







简介:Lucene是Java语言开发的开源全文检索库,广泛用于搜索引擎和信息检索系统。本文档深入探讨了Lucene的核心架构、索引过程、查询解析、搜索机制和扩展优化技术。Lucene通过索引和搜索功能使开发者能够高效地处理文本数据检索。文档还介绍了Lucene在实际应用中的案例,以及如何通过学习资源和实践项目提升相关技能。 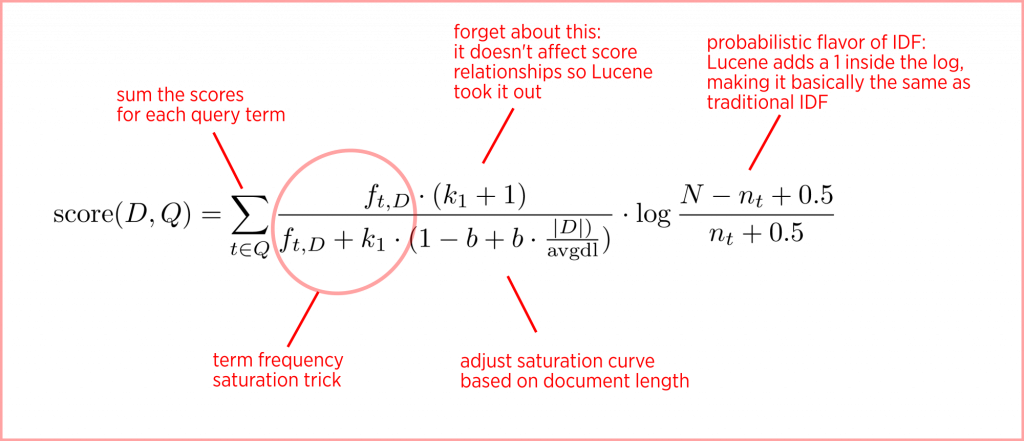
1. Lucene架构与工作原理解析
作为全文搜索引擎库,Lucene 的设计与工作原理一直是搜索技术的核心。本章将从架构层面开始,逐层剖析 Lucene 的工作原理,为深入理解其索引过程、查询机制及优化策略打下坚实的基础。
1.1 Lucene 的核心组件
Lucene 的核心组件主要包括索引器(Indexer)、搜索器(Searcher)、分析器(Analyzer)、索引存储(Index Storage)和查询解析器(Query Parser)。其中,索引器负责将文档数据转化为索引,搜索器用于执行查询并返回结果,分析器对文本进行分词处理,索引存储用于持久化索引数据,而查询解析器负责将用户输入的查询语句解析为可执行的查询对象。
1.2 工作流程概述
从用户查询到返回搜索结果,Lucene 的工作流程包括以下几个步骤:接收用户查询语句,解析查询语句,遍历索引数据,匹配并计算文档的相关性,最后返回排序后的结果列表。这个过程的效率和精确度,直接关系到用户体验和系统性能。
1.3 Lucene 的优势与挑战
Lucene 提供了强大的文本处理能力、高效的搜索速度和可扩展的索引架构,但同时也面临着优化索引数据结构、提升搜索准确性、处理大量数据时的性能挑战等问题。接下来的章节将深入探讨如何应对这些挑战。
2. 索引过程详细说明
2.1 索引的基本概念
索引是搜索引擎中非常关键的部分,它涉及到对原始数据的处理,使得搜索过程更为快速高效。索引过程的一个核心概念是分词,它是将文本数据转化为更小单位的过程,通常称为词项(Term)。
2.1.1 分词技术的原理和应用
分词技术的目的是将连续的文本分割成有意义的单词或短语。在中文处理中,分词技术尤为重要,因为中文本身不像英文那样有明显的单词分界。
在Lucene中,分词技术是通过分析器(Analyzer)来实现的。分析器负责对原始文本进行分词处理,并对分词结果进行过滤和标准化,如去除停用词、小写转换等。应用分析器的步骤如下:
- 读取原始文本 :首先,需要将原始文本作为输入。
- 分词处理 :然后使用特定的分词算法将文本切分为一系列词项。
- 词项过滤 :对分词结果进行过滤,剔除掉不必要或对搜索无帮助的词项。
- 词项标准化 :对词项进行处理,如小写转换、词干提取等。
Lucene提供了多种分析器,包括标准分析器、简单分析器、空格分析器、停用词分析器等。此外,也可以通过实现自定义的分析器来自定义分词逻辑。
2.1.2 字段类型及其作用
在Lucene中,索引的数据被存储为一系列的字段,而每个字段都有其对应的类型。字段类型定义了数据的存储方式以及如何被索引。
- 文本字段(TextField) :文本字段通常用于存储需要进行全文搜索的文本数据。
- 未分词字段(UntokenizedField) :用于存储短文本或关键字,保持其为一个整体,适用于精确匹配。
- 数值字段(NumericField) :用于存储数值类型的数据,如整数、浮点数等。
- 布尔字段(BooleanField) :存储布尔值,用于逻辑判断或过滤条件。
不同类型的字段适用于不同的搜索需求。例如,数值字段可用于数值范围的查询,而未分词字段适用于短语查询。
2.2 词项和倒排索引的建立
2.2.1 词项的概念和处理过程
词项是倒排索引中的核心元素,它代表了文档中的一个唯一词汇。词项处理包括创建词项列表,确定词项的频率和位置信息。
处理过程如下:
- 文档读取 :首先对每个文档内容进行读取。
- 分词 :对文档内容进行分词,生成词项列表。
- 词项统计 :计算每个词项在文档中的出现频率以及位置信息。
- 存储 :将词项及其相关统计信息存储起来,用于后续的索引和搜索。
2.2.2 倒排索引的结构和构建方法
倒排索引(Inverted Index)是一种索引结构,它将词项映射到包含该词项的所有文档。它由两个主要部分组成:
- 词典(Vocabulary) :包含索引中所有唯一词项的有序列表。
- 倒排列表(Posting List) :对于词典中的每个词项,都有一个倒排列表记录了包含该词项的所有文档的引用。
构建倒排索引的方法:
- 初始化词典 :创建一个空的词典,用于存储词项。
- 遍历文档集 :逐个处理每个文档,对文档内容进行分词和处理。
- 填充词典和倒排列表 :将词项添加到词典中,并更新倒排列表,记录词项在文档中的位置和频率。
- 优化索引 :完成所有文档的处理后,对索引进行优化,如删除停止词索引项、合并小倒排列表等。
2.3 索引优化策略
2.3.1 索引大小和性能的平衡
在索引过程中,需要平衡索引的大小和搜索性能。
- 索引压缩 :为了减少索引大小,可以使用索引压缩技术,例如变长编码、字典编码等。
- 字段选择 :仅对需要进行搜索的字段建立索引,避免对不必要的字段进行索引。
- 索引分片 :将索引分成多个分片,通过并行处理提高索引速度。
2.3.2 索引更新和维护的高效方法
随着数据的不断增加,高效地更新和维护索引变得至关重要。
- 增量更新 :只更新变化的部分而不是重建整个索引。
- 事务日志 :记录索引操作的日志,以便在系统崩溃后可以恢复到最近的稳定状态。
- 后台合并 :定期将小的倒排索引合并为大的倒排索引,以减少索引分片数量并优化搜索性能。
在本章节中,我们详细介绍了索引过程的基本概念、词项与倒排索引的建立以及索引优化策略。通过这些内容,读者应该对Lucene的索引机制有了一个深入的理解。接下来,我们将继续探讨查询解析与搜索技术,进一步了解Lucene是如何从建立的索引中检索出用户所需信息的。
3. 查询解析与搜索技术
在前一章中我们已经深入了解了Lucene的索引过程和构建原理,接下来我们将深入探讨查询解析和搜索技术。Lucene的搜索功能强大而灵活,支持多种复杂的查询方式,利用了诸如布尔逻辑、短语查询、TF-IDF算法和相关性排序等技术。此外,为了满足日益增长的性能需求,Lucene还提供了各种搜索优化手段。
3.1 查询语言解析
3.1.1 布尔逻辑在查询中的应用
