







背景
提供免费算力支持,有交流群有值班教师答疑的华为昇思训练营进入第十三天了。
今天是第十三天,从第十天开始,进入了应用实战阶段,前九天都是基础入门阶段,具体的学习内容可以看链接
基础学习部分
昇思25天学习打卡营第一天|快速入门
昇思25天学习打卡营第二天|张量 Tensor
昇思25天学习打卡营第三天|数据集Dataset
昇思25天学习打卡营第四天|数据变换Transforms
昇思25天学习打卡营第五天|网络构建
昇思25天学习打卡营第六天|函数式自动微分
昇思25天学习打卡营第七天|模型训练
昇思25天学习打卡营第八天|保存与加载
昇思25天学习打卡营第九天|使用静态图加速
应用实践部分
昇思25天学习打卡营第十天|CycleGAN图像风格迁移互换
昇思25天学习打卡营第十一天|DCGAN生成漫画头像
昇思25天学习打卡营第十二天|Diffusion扩散模型
学习内容
模型简介
生成式对抗网络(Generative Adversarial Networks,GAN)是一种生成式机器学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。
最初,GAN由Ian J. Goodfellow于2014年发明,并在论文Generative Adversarial Nets中首次进行了描述,其主要由两个不同的模型共同组成——生成器(Generative Model)和判别器(Discriminative Model):
- 生成器的任务是生成看起来像训练图像的“假”图像;
- 判别器需要判断从生成器输出的图像是真实的训练图像还是虚假的图像。
GAN通过设计生成模型和判别模型这两个模块,使其互相博弈学习产生了相当好的输出。
GAN模型的核心在于提出了通过对抗过程来估计生成模型这一全新框架。在这个框架中,将会同时训练两个模型——捕捉数据分布的生成模型 G G G 和估计样本是否来自训练数据的判别模型 D D D 。
在训练过程中,生成器会不断尝试通过生成更好的假图像来骗过判别器,而判别器在这过程中也会逐步提升判别能力。这种博弈的平衡点是,当生成器生成的假图像和训练数据图像的分布完全一致时,判别器拥有50%的真假判断置信度。
用 x x x 代表图像数据,用 D ( x ) D(x) D(x)表示判别器网络给出图像判定为真实图像的概率。在判别过程中, D ( x ) D(x) D(x) 需要处理作为二进制文件的大小为 1 × 28 × 28 1\times 28\times 28 1×28×28 的图像数据。当 x x x 来自训练数据时, D ( x ) D(x) D(x) 数值应该趋近于 1 1 1 ;而当 x x x 来自生成器时, D ( x ) D(x) D(x) 数值应该趋近于 0 0 0 。因此 D ( x ) D(x) D(x) 也可以被认为是传统的二分类器。
用 z z z 代表标准正态分布中提取出的隐码(隐向量),用 G ( z ) G(z) G(z):表示将隐码(隐向量) z z z 映射到数据空间的生成器函数。函数 G ( z ) G(z) G(z) 的目标是将服从高斯分布的随机噪声 z z z 通过生成网络变换为近似于真实分布 p d a t a ( x ) p_{data}(x) pdata(x) 的数据分布,我们希望找到 θ θ θ 使得 p G ( x ; θ ) p_{G}(x;\theta) pG(x;θ) 和 p d a t a ( x ) p_{data}(x) pdata(x) 尽可能的接近,其中 θ \theta θ 代表网络参数。
D ( G ( z ) ) D(G(z)) D(G(z)) 表示生成器 G G G 生成的假图像被判定为真实图像的概率,如Generative Adversarial Nets中所述, D D D 和 G G G 在进行一场博弈, D D D 想要最大程度的正确分类真图像与假图像,也就是参数 log D ( x ) \log D(x) logD(x);而 G G G 试图欺骗 D D D 来最小化假图像被识别到的概率,也就是参数 log ( 1 − D ( G ( z ) ) ) \log(1−D(G(z))) log(1−D(G(z)))。因此GAN的损失函数为:
min G max D V ( D , G ) = E x ∼ p d a t a ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \min\limits_{G}\max\limits_{D} V(D,G)=E_{x\sim p_{data}\;\,(x)}[\log D(x)]+E_{z\sim p_{z}\,(z)}[\log (1-D(G(z)))] GminDmaxV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
从理论上讲,此博弈游戏的平衡点是 p G ( x ; θ ) = p d a t a ( x ) p_{G}(x;\theta) = p_{data}(x) pG(x;θ)=pdata(x),此时判别器会随机猜测输入是真图像还是假图像。下面我们简要说明生成器和判别器的博弈过程:
- 在训练刚开始的时候,生成器和判别器的质量都比较差,生成器会随机生成一个数据分布。
- 判别器通过求取梯度和损失函数对网络进行优化,将靠近真实数据分布的数据判定为1,将靠近生成器生成出来数据分布的数据判定为0。
- 生成器通过优化,生成出更加贴近真实数据分布的数据。
- 生成器所生成的数据和真实数据达到相同的分布,此时判别器的输出为1/2。
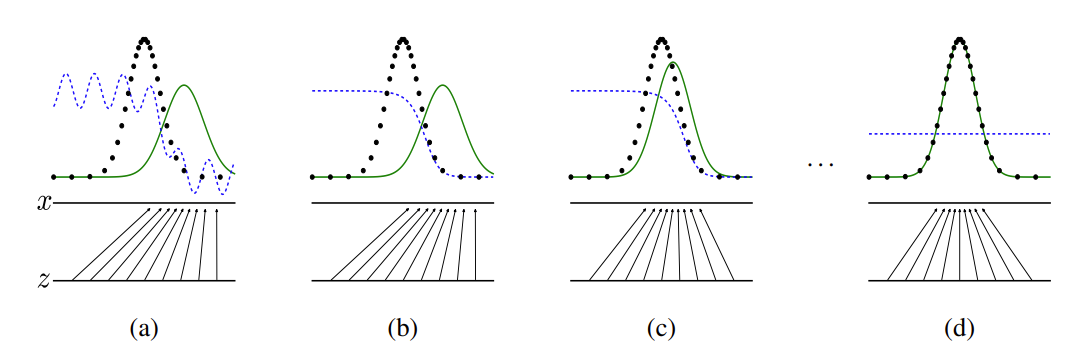
