






Hash表
Hash表也叫哈希表,它常常用于解决快速查找数据的问题。比如你想通过一个key查找对应的value,整个查找过程耗时非常短,而且是常数时间。数组可以用来作为一个简单的哈希表,其中的key就是数组的下标,value则是该下标对应的存储。然而,功能齐全哈希表还需要考虑元素增长的情况、不同的key有可能映射到相同的元素等等。哈希表常用于构建更加高级的数据结构,比如各大编程语言里常用的字典类型。
哈希表的key可以是整型、字符串、实数或复合类型。然而,用整型或浮点型作为key效率会很高,原因在于它们无需生成数组的索引,避免了没有必要的运算。
总之,如果你需要建立一对一关系,那么哈希表是最佳选择。本文将通过以下几方面来介绍哈希表:
- 定义
- 实现和操作
- 空间复杂度和时间复杂度
定义
In computing, a hash table (hash map) is a data structure that implements an associative array abstract data type, a structure that can map keys to values. A hash table uses a hash function to compute an index, also called a hash code, into an array of buckets or slots, from which the desired value can be found. During lookup, the key is hashed and the resulting hash indicates where the corresponding value is stored.
以上信息说明哈希表不具备线性结构特征,它能将key映射到value,这种映射是通过hash function来完成的,比如key传入给hash function最后会生成一个整型数字,也就是hash code,这个hash code就是数组的下标。示意图如下所示:
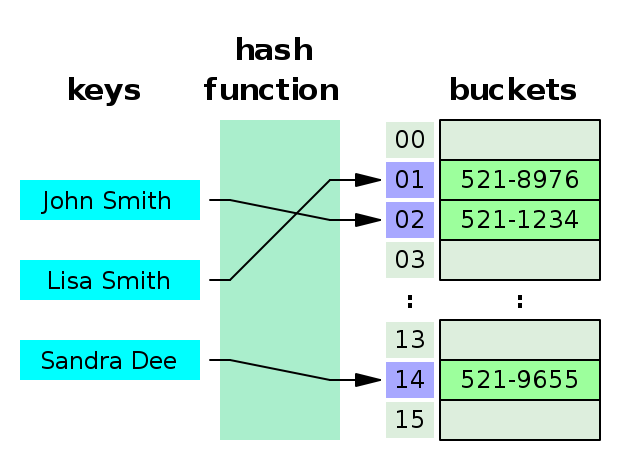
从上图可知,hash function扮演了重要的角色,它必须满足均匀分布的特性,其次它需要快速计算出hash code,否则会影响哈希表的性能。另外,上图右边的存储是一个bucket数组,数组中的每一个元素对应一个bucket,因此,当哈希表装满了元素之后,它需要新建一个更大的bucket数组,以便能存储更多的key, value,这就要求哈希表有一个rehash的过程,这个过程不仅要分配新的bucket数组,而且还要把之前的key重新计算hash code。为了避免大规模同时计算新的hash code,需要采用一些方法,比如仅在每一次更新操作的过程中重新计算新的hash code。因此,一个好的hash表需要考虑的因素非常多,在现实世界里,你需要结合问题的特点来设计更加高效的hash表。
解决了以上问题之后,你就能很高效地通过key来存取元素,因此,一个hash表至少需要提供以下几种操作:
- 设计hash function
- 通过key来存value
- 根据key来取value
- 选择rehash策略
实现和操作
实现一个哈希表的关键点有以下几点:
- 设计一个满足均匀分布的hash function
- 通过chaining或者probe方法解决key冲突的问题
- 如何根据元素的多少来增减哈希表的容量,也就是rehash
1)设计hash function
Hash函数的设计需要考虑应用场景。如果key是正整数,那么我们只需要将其映射到数组的索引;如果key是字符串,那么,我们可以使用密码学上的MD5函数来生成固定长度的哈希码,然后,根据哈希表的容量来生成数组索引。设计哈希函数的一个基本原则是让它生成均匀分布的哈希码。接下来,让我们来为类型为字符串的key设计一个好的hash function,如下所示:
def hash_function(self, key):
return hashlib.md5(key.encode()).digest()我们用到了Python自带的库hashlib,它提供了MD5函数,这种函数能够生成128-bits的数据,而且满足均匀分布的特性。
得到均匀分布的hash code之后,接下来就要根据当前的bucket来生成索引,如下所示:
def index(storage, hash_code):
return int.from_bytes(hash_code, 'big') & (len(storage) - 1)上面用到了位&操作,这种操作就决定了storage的长度必须是2^n,其中n是正整数,而且大于等于1。
2)使用chaining方法来解决冲突
接下来,我么选择拉链法(chaining)来解决key冲突的问题。这种方法会通常会借助单向链表数据结构或者红黑树,为了简单起见,我们选择单向链表来存储冲突的节点信息。比如下图的John Smith和Sandra Dee发生了冲突,它们被存储在152号bucket,这个bucket存放了一个单向链表,里面存放了2个链表节点。
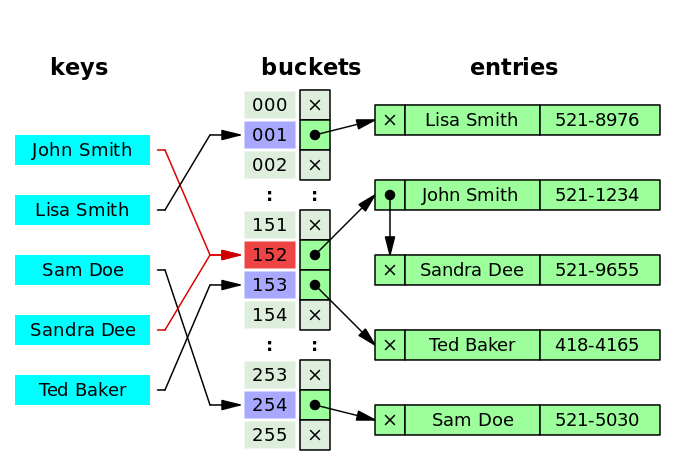
这种结构决定了key,value的存储方式,因此需要单独写2个方法来获取和修改key,value。如下所示:
# return 1 when insert, 0 when replace
def set(storage, key, value):
hash_code = hash_function(key)
idx = index(storage, hash_code)
return storage[idx].insert(key, value)
def search(storage, key):
hash_code = hash_function(key)
idx = index(storage, hash_code)
single_linked_list = storage[idx]
