







刚学python不久,写了一个自己认为还比较简单易懂“爬取图片的方式,并保存本地指定路径下”。我爬取的内容是“Yestone邑石网”的部分图片链接如下,https://www.yestone.com/gallery/1501754333627
爬取的页面如图1所示。
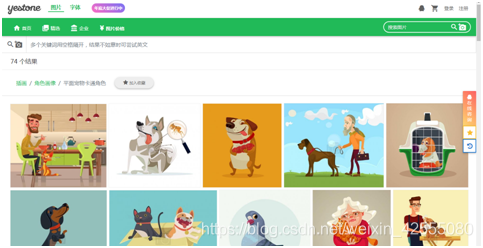
图1
爬取的Python代码如下
import requests
from bs4 import BeautifulSoup #注释1
from PIL import Image #注释2
import os
from io import BytesIO #注释3
import time
url = "http://www.yestone.com/gallery/1501754333627"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36"}#注释4
response = requests.get(url, headers=headers)#注释5
soup = BeautifulSoup(response.content, 'html.parser') #注释6
items = soup.find_all('img', class_='img-responsive') #注释7
#定义一个相对路径
folder_path = './photo'#注释8
if os.path.exists(folder_path) == False:#注释9
os.makedirs(folder_path)#注释10
for index, item in enumerate(items):
if item:
html = requests.get(item.get('data-src'))
img_name = folder_path + str(index+1) + '.png' #注释11
image = Image.open(BytesIO(html.content)) #注释12
image.save('C:/Users/Administrator/PycharmProjects/staticCrawlWord/pratice/photo'+img_name)#注释13
print('第%d张图片下载完成' % (index + 1))#注释14
time.sleep(1) # 自定义延时
print('抓取完成')
结果如下所示在指定文件夹下会依次写入图片文件,如图2所示:
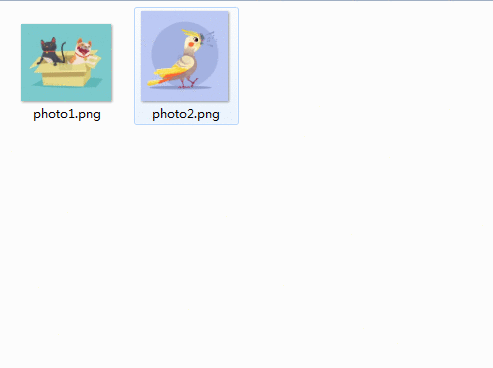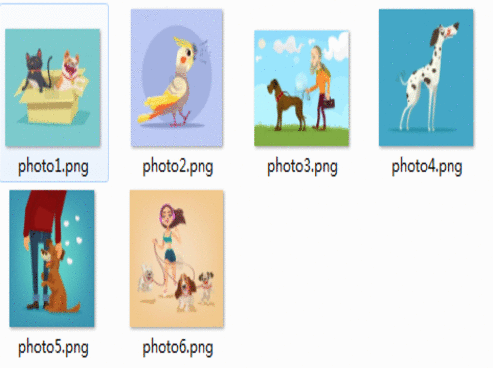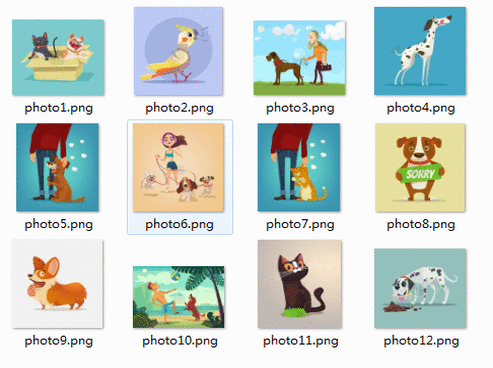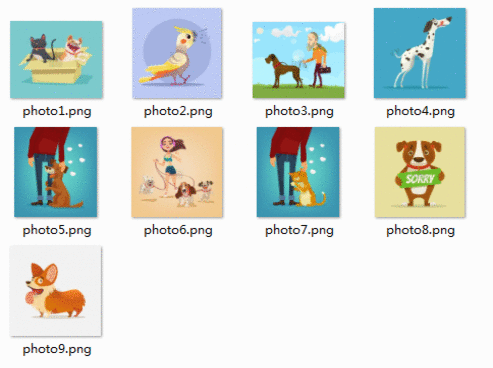
图2
详解
接下来我们对注释部分的内容进行讲解:
1) 注释1——Beautifulsoup库
我们先来看看它的官方定义:
BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库。它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。Beautiful Soup会帮你节省数小时甚至数天的工作时间。(解释来自Beautiful Soup 4.2.0 文档(若链接无法打开,请访问https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html))
简单的说,Beautifulsoup就是一个用来解析网页的模块,由于Beautifulsoup 3已经停止维护,Beautifulsoup模块迁移到bs4,因此,我们需要在命令行输入pip install bs4来完成Beautifulsoup模块的安装,完成后使用from bs4 import BeautifulSoup进行调用。
2) 注释2——PIL库
PIL(Python Image Library)是python的第三方图像处理库,但是由于其强大的功能与众多的使用人数,几乎已经被认为是python官方图像处理库了。其官方主页为:PIL。 PIL历史悠久,原来是只支持python2.x的版本的,后来出现了移植到python3的库