查询语言是用户与搜索系统交互的界面,其中布尔逻辑是构成查询表达式的基石。布尔逻辑包括三个基本操作:与(AND)、或(OR)、非(NOT),它们在Lucene查询中均有实现。
在Lucene中,布尔操作符用于组合多个查询条件,精确地控制返回搜索结果集。例如,如果用户想要查询"咖啡"和"书"都出现在文档中的记录,可以使用"咖啡 AND 书";如果用户想要获取包含"咖啡"或者"茶"的文档,可以使用"咖啡 OR 茶";如果用户想要排除包含"咖啡"的文档,可以使用"NOT 咖啡"。
Lucene通过QueryParser类来解析这些布尔表达式。这个类将用户输入的字符串解析为Lucene能理解的Query对象。例如:
Query q = QueryParser.parse("咖啡 AND 书", "content", analyzer);
在这个例子中, content 是我们要搜索的字段名, analyzer 是用于文本分析的分词器。
布尔逻辑的运用允许用户构建复杂的搜索条件,是实现高级搜索功能不可或缺的一部分。
3.1.2 短语查询和邻近查询的处理
短语查询用于精确匹配一系列单词的顺序。例如,如果用户想要搜索"lucene for dummies"这个确切短语,可以使用短语查询:
Query q = QueryParser.parse("\"lucene for dummies\"", "content", analyzer);
邻近查询则可以用来搜索在一定词间距内的词组。例如,如果想要找到文档中"lucene"和"dummies"两个词之间最多相隔2个词的记录,可以这样做:
Query q = QueryParser.parse("lucene NEAR/2 dummies", "content", analyzer);
这两个查询类型都属于精确查询,通常用于那些需要严格匹配的场景。
3.2 搜索算法深入分析
3.2.1 TF-IDF算法的原理和计算
TF-IDF(Term Frequency-Inverse Document Frequency)算法用于评估一个词语对于一个文档集或者一个语料库中的其中一份文档的重要程度。TF-IDF算法的核心思想是:如果某个词在一篇文章中出现的频率高(TF),并且在其他文档中很少出现(IDF),那么这个词就越能代表该文档。
在Lucene中,这个算法被用于相关性评分,以帮助系统决定哪些文档与查询条件更为相关。TF-IDF的计算公式如下:
TF-IDF(t, d) = TF(t, d) * log(IDF(t, D))
其中,TF(t, d)表示词t在文档d中出现的频率,IDF(t, D)表示在文档集D中,词t的逆文档频率,计算公式为:
IDF(t, D) = log(|D| / (|{d ∈ D: t ∈ d}| + 1))
3.2.2 相关性排序的实现机制
Lucene使用一个名为BM25的算法来对搜索结果进行相关性排序,BM25是TF-IDF算法的改进版,它通过调整词频和文档频率的比例来优化排名结果。
在实现机制上,Lucene通过IndexSearcher类的search方法来执行搜索,并返回一个排序后的TopDocs对象。这个过程包括以下几个步骤:
- 用户输入搜索条件,并提交查询。
- Lucene解析查询语句,构建Query对象。
- IndexSearcher搜索索引,并计算每个文档的相关性得分。
- Lucene根据得分对结果进行排序,并返回得分最高的TopN个文档。
代码示例:
TopDocs docs = searcher.search(query, null, 10);
这段代码执行了搜索操作,并要求返回排名前10的结果。文档排名是根据相关性得分来确定的。
3.3 搜索过程的优化
3.3.1 搜索性能的提升方法
提升搜索性能是确保用户获得快速响应的关键。Lucene提供了一些优化搜索性能的策略:
- 索引预热 :在搜索前,先加载索引到内存中,可以加快搜索速度。
- 查询缓存 :通过缓存之前执行过的搜索结果,可以在用户进行重复查询时减少计算量。
- 字段加权 :根据需要,可以给不同的字段设置不同的权重,影响查询结果的排序。
- 布尔查询优化 :避免使用过于复杂的布尔查询,因为它们可能会导致性能下降。
3.3.2 查询缓存和结果缓存技术
查询缓存是通过存储前一个相同查询的结果来加速后续相同查询的处理,而结果缓存则是存储整个搜索的结果集。
在Lucene中,可以通过以下方式实现查询缓存:
CachingWrapperFilter cachingFilter = new CachingWrapperFilter(queryCache);
这里,queryCache是一个预先设置好的查询缓存实例。将这个缓存过滤器加入查询管道中,可以提高查询效率。
而结果缓存可以通过以下方式实现:
TopFieldCollector collector = TopFieldCollector.create(
SortingFactory.DEFAULT, 10, true, true, false, false);
searcher.search(query, cachingFilter, collector);
TopFieldDocs topDocs = ***Docs();
在这个例子中,我们使用了TopFieldCollector来创建一个结果缓存,并且在执行搜索时指定了这个缓存。
通过这些策略,开发者可以在保持搜索准确性的前提下,显著提高搜索的速度和效率。
4. Lucene扩展与优化实践
在当今这个大数据的时代,数据的存储、检索和处理变得越来越重要。Lucene作为一个功能强大的搜索引擎库,它的应用范围非常广泛。除了本身提供的强大搜索能力之外,Lucene还有一些扩展和优化的实践,能进一步提升系统性能和用户体验。在本章中,我们将深入探讨Lucene的分布式搜索框架Solr、Lucene的附加功能应用,以及性能调优和故障排查的方法。
4.1 Lucene的分布式搜索框架Solr
4.1.1 Solr的安装和配置
Solr是由Apache软件基金会开发的一个开源搜索平台,建立在Lucene库之上,提供了REST API风格的查询语言和处理分布式索引的管理能力。首先,我们需要安装和配置Solr,以便开始使用这个强大的搜索框架。
安装Solr
安装Solr的第一步是下载最新的Solr发行版。打开官方下载页面,选择适合你的操作系统的版本进行下载。下载完成后,解压到一个指定的目录。
