







文章目录
写在前面:《基于语义相似的水文时间序列相似性挖掘》;期刊:《水文》;主办单位:水利部水文局、水利部水利信息中心;月刊;中文核心期刊;
作者:朱跃龙,博士生导师

1 摘要
- 利用数据挖掘技术,从长期观测的数据序列中发现蕴藏的规律,是当前研究热点之一。
- 相似性挖掘是时间序列挖掘的基础
算法步骤安排:
(1) 首先利用小波变换将时间序列进行平滑处理;
(2) 在此基础上,进行极值点分段并符号化,每个符号代表一种语义模式,从而选取语义相似的子序列作为候选集;
(3)将候选集中子序列,通过动态时间弯曲距离进行精确匹配从而得到相似子序列(以太湖流域大浦口站水位数据为例),
实验证明,该方法能够在大幅度降低时间复杂度的基础上较准确地查找出相似子序列。
2 引言
-
时间序列数据挖掘,主要包括相似性分析、关联规则挖掘、模式发现、预测和周期分析等几个方面,而相似性挖掘是其中的一个重要课题,它是聚类、分类、关联规则发现以及周期分析的基础。
-
水文时间序列数据挖掘,可以用于雨洪过程预测、环境演变分析、水文过程规律发现等。
2.1 现有研究
- 简单综述
时间序列相似性研究,最早开始于Agrawal R提出的基于傅立叶变换的方法,之后逐渐又有离散小波
变换、符号化表示、分段聚集近似、分段线性变换等方法的提出,这些方法各有所长,分别适应于不同的应用领域。
- 相似性研究有两个点:对序列数据降维、定义相似度量函数
目前的研究中,上述的方法主要用于对时间序列数据变换的处理过程以达到降维的目的,而相似性度量问题也是相似性研究中的一个重要课题。主要方法有欧氏距离、动态时间弯曲距离(DTW)、斜率距离、最长公共字串,以及在此基础上的各种变形。
这些度量方法各有所长,也有各自的缺点,目前应用的最多的是动态时间弯曲距离(DTW)
2.2 本文的研究
-
引入语义的相关概念,提出一种基于语义相似的水文时间序列相似性挖掘方法。
-
首先,对水文时间序列进行小波变换,在此基础上进行极值点分段,并符号化。【创新点:先对序列进行小波变换,然后极值点分段(涉及到序列分段的概念),然后加入了一个符号化的概念】
-
分别理解各种符号的语义模式,找出所有与查询序列语义模式符号序列相似的子序列作为候选集【我倒要好好学习一下,这个是怎么理解各个符号的语义模式的!】
-
最后,分别对候选集中的序列,与原序列 都采用极值点分段,然后使用 DTW 距离匹配。
也就是说:先用语义符号相似匹配,筛除语义不同的子序列,然后根据DTW进行精确匹配。
- 文章的数据集:太湖流域大浦口站水位数据,对该方法进行验证。该方法不但能有效地降低 时间复杂度,而且还具有较好的准确性。
3 基于语义相似的水文时间序列相似性挖掘
3.1 什么是语义
- 语义就是数据的含义;语义可以简单看作是数据所对应的,现实世界中的事物所代表的含义,以及这些含义之间的关系;
- 数据就是符号;
3.2 小波变换
- 保留能够体现整体变化趋势的 局部极值点信息,而序列中的短期波动会影响对数据的处理,所以平滑处理是十分必要的。
注意:130d就是130天,d是单位

- 从下图可以看出,小波变换能够保持原有的整体变换趋势。
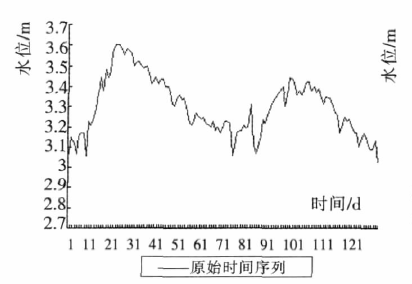
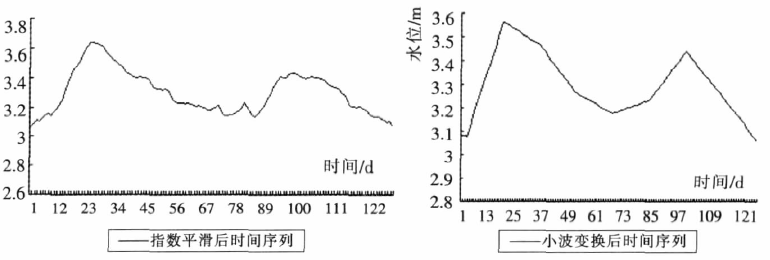
3.3 水文时间序列语义模式表示
- 在小波变换的基础上进行极值点分段