pillow,pillow号称是friendly fork for PIL,其功能和PIL差不多,但是支持python3。本文主要介绍PIL那些最常用的特性与用法,主要参考自:http://www.effbot.org/imagingbook。如果当然也可以参阅此CSDN文章:https://www.cnblogs.com/lyrichu/p/9124504.html
3) 注释3——BytesIO
BytesIO库的主要作用就是实现了在内存中读写bytes。具体内容可以参考一下CSDN文章:https://blog.csdn.net/u012084802/article/details/79464205
从网络上获取图片并保存到本地的方法很多,其中之一就是利用
PIL+requests+BytesIo,如下代码:
import requests
from PIL import Image
from io import BytesIO
response = requests.get(img_src)
image = Image.open(BytesIO(response.content))
image.save('D:/9.jpg')
这种方法就是将url从网上get下来,然后利用PIL,通过open打开和save保存,之前看到大多就是image.show(),而并没有讲这么保存,这个我试了一下,就是会打开这个image的图片,后来看到这篇matplotlib和PIL库的使用 (网址如下:http://www.jb51.net/article/102981.htm )的时候,看到原来只要save就可以了,参数就是你要保存的文件名。
注意,这个BytesIO是必须的,它是用来操作二进制数据的,图片就是二进制数据了,和它相对的自然是StringIO,这是用来存str的。他们的区别就好似python读写普通文件和二进制文件。
4) 注释4——headers
访问网址的时候HTTP请求的头文件里都会包含一个User-Agent,这个关键字的解释如下:
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。(解释源自百度百科 - “用户代理”)
在爬虫里,UA就好比一张通行证,通过伪装UA标识,可以让某些爬虫检测机制将你的爬虫当做一个用浏览器访问其网页的自然人,在错误的判断下,便不对这个爬虫进行反爬虫的操作(关于反爬虫在后面的文章里我会仔细说明)。当然要真正的达到”通行”的目的,可能要做的远不止如此。headers就是刚才所说的HTTP请求里的头文件,如果将UA比喻成通行证,那么headers就是你的爬虫的档案,它包含了访问者的设备信息,语言信息,编码信息,请求来源信息等各种内容,它同样可以伪装,让你的爬虫变成一个”清白”的访问者,从而让服务器返回正确的内容,爬虫顺利的爬取各种想要的资源。UA是这个档案里的一条内容。通常情况下,在获取某些get请求的内容而非post请求的内容时,我们只需要将UA修改成一般浏览器的UA就好了,无需增加其他关键字。
5) 注释5——requests.get()
response便是通过向目标服务器进行请求后获得的响应对象,它作为一个对象,包含了服务器的响应的全部内容,就好比派遣一个间谍去获得敌人的内部资料,间谍得手后成功返回,所有的资料都保存在间谍的身上,那么这个间谍就是这个响应对象,我们可以从间谍口中得到任何想知道的内容。(比喻可能不太恰当)然后,如果我们想要获得response对象(一个包含指定URL全部HTML内容的对象)里面的内容,我们可以做一些其他方法或者库的操作。
6) 注释6——BeautifulSoup()
这里新建了一个Beautifulsoup对象,它有两个必要的参数,第一个参数是HTML代码对象,比如这里content存储了URL为” http://www.yestone.com/gallery/1501754333627“
的这张网页的HTML代码,它是个字符串或者是一个文件句柄第二个参数是HTML解析器,这个解析器可以使用内置标准的”html.parser“,也可以安装第三方的解析器,比如lxml和html5lib。(如表1是几种解析器的对比)
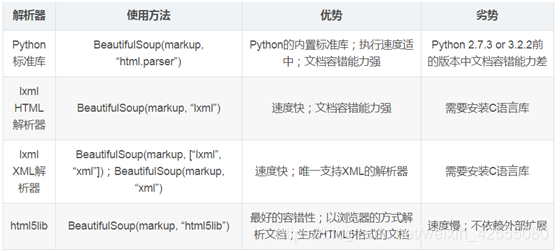
