









1、序号函数:row_number() / rank() / dense_rank()
RANK():并列排序,跳过重复序号 —— 1、1、3
ROW_NUMBER():顺序排序 —— 1、2、3
DENSE_RANK(): 并列排序,不跳过重复序号 —— 1、1、2
--给窗口指定别名:WINDOW my_window_name AS (PARTITION BY uid ORDER BY score)
SELECT
uid,
score,
rank() OVER my_window_name AS rk_num,
row_number() OVER my_window_name AS row_num
FROM exam_record
WINDOW my_window_name AS (PARTITION BY uid ORDER BY score)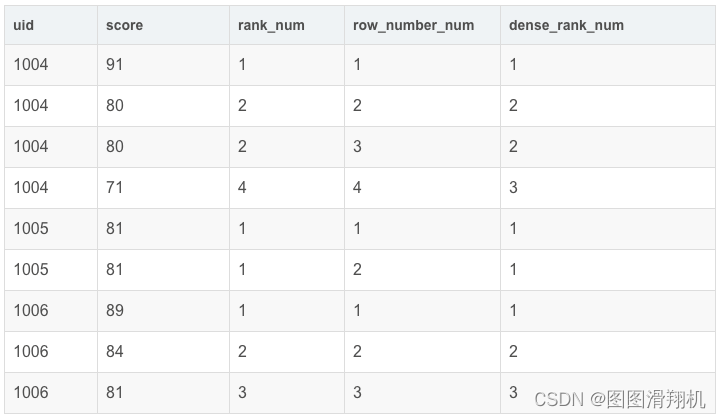
附注:也可以使用自连接的方法实现分数排序,相当于rank()
SELECT
P1.uid,
P1.score,
(SELECT
COUNT(P2.score)
FROM exam_record P2
WHERE P2.score > P1.score) + 1 AS rank_1
FROM exam_record P1
ORDER BY rank_1; 
这里1234447..,如果想要7改为5呢,不跳过位次。相当于DENSE_RANK 函数。
只需要改 COUNT(P2.score) 为 COUNT(distinct P2.score) 即可。
2、分布函数:percent_rank()/cume_dist()
1)percent_rank():
将某个数值在数据集中的排位作为数据集的百分比值返回,此处的百分比值得范围为0到1.此函数可用于计算值在数据集内的相对位置。如班级成绩为例,返回的百分数30%表示某个分数在班级总分排名的前30%。
每行按照公式(rank-1)/(rows-1)进行计算。其中rank为RANK()函数产生的序号,rows为当前窗口的记录总行数。
SELECT
uid,
score,
rank() OVER my_window_name AS rank_num,
PERCENT_RANK() OVER my_window_name AS prk
FROM exam_record
WINDOW my_window_name AS (ORDER BY score desc)
2)cume_dist():
如果按升序排列,则统计:小于等于当前值的行数/总行数。
如果按降序排列,则统计:大于等于当前值的行数/总行数。
SELECT
uid,
score,
rank() OVER my_window_name AS rank_num,
cume_dist() OVER my_window_name AS cume_dist_num
FROM exam_record
WINDOW my_window_name AS (ORDER BY score asc)
3、前后函数:lag(expr,n,defval)/lead(expr,n,defval) ※
Lag()和Lead() 分析函数可以在同一次查询中取出同一字段的前N行的数据(Lag)和后N行的数据(Lead)作为独立的列。
常用来取今天和昨天某个字段的插值,当然这种操作也可以用表自连接实现,但是Lag()和Lead()效率更高。函数语法如下:
lag( exp_str,offset,defval) over(partition by .. order by …)
lead(exp_str,offset,defval) over(partition by .. order by …)
其中:
-
exp_str 是字段名
-
Offset 是偏移量,即是上1个或上N个的值,假设当前行在表中排在第5行,offset 为3,则表示我们所要找的数据行就是表中的第2行(即5-3=2)。
-
Defval 默认值,当两个函数取 上N 或者 下N 个值,当在表中从当前行位置向前数N行已经超出了表的范围时,lag() 函数将defval这个参数值作为函数的返回值,若没有指定默认值,则返回NULL,那么在数学运算中,总要给一个默认值才不会出错。
-
返回位于当前行的前 n 行的expr的值:LAG(expr,n)
-
返回位于当前行的后n行的expr的值:LEAD(expr,n)
举例:查询前1名同学及后一名同学的成绩和当前同学成绩的差值(只排分数,不按uid分组)、
1、先将前一名和后一名同学的分数与当前行的分数放在一起。
SELECT
uid,
score,
LAG(score,1,0) OVER my_window_name AS `前一名分数`,
LEAD(score,1,0) OVER my_window_name AS `后一名分数`
FROM exam_record
WINDOW my_window_name AS (ORDER BY score desc)
SELECT
uid,
score,
score - `前一名分数` AS `与前一名分差`,
score - `后一名分数` AS `与后一名分差`
FROM (
SELECT
uid,
score,
LAG(score,1,0) OVER my_window_name AS `前一名分数`,
LEAD(score,1,0) OVER my_window_name AS `后一名分数`
FROM exam_record
WINDOW my_window_name AS (ORDER BY score desc)
) res