# 假设下载到的文件名为solr-<version>.tgz
tar xzf solr-<version>.tgz solr-<version>/bin/install_solr_service.sh --strip-components=2
sudo ./install_solr_service.sh solr-<version>.tgz
上述命令会安装Solr服务,并将其注册为系统服务,从而允许使用操作系统的标准工具来管理Solr进程。
配置Solr
配置Solr主要包括定义集合(collections)和核心(cores)。集合是Solr中用于分布式搜索和索引复制的数据结构。你可以通过Solr的管理界面来创建集合。核心则是索引的容器,每个核心都有自己的配置和索引数据。
<!-- 创建名为mycollection的集合 -->
<requestHandler name="/replication" class="solr.ReplicationHandler">
<lst name="master">
<str name="replicateAfter">commit</str>
<str name="replicateAfter">optimize</str>
<str name="confFiles">solrconfig.xml,stopwords.txt</str>
</lst>
</requestHandler>
通过上述配置,我们指定了当数据提交(commit)或者优化(optimize)时进行复制,并且指定了需要复制的配置文件。
启动和验证Solr
启动Solr服务后,可以通过Solr管理界面来验证安装是否成功。启动服务可以使用如下命令:
sudo service solr start
在浏览器中输入 *** ,如果能够看到Solr的管理界面,说明安装和配置成功。
4.1.2 SolrCloud的集群管理
SolrCloud是Solr的集群解决方案,提供了一个高可用和可扩展的平台。接下来我们将介绍如何管理SolrCloud集群。
集群架构
在SolrCloud中,集群是由一系列的节点组成的,每个节点都是一个运行Solr的JVM进程。节点可以配置为领导者(leader)或跟随者(follower),领导者负责处理客户端的请求,而跟随者复制领导者的更改。
配置ZooKeeper
SolrCloud使用ZooKeeper来管理集群状态和配置信息。每个节点需要指向ZooKeeper集群。配置 solr.xml 文件,添加ZooKeeper服务器地址:
<solr>
<str name="zkHost">node1:2181,node2:2181,node3:2181</str>
</solr>
创建集群和集合
通过Solr管理界面,我们可以创建集群和定义集合。集合可以配置为不同的副本数量,以保证数据的可靠性和冗余度。
# 创建名为mycollection的集合,副本数量为3
./solr create -c mycollection -p 8983 -s 3
集群的日常管理
集群的日常管理包括添加和移除节点、更新配置、监控集群状态等。这些操作都可以通过SolrCloud的管理界面或使用Solr提供的命令行工具来完成。
4.2 Lucene的附加功能应用
4.2.1 高亮显示技术的实现
在搜索结果中高亮显示匹配的关键词是一种常见的用户体验优化手段。Lucene通过Highlighter API提供了高亮显示功能。
实现高亮显示
使用Highlighter进行高亮显示需要三个步骤:创建一个查询、创建一个 Highlighter 对象、使用 Highlighter 对象进行高亮显示。
// 创建Query对象
Query query = new QueryParser("contents", analyzer).parse("*:*");
// 创建Highlighter对象
Highlighter highlighter = new Highlighter(new QueryScorer(query));
// 创建SimpleHTMLFormatter对象,可以自定义前后缀
SimpleHTMLFormatter formatter = new SimpleHTMLFormatter("<b>", "</b>");
// 使用highlighter进行高亮显示
TokenStream tokenStream = TokenSources.getTokenStream("contents", reader, fieldSelector);
String highlightedText = highlighter.getBestFragment(formatter, tokenStream, "the text to highlight");
上述代码展示了如何使用Highlighter API来实现高亮显示。首先通过查询构建器创建一个查询对象,然后创建一个Highlighter对象,并且通过SimpleHTMLFormatter定义高亮显示的格式。最后,使用Highlighter对象和TokenStream来获取高亮显示的文本片段。
4.2.2 近实时搜索的原理和效果
近实时搜索(Near Real Time, NRT)允许用户在数据被索引后的短暂延迟内搜索到这些数据。Lucene通过添加事务日志(CommitLog)来实现NRT。
近实时搜索的工作原理
在使用Lucene索引文档时,系统会将索引操作写入事务日志。在进行搜索时,Lucene会读取这些事务日志,并将未提交的数据合并到搜索结果中。这样,即使数据还未被提交到主索引,用户也能搜索到这些数据。
实现近实时搜索
为了实现近实时搜索,你需要确保Lucene的配置允许使用事务日志。在 solrconfig.xml 中设置 useTransactionLog 为 true ,并且确认 commitWithin 参数被设置为一个合理的值(如1000毫秒),以便系统知道提交数据的最大延迟时间。
<requestHandler name="/select" class="solr.SearchHandler">
<!-- 在此处配置请求处理器 -->
<lst name="defaults">
<int name="rows">10</int>
<str name="echoParams">explicit</str>
