







 本文深入探讨了MongoDB的事务模型,包括单行一致性保证的实现,如通过OperationContext、RecoveryUnit和WriteUnitOfWork来封装wiredTiger层的事务。分析了MongoDB的查询操作事务隔离级别,指出默认使用Snapshot Isolation,但在YieldPolicy的影响下,查询可能降级为Read-Committed隔离级别。此外,文章提到了表记录数在异常恢复后可能出现的不一致问题,这是为了避免写放大的权衡结果。
本文深入探讨了MongoDB的事务模型,包括单行一致性保证的实现,如通过OperationContext、RecoveryUnit和WriteUnitOfWork来封装wiredTiger层的事务。分析了MongoDB的查询操作事务隔离级别,指出默认使用Snapshot Isolation,但在YieldPolicy的影响下,查询可能降级为Read-Committed隔离级别。此外,文章提到了表记录数在异常恢复后可能出现的不一致问题,这是为了避免写放大的权衡结果。
本文基于MongoDB 3.6,对于Mongodb上层事务中会让人困惑的几点进行源码层面的分析
mongodb 的写操作(insert/update/delete)提供的“单行一致性”的具体含义,如何做到的?
为何db.coll.count()在宕机崩溃后经常就不准了。
mongodb 查询操作的事务隔离级别。
写操作的事务性
MongoDB的数据组织
在了解写操作的事务性之前,需要先了解mongo层的每一个table,是如何与wiredtiger层的table(btree)对应的。mongo层一个最简单的table包含一个 ObjectId(_id) 索引。_id类似于Mysql中主键的概念
rs1:PRIMARY> db.abc.getIndexes()
[
{
"v" : 1,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "test.abc"
}
]
但是mongo中并不会将_id索引与行内容存放在一起(即没有聚簇索引的概念)。取而代之的,mongodb将索引与数据分开存放,通过RecordId进行间接引用。 举例一张包含两个索引(_id 和 name)的表,在wt层将有三张表与其对应。通过name索引找到行记录的过程为:先通过name->Record的索引找到RecordId,再通过RecordId->RowData的索引找到记录内容。
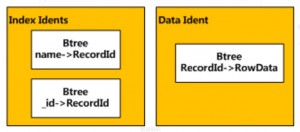
此外,一个Mongodb实例还包含一张记录对每一行的写操作的表local.oplog.rs, 该表主要用于复制(primary-secondary replication)。每一次(对实例中任何一张表的任何一行的)更新操作,都会产生唯一的一条oplog,记录在local.oplog.rs表里。
理解单行事务
mongodb对某一行的写操作,会产生三个动作
对wt层的数据段btree(上图中的Data Ident)执行写操作
对wt层索引段的每个索引btree执行写操作
对oplog表执行写操作
mongodb的单行事务,说的是:对数据,索引,oplog这三者的更新是原子的。不存在索引段中的某个RecordId,在数据段中找不到,也不存在一条记录的更改被应用,但是没有记录到oplog中, 反之亦然。
从下面的代码可以看到,一个插入操作,更新数据,索引,以及Oplog的过程。
collection_impl.cpp
332 Status CollectionImpl::insertDocuments(OperationContext* opCtx)
370 Status status = _insertDocuments(opCtx, begin, end, enforceQuota, opDebug); // 更新数据和索引
375 getGlobalServiceContext()->getOpObserver()->onInserts(opCtx, ns(), uuid(), begin, end, fromMigrate); // 更新Oplog
380 return Status::OK();
381 }
452 Status CollectionImpl::_insertDocuments(OperationContext* opCtx)
489 _recordStore->insertRecords(opCtx, &records, ×tamps, _enforceQuota(enforceQuota)); // 更新数据
493 std::vector bsonRecords;
495 int recordIndex = 0;
496 for (auto it = begin; it != end; it++) {
497 RecordId loc = records[recordIndex++].id;
501 BsonRecord bsonRecord = {loc, &(it->doc)};
502 bsonRecords.push_back(bsonRecord);
503 }
505 int64_t keysInserted;
506 status = _indexCatalog.indexRecords(opCtx, bsonRecords, &keysInserted); // 更新所有索引
511 return status;
512 }
单行事务的实现
OperationContext与RecoveryUnit
客户端的每个请求(insert/update/delete/find/getmore),会生成一个唯一的OperationContext记录执行的上下文,OperationContext从请求解析时创建,到请求执行完成时释放。一般情况下,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 778
778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









