






我们实际用到的项目大都是有监督的,而人工智能未来的一大难点将会是无监督学习。在前面说过的降维算法,大部分都是无监督,除了LDA。
无监督算法有聚类,密度估计,常常用在做分类或者异常检测上。
一.聚类
聚类就是识别相似的实例把它分配给相似实例所属的集群或者组.它在这些领域用的比较多,客户细分,数据分析,异常检测,半监督学习,搜索引擎,分割图片。
常用的聚类算法有两种,一种是K-means,另一种是DBSCAN
1.K-means算法
这个算法很简单,就是把一组数据分类k个类,使用这个算法的时候一般要指明需要分为K个类。每个类都有1个中心点,它代表这个类的中心。比如,把一个数据集划分为3个类,那么就有三个中心点,其他任何一个数据,计算自己到这三个点之间的距离,距离最短的那个,就是这个点的类。
1.简单的算法过程
(1)随机选择k个点作为中心点,计算每一个中心点到其他点的距离,进行第一次聚类,得到K个类。
(2)对每个类的样本计算均值,均值作为每个类的中心,然后重新聚类,得到新的K个类。
(3)重复第二步,直到类别没有发生变化。
2.选择中心点
K-means算法的初始中心点的选择十分影响聚类结果。有一种叫做k-means++的初始化方法
(1).随机选择第一个中心点
(2).选择第k个中心点的要求是选择一个概率为的实例x(i),其中
是实例x(i)与已经选择的最远中心点的距离。也就是后面选择的中心点要尽量远离已经选择的中心点。
当然,现在使用的k-means算法根本不是上面提到的步骤,因为把所有数据都计算一遍,未免也太慢了。使用的是加速算法,三角不等式的原理。
3.惯性指标
由于中心点的选择,每次结果都不一样,因此,在使用kmeans算法的时候,可以进行多次计算,算出多个中心点和聚类结果,怎么衡量好不好呢?这个指标就是惯性,也就是每个点到其中心点的均方。这个值越小,代表效果约好。
4.k值的选择
得到一个数据集,我们也不知道它应该分为多少类,我们该怎么选择k值?
可以尝试使一组连续的k值,计算惯性,然后画图,每一个k值对应一个惯性值。在曲线的转折点就可能是聚类k值的选择。
当然这个方法有些粗糙,也有更加精确的办法。使用轮廓系数,轮廓系数我前面在机器学习的衡量指标里面讲过了。(a-b)/max(a, b),其中a是与同一个类的其他样本的平均距离,b是平均最近集群距离(也就是其他类的平均距离中最小的那个距离)。轮廓系数在-1到1之间,越大越好。计算每个类的平均轮廓系数,就能得到只好的k值。
5.k-means的局限性和应用
这个算法会被k和初始化的中心点所影响。在聚类之前,最好对样本进行归一化。
应用有许多,比如使用聚类对图像分割,
我在网上随便找了一张图片,一般来讲图片是3维,彩色图至少有3个通道,我找到的这张图有四个通道,那也无所谓。
使用kmeans算法把这朵花分割出来
import matplotlib.pyplot as plt
from sklearn.cluster import KMeansimage = plt.imread('花.png')

