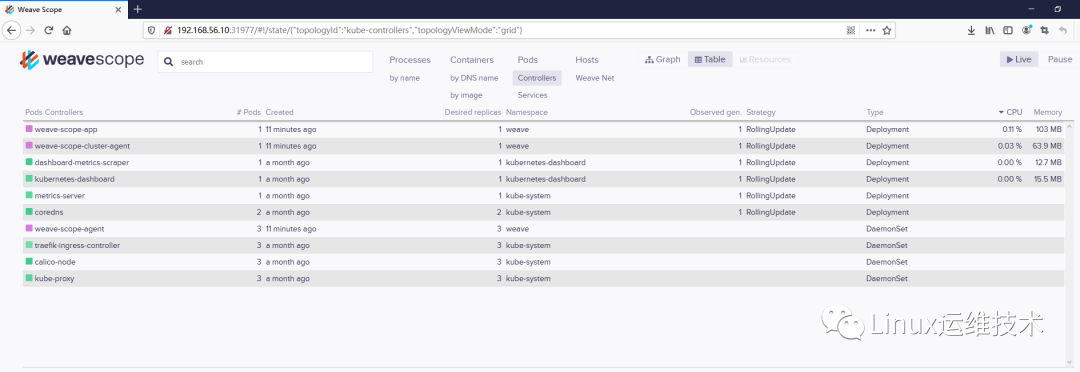
3、拓扑结构
Scope 会自动构建应用和集群的逻辑拓扑。比如点击顶部 PODS,会显示所有 Pod 以及 Pod 之间的依赖关系。
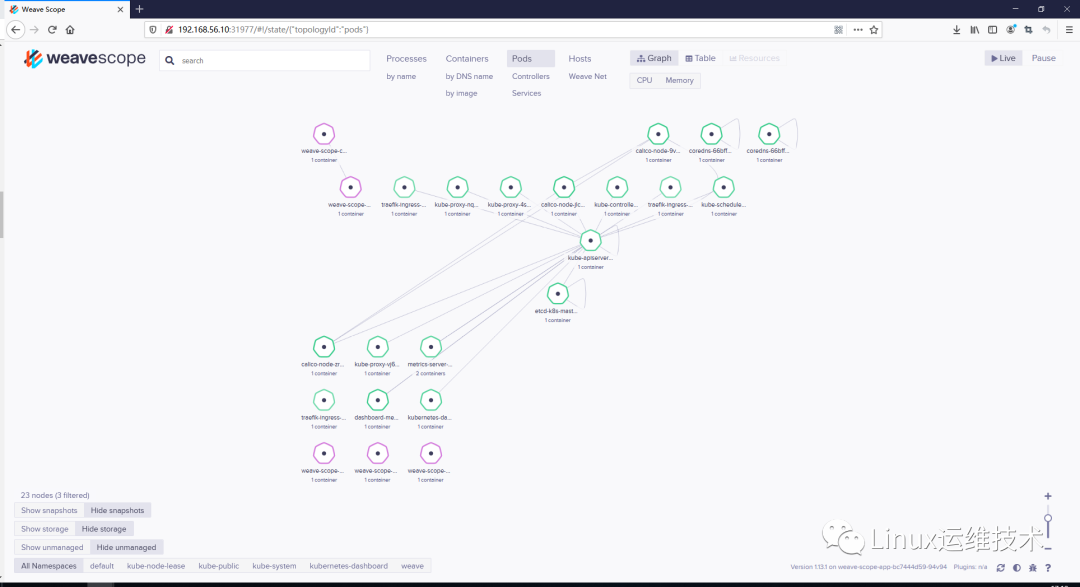
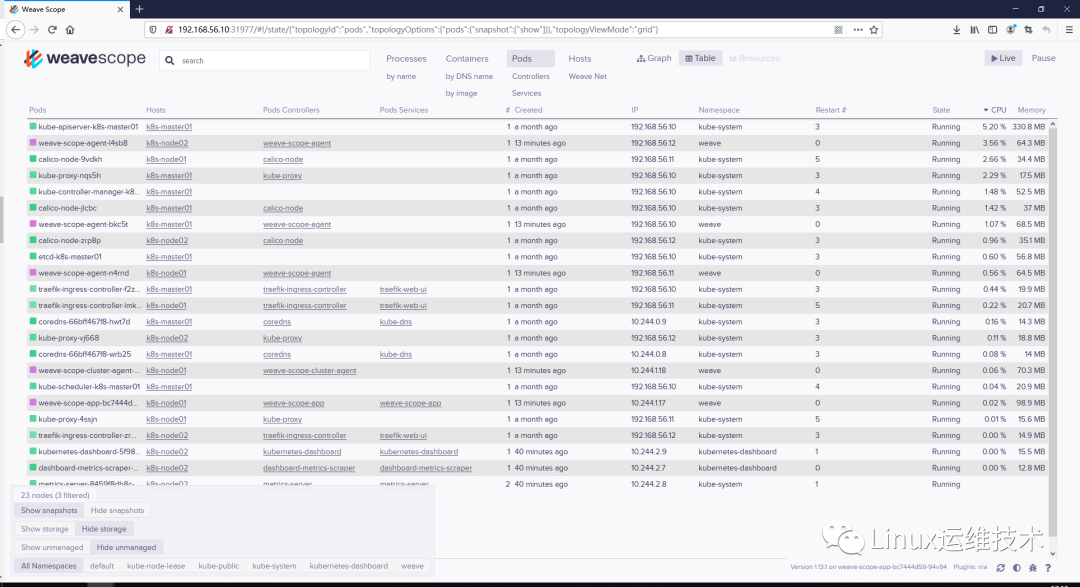
点击 HOSTS,会显示各个节点之间的关系。
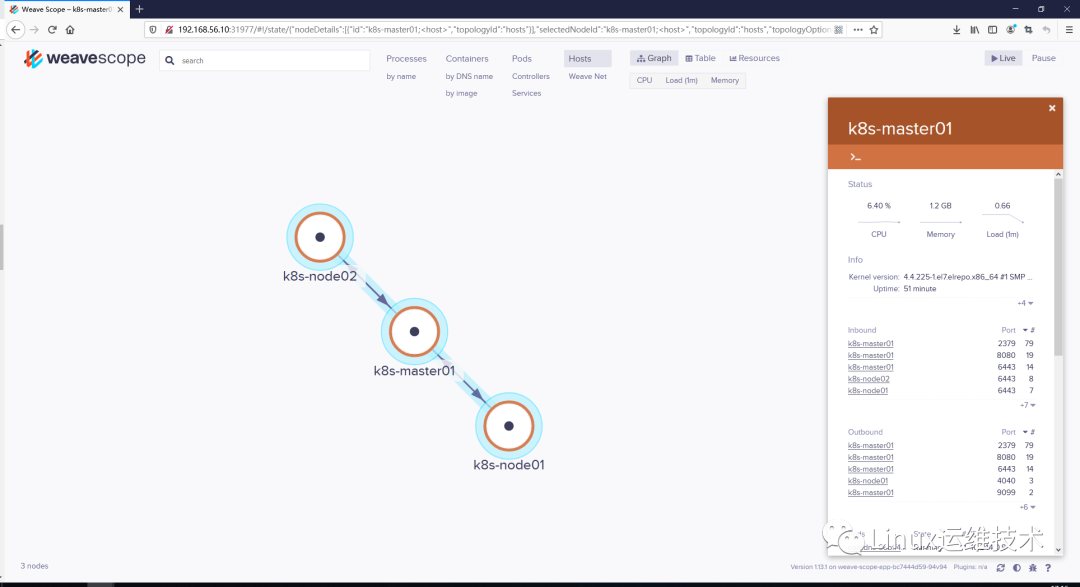

4、实时资源监控
可以在 Scope 中查看资源的 CPU 和 Memory使用情况。支持的资源有 Host、Pod 和 Container。
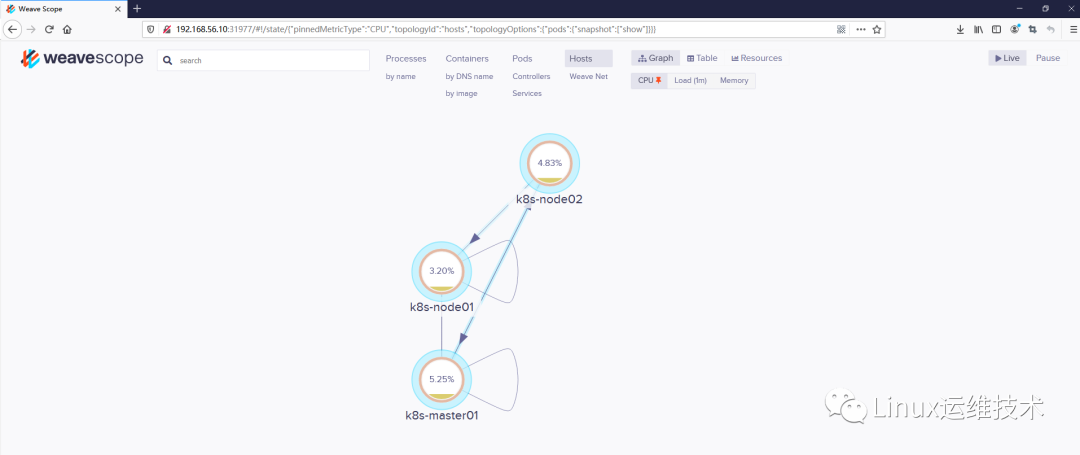
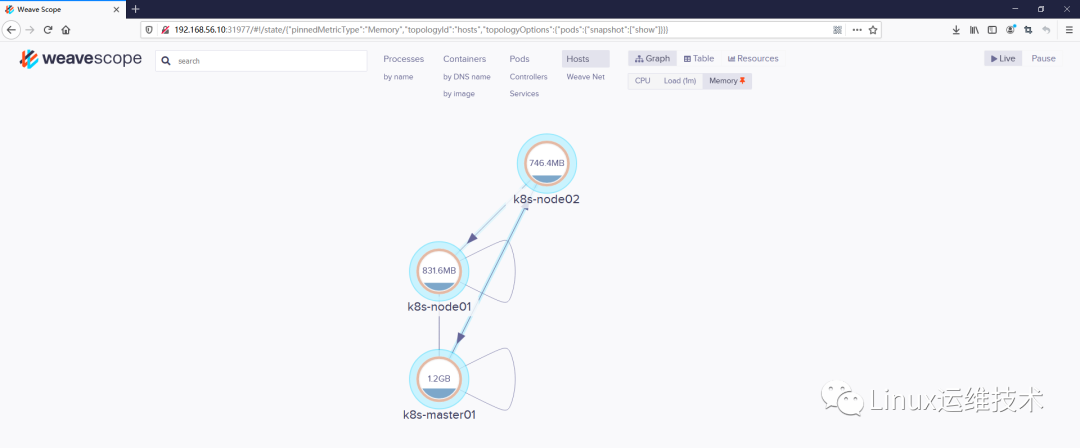
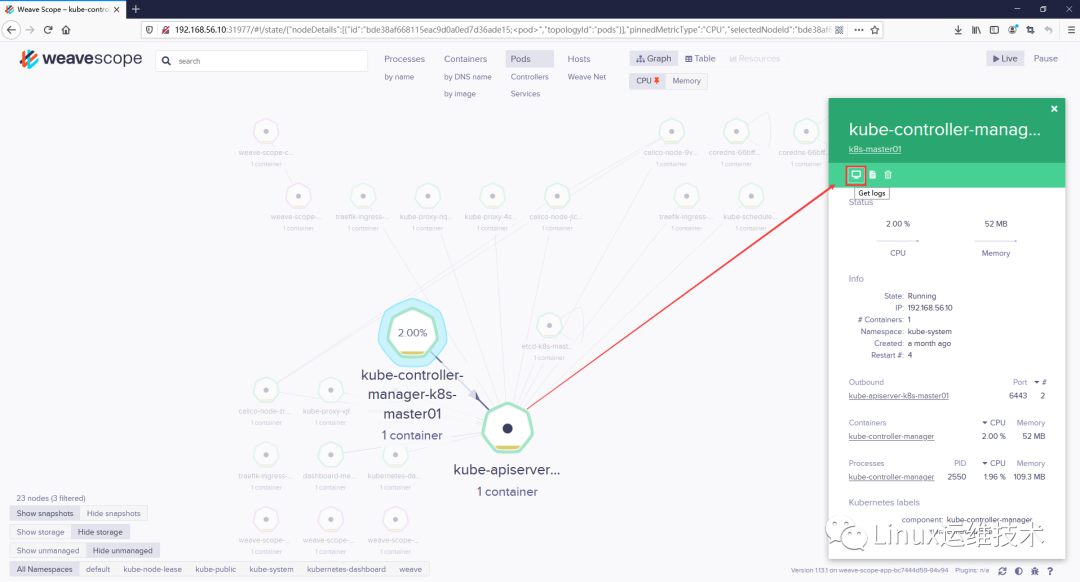
5、在线操作
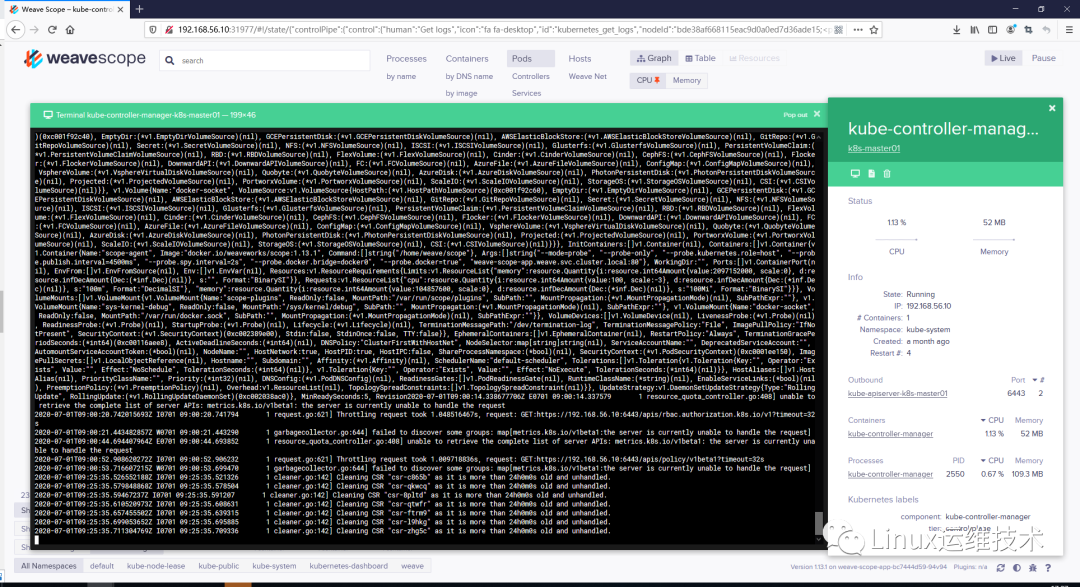
可以查看 Pod 的日志:
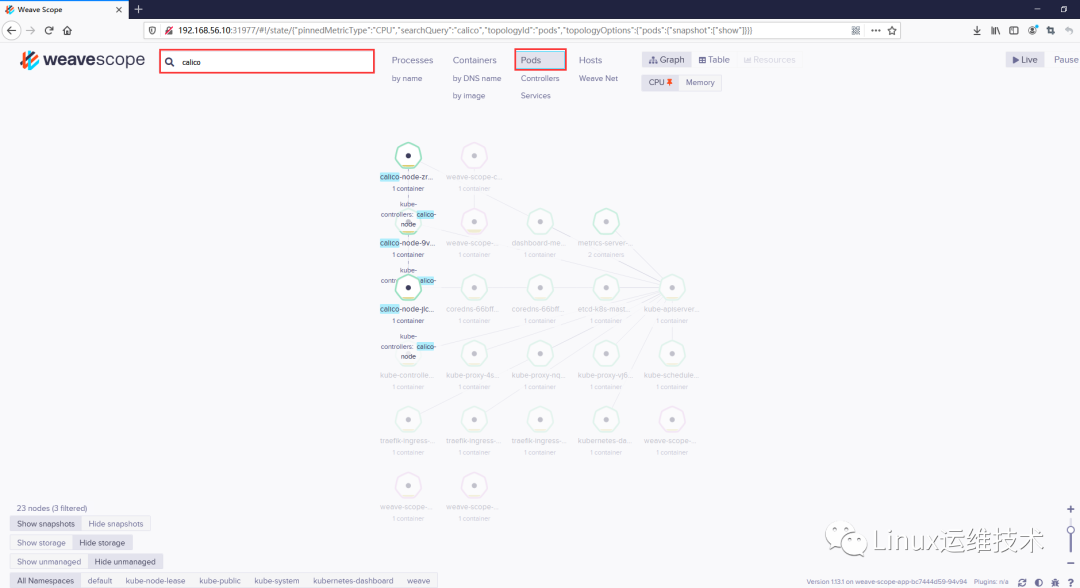
6、强大的搜索功能
Scope 支持关键字搜索和定位资源。
核心指标监控之metrics-server
在最初的系统资源监控,是通过cAdvisor去收集单个节点以及相关Pod资源的指标数据,但是这一功能仅能够满足单个节点,在集群日益庞大的过程中,该功能就显得low爆了。于是将各个节点的指标数据进行汇聚并通过一个借口进行向外暴露传送是必要的。
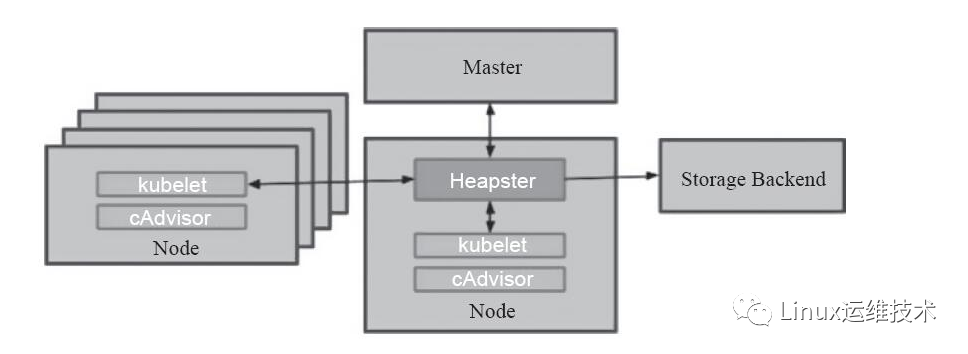
