







 所谓的不平衡指的是不同类别的样本量差异非常大,或者少数样本代 表了业务的关键数据(少量样本更重要),需要对少量样本的模式有 很好的学习。样本类别分布不平衡主要出现在分类相关的建模问题上。 样本类别分布不均衡从数据规模上可以分为大数据分布不均衡和小数 据分布不均衡两种:大数据分布不均衡——整体数据规模较大,某类别样本占比较 小。例如拥有1000万条记录的数据集中,其中占比5万条的少 数分类样本便于属于这种情况。小数据分布不均衡——整体数据规模小,则某类别样本的数量 也少,这种情况下,由于少量样本数太少,
所谓的不平衡指的是不同类别的样本量差异非常大,或者少数样本代 表了业务的关键数据(少量样本更重要),需要对少量样本的模式有 很好的学习。样本类别分布不平衡主要出现在分类相关的建模问题上。 样本类别分布不均衡从数据规模上可以分为大数据分布不均衡和小数 据分布不均衡两种:大数据分布不均衡——整体数据规模较大,某类别样本占比较 小。例如拥有1000万条记录的数据集中,其中占比5万条的少 数分类样本便于属于这种情况。小数据分布不均衡——整体数据规模小,则某类别样本的数量 也少,这种情况下,由于少量样本数太少,
所谓的不平衡指的是不同类别的样本量差异非常大,或者少数样本代 表了业务的关键数据(少量样本更重要),需要对少量样本的模式有 很好的学习。样本类别分布不平衡主要出现在分类相关的建模问题上。 样本类别分布不均衡从数据规模上可以分为大数据分布不均衡和小数 据分布不均衡两种:
- 大数据分布不均衡——整体数据规模较大,某类别样本占比较 小。例如拥有1000万条记录的数据集中,其中占比5万条的少 数分类样本便于属于这种情况。
- 小数据分布不均衡——整体数据规模小,则某类别样本的数量 也少,这种情况下,由于少量样本数太少,很难提取特征进行 有/无监督算法学习,此时属于严重的小数据样本分布不均衡。 例如拥有100个样本,20个A类样本,80个B类样本。
工程过程中,应对样本不均衡问题常从以下三方面入手:
- 欠采样:在少量样本数量不影响模型训练的情况下,可以通过对多数样本 欠采样,实现少数样本和多数样本的均衡。
- 过采样:在少量样本数量不支撑模型训练的情况下,可以通过对少量样本 过采样,实现少数样本和多数样本的均衡。
- 模型算法:通过引入有倚重的模型算法,针对少量样本着重拟合,以提升 对少量样本特征的学习。
一、正采样和负采样
1. 负采样
a) 负采样——随机删除
可以以样本序号为种子,利用random.sample()进行采样
import numpy as np
import random
seed_idx = np.arange(0, 100, 1)
sample_idx = random.sample(seed_idx, 40)
b) 负采样——原型生成(Prototype generation)
PG算法主要是在原有样本的基础上生成新的样本来实现样本均衡:
-
1)以少量样本总数出发,确定均衡后多样本总数Nmaj
-
2)多量样本出发,利用k-means算法随机的计算k个多量样本的中心
-
3)认为k-means的中心点可以代表该样本簇的特征,以该中心点s‘代表该样本簇
-
4)重复2、3两步Nmaj次,生成新的多量样本集合
下图所示为三类共2000个样本点的集合,每个样本维度为2,label1个数为1861,label2个数为108,label3个数为31。利用PG算法完成数据均衡后,样本整体分布没有变化。

2. 过采样
随机复制, 简单复制少数样本形成多条记录,缺点是如果样本特征少可能导致过拟合
经过改进的过采样通过在少数类中加入随机噪声、干扰数据或者通过一定规则产生新的合成样本
-
SMOTE算法
通过从少量样本集合中筛选的样本xi和xj及对应的随机数0<λ<1,通过两个样本之间的关系来构建新的样本xn=xi+λ(xj-xi)由于SMOTE算法构建样本时,是随机的进行样本点的组 合和𝝀参数设置,因此会有以下2个问题:
- 在进行少量样本构造时,未考虑样本分布情况,对于少量样本比较稀 疏的区域,采用与少量样本比较密集的区域相同的概率进行构建,会使构建 的样本可能更接近于边界;只是简单的在同类近邻之间插值,并没有考虑少 数类样本周围多数类样本的分布情况。
- 当样本维度过高时,样本在空间上的分布会稀疏,由此可能使构建的 样本无法代表少量样本的特征。

-
衍生:SMOTEBoost、Borderline-SMOTE、Kmeans-SMOTE
- SMOTEBoost把SMOTE和Boost算法结合,在每一轮分类学习的过程中增加对少数类的样本的权重,使得基学习器(base learner)能更好的关注少数类样本;
- Borderline-SMOTE在构建样本时考虑少量样本周围的样本分布,选择少量样本集合——其邻居节点既有多量样本也有少量样本,且多量样本数不大于少量样本的点来构建新样本
- Kmeans-SMOTE包括聚类、过滤和过采样三步,利用Kmeans算法完成聚类后,进行样本簇过滤,在每个样本簇内利用SMOTE算法构建新样本。

