






状况:公司大数据刚起步没有经验,18年购买了 腾讯云的 EMR 服务 3 * 4核8G 的集群,配置的是 spark on yarn 。所有任务用在msater上用 python+crontab 提交到spark。此时可用的 EMR 组件只有: hdfs, sqoop, hive, hbase, spark。接下来我就讲诉一下我是如何一步步的把hive 引擎配置成 TEZ;把 sqoop, spark, livy 集成进 hue + oozie(工作流);然后把presto, airpal 安装到集群里。并实测 presto 和 hive on tez 的性能对比
问题1:
python 编写的spark 程序 总是 被莫名其妙的 killed
解决:
升级集群硬件配置。 不得。原因是 yarn 的资源管理模式是圈地式的分配,预先申请多少不可超过,否则直接 kill。例如 :
spark-submit --master yarn --executor-memory 4g xxx-python-file 这里指定了executor 的内存是4g,但是 spark 是 java 写,有一个东西叫堆外内存,即jvm消耗的额外内存,随随便便一个程序 8G 内存的节点就 oom 了 或者被 yarn kill。spark 提供了参数来调控这个问题:spark.yarn.executor.memoryOverhead (堆外内存)
yarn.scheduler.maximum-allocation-mb (executor 最大申请内存)
spark 申请内存的原则:
executor-memory + memoryOverhead <= yarn.scheduler.maximum-allocation-mb
spark 集群内存分配有个hadoop 官方工具:
spark on yarn 集群内存配置规划工具下载public-repo-1.hortonworks.com使用方法: -c cpu核数,-m 节点内存, -d 磁盘数, -k 是否有 HBASE
python hdp-configuration-utils.py -c 16 -m 64 -d 4 -k True返回结果:
Using cores=16 memory=64GB disks=4 hbase=True
Profile: cores=16 memory=49152MB reserved=16GB usableMem=48GB disks=4
Num Container=8
Container Ram=6144MB
Used Ram=48GB
Unused Ram=16GB
yarn.scheduler.minimum-allocation-mb=6144
yarn.scheduler.maximum-allocation-mb=49152
yarn.nodemanager.resource.memory-mb=49152
mapreduce.map.memory.mb=6144
mapreduce.map.java.opts=-Xmx4096m
mapreduce.reduce.memory.mb=6144
mapreduce.reduce.java.opts=-Xmx4096m
yarn.app.mapreduce.am.resource.mb=6144
yarn.app.mapreduce.am.command-opts=-Xmx4096m
mapreduce.task.io.sort.mb=1792
tez.am.resource.memory.mb=6144
tez.am.launch.cmd-opts =-Xmx4096m
hive.tez.container.size=6144
hive.tez.java.opts=-Xmx4096m问题2:
EMR 升级到 8 核 16 G 以后, 修改 yarn.scheduler.maximum-allocation-mb=12288,重启机器,2个工作节点后,可用内存应该有 24G,但是 yarn 监控显示只有 19G。
解决:
登陆到各个节点 , 查看 yarn-site.xml 发现 yarn.scheduler.maximum-allocation-mb 有2个重复的,有一台工作节点的yarn.scheduler.maximum-allocation-mb 是 7192 (7G),所以只有19G。删除后重启集群即可。
问题3:
Hive 查询缓慢,每次都会 mapreduce;
解决:
配置hive 的查询引擎为 TEZ,并开启矢量查询。配置如下:
在 hive-site.xml 中加配置项:
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
<property>
<name>hive.vectorized.execution.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.vectorized.execution.reduce.enabled </name>
<value>true</value>
</property>
问题4:
Hue 不能使用:
1.无法登陆
2.oozie 工作流执行 sqoop 无法执行 (killed, main exit 1)
3.spark-notebook 未安装,无法使用 spark
4.工作流传递变量
解决:
1.登陆到 master 节点,执行 hue changepassword 重置密码Apache Livylivy.apache.org
2.上传 jdbc mysql connect.jar 到 hdfs://xxx/usr/haoop/share/lib/sqoop/ 目录下
3.在master节点安装 livy

并配置 livey 启动端口到 xx/hue/desktop/conf/hue.ini 文件中:
livy_server_port=xxx;
livy_server_host=xxx;
4.使用 ${wf:actionData(nodeName).variableName} 的方式获取上一个工作流节点的输出值
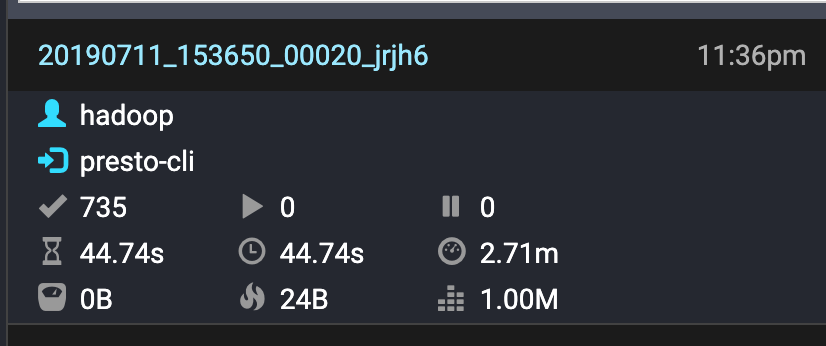
执行同样的SQL: hive on tez 用时 78秒, presto 用时 45秒

未完待续....















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