Heapster就是这样的一种方式,通过为集群提供指标API和实现并进行监控,它是集群级别的监控和事件数据的聚合工具,但是一个完备的Heapster监控体系是需要进行数据存储的,为此其解决方案就是引入了Influxdb作为后端数据的持久存储,Grafana作为可视化的接口。原理就是Heapster从各个节点上的cAdvisor采集数据并存储到Influxdb中,再由Grafana展示。原理图如下:
时代在变迁,陈旧的东西将会被淘汰,由于功能和系统发展的需求,Heapster无法满足k8s系统监控的需求,为此在Kubernetes 1.7版本以后引入了自定义指标(custom metrics API),在1.8版本引入了资源指标(resource metrics API)。逐渐地Heapster用于提供核心指标API的功能也被聚合方式的指标API服务器metrics-server所替代。
在新一代的Kubernetes指标监控体系当中主要由核心指标流水线和监控指标流水线组成:
核心指标流水线:是指由kubelet、、metrics-server以及由API server提供的api组成,它们可以为K8S系统提供核心指标,从而了解并操作集群内部组件和程序。其中相关的指标包括CPU的累积使用率、内存实时使用率,Pod资源占用率以及容器磁盘占用率等等。其中核心指标的获取原先是由heapster进行收集,但是在1.11版本之后已经被废弃,从而由新一代的metrics-server所代替对核心指标的汇聚。核心指标的收集是必要的。如下图:
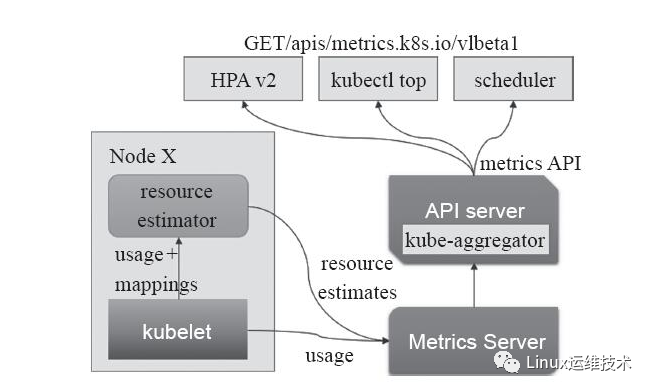
监控指标流水线:用于从系统收集各种指标数据并提供给终端用户、存储系统以及HPA。它们包含核心指标以及许多非核心指标,其中由于非核心指标本身不能被Kubernetes所解析,此时就需要依赖于用户选择第三方解决方案。如下图:
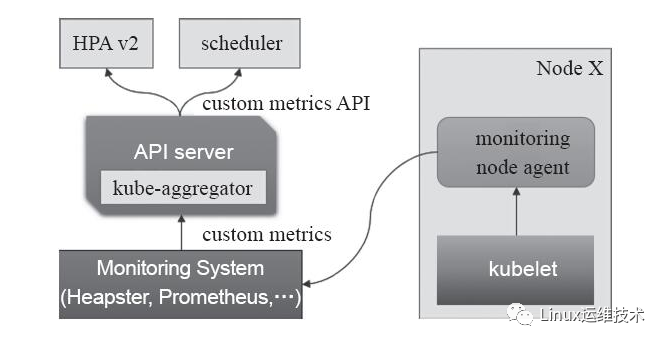
一个可以同时使用资源指标API和自定义指标API的组件是HPAv2,其实现了通过观察指标实现自动扩容和缩容。而目前资源指标API的实现主流是metrics-server。