X = image.reshape(-1, 4)#把图片转为1维度的数组
#聚类算法
#分割出红色的花
kmeans = KMeans(n_clusters=2)#聚类为两个类别
kmeans = kmeans.fit(X)seg_img = kmeans.cluster_centers_[kmeans.labels_]#按照标签划分
seg_img = seg_img.reshape(image.shape)#转为图像的矩阵
plt.imshow(seg_img)
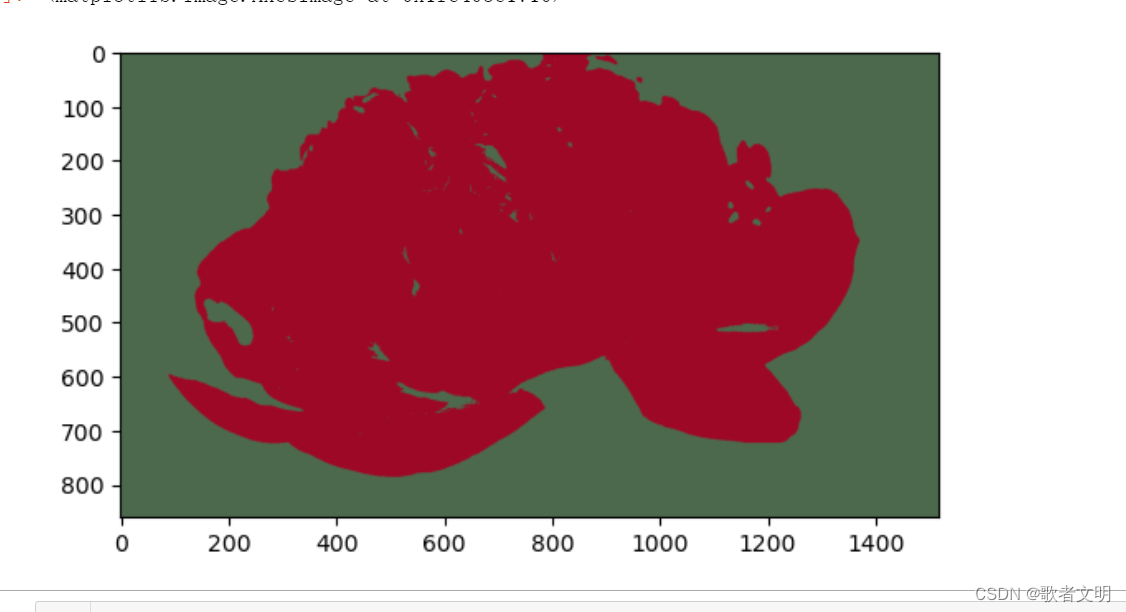
这个是一个十分粗糙的用法。
也能够使用kmeans对数据进行预处理。
也能够进行半监督的学习。比如我们有许多数据,有一些数据有标签,有一些数据没有标签,我们可以使用聚类找到一些有代表性的样本,然后标记,然后用来作为训练样本。这样可以大大提高分类的效率。
2.DBSCAN
这是基于局部密度的算法,它的原理如下
(1).对于每个实例,该算法都很计算在距离它的一小段领域segama内的实例,该区域被称为segama领域
(2).如果一个实例在其segama领域中至少包含min_sample个实例,则该实例被视为核心势力。也就是说核心实例位于密集区域中的实例
(3).核心实例附件所有实例都属于同一个类。由于核心实例附件也有其他核心实例,因而他们链接起来就是一长串。
(4).不是核心实例,而且也不属于这些类的实例,全都是异常。
scikit-learn中提供了这个算法。scikit-learn的接口很同意,比如fit代表训练,transform代表转换返回数据。
在上面的例子中使用kmeans算法就是这样,如果你训练,就用fit,然后想要得到训练后的数据,就可以使用fit_transform
如果要对数据分类,就要使用predict接口。
继续讲DBSCAN吧。
它有点特殊,没有提供predict这样的接口,因为它无法确认新的实例属于哪个实例,但是我们可以自己实现这个算法。
DBSCAN有很多实例,大家可以去官网看看,看官方文档你会收获很多很多,提升自己的认识。
DBSCAN需要的参数有误差eps和min_sample,这两个值对算法的影响很大
其中几个重要的实例有labels_,它返回的是每个样本的标签,标签为-1代表异常
core_sample_indices_变量可以得到核心样本的索引,components_变量可以得到核心样本本身
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=1000, noise=0.05)
#画出图像
plt.scatter(X[:,0], X[:,1], c=y)
#可以看出分为了两个类别
#创建分类器,eps如果取值太小,分类就不好
dbscan = DBSCAN(eps=0.2, min_samples=5)
#训练
dbscan.fit(X)我们可以得到分类良好的部分作为其他分类器的训练样本
X_train = dbscan.components_
y_train = dbscan.core_sample_indices_















 1732
1732











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









