







基础普及: https://zhuanlan.zhihu.com/p/25928551
综述类(有不同算法在各数据集上的性能对比):
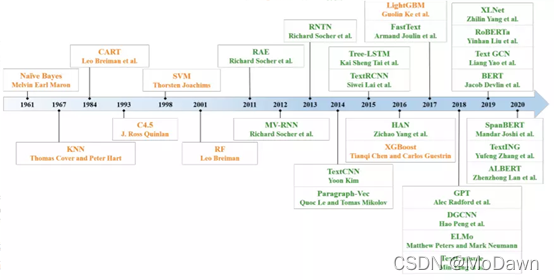
Deep Learning Based Text Classification:A Comprehensive Review(20.04)
A Survey on Text Classification: From Shallow to Deep Learning(20.08)
复现: https://github.com/wellinxu/nlp_store
总体步骤:输入文档 -> 预处理 -> 文本表示 -> 分类器 -> 类别输出
主要流程:预处理模型的文本数据;
浅层学习模型通常需要通过人工方法获得良好的样本特征,然后使用经典的机器学习算法对其进行分类,其有效性在很大程度上受到特征提取的限制;
而深度学习通过学习一组非线性变换将特征工程直接集成到输出中,从而将特征工程集成到模型拟合过程中。
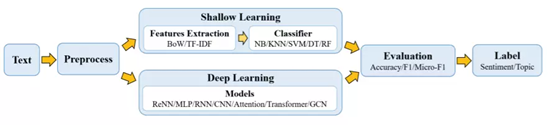
浅层学习仍然需要进行耗时又昂贵的功能设计,还通常会忽略文本数据中的自然顺序结构或上下文信息,使学习单词的语义信息变得困难,适用于小数据集。
深度学习方法避免了人工设计规则和功能,并自动为文本挖掘提供了语义上有意义的表示形式,文本分类只是其下游NLP任务之一。它是数据驱动的方法,具有很高的计算复杂性,较浅层模型难以解释其原因和工作方式。需提高其语义表示能力和鲁棒性。
常见应用:垃圾邮件识别、情感分类(SA)、新闻分类(NC)、主题分析(TL)、
问答(QA)、对话行为分类(DAC)、自然语言推理(NLI)、事件预测(EP)
类别:二分类、多分类、多标签分类;机器学习、深度学习
一、预处理
分词、去停用词(中文)、词性标注(多省略)、数据清理和数据统计
分析输入数据集,对其进行分类(如单标签,多标签,无监督,不平衡的数据集,多章,短文本,跨语言,多标签,少样本文本,包含术语词汇)
分词方法:基于字符串匹配、基于理解、
基于统计:N元文法模型(N-gram),最大熵模型(ME),
隐马尔可夫模型(Hidden Markov Model ,HMM),
条件随机场模型(Conditional Random Fields,CRF)等

句子化为等长:对于不同长度的文本,太短的就补空格,太长的就截断(利用pad_sequence 函数,也可以自己写代码pad)
数据增强:分为shuffle和drop两种,前者打乱词顺序,后者随机的删除掉某些词。有助于提升数据的差异性,对基于词word的模型有一定提升,但对于基于字char的模型可能起副作用。
二、文本表示
文本向量化 -> 向量空间模型(vecto rspace model,VSM)
- 文档、项/特征项、项的权重
向量的相似性度量(similarity)
- 相似系数Sim(D1,D2)指两个文档内容的相关程度(degree of relevance)
- 可借助n维空间中两个向量之间的某种距离来表示,常用的方法是使用向量之间的内积。如果考虑向量的归一化,则可使用两个向量夹角的余弦值来表示。
文本特征选择(常用方法)
- 基于文档频率(document frequency, DF)的特征提取法
- 信息增益(information gain, IG)法(依据为分类提供的信息量来衡量重要程度)
- χ2统计量(CHI)法(越高,与该类之间的相关性越大,携带的类别信息越多)
- 互信息(mutual information, MI)方法(越大,特征和类别共现的程度越大)
特征权重计算方法
- 一般方法是利用文本的统计信息,主要是词频,给特征项赋予一定的权重。
- 倒排文档频度(inverse document frequency, IDF)法、TF-IDF法(变种:TFC法和ITC法)、TF-IWF(inverse word fr
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









