






一、集群规划
因为伪分布式集群已经搭建好,所以打算将那个集群改造成ha集群
集群规划:
| 节点名称 | NN | JJN | DN | ZKFC | ZK | RM | NM |
| hadoop1 | NameNode | JournalNode | DataNode | ZKFC | Zookeeper |
| NodeManager |
| hadoop2 | NameNode | JournalNode | DataNode | ZKFC | Zookeeper | ResourceManager | NodeManager |
| hadoop3 |
| JournalNode | DataNode |
| Zookeeper | ResourceManager | NodeManager |
二、搭建Zookeeper集群
参考下面搭建zookeeper集群的文章
https://blog.csdn.net/weixin_42533409/article/details/81708818
三、配置hadoop HA集群
先参考如何搭建简易分布式集群的教程
【hadoop搭建伪分布式集群(非HA)】
https://blog.csdn.net/weixin_42533409/article/details/81701564
1)修改core-site.xml
<!--将两个namenode的地址组装成一个集群mycluster-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!--指定hadoop临时目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop/hadoop-2.6.1/data/tmp</value>
</property>
<!--指定zookeeper地址,指定ZKFC故障自动切换转移-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
2)修改hdfs-site.xml
<!--指定副本数-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--完全分布式集群名称-->
<!--指定hdfs的nameservice为mycluster,需要和core-site.xml中的保持一致
dfs.ha.namenodes.[nameservice id]为在nameservice中的每一个NameNode设置唯一标示符。
