






声明: 此文章仅限于记录学习之用 , 受限于自身水平和理解能力 , 因此结论可能是不正确的. 如果您需要学习,建议参考其他文章
看了下网上一些大佬的教程, 写的云山雾绕的. 简单总结下吧. 以言简意赅为主.
介绍下hash
hash 就是把任意输入通过算法生成一个int值. 这个值就是放数据的地址, 然后在这个地址中存储数据.
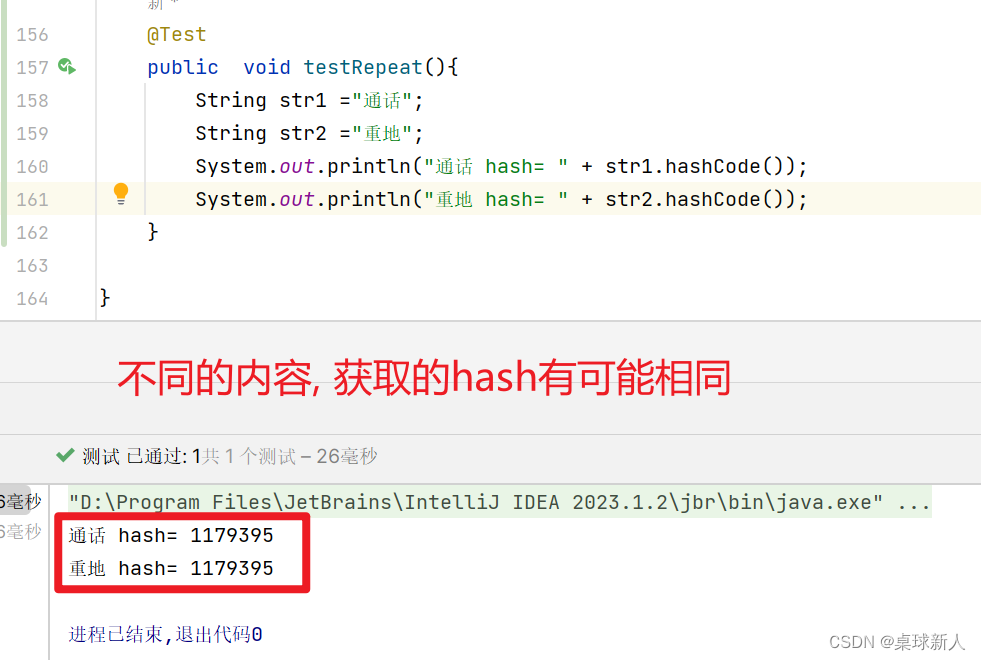
注意: 不同的内容可能生成相同的哈希码, 这就是我们常说的hash冲突. 如何处理hash冲突问题,衍生了以下几套经典算法.
