







一、前言
本案例作为大数据框架在公共安全领域应用实践的开篇之作,将从最基础的数据架构体系优化讲起。在接下来的章节里将详细描述Kafka的基本原理、Kafka增强组件以及基于Kafka的Lambda架构的具体应用场景以及相应的研发成果。
Lambda架构由Storm的作者Nathan Marz提出。旨在设计出一个能满足。实时大数据系统关键特性的架构,具有高容错、低延时和可扩展等特。
Lambda架构整合离线计算和实时计算,融合不可变(Immutability,读写分离和隔离 一系列构原则,可集成Hadoop,Kafka,Storm,Spark,HBase等各类大数据组件。 大数据系统的关键问题:如何实时地在任意大数据集上进行查询?大数据再加上实时计算,问题的难度比较大。Lambda架构通过分解的三层架构来解决该问题:Batch Layer,Speed Layer和Serving Layer。如下图所示意。
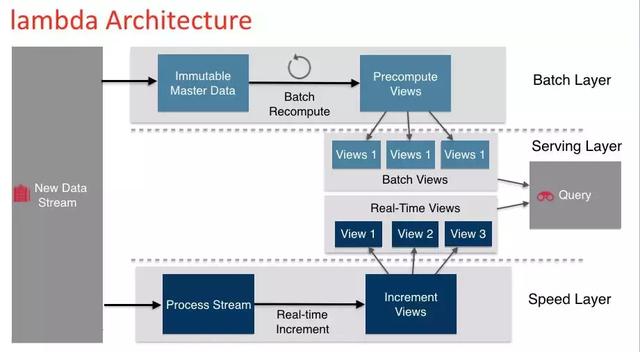
图1.1 Lambda架构图
数据流进入系统后,同时发往Batch Layer和Speed Layer处理。Batch Layer以不可变模型离线存储所有数据集,通过在全体数据集上不断重新计算构建查询所对应的Batch Views。Speed Layer处理增量的实时数据流,不断更新查询所对应的Real time Views。Serving Layer响应用户的查询请求,合并Batch View和Real time View中的结果数据集到最终的数据集。
二、基于Kafka的Lambda架构
2.1 某省大数据平台实践案例
以某省厅大数据建设方案为例,将Kafka作为统一的数据流通道(data pipeline)。Kafka分为地市和省厅两级,地市数据首先经过流式化处理发送到地市的Kafka,经过标准化后,地市Kafka的再汇集到省厅Kafka。

某省大数据平台实践
2.2 引入Kafka的必要性
在大数据系统中,常常会碰到一个问题,整个大数据是由各个子系统组成,数据需要在各个子系统中高性能、低延迟的不停流转。传统的企业消息系统并不是非常适合大规模的数据处理。容易造成日志数据难以收集,容易丢失信息,Oracle实例之间的管道无法供其它系统使用,数据架构易创建难扩展,数据质量差等问题。为了同时搞定在线应用(消息)和离线应用(数据文件,日志),Kafka就出现了。Kafka可以起到两个作用:
• 降低系统组网复杂度。
• 降低编程复杂度,各个子系统不再是相互协商接口,各个子系统类似插口插在插座上,Kafka承担高速数据总线的作用。
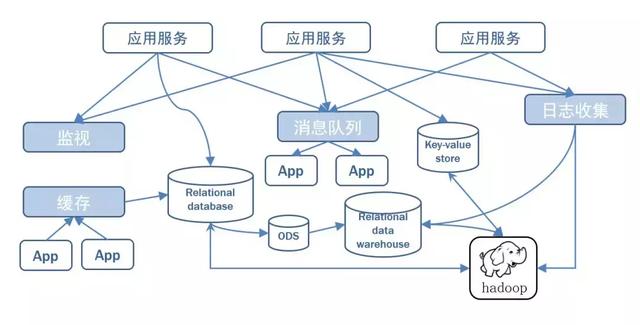
传统数据架构
引入Kafka后,可以构建以流为中心数据架构。Kafka是作为一个全局数据管道。每个系统都向这个中心管道发送数据或者从中获取数据。应用程序或流处理程序可以接入管道并创建新的派生流。这些派生流又可以供其它各种系统使用。
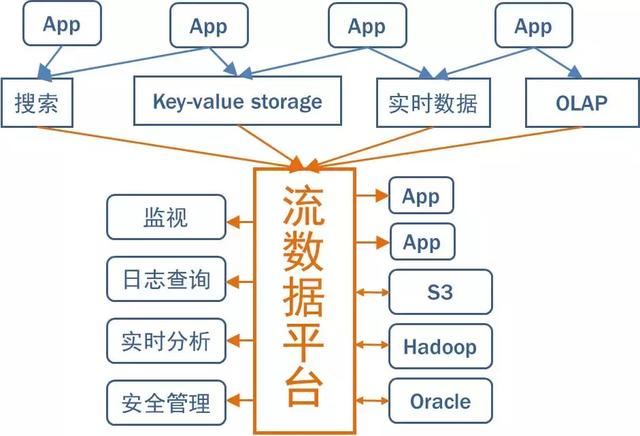
以流为中心的数据架构
三、Kafka技术分析
3.1 Kafka的特点
Kafka可以让合适的数据以合适的形式出现在合适的地方。Kafka的做法是提供消息队列,让生产者单往队列的末尾添加数据,让多个消费者从队列里面依次读取数据然后自行处理。

Kafka消息队列
• 分布式系统,易于向外扩展。所有的producer、broker和consumer都会有多个,均为分布式的。无需停机即可扩展机器。</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 265
265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









