







前文中提到如何将xls格式的数据读入stata并且将其转换为dta格式的数据,
向stata中加载数据并且转换为dta格式之后读取
1、简单描述性统计分析
在读入数据之后,我们在进行回归模型构建之前,往往需要对数据进行描述性统计分析,描述性统计分析的具体方法如下,示例使用的方法是summarize,也有其他的一些方法可以参考,它们输出的描述性统计的指标类型各不相同:
summarize coding tc ti_len ab_len au_num de_len if_oa py py2 if_fu nr pg country_len school_len if2
summarize后面的部分显示的就是各个变量名,分别对这些变量进行描述性统计分析
结果:
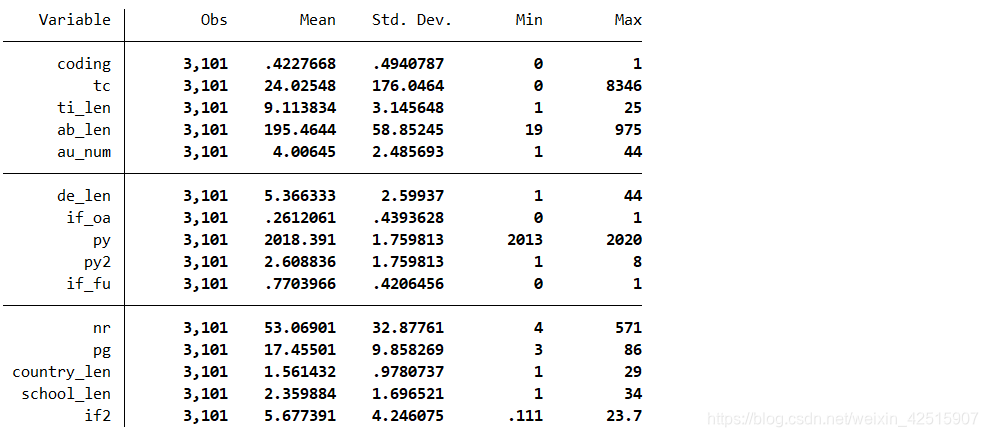
通过描述性统计分析,我们可以初步查看发现数据的基本特征,以及是否有异常值,以便更好地处理数据以拟合之后的模型。
2、bootstrap统计量-有置信区间
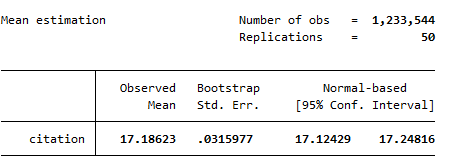
bootstrap抽样得到的统计量和相关置信区间,是很多高级期刊在论文图表中重点表现的内容,常常以误差棒的形式体现。
在Stata中实现的方式也较为简单,如下:
bootstrap: mean citation #得到citation的均值的抽样分布
输出结果中同时显示出95%的置信区间:

















 5116
5116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