<bool name="useTransactionLog">true</bool>
<int name="commitWithin">1000</int>
</lst>
</requestHandler>
通过上述配置,可以有效提升Lucene处理近实时搜索的效率和响应速度。
4.3 性能调优和故障排查
4.3.1 性能分析工具的使用
为了提升Lucene的性能,我们需要使用一些性能分析工具来监控和诊断性能瓶颈。
使用Lucene自带的监控工具
Lucene提供了一系列的监控工具,例如 PerFieldAnalyzerWrapper 可以用来分析不同字段的性能; IndexSearcher 的日志信息可以用来分析搜索性能。
// 使用PerFieldAnalyzerWrapper来分析不同字段的性能
PerFieldAnalyzerWrapper analyzerWrapper = new PerFieldAnalyzerWrapper(new WhitespaceAnalyzer());
analyzerWrapper.addAnalyzer("contents", new KeywordAnalyzer());
// 使用IndexSearcher的getTopReaderContext()方法来获取索引读取上下文
TopDocs topDocs = searcher.search(query, null, 10);
使用第三方性能分析工具
除了Lucene自带的工具外,还有一些第三方的性能分析工具,如Apache JMeter、Elasticsearch的Search Profiler等,可以用来模拟高负载下Lucene的性能表现。
4.3.2 常见性能问题的诊断与解决
Lucene的性能问题可能来源于多个方面,比如索引大小、查询复杂度、硬件性能等。下面是如何诊断和解决常见性能问题的步骤。
索引大小和性能的平衡
当索引大小增长时,搜索性能可能会受到影响。可以通过优化索引结构、压缩索引或使用分区索引来减少索引大小。
索引更新和维护的高效方法
索引的频繁更新可能会影响性能,特别是在近实时搜索的场景下。合理使用提交间隔、调整合并策略和优化索引写入吞吐量是优化更新操作的有效方法。
硬件性能的提升
硬件性能的提升也是一个常见的优化方式,比如增加内存容量、使用更快的硬盘、增加CPU资源等。提升硬件资源可以在不改变软件代码的情况下,有效提升系统性能。
通过上述分析,我们可以看到,对于Lucene而言,合理的索引优化和查询优化策略能够显著提升搜索性能。同时,通过使用Solr来实现分布式搜索和集群管理,可以进一步提高系统的可用性和扩展性。在实际应用中,还需要根据具体的应用场景,灵活应用和扩展这些技术,以适应不断变化的需求。
5. Lucene在不同应用中的实际应用案例
5.1 Lucene在Web应用中的集成
5.1.1 前端搜索框的实现
在现代Web应用中,集成一个高效的搜索框是提供良好用户体验的关键一环。使用Lucene可以快速实现一个强大的搜索引擎,而无需依赖外部服务。在本节中,我们将详细介绍如何在Web应用中实现一个前端搜索框,并使用Lucene作为后端的搜索引擎。
技术实现步骤:
- 设计搜索框界面 :在前端页面上创建一个搜索框,通常是一个HTML表单元素
<input type="text">。 - 设置事件监听器 :当用户在搜索框中输入查询时,需要绑定一个事件监听器来捕捉这些输入。这通常使用JavaScript完成,例如使用
addEventListener。 - 发送异步请求 :用户输入的查询通过AJAX请求发送到服务器。AJAX允许我们异步地与服务器通信,不影响页面的其他部分。
- 服务器端处理 :服务器接收到查询后,使用Lucene进行搜索处理。这一部分通常涉及到对Lucene API的调用,以及搜索结果的获取。
- 返回结果到前端 :搜索完成后,将结果格式化为JSON或其他格式,然后发送回前端。
- 前端展示结果 :前端JavaScript代码解析服务器返回的数据,并动态更新页面来展示搜索结果。
代码示例:
<!-- 搜索框的HTML结构 -->
<input type="text" id="searchBox" placeholder="Search..." />
<div id="results"></div>
<!-- JavaScript部分 -->
<script>
document.getElementById('searchBox').addEventListener('input', function(e) {
var query = e.target.value;
// 发送AJAX请求到服务器
fetch('/search?query=' + encodeURIComponent(query))
.then(response => response.json())
.then(data => {
// 将搜索结果展示到页面上
var resultsContainer = document.getElementById('results');
resultsContainer.innerHTML = data.map(item => `<div>${item}</div>`).join('');
})
.catch(error => console.error('Error:', error));
});
</script>
在服务器端,你需要有一个能够处理搜索请求并调用Lucene进行搜索的端点:
# 假设使用Python Flask框架
from flask import Flask, request, jsonify
from lucene import search
app = Flask(__name__)
@app.route('/search')
def search_handler():
query = request.args.get('query', '')
results = search(query) # search()是一个假设的函数来处理搜索逻辑
return jsonify(results)
if __name__ == '__main__':
app.run()
这个过程展示了如何将用户查询与后端的Lucene索引结合起来,并将搜索结果返回到前端。在实际应用中,你需要创建合适的索引模型,调用合适的Lucene搜索函数,并处理可能出现的异常。