自v1.8版本后,容器的cpu和内存资源占用利用率都可以通过客户端指标API直接调用,从而获取资源使用情况,要知道的是API本身并不存储任何指标数据,仅仅提供资源占用率的实时监测数据。
资源指标和其他的API指标并没有啥区别,它是通过API Server的URL路径/apis/metrics.k8s.io/进行存取,只有在k8s集群内部署了metrics-server应用才能只用API,其简单的结构图如下:
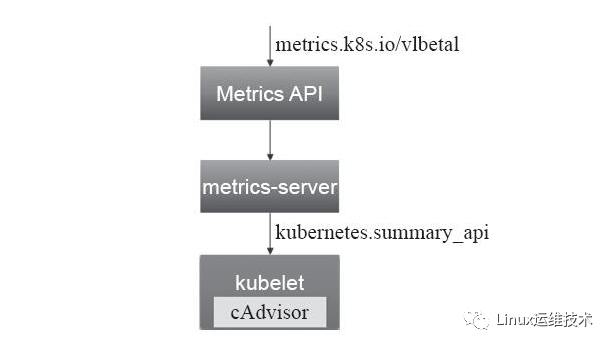
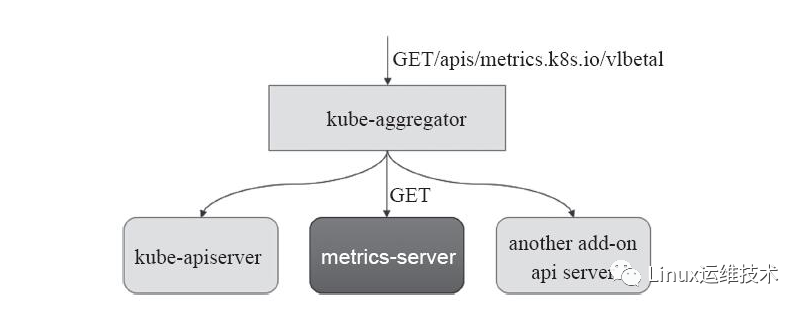
Heapster。Metrics Server 通过 Kubernetes 聚合 器( kube- aggregator) 注册 到 主 API Server 之上, 而后 基于 kubelet 的 Summary API 收集 每个 节 点上 的 指标 数据, 并将 它们 存储 于 内存 中 然后 以 指标 API 格式 提供,如下图:
Metrics Server基于 内存 存储, 重 启 后 数据 将 全部 丢失, 而且 它 仅能 留存 最近 收集 到 的 指标 数据, 因此, 如果 用户 期望 访问 历史 数据, 就不 得不 借助于 第三方 的 监控 系统( 如 Prometheus 等)。
一般说来, Metrics Server 在 每个 集群 中 仅 会 运行 一个 实例, 启动 时, 它将 自动 初始化 与 各 节点 的 连接, 因此 出于 安全 方面 的 考虑, 它 需要 运行 于 普通 节点 而非 Master 主机 之上。直接 使用 项目 本身 提供 的 资源 配置 清单 即 能 轻松 完成 metrics- server 的 部署。
Kubernetes官方 metrics-server yaml链接
