






1.引入maven依赖
org.jsoup
jsoup
1.10.2
2.代码
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class JsoupTest {
/**
* 读HTML文件
* @param pathname
* @return
*/
public static String readHtml(String path) {
StringBuffer buff = new StringBuffer();
// 建立一个对象,它把文件内容转成计算机能读懂的语言
try (FileReader reader = new FileReader(path); BufferedReader br = new BufferedReader(reader)) {
String line;
int count = 0;
while ((line = br.readLine()) != null) {
// 一次读入一行数据
buff.append(line);
count++;
}
} catch (IOException e) {
e.printStackTrace();
}
return buff.toString();
}
/**
* jsoup方法中 text() :用于获取获取标签的文本 html() :获取标签里面的所有字符串包括html标签
* attr(attributeKey)获取属性里面的值,参数是属性名称
*/
public static void main(String[] args) {
try {
// 本地html存放路径
String file_path = "D:\\index.html";
// 读取html获取文档
String html = readHtml(file_path);
Document document = Jsoup.parse(html);
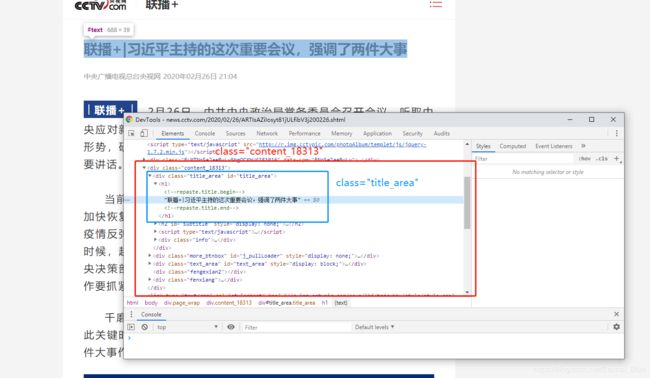
// 通过select获取元素
// 一个页面中的class可能会重复,为避免取多余的数据,
// 先取部分区域的数据,然后再从这部分区域数据中取出真正需要的数据
// 格式: class用"#"、id用"."、标签用h1 例如: div.title_area>h1
Elements div = document.select(".content_18313");// 外层部分区域标签内的数据
Elements title = div.select(".title_area>h1");// 真正需要标签内的数据
System.out.println("打印最终结果:" + title.text());
} catch (Exception e) {
e.printStackTrace();
}
}
}














 5479
5479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









