






一、概述
什么是散列表?散列表也被称为 hash表,它是一种用于以 常数平均时间执行插入、删除和查找的技术。其通过 关键字(key)来实现对数据的直接访问。关键字和数据的映射关系称为 散列函数又称 hash函数,记做 hash(x),我们把散列表的大小记做 tableSize。理想的散列表: 关键字被映射到tableSize个单元内,并且任意两个不同的关键字被映射到不同的单元 。事实上单元的数量有限,而关键字实际上是用不完的。 因此要找到一个散列函数,该函数要在单元之间均匀的分配关键字,这就是散列的基本想法。剩下的还有一个问题就是:当两个关键字散列到同一个单元的时候 ( 这叫做 冲突),应该如何解决这种冲突?二、散列函数
如果输入的关键字是整数,则一般合理的方法就是直接返回key%tableSize ( 即hash(x) = x%tableSize ),但如果关键字不是整数,比如说字符串那么以上的散列函数就不适合了,好的解决办法就是将字符串中字符的ASCII 码值加起来生成一个整数,然后在使用以上的散列函数,看过String源码的朋友应该注意到String类提供了一个方法叫做hashCode(),下面我们来看下这段源码
public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h; }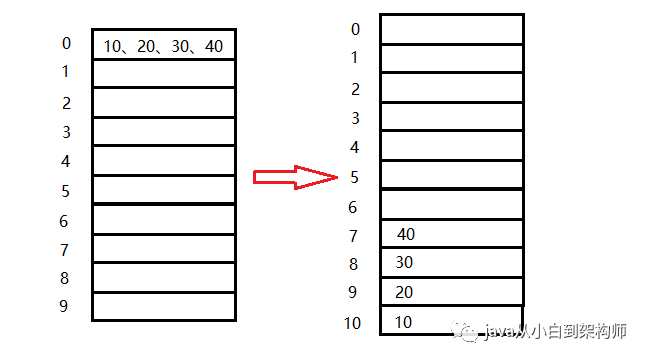
三、冲突解决策略
上面提到两个关键字被散列到同一个单元,我们必须找到一种策略,该策略可以很好的解决这种冲突 。第一种解决冲突的方法通常叫做 分离链接法,其做法是将散列到同一个单元的所有元素保留到一个表中,如下图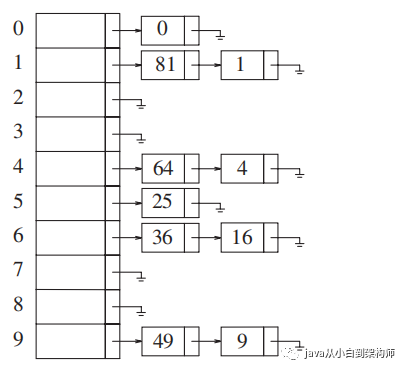
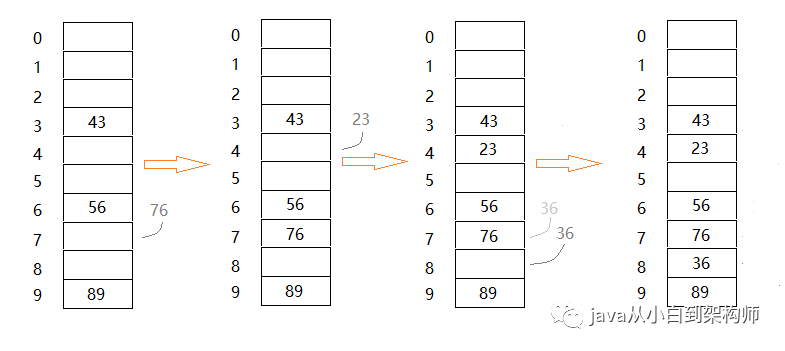
第二种解决冲突的方法可以用线性探测法。当产生冲突的时候该方法会相继探测逐个单元以查找出一个空单元,然后将该冲突值放入这个空的单元里。例如我们在tableSize=10的散列表相继插入【56,89,43,76,23,36】
三、代码实现
接下来我们选择其中一种解决冲突的方法进行代码实现,两种方法相比较,我们选择 分离链接法来进行代码实现。 (Java7的HashSet和HashMap是用分离链接散列实现的) 首先创建SeparateChainingHashTable类,定义好成员变量,添加构造器,根据上面的分析,我们应当保证散列表的大小始终为素数。我们定义了一个默认的容量为11,还定义一个有参构造器通过方法nextPrime(),将capacity转换为大于capacity的最小素数,如下代码public class SeparateChainingHashTable { private List[] entries; private int currentSize; // 默认散列表的容量 private static final int DEFAULT_CAPACITY = 11; SeparateChainingHashTable() { this(DEFAULT_CAPACITY); } SeparateChainingHashTable(int capacity) { this.entries = new List[nextPrime(capacity)]; }} /** * 添加元素 * * @param t */ public void add(T t) { if (contains(t)) return; // 获取关键字 int key = getKey(t); if (entries[key] == null) entries[key] = new LinkedList<>(); entries[key].add(t); if (++currentSize >= entries.length) { // 扩容 rehash(); } } /** * 判断是否包含元素 * * @param t * @return */ public boolean contains(T t) { List entry = entries[getKey(t)]; if (entry == null) return false; return entry.contains(t); } /** * 对当前散列表进行扩容 */ private void rehash() { List[] oldEntries = this.entries; int oldSize = this.entries.length; this.entries = new List[nextPrime(oldSize << 1)]; for (List oldEntry : oldEntries) { if (oldEntry == null) continue; for (T t : oldEntry) { add(t); } } currentSize = 0; } /** * 删除元素 * * @param t */ public void remove(T t) { if (!contains(t)) return; List entry = entries[getKey(t)]; entry.remove(t); currentSize--; }本章主要帮助大家梳理了散列的基本思想,介绍了常规的hash函数,以及解决hash冲突的几种方法,编写了分离链接法实现的散列表。当然散列的实现不止文章中说到的几种方法,例如:布谷鸟散列、跳房子散列等等,关于这些散列感兴趣的朋友可以去找资料详细了解一下。(如果有必要,后续我们会对这两种散列的实现进行分享)
实际工作中我们也经常接触散列这种数据结构,例如标准库中的HashMap、HashTable,在分布式系统中我们经常听到的一致性Hash算法等等,都涉及到了散列,由此可见hash的重要性。
感兴趣的读者朋友可以 关注本公众号,和我们一起学习探究。

本人因所学有限,如有错误之处,望请各位指正!














 203
203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