5.1.2 搜索结果的动态展示
当用户在前端搜索框中输入查询并提交搜索请求后,服务器需要处理这些请求并返回搜索结果。在本小节中,我们将探讨如何实现搜索结果的动态展示,即如何将从Lucene检索到的数据展示给用户。
动态展示的步骤:
- 查询Lucene索引 :使用Lucene提供的API根据用户的输入构建查询,并在索引中搜索匹配的文档。
- 获取搜索结果 :从Lucene获取查询结果,这通常是一个文档集合(Document list)。
- 数据转换和格式化 :将Lucene返回的搜索结果集转换为适合在Web页面上展示的格式,如JSON、HTML等。
- 更新页面内容 :使用JavaScript动态更新页面的内容,将搜索结果显示给用户。这可能涉及到DOM操作,如添加、删除或修改页面元素。
代码示例:
假设我们已经使用Lucene得到了搜索结果,下面是如何将这些结果格式化并展示在页面上的JavaScript代码示例。
// 假设这是从服务器接收到的搜索结果
var searchResults = [
{ id: 1, title: "Document 1", content: "Content of document 1" },
{ id: 2, title: "Document 2", content: "Content of document 2" },
// ... 更多结果
];
// 动态创建展示搜索结果的HTML元素
function displayResults(results) {
var resultsContainer = document.getElementById('results');
resultsContainer.innerHTML = ''; // 清空之前的搜索结果
results.forEach(function(result) {
// 创建结果项的HTML结构
var resultItem = document.createElement('div');
resultItem.className = 'search-result';
resultItem.innerHTML = `
<h3>${result.title}</h3>
<p>${result.content}</p>
`;
// 将结果项添加到结果容器中
resultsContainer.appendChild(resultItem);
});
}
// 调用函数展示结果
displayResults(searchResults);
在上述示例中,我们假设 searchResults 是从服务器返回的搜索结果数组,每个对象包含一个文档的ID、标题和内容。 displayResults 函数接受这些结果作为参数,创建相应的HTML结构,并动态地将它们添加到页面的搜索结果容器中。
5.2 Lucene在企业级搜索的应用
5.2.1 大数据量的索引和查询
在处理企业级应用时,经常会遇到需要处理大量数据的情况。因此,如何有效地为这些大数据量建立索引,并提供快速的查询能力,是应用Lucene时需要重点考虑的问题。
大数据量索引策略:
- 分批索引 :对于大量的数据,可以将其分成多个批次进行索引。这有助于管理内存使用,并且可以进行增量索引更新。
- 分布式索引 :在Lucene中实现分布式索引,可以将数据分布到多个服务器上进行索引,然后合并各个服务器上的索引,以此来处理大数据量。
- 索引合并与优化 :定期对索引进行合并和优化,以减少索引的碎片化,提高查询效率。
大数据量查询策略:
- 查询缓存 :利用查询缓存来存储常用的查询结果,避免对索引的重复搜索,可以显著提高查询响应速度。
- 分片查询 :将大数据量的索引分片,对每个分片进行查询,然后合并查询结果,可以提高并发处理能力和吞吐量。
- 查询优化 :优化查询表达式和查询性能,使用更有效的查询语法,如布尔查询、范围查询、近似匹配等。
代码示例与逻辑分析:
// 示例代码展示如何分批构建索引
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.RAMDirectory;
public void batchIndexing(List<Document> documents) throws IOException {
StandardAnalyzer analyzer = new StandardAnalyzer();
Directory directory = new RAMDirectory();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter writer = new IndexWriter(directory, config);
// 假设documents是准备索引的文档集合
// 将文档集合分割成固定大小的批次进行索引
final int BATCH_SIZE = 10000;
List<Document> batch = new ArrayList<>(BATCH_SIZE);
for (Document doc : documents) {
batch.add(doc);
if (batch.size() == BATCH_SIZE) {
writer.addDocuments(batch);
batch.clear();
}
}
// 添加剩余的文档
writer.addDocuments(batch);
writer.close();
}
上面的Java代码片段展示了如何将一个大的文档集合分批索引。这是通过创建一个批处理列表,将文档添加到该批处理列表中,直到达到预设的批次大小后,使用Lucene的 IndexWriter 类将其添加到索引中,然后清空批处理列表,继续添加新的文档。
参数说明:
-
documents:一个包含所有待索引文档的列表。 -
BATCH_SIZE:批处理列表的大小。这可以根据可用内存和文档大小进行调整。 -
StandardAnalyzer:用于分析文档并建立索引的分词器。 -
RAMDirectory:用于存储索引的目录。这里使用RAMDirectory可以提高索引速度,因为所有的操作都在内存中完成,适用于需要快速索引的场景。
通过上述代码和策略,可以在保持性能的同时有效地索引大量数据,为企业级应用提供快速可靠的搜索功能。
5.2.2 安全性和访问控制的实现