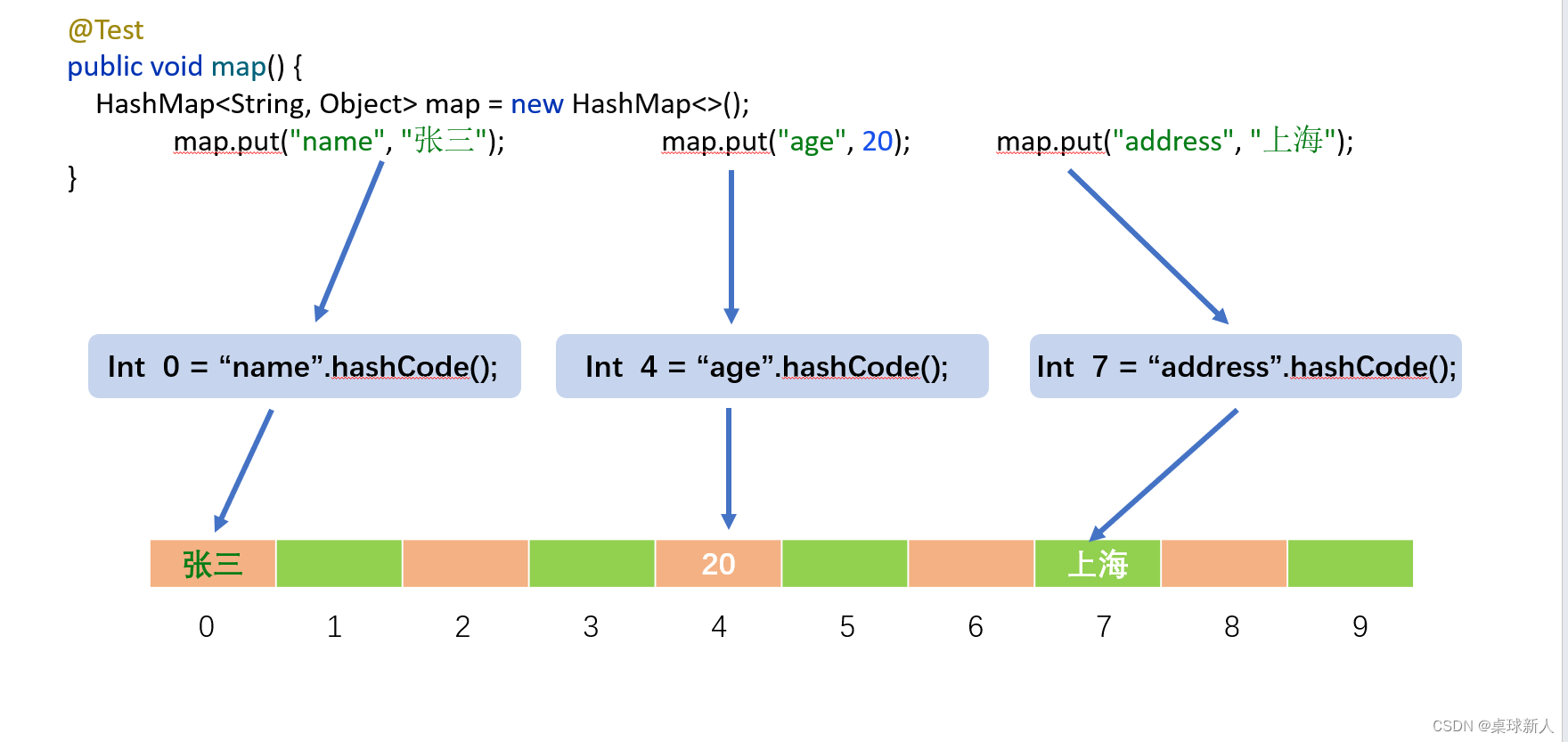
使用演示hashMap 存取的过程.
根据key获取到 hashCode, 取到内存地址, 然后把value存入此区域.
获取值也是同样道理.
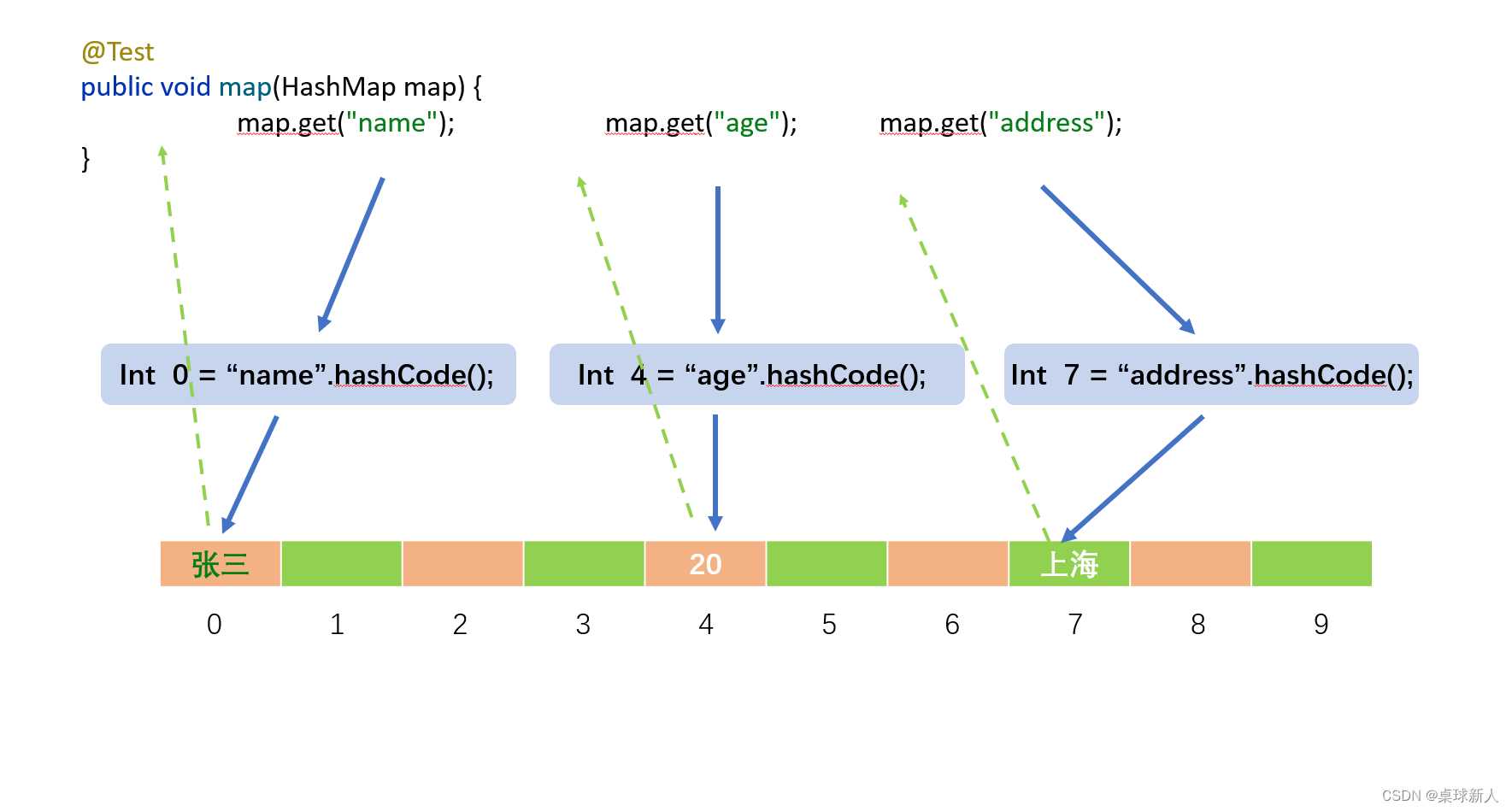
上图是最简易的hash存取示范. 结合刚刚说的"不同内容的hashCode可能相同", 因此是有hash冲突覆盖的情况.
解决hash冲突的常见方式
拉链寻址算法
从名字入手,可以更好的理解. 众所周知除了阿里巴巴喜欢胡乱造词, 大部分命名都有比较贴切的含义. 我看了下示例代码, 原来"拉链"不是衣服上的拉锁. 而是增加了y轴维度. 如果地址相同, 那就纵向排列. 拼多多这图最适合.

示例代码
package hash_table;
import java.util.LinkedList;
/**
* 拉链寻址的优点是可以有效地处理大量的哈希冲突,因为每个槽都可以包含一个链表,可以容纳更多的元素。
* 然而,它也有一些缺点。
* 例如,如果哈希表中有许多空槽,则可能会浪费大量内存,因为它需要为每个槽分配空间以存储链表头指针.
