







 作者丨凉爽的安迪@知乎 来源丨https://zhuanlan.zhihu.com/p/125145283 编辑丨极市平台
作者丨凉爽的安迪@知乎 来源丨https://zhuanlan.zhihu.com/p/125145283 编辑丨极市平台
极市导读
本文的讲述的是关于深度学习中的Attention机制,本文并非定位于对Attention机制的各类框架和玩法进行综述,而是介绍了四个Attention的有代表性和有意思的工作,并给出关于Attention机制的合理性的进一步的思考。 >>明日直播!田值:实例分割创新式突破BoxInst,仅用Box标注,实现COCO 33.2AP!
写在前面: 本文是一篇关于深度学习中的 Attention机制 的文章。与之前的系列文章不同,本文并非定位于对Attention机制的各类框架和玩法进行综述,因此不会花费过多的篇章去介绍Attention的发展历史或数学计算方法;更多是简单地介绍几个Attention的代表性和有意思的工作,并去思考Attention机制的合理性,提出一些进一步的思考。
以下是本文的主要框架:
- 问题来源 & 背景
- “朴素”的Attention思想
- Attention相关的有趣工作
- What's more
1. 问题来源 & 背景
最近做了非常非常久的多任务学习工作(或许后面会整理一下),在尝试到MMoE这个模型时,发现了一件有意思的事情。
我们知道,在MMoE模型中,专家层的下一层——Gate层的工作是针对不同的任务,对专家的输出进行加权求和,使得不同任务按照自己的需要获取不同专家的信息,最终目的应该是将不同专家提取到的特征用一种更加无损的方式融合起来。
MMoE如下图最右侧的C模型,Gate A的工作是对专家0,1,2的输出进行加权,并将加权之后的结果输出给Tower A,用于A任务后续计算Logit。
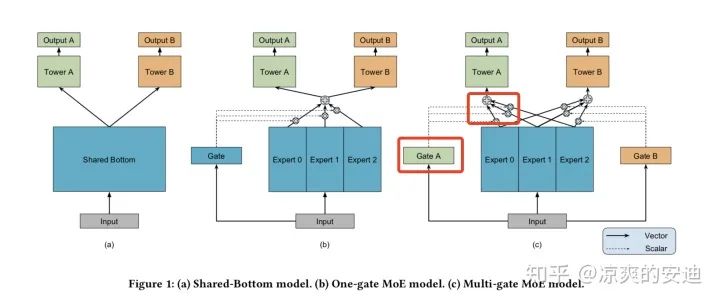
图1,MMoE模型结构,
在Gate A中采取了一种很有趣的方式来对专家0,1,2的方式进行加权融合:
- 专家0,1,2分别是从input处连接的全连接网络。
- 对于每个Tower(与Gate一一对应),从input处连接一个全连接网络(网络参数W的Size为input size * 3),并对这个全连接模块的输出进行Softmax。
- 将Softmax后的结果作为权重,分别乘以专家0,1,2的输出,作为加权融合后的结果,用作Tower A后续的操作。
读完Paper后,第一遍实现MMoE时并没有发现什么问题。后面和同事讨论,我们感觉Gate模块本质上就是一个对专家输出进行加权融合的模块,那这个模块为何不用主流的Attention来实现一下呢?
于是,我们修改了MMoE Gate层的结构,为每个任务随机设置了一个Context向量,作为Attention模块的Query,用Context与MMoE专家的输出计算相似度,根据相似度对于专家输出进行加权。修改后的模型,在我们的场景下,在多个任务上的评价指标居然高于原生的MMoE Gate层不少。
这件事情让我萌发了再深入思考一下Attention机制的想法!
2. “朴素”的Attention思想
如果用一句话来描述Attention机制的作用,你会怎么选择?
Attention机制的作用就是对信息进行更好地加权融合。
我们来看下这句话的关键词。其实就两个,第一,信息;第二,加权融合。
这两个词怎么来理解呢?
- “信息”。深度学习里的信息,无非就是特征,隐藏层的输出。
2. “加权融合”。这个也比较好理解,我们可能通过不同的方式获取了几组信息后,并非简单地将这几组信息直接进行concat或者直接相加,而是根据每组信息的重要性,为其赋予一个权重,再按照权重求和。
从这个角度上来看,Attention机制人如其名——注意力机制,表现了对信息重要性程度的关注。Attention作为深度学习的一个组件,其实是通过信息加权融合的方式,目的是为了让网络获取更好的特征表达。
Attention的例子在生活中比比皆是。
男生:多喝热水。
女生:你怎么就知道让我喝热水,啥也不是!
因为女生情绪比较激动,可能忽略了平时男生对她也是体贴的,导致一个临时事件
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 85
85











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