在企业环境中,数据的安全性和访问控制是至关重要的。利用Lucene实现企业级搜索时,需要确保对敏感数据的保护,以及对用户访问权限的管理。
实现安全性和访问控制的策略:
- 权限管理 :为不同的用户或用户组设置访问权限,控制哪些用户可以索引、搜索和更新数据。
- 数据加密 :对敏感数据进行加密,确保数据在索引和搜索过程中的安全。
- 访问控制列表(ACL) :实施基于ACL的访问控制策略,只有拥有相应权限的用户才能执行特定操作。
- 审计日志 :记录所有索引和搜索操作的详细信息,便于问题追踪和合规性审查。
代码示例与逻辑分析:
// 示例代码展示如何在Lucene中应用权限控制
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.RAMDirectory;
public void addDocumentWithSecurity(Directory directory, Document doc, String user) throws IOException {
// 假设我们在索引过程中检查用户的权限
if (isUserAllowed(user)) {
try (IndexWriter writer = new IndexWriter(directory, new IndexWriterConfig().openMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND))) {
// 将用户信息添加为文档的一个字段
doc.add(new StringField("user", user, Field.Store.YES));
writer.addDocument(doc);
}
} else {
throw new IOException("User does not have access rights.");
}
}
// 检查用户是否有权索引文档的示例函数
private boolean isUserAllowed(String user) {
// 这里应包含检查用户权限的逻辑,比如查询ACL表
return user.equals("admin") || user.equals("editor");
}
在这段示例代码中,我们在添加文档到索引之前检查用户的权限。 isUserAllowed 方法应该实现检查用户是否有权索引文档的逻辑。在实际应用中,这可能需要查询一个包含用户权限的数据库或ACL(访问控制列表)。
参数说明:
-
directory:索引存储的目录。 -
doc:要索引的文档对象。 -
user:试图索引该文档的用户。 -
StringField("user", user, Field.Store.YES):将用户信息存储为文档的一个字段,这对于后续实现基于用户的查询非常有用。
通过实施这些策略,你可以确保在利用Lucene进行企业级搜索时,数据安全性和用户权限得到有效管理。
6. 学习资源与提升Lucene技能的方法
深入学习和掌握Lucene不仅需要理解其架构和原理,还需要通过实践和学习资源不断深化理解和技能。接下来将详细介绍学习Lucene官方文档、参与社区资源、实战项目案例剖析以及进阶指南等方面的内容。
6.1 学习Lucene的官方文档和社区资源
6.1.1 官方文档的阅读和理解
Lucene的官方文档是学习和掌握其技术细节最直接、最权威的资源。官方文档包含了丰富的概念性描述、API参考以及高级特性介绍。例如,对于初学者而言,了解如何创建和配置索引以及如何进行基本的查询是基础。而对于进阶用户,深入理解倒排索引的原理、查询解析机制和索引优化策略是提升技能的关键。
在官方文档中,可以通过以下步骤系统性地学习Lucene:
- 概念和术语 :从基本概念开始学习,比如文档、字段、索引、查询等。
- API使用 :学习如何使用Lucene提供的API进行索引构建和搜索操作。
- 示例代码 :通过阅读和运行官方示例代码加深对API使用的理解。
- 进阶特性 :探索和学习倒排索引、查询解析器、搜索算法等高级特性。
- 性能优化 :了解如何通过优化Lucene配置提升搜索性能。
6.1.2 社区支持和讨论的参与
Lucene社区非常活跃,提供了一个交流和求助的平台。社区资源包括论坛、邮件列表、聊天室和用户群组等。加入Lucene社区不仅可以帮助解决问题,还可以了解最新动态和趋势。
参与社区的步骤可以包括:
- 论坛发帖 :遇到问题时,可以在社区论坛中发帖求助。
- 邮件列表 :订阅邮件列表,获取最新消息和讨论内容。
- 参与讨论 :参与聊天室和用户群组的讨论,与社区成员交流经验。
- 贡献代码 :有能力的用户可以参与Lucene的开源项目,为社区贡献代码。
- 反馈问题 :遇到bug时,积极反馈到社区中,推动问题解决。
6.2 实战项目和案例研究
6.2.1 开源项目案例的剖析
在学习Lucene的过程中,直接参与开源项目是非常有效的提升方式。通过阅读和分析项目源码,可以了解如何在实际项目中应用Lucene。以下步骤可以帮助你更深入地理解开源项目:
- 选择项目 :选择一个与你工作相关的项目开始研究。
- 代码审查 :详细审查项目的代码库,理解Lucene的具体应用。
- 运行项目 :亲自运行项目,观察Lucene在实际环境中的表现。
- 环境部署 :搭建项目环境,对Lucene进行配置和调整。
- 功能扩展 :尝试对项目进行功能扩展,以实践和巩固所学知识。
6.2.2 行业案例的实践分析
除了开源项目,分析行业中的实际案例也能帮助你理解Lucene的应用场景和挑战。下面是一个行业案例分析的示例表格:
| 行业领域 | 挑战 | 解决方案 | 成功要素 | |-----------|-------|-----------|-----------| | 电子商务 | 商品搜索的精确度和速度 | 使用Lucene构建高效的倒排索引,实现复杂的查询解析 | 索引更新机制、查询性能优化 | | 企业文档管理 | 大量文档的存储和快速检索 | 实现分布式索引和查询,保证数据的安全性和可靠性 | 高效的索引分片、加密存储技术 | | 科学研究 | 处理大量非结构化数据 | 利用Lucene的高级特性进行复杂数据的索引和搜索 | 自然语言处理技术、个性化搜索算法 |
通过分析不同行业领域中的实际应用案例,可以发现Lucene的多样性和灵活性,以及在特定场景下的优化和应用策略。