4、头尾函数:FIRST_VALUE(expr),LAST_VALUE(expr)
-
FIRST_VALUE(expr),返回第一个expr的值
-
LAST_VALUE(expr),返回最后一个expr的值
-
应用场景:截止到当前成绩,按照分数排序查询第1个和最后1个的分数
SELECT
uid,
score,
FIRST_VALUE(score) OVER my_window_name AS `第一行分数`,
LAST_VALUE(score) OVER my_window_name AS `最后一行分数`
FROM exam_record
WINDOW my_window_name AS (ORDER BY score desc)
5、聚合函数+窗口函数联合使用
聚合函数也可以用于窗口函数,因窗口函数的执行顺序(逻辑上的)是在FROM,JOIN,WHERE,GROUP BY,HAVING之后,在ORDER BY,LIMIT,SELECT DISTINCE之前,它执行时GROUP BY的聚合过程已经完成了,所以不会再产生数据聚合。
注:窗口函数是在where之后执行的,所以如果where子句需要用窗口函数作为条件,需要多一层查询,在子查询外面进行。
SELECT
uid,
score,
sum(score) OVER my_window_name AS sum_score,
max(score) OVER my_window_name AS max_score,
min(score) OVER my_window_name AS min_score,
avg(score) OVER my_window_name AS avg_score
FROM exam_record
WINDOW my_window_name AS (ORDER BY score desc)
mysql> SELECT
-> stu_id,
-> lesson_id,
-> score,
-> create_time,
-> FIRST_VALUE(score) OVER w AS first_score, -- 按照lesson_id分区,create_time升序,取第一个score值
-> LAST_VALUE(score) OVER w AS last_score -- 按照lesson_id分区,create_time升序,取最后一个score值
-> FROM t_score
-> WHERE lesson_id IN ('L001','L002')
-> WINDOW w AS (PARTITION BY lesson_id ORDER BY create_time)
-> ;
+--------+-----------+-------+-------------+-------------+------------+
| stu_id | lesson_id | score | create_time | first_score | last_score |
+--------+-----------+-------+-------------+-------------+------------+
| 3 | L001 | 100 | 2018-08-07 | 100 | 100 |
| 1 | L001 | 98 | 2018-08-08 | 100 | 98 |
| 2 | L001 | 84 | 2018-08-09 | 100 | 99 |
| 4 | L001 | 99 | 2018-08-09 | 100 | 99 |
| 3 | L002 | 91 | 2018-08-07 | 91 | 91 |
| 1 | L002 | 86 | 2018-08-08 | 91 | 86 |
| 2 | L002 | 90 | 2018-08-09 | 91 | 90 |
| 4 | L002 | 88 | 2018-08-10 | 91 | 88 |
+--------+-----------+-------+-------------+-------------+------------+













 958
958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









