







scrapy框架介绍
scrapy是由Python语言开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。
scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
scrapy最吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型的爬虫基类,比如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持
scrapy框架的网址:https://scrapy.org
scrapy框架运行原理

不知道大家是否还记得,在我们平时写爬虫的时候一般都是划分三个函数。
# 获取网页信息
def get_html():
pass
# 解析网页
def parse_html():
pass
# 保存数据
def save_data():
pass
这三个函数基本上没有说谁调用谁的这种说法,最后只能通过主函数来将这些函数调用起来。
很显然,我们的scrapy框架也正是这样的原理,只不过它是把这三部分的功能保存在不同的文件之中,通过scrapy引擎来调用它们。
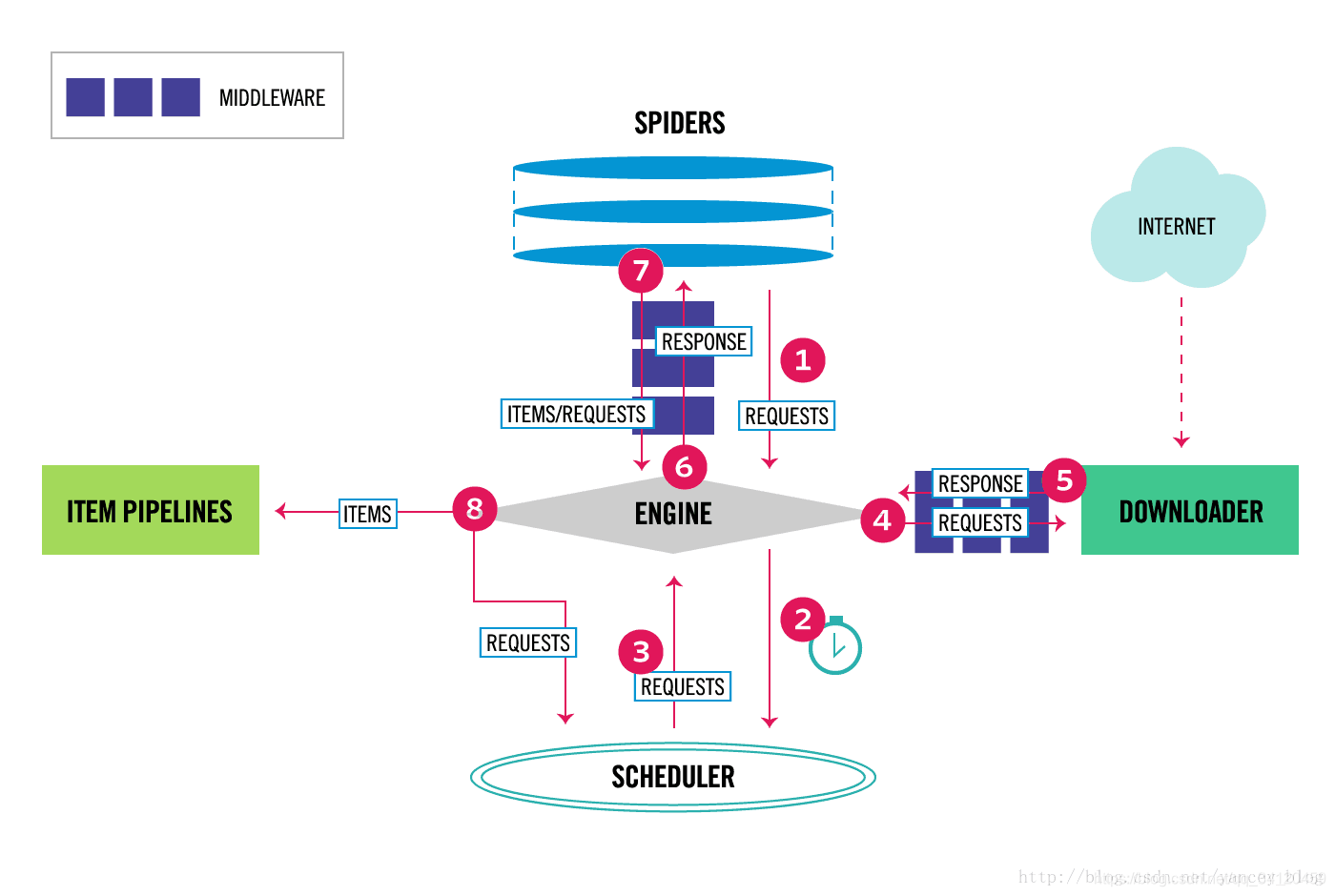
下面我就对上图中的内容做简单的描述:
- **Scrapy Engine **:负责控制数据流在系统中的所有组件的流动,并在相应动作发生时触发事件。
- Scheduler:负责从引擎接收requests并将它们入队,以便以后引擎请求它们时提供给引擎。
- Dowmloader:负责获取页面数据并提供给引擎,而后提供给spider。
- Spider:Spider是scrapy用户编写用于分析Response并提取item或者是额外跟进的URL类。每个spider处理一个特定的网站。
- Item PIpeline:负责处理被spider提取出来的item。典型的处理有清理、验证、及持久化。(例如保存到数据库)
- DowmLoader Middlewares:是在引擎与下载器之间的特定钩子,处理spider输入的Response和输出的items及requests,并提供一个便捷的机制,通过自定义代码来拓展Scrapy功能。
scrapy工作流程
当我们使用scrapy写好代码并运行的时候就会出现如下的对话。
引擎:兄弟萌,辣么无聊,爬虫搞起来啊!
