







论文笔记(2)
Convolutional Two-Stream Network Fusion for Video Action Recognition
主要贡献
1.提出空间和时间网络可以在卷积层进行融合,而不是在softmax层进行融合,在卷积层进行融合不会损失性能,但可以节省大量的参数;
2.发现空间上从最后一个卷积层进行融合比在之前的卷积层效果更好,在类预测层进行融合可以提高预测精度;
3.通过抽象的卷积特征汇集到时空邻近区域进一步提高性能。
双流卷积神经网络的缺点
1.不能在空间和时间特征之间学习像素级的对应关系(因为融合只是在分类的分数上);
2.有限时间规模,因为空间卷积操作只在单帧上,时序卷积操作只在堆叠的L个时序相邻的光流帧上(例如L=10)。
空间融合
融合函数:
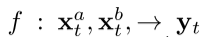
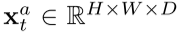
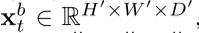
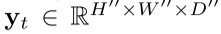
Sum fusion:
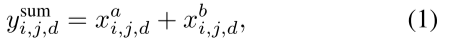
Max fusion:
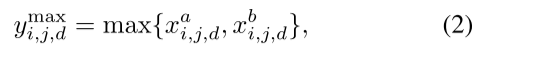
Concatenation fusion:
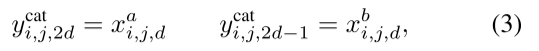
Conv fusion:
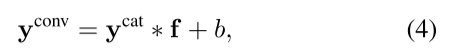
∗代表卷积
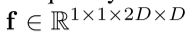
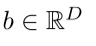
Bilinear fusion:
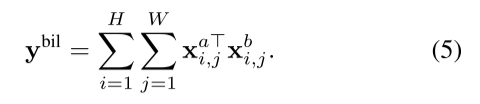
T代表矩阵外积

融合位置


时间融合

(a)二维池化忽略了时间,只是在空间邻近区域进行池化,单独缩小每个时间样本的特征图的大小;
(b)三维池化首先从局部的时空邻近区域跨时间叠加特征地图,然后收缩这个时空立方体;
(c)3D conv + 3D pooling是在池化之前先与贯穿特征通道、空间和时间的融合核进行卷积;

网络架构


图片转自:https://blog.csdn.net/u013588351/article/details/102074562
实验结果
使用更深的网络架构

与最先进技术的对比
















 694
694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









