







python 模拟登录豆瓣爬取影评
上一篇文章我们爬取了豆瓣的中的电视剧《隐秘的角落》电视剧的短评,在爬取的过程中也许你会发现,headers信息中的cookie信息是我登陆后设置进去的,那么也给了我一些思路,是否可以通过模拟登录豆瓣之后来保存cookie呢?
说干就干!!
此教程仅用于学习,不得商业获利!如有侵害任何公司利益请告知删除!
cookie反爬虫是指服务器通过校验请求头中的cookie值来区分正常的用户和爬虫程序的手段之一。
需求分析
模拟登录豆瓣,爬取影评并做词云分析
功能分析
豆瓣在没有登录的情况下,根据之前的情况你会发现,它只允许查看前200条的数据。登录之后就可以正常访问了。
功能实现
-
模拟登录豆瓣,实现requests库保存cookie信息 -
批量抓取数据 -
词云展示
登录豆瓣
登录接口分析
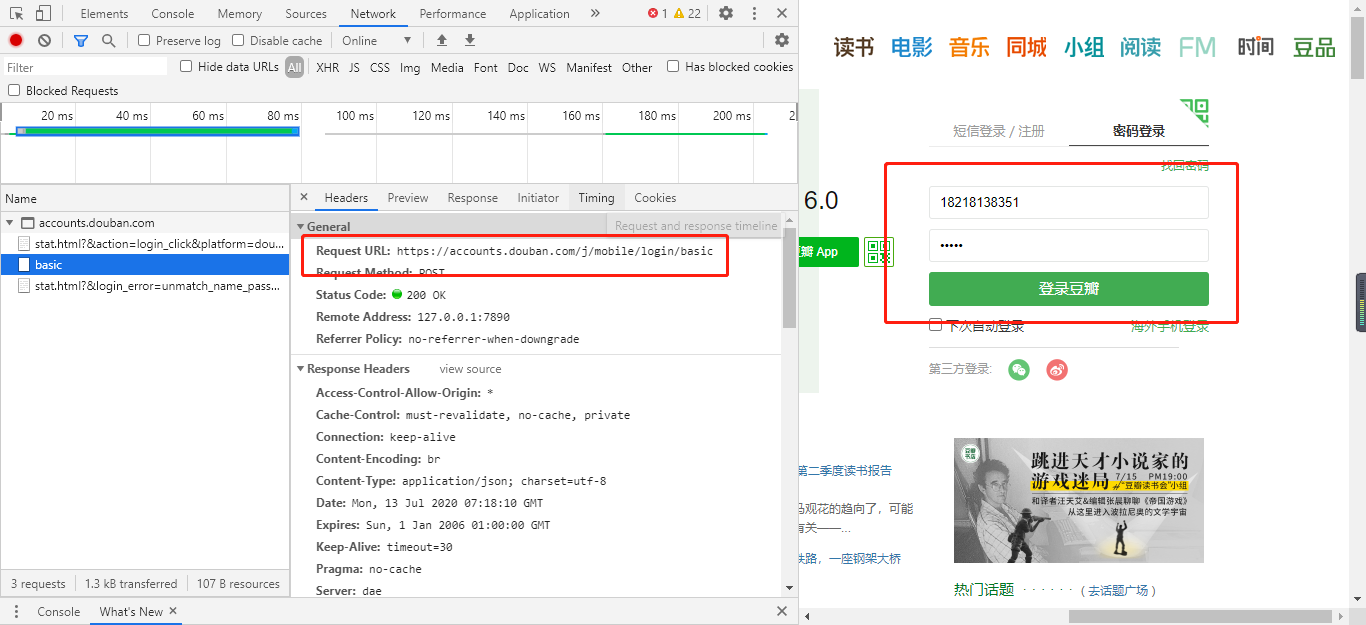
在上图,打开调试窗口,输入错误的账户名和密码,捕捉登录请求。
捕捉到的请求为:https://accounts.douban.com/j/mobile/login/basic
因为这是一个post请求,所以还需要下拉去查看请求的参数
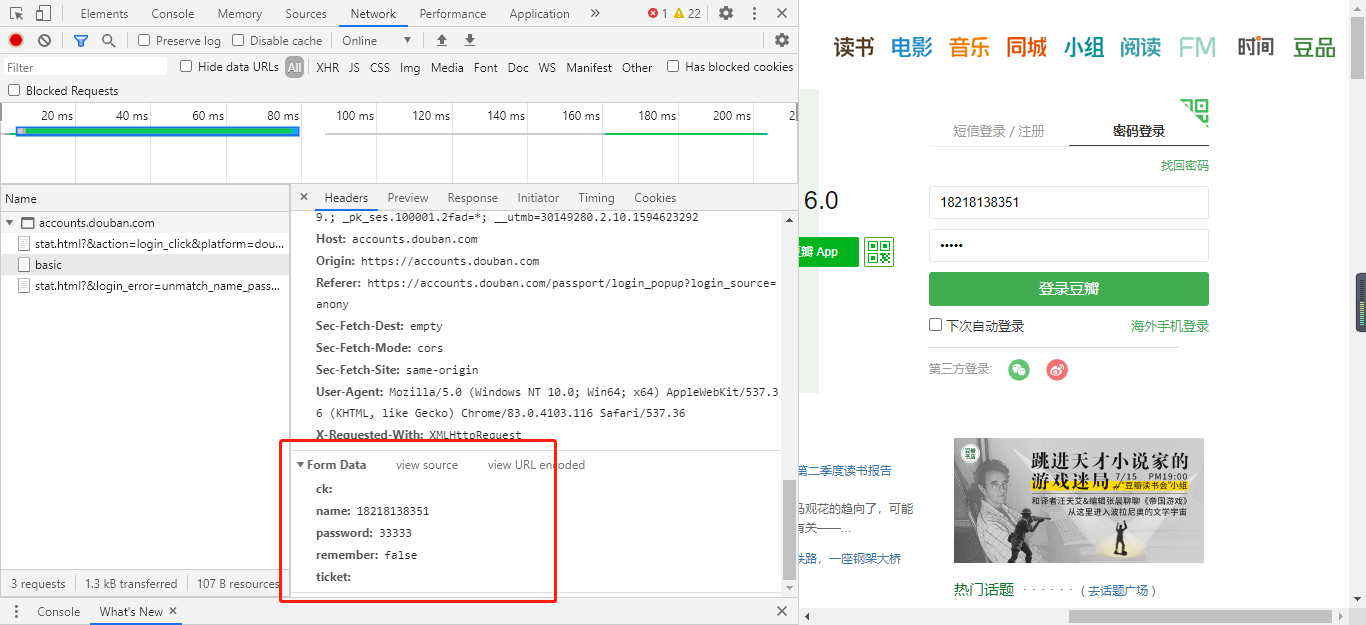
那么就可以开始写代码了
import requests
headers = {
'Referer': 'https://accounts.douban.com/passport/login_popup?login_source=anony',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}
data = {
'ck': '',
'name': '', # 输入你豆瓣的账户名
'password': '', # 输入你豆瓣的密码
'remember': 'false',
'ticket': ''
}
