






引入流
流简介
要讨论流,先来谈谈集合,这是最容易上手的方式。Java 8中的集合支持一个新的stream方法,它会返回一个流(接口定义在java.util.stream.Stream里)。在后面会看到,还有很多其他的方法可以得到流,比如利用数值范围或从I/O资源生成流元素。
流到底是什么?简短的定义就是“从支持数据处理操作的源生成的元素序列”。下面会一步步剖析这个定义。
- 元素序列——就像集合一样,流也提供了一个接口,可以访问特定元素类型的一组有序值。因为集合是数据结构,所以它的主要目的是以特定的时间/空间复杂度存储和访问元素(如
ArrayList与LinkedList)。但流的目的在于表达计算,比如前面见到的filter、sorted和map。集合讲的是数据,流讲的是计算。 - 源——流会使用一个提供数据的源,如集合、数组或输入/输出资源。请注意,从有序集合生成流时会保留原有的顺序。由列表生成的流,其元素顺序与列表一致。
- 数据处理操作——流的数据处理功能支持类似于数据库的操作,以及函数式编程语言中的常用操作,如
filter、map、reduce、find、match、sort等。流操作可以顺序执行,也可并行执行。
此外,流操作有两个重要的特点。
- 流水线——很多流操作本身会返回一个流,这样多个操作就可以链接起来,形成一个大的流水线。这让一些优化成为可能,如延迟和短路。流水线的操作可以看作对数据源进行数据库式查询。
- 内部迭代——与使用迭代器显式迭代的集合不同,流的迭代操作是在背后进行的。
让我们来看一段能够体现所有这些概念的代码:
从menu获得流
import static java.util.stream.Collectors.toList;
List<String> threeHighcaloricDishNames =
menu.stream() //从menu获得流(菜肴列表)建立操作流水线:
.filter(d -> d.getCalories() > 300)//首先选出高热量的
.map(Dish::getName)//获取菜名
.limit(3)//只选择头三个
.collect(toList());//将结果保存在另一个List中
System.out.println(threeHighcaloricDishNames);//结果是[pork, beef, chicken]
在本例中,先是对menu调用stream方法,由菜单得到一个流。数据源是菜肴列表(菜单),它给流提供一个元素序列。接下来,对流应用一系列数据处理操作:filter、map、limit和collect。除了collect之外,所有这些操作都会返回另一个流,这样它们就可以接成一条流水线,于是就可以看作对源的一个查询。最后,collect操作开始处理流水线,并返回结果(它和别的操作不一样,因为它返回的不是流,在这里是一个List)。在调用collect之前,没有任何结果产生,实际上根本就没有从menu里选择元素。可以这么理解:链中的方法调用都在排队等待,直到调用collect。下图显示了流操作的顺序:filter、map、limit、collect,每个操作简介如下:
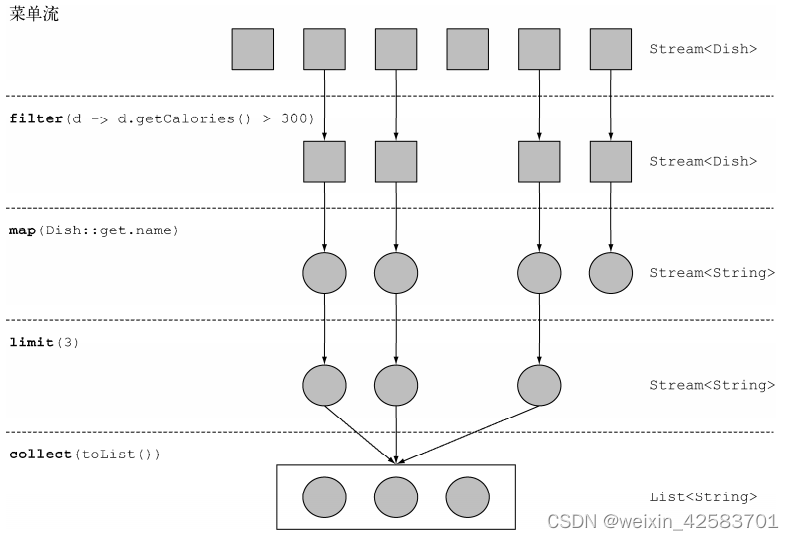
