









chatGPT 所用的GPT模型,最早的模型是GPT1。
今天,我们来详解GPT1的论文 Improving Language Understanding by Generative Pre-Training
论文可以从下面链接下载:https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
这是一篇2018年的论文。谁能想到,在2022年大方异彩,震惊世界的GPT 模型, 它的第一篇论文,讲的GPT 1模型,在2018年时投稿了好多次,但却没有会议或者期刊接收,如果当年openAI的人放弃了GPT模型,或许人类会错失这次生产力大发展的机会?
这篇论文的题目是,通过生成式预训练提升语言模型的理解能力。
在“生成式预训练”中,“生成式”通常指的是一种模型训练的方法,其中模型被训练来生成类似于输入数据的输出。在自然语言处理领域,生成式模型通常指的是能够生成文本或者语言的模型,例如生成式对话模型或生成式语言模型。在“Improving Language Understanding by Generative Pre-Training”中,生成式预训练意味着使用生成式模型进行预训练,以提高对语言的理解能力。
自然语言理解涵盖了各种不同的任务,如文本蕴涵、问答、语义相似度评估和文档分类等。尽管大量的无标注文本语料库很丰富,但用于学习这些特定任务的标注数据却很少,这使得判别式训练模型难以表现出色。openAI团队证明,通过对丰富的无标注文本语料库进行生成式语言模型的预训练,然后在每个特定任务上进行判别式微调,可以实现在这些任务上的显著提升。与以往的方法不同,openAI团队在微调过程中利用了任务感知的输入转换,以实现有效的迁移学习,同时最小程度地改变模型架构。openAI团队在自然语言理解的各种基准测试上展示了其方法的有效性。openAI团队的通用任务-无关模型(一种不针对特定任务的模型,它可以用于各种不同的任务和领域)在9个研究中的12个任务中超越了专门为每个任务设计的判别式训练模型,在其中9个任务中显著改进了现有技术水平。例如,在常识推理上取得了8.9%的绝对改进,在问答上取得了5.7%的改进,在文本蕴涵上取得了1.5%的改进。
openAI说他们的工作广泛地属于自然语言处理的半监督学习范畴。这一领域最早的方法利用未标记数据来计算单词级或短语级的统计信息,然后将其作为监督模型中的特征。然而这样的方法主要是传递单词级信息,而openAI的目标是捕捉更高层次的语义。GPT1的方法,无监督预训练,是半监督学习的一种特殊情况,其目标是找到一个良好的初始化点,而不是修改监督学习的目标。之前的研究发现,预训练作为一种正则化方案,使深度神经网络能够更好地泛化。
训练过程包括两个步骤。第一步从大量的文字中学习一个大语言模型,第二步对不同的任务用监督学习的方法使模型适应不同的任务。
第一步,无监督预训练
给定一个未标记的标记语料库 U = {u1, ..., un},使用标准的语言建模目标来最大化以下似然性:
L1(U) = Σi log P(ui|ui−k, ..., ui−1; θ)
这里 k 是上下文窗口的大小,条件概率 P 是使用具有参数 θ 的神经网络建模的。这些参数是使用随机梯度下降进行训练的。
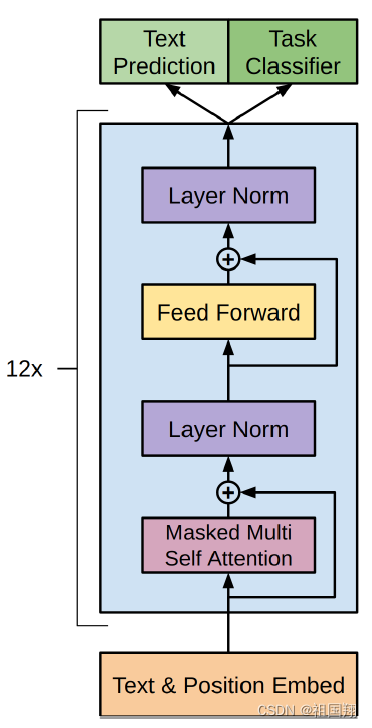
用无监督学习的方法预训练一个语言模型,使用了一个多层Transformer解码器(Transformer的一个变种)作为语言模型。该模型对输入上下文应用了多头自注意力操作,然后经过逐位置的前馈层生成目标标记的输出分布。
第二步,监督微调
无监督预训练之后,调整参数以适应监督目标任务。假设有一个标记的数据集C,其中每个实例由一系列输入标记x1,...,xm以及一个标签y组成。输入通过预训练的模型后,得到最终的Transformer块激活hml,然后将其输入到一个添加的线性输出层,该层具有参数Wy,用于预测y: P(y|x1, ..., xm) = softmax(hml*Wy)
最大化的以下目标: L2(C) = Σ(x,y) log P(y|x1, ..., xm)
此外,openAI团队还发现将语言建模作为微调的辅助目标有助于学习,可以提高监督模型的泛化能力,以及加速收敛。具体来说,优化了以下目标(带有权重λ):
L3(C) = L2(C) + λ * L1(C)
总的来说,在微调过程中所需的额外参数仅为Wy以及分隔令牌的嵌入。
另外,一些任务特定需要输入转换
