







 本文详细介绍了Attention机制的由来,从机器翻译的seq2seq模型开始,逐步引入Attention机制的演变,包括self-attention、Soft attention、Hard attention等变种。通过理解Attention机制,可以更好地掌握深度学习中的序列处理和信息聚焦。
本文详细介绍了Attention机制的由来,从机器翻译的seq2seq模型开始,逐步引入Attention机制的演变,包括self-attention、Soft attention、Hard attention等变种。通过理解Attention机制,可以更好地掌握深度学习中的序列处理和信息聚焦。
Attention 机制的由来与发展
看 NLP 方向的论文,几乎每篇都能看到 self-attention、transformer、bert 的出现,如果直接去学习这几个模型的话,很容易迷失在各种矩阵操作中,心里会一直有个疑问,为什么要这么做?但是了解 attention 机制的源头及发展后,心里就慢慢清晰了起来。所以,写这篇文章打算从头梳理一下 attention。
机器翻译理论部分
在 NLP 中给定一个序列,输出另一个序列的任务,称为 seq2seq,也就是序列到序列的任务。也是机器翻译最常用的模型,解决的最大的问题就是输入序列和输出序列的长度不一致问题。
在机器翻译问题中,假设我们有一系列的训练样本 ( x i , y i ) , i = 1... n (x_i,y_i),i=1...n (xi,yi),i=1...n,其中 x x x 代表待翻译的句子, y y y 代表翻译后的句子。
对于每一个训练样本 ( x i , y i ) (x_i,y_i) (xi,yi) , x , y x,y x,y 分别代表两个序列, x = ( x < 1 > , x < 2 > , … , x < T x > ) x = \left(x^{<1>}, x^{<2>}, \ldots, x^{<T_{x}>}\right) x=(x<1>,x<2>,…,x<Tx>), y = ( y < 1 > , y < 2 > , … , y < T y > ) y = \left(y^{<1>}, y^{<2>}, \ldots, y^{<T_{y}>}\right) y=(y<1>,y<2>,…,y<Ty>)。
例如在中英翻译中, x = ( 我 , 是 , 中 国 , 人 ) x=(我,是,中国,人) x=(我,是,中国,人) , y = ( I , a m , c h i n e s e ) y=(I,am,chinese) y=(I,am,chinese)。
根据极大似然估计, 我们的目标函数可以写为最大化: P ( Y ∣ X ) = ∏ i = 1 n P ( Y i ∣ X i ) P(Y \mid X)=\prod_{i=1}^{n} P\left(Y_{i} \mid X_{i}\right) P(Y∣X)=i=1∏nP(Yi∣Xi)
转换成 log \log log 形式则是最小化:
min θ − 1 N ∑ i = 1 N log P ( Y i ∣ X i ) \underset{\theta}{\operatorname{min}} -\frac{1}{N} \sum_{i=1}^{N}\log_{}{ P\left(Y_{i} \mid X_{i}\right)} θmin−N1i=1∑NlogP(Yi∣Xi)
其中 θ \theta θ为模型参数。
现在我们只需要知道 P ( Y ∣ X ) P(Y \mid X) P(Y∣X) 怎么求即可。