Spider:好啊,老哥,早就想搞了,今天就爬xxx网站好不好?
引擎:没有问题,入口URL发过来!
Spider:呐,入口的URL是:https://www.xxx.com
引擎:调度器老弟,我这有requests请求你帮我排序入队一下吧。
调度器:引擎老哥,这是我处理好的requests
引擎:下载器老弟,你按照下载中间件的设置帮我下载一下这个requests请求
下载器:可以了,这是下载好的内容。(如果失败:sorry,这个requests下载失败了,然后引擎告诉调度器,这个requests下载失败了,你记录一下,我们待会儿再下载)
引擎:爬虫老弟,这是下载好的东西,下载器已经按照下载中间件处理过了,你自己处理一下吧。
Spider:引擎老哥,我的数据已经处理完毕了,这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的item数据。
引擎:管道老弟,我这有个item,你帮我处理一下。
引擎:调度器老弟,这是需要跟进的URL你帮我处理一下。(然后从第四步开始循环,直到获取完全部信息)
scrapy框架的安装
scrapy的安装需要Python3.6+的版本。如果你使用的是Anaconda或者Miniconda,要安装scrapy,请运行:
conda install -c conda-forge scrapy
另外,如果你已经熟悉Python安装包的安装,则可以使用以下方法:
pip install scrapy
scrapy的依赖
scrapy是用纯Python编写的,并且依赖一些关键的Python包:
- lxml:一个高效的XML和HTML解析器。
- parsel:在lxml之上编写的HTML和XML数据提取库
- w3lib:用于处理URL和网页编码的多功能帮助器
- twisted:异步网络框架
- cryptography和pyOpenSSL:处理各种网络级别的安全需求
安装完成之后可以在命令行输入:
scrapy version
scrapy框架的使用
scrapy框架的命令介绍
scrapy命令主要分为两种:全局命令和项目命令(使用Scrapy-h可以查看)
全局命令:哪里都能使用。
项目命令:必须在爬虫项目里才能够使用到。
scrapy的常用命令有:
scrapy startproject 项目名称 # 创建一个爬虫项目或工程
scrapy genspider 爬虫名 域名 # 在项目下创建一个爬虫spider类
scrapy runspider 爬虫文件 #运行一个爬虫spider类
scrapy list # 查看当前项目有多少个爬虫
scrapy crawl 爬虫名称 # 通过名称指定运行爬取信息
scrapy shell url/文件名 # 使用shell进入scrapy交互环境
更多的命令,我们可以在命令行输入
scrapy -h

使用命令的格式
使用格式:
scrapy <command> [options][args]
可用的命令
bench 测试本地硬件性能(工作原理):scrapy bench
commands
fetch 取URL使用scrapy下载
genspider 产生新的蜘蛛使用预先定义的模板
runspider 运行单独一个爬虫文件:scrapy runspider abc.py
settings 获取设置值
shell 进入交互终端,用于爬虫调试(如果你不调试,那就不常用)scrapy shell https://www.baidu.com
startproject 创建一个爬虫项目,如:scrapy startproject demo(demo 创建的爬虫项目名字)
version 查看版本(scrapy version)
view 下载一个网页源码,并在默认的文本编辑器中打开源代码:scrapy view https://www.baidu.com
scrapy框架的使用
- 使用scrapy startproject命令来创建一个爬虫项目
- 进入项目目录,创建爬虫spider类
- 进入items.py创建自己的item容器类
- 进入自定义的spider类,解析Response信息,并封装到Item中。
- 使用Item Pipline项目管道对解析出来的Item数据进行清理、验证、去重和存储
- 执行爬取命令来进行爬取信息
scrapy爬虫实战
上面的理论说再多也没有用,我们还是来用简单的例子,来学习Scrapy爬虫。
这次的实战内容,我们就来获取我爱我家的房源信息。
链接如下:
https://fang.5i5j.com/
首先我们在你要创建爬虫项目的路径输入:
scrapy startproject fangdemo
fangdemo
|—— fangdemo
| |—— __init__.py
| |—— __pycache__.