* 此外,如果链表变得很长,则搜索元素所需的时间可能会增加。
* @param <K>
* @param <V>
*/
public class HashMapBySeparateChaining<K, V> {
//定义一个存储链表的数组
private final LinkedList<Node<K, V>>[] arr = new LinkedList[8];
/**
* 插入元素:首先计算元素的哈希值,并将其存储在哈希表中的相应槽中。然后,将元素添加到该槽中的链表中。
* @param key
* @param value
*/
public void put(K key, V value) {
int index = key.hashCode() & (arr.length - 1);
//如果此地址是空的, 直接创建一个链表, 将内容存进去
if (arr[index] == null) {
arr[index] = new LinkedList<>();
arr[index].add(new Node<>(key, value));
} else {
//如果此地址已经被占用了(hashCode冲突).就在链表中新增
arr[index].add(new Node<>(key, value));
}
}
/**
* 查找元素:首先计算元素的哈希值,并找到其在哈希表中的相应槽。然后,在该槽的链表中搜索该元素。
* @param key
* @return
*/
public V get(K key) {
int idx = key.hashCode() & (arr.length - 1);
for (Node<K, V> kvNode : arr[idx]) {
if (key.equals(kvNode.getKey())) {
return kvNode.value;
}
}
return null;
}
/**
* 定义实体类
* @param <K>
* @param <V>
*/
static class Node<K, V> {
final K key;
V value;
public Node(K key, V value) {
this.key = key;
this.value = value;
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
}
}
特点
- 拉链寻址的优点是可以有效地处理大量的哈希冲突,因为每个槽都可以包含一个链表,可以容纳更多的元素。
- 然而,它也有一些缺点。
- 例如,如果哈希表中有许多空槽,则可能会浪费大量内存,因为它需要为每个槽分配空间以存储链表头指针.
- 此外,如果链表变得很长,则搜索元素所需的时间可能会增加。
开放寻址算法
开放寻址算法,开放就是没有明确划分位置的,比如公共教室的座位, 地铁的座位,火车站大厅的座椅等…就是我们理解的随便坐. 比如你去上课, 你肯定有个最喜欢的位置,一般情况就坐那. 但是你的位置被占了, 作为新时代文明青年, 你不好去赶走人家, 只能从这个位置往后找,直到找到第一个空座就直接坐下了.
你可能问为啥是找到第一个空座就坐下, 这个这个生活场景中不好解释. 但是在哈希表中是为了节约空间,减少空槽

请注意,需要把教室想象成一个哈希表(一维数组) .
示例代码
package hash_table;
import com.alibaba.fastjson.JSON;
/**
* 开放寻址是一种解决哈希表中冲突的方法。
* 当插入一个新的关键字时,如果发现该关键字对应的哈希地址已被其他关键字占用,
* 则从当前哈希地址开始,按某种探查顺序连续探测可用的空地址,直至找到一个空地址为止。
* @author Administrator
* @param <K>
* @param <V>
*/
public class HashMapByOpenAddressing<K, V> {
private final Node<K, V>[] arr = new Node[8];
public void put(K key, V value) {
int index = key.hashCode() & (arr.length - 1);
//如果此哈希地址为空,就直接存放
if (arr[index] == null) {
arr[index] = new Node<>(key, value);
} else {
//如果哈希地址被占用了, 就往后找空槽存进去
for (int i = index; i < arr.length; i++) {
if (arr[i] == null) {
arr[i] = new Node<>(key, value);
break;
}
}
}
}
public V get(K key) {
int idx = key.hashCode() & (arr.length - 1);
//从hash地址开始往后找, 直到找到后返回
for (int i = idx; i < arr.length; i++) {
if (arr[i] != null && arr[i].key == key) {
return arr[i].value;
}
}
return null;
}
static class Node<K, V> {
final K key;
V value;
public Node(K key, V value) {
this.key = key;
this.value = value;
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
}
@Override
public String toString() {
return "HashMap{" +
"arr=" + JSON.toJSONString(arr) +
'}';
}
}
特点
开放寻址的缺点很明显, 在get的时候, 如果产生hashCode冲突需要向后遍历获取, 效率太低了. 下面的合并散列来解决此问题.
