






一:select
1.select
使用SELECT语句从表或视图获取数据.

2.解释
SELECT之后是逗号分隔列或星号(*)的列表,表示要返回所有列。
FROM指定要查询数据的表或视图。
JOIN根据某些连接条件从其他表中获取数据。
WHERE过滤结果集中的行。
GROUP BY将一组行组合成小分组,并对每个小分组应用聚合函数。
HAVING过滤器基于GROUP BY子句定义的小分组。
ORDER BY指定用于排序的列的列表。
LIMIT限制返回行的数量。
3.select * 的问题
使用星号(*)可能会返回不使用的列的数据。 它在MySQL数据库服务器和应用程序之间产生不必要的I/O磁盘和网络流量。
如果明确指定列,则结果集更可预测并且更易于管理。 想象一下,当您使用星号(*)并且有人通过添加更多列来更改表格数据时,将会得到一个与预期不同的结果集。
使用星号(*)可能会将敏感信息暴露给未经授权的用户
二:DISTINCT
1.DISTINCT子句
从表中查询数据时,可能会收到重复的行记录。为了删除这些重复行,可以在SELECT语句中使用DISTINCT子句。
SELECT DISTINCT
columns
FROM
table_name
WHERE
where_conditions;
举例/:
SELECT lastname FROM employees ORDER BY lastname;
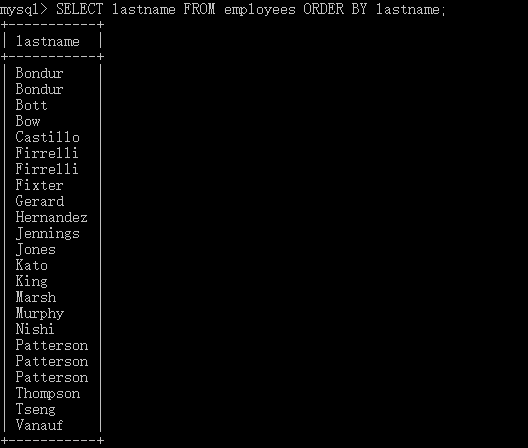
select distinct lastname from employees order by lastname;

2.distinct子句对NULL的处理
会将NULL作为相同的数据,留下一个NULL。
select distinct state from customers;
3.distinct在多列上的使用
可以使用具有多个列的DISTINCT子句。 在这种情况下,MySQL使用所有列的组合来确定结果集中行的唯一性。
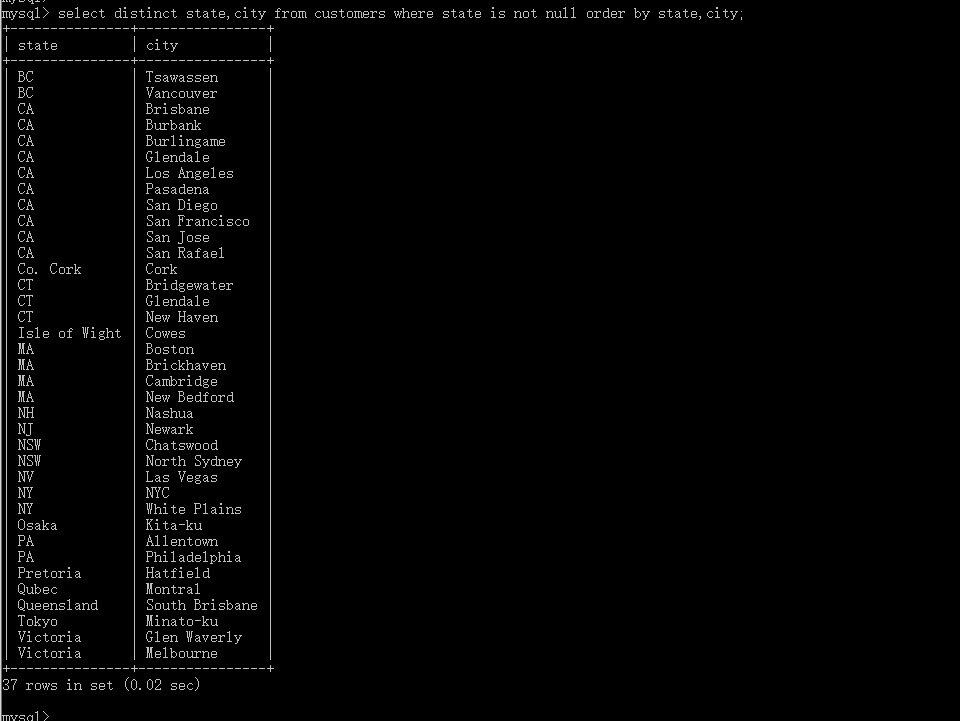
select distinct state,city from customers where state is not null order by state,city;
4.distinct与group by比较
如果在SELECT语句中使用GROUP BY子句,而不使用聚合函数,则GROUP BY子句的行为与DISTINCT子句类似。
这个其实适合一列的。
一般而言,DISTINCT子句是GROUP BY子句的特殊情况。 DISTINCT子句和GROUP BY子句之间的区别是GROUP BY子句可对结果集进行排序,而DISTINCT子句不进行排序。
如果将ORDER BY子句添加到使用DISTINCT子句的语句中,则结果集将被排序,并且与使用GROUP BY子句的语句返回的结果集相同。

5.distinct与聚合函数
可以使用具有聚合函数(例如SUM,AVG和COUNT)的DISTINCT子句中,在MySQL将聚合函数应用于结果集之前删除重复的行。
select count(distinct state) from customers where country='USa';

6.distinct与limit一起使用
如果要将DISTINCT子句与LIMIT子句一起使用,MySQL会在查找LIMIT子句中指定的唯一行数时立即停止搜索。
















 505
505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