filter——接受Lambda,从流中排除某些元素。在本例中,通过传递lambda d -> d.getCalories() > 300,选择出热量超过300卡路里的菜肴。map——接受一个Lambda,将元素转换成其他形式或提取信息。在本例中,通过传递方法引用Dish::getName,相当于Lambdad -> d.getName(),提取了每道菜的菜名。limit——截断流,使其元素不超过给定数量。collect——将流转换为其他形式。在本例中,流被转换为一个列表。可以把collect看作能够接受各种方案作为参数,并将流中的元素累积成为一个汇总结果的操作。这里的toList()就是将流转换为列表的方案。
这段代码,与逐项处理菜单列表的代码有很大不同。首先,使用了声明性的方式来处理菜单数据,即对这些数据需要做什么:“查找热量最高的三道菜的菜名。”并没有去实现筛选(filter)、提取(map)或截断(limit)功能,Streams库已经自带了。因此,Stream API在决定如何优化这条流水线时更为灵活。例如,筛选、提取和截断操作可以一次进行,并在找到这三道菜后立即停止。
在进一步介绍能对流做什么操作之前,先回过头来看看Collection API和新的StreamAPI的思想有何不同。
流与集合
Java现有的集合概念和新的流概念都提供了接口,来配合代表元素型有序值的数据接口。所谓有序,就是按顺序取用值,而不是随机取用的。这两者有什么区别:
- 比如说存在DVD里的电影,这就是一个集合(也许是字节,也许是帧),因为它包含了整个数据结构。
- 现在再来想想在互联网上通过视频流看同样的电影。现在这是一个流(字节流或帧流)。流媒体视频播放器只要提前下载用户观看位置的那几帧就可以了,这样不用等到流中大部分值计算出来,就可以显示流的开始部分了(想想观看直播足球赛)。特别要注意,视频播放器可能没有将整个流作为集合,保存所需要的内存缓冲区——而且要是非得等到最后一帧出现才能开始看,那等待的时间就太长了。出于实现的考虑,也可以让视频播放器把流的一部分缓存在集合里,但和概念上的差异不是一回事。
粗略地说,集合与流之间的差异就在于什么时候进行计算。集合是一个内存中的数据结构,它包含数据结构中目前所有的值——集合中的每个元素都得先算出来才能添加到集合中。(可以往集合里加东西或者删东西,但是不管什么时候,集合中的每个元素都是放在内存里的,元素都得先算出来才能成为集合的一部分。)
相比之下,流则是在概念上固定的数据结构(不能添加或删除元素),其元素则是按需计算的。这对编程有很大的好处。这个思想就是用户仅仅从流中提取需要的值,而这些值——在用户看不见的地方——只会按需生成。这是一种生产者-消费者的关系。从另一个角度来说,流就像是一个延迟创建的集合:只有在消费者要求的时候才会计算值。
与此相反,集合则是急切创建的(供应商驱动:先把仓库装满,再开始卖)。以质数为例,要是想创建一个包含所有质数的集合,那这个程序算起来就没完没了,因为总有新的质数要算,然后把它加到集合里面。当然这个集合是永远也创建不完的,消费者这辈子都见不着了。
另一个例子是用浏览器进行互联网搜索。假设你搜索的短语在Google或是网店里面有很多匹配项。你用不着等到所有结果和照片的集合下载完,而是得到一个流,里面有最好的10个或20个匹配项,还有一个按钮来查看下面10个或20个。当你作为消费者点击“下面10个”的时候,供应商就按需计算这些结果,然后再送回你的浏览器上显示。
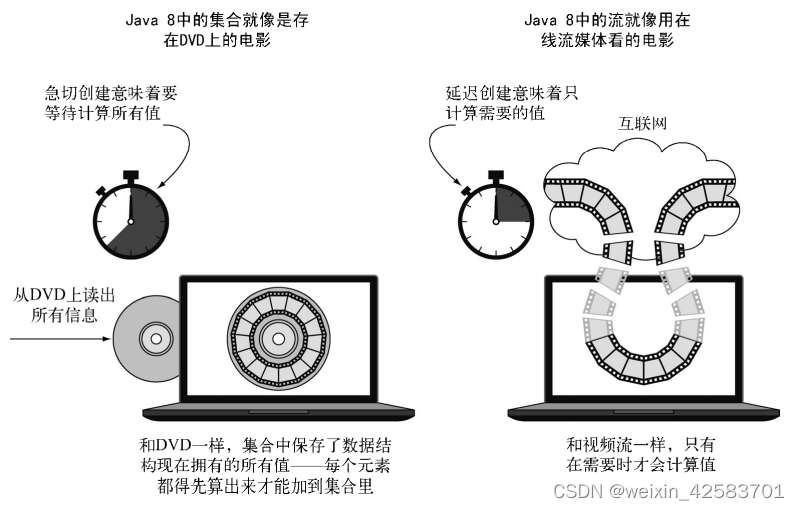
用DVD对比在线流媒体的例子展示了流和集合之间的差异














 8986
8986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