3.3.1 极值点线性分段表示
- 构建一个“新的时间序列”,用原时间序列的极值点构成

3.3.2 基于小波变换的时间序列语义模式表示

4 实验验证
在水文领域,长期的观测积累了大量的水文数据,其中蕴涵着重要的水文规律。面对如此海量和复杂的水文数据,数据挖掘技术在处理水文领域复杂问题的过程中发挥了越来越重要的作用。
其中,文时间序列的相似性分析是水文数据挖掘中最基本、最重要的技术之一,它在水文领域最为直接的应用是回答防汛指挥中经常会问到的“当前水文过程相当于历史上哪一时期的同类过程”等问题。
因而水文时间序列相似性的研究在洪水预报、防洪调度等方面有着重要的现实意义。
本节将以太湖水位数据为研究对象,验证基于语义相似的水文时间序列相似性挖掘方法的可行性和有效性。
4.1 数据部分
-
太湖流域大浦口站点,1955年-2005年,共48年的水位数据。
【也就是单个站点,考虑其水位数据,水位数据是连续的,而雨量数据是离散的。】 -
指的注意的是,水位数据是每小时记录一次,因此48年的水位数据是非常庞大的!
-
作者是考虑的在一元序列中,查找相似序列。
4.2 对比实验
- 实验1,采用
DTW_EP方法
这种方法首先对数据采用极值点分段,然后利用DTW距离进行相似性度量。是一种比较基础流行的方法,经常用作对比实验。(名字就是自己指定的,没有其他含义)
- 实验2,采用
DTW_SS方法
