







上一篇讲的是逻辑回归分类算法的使用,但是还有很多问题没有解决,比如样本不均匀问题(1000万客户中999万都是低风险客户,那预测结果都是低风险客户,准确度ACC达99.9%,但训练出来的模型没有判别能力,区分不出高风险客户)、模型效果评价方法的总结(混淆矩阵、ROC曲线与AUC值、Accuracy模型准确度等指标)、不同分类模型的优缺点对比与适用情况(逻辑回归的两个前提假设是目标值服从伯努利分布、概率计算使用sigmoid函数、而且需要自己选定特征值等)等等,这些先记下来之后算法积累多一些以后写专题去归纳一下。[1]
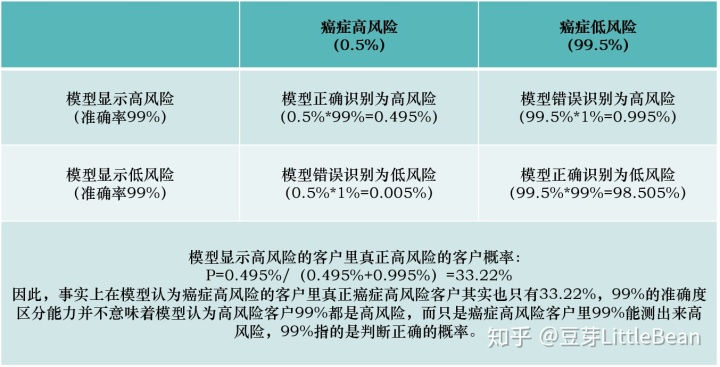
这一篇讲的是贝叶斯分类算法,贝叶斯的精髓是贝叶斯公式,即用先验概率去计算后验概率,通俗一点,还是拿保险公司举例,假设保险公司99.5%是癌症低风险客户,0.5%是癌症高风险客户,保险公司的模型区分准确度是99%(99.5%的癌症低风险客户中,保险公司能识别99%为低风险,1%会误判为高风险;0.5%的癌症高风险客户中99%识别为高风险,1%会误判为低风险)。乍一看,这个区分能力还挺强的,准确度能达到99%,但实际上效果真的是这样吗?这就是贝叶斯公式要解决的事情。
一、贝叶斯算法
1、贝叶斯公式的现实意义
上面的问题可以用贝叶斯公式分析,贝叶斯公式如下:
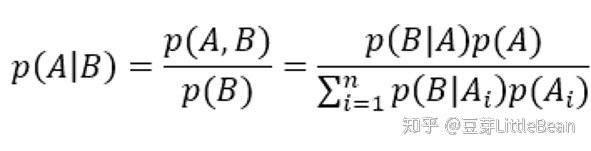
我们要计算模型识别高风险中,真正癌症高风险的概率,计算如下表:
2、贝叶斯分类算法原理
以上就是贝叶斯公式的思想,这一部分我们要说的是这个思想如何运用在分类算法中。
假设我们有如下样本:
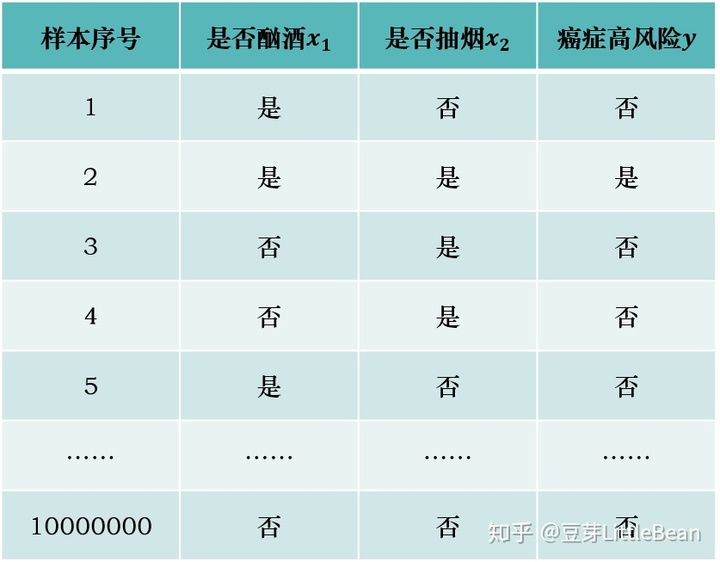
- 计算10,000,000个样本中癌症高风险的概率(先验概率:
=0.5%,
=99.5%);
- 计算第1个样本(
=是,
=否)的条件下, 是癌症低风险(
=否|
=是,
=否)和是癌症高风险(
=是|
=是,
=否)的概率,认为概率大的那一类为样本所属类别;
- 因为假设了
、
是互相独立的条件,因此条件概率就可以计算了;
3、贝叶斯分类算法的缺陷
贝叶斯分类算法要求
二、代码实现(数据为sklearn中的鸢尾花数据(iris))
## Step1:导入库
## 1、忽略警告处理
import warnings
warnings.filterwarnings('ignore')
import numpy as np
## 2、加载莺尾花数据集
from sklearn import datasets
# 3、导入高斯朴素贝叶斯分类器(训练数据是数值类型的数据,这里假设每个特征服从高斯分布,因此选择高斯朴素贝叶斯来进行分类计算)
from sklearn.naive_bayes import GaussianNB
# 如果训练数据是离散的,则使用基于类目特征的朴素贝叶斯CategoricalNB,相应的语句为:from sklearn.naive_bayes import CategoricalNB
from sklearn.model_selection import train_test_split
## Step2:数据导入分析
X, y = datasets.load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
## Step3: 模型训练
# 使用高斯朴素贝叶斯进行计算
clf = GaussianNB(var_smoothing=1e-8)
# 如果使用的是使用基于类目特征的朴素贝叶斯CategoricalNB,相应的语句为:clf = CategoricalNB(alpha=1)
clf.fit(X_train, y_train)
##Step4: 模型预测
# 评估
y_pred = clf.predict(X_test)
acc = np.sum(y_test == y_pred) / X_test.shape[0]
# 如果使用的是基于类目特征的朴素贝叶斯CategoricalNB,acc的计算可以直接使用语句:acc = clf.score(X_test, y_test)
print("Test Acc : %.3f" % acc)
# 预测
y_proba = clf.predict_proba(X_test[:1])
print(clf.predict(X_test[:1]))
print("预计的概率值:", y_proba)阿里云天池计划学习打卡:AI训练营机器学习-阿里云天池
参考
- ^注1:由于这个笔记是为了实用,中间梯度下降,损失函数选取等原理没有涉及,算是比较粗浅的入门使用笔记














 1226
1226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









