







Kafka是什么
分布式的发布-订阅消息系统Kafka存在的意义
语言无关性:解除子系统耦合
异步处理:削峰填谷Kafka架构
架构1
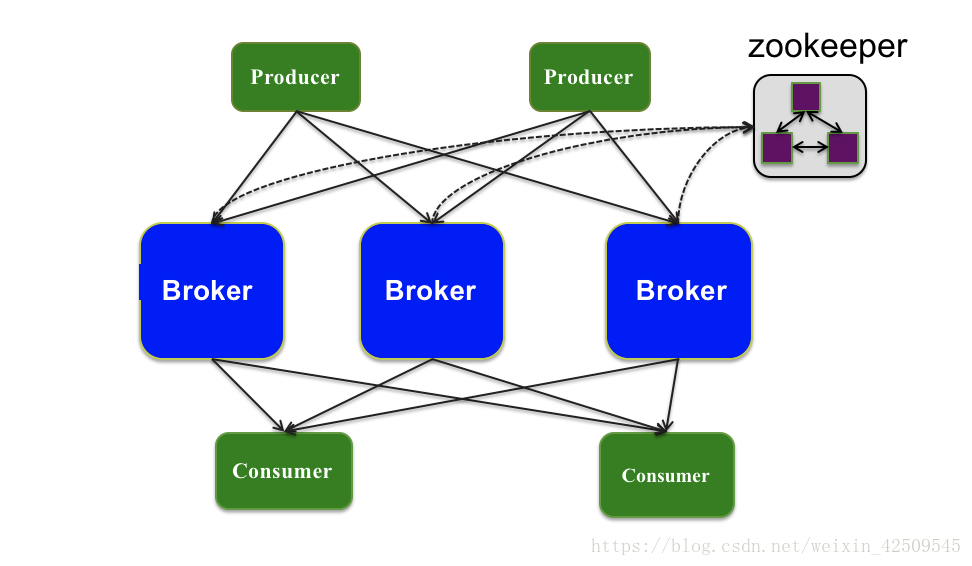
架构2
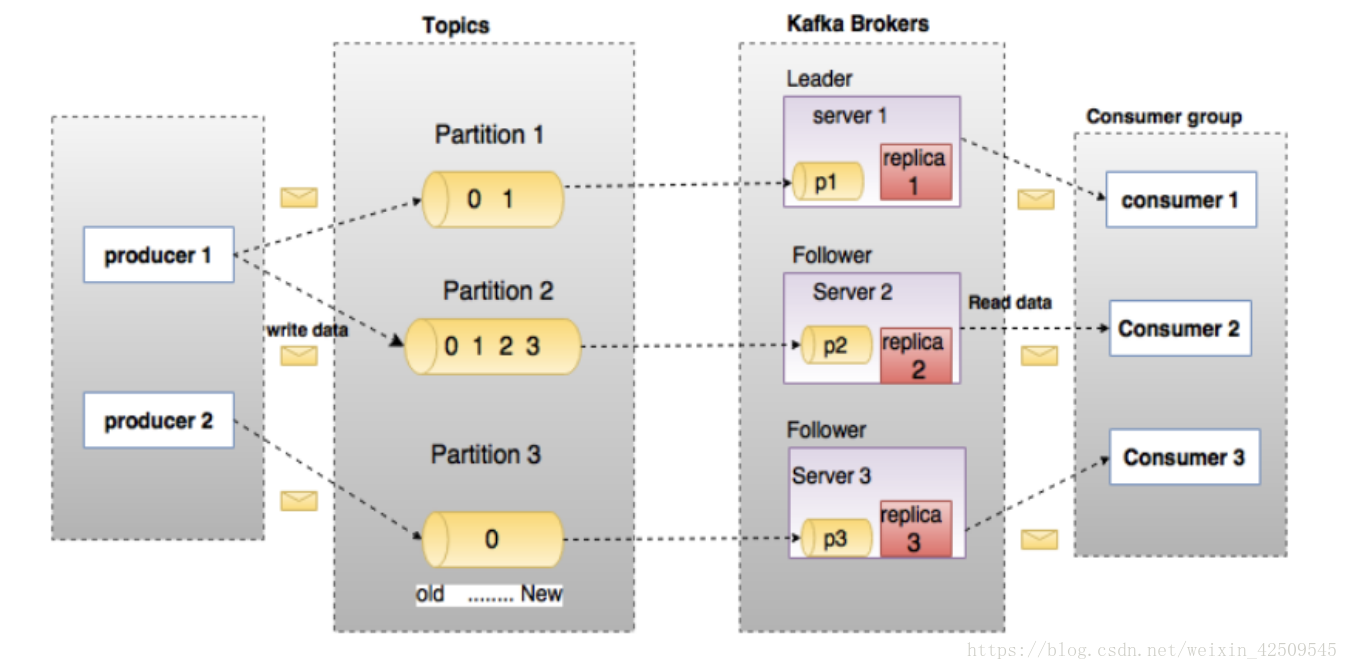
Kafka组件说明
Topic:如果将Kafka看作数据库,那么Topic就是一个表。
是一个逻辑上概念,对应的物理概念是Partition,其实就是一个目录,
目录下面是存储data的segment文件和存储offset的index文件
Producer:生产方开发Producer-Client,生产消息并发送至Topic中
Broker:可以视为起中介人作用的服务,
1. 负责从Producer接受Topic,并在规定时间内存储到磁盘
2. 负责将Topic发送给Consumer
3. 由zk负责管理,负责选举leader,其他则为follower
Consumer:消费方开发Consumer-Client,并从Topic中消费数据Topic创建
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic test
创建一个有3个分区,每个分区需分配3个副本,名为test的topicKafka是如何保证不丢失数据的
待定Kafka是如何保证不重复消费数据的
待定Kafka的broker是如何通知的
待定Kafka的Producer案例
Producer:生产方开发Producer-Client,生产消息并发送至Topic中
1.producer数据源在哪里?假设我需要读取hdfs上的user_pay.txt的内容
[bigdata@bigdata ~]$ start-dfs.sh
Starting namenodes on [bigdata]
bigdata: starting namenode, logging to /home/bigdata/hadoop-2.7.3/logs/hadoop-bigdata-namenode-bigdata.out
bigdata: starting datanode, logging to /home/bigdata/hadoop-2.7.3/logs/hadoop-bigdata-datanode-bigdata.out
[bigdata@bigdata ~]$ hdfs dfs -ls /alibaba
Found 2 items
-rw-r--r-- 1 bigdata supergroup 2296273496 2018-08-10 23:09 /alibaba/user_pay.txt