return single_linked_list.find(key)其中storage中的元素是SinglyLinkedListNode类型,它的定义可以在参考这篇文章。
3)rehash
如果哈希表里的元素是表容量的0.75倍以上,那么需要申请更大的容量,然后重新建立key,value,这个过程就是rehash。rehash的策略有很多种,常见的方法是在修改key,value的时候做一次rehash,这么做的好处是不影响哈希表的性能。这种rehash策略需要考虑2种场景:
- 当修改key,value,需要把已有的key,value移动到新的存储bucket
- 当增加新的key,value,直接将它们添加到新的存储bucket
对于第一种情况,你需要用到移除操作,因此,需要定义以下移除函数:
def remove(storage, key, value):
hash_code = hash_function(key)
idx = index(storage, hash_code)
removed_node = storage[idx].remove(key)
return removed_node以上函数的作用是:从指定的storage中移除某个key,value。
最后,需要将以上方法组合在一起,实现以下哈希表数据结构:
import hashlib
import singly_linked_list
class HashTable:
def __init__(self, number_of_buckets):
self.number_of_entries = 0
self.active_storage = [singly_linked_list.SinglyLinkedList() for i in range(number_of_buckets)]
self.back_end_storage = None
def _load_factor(self):
return self.number_of_entries / len(self.active_storage)
def __getitem__(self, key):
result = search(self.active_storage, key)
if result is None and self.back_end_storage is not None:
result = search(self.back_end_storage, key)
return result
def __setitem__(self, key, value):
should_rehash = self._load_factor() > 0.75
count_of_added_entry = 0 # the final value will either be 0 or 1
if should_rehash:
count_of_added_entry = self._rehash(key, value)
else:
count_of_added_entry = set(self.active_storage, key, value)
self.number_of_entries += count_of_added_entry
def _rehash(self, key, value):
from_storage = self.active_storage
if self.back_end_storage is None:
# first time to rehash
self.back_end_storage = [singly_linked_list.SinglyLinkedList() for i in range(len(self.active_storage) * 2)]
self.number_of_old_entries = self.number_of_entries
to_storage = self.back_end_storage
removed_node = remove(from_storage, key, value)
if removed_node is not None:
set(to_storage, removed_node.key, removed_node.value)
self.number_of_old_entries -= 1
if self.number_of_old_entries == 0:
self.active_storage = self.back_end_storage
self.back_end_storage = None
return 0
else:
set(to_storage, key, value)
return 1以上HashTable的用法如下所示:
if __name__ == '__main__':
my_hash = HashTable(8)
my_hash['abc'] = 1
my_hash['abc1'] = 2
print(my_hash['abc'])
print(my_hash['abc1'])空间复杂度和时间复杂度
哈希表是一种非常高效的数据结构,它常常用于更加高级的数据结构,比如C++中的map,Python中的dict,C#中的Dictionary。这类数据结构的特点是具有关联性,存取数据通常非常快,几乎在一个常量时间内完成。但是这类数据结构也会有一个致命的问题:无序。这种数据结构主要提供了以下几类操作:
__getitem__获取value__setitem__修改value
它们的时间复杂度与解决冲突的策略和哈希函数有关,一般情况下,以上2种方法的时间复杂度是O(1);正常情况下,空间复杂度是O(1),然而,当发生rehash的时候,时间复杂度就会变成O(n)。
以上就是关联数据结构HashTable的内容,如果你想获取完整的源码,那么可以到这里看看。接下来,让我们看看一些更加复杂的数据结构:堆














 546
546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