配置一个逗号分隔的NameNode ID列表。这将是被DataNode识别为所有的NameNode。
例如,如果使用"mycluster"作为nameservice ID,并且使用"nn1"和"nn2"作为NameNodes标示符
-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!--namenode数据的存放地点,也就是namenode元数据存放的地方,记录了hdfs系统中文件的元数据-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop/hadoop-2.6.1/dfs/name</value>
</property>
<!--datanode数据的存放地点,也就是block块存放的目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop/hadoop-2.6.1/dfs/data</value>
<!--开启hdfs的web访问接口,默认端口时50070-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--集群中namenode节点有哪些-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!--nn1的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop1:8020</value>
</property>
<!--nn2的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop2:8020</value>
</property>
<!--nn1的HTTP通信地址-->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop1:50070</value>
</property>
<!--nn2的HTTP通信地址-->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop2:50070</value>
</property>
<!--指定namenode元数据在JournalNode的存放位置-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/mycluster</value>
</property>
<!--配置隔离机制方法,同一时刻只能有一台服务器对外响应,多个机制用换行分隔,即每个机制暂用一行,也可用shell命令切换-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence
shell(/bin/true)
</value>
</property>
<!--使用隔离机制时需要ssh无密码登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!--声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/hadoop/hadoop-2.6.1/data/ha/jn</value>
</property>
<!--关闭权限检查-->
<property>
<name>dfs.permisstions.enable</name>
<value>false</value>
</property>
<!--访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--配置自动故障转移-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
3)修改mapred-site.xml
<!--指定mr框架为yarn方式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--指定mr历史服务器主机,端口-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<!--指定mr历史服务器webUI主机,端口-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
<!--历史服务器的WEB UI最多显示20000个历史的作业记录信息-->
<property>
<name>mapreduce.jobhistory.joblist.cache.size</name>
<value>20000</value>
</property>
<!--配置作业运行日志-->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/history/done</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/tmp/hadoop-yarn/staging</value>
