







文章目录
1 解决过程【成功】
- 源代码如下:
import pandas as pd
from sklearn.preprocessing import StandardScaler
# 1. 导入数据
def load_data() -> pd.DataFrame:
data = pd.read_excel('data3.xlsx')
print(data)
data.columns = ['BillingDate', 'VolumnHL'] # 修改一下属性名
print("======================")
print(data)
return data
# load_data()
# 2. 归一化(可以帮助模型更快拟合)
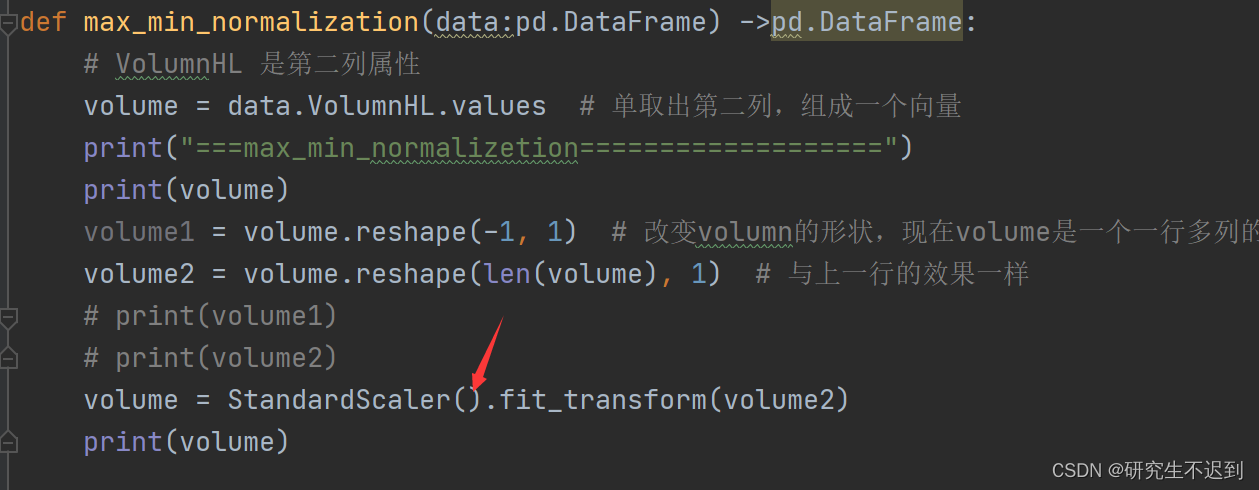
def max_min_normalization(data:pd.DataFrame) ->pd.DataFrame:
# VolumnHL 是第二列属性
volume = data.VolumnHL.values # 单取出第二列,组成一个向量
print("===max_min_normalizetion===================")
print(volume)
volume1 = volume.reshape(-1, 1) # 改变volumn的形状,现在volume是一个一行多列的向量,改成多行一列的向量
volume2 = volume.reshape(len(volume), 1) # 与上一行的效果一样
# print(volume1)
# print(volume2)
volume = StandardScaler.fit_transform(volume2)
print(volume)
data = load_data()
max_min_normalization(data)
- 输出的报错信息:

- 解决:就是少了一个括号!!
- 当然,在很多代码中,还有很多教程喜欢这样去写:
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
- 总而言之就是
StanderScaler后面的()千万不要忘记!否则报错之后很难排查出来!
2 学习Sklearn之数据预处理——StandardScaler
2.1 数据处理——标准化、归一化
-
数据标准化和归一化,都属于数据特征无量纲的一种方式。
【“无量纲”——将不同规格的数据转换都统一规格,或不同分布的数据转换到某个特定分布的需求】 -
特别是对于需要计算梯度和矩阵的模型(例如逻辑回归中通过梯度下降求解损失函数),无量纲化之后的数据特征对于模型求解有加速作用!
-
在k近邻、聚类算法中,需要计算距离时,使用无量纲化可以提升模型精度,避免异常值对整体计算造成的影响。
-
中心化处理:让所有记录减去一个固定值,即让数据样本平移到某个位置;
-
缩放处理:通过除以某一个固定值,将数据固定在某个范围之内!
2.2 为什么要归一化?
- 归一化后加快了梯度下降求最优解的速度;
如果机器学习模型使用梯度下降Q法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。 - 归一化有可能提高精度;
一些分类器需要计算样本之间的距离(如欧氏距离Q),例如KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(此如这时实际情况是值域范围小的特征更重要)。
2.3 归一化的适用范围
- 概率模型(树型模型)不需要做归一化
2.4 归一化公式
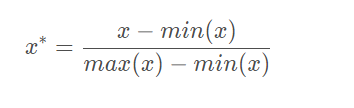
- Normalization和Min-Max Scaling都是数据归一化:数据x按照最小值中心化之后,再按极差(最大值-最小值)进行缩放,最终会被收敛到[0,1]之间!
2.5 标准化公式
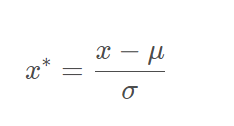
- 标准化:数据x按照均值中心化之后,再按标准差缩放,数据就会服从均值为0,方差为1的标准正态分布,这个过程就叫做数据标准化。
如果本篇文章对你有帮助的话,麻烦收藏+点赞+关注我哦!
3 标准化和归一化区别?
- 首先明确,标准化和归一化都不会改变数据的分布。
- 归一化会严格限制数据变化后的范围,默认是[0,1]
- 标准化则没有严格的区间,变化之后的数据没有范围,只是数据整体的均值为0,标准差为1
4 数据处理时的选择
- 在大多数机器学习算法中,因为
归一化MinMaxScaler对异常值敏感,所以都会选择标准化StandardScaler进行特征缩放,例如聚类、逻辑回归、支持向量机、PCA算法等等。 - 如果在缩放时,不涉及距离、梯度等的计算,并且对数据的范围有严格要求,就可以使用归一化进行缩放。















 3035
3035











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