https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/metrics-server
#从官方YAML文件中下载以下文件[root@k8s-master01 yaml]# lltotal 24-rw-r--r-- 1 root root 411 Jul 1 18:24 auth-delegator.yaml-rw-r--r-- 1 root root 433 Jul 1 18:26 auth-reader.yaml-rw-r--r-- 1 root root 402 Jul 1 18:26 metrics-apiservice.yaml-rw-r--r-- 1 root root 3468 Jul 1 18:27 metrics-server-deployment.yaml-rw-r--r-- 1 root root 350 Jul 1 18:27 metrics-server-service.yaml-rw-r--r-- 1 root root 889 Jul 1 18:28 resource-reader.yaml#node节点下载测试的image镜像 (如果不能下载,可以在阿里云镜像仓库搜索)docker pull k8s.gcr.io/metrics-server-amd64:v0.3.6#修改下面这个文件的部分内容[root@k8s-master01 yaml]# vim metrics-server-deployment.yaml#在metrics-server这个容器字段里面修改command为如下: spec: priorityClassName: system-cluster-critical serviceAccountName: metrics-server containers: - name: metrics-server image: k8s.gcr.io/metrics-server-amd64:v0.3.6 command: - /metrics-server - --metric-resolution=30s - --kubelet-insecure-tls - --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP#再修改metrics-server-nanny容器中的cpu和内存值,如下: command: - /pod_nanny - --config-dir=/etc/config - --cpu=100m - --extra-cpu=0.5m - --memory=100Mi - --extra-memory=50Mi - --threshold=5 - --deployment=metrics-server-v0.3.6 - --container=metrics-server - --poll-period=300000 - --estimator=exponential - --minClusterSize=10 #由于启动容器还需要权限获取数据,需要在resource-reader.yaml文件中增加nodes/stats[root@k8s-master metrics]# vim resource-reader.yaml....rules:- apiGroups: - "" resources: - pods - nodes - nodes/stats - namespaces#部署开始[root@k8s-master01 yaml]# kubectl apply -f .