s = requests.Session()
def login_douban():
login_url = 'https://accounts.douban.com/j/mobile/login/basic'
try:
html = s.post(url=login_url, headers=headers, data=data).content.decode('utf-8')
print(html)
except Exception as e:
print(e)
if __name__ == '__main__':
login_douban()
这个Session是我们常说的session吗
这里要注意的就是这个requests.Session()不是我们常说的session,我们常说的session是保存在服务端中的,而现在的Session是保存cookie的对象
批量爬取评论
在批量爬取评论的时候发现,它总共有25页,所以我写了个循环,循环了25次,但是这次我想到了新的思路,这次我假设我不知道它到底有几页,我可以让程序来判断,这样可以减少很多麻烦。
在批量爬取之前也要先学会爬取第一页的评论,之前使用的是xpath,而这次使用的是re(正则表达式)
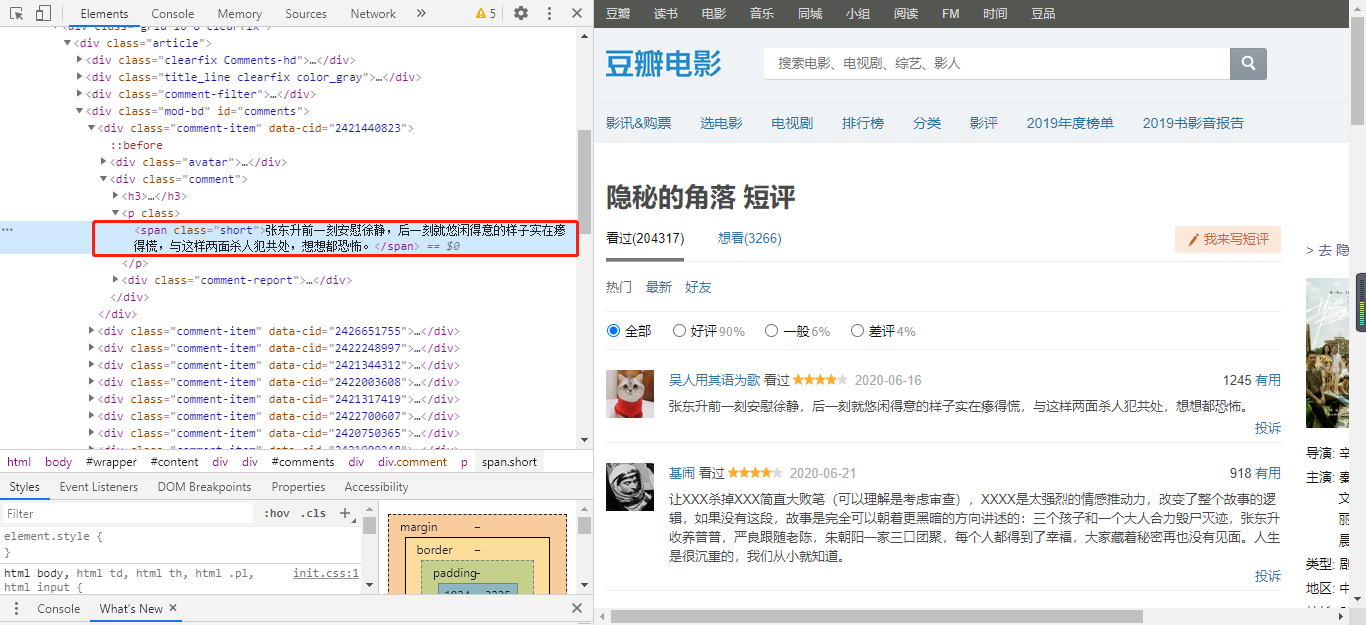
从上图可以发现我们需要的数据在span标签下,
def spider_comment(page=0):
'''
爬取某页影评
:param page: 页数
:return:
'''
print('开始爬取第%d页' % int(page))
start = int(page * 20)
comment_url = 'https://movie.douban.com/subject/33404425/comments?start=%d&limit=20' % start
try:
response = s.get(url=comment_url, headers=headers)
response.raise_for_status()
except requests.HTTPError as e:
print(e)
print('status_code', response.status_code)
return 0
except Exception as e:
print(e)
print('other')
html = response.content.decode('utf-8')
comment = re.findall('<span class="short">(.*?)</span>', html)
if not comment:
return 0
with open(COMMEMT_FILE_PAHT, 'a', encoding='utf-8') as f:
f.write('/n'.join(comment))
return 1
def batch_spider_comment():
'''
批量爬取影评
:return:
'''
# 清空之前的记录
if os.path.exists(COMMEMT_FILE_PAHT):
os.remove(COMMEMT_FILE_PAHT)
page = 0
while spider_comment(page):
page += 1
time.sleep(random.random()*3)
print('爬取完毕')
到了这我相信大家应该学会了如何使用requests模拟登录了吧,要实现批量爬取的时候也希望大家可以明白在实现批量爬取的时候需要先登录才可以
if __name__ == '__main__':
# 登录成功后批量爬取
if login_douban():
batch_spider_comment()















 376
376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









