









chatGPT 来自于 GPT3.5, GPT3.5 是在GPT3 的 基础上做微调,而GPT3基于GPT2, GPT2基于GPT1, GPT1 最终是 基于 Transformer。
Transformer 其实不仅仅是 chatGPT 背后的技术,Transformer是当今几乎所有先进模型(包括大模型)的核心,今天我就带你搞懂Transformer,Let's go!
Transformer 论文 题目叫 Attention Is All You Need, 翻译成中文叫“你需要的只是注意力”。
这是一篇2017年的谷歌团队的论文,在这篇论文之前,主要的序列化模型都是基于循环神经网络或者卷积神经网络,包括编码器和解码器。性能最佳的模型还通过注意机制连接编码器和解码器。这篇论文提出了一种新的简单网络架构,即Transformer,完全基于注意机制(这也是为什么论文标题叫“你需要的只是注意力”),不再使用循环和卷积。
循环模型通常沿着输入和输出序列的符号位置对计算进行分解。将位置与计算时间步骤对齐,它们生成一系列隐藏状态 ht,而ht作为前一个隐藏状态 ht-1 和位置 t 的输入的函数。这种固有的顺序特性导致在训练时无法并行化。
这篇论文提出了Transformer,这是一种模型架构,它摒弃了循环模型,而是完全依赖注意机制来绘制输入和输出之间的全局依赖关系。Transformer允许更大规模的并行化。
模型具体架构:
大多数有竞争力的神经序列转换模型都具有编码器-解码器结构。在这种结构中,编码器将输入符号表示的序列 (x1; :::; xn) 映射到连续表示的序列 z = (z1; :::; zn)。给定 z,解码器便逐个元素地生成输出序列 (y1; :::; ym)。在每个步骤中,模型都是自回归的,在生成下一个元素时,使用先前生成的信号作为额外的输入。Transformer遵循这种整体架构,编码器和解码器都使用堆叠的自注意力和逐点全连接层,编码器和解码器分别显示在下图的左半部分和右半部分。
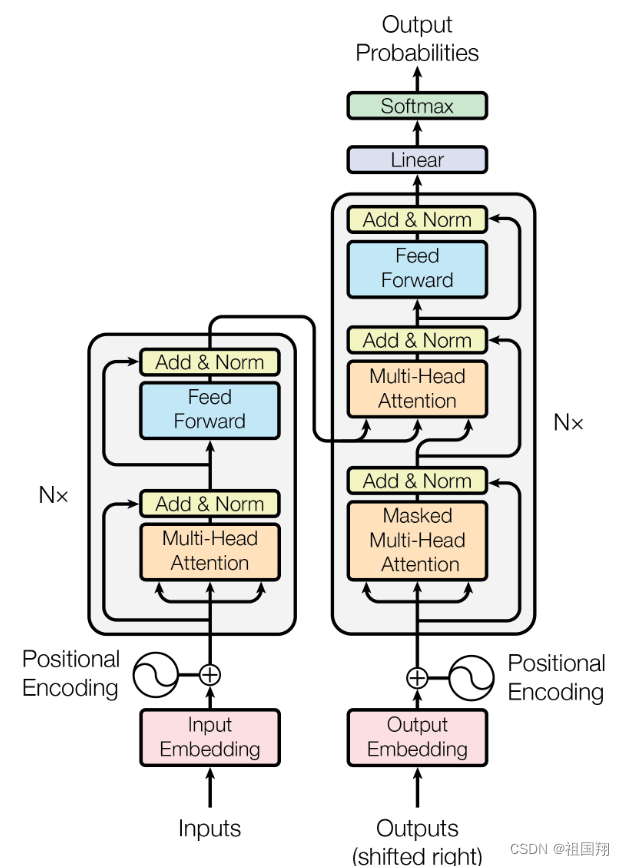
编码器:编码器由 N = 6 个相同的层堆叠而成。每一层包括两个子层。第一个是多头自注意力机制,第二个是简单的逐位置全连接前馈网络。作者在这两个子层周围采用了残差连接,然后进行层归一化。也就是说,每个子层的输出是LayerNorm(x + Sublayer(x)),其中 Sublayer(x) 是子层本身实现的函数。为了方便这些残差连接,模型中所有的子层以及嵌入层都会产生维度为 dmodel = 512 的输出。
解码器:解码器同样由 N = 6 个相同的层组成。除了每个编码器层中的两个子层外,解码器还插入了第三个子层(放在两层的中间),用于对编码器堆栈的输出执行多头注意力。与编码器类似,作者在每个子层周围采用了残差连接,然后进行层归一化。作者还修改了解码器堆栈中的自注意子层,以防止前面的位置的信息受后续位置信息的影响。这种屏蔽操作,结合输出嵌入向后偏移一个位置,确保了位置 i 的预测只能依赖于位置小于 i 的已知输出。
层归一化是一种用于神经网络中的正则化技术,它的作用是对神经网络中每一层的输出进行归一化处理,以防止训练过程中出现梯度消失或梯度爆炸等问题。在每一层的输出上应用层归一化,可以使得网络对输入数据的变化更加鲁棒,有助于提高训练的稳定性。层归一化会计算每一层输出的均值和方差,并使用这些统计量来对输出进行归一化处理,使得输出的均值接近于0,方差接近于1。这有助于加速网络的收敛过程,并提高模型对输入数据的适应性。
一个注意力函数可以被描述为将一个查询和一组键-值对映射到一个输出的过程,其中查询、键、值和输出都是向量。输出是值的加权和,其中分配给每个值的权重是由查询与相应键的兼容性函数计算得到的。
在 Transformer 模型中,兼容性函数选择的是缩放点积(scaled dot-product),所以Transformer 模型中的注意力称为缩放点积注意力。
输入由维度为 dk 的查询和键组成,以及维度为 dv 的值。作者计算查询与所有键的点积,将每个点积除以 sqrt(dk),并应用 softmax 函数以获得值的权重。
在实践中,作者同时对一组查询进行注意力函数的计算,将它们打包成一个矩阵 Q。键和值也被打包成矩阵 K 和 V。计算输出矩阵如下:
Attention(Q, K, V) = softmax((QK^T) / sqrt(dk))V
缩放点积注意力示意图如下:

类似于卷积神经网络的多层卷积核,注意力也可以有多个来同时学习不同的信息,于是就变成了多头注意力。
具体的,相比于对dmodel 维的查询、键和数值执行一个注意力函数,作者发现通过使用不同的线性投影(线性投影矩阵需要学习)将查询、键和数值投影到 dk、dk 和 dv 维度上(各自投影 h 次),能带来益处。在每个投影版本的查询、键和数值上,并行执行注意力函数,得到 dv 维度的输出数值。然后将这些输出数值进行串联,再次进行投影,得到最终的数值,如下图所示:
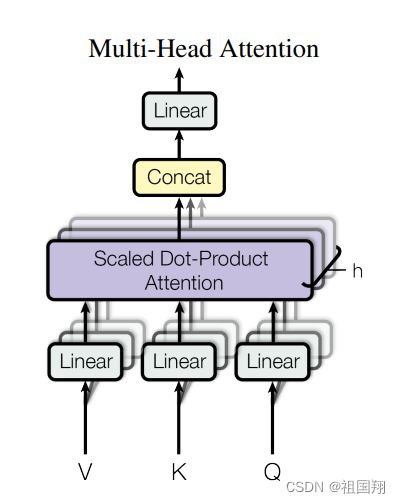
多头注意力公式表示如下:

在这篇论文中,h=8,dk=dv=dmodel/h=64
多头注意力使模型能够在不同位置同时关注来自不同表示子空间的信息。使用单个注意力头会抑制这一效果。
Transformer 模型在三种不同的方式中使用多头注意力:
• 在“编码器-解码器注意力”层中,查询来自前一个解码器层,而内存的键和数值来自编码器的输出。这使得解码器中的每个位置都可以关注输入序列中的所有位置。
• 编码器包含自注意力层。在自注意力层中,所有的键、数值和查询都来自同一个地方,即编码器中前一层的输出。编码器中的每个位置都可以关注编码器前一层的所有位置。
• 同样,解码器中的自注意力层允许解码器中的每个位置关注解码器中包括直到该位置在内的所有位置。需要防止解码器中的左侧信息流动,以维持自回归特性,确保生成的每个位置的输出只依赖于其左侧已生成的部分输出,而不依赖于右侧的信息。这样可以确保生成的序列满足自回归的特性。作者通过在缩放点积注意力内部实现这一点,通过将所有与非法连接对应的输入值屏蔽掉(设置为-∞)。
阅读这段,要对照Transformer 模型图,边读边看边理解,因此把模型图再放一下,方便对照查看:

除了注意力子层外,编码器和解码器中的每一层都包含一个全连接的前馈网络,该网络分别和相同地应用于每个位置。这个前馈网络由两个线性变换和它们之间的ReLU激活函数组成。
FFN(x) = max(0, xW1 + b1)W2 + b2
虽然线性变换在不同位置上是相同的,但它们在层与层之间使用不同的参数。 输入和输出的维度是dmodel = 512,内层的维度是dff = 2048。
与其他序列转换模型类似,transformer使用学习到的嵌入来将输入标记和输出标记转换为维度为dmodel的向量。transformer还使用通常的学习线性变换和softmax函数来将解码器的输出转换为预测的下一个标记的概率。两个嵌入层和预softmax线性变换之间共享相同的权重矩阵。在嵌入层中,这些权重乘以sqrt(dmodel)。
模型不包含循环和卷积,为了让模型能够利用序列的顺序,必须注入关于序列中标记的相对或绝对位置的一些信息。为此,作者在编码器和解码器堆栈的底部添加了“位置编码”到输入嵌入中。位置编码具有与嵌入相同的维度dmodel,以便二者可以相加。有许多选择的位置编码,包括学习的和固定的。
在这项工作中,作者使用不同频率的正弦和余弦函数:
PE(pos,2i) = sin(pos/10000^(2i/dmodel))
PE(pos,2i+1) = cos(pos/10000^(2i/dmodel))
这里,pos是位置,i是维度。也就是说,位置编码的每个维度对应一个正弦波。波长从2π到10000·2π形成一个几何级数。作者选择这个函数是因为作者猜想它会让模型很容易学会根据相对位置进行注意,因为对于任何固定的偏移k,PE(pos+k)可以表示为PE(pos)的线性函数。
作者还尝试使用了学习的位置嵌入,发现两个版本产生的结果几乎相同。作者选择了正弦版本,因为这可能使模型能够推广到比训练时遇到的序列长度更长的情况。
训练:
训练的数据集有英德数据集和英法数据集,需要注意,transformer 是为了翻译任务而研发的,就是适用于序列到序列的模型,连作者都没想到,transformer后来会如此通用。
使用了Adam优化器,其中β1 = 0.9,β2 = 0.98,ε = 10^-9。根据以下公式随着训练的进行改变学习率:lrate = dmodel^-0.5 · min(step_num^-0.5, step_num ·warmup_steps^-1.5)
这意味着在前warmup_steps个训练步骤中,学习率将线性增加,之后将按照步数的倒数平方根成比例地减小。使用了warmup_steps = 4000。
正则化: 残差丢弃(Residual Dropout)作者团队对每个子层的输出应用了丢弃(dropout),在将其添加到子层输入并进行归一化之前。此外,还对编码器和解码器堆栈中的嵌入和位置编码的总和应用了丢弃。对于基本模型,使用了丢弃率Pdrop = 0.1。
总结:
在这项工作中,作者提出了Transformer,这是第一个完全基于注意力机制的序列转导模型,用多头自注意力机制取代了在编码器-解码器架构中常用的循环层。
对于翻译任务,Transformer的训练速度可以显著快于基于循环或卷积层的架构。在WMT 2014英德翻译和WMT 2014英法翻译任务中,取得了新的最先进水平。
作者用于训练和评估模型的代码可在在以下网址查看 GitHub - tensorflow/tensor2tensor: Library of deep learning models and datasets designed to make deep learning more accessible and accelerate ML research.















 296
296











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