</property>
4)修改slaves
hadoop1
hadoop2
hadoop3
5)修改yarn-site.xml
<!--reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--启用resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rmCluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop3</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
<!--启动自动恢复-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
四、初始化并运行hadoop
在hadoop1节点配置的hadoop复制到其它两个节点
提醒:jdk环境和hadoop环境没有配的参照上个教程配置
重点强调:一定要按照以下步骤逐步进行操作
重点强调:一定要按照以下步骤逐步进行操作
重点强调:一定要按照以下步骤逐步进行操作
1)分别启动hadoop1,hadoop2,hadoop3节点的zookeeper
hadoop1:


hadoop2:
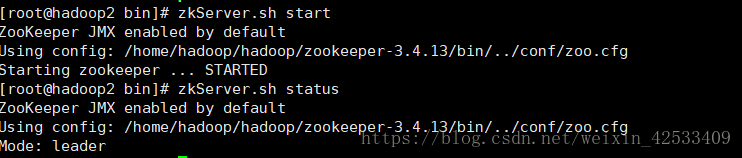
hadoop3:
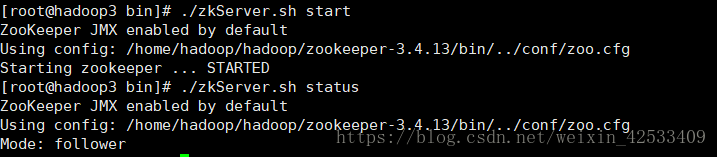
2)在配置的各个journalnode节点启动该进程
hadoop1

hadoop2

hadoop3

3)格式化namenode
先选取一个namenode(hadoop1)节点进行格式化
执行命令:hadoop namenode -format

4)启动nn1

5)在nn2上,同步nn1的数据
bin/hdfs namenode -bootstrapStandby
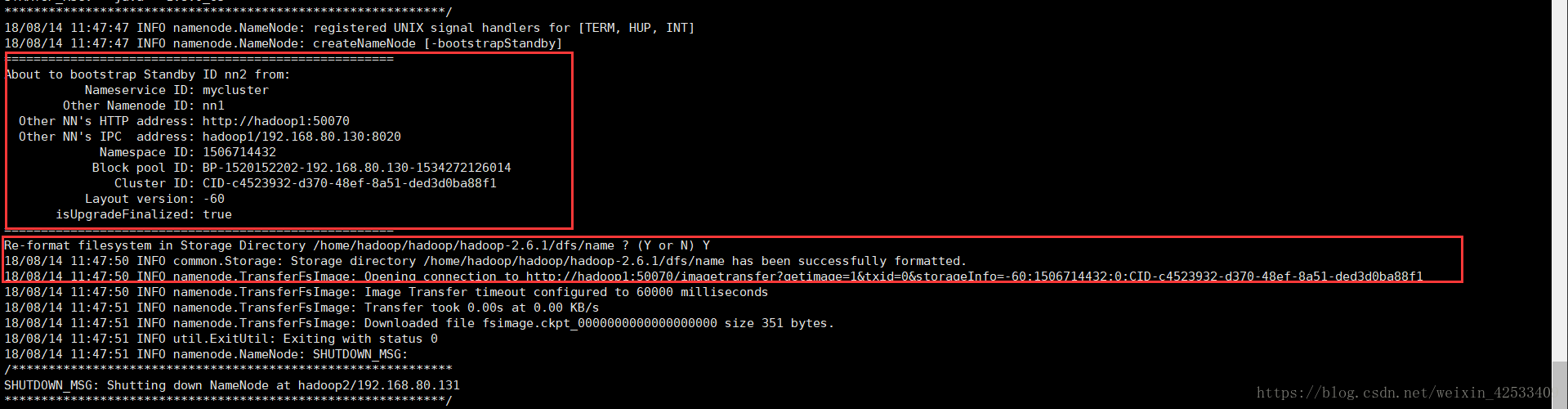
6)启动nn2


7)在nn1的sbin目录下启动所有datanode

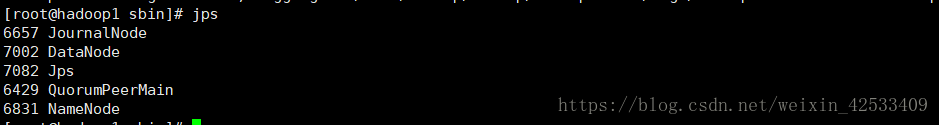
这个jps进程时有误的,因为没有DFZKFailoverController(因为hdfs-site.xml中没有配置dfs.ha.fencing.methods下面的shell(/bin/true)),下面是正确的