在上图中,蓝色虚线表示判别器,黑色虚线表示真实数据分布,绿色实线表示生成器生成的虚假数据分布, z z z 表示隐码, x x x 表示生成的虚假图像 G ( z ) G(z) G(z)。该图片来源于Generative Adversarial Nets。详细的训练方法介绍见原论文。
数据集
数据集简介
MNIST手写数字数据集是NIST数据集的子集,共有70000张手写数字图片,包含60000张训练样本和10000张测试样本,数字图片为二进制文件,图片大小为28*28,单通道。图片已经预先进行了尺寸归一化和中心化处理。
本案例将使用MNIST手写数字数据集来训练一个生成式对抗网络,使用该网络模拟生成手写数字图片。
数据集下载
使用download接口下载数据集,并将下载后的数据集自动解压到当前目录下。数据下载之前需要使用pip install download安装download包。
下载解压后的数据集目录结构如下:
./MNIST_Data/
├─ train
│ ├─ train-images-idx3-ubyte
│ └─ train-labels-idx1-ubyte
└─ test
├─ t10k-images-idx3-ubyte
└─ t10k-labels-idx1-ubyte
数据加载
使用MindSpore自己的MnistDatase接口,读取和解析MNIST数据集的源文件构建数据集。然后对数据进行一些前处理。
数据集可视化
通过create_dict_iterator函数将数据转换成字典迭代器,然后使用matplotlib模块可视化部分训练数据。
隐码构造
为了跟踪生成器的学习进度,我们在训练的过程中的每轮迭代结束后,将一组固定的遵循高斯分布的隐码test_noise输入到生成器中,通过固定隐码所生成的图像效果来评估生成器的好坏。
模型构建
本案例实现中所搭建的 GAN 模型结构与原论文中提出的 GAN 结构大致相同,但由于所用数据集 MNIST 为单通道小尺寸图片,可识别参数少,便于训练,我们在判别器和生成器中采用全连接网络架构和 ReLU 激活函数即可达到令人满意的效果,且省略了原论文中用于减少参数的 Dropout 策略和可学习激活函数 Maxout。
生成器
生成器 Generator 的功能是将隐码映射到数据空间。由于数据是图像,这一过程也会创建与真实图像大小相同的灰度图像(或 RGB 彩色图像)。在本案例演示中,该功能通过五层 Dense 全连接层来完成的,每层都与 BatchNorm1d 批归一化层和 ReLU 激活层配对,输出数据会经过 Tanh 函数,使其返回 [-1,1] 的数据范围内。注意实例化生成器之后需要修改参数的名称,不然静态图模式下会报错。
判别器
如前所述,判别器 Discriminator 是一个二分类网络模型,输出判定该图像为真实图的概率。主要通过一系列的 Dense 层和 LeakyReLU 层对其进行处理,最后通过 Sigmoid 激活函数,使其返回 [0, 1] 的数据范围内,得到最终概率。注意实例化判别器之后需要修改参数的名称,不然静态图模式下会报错。
损失函数和优化器
定义了 Generator 和 Discriminator 后,损失函数使用MindSpore中二进制交叉熵损失函数BCELoss ;这里生成器和判别器都是使用Adam优化器,但是需要构建两个不同名称的优化器,分别用于更新两个模型的参数,详情见下文代码。注意优化器的参数名称也需要修改。
模型训练
训练分为两个主要部分。
第一部分是训练判别器。训练判别器的目的是最大程度地提高判别图像真伪的概率。按照原论文的方法,通过提高其随机梯度来更新判别器,最大化 l o g D ( x ) + l o g ( 1 − D ( G ( z ) ) log D(x) + log(1 - D(G(z)) logD(x)+log(1−D(G(z)) 的值。
第二部分是训练生成器。如论文所述,最小化 l o g ( 1 − D ( G ( z ) ) ) log(1 - D(G(z))) log(1−D(G(z))) 来训练生成器,以产生更好的虚假图像。
在这两个部分中,分别获取训练过程中的损失,并在每轮迭代结束时进行测试,将隐码批量推送到生成器中,以直观地跟踪生成器 Generator 的训练效果。
模型推理
下面我们通过加载生成器网络模型参数文件来生成图像,代码如下:
import mindspore as ms
# test_ckpt = './result/checkpoints/Generator199.ckpt'
# parameter = ms.load_checkpoint(test_ckpt)
# ms.load_param_into_net(net_g, parameter)
# 模型生成结果
test_data = Tensor(np.random.normal(0, 1, (25, 100)).astype(np.float32))
images = net_g(test_data).transpose(0, 2, 3, 1).asnumpy()
# 结果展示
fig = plt.figure(figsize=(3, 3), dpi=120)
for i in range(25):
fig.add_subplot(5, 5, i + 1)
plt.axis("off")
plt.imshow(images[i].squeeze(), cmap="gray")
plt.show()
总结
因为实践营的机器是虚拟机器,资源有限,所以有时训练和推理会卡住或者很慢,可以重新启动一次jupyter试试

















 1017
1017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