表1
7) 注释7——find_all()
这里使用了soup对象的一个方法”find_all()“,字面理解就是”找出所有的“,那么找出什么,如何定位这个所谓的”什么”?这里就要传入两个参数,第一个是HTML文档的节点名,也可以理解为HTML的标签名;第二个则是该节点的class类名,比如上面代码中,我要找出该网页上所有的img节点,且我需要的img节点的类名为”img-resonsive”。但是对于一些没有class类名的HTML元素我们该如何寻找?
我们还可以用到另一个属性:attrs,比如这里可以写成:
img_list = soup.find_all(name=‘img’, attrs={‘class’: ‘height_min’})
attrs是字典类型,冒号左边为关键字,右边为关键字的值。不一定要通过class来查找某一个元素,也可以通过比如”id”,”name”,”type”等各种HTML的属性,如果想要的元素实在没有其他属性,可以先定位到该元素的父属性,再使用”.children“定位到该元素。更多Beautifulsoup的高级用法请参考上面的”Beautiful Soup 4.2.0 文档
“https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
参看find_all()方法的链接如下:find_all官方文档说明https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/#find-all
8) 注释8——定义相对路径
我使用’./photo’定义了一个和运行代码同一个文件夹下的名为photo的文件夹
另外:
- “/”:表示根目录,在windows系统下表示某个盘的根目录,如“E:\”;
- “./”:表示当前目录;(表示当前目录时,也可以去掉“./”,直接写文件名或者下级目录)
- “…/”:表示上级目录。
在Python中可以使用os.getcwd()函数获得当前的路径。
其原型如下所示:os.getcwd()
该函数不需要传递参数,它返回当前的目录。需要说明的是,当前目录并不是指脚本所在的目录,而是所运行脚本的目录。
>>>import o
>>>print os.getcwd()
返回值为 D:\Program Files\Python27
这里的目录即是python的安装目录。若把上面的两行语句保存为getcwd.py,保存于E:\python\盘,运行后显示是E:\python
9) 注释9 10——os.path.exists()和os.makedirs()
分别是判断文件是否存在和建立文件夹的方法。内容可以参考一下链接:http://www.runoob.com/python3/python3-os-file-methods.html
10) 注释11——img_name
定义了一个文件名
11) 注释12 13——Image.open和Image.save函数
分别是读取并将数据写入指定文件夹下的函数
在Python中可以使用os.listdir()函数获得指定目录中的内容。
其原型如下所示:
os.listdir(path)
其参数path 为要获得内容目录的路径。
>>> import os
>>> print os.listdir(os.getcwd())
结果为:['photo1.png', 'photo10.png', 'photo11.png', 'photo12.png', 'photo13.png', 'photo14.png', 'photo15.png'……]
>
12) 注释14打印在console控制台的内容
小结:
本篇文章是关于爬取图片并保存到本地,用到的Python IDE是PyCharm,使用到的Python库是Requests+PIL+BytesIO+BeautifulSoup(这些Python库都可以在Pycharm上通过file》setting中添加到),通过对比修改,算是一种较为简单的爬取方法,里面的内容,如果不合适或者是错误的地方,欢迎大佬们批评指导。

















 1890
1890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