-rw-r--r-- 1 bigdata supergroup 183141282 2018-08-10 08:20 /alibaba/user_view.txt
====================================================================
2. producer目的地在哪里?当然是送入topic
====================================================================
3. topic如何构建:
3.1. 启动zk
[bigdata@bigdata kafka_2.11-0.10.1.0]$ pwd
/home/bigdata/kafka_2.11-0.10.1.0
[bigdata@bigdata kafka_2.11-0.10.1.0]$ bin/zookeeper-server-start.sh -daemon config/zookeeper.properties;jps
4146 QuorumPeerMain
4147 Jps
2856 NameNode
3161 SecondaryNameNode
2988 DataNode
[bigdata@bigdata kafka_2.11-0.10.1.0]$
-----------------------------------------------------------------------
3.2. 启动kafka
[bigdata@bigdata kafka_2.11-0.10.1.0]$ bin/kafka-server-start.sh -daemon config/server.properties #在这里设置broker的监听端口9092
[bigdata@bigdata kafka_2.11-0.10.1.0]$ jps
4146 QuorumPeerMain
4403 Kafka
2856 NameNode
3161 SecondaryNameNode
2988 DataNode
4460 Jps
[bigdata@bigdata kafka_2.11-0.10.1.0]$
-----------------------------------------------------------------------
3.3. topic创建
[bigdata@bigdata kafka_2.11-0.10.1.0]$ bin/kafka-topics.sh --create --zookeeper bigdata:2181 --replication-factor 1 --partitions 1 --topic user_pay
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic "user_pay".