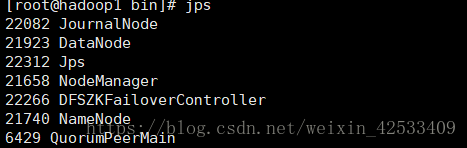
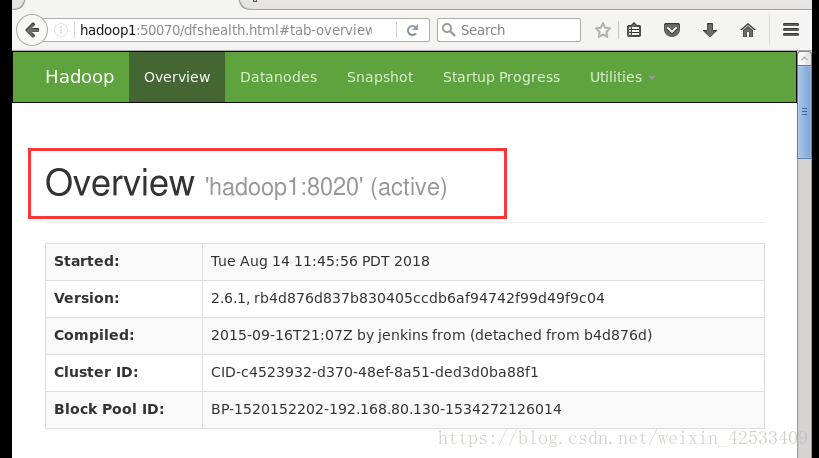
8)在web页面访问:
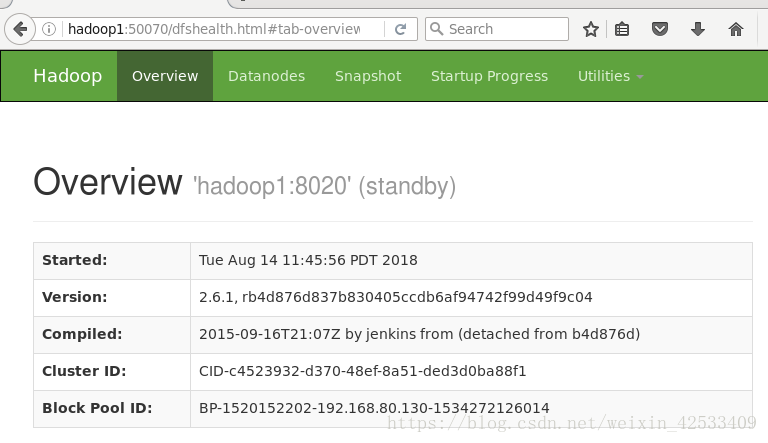
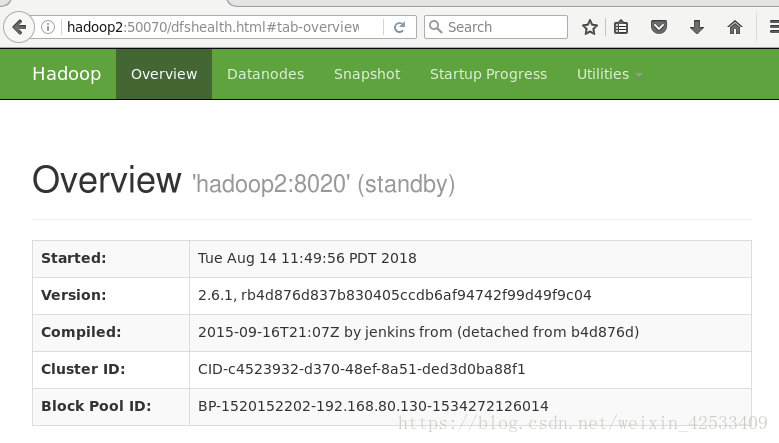
注:出现这个问题的原因是zkfc进程没有启动起来,原因hdfs-site.xml下的dfs.ha.fencing.methods这个属性没有加shell(/bin/true),
需要特别注意的是,sshfence和shell需要换行来区分,注意左右别有特殊字符
需要手动或自动切换主机状态
9)手动切换状态,在各个NameNode节点上启动DFSZK Failover Controller,先在哪台机器启动,哪个机器的NameNode就是Active NameNode
我们在nn1节点启动zkfc

不过这种方法不好使
使用下面的方法,强转:
hdfs -transitionToActive nn1 --forcemanual
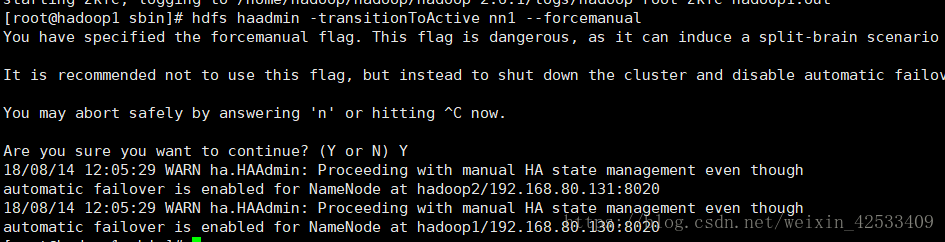
这种转成功了

五、初始化并运行yarn
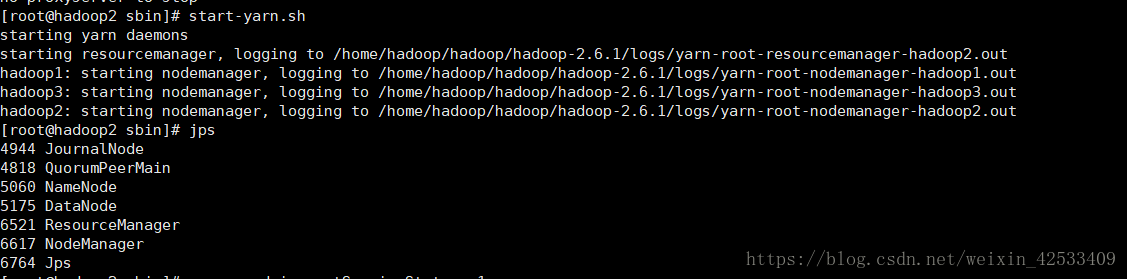
根据我们最开头的图例,yarn安装在hadoop2和hadoop3节点
所以先启动hadoop2节点的yarn
hadoop2:
hadoop3:
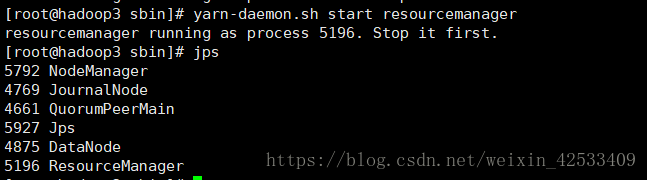
我在启动hadoop3的时候,提示resourcemanager已经启动了
在查看进程的时候,发现ha-yarn已经有了

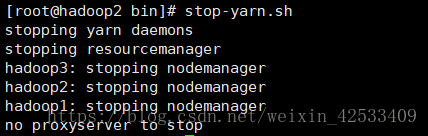
六、关闭hadoop
在hadoop1节点的bin目录下面
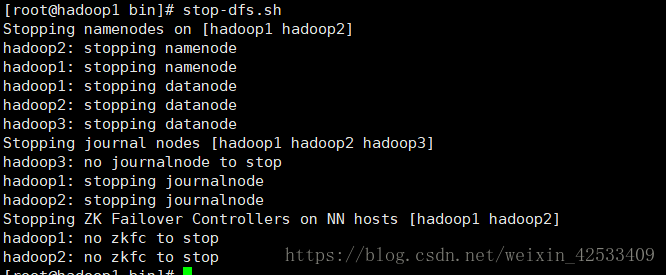
在hadoop2节点停掉yarn
启动后的时侯,同理
hdfs haadmin -getServiceState nn1(或nn2)查看主节点的状态是active还是standby
yarn rmadmin -getServiceState rm1(或rm2)查看yarn主从关系,状态
