







文章目录
计量背景
计量就是使用数据回答因果问题,计量经济学的工具就是有条理的数据分析,同时辅之以统计推断。
最常用的计量工具如下:随机实验 、回归、工具变量、断点回归和双重差分。
接下来对每种计量工具进行说明。每一种工具背后都有庞大的知识体系,之后将慢慢补充每种方法的
细节和适用场景。
1、随机实验
1.1 随机实验介绍
以美国平价医疗法案为例,美国评价医疗法案强制美国人购买医疗保险,并用税收惩罚那些不愿购买医疗保险的人。为了考察政府在医疗卫生市场中是否发挥了恰当作用,其中一项实验从医疗保险对健康产生的因果效应切入。
现实情况是:美国人花在医疗保险上的钱比任何国家都多,但是美国人的健康状况却很糟糕。
美国没有全民保险计划。在美国的老年人可以享受老年医疗保险这一联邦保险计划,美国的穷人可以享受公共医疗补助,但是很多已经参加工作的人却长期得不到保险,这些工人很多时候是主动选择不参加雇主的保险计划,他们可以依靠医院急诊室这类机构,来满足他们的医疗需求,但是急诊室不能提供长期护理,不是治疗各种疾病的最佳场所。因此,得出的一个推断是,美国人糟糕的健康问题可能是因为没有政府强制的医疗保险,而强制的医疗保险往往会带来健康红利。
于是,据此提炼出一个简单的研究问题:针对同一个人,比较他在拥有保险和没有保险时的健康水平。
1.2 随机实验局限性-选择偏误
在揭示因果效应时,会遇到的一个问题之一是选择偏误,选择偏误的含义是对不同的样本,缺乏可比性的结果。比如说在分析是否购买保险对居民身体健康的影响因素时,不同人身体健康存在的固有差异,这种差异可能是因为他们自身的受教育程度不同,收入和就业情况也不同,在这些因素中,有一部分是可观测到的差异,但是还有很多是未被观测到的差异,于是计量学家开始面临第一个挑战:
消除那些因不可观测的差异造成的选择偏误。
1.3 解决选择偏误的方法-大样本随机分配
当样本属于不同的群组时,第一个想到的解决方法是:实验性随机分配。在大样本的前提下通过随机实验来减小选择偏误。
大数定律认为-当样本规模不断增加时,样本均值会越来越接近我们从中抽样的总体的均值。
当样本统计量的期望等于相应的总体参数(总体均值)时,就说它是均值的无偏估计量。
1.4 期望-均值和方差-变异性
因此,对来自随机实验或其他研究涉及的数据进行分析时,计量高手通常都会从检查处理组和控制组是否真的相似开始,这个检验称之为平衡性检验。即对两个组中的各个变量均值进行比较,如果除了主要自变量之外的其他控制变量均值接近,我们认为通过了平衡性检验。平衡性检验过程中,常用的统计量指标是-标准误,通过比较组间均值差和标准误之间的关系,来得出差异是否属于偶然差异。(大于两倍标准误的差异被认为是统计显著,统计显著的差异可能不是单纯由抽样过程中的偶然性导致,统计不显著的差异可能源于抽样过程中出现的变异)。
除了均值之外,还对样本的变异性感兴趣,对变异性的概括性度量是方差,方差描述了变量的分布情况,即变量的取值范围。注意的是不要混淆的变量的标准差和统计量的标准差。
1.5 t统计量和中心极限定理
中心极限定理认为,当样本容量足够大时,t统计量的分布会无限接近于正态分布。
2、回归
2.1 回归介绍
随机分配是真实的实验,但是在现实情况和现实的数据中,我们只能借助于计量工具来实现和真实实验一样的效果,最常见的工具是回归,也就是比较具有相同可观测特定的处理组和控制组。
基于回归进行因果推断的前提假设是,假设处理组和控制组在可观测的关键变量上都一样,此时看不见的因素导致的选择偏误可以得到消除。
回归的目的就是通过现有数据将处理变量和因变量联系起来,同时将控制变量包含到模型中,常见的回归方程是 Yi=α+βPi+γAi+ei。
其中α、β和γ就是希望确定的参数,以使得预测值和真实值尽可能接近。
其中通过最小化ei(残差-模型预测值和真实值之间的插值)的平方和来进一步确定方程的参数的方法,我们称之为OLS(普通最小二乘)估计。
2.2 回归分析案例
2.2.1 因变量为对数变量的回归结果解释
很多时候,我们会对因变量进行对数处理,以规范化因变量,这个时候我们对回归估计值的解读是百分比的变化,比如,一个模型中讨论学生就读于私立大学和公力大学对今后收入的影响,将是否是私立学校作为主要自变量,得出来该变量的系数是0.135,对这个结果的解读是**:私立大学学生获得的收入比其他学生高出14%。**
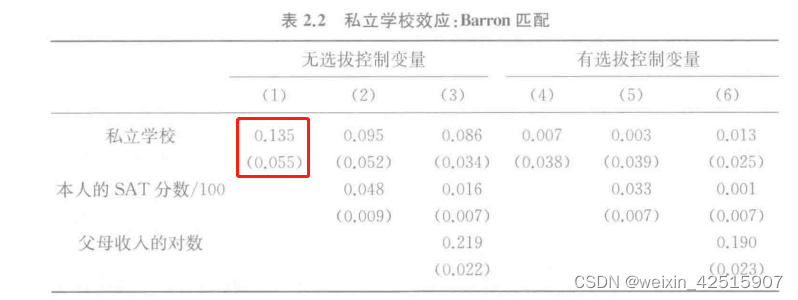
括号中的数值是估计值对应的标准误,在红色框中,0.135是对应标准误的2倍多,这说明私立大学与公立大学收入差的估计值不是偶然发现,也就是说私立大学的系数是显著的。
同时表格中还考虑了SAT分数作为控制变量-对学生的能力进行控制。SAT/100系数表示的是:当SAT分数每高100分,大约可以使收入提高4.8%。
后面的各个模型是在模型1的基础上加入了多种不同的控制变量,以消除更多的选择偏误,可以看到在模型5和模型6中,私立学校的系数变化已经不是很明显,这说明在添加了足够多的控制变量之后,我们真实的实验组和控制组之间的关系已经越来越接近真实的随机实验。模型5和模型6的结果中,估计值小于标准误的2倍,不显著,认为进入私立大学与否与未来收入无关。
但是即使我们控制了足够多的控制变量,我们仍然无法完全避免选择偏误,这部分无法避免的选择偏误我们称之为遗漏变量偏误。
2.2 回归的敏感性分析
因为我们不能确定给定的一组控制变量是否足以消除选择偏误,所以我们需要考虑回归结果对控制变量变化的敏感程度。当模型包含一组核心控制变量之后,无论模型中加入或者去除其他变量,得到的处理雄安用对此都不敏感,我们就说这个结果是稳健的。

















 681
681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









