






1、统计出/etc/passwd文件中其默认shell为非/sbin/nologin的用户个数,并将用户都显示出来
grep -v "/sbin/nologin" /etc/passwd | cut -d: -f1 #显示默认shell为非/sbin/nologin的用户

grep -v "/sbin/nologin" /etc/passwd | cut -d: -f1 | wc -l #默认shell为非/sbin/nologin的用户个数

2、查出用户UID最大值的用户名、UID及shell类型
cat /etc/passwd | sort -t: -k3 -nr |head -n1 |cut -d: -f1,3,7

3、统计当前连接本机的每个远程主机IP的连接数,并按从大到小排序
netstat -nt | grep "tcp" | tr -s " " ":" | cut -d: -f6 | uniq -c |sort -nr

4、编写脚本 createuser.sh,实现如下功能:使用一个用户名做为参数,如果 指定参数的用户存在,就显示其存在,否则添加之;显示添加的用户的id号等 信息
#!/bin/bash
User=$1
Color="\033[1;$[RANDOM%7+31]m"
ColorEnd="\033[0m"
id $User &>/dev/null && echo "User $User already exists" || (useradd $User && echo "User $User was created successfully") && echo -e "The $User information is $Color`id $User`$ColorEnd"

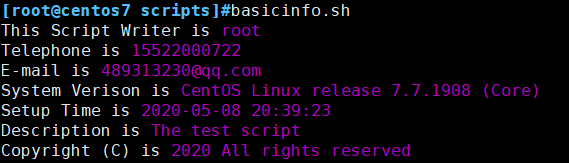
5、编写生成脚本基本格式的脚本,包括作者,联系方式,版本,时间,描述等
#!/bin/bash
Color='\033[$[RANDOM%7+31]m'
ColorEnd='\033[0m'
echo -e "This Script Writer is $Color$USER$ColorEnd"
echo -e "Telephone is $Color`echo 15522000722`$ColorEnd"
echo -e "E-mail is $Color`echo 489313230@qq.com`$ColorEnd"
echo -e "System Verison is $Color`cat /etc/redhat-release`$ColorEnd"
echo -e "Setup Time is $Color`date '+%F %T'`$ColorEnd"
echo -e "Description is $Color`echo The test script`$ColorEnd"
echo -e "Copyright (C) is $Color`date +%Y` All rights reserved$ColorEnd"
文本处理命令
cut 显示文件或STDIN数据的指定列
cut [OPTION]... [FILE]...
-d DELIMITER: 指明分隔符,默认tab
-f FILEDS:
#: 第#个字段
#,#[,#]:离散的多个字段,例如1,3,6
#-#:连续的多个字段, 例如1-6
混合使用:1-3,7
-c 按字符切割
--output-delimiter=STRING指定输出分隔符
显示文本前或后行内容
head [OPTION]... [FILE]...
-c # 指定获取前#字节
-n # 指定获取前#行
-# 指定行数
tail [OPTION]... [FILE]...
-c # 指定获取后#字节
-n # 指定获取后#行
-# 同上
-f 跟踪显示文件fd新追加的内容,常用日志监控 相当于 --follow=descriptor
-F 跟踪文件名,相当于--follow=name --retry
文本排序sort
sort [options] file(s)
-r 执行反方向(由上至下)整理
-R 随机排序
-n 执行按数字大小整理
-f 选项忽略(fold)字符串中的字符大小写
-u 选项(独特,unique)删除输出中的重复行
-t c 选项使用c做为字段界定符
-k X 选项按照使用c字符分隔的X列来整理能够使用多次
uniq 从输入中删除前后相接的重复的行
uniq [OPTION]... [FILE]...
-c: 显示每行重复出现的次数
-d: 仅显示重复过的行
-u: 仅显示不曾重复的行
注:连续且完全相同方为重复
grep 文本搜索工具
grep [OPTIONS] PATTERN [FILE...]
--color=auto: 对匹配到的文本着色显示
-m # 匹配#次后停止
-v 显示不被pattern匹配到的行
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
-A # after, 后#行
-B # before, 前#行
-C # context, 前后各#行
-e 实现多个选项间的逻辑or关系
grep –e ‘cat ’ -e ‘dog’ file
-w 匹配整个单词
-E 使用ERE
-F 相当于fgrep,不支持正则表达式
-f file 根据模式文件处理















 2214
2214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









