







 本文探讨了分布式流水线并行,特别是Gpipe方法,如何通过微批处理和重计算策略来提高GPU效率及降低显存消耗。文章还提到了张量并行的差异以及大模型分布式训练中的应用。
本文探讨了分布式流水线并行,特别是Gpipe方法,如何通过微批处理和重计算策略来提高GPU效率及降低显存消耗。文章还提到了张量并行的差异以及大模型分布式训练中的应用。
0 引言
分布式流水线并行,同样只是作为个人学习总结记录,错误请指出。
1 对比
流水线并行和张量并行都可以看作是模型并行的一种,只是对模型切分的维度不同,流水线并行可以看作是层间并行,将模型不同的层放到不同的GPU上,张量并行看作是层内并行,是对层内具体的矩阵运算进行拆分。

2 流水线并行-Gpipe
假设模型太大,有T1、T2、T3、T4四层,一张GPU上放不下,流水线并行就是将T1、T2放到GPU0上,T3、T4放到GPU1上,如下图所示。
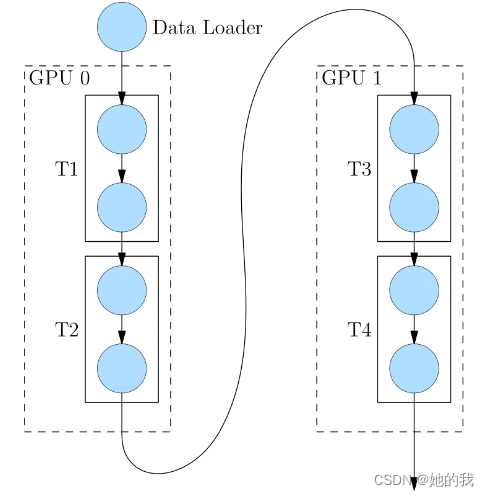
通过流水线并行能够将大模型切分到更多的GPU上,但是缺点也是显而易见,在计算过程中,必须顺序执行,后面的计算过程依赖于前面的计算结果,导致GPU效率不高,如下图有很多空白的地方。假设将模型放到四个GPU上,横轴为时间线,可以看出同一时间只有一个GPU在运行,F表示前向过程,B表示后向过程。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5260
5260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