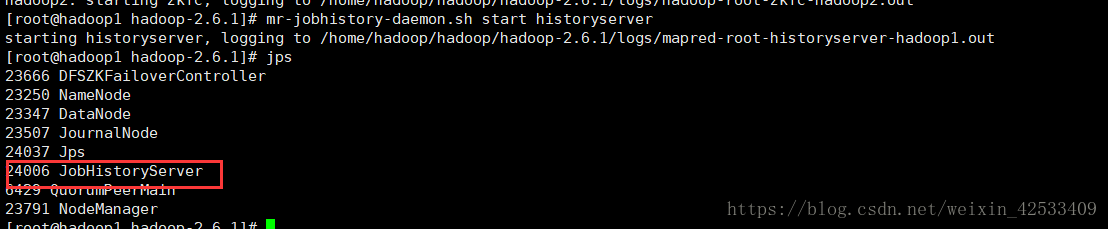
七、启动mapreduce任务历史服务器(启动它的作用是在yarn web页面上查看历史map任务)
mr-jobhistory-daemon.sh start historyserver
八、遇到的问题
1)启动namenode时两台主机都是standby
在bin目录下执行命令:hadoop-daemon.sh start zkfc(选举一台主机为active)也不好使
解决方式:
进入zookeeper下面的bin目录,执行命令:
zkCli.sh -server server:2181
ls / 报错:
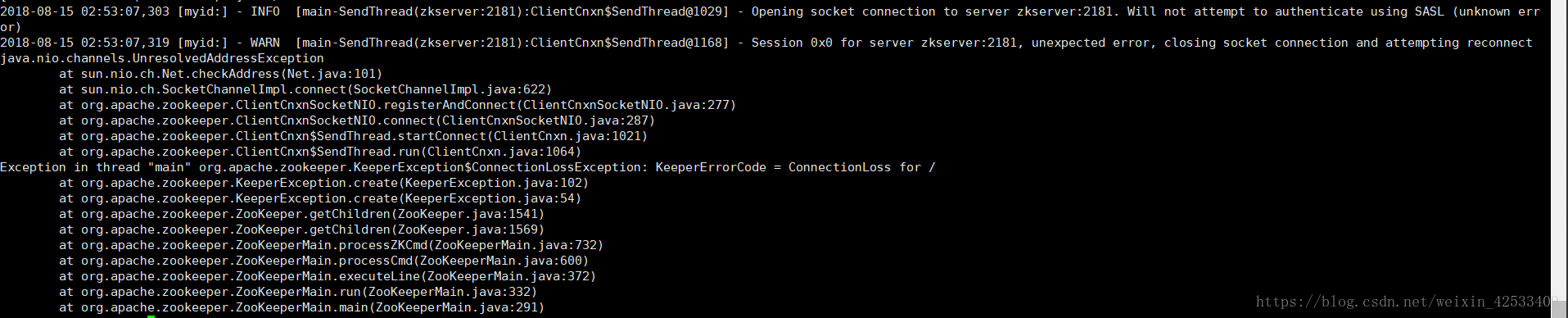
因为这个命令是错的,正确的应该是:
zkCli.sh -server hadoop1:2181

2)Error: Could not find or load main class zkfc-formatZK
3)启动namenode之后,jps下面没有DFSZKFailoverController
实际上,上面3个问题都跟zookeeper不能正常选举主机有关,主要的错误在于我耍了小聪明,以为hdfs-site.xml中不配置dfs.ha.fencing.methods的shell(/bin/true)属性也没问题,实际上错了,必须要配置
顺便说明,修改配置之后,不需要其它任何操作,包括重新格式化namenode(不轻易这么做,因为会格式化掉元数据),等等
重启即可,重启之后,在web页面上展示出来的就是一个active和一个standby
4)在启动yarn的时候,启动hadoop2节点时,hadoop3的resourcemanager也会启动,但是反过来不行,遇到这种情况,手动重启hadoop2节点的resourcemanager
yarn-daemon.sh start resourcemanager
九、Q & A
目前状态:
hadoop1:
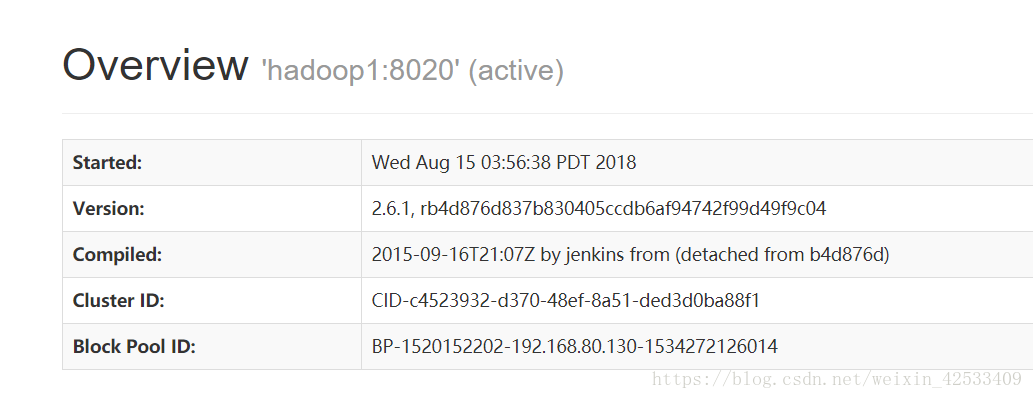
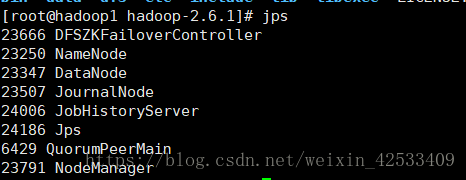
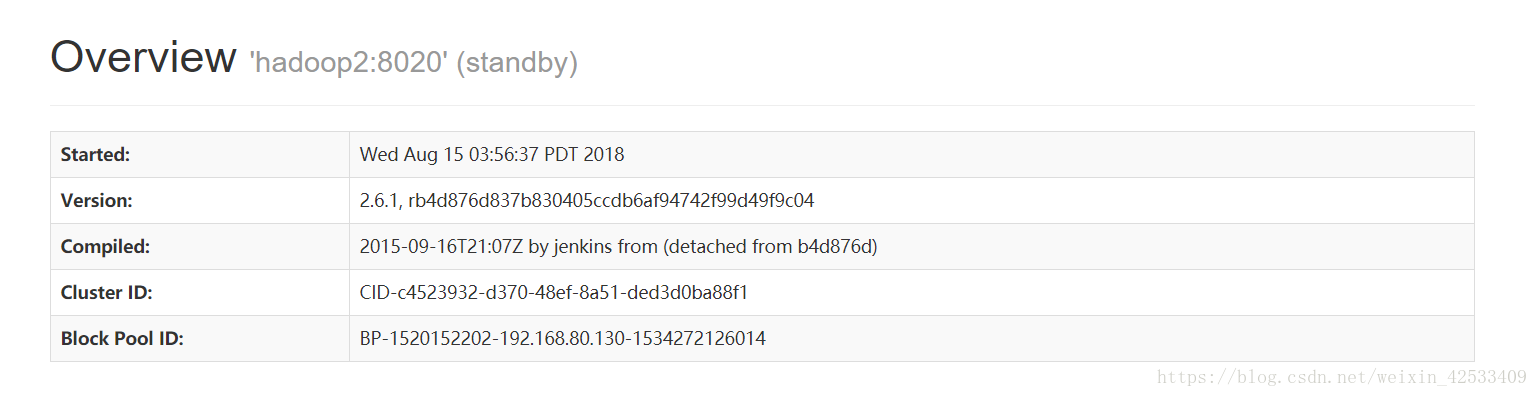
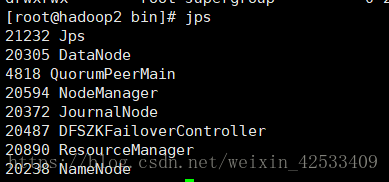
hadoop2:
让我们杀掉hadoop1的namenode进程,看看会发生什么?