这种方法就是文章中提出的,先对序列做小波变化,使得序列更加平滑的同时保留重要极值点;然后使用极值点分段;然后对所有序列都进行符号化表示;然后根据符号化后的序列进行匹配,筛除语义不相似的序列;最后对于筛选出的序列,使用DTW进行精确匹配,得到最终的答案。
4.2.1 对比实验结果1
- 随着数据集增加,DTW_SS能够很好的保持一个较低的时间复杂度。
- 而DTW_EP 就会产生爆炸增长!
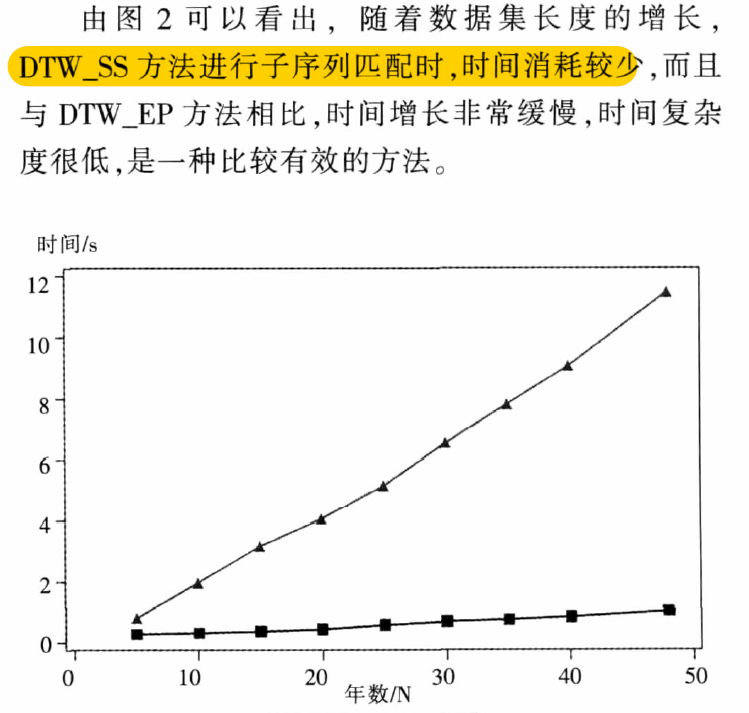
4.2.2 对比实验结果2
原序列(也可以叫做查询序列)—— 1984年6月1日~8月1日,长度为62
Query_len = 62
分别用 DTW_EP 方法 、 DTW_SS 方法 进行子序列匹配,分别找出5个相似的子序列进行输出。
- 输出结果:
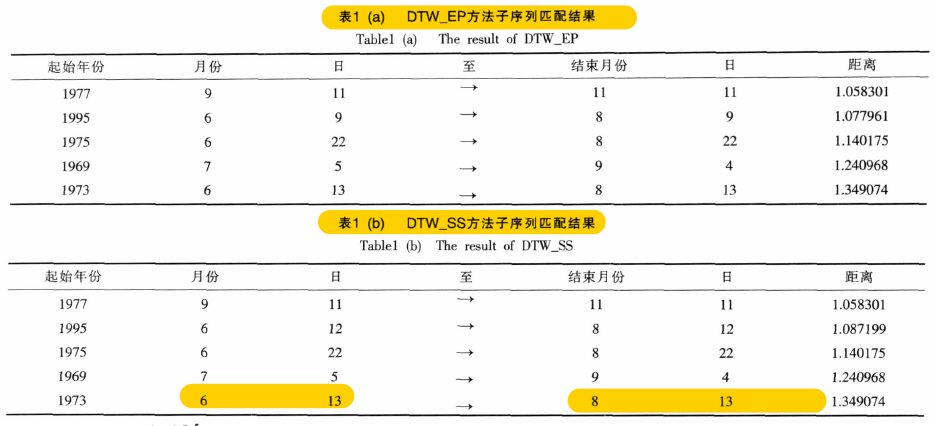
- 分析结果:
看到结果有着很大的相似度,但是细想一下也觉得非常合理。因为作者提出的方法,只是提供了一个筛选思路以减少计算复杂度,而核心方法:根据极值点分段+DTW距离,是没有改变的!
所以说,两种算法结果相似是非常合理的。
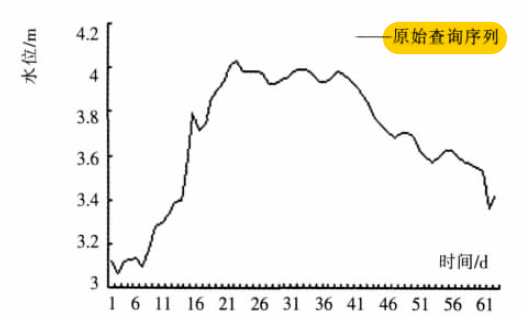
原始序列(长度=62)如下图:
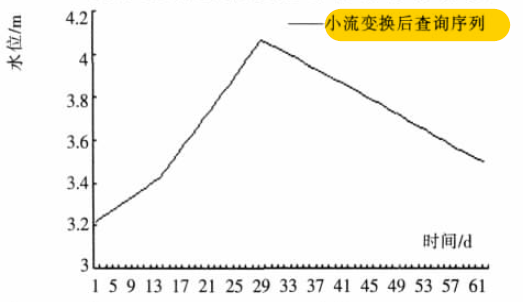
小波变换后如下图:(很显然符号表示是{UD})
三个相似度最高的序列:
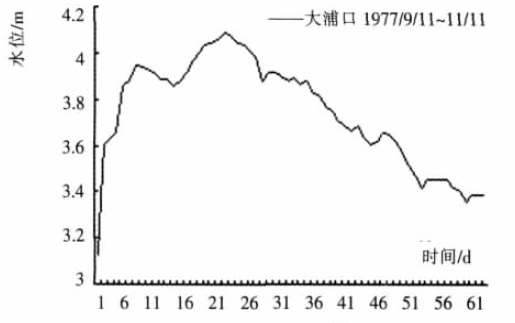

