






不同于标准的云负载均衡器,Kubernetes服务自己并不对底层应用执行健康检查。反之,服务通过检查集群的共享状态来判断pod是否准备就绪并能够处理请求。但是如何才能知道pod是否已准备好呢?
两种健康检查:存活性——应用是否正确启动;就绪性——应用是否准备好处理请求。
这两种健康检查对于服务的可恢复性而言是至关重要的。它们能确保流量都被路由到健康的微服务实例,而远离那些执行有问题或者完全不能执行的实例。
默认情况下,Kubernetes会对每个运行的pod执行轻量级的基于进程(个人理解是基于容器是否运行正常的检查,不知道此处是不是把容器当做一个进程来看,具体原理待研究)的存活检查。如果market-data服务中某个容器的存活检查失败,Kubernetes会尝试重新启动该容器(只要该容器的重启策略没有被设置为Never)。每个工作节点中的Kubelet进程负责执行该健康检查。这个进程会持续查询容器的运行时环境(比如Docker引擎)来确定是否需要重新启动一个容器。
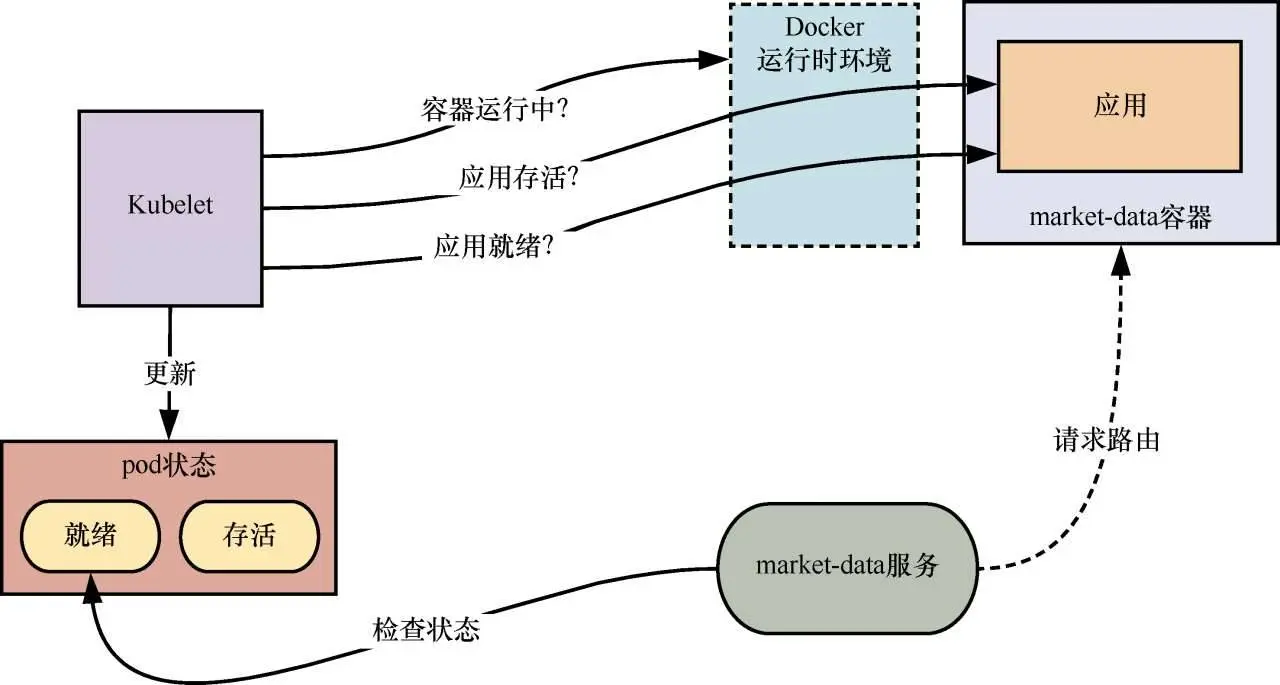
Kubernetes以指数退避调度算法来执行重启。如果某个pod在5min后没有存活,则它会被标记出来删除。如果某个复制集负责管理这个pod,那么控制器会尝试分配一个新的pod来保持所需的服务容量。
单凭这一点是不够的,因为微服务可能会遇到一些不会导致容器本身失败的故障场景:由请求饱和引起的死锁、底层资源超时或普通的编码错误。如果调度器不能识别此类场景,那么服务的性能可能会由于服务路由请求到没有响应的pod而下降,这可能导致级联故障。
为了避免这种情况,需要调度器不断检查容器中应用的状态,确保它处于存活状态并准备就绪。在Kubernetes中,可以通过配置探针来实现这一点,探针可以是HTTP GET请求、容器中执行的脚本或TCP套接字检查。
market-data-replica-set.yml中的存活探针
livenessProbe: --- 在8000端口配置一个存活探针以查询/ping接口
httpGet:
path: /ping
port: 8000
initialDelaySeconds: 10
readinessProbe:
path: /ping
port: 8000
initialDelaySeconds: 10
timeoutSeconds: 15 --- 在8000端口配置一个就绪探针查询/ping接口
再次使用kubectl来应用这一配置以更新复制集的状态。Kubernetes会尽最大能力使用这些探针来确保微服务实例的健康和活跃。在本例中,存活检查和就绪检查都是同一个端点,但是如果微服务有外部依赖(比如队列服务),确保服务的就绪检查就依赖于应用与那些依赖之间的联通性是有意义的。















 499
499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









