







剖析---(爬取深度源码分析)
再使用scrapy时候,我们大多都是开箱即用,简单看了一下网上使用教程就直接投入使用,不过scrapy定位也是为开发者提供方便,今天我们探讨一下它核心,分析一下一些它内置功能的实现。(滴滴..开车,扶好,坐稳)
- scrapy 内部是如何实现爬虫的优先级和深度的?
- scrapy 内部signals如何扩展?
- scrapy如何实现去重?
先来探讨第1个问题。调度器---下载中间件,首先这个是它内部的一个流程,先讲调度器,1. 使用队列(广度优先) 2. 使用栈(深度优先) 3. 使用优先级队列(利用redis的有序集合) 。
反而之下载中间件: 在request对象请求下载过程中,会经过一系列的中间件,而这些中间件,在请求下载时候,都会经过下载中间件的process_request这个方法,下载完毕后,会经过process_response方法,这些中间件很有用处,它们会统一的对所有的request对象进行下载前或下载后做处理。我们可以自定义中间件,在请求时候,可以添加一些请求头,再返回时候,获得cookie。自定制下载中间件时,需要在settings.py中配置才会生效。下述是我的配置文件。
DOWNLOADER_MIDDLEWARES = {
# 下载中间件
# 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
# 'scrapy_useragents.downloadermiddlewares.useragents.UserAgentMiddleware': 500,
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810
}说到中间件,其实scrapy给我们实现了很多下载中间件,方便实用,下面我们来看下有哪些中间件
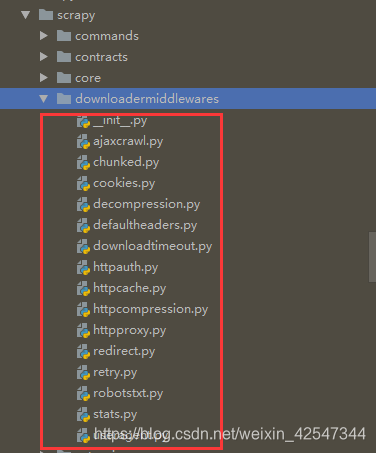
给我们提供了这么多便利,这里不一一全部分析这些中间件了,拿第一个出来举个栗子,看管请看源码
"""Set User-Agent header per spider or use a default value from settings"""
# 这是useragent.py 中间件
from scrapy import signals
class UserAgentMiddleware(object):
"""This middleware allows spiders to override the user_agent"""
def __init__(self, user_agent='Scrapy'):
self.user_agent = user_agent
@classmethod
def from_crawler(cls, crawler):
o = cls(crawler.settings['USER_AGENT'])
crawler.signals.connect(o.spider_opened, signal=signals.spider_opened)
return o
def spider_opened(self, spider):
self.user_agent = getattr(spider, 'user_agent', self.user_agent)
def process_request(self, request, spider):
if self.user_agent:
request.headers.setdefault(b'User-Agent', self.user_agent)这里UserAgentMiddleware类的from_crawler方法是从settings.py文件中获取USER_AGENT,然后应用到爬虫。
所有scrapy中间件,都是有默认的优先级数值,在源码文件可以看到
DOWNLOADER_MIDDLEWARES_BASE = {
# Engine side
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300,
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560,
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590,
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600,
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,
'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900,
# Downloader side
}(所以,在我们自定制中间件时候,请求时一定要比默认的对应中间件的数值大,返回响应时一定要比默认的数值小,否则默认的中间件会覆盖掉自定制的中间,执行顺序:请求时从小到大,响应时从大到小),从而无法生效
当然,这些中间件也有返回值,请求中间件,process_request返回None表示继续执行后续的中间件,返回response就会跳过后续请求中间件,直接执行所有响应中间件。
返回响应时,process_response必须要有返回值,正常情况下返回response,也可以返回一个request对象,也可以跑出异常。
爬虫中间件
爬虫应用将item对象或者request对象一次穿过爬虫中间件process_spider_output方法传给引擎进行分发,下载完后一次穿过爬虫中间件的process_spider_input方法。
返回值: process_spider_output方法必须返回一个None或抛出一个异常
同样的,我们自定义爬虫中间件也要在配置文件中配置
SPIDER_MIDDLEWARES = {
'crawlradar.middlewares.CrawlradarSpiderMiddleware': 543,
}爬虫中间件具体有什么作用呢?各位看官且听我说:我们的爬虫爬取的深度(DEPTH_LIMIT参数) 和 优先级就是通过内置的爬虫中间件实现的。scrapy为我们提供了这么些 爬虫中间件:
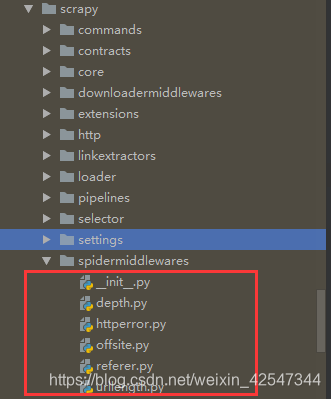
相信各位看到了一个文件为 depth.py的,没错,就这个家伙,为我们实现了爬虫深度和优先级,具体我们要分析源码。
"""
Depth Spider Middleware
See documentation in docs/topics/spider-middleware.rst
"""
import logging
from scrapy.http import Request
logger = logging.getLogger(__name__)
class DepthMiddleware(object):
def __init__(self, maxdepth, stats, verbose_stats=False, prio=1):
self.maxdepth = maxdepth
self.stats = stats
self.verbose_stats = verbose_stats
self.prio = prio
@classmethod
def from_crawler(cls, crawler):
settings = crawler.settings
maxdepth = settings.getint('DEPTH_LIMIT')
verbose = settings.getbool('DEPTH_STATS_VERBOSE')
prio = settings.getint('DEPTH_PRIORITY')
return cls(maxdepth, crawler.stats, verbose, prio)
def process_spider_output(self, response, result, spider):
def _filter(request):
if isinstance(request, Request):
depth = response.meta['depth'] + 1
request.meta['depth'] = depth
if self.prio:
request.priority -= depth * self.prio
if self.maxdepth and depth > self.maxdepth:
logger.debug(
"Ignoring link (depth > %(maxdepth)d): %(requrl)s ",
{'maxdepth': self.maxdepth, 'requrl': request.url},
extra={'spider': spider}
)
return False