#用kafka-topics.sh查看创建好的topic
[bigdata@bigdata kafka_2.11-0.10.1.0]$ bin/kafka-topics.sh --list --zookeeper bigdata:2181
log1
user_pay
#用zkCli.sh查看创建好的topic
[bigdata@bigdata kafka_2.11-0.10.1.0]$ zkCli.sh -server bigdata:2181
///中略///
[zk: bigdata:2181(CONNECTED) 0] ls /
[cluster, controller_epoch, controller, brokers, zookeeper, admin, isr_change_notification, consumers, config]
[zk: bigdata:2181(CONNECTED) 1] ls /brokers
[ids, topics, seqid]
[zk: bigdata:2181(CONNECTED) 2] ls /brokers/topics
[user_pay, log1]
[zk: bigdata:2181(CONNECTED) 3]
====================================================================
4. 编写HdfsApi
public class HdfsApi {
String url="/alibaba/";
// String url="/alibaba";
public HdfsApi(String filename){
this.url=url + filename;
}
public BufferedReader getReader(){
FileSystem fs=null ;
BufferedReader bufferedReader=null;
try {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://bigdata:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
Path myPath = new Path(url);
fs = myPath.getFileSystem(conf);
if(fs.exists(myPath)){
System.out.println("Reading from" + url + " on hdfs...");
FSDataInputStream in=fs.open(myPath);
bufferedReader=new BufferedReader(new InputStreamReader(in));
return bufferedReader;
}else{
System.out.println(url + "is not exists");
}
} catch (Exception e) {
System.out.println("Exception:" + e);
} finally {
// if(fs != null)
// try{
// fs.close();
// }catch (Exception e){
// e.printStackTrace();
// }
}
return bufferedReader;
}
}
====================================================================
5. 编写ProducerApi
public class TopicApi {
public Producer<String, String> getProducer()
{
Properties props = getConfig();
Producer<String, String> producer = new KafkaProducer<String, String>(props);
return producer;
}
// config
public Properties getConfig()
{
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
return props;
}
}
====================================================================
6. 使用hdfsApi从hdfs读出数据,使用ProducerApi组装成ProducerRecord,并送入Topic
public class UserPayProducer {
public static void main(String[] args) {
// String filename=args[0];
//hdfsreader
String filename="up.txt";
HdfsApi hdfsApi=new HdfsApi(filename);
BufferedReader hdfsReader=hdfsApi.getReader();
//kafkatopic
TopicApi kafkaApi=new TopicApi();
Producer kafkaProducer=kafkaApi.getProducer();
System.out.println("starting ok");
//hdfs-->kafakaTopic
String UserPayRecord=null;
try {
while ((UserPayRecord=hdfsReader.readLine())!=null){
String[] str= UserPayRecord.split(",");
ProducerRecord producerRecord=new ProducerRecord("user_pay",str[0],str[1]+","+str[2]);
kafkaProducer.send(producerRecord);
System.out.println("Sending record to the Topic of the user_pay...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
====================================================================
7. mvn package 打包成jar包
====================================================================
8. 在linux环境下启动并真正生产消息并送给borker
[bigdata@bigdata testdata]$ java -cp shops-flow-analysis-0.1.0-SNAPSHOT-jar-with-dependencies.jar com.arua.kafka.UserPayProducer
====================================================================
9. 见证结果(kafka存储格式不是用low的txt文档,cat自然乱码。)
/home/bigdata/kafka_2.11-0.10.1.0/kafka-logs/user_pay-0
[bigdata@bigdata user_pay-0]$ cat 00000000000000000000.log
6E�*��������221278701862,2015-12-25 17:00:005������������34342311862,2016-10-05 11:00:006a���������169552851862,2016-02-10 15:00:006ق��������137991281862,2016-01-13 14:00:006|Ǥ�������137991281862,2016-07-05 12:00:006�\-�������202448781862,2016-09-17 15:00:006�%���������202448781862,2016-05-29 16:00:004�R�w��������4384441862,2016-02-22 17:00:06Uj�*�������220031931862,2016-08-07 15:00:00 6��h��������202448781862,2016-04-17 16:00:00[bigdata@bigdata user_pay-0]$
Kafka的Consumer案例
详见笔者博客的关于Spark+Redis的博文













 19万+
19万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