6.3 深入学习和进阶指南
6.3.1 高级特性的学习路径
掌握Lucene的高级特性可以显著提升你的搜索解决方案的质量。以下是一些建议的学习路径:
- 分布式搜索 :学习如何使用Lucene的分布式搜索框架,如Solr,以支持大规模数据集的搜索需求。
- 性能优化 :深入学习索引和查询优化技术,包括硬件选型、索引结构优化等。
- 文本分析 :掌握分词、词干提取、停用词处理等文本分析技术,以提高搜索的相关性和准确性。
6.3.2 专业书籍和课程推荐
为了进一步提升技能,推荐一些专业书籍和在线课程,这些资源可以帮助你更系统地学习Lucene。
| 类别 | 资源名称 | 简介 | |------|-----------|------| | 书籍 | "Lucene in Action" | 由Lucene核心开发者编写,介绍了Lucene的使用和高级特性 | | 书籍 | "Mastering ElasticSearch" | 虽然偏重Elasticsearch,但同样适用于Lucene用户学习搜索技术 | | 课程 | Udemy的"Solr and Lucene for Developers" | 该课程详细介绍了如何使用Solr和Lucene进行搜索和索引 | | 课程 | Coursera的"Search Engines: Information Retrieval in Practice" | 该课程从理论到实践全面讲解了搜索技术 |
通过阅读专业书籍、参加在线课程,并结合实践项目,你可以有效地提升在Lucene领域的专业技能。
7. Lucene的性能优化与高级特性应用
7.1 索引存储和压缩技术
在处理大量数据时,索引的存储效率和压缩技术显得尤为重要。Lucene提供了多种索引存储格式,每种格式都有其独特的优势。例如,Lucene的原始索引格式(在Lucene 3.x版本中使用)支持快速读写,但压缩效率较低。而PostingsFormat的改进版本(在Lucene 4.x版本中引入)提高了压缩效率,并且在读取速度上也有所优化。
7.1.1 索引压缩策略
Lucene使用一系列算法来压缩索引数据,减少了磁盘空间的占用,并能减少I/O操作,提升整体性能。常见的索引压缩技术包括:
- VInt和Zippy编码 :用于整数的高效压缩。
- PackedInts :优化了整数数组的压缩,可以更高效地存储文档频率信息和项频信息。
- LiveDocs格式 :用于压缩删除标记,节省空间。
代码块示例
Lucene提供了API来检查当前使用的索引格式和压缩技术。以下是一个检查索引压缩技术和存储格式的代码示例:
import org.apache.lucene.index.IndexFormatживые
import org.apache.lucene.index.IndexReader
public class IndexCompressionInfo {
public static void checkIndexCompression(String indexPath) throws IOException {
IndexReader reader = DirectoryReader.open(FSDirectory.open(new File(indexPath).toPath()));
System.out.println("Index format: " + reader.getVersion().name());
System.out.println("Postings format: " + reader.getCommitUserData().get("index.postings_format"));
System.out.println("压缩技术: ");
PackedInts.Reader[] fieldInfos = (PackedInts.Reader[]) reader.getLiveDocs();
for (PackedInts.Reader fieldInfo : fieldInfos) {
if (fieldInfo != null) {
System.out.println("Field " + fieldInfo.getName() + " uses packing format " + fieldInfo.getFormat());
}
}
reader.close();
}
}
该代码示例中,我们首先打开一个索引目录的读取器,然后打印出索引的版本信息和压缩技术。这对于诊断性能问题和优化索引非常有帮助。
7.2 分析器和过滤器的高级使用
Lucene的分析器(Analyzer)和过滤器(Filter)机制对于文本的预处理至关重要。它们可以帮助我们去除停用词、进行词干提取、转换文本格式等。理解和利用这些工具,可以帮助开发者构建更有效的搜索和索引策略。
7.2.1 自定义分析器
自定义分析器可以针对特定的需求进行文本处理。以下是一个实现自定义分词和过滤的例子,包括了一个自定义分词器和停用词过滤器:
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.standard.StandardTokenizer;
import org.apache.lucene.analysis.core.StopFilter;
import org.apache.lucene.analysis.CharArraySet;
public class CustomAnalyzer extends Analyzer {
private CharArraySet stopWords;
public CustomAnalyzer() {
stopWords = new CharArraySet(List.of("stop", "word", "list"), false);
}
@Override
protected TokenStreamComponents createComponents(String fieldName) {
final TokenStreamComponents ts = new TokenStreamComponents(new StandardTokenizer());
TokenStream result = new StopFilter(ts.getTokenStream(), stopWords);