else:
if self.verbose_stats:
self.stats.inc_value('request_depth_count/%s' % depth,
spider=spider)
self.stats.max_value('request_depth_max', depth,
spider=spider)
return True
# base case (depth=0)
if 'depth' not in response.meta:
response.meta['depth'] = 0
if self.verbose_stats:
self.stats.inc_value('request_depth_count/0', spider=spider)
return (r for r in result or () if _filter(r))爬虫执行到深度中间件时,会先调用from_crawler方法,这个方法会先调用settings文件中,获取几个参数:DEPTH_LIMIT(爬取深度),DEPTH_PRIORITY(优先级),DEPTH_STATS_VERBOSE(是否采集最后一层),然后通过process_spider_output方法中判断有没有设置过depth,如果没有就给当前的request对象设置depth=0,然后通过每层加一depth = response.meta['depth'] + 1 实现层级的控制
说明:如果配置DEPTH_PRIORITY设置为1,则请求的优先级会递减(0,-1,-2,-3....)
如果配置DEPTH_PRIORITY设置为-1,则请求的优先级会递增(0,1,2,3.....)
通过这种方式,改变配置值的正负,来实现优先级的控制(深度优先(从大到小),广度优先(从小到大))
RFPDupeFilter 去重
scrapy支持通过RFPDupeFilter来完成页面去重(防止重复抓取),RFPDupeFilter实际是根据request_fingerprint实现过滤的,实现如下:
from __future__ import print_function
import os
import logging
from scrapy.utils.job import job_dir
from scrapy.utils.request import referer_str, request_fingerprint
class BaseDupeFilter(object):
@classmethod
def from_settings(cls, settings):
return cls()
def request_seen(self, request):
return False
def open(self): # can return deferred
pass
def close(self, reason): # can return a deferred
pass
def log(self, request, spider): # log that a request has been filtered
pass
class RFPDupeFilter(BaseDupeFilter):
"""Request Fingerprint duplicates filter"""
def __init__(self, path=None, debug=False):
self.file = None
self.fingerprints = set()
self.logdupes = True
self.debug = debug
self.logger = logging.getLogger(__name__)
if path:
self.file = open(os.path.join(path, 'requests.seen'), 'a+')
self.file.seek(0)
self.fingerprints.update(x.rstrip() for x in self.file)
@classmethod
def from_settings(cls, settings):
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(job_dir(settings), debug)
def request_seen(self, request):
fp = self.request_fingerprint(request)
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + os.linesep)
def request_fingerprint(self, request):
return request_fingerprint(request)
def close(self, reason):
if self.file:
self.file.close()
def log(self, request, spider):
if self.debug:
msg = "Filtered duplicate request: %(request)s (referer: %(referer)s)"
args = {'request': request, 'referer': referer_str(request) }
self.logger.debug(msg, args, extra={'spider': spider})
elif self.logdupes:
msg = ("Filtered duplicate request: %(request)s"
" - no more duplicates will be shown"
" (see DUPEFILTER_DEBUG to show all duplicates)")
self.logger.debug(msg, {'request': request}, extra={'spider': spider})
self.logdupes = False
spider.crawler.stats.inc_value('dupefilter/filtered', spider=spider)
class Request(object_ref):
def __init__(self, url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None):这个请求类初始化参数 dont_filter=False ,默认是False,改为True内部就不会去重了。
signals(信号)
scrapy使用信号传递爬虫状况,下述是信号灯说明(借鉴源码:scrapy/xlib/signals.py)
"""
Scrapy signals
These signals are documented in docs/topics/signals.rst. Please don't add new
signals here without documenting them there.
"""
engine_started = object() # 引擎的开始
engine_stopped = object() # 引擎的结束
spider_opened = object() # 爬虫开始
spider_idle = object() # 爬虫空闲
spider_closed = object() # 爬虫结束
spider_error = object() # 爬虫错误
request_scheduled = object() # 调度器开始调度
request_dropped = object() # 请求舍弃
request_reached_downloader = object() # 响应接收完毕
response_received = object() # 响应接收到
response_downloaded = object() # 下载完毕
item_scraped = object()
item_dropped = object()
item_error = object()
# for backwards compatibility
stats_spider_opened = spider_opened
stats_spider_closing = spider_closed
stats_spider_closed = spider_closed
item_passed = item_scraped
request_received = request_scheduled
今天分析到这里,还会继续死磕scrapy,会继续更新














 580
580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