首先我们知道: P ( Y ∣ X ) = P ( y < 1 > , y < 2 > , y < 3 > , … y < T y > ∣ x < 1 > , x < 2 > , … x < T x > ) P(Y \mid X) = P\left(y^{<1>}, y^{<2>}, y^{<3>}, \ldots y^{<T_{y}>} \mid x^{<1>}, x^{<2>}, \ldots x^{<T_{x}>}\right) P(Y∣X)=P(y<1>,y<2>,y<3>,…y<Ty>∣x<1>,x<2>,…x<Tx>)
上面这个式子可以用下面的公式转换,由于序列太长,所以只写了一部分举例:
P ( y < 1 > , y < 2 > ∣ x < 1 > , x < 2 > ) = P ( y < 1 > ∣ x < 1 > , x < 2 > ) ⋅ P ( y < 2 > ∣ y < 1 > , x < 1 > , x < 2 > ) P\left(y^{<1>}, y^{<2>} \mid x^{<1>}, x^{<2>}\right) = P\left(y^{<1>}\mid x^{<1>}, x^{<2>}\right) \cdot P\left( y^{<2>}\mid y^{<1>},x^{<1>}, x^{<2>}\right) P(y<1>,y<2>∣x<1>,x<2>)=P(y<1>∣x<1>,x<2>)⋅P(y<2>∣y<1>,x<1>,x<2>)
这个式子就是序列模型的原理。下面讲 seq2seq 模型时,就可以对照理解这个式子了。
seq2seq 最初模样
seq2seq 模型被称为条件语言模型(conditional language model)。最早由bengio等人发表在 computer science 上的论文:Learning Phrase Representations using RNN Encoder–Decoder
for Statistical Machine Translation
其结构如下图所示:
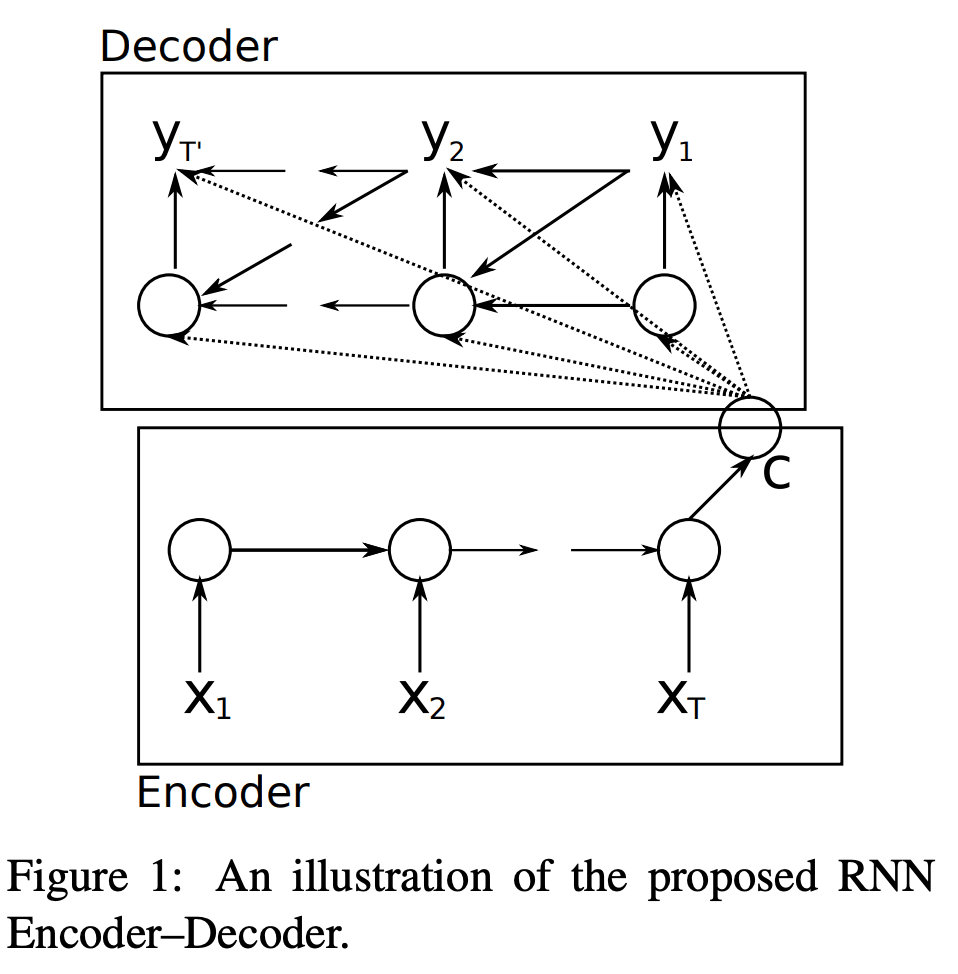
Encoder 用 RNN 来构成,每个 time-step 向 Encoder中 输入一个词的向量 $ x^{}$ ,输出为 h < t > h^{<t>} h<t>,直到句子的最后一个单词被输入 x < T x > x^{<T_x>} x<Tx>,得到的输出为句向量 c = t a n h ( V h < T x > ) c=tanh(Vh^{<T_x>}) c=tanh(Vh<Tx>)。
其中 Encoder 中 RNN 状态更新公式为:
h < t > = f ( h < t − 1 > , x < t > ) , t = 1 , … , T x h^{<t>}=f\left(h^{<t-1>}, x^{<t>}\right), t=1, \ldots, T_{x} h<t>=f(h<t−1>,x<t>),t=1,…,Tx
其中 f f f 代表 RNN,也可以换成 LSTM 或 GRU。
句子向量 c c c 由 Encoder 最后一刻的输出状态 h < T x > h^{<T_x>} h<Tx> 变换得到:
c = t a n h ( V h < T x > ) c=tanh(Vh^{<T_x>}) c=tanh(Vh<Tx>)
Decoder 用另一个 RNN 来构成,用来根据之前 Encoder 得到的句向量 c c
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 640
640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