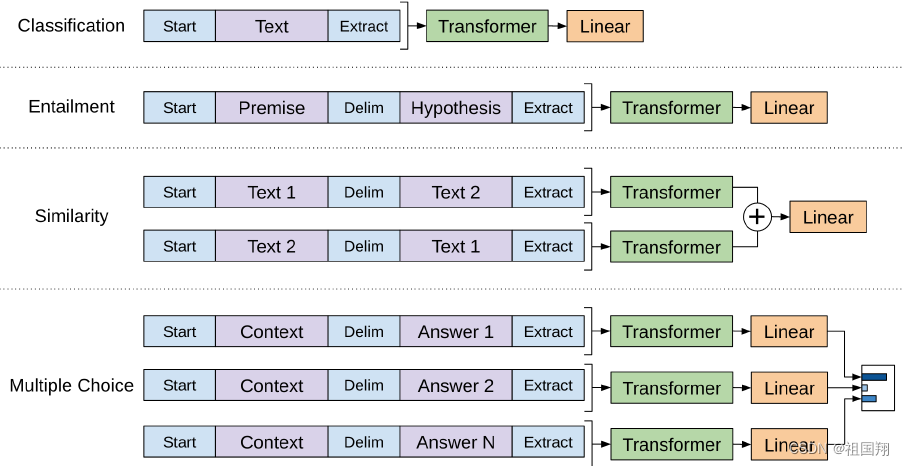
对于一些任务,比如文本分类,可以直接按照上面描述的方式对模型进行微调。而对于某些其他任务,比如问答或文本蕴涵,其具有结构化输入,例如有序的句子对或文档、问题和答案的三元组。由于预训练模型是在连续文本序列上训练的,因此需要对其进行一些修改,以适用于这些任务。先前的工作提出了在传输表示之上学习任务特定架构的方法。这种方法重新引入了大量的任务特定定制,并且不使用传输学习来进行这些额外的架构组件。相反,openAI团队采用了一种遍历式的方法,将结构化输入转换为一个有序序列,以便预训练模型可以处理。这些输入转换能够避免在不同任务之间做出大量的架构更改。所有转换都包括添加随机初始化的起始和结束令牌。
下面简要描述这些输入转换:
对于文本蕴涵任务,我们将前提p和假设h的令牌序列连接起来,中间用分隔符令牌($)分隔。
对于相似度任务,要比较的两个句子没有固有的顺序。为了反映这一点,openAI团队修改输入序列,包含两种可能的句子顺序(中间有分隔符),并独立处理每个序列,以生成两个序列表示hml,然后将它们在输入线性输出层之前进行逐元素相加。
对于问答和常识推理任务,输入是一个上下文文档z,一个问题q,以及一组可能的答案ak。openAI团队将文档上下文和问题与每个可能的答案连接起来,中间添加一个分隔符令牌,得到[z; q; $; ak]。每个序列都将独立地被模型处理,然后通过softmax层进行归一化,以生成可能答案的输出分布。
添加分隔符令牌的主要目的是为了在转换结构化输入为序列时,能够清晰地标识不同部分之间的边界。这样做有助于模型更好地理解输入的结构和关系,从而更有效地处理这些结构化输入。在某些任务中,例如文本蕴涵任务和问答任务,不同部分的分隔符可以帮助模型正确地对输入进行解释和处理,从而提高了模型的性能。因此,添加分隔符令牌有助于确保模型能够正确地理解并处理不同部分的结构化输入。
下图是GPT1使用的Transformer架构和训练目标
下图演示了在不同任务上进行微调的转换。将所有结构化输入转换为标记序列,以便由预训练的模型处理,然后接上一个线性加softmax层。
关于具体训练,openAI团队使用BooksCorpus数据集来对语言模型进行预训练。该数据集包含超过7,000本未发表的书籍,涵盖了各种类型的作品,包括冒险、奇幻和言情小说。最重要的是,它包含了连续文本的长篇章节,这使得生成模型能够学习对长程信息进行条件化。
GPT1模型在很大程度上遵循了最初的Transformer工作。openAI团队训练了一个12层的仅解码Transformer,其中包括掩码的自注意力头(768维状态和12个注意力头)。对于位置感知的前馈网络,使用了3072维的内部状态。采用了Adam优化方案,最大学习率为2.5e-4。学习率在前2000次更新中线性增加到零,然后按照余弦退火到零。使用64个随机抽样的连续序列,每个序列包含512个标记,进行100个epoch的小批量训练。由于layernorm在整个模型中被广泛使用,因此简单的权重初始化N(0; 0:02)就足够了。使用了一个包含40,000次合并的字节对编码(BPE)词汇表,以及残差、嵌入和注意力的丢失率为0.1,用于正则化。还采用了L2正则化的修改版本,其中所有非偏置或增益权重的w = 0:01。对于激活函数,使用了高斯错误线性单元(GELU)。使用了学习的位置嵌入,而不是最初的工作中提出的正弦版本。使用ftfy库2清理BooksCorpus中的原始文本,标准化一些标点符号和空格,并使用spaCy分词器。
除非另有说明,会重用无监督预训练的超参数设置。向分类器添加了丢失率为0.1的丢失率。对于大多数任务,我们使用学习率为6.25e-5和批量大小为32。模型参数优化速度很快,对于大多数情况,进行3个epoch的训练就足够了。使用线性学习率衰减计划,在训练的0.2%时间内进行预热。参数 λ 设置为0.5。
总的来说,GPT1是一种通过生成式预训练和判别式微调实现强大自然语言理解的框架。通过在包含大段连续文本的多样语料库上进行预训练,模型获得了丰富的世界知识和处理长距离依赖的能力,然后成功地将这些能力转移到解决问题回答、语义相似度评估、蕴涵判定和文本分类等判别任务上,提高了所研究的12个数据集中的9个的最新技术水平。















 18万+
18万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