return new TokenStreamComponents(ts.getTokenizer(), result);
}
}
在这个例子中, CustomAnalyzer 类扩展了 Analyzer 基类,并重写了 createComponents 方法来实现自定义的分词和过滤逻辑。
7.3 高级查询技巧
Lucene查询语言支持复杂的查询构造,如范围查询、通配符查询和模糊查询等,这些高级查询技巧对于提升搜索精度和灵活性至关重要。
7.3.1 范围查询与通配符查询
范围查询和通配符查询是构建复杂搜索需求的常用工具。范围查询允许用户查找落在特定范围内的数据,而通配符查询则支持模糊匹配。
import org.apache.lucene.search.BooleanClause;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.WildcardQuery;
import static org.apache.lucene.index.Term.term;
public class AdvancedQueryExample {
public static Query createRangeQuery(String fieldName, String lowerVal, String upperVal) {
return LongPoint.newRangeQuery(fieldName, Long.parseLong(lowerVal), Long.parseLong(upperVal));
}
public static Query createWildcardQuery(String fieldName, String pattern) {
return new WildcardQuery(term(fieldName, pattern));
}
public static Query createBooleanQuery() {
BooleanQuery.Builder builder = new BooleanQuery.Builder();
Query termQuery = new TermQuery(term("title", "lucene"));
Query wildcardQuery = createWildcardQuery("author", "d*ck*");
builder.add(termQuery, BooleanClause.Occur.SHOULD);
builder.add(wildcardQuery, BooleanClause.Occur.SHOULD);
return builder.build();
}
}
在这段代码中,我们构建了一个复合查询(BooleanQuery),将范围查询和通配符查询结合起来,提供了一个更为复杂的搜索条件。
7.4 词典和同义词扩展
在某些情况下,用户希望搜索结果能够包含同义词或相关词。Lucene支持通过词典和同义词扩展机制来实现这一需求。
7.4.1 同义词过滤器
同义词过滤器(SynonymFilter)是处理同义词问题的一种有效方式。通过定义同义词文件,可以将搜索扩展到语义相关的词汇。
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.analysis.synonym.SynonymFilter;
import org.apache.lucene.analysis.synonym.SynonymMap;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.core.StopFilter;
import org.apache.lucene.analysis.standard.StandardTokenizer;
public class SynonymAnalyzer extends Analyzer {
@Override
protected TokenStreamComponents createComponents(String fieldName) {
final TokenStreamComponents ts = new TokenStreamComponents(new StandardTokenizer());
TokenStream result = new StopFilter(ts.getTokenStream(), StandardAnalyzer.STOP_WORDS_SET);
try {
SynonymMap.Builder builder = new SynonymMap.Builder(true);
builder.add(new CharsRef("search"), new CharsRef("lookup"), true);
// 添加更多同义词映射...
SynonymMap synonymMap = builder.build();
result = new SynonymFilter(result, synonymMap, false);
} catch (IOException e) {
e.printStackTrace();
}
return new TokenStreamComponents(ts.getTokenizer(), result);
}
}
在上述代码中,我们通过 SynonymAnalyzer 类扩展了标准分析器,增加了对同义词的处理功能。这样,当用户搜索"search"时,将同时考虑"lookup"的结果。
通过本章的介绍,您已经了解了如何进一步优化Lucene的性能并应用其高级特性。接下来,您将有机会在实践中应用这些知识,提升搜索系统的性能和用户满意度。
简介:Lucene是Java语言开发的开源全文检索库,广泛用于搜索引擎和信息检索系统。本文档深入探讨了Lucene的核心架构、索引过程、查询解析、搜索机制和扩展优化技术。Lucene通过索引和搜索功能使开发者能够高效地处理文本数据检索。文档还介绍了Lucene在实际应用中的案例,以及如何通过学习资源和实践项目提升相关技能。















 8154
8154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