| |—— items.py # Item定义,定义抓取的数据结构
| |—— middlewares.py # 定义Spider和Dowmloader和Middlewares中间件实现
| |—— pipelines.py # 它定义Item Pipeline的实现,即定义数据管道
| |—— settings.py # 它定义项目的全局配置
| |__ spiders # 其中包含一个个Spider的实现,每个Spider都有一个文件
|—— __init__.py
|—— __pycache__
|—— scrapy.cfg # scrapy部署时的配置文件,定义了配置文件的路径、部署相关的信息内容。
当我们创建完项目之后,它会有提示,那么我们就按照它的提示继续操作。
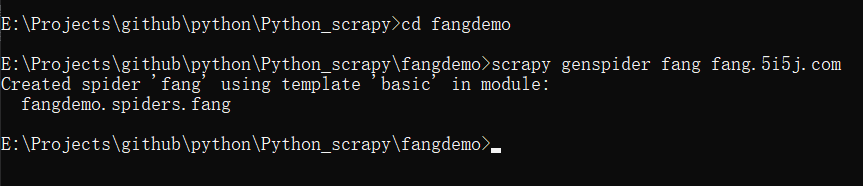
当你按照上面的操作,之后你就会发现,在spiders文件夹下就会出现fang.py这个文件。这个就是我们的爬虫文件。
接下来,我们可以在fang.py里面写一些代码进行测试。
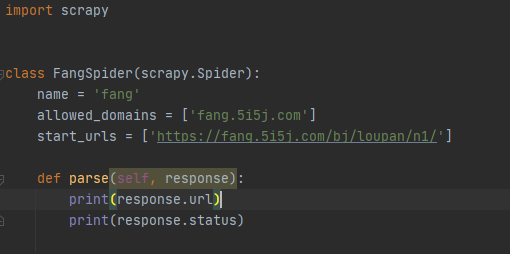
编写完毕之后可以在命令行输入:
scrapy crawl fang
在前期scrapy会有一大堆的请求准备,接下来开始爬取,最后关闭这些文件。
当然,如果你写的代码是没有bug的时候可以使用以下命令:
scrapy crawl fang --nolog
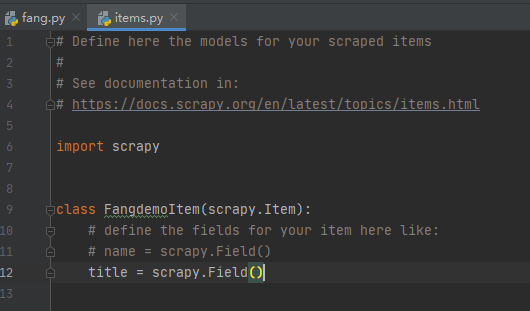