合并散列
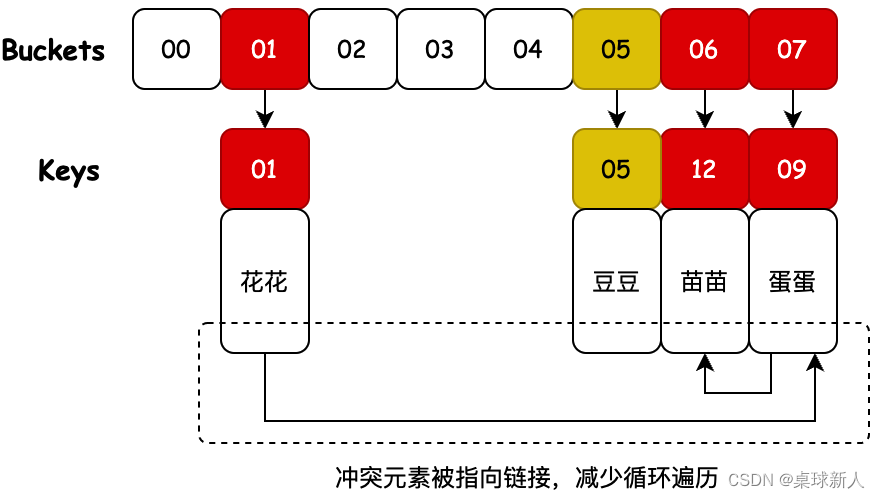
合并散列就是在开放寻址的基础上,进行了优化, 解决了查询时遍历数据效率过低的问题. 具体做法是,如果出现hashCode冲突, 向后找空槽存入, 原对象指向新对象. 表达不清晰,大家看下下图试试理解.

示例代码
package hash_table;
import com.alibaba.fastjson.JSON;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Objects;
/**
* 合并散列(Coalesced hashing)是单独链接和开放寻址的混合,其中桶或节点在表中链接。该算法非常适合固定内存分配。通过识别哈希表上索引最大的空槽来解决合并哈希中的冲突,然后将冲突值插入该槽中。桶还链接到插入节点的插槽,其中包含其冲突哈希地址。
*/
public class HashMap04ByCoalescedHashing<K, V> implements Map<K, V> {
private final Logger logger = LoggerFactory.getLogger(HashMap04ByCoalescedHashing.class);
private final Node<K, V>[] tab = new Node[8];
@Override
public void put(K key, V value) {
int idx = key.hashCode() & (tab.length - 1);
//未冲突直接保存
if (tab[idx] == null) {
tab[idx] = new Node<>(key, value);
return;
}
//key相同 value覆盖
if (Objects.equals(tab[idx].key, key)) {
tab[idx] = new Node<>(key, value);
return;
}
//hash冲突时
//找个下标
int cursor = tab.length - 1;
while (tab[cursor] != null && tab[cursor].key != key) {
--cursor;
}
//把hash冲突的元素存起来
tab[cursor] = new Node<>(key, value);
// 将碰撞节点指向这个新节点
while (tab[idx].idxOfNext != 0) {
idx = tab[idx].idxOfNext;
}
tab[idx].idxOfNext = cursor;
}
@Override
public V get(K key) {
int idx = key.hashCode() & (tab.length - 1);
while (tab[idx].key != key) {
idx = tab[idx].idxOfNext;
}
return tab[idx].value;
}
static class Node<K, V> {
final K key;
V value;
int idxOfNext;
public Node(K key, V value) {
this.key = key;
this.value = value;
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
public int getIdxOfNext() {
return idxOfNext;
}
public void setIdxOfNext(int idxOfNext) {
this.idxOfNext = idxOfNext;
}
}
@Override
public String toString() {
return "HashMap{" +
"tab=" + JSON.toJSONString(tab) +
'}';
}
}
特点
请注意,合并散列寻址并不是常见的哈希表冲突解决策略。常用的冲突解决策略包括线性探测、二次探测和链地址法等。合并散列寻址更常用于特定场景下的优化。
布谷鸟散列算法
待更新
跳房子散列算法
待更新
罗宾汉哈希算法
待更新
参考资料
图片来源
- 拉链寻址原图来自拼多多商品.
- 开放寻址原图来自中国海洋大学官网
- 合并散列原图来自大河网新闻, 小傅哥 bugstack 虫洞栈
内容来源:
部分解释参考自: https://gitcode.com/search Ai搜索
目录结构及部分算法参考自小傅哥 bugstack 虫洞栈 (技术很好,但个人感觉他教程写的着实一般)















 5262
5262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