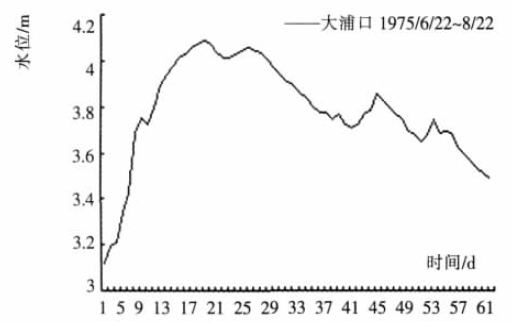
说实话吧,我觉得最后一个图片看走势,相似度应该是最高的。第一个图片的相似度反而没有那么高!因为原序列在时间点11之前,水位保持在3.2mm波动,而第一张图在时间点11时,已经接近峰值4mm左右
我不是很明白这个点!!!
因为到了最后匹配,还是用的是DTW算法呀,那么这个地方应该是DTW的问题了…= =
4.3 说明小波变换的重要性
以数据密度高的 1973~1977年5年数据为例,下图展示了这五年水位的原始时间序列、以及其小波变换后时间序列。
可以看出时间序列经小波变换后平滑掉了原始序列中的短期波动,而保留了体现整体变化趋势的重要极值点信息。
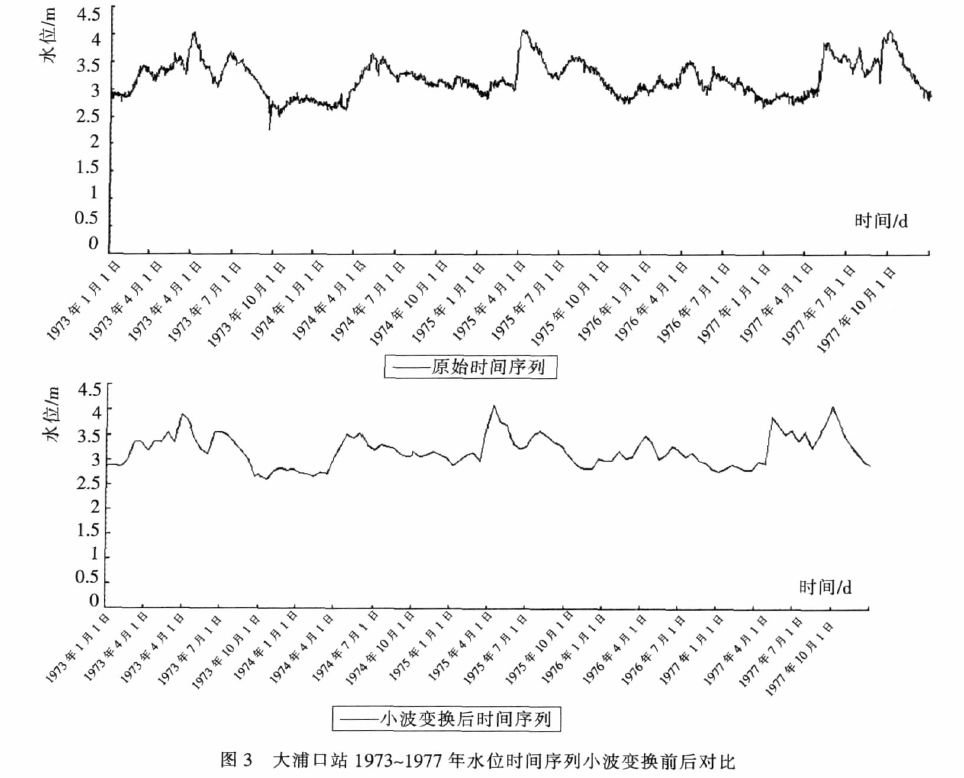
- 因此证明了,小波变换这一步骤是必要的,而且对于去除短期波动、保留更加重要的极值信息 有很大帮助!
5 总结
总之,利用DTW_ SS方法进行一元子序列匹配相似性查询时,与DTW_ EP方法查询效果相当,而在计算时间上DTW_ ss方法明显优于DTW_EP 方法。
因而利用基于语义相似的水文时间序列DTW距离度量相似性挖掘是一种时间开销小的方法。
















 946
946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









