







本文讲梯度下降(Gradient Descent)前先看看利用梯度下降法进行监督学习(例如分类、回归等)的一般步骤:
1, 定义损失函数(Loss Function)
2, 信息流forward propagation,直到输出端
3, 误差信号back propagation。采用“链式法则”,求损失函数关于参数Θ的梯度
4, 利用最优化方法(比如梯度下降法),进行参数更新
5, 重复步骤2、3、4,直到收敛为止
所谓损失函数,就是一个描述实际输出值和期望输出值之间落差的函数。有多种损失函数的定义方法,常见的有均方误差(error of mean square)、最大似然误差(maximum likelihood estimate)、最大后验概率(maximum posterior probability)、交叉熵损失函数(cross entropy loss)。本文就以均方误差作为损失函数讲讲梯度下降的算法原理以及用其解决线性回归问题。在监督学习下,对于一个样本,它的特征记为x(如果是多个特征,x表示特征向量),期望输出记为t(t为target的缩写),实际输出记为o(o为output的缩写)。两者之间的误差e可用下式表达(为了节省时间,各种算式就用手写的了):
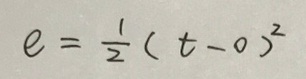
前面的系数1/2主要是为了在求导时消掉差值的平方项2。如果在训练集中有n个样本,可用E来表示所有样本的误差总和,并用其大小来度量模型的误差程度,如下式所示:
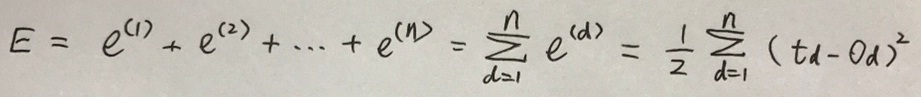
对于第d个实例的输出可记为下式:
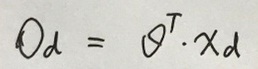
对于特定的训练数据集而言, 只有Θ是变量,所以E就可以表示成Θ的函数,如下式:
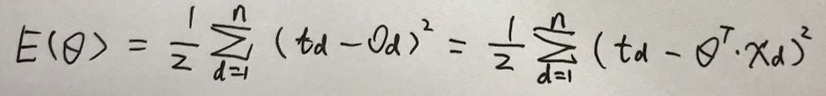
所以,对于神经网络学习的任务,就是求到一系列合适的Θ值&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1048
1048











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