[root@k8s-master01 yaml]# kubectl api-versions |grep metricsmetrics.k8s.io/v1beta1#检查资源指标API的可用性[root@k8s-master metrics]# kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes"{"kind":"NodeMetricsList","apiVersion":"metrics.k8s.io/v1beta1","metadata":{"selfLink":"/apis/metrics.k8s.io/v1beta1/nodes"},"items":[{"metadata":{"name":"k8s-master01","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/k8s-master01","creationTimestamp":"2020-07-01T10:39:13Z"},"timestamp":"2020-07-01T10:39:06Z","window":"30s","usage":{"cpu":"522620800n","memory":"1291224Ki"}},{"metadata":{"name":"k8s-node01","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/k8s-node01","creationTimestamp":"2020-07-01T10:39:13Z"},"timestamp":"2020-06-02T04:41:50Z","window":"30s","usage":{"cpu":"581168505n","memory":"855916Ki"}},{"metadata":{"name":"k8s-node02","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/k8s-node02","creationTimestamp":"2020-07-01T10:39:13Z"},"timestamp":"2020-07-01T10:39:07Z","window":"30s","usage":{"cpu":"284768749n","memory":"716116Ki"}}]}#确保Pod对象运行正常[root@k8s-master metrics]# kubectl get pods -n kube-system |grep metricsmetrics-server-v0.3.6-5bf55fb6b5-z7xg6 2/2 Running 0 10m以上如果内容没有做修改的话,会出现容器跑不起来一直处于CrashLoopBackOff状态,或者出现权限拒绝的问题。可以通过kubectl logs进行查看相关的日志。
下面使用kubectl top命令进行查看资源信息:
[root@k8s-master01 yaml]# kubectl top nodeNAME CPU(cores) CPU% MEMORY(bytes) MEMORY% k8s-master01 807m 20% 1374Mi 23% k8s-node01 388m 9% 872Mi 14% k8s-node02 503m 12% 730Mi 12%[root@k8s-master01 yaml]# kubectl top pod -l k8s-app=kube-dns --containers=true -n kube-systemPOD NAME CPU(cores) MEMORY(bytes) coredns-66bff467f8-hwt7d coredns 4m 14Mi coredns-66bff467f8-wrb25 coredns 13m 14Mi















 1016
1016











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