通过比较不同算法得到的样本构造,可得以下结论:
-
利用样本构建的方法,可以得到新的少量样本;
-
利用不同算法构建的新样本在数量和分布上不同,其中利用SMOTE算法构建的新样本,由于没有考虑原始样本分布情况,构建的新 样本会受到“噪声”点的影响。同样ASASYN算法只考虑了分布密度而未考虑样本分布,构建的新样本也会受到“噪声”点的影响。 Borderline-SMOTE算法由于考虑了样本的分布,构建的新样本能够比较好的避免“噪声”点的影响。Kmeans-SMOTE算法由于要去寻找簇 后再构建新样本,可构建的新样本数量受限。
注:“噪声”点对应类别上属于少量样本,但是分布上比较靠近边界或者与多量样本混为一起。
二、模型算法
上述的过采样和欠采样都是从样本的层面去克服样本的不平衡,从算法层面来说,克服样本不平 衡。在现实任务中常会遇到这样的情况:不同类型的错误所造成的后果不同。
- 例如:在医疗诊断中,错误地把患者诊断为健康人与错误地把健康人诊断为患者,看起来都是犯 了“一次错误”,但是后者的影响是增加了进一步检查的麻烦,前者的后果却可能是丧失了拯救生命 的最佳时机;
- 再如,门禁系统错误地把可通行人员拦在门外,将使得用户体验不佳,但错误地把陌生人放进门 内,则会造成严重的安全事故;
- 在信用卡盗用检查中,将正常使用误认为是盗用,可能会使用户体验不佳,但是将盗用误认为是 正常使用,会使用户承受巨大的损失。
为了权衡不同类型错误所造成的不同损失,可为错误赋予“非均等代价” (unequal cost)。
-
模型算法 – Cost Sensitive算法
-
模型算法 – MetaCost算法
-
模型算法 – Focal Loss
1. 权重设置
在训练的时候给损失函数直接设定一定的比例,使得算法能够对小类数据更多的注意力。例如在深度学习中,做一个3分类任务,标签a、b、c的样本比例为1:1:8。在我们的交叉熵损失函数中就可以用类似这样的权重设置:
torch.nn.CrossEntropyLoss(weight=torch.from_numpy(np.array([8,8,1])).float().to(device))
2. 新的损失函数——Focal Loss
- 总述
Focal loss主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题。该损失函数降低了大量简单负样本在训练中所占的权重,也可理解为一种困难样本挖掘。
2. 损失函数形式
Focal loss是在交叉熵损失函数基础上进行的修改,首先回顾二分类交叉上损失:
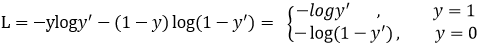
y ′ y' y′是经过激活函数的输出,所以在0-1之间。可见普通的交叉熵对于正样本而言,输出概率越大损失越小。对于负样本而言,输出概率越小则损失越小。此时的损失函数在大量简单样本的迭代过程中比较缓慢且可能无法优化至最优。那么Focal loss是怎么改进的呢?
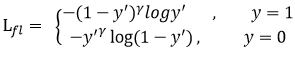
首先在原有的基础上加了一个因子,其中gamma>0使得减少易分类样本的损失。使得更关注于困难的、错分的样本。
例如gamma为2,对于正类样本而言,预测结果为0.95肯定是简单样本,所以(1-0.95)的gamma次方就会很小,这时损失函数值就变得更小。而预测概率为0.3的样本其损失相对很大。对于负类样本而言同样,预测0.1的结果应当远比预测0.7的样本损失值要小得多。对于预测概率为0.5时,损失只减少了0.25倍,所以更加关注于这种难以区分的样本。这样减少了简单样本的影响,大量预测概率很小的样本叠加起来后的效应才可能比较有效。
此外,加入平衡因子alpha,用来平衡正负样本本身的比例不均:文中alpha取0.25,即正样本要比负样本占比小,这是因为负例易分。
只添加alpha虽然可以平衡正负样本的重要性,但是无法解决简单与困难样本的问题。
gamma调节简单样本权重降低的速率,当gamma为0时即为交叉熵损失函数,当gamma增加时,调整因子的影响也在增加。实验发现gamma为2是最优。
https://github.com/yatengLG/Focal-Loss-Pytorch/blob/master/Focal_Loss.py,该作者的github上有使用例子。
import torch
from torch import nn
from torch.nn import functional as F
import time
class focal_loss(nn.Module):
"""
需要保证每个batch的长度一样,不然会报错。
"""
def __init__(self,alpha=0.25,gamma = 2, num_classes = 2, size_average =True):
"""
focal_loss损失函数, -α(1-yi)**γ *ce_loss(xi,yi) = -α(1-yi)**γ * log(yi)
:param alpha:
:param gamma:
:param num_classes:
:param size_average:
"""
super(focal_loss, self).__init__()
self.size_average = size_average
if isinstance(alpha,list):
# α可以以list方式输入,size:[num_classes] 用于对不同类别精细地赋予权重
assert len(alpha) == num_classes
print("Focal_loss alpha = {},对每一类权重进行精细化赋值".format(alpha))
self.alpha = torch.tensor(alpha)
else:
assert alpha<1 #如果α为一个常数,则降低第一类的影响
print("--- Focal_loss alpha = {},将对背景类或者大类负样本进行权重衰减".format(alpha))
self.alpha = torch.zeros(num_classes)
self.alpha[0] += alpha
self.alpha[1:] += (1-alpha)
self.gamma = gamma
def forward(self, preds,labels):
"""
focal_loss损失计算
:param preds: 预测类别. size:[B,N,C] or [B,C] B:batch N:检测框数目 C:类别数
:param labels: 实际类别. size:[B,N] or [B]
:return:
"""
preds = preds.view(-1, preds.size(-1))
self.alpha  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1222
1222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