不知道大家是否还记得最前面的图片,当spider运行的时候会产生一系列的item,那么我们现在就可以选择items.py,实例化对象。
代码如下所示:
比如我们现在要获取到网页中的标题、地址与价格,如下图所示:
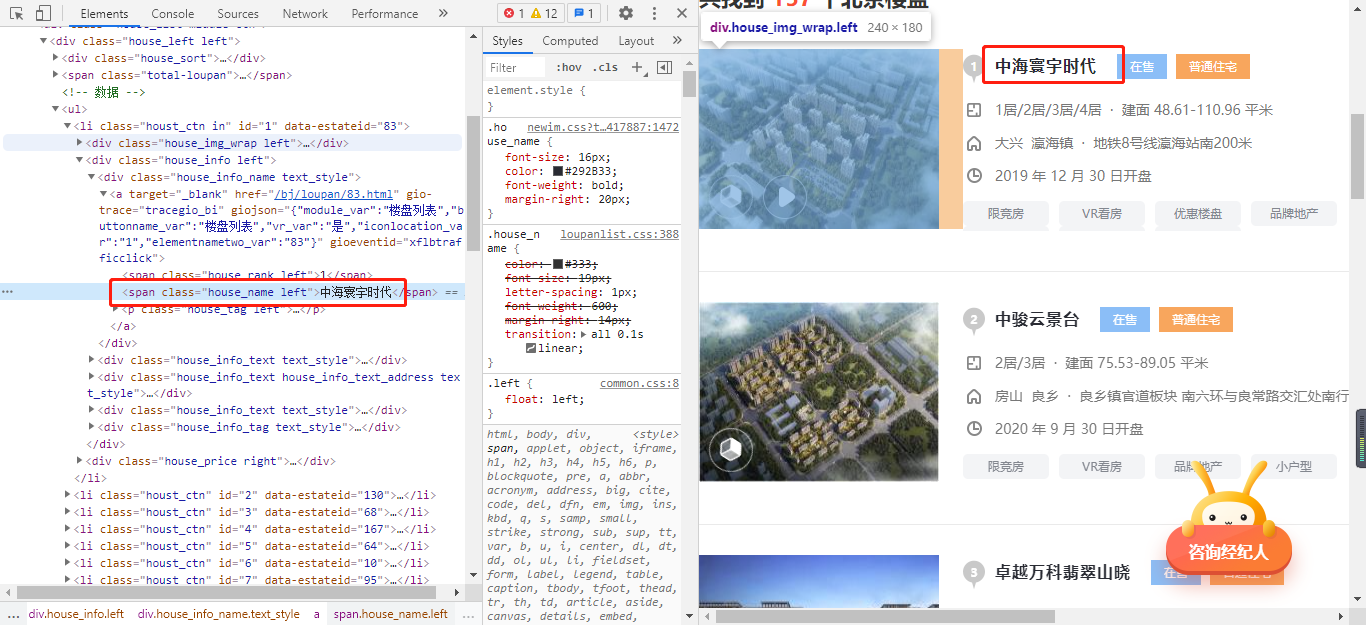
那我们可以简单的使用css解析器来提取数据。
代码如下所示:

这样,我们就可以提取出我们需要的数据了。
接下来,我们将最后一行的print(item)修改为yield item,那么接下来就会来到管道。
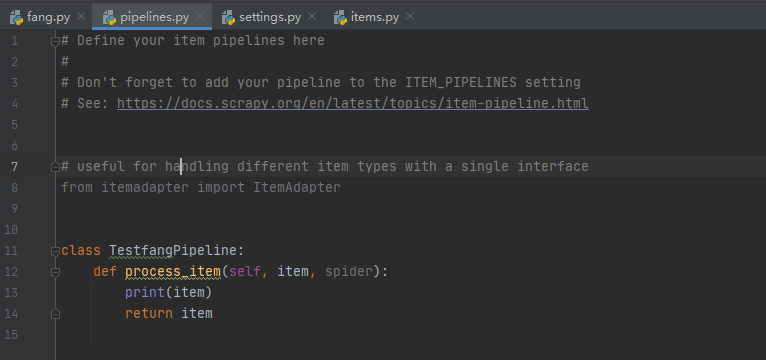
但是,在这里的Item默认是关闭的,因此我们需要到settings将其打开。
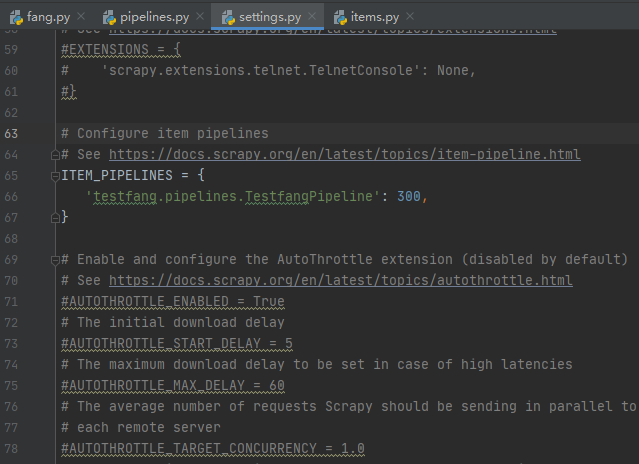
上面的内容学完之后,相信你对scrapy有大概的了解了吧。
最后
没有什么事情是可以一蹴而就的,生活如此,学习亦是如此!
因此,哪里会有什么三天速成,七天速成的说法呢?
唯有坚持,方能成功!
啃书君说:
文章的每一个字都是我用心敲出来的,只希望对得起每一位关注我的人。在文章末尾点【赞】,让我知道,你们也在为自己的学习拼搏和努力。
路漫漫其修远兮,吾将上下而求索。
我是啃书君,一个专注于学习的人,你懂的越多,你不懂的越多。更多精彩内容,我们下期再见!















 118
118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