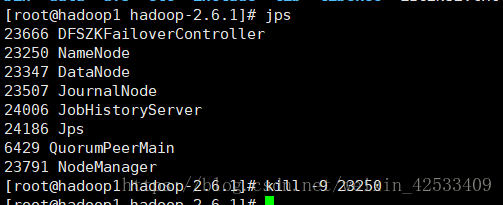
再看web页面
hadoop1节点已经不能访问了
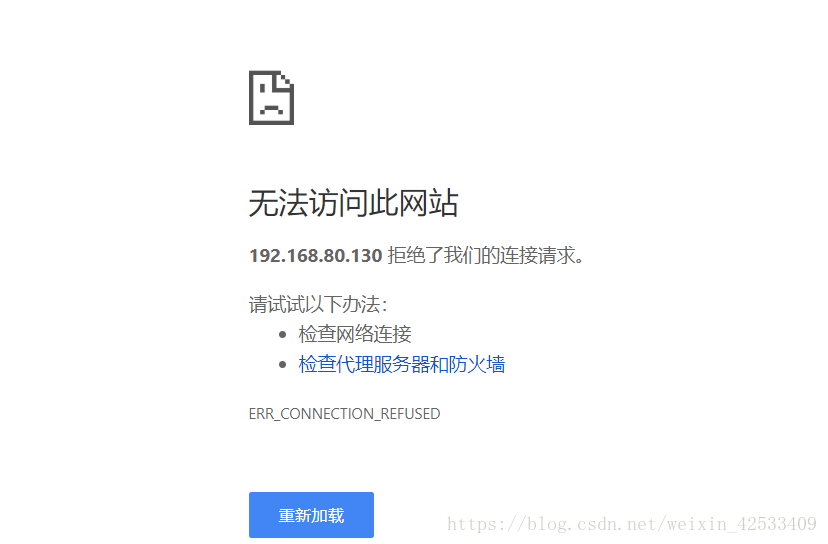
hadoop2节点切换到active了
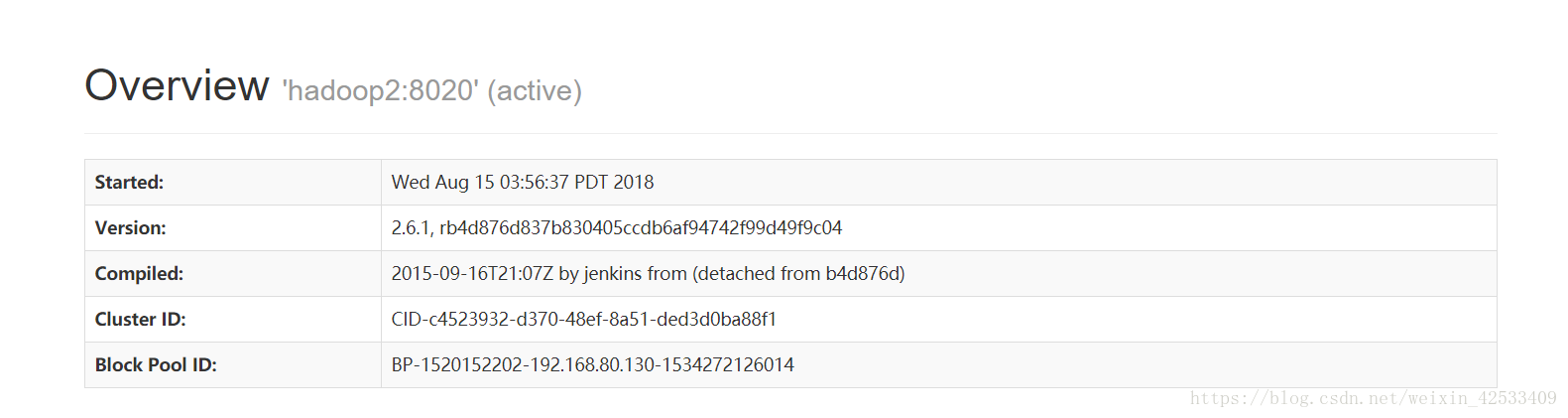
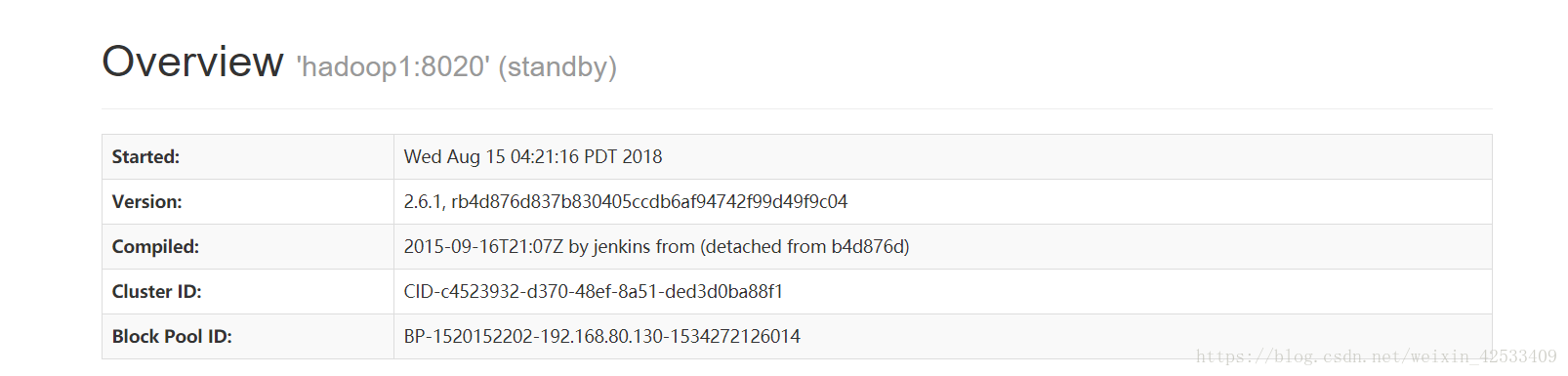
重新启动hadoop1的namenode时:
hadoop-daemon.sh start namenode
hadoop1切换到standby状态
十、拓展
1.最终一致性:client不论连接到哪个Server,展示给它都是同一个视图,这是zookeeper最重要的性能。
2 .可靠性:具有简单、健壮、良好的性能,如果消息m被到一台服务器接受,那么它将被所有的服务器接受。
3 .实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
4 .等待无关(wait-free):慢的或者失效的client不得干预快速的client的请求,使得每个client都能有效的等待。
5.原子性:更新只能成功或者失败,没有中间状态。
6 .顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